Universidade Federal Rural de Pernambuco Unidade Acadêmica de Garanhuns
Curso de Bacharelado em Ciência da Computação
ADRIANO DE MELO COSTA
SUPERVISED FRACTIONAL EIGENFACES: Extração de
características para redução de dimensionalidade em
problemas de reconhecimento de faces com técnica derivada
da Análise de Componentes Principais
ADRIANO DE MELO COSTA
SUPERVISED FRACTIONAL EIGENFACES: Extração de
características para redução de dimensionalidade em
problemas de reconhecimento de faces com técnica derivada
da Análise de Componentes Principais
Monografia apresentada ao Curso de Bacharelado em Ciência da Computação da Universidade Federal Rural de Pernambuco da Unidade Acadêmica de Garanhuns, como requisito para obtenção do Grau de Bacharel em Ciência da Computação.
Orientador: Prof. Msc. Tiago Buarque Assunção de Carvalho
Na versão final da monografia, após a defesa e feita as devidas correções no documento, deve ser providenciada a ficha catalográfica. Elaborada pelo bibliotecário da UAG, deve ser colocada no verso da folha anterior.
Essa folha atual deverá conter a folha de aprovação com data e assinatura dos membros da banca. Ela será entregue ao aluno no dia da defesa, devidamente assinada, e deve substituir essa folha onde estão escritas essas informações.
ADRIANO DE MELO COSTA
SUPERVISED FRACTIONAL EIGENFACES: Extração de características para redução de dimensionalidade em problemas de reconhecimento de
faces com técnica derivada da Análise de Componentes Principais
Monografia apresentada ao Curso de Bacharelado em Ciência da Computação da Universidade Federal Rural de Pernambuco da Unidade Acadêmica de Garanhuns, como requisito para obtenção do Grau de Bacharel em Ciência da Computação
Data da Aprovação: ____ de _______________ de 2015.
________________________________________ Prof. Me. Tiago Buarque Assunção de Carvalho
Professor Orientador (UFRPE-UAG)
________________________________________ Prof. Me. Luís Filipe Alves Pereira
Examinador (UFRPE-UAG)
________________________________________ Prof. Me. Rian Gabriel Santos Pinheiro
Examinador (UFRPE-UAG)
AGRADECIMENTOS
Agradeço a todos aqueles que direta ou indiretamente me apoiaram até a chegada deste grande objetivo. Dado o espaço que disponho, não tenho como citar aqui os nomes de todas as pessoas que de alguma forma contribuíram com meu trabalho ao longo dos últimos anos. Mas alguns nomes eu não poderia deixar de citar.
Agradeço a minha mãe Maria Auxiliadora de Melo Costa pelo carinho, apoio e incentivo que me permitiram chegar até aqui.
Agradeço também a todos os amigos da faculdade que me ajudaram a crescer como pessoa e que estiveram presentes durante essa longa caminhada em busca do nosso objetivo. Mas em especial não poderia deixar de citar nomes como José Belmiro Neto, Céfanys de Morais, Amanda Oliveira, João Ferreira, José Augusto César, Romáryo Almeida Cavalcanti e Thalita Nicolle.
Agradeço ainda a todos os professores da UAG, em especial a Sansuke Watanabe, Gersonilo Oliveira, Juliana Saraiva, Érica Sousa, Bruno Nogueira, Kádna Camboim, Maria Aparecida,Jean Araújo e Marcius Petrúcio, os quais além de exímios profissionais são pessoas singulares.
Agradeço também a todos os meus colegas de trabalho, os quais, embora não tenham qualquer relação com esse trabalho, me aturaram pelos últimos cinco anos e isso é um grande feito.
RESUMO
O reconhecimento de faces é uma área de pesquisa que recebeu muitos investimentos nos últimos anos. Mas mesmo com todos os avanços obtidos ainda pode ser considerado um processo de alto custo computacional. E como forma de contornar este problema, diversos modelos foram propostos para obtenção de uma representação compacta de faces e que, ao mesmo tempo, permita reconhecer os indivíduos rapidamente.
Visando abordar este problema, nesta pesquisa foi feito um estudo de algoritmos de redução de dimensionalidade baseados em extração de características de faces. Com base neste estudo, foi proposto um método de extração de características (denominado
Supervised Fractional Eigenfaces) que une aspectos dos algoritmos Supervised Principal
Component Analysis e Fractional Eigenfaces, ambos derivados da técnica de Análise de Componentes Principais.
Com o objetivo de verificar a eficiência da técnica proposta, foram realizados testes de reconhecimento facial em três bancos de faces amplamente utilizados na literatura (ORL, YALE e Georgia Tech). Estas bancos foram submetidos aos algoritmos de extração de características e estas, por sua vez, foram usadas em testes de classificação usando o algoritmo 1-Vizinho mais Próximo (1-NN, na sigla em inglês). O desempenho dos algoritmos foi avaliado de forma quantitativa por meio das taxas de erro obtidas pelo classificador. Os resultados obtidos neste teste foram satisfatórios e mostraram um desempenho superior do algoritmo proposto, frente aos anteriores, nos três bancos de imagens testados. Adicionalmente foi realizado um teste qualitativo com vista a avaliar os algoritmos em problemas de projeção de faces em um espaço bidimensional. Este teste também indicou um bom resultado do algoritmo proposto frente os demais.
ABSTRACT
The face recognition is an area of research that has received much investment in recent years. Besides all these advances it is still considered a high computational cost process. To address this issue, several models have been proposed to obtain a compact representation of faces and allow to recognize individuals quickly.
This research is a study of dimensionality reduction algorithms based on extraction of faces characteristics. Based on this we proposed a feature extraction method (called Supervised Fractional Eigenfaces) joining aspects of the algorithms: Supervised Principal Component Analysis, and Fractional Eigenfaces, both derived from the Principal Component Analysis (PCA).
In order to verify the efficiency of the proposed technique facial recognition test were performed in three faces datasets widely used in the literature (ORL, YALE and Georgia Tech). These sets were submitted to the feature extraction algorithms and classified using the algorithm 1-Nearest Neighbor (1-NN). The performance of the algorithms was evaluated by the error rates obtained by the classifier. The results of this test showed superior performance of the proposed algorithm in the three tested image databases. Additionally we performed a qualitative test to assess the algorithms faces projection problem in a two-dimensional space. This test also indicated a good result of the proposed compared to the other algorithms.
LISTA DE FIGURAS
LISTA DE TABELAS
LISTA DE SIGLAS
PCA Principal Component Analysis
SPCA Supervised Principal Component Analysis DSPCA Dual Supervised Principal Component Analysis
FE Fractional Eigenfaces
SFE Supervised Fractional Eigenfaces
SUMÁRIO
1 Introdução ... 13
1 Fundamentação Teórica ... 15
1.1 Reconhecimento de Padrões ... 15
1.2 Reconhecimento de Faces ... 15
1.3 Conjunto de Dados... 16
1.4 Pré-processamento de Dados ... 17
1.5 Redução de Dimensionalidade ... 18
1.6 Análise de Componentes Principais ... 19
1.7 Eigenfaces: PCA em Problemas de Alta Dimensionalidade ... 22
1.8 Supervised Principal Component Analysis ... 24
1.9 Dual Supervised Principal Component Analysis ... 27
1.10 Fractional Eigenfaces ... 29
2 Proposta Apresentada: Supervised Fractional Eigenfaces... 31
3 Experimentos Realizados e Resultados Obtidos ... 34
3.1 Percurso Metodológico ... 34
3.2 Descrição das Bases de Imagens Usadas ... 35
3.3 Teste de Visualização ... 36
3.4 Teste de Classificação – Reconhecimento Facial ... 42
4 Conclusão e Trabalhos Futuros ... 49
Referências Bibliográficas ... 51
Apêndice A – Resultado Analíticos do Teste de Classificação. ... 54
13
1
Introdução
O reconhecimento facial é uma área de pesquisa em processamento de imagens e visão computacional que vem se mantendo bastante ativa nas últimas duas décadas. Além de ser uma das aplicações mais bem sucedidas das técnicas contemporâneas de análise e compreensão de imagens (SEVCENCO e LU, 2012).
Devido a sua importância para diversas disciplinas, a pesquisa em reconhecimento de faces evoluiu muito desce os primeiros trabalhos realizados na década de 1950. Segundo (CHELLAPPA e ZHAO, 2005), as primeiras pesquisas a respeito foram feitas em psicologia e apenas na década seguinte foram publicados os primeiros trabalhos na área de engenharia. Mas as verdadeiras pesquisas em reconhecimento automático de faces só tiveram início na década de 1970, depois das apresentações dos trabalhos de (KELLY, 1970) e de (KANADE, 1973).
As duas últimas décadas têm testemunhado esforços de investigação sustentáveis que levaram a novos métodos e algoritmos com uma melhor capacidade de reconhecimento facial. Em (SEVCENCO e LU, 2012) são destacados os seguintes métodos: Análise de Componentes Principais (PCA, do inglês Principal Component Analysis), análise de componentes independentes, análise discriminante linear, isomaps, incorporação localmente linear, laplacianfaces com base em eigenmaps laplacianos e whitenedfaces.
Em especial o PCA teve vários trabalhos desenvolvidos com vista a melhorar os resultados obtidos em (TURK e PENTLAND, 1991) para aplicação do PCA em reconhecimento de faces. Como alguns exemplos podemos citar as técnicas Fisherfaces (BELHUMEUR, HESPANHA e KRIEGMAN, 1996), Supervised-PCA (SANTIAGO-MOZOS et al, 2003) e Fractional Eigenfaces (CARVALHO, 2014).
14
KITTLER, 2014). Com isso, vemos que ainda existe um espaço para melhoria nas técnicas disponíveis no estado da arte.
Assim, esta pesquisa teve como o objetivo geral a redução das taxas de erro em algoritmos de reconhecimento facial. Para isso, foram analisadas hipóteses que buscavam combinar técnicas presentes no estado da arte, de forma à obter uma abordagem derivada delas. Com vista a atingir o objetivo geral, este trabalho teve como objetivos específicos:
Realização de testes de desempenho classificatório do algoritmo DSPCA (Dual Supervised Principal Component Analysis) em problemas de reconhecimento de faces. Seguido da aplicações dos mesmos teste para o algoritmo Fractional Eigenfaces.
Realização dos mesmos testes anteriores para o algoritmo do método proposto, Supervised Fractional Eigenfaces (SFE).
Comparação dos resultados obtidos com visando confirmar as melhorias identificadas.
Ao final do trabalhos foram obtidos resultados que confirmaram as melhorias obtidas pelo método proposto. Foram realizados testes de reconhecimento facial em três bancos de imagens e o SFE apresentou as menores taxas de erro em comparação aos algoritmos dos quais foi derivado.
15
1
Fundamentação Teórica
Neste capítulo são tratados os conceitos e fundamentos utilizados para embasar e subsidiar este trabalho, sendo, portanto, de extrema importância para o entendimento teórico acerca das teorias abordadas e dos métodos usados durante todo o desenvolvimento da pesquisa.
1.1 Reconhecimento de Padrões
Segundo (ROKACH, 2009), “o reconhecimento de padrões é a disciplina científica cujo objetivo é classificar padrões (também conhecido como objetos, instâncias, amostras ou exemplos) em um conjunto de categorias, também chamadas de classes ou rótulos”. Esse processo de classificação é realizado através de uma função, a qual recebe como entrada um padrão (representado por conjunto de dados) e estima a provável classe desse padrão.
“A história desta área é longa, mas antes da década de 1960 era trabalhada, principalmente, em pesquisas teóricas na área de Estatística. Mas, tal como ocorreu com muitas outras áreas, o advento dos computadores aumentou a demanda por aplicações práticas de reconhecimento de padrões, o que, por sua vez, estabeleceu novas exigências para desenvolvimentos teóricos.” (THEODORIDIS e KOUTROUMBAS, 2009)
Uma importante subárea dentro do reconhecimento de padrões é a visão computacional. Segundo (THEODORIDIS e KOUTROUMBAS, 2009) “um sistema de visão computacional objetiva capturar imagens através de uma câmera para, em seguida, produzir uma descrições do que foi visto”. Algumas aplicações típicas que podem ser citadas dentro dessa área são a inspeção automática de peças em linhas de montagem, sistemas de vigilância e aplicações de reconhecimento de faces. Na próxima seção apresentaremos em mais detalhe o campo de estudo de reconhecimento facial.
1.2 Reconhecimento de Faces
16
faces, por este destinar-se a localização de faces em imagens sem fornecer a identificação da pessoa.
Um dos primeiros trabalhos sobre reconhecimento de faces datam da década de setenta de (KELLY, 1970). Desde então, várias avanços foram realizados e novas linhas de pesquisa foram criadas mesclando conhecimentos oriundos de outras áreas de conhecimento. Em especial podemos citar vários trabalhos com uso de técnicas portadas da Estatística (KIRBY e SIROVICH, 1990), de (TURK e PENTLAND, 1991), (BELHUMEUR, HESPANHA e KRIEGMAN, 1996), (CARVALHO et al, 2014).
Com quase meio século tendo se passado, a tarefa de reconhecimento de faces ainda se mostra um tarefa complexa. Problemas ligados a qualidade das imagens usadas, a forma de captura e ao próprio custo computacional envolvido, tornam bastante complexa a construção de aplicações eficientes e com boas taxas de acerto em suas predições. Isso faz com que nosso cérebro ainda possua o melhor "sistema" de reconhecimento de faces conhecido.
Na seção seguinte será apresentado um critério comumente usados para classificar os algoritmos de reconhecimento de padrões, e por extensão os algoritmo de reconhecimento facial.
1.3 Conjunto de Dados
Não existe uma definição matemática para o termo conjunto, ao invés disso ele é tido como um uma noção primitiva, ou seja, um elemento que, dada sua simplicidade não é passível de ter uma definição formal. Assim a definição comumente aceita para conjunto é a de que o mesmo representa um agrupamento de elementos. (IEZZI e MURAKAMI, 1977).
17
podem ser representados de forma compacta por meio de uma coleção de dados chamada de vetor de características. (FACELI et al, 2011).
Um conjunto de dados pode ser formalmente representado por meio de uma matriz de padrões, onde 𝑛 é o número de padrões e 𝑑 é o número de atributos de cada padrão. O valor de 𝑑 defini a dimensionalidade dos objetos ou o espaço de padrões (ou ainda, espaço de atributos). Desta definição temos cada elemento 𝑥𝑖𝑗 representando o valor do j-ésima atributo para o i-ésimo padrão.
No contexto do reconhecimento de faces, cada face é considerada um padrão e, inicialmente, cada um dos pixels da imagem desta face é um atributo. Imagens são comumente representadas por meio de uma matriz de pixels 𝐼ℎ 𝑥 𝑤. Esta representação pode ser substituída, sem perca de generalidade, por um vetor 𝑖 de comprimento ℎ ∗ 𝑤. Dessa forma, um conjunto de 𝑛 imagens pode ser armazenado em uma matriz 𝑿𝑛 𝑥 𝑑, conforme a definição anterior.
Os atributos de um objetos também podem ser encarados como uma variável aleatória, esta abordagem permite aplicar diversas técnicas estatísticas ao contexto de aprendizagem de máquina.
1.4 Pré-processamento de Dados
Apesar de algoritmos de aprendizagem de máquina serem frequentemente adotados para extrair conhecimento de conjuntos de dados, seu desempenho é, geralmente, afetado pelo estado dos dados. Esse estado do conjunto de dados pode ser influenciado pelos tipos de dados das características, pela escala relativa entre os valores delas, pela existência de ruído nestes valores e ainda pela quantidade características. (FACELI et al, 2011).
Técnicas de pré-processamento de dados são frequentemente utilizadas para melhorar a qualidade dos dados por meio da eliminação ou minimização dos problemas citados. Essas ações visam melhorar o desempenho dos algoritmos que irão extrair conhecimento desta base. Com isso obtém-se modelos e informações mais fiéis ao dados, além de reduzir a complexidade computacional. (FACELI et al, 2011).
18
modelos de a partir de imagens é considerado difícil. Essa dificuldade está ligada em especial ao alto custo computacional envolvido. Por exemplo, um conjunto de 16 imagens em escala de cinza e com dimensão de 256 por 256 pixels, seria representado por uma matriz 𝐶 de dimensões 16 por 65.536. Neste mesmo conjunto de imagens, a aplicação de uma técnica de redução de dimensionalidade conhecida como Eigenfaces, por exemplo, pode reduzir o número de colunas de 𝐶 para 7, tendo como consequência apenas uma pequena perca de informação relevante. (TURK e PENTLAND, 1991).
Na seção seguinte será apresentada uma discussão sobre os efeitos da alta dimensionalidade em conjunto de dados.
1.5 Redução de Dimensionalidade
Muitas técnicas de aprendizagem de máquina são projetados para aprender quais são os atributos mais relevantes em um conjunto de dados para usá-los na tomada de decisões futuras. Em (WITTEN e FRANK, 2005) os autores citam que em experimentos com uma árvore de decisão (algoritmo C4.51) foi medido o efeito da adição um atributo binário
aleatório no conjunto de dados, como resultado a performance do algoritmo foi reduzida em taxas que variaram de 5% a 10%.
Por causa do efeito negativo dos atributos irrelevantes na maioria dos algoritmos de aprendizagem de máquina, é comum que a fase de aprendizagem seja precedida pela aplicação de alguma técnica de redução de dimensionalidade. Essa técnica visa eliminar os atributos menos relevantes e gerar uma representação mais compacta do espaço de dados. (WITTEN e FRANK, 2005).
O efeito do número muito grande atributos é descrito pelo problema da “maldição da dimensionalidade”. Esse termo foi inicialmente usado por (BELLMAN, 1957) no contexto de Teoria de Controle. Em (FACELI et al, 2011) temos um exemplo interessante do resultado deste efeito, suponha que temos um conjunto de dados com apenas um
19
atributo que pode assumir um entre 10 valores. Esse conjunto de dados pode ter então
101 objetos diferentes, um para cada valor diferente do atributo. Já se o número de atributos passar para 6, o número de possíveis objetos passa a ser de 106, que é um número muito maior que o anterior. Uma forma de minimizar o impacto do deste problema é combinar ou eliminar parte dos atributos menos relevantes.
Segundo a literatura de reconhecimento de padrões as técnicas de redução de dimensionalidade podem ser divididas em duas grandes abordagens: seleção e extração de atributos. (SAMMUT e WEBB, 2011).
Dado um conjunto de dados X, a redução de dimensionalidade pode ser operada em dois caminhos distintos. O primeiro visa identificar os atributos, ou variáveis, que não contribuem para a tarefa de classificação. Pois nesse tipo de problema podemos negligenciar o uso de atributos que não contribuem para a separabilidade das classes. Essa tarefa pode ser definida como a escolha dos 𝑑′ melhores atributos dentre os 𝑑
atributos disponíveis. A essa abordagem damos o nome de seleção de características. (SAMMUT e WEBB, 2011). A seleção de características também pode ser aplicada em problemas de regressão, um estudo a respeito pode ser encontrado em (MILLER, 2002).
O segundo caminho para redução de dimensionalidade é a busca de uma transformação do conjunto de dados para um espaço de menor dimensionalidade. Essa tarefa pode ser feita como um pré-processamentos dos dados ou em conjunto com um classificador. A essa abordagem damos o nome de extração de atributos. Ela pode ser feita por meio de uma combinação linear ou não-linear dos atributos originais e, além disso, pode ser supervisionada ou não-supervisionada. (SAMMUT e WEBB, 2011).
A extração de características por meio de transformações não-lineares foge ao escopo deste trabalho e não será detalhada aqui. Na seção a seguir será detalhada uma das técnicas mais conhecidas para extração linear de características, conhecida como PCA.
1.6 Análise de Componentes Principais
inter-20
relacionadas, enquanto mantém o máximo possível da variância presente nos dados. Isto é obtido projetando os dados para um novo conjunto de variáveis, os principais componentes, que são não-correlacionadas e ordenadas de forma que o primeiro contém a maior parcela de variância presente em todas as variáveis originais. (JOLLIFFE, 2002).
Segundo (SAMMUT e WEBB, 2011), geometricamente, o PCA pode ser interpretado como uma rotação dos eixos do sistema de coordenadas original para um novo conjunto de eixos ortogonais que estão ordenados em termos da quantidade de variância dos dados originais que estes acomodam. No entanto, isso não quer dizer que vamos ser capazes de atribuir uma interpretação a estas novas variáveis. Ou seja, o PCA nos permite a extração de um novo conjunto de variáveis que melhor representa a variância original dos dados, mas em geral não se pode atribuir uma interpretação clara do conteúdo representado por essas variáveis.
Os componentes principais extraídos pelo PCA são definidos como sendo os autovetores da matriz de covariância do conjunto de dados2. Por sua vez, a projeção dos
objetos no novo espaço é obtida pela multiplicação de cada vetor de características pela matriz formada pelos autovetores associados aos maiores autovalores da matriz de covariância. Esse processo é realizado conforme Algoritmo 1.
Algoritmo 1. Principal Component Analysis (PCA). Entradas:
Conjunto de treino representado pela matriz 𝑿𝑛 𝑥 𝑝, onde 𝑛 é o número de objetos e 𝑝 o de atributos.
Conjunto de teste 𝑻𝑡 𝑥 𝑝 contendo 𝑡 objetos; Calculo dos Componentes principais:
Calcular a média dos objetos do conjunto de treino, sendo que cada objeto
2 Uma explanação detalhada do conceito de autovetores e autovalores pode ser obtida em
21
corresponde a uma linha da 𝑿 e é representado por 𝒙𝒊:
𝒙̅ = 𝑛 ∑ 𝒙1 𝒊 𝑛
𝑖=1
A matriz de covariância pode ser definida como:
𝐶𝑝 𝑥 𝑝 = 𝑛 ∑(𝒙1 𝒊− 𝒙̅)(𝒙𝑖− 𝒙̅)𝑇 𝑛
𝑖=1
Em seguida calcula-se os autovetores 𝒖𝑖 (𝑖 = 1, 2, ..., 𝑑) correspondentes aos 𝑑 maiores autovalores de 𝐶, os quais são denominados componentes principais de 𝑿. Saída:
A projeção 𝑃 de cada objeto do conjunto de treino no novo espaço ocorre da seguinte forma:
𝒙𝑖′ = [𝒖
1, 𝒖2, … , 𝒖𝑑](𝒙𝒊− 𝒙̅) A projeção do conjunto de teste ocorre de forma análoga
𝒕𝑗′ = [𝒖1, 𝒖2, … , 𝒖𝑑](𝒕𝑗− 𝒙̅)
Uma definição formal detalhada para o PCA pode ser consultada em (JOLLIFFE, 2002).
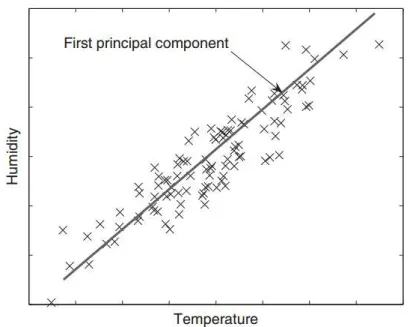
22
Figura 1. Exemplo de aplicação do PCA (SAMMUT e WEBB, 2011). Os pontos representados pelo símbolo x representam as amostras. E a reta plotada no gráfico é a
representação do primeiro componente principal extraído a partir destas amostras.
Outra característica importante do PCA, é seu cálculo ser independente da identificação das amostras em suas respectivas classes, por esse motivo o PCA é classificado como um método não-supervisionado. Esta característica lhe permite ser diretamente aplicável a problemas de classificação, regressão ou agrupamento.
Uma outra aplicação bastante comum do PCA é o problema de visualização. Neste contexto dados com alta dimensionalidade são projetados em espaços de 2 ou 3 dimensões de forma a permitir um visualização da relação entre os objetos (SAMMUT e WEBB, 2011). Na seção seguinte será apresentada uma variação do algoritmo PCA que permite um drástica redução no custo computacional do PCA.
1.7 Eigenfaces: PCA em Problemas de Alta Dimensionalidade
Em muitos aplicações do PCA o número de objetos é muito menor que a dimensionalidade do espaço no qual esses objetos estão sendo representados. Neste contexto a aplicação direta do PCA será ineficiente. (BISHOP, 2006).
23
situação é encontrada, por exemplo, ao se lidar com imagens de dimensão 256 por 256 pixels, neste caso a matriz de covariância teria dimensão 65536 por 65536. Em vez disso, é preferível um método que dependa somente do número de objetos de treino 𝑛 ou que tenha uma dependência reduzida de 𝑝.
No Algoritmo 2 é apresentado uma variação do PCA que reduz o custo computacional para aplicações análogas as descritas acima. Essa redução é obtida por meio de um artificio matemático, no qual os componentes principais são calculados a partir de uma matriz 𝐷 de dimensão menor que a matriz de covariância usada no PCA. Em (GHODSI, 2006) este algoritmo é apresentado como Dual PCA e em (TURK e PENTLAND, 1991) como Eigenfaces.
Algoritmo 2. Eigenfaces. Entradas:
Conjunto de treino representado pela matriz 𝑿𝑛 𝑥 𝑝, onde 𝑛 é o número de objetos e 𝑝 o de atributos (𝑛 ≪ 𝑝)
Conjunto de teste 𝑻𝑡 𝑥 𝑝 contendo 𝑡 objetos; Calculo dos Componentes principais:
Calcular a média dos objetos do conjunto de treino:
𝒙̅ = 1𝑛 ∑ 𝑥𝑖 𝑛
𝑖=1
Em substituição a matriz de covariância, calculamos os autovalores da matriz 𝐷
que possui um tamanho significativamente menor, conforme segue:
𝐷𝑛 𝑥 𝑛 = 1𝑛 ∑(𝑥𝑖 − 𝑥̅)𝑇(𝑥𝑖− 𝑥̅) 𝑑
𝑖=1
24
a partir dos autovetores 𝑒𝑖 da forma a seguir:
𝒖𝑖 = (𝑛𝛼1
𝑖)1 2⁄ [(𝒙1− 𝒙̅), … , (𝒙𝑛− 𝒙̅)]𝒆𝑖
𝑇,
onde 𝛼𝑖 é o autovalor associado ao autovetor 𝑒𝑖. Saída:
A projeção de cada objeto do conjunto de treino no novo espaço ocorre da seguinte forma:
𝒙′𝑖 = [𝒖1, 𝒖2, … , 𝒖𝑑]𝑇(𝒙𝑖 − 𝒙̅) A projeção do conjunto de teste ocorre de forma análoga
𝒕′𝑖 = [𝒖1, 𝒖2, … , 𝒖𝑑]𝑇(𝒕𝑖− 𝒙̅)
Em (TURK e PENTLAND, 1991 o Eigenfaces foi aplicado a problemas de reconhecimento de faces. Neste trabalho além dos resultados obtidos na tarefa de reconhecimento, foi encontrada uma interessante interpretação dos componentes principais que passaram a ser denominados de autofaces (ou eigenfaces, em inglês). Ao reproduzir os componentes principais como uma matriz bidimensional de mesma dimensões das imagens originais, obteve-se uma representação das regiões de maior variância nas imagens. Observou-se que, em geral, as autofaces extraídas possuem uma aparência ou, pelo menos, contornos que lembram rostos, fato este que explica o uso do termo autofaces para denominá-las.
Na seção seguinte será apresenta um recente proposta de método derivado do PCA para extração de características, mas que inclui o diferencia de usar o paradigma supervisionado para extração das características.
1.8 Supervised Principal Component Analysis
25
forma não-supervisionada, o SPCA consegue capturar os principais componentes que apresentam a máxima dependência estatística em relação a classe. Com isso, as projeções obtidas com SPCA tendem a apresentar um maior poder discriminatório sobre os dados.
Do ponto de vista estatístico o PCA objetiva criar um projeção em um subespaço de menor dimensionalidade e que preserve o máximo possível da variância dos dados. Já o SPCA busca uma projeção que maximize a dependência entre a projeção obtida e o valor das classes.
Em (BARSHAN et al, 2011) são apresentados uma serie de experimentos comparativos do SPCA com outros algoritmos relacionados, nestes testes o SPCA teve uma taxa de erro igual ou menor que os demais métodos nos principais conjunto de dados utilizados. Para fins de comparação, em um dos testes realizados pelo autor o PCA teve uma taxa de erro de 18,6%, enquanto SPCA teve uma taxa de 7,6%.
O Algoritmo 3 é uma versão adaptada da descrição do algoritmo apresentada em (BARSHAN et al, 2011).
Algoritmo 3. Supervised Principal Component Analysis (SPCA). Entradas:
Conjunto de treino representado pela matriz 𝑿𝑝 𝑥 𝑛, onde 𝑛 é o número de objetos e 𝑝 o de atributos;
Conjunto de teste 𝑻𝑝 𝑥 𝑡 contendo 𝑡 objetos;
Um vetor 𝒚 contendo os valores da classe para cada amostra de treino; Construção da matriz de kernel
Construímos a matriz de kernel 𝐿𝑛 𝑥 𝑛 que irá armazenar a informação da variável alvo. Esta matriz é construída da forma a seguir:
𝑙𝑖,𝑗 = {1 se o objeto 𝑖 pertence a mesma classe que o objeto 𝑗, 0 caso contrário}
26
Calcula-se a matriz 𝑄 da forma a seguir:
𝑄𝑛 𝑥 𝑛 = 𝑋𝐻𝐿𝐻𝑋𝑇,
onde 𝐻 é chamada de matriz de centralização e pode ser definida da seguinte forma:
𝐻𝑛 𝑥 𝑛 = 𝐼 − 𝑛−1𝒆𝒆𝑇
sendo 𝐼 a matriz identidade e 𝒆 um vetor onde todas as posições valem 1.
Em seguida calculam-se os autovetores 𝒖𝑖 (𝑖 = 1, 2, ..., 𝑑) correspondentes aos 𝑑 maiores autovalores de 𝑄.
Projeção dos dados:
A projeção de cada objeto do conjunto de treino no novo espaço ocorre da seguinte forma:
𝒙′𝑖 = [𝒖1, 𝒖2, … , 𝒖𝑑]𝑇𝒙𝒊
A projeção do conjunto de teste ocorre de forma análoga
𝒕′𝑗 = [𝒖1, 𝒖2, … , 𝒖𝑑]𝑇𝒕𝒋
O título deste algoritmo já foi utilizado por outros autores, para nomear outros métodos derivados do PCA. Por exemplo temos os trabalhos (PERANTONIS, PETRIDIS e VIRVILIS, 2000), (SANTIAGO-MOZOS, 2003) e (BAIR, 2006). Além disso, o nome Supervised Principal Component Analysis também foi utilizado em 2010 como título para o registro da patente (LI, 2013). Da mesma forma que os artigos, essa patente descreve um algoritmo diferente.
27
1.9 Dual Supervised Principal Component Analysis
Da mesma forma que o PCA, o SPCA é impraticável para problemas onde a dimensionalidade 𝑝 é muito maior que o número de objetos disponíveis no conjunto de dados. Em virtude disso, em (BARSHAN et al, 2011) temos a apresentação de uma versão mais eficiente do algoritmo SPCA chamada de Dual Supervised Principal Component Analysis (DSPCA). Essa proposta aplicasse a contextos de alta dimensionalidade e visa reduzir a complexidade dos cálculos fazendo com que esta dependa principalmente da quantidade de amostras 𝑛.
O DSPCA usa uma estratégia semelhante ao Dual PCA para reduzir o custo computacional do cálculo dos componentes principais, porém possui uma limitação em relação ao número de componentes extraídos. A matriz da qual são extraídos os autovetores – 𝑆𝑇𝑆 – possui dimensões 𝑐 𝑥 𝑐, onde 𝑐 é o quantidade de classes entre os objetos. Com isso, o DSPCA pode extrair, no máximo, 𝑐 componentes a partir de um conjunto de dados.
No Algoritmo 4 temos a apresentação do DSPCA em uma adaptação da descrição apresentada em (BARSHAN et al, 2011).
Algoritmo 4. Dual Supervised Principal Component Analysis (DSPCA). Entradas:
Conjunto de treino representado pela matriz 𝑿𝑝 𝑥 𝑛, onde 𝑛 é o número de objetos e 𝑝 o de atributos;
Conjunto de teste 𝑻𝑝 𝑥 𝑡 contendo 𝑡 objetos;
Matriz de kernel 𝐿 construída conforme especificação do Algoritmo 3;
Um vetor 𝒚 contendo os valores da classe para cada amostra de treino. Decomposição da matriz 𝐿
28
𝐿 = ∆𝑇∆
A matriz ∆ também pode ser construída diretamente seguindo os passos descritos abaixo:
1. Construir uma matriz ∆𝑐 𝑥 𝑛 onde 𝑐 é o número de classes e 𝑛 é o número de objetos;
2. Em seguida os valores para cada elemento de ∆ são definidos da seguinte forma:
𝛿𝑖,𝑗 = {1 se o objeto 𝑗 pertence à classe 𝑖, ou 0 caso contrario} Calculo dos Componentes Principais:
Calcula-se a matriz 𝑆 da forma a seguir:
𝑆𝑝 𝑥 𝑐 = 𝑿𝐻∆𝑇, onde 𝐻 é calculada conforme Algoritmo 3.
Em seguida calculam-se os autovetores 𝒗𝑖 (𝑖 = 1, 2, ..., 𝑑) correspondentes aos 𝑑 maiores autovalores de 𝑆𝑇𝑆 = ∆𝐻[𝑋𝑇𝑋]𝐻∆𝑇. Esse vetores são agrupados numa matriz
𝑉𝑐 𝑥 𝑑, (𝑐 é o numero de classes).
Para obtenção dos principais componentes se faz necessária a etapa de cálculo descrita abaixo:
𝑈𝑝 𝑥 𝑑 = 𝑆𝑉𝐴−1
sendo 𝐴 uma matriz diagonal, onde cada elemento 𝑎𝑖𝑖 corresponde ao 𝑖-ésimo autovalor de 𝑆𝑇𝑆.
Projeção dos dados:
Seja 𝑈 = [𝒖1, … , 𝒖𝑑], então a projeção 𝑃 do conjunto de treino no novo espaço ocorre da seguinte forma:
𝒙′𝑖 = [𝒖1, … , 𝒖𝑑]𝑇𝒙𝒊
29
𝒕′𝑗 = [𝒖1, … , 𝒖𝑑]𝑇𝒕𝒋
Na seção seguinte é apresentada uma proposta mais recente de um algoritmo derivado do Eigenfaces e que obteve bons resultados em problemas de reconhecimento de faces.
1.10 Fractional Eigenfaces
O Fractional Eigenfaces (FE) é um algoritmo apresentado em (CARVALHO et al, 2014) como uma proposta de extensão para o algoritmo Fractional Principal Component Analysis (Fractional PCA) proposto em (GAO, ZHOU e PU, 2013). A vantagem do Fractional Eigenfaces é proporcionar uma redução do custo computacional do Fractional PCA por meio de um artificio matemático similar ao Eigenfaces. Além disso, nos testes apresentados em (CARVALHO et al, 2014), o Fractional Eigenfaces apresentou taxas de acerto superiores ao Eigenfaces original.
O FE pode ser obtido a partir do Algoritmo 2 por meio das alterações descritas a seguir.
A forma de cálculo da matriz 𝐷 deve ser feita da seguinte forma:
𝐷𝑛𝑟𝑥𝑛 = 1𝑛 ∑ [(𝑥1𝑗)
𝑟 − (𝑥̅ 𝑗)𝑟
⋮
(𝑥𝑛𝑗)𝑟 − (𝑥̅𝑗)𝑟
] [(𝑥1𝑗)
𝑟 − (𝑥̅ 𝑗)𝑟
⋮
(𝑥𝑛𝑗)𝑟 − (𝑥̅𝑗)𝑟
]
𝑇 𝑝
𝑗=1
Ou seja os valores de cada atributo da matriz dos dados e as suas respectivas médias devem ser elevadas ao expoente fracionário3𝑟. O valor ideal da constante 𝑟 deve
ser estimado para cada conjunto de teste, em (CARVALHO et al, 2014) os experimentos foram realizados utilizando 𝑟 = 0,01. A última alteração em relação ao Algoritmo 2 é a forma de cálculo dos objetos projetados, a qual passará a ser feita da seguinte forma:
3 Uma explanação detalhada sobre a fundamentação matemática por trás da aplicação desta operação foge
30
𝐱′ = [𝒖1, 𝒖2, … , 𝒖𝑑]𝑇((𝒙𝑖)𝑟 − (𝒙̅)𝑟), para os objetos de treino e
𝒕′𝑗 = [𝒖1, 𝒖2, … , 𝒖𝑑]𝑇((𝒕𝑗)𝑟 − (𝒙̅)𝑟), para os objetos de teste.
Nas demais etapas do algoritmo o Fractional Eigenfaces se comporta de maneira igual ao descrito no Algoritmo 2.
31
2
Proposta Apresentada: Supervised Fractional Eigenfaces
Com base nos trabalhos apresentados anteriormente foi desenvolvido uma proposta de algoritmo que combina características do DSPCA e do Fractional Eigenfaces (FE), sendo este intitulado de Supervised Fractional Eigenfaces (SFE). Nesta combinação temos os valores do conjunto de dados sendo submetidos a mesma transformação utilizada pelo FE.
Para obtenção do novo método, foi tomado como base o algoritmo DSPCA. Numa análise do DSPCA foi percebido que a multiplicação 𝑿𝐻, ocorrida na etapa de cálculo dos autovetores, é equivalente a operação de subtração da média (centralização dos dados) que ocorre no Algoritmo 2. Ou seja, considerando 𝒙𝑖 como sendo o vetor formado pela
𝑖-ésima linha de 𝑿 e 𝒙̅ sendo o vetor média calculado conforme Algoritmo 2, temos
𝑿𝐻 = [𝒙1− 𝒙̅⋮ 𝒙𝑛− 𝒙̅
]
A partir da substituição da multiplicação 𝑿𝐻 pela operação descrita acima, foi possivel aplicar o expoente fracionário 𝑟 aos vetores das amostras e ao da média. Assim a operação de centralização dos dados passou a ser realizada da seguinte forma:
𝑅 = [(𝒙1)
𝑟 − (𝒙̅)𝑟
⋮ (𝒙𝑛)𝑟 − (𝒙̅)𝑟
]
com R subsitituindo XH nas etapas seguintes do DSPCA.
A partir deste ponto o algoritmo proposto comportasse igual ao DSPCA para o cálculo do componentes principais. A última alteração incluida é na etapa de projeção dos amostras, sendo esta processada de maneira analoga ao Fractional Eigenfaces.
O método o SFE está descrito no Algoritmo 5.
32
Conjunto de treino representado pela matriz 𝑿𝑛𝑥𝑝, onde 𝑛 é o número de objetos
e𝑝 o de atributos;
Conjunto de teste 𝑻𝑡𝑥𝑝 contendo 𝑡 objetos;
Matriz ∆𝑐𝑥n obtida conforme descrito no Algoritmo 4;
Constante 𝑟 fornecida pelo usuário (o valor ideal deve ser estimado por meio de
experimentos)
Um vetor 𝒚 contendo os valores da variável alvo (classe) para cada amostra de
treino.
Calculo dos Componentes Principais:
Calcula-se a matriz 𝑅 da forma a seguir:
𝑅𝑛𝑥𝑝 = [(𝒙1)
𝑟 − (𝒙̅)𝑟
⋮ (𝒙𝑛)𝑟 − (𝒙̅)𝑟
],
onde 𝒙𝑖, é o vetor formado pela 𝑖-ésima linha de 𝑿 e 𝒙̅ é um vetor formado pela média de cada coluna (é calculado conforme descrito no Algoritmo 1).
𝑆𝑐𝑥𝑝 = ∆𝑅
Em seguida calculam-se os autovetores 𝒗𝑖 (𝑖 = 1, 2, ..., 𝑑) correspondentes aos 𝑑 maiores autovalores de 𝑆𝑆𝑇 = ∆[𝑅𝑅𝑇]∆𝑇. Esse vetores são agrupados numa matriz
𝑉𝑐𝑥𝑑, (𝑐 é o numero de classes).
Para obtenção dos principais componentes se faz necessária a etapa de cálculo descrita abaixo:
𝑈𝑝𝑥𝑑 = 𝑆𝑇𝑉𝐴−1
sendo 𝐴 uma matriz diagonal, onde cada elemento 𝑎𝑖𝑖 corresponde ao 𝑖-ésimo autovalor de 𝑆𝑆𝑇.
Projeção dos dados:
A projeção de cada amostra do conjunto de treino no novo espaço ocorre da seguinte forma:
33
𝒕′𝑖 = ((𝒕𝑖)𝑟 − (𝒙̅)𝑟)U
34
3
Experimentos Realizados e Resultados Obtidos
Nesta seção, é descrito o estudo relacionado para verificação da eficácia do método proposto - Supervised Fractional Eigenfaces - em comparação com os algoritmos de redução de dimensionalidade dos quais o mesmo foi derivado. O desempenho dos métodos foi avaliado por meio de testes de visualização e de classificação.
Na Seção 4.1 é definido o percurso metodológico seguido ao longo deste trabalho. Em seguida, na Seção 4.2 são apresentados os conjuntos de imagens que serviram de base para os testes realizados. Na Seção 4.3 foi avaliado a aplicação dos algoritmos para a projeção bidimensional de um conjunto de faces. E na Seção 4.4 foi feita uma comparação do desempenho dos métodos em problemas de classificação para reconhecimento facial.
3.1 Percurso Metodológico
Esta pesquisa foi realizada em três etapas distintas e complementares, sendo a primeira voltada ao estudo bibliográfico acerca dos principais temas pertinentes ao objetivo do trabalho e subsidiem o atingimento dos objetivos específicos. Na etapa seguinte, Foi feito o estudo referente ao desenvolvimento da proposta.
Na terceira etapa foram realizados os testes comparativos entre os métodos originais e a proposta derivada destes. Os testes foram baseados na metodologia quantitativa, na qual, de acordo com (WAINER, 2007):
As variáveis a serem observadas são consideradas objetivas, isto é, diferentes observadores obterão os mesmos resultados em observações distintas;
Não há desacordo do que é melhor e o que é pior para os valores dessas variáveis objetivas;
Medições numéricas são consideradas mais ricas que descrições verbais, pois elas se adequam à manipulação estatística.
35
avaliados no trabalho. Na seção seguinte é feita a descrição dos experimentos realizados e dos resultados obtidos.
3.2 Descrição das Bases de Imagens Usadas
Nos experimentos foram utilizados bancos (bases) de imagens de faces obtidas de três fontes: YALE4, AT&T5 e Georgia Tech6. A seguir temos uma breve descrição de cada um
destes conjuntos de imagens.
A base de faces YALE foi construída pelo YALE Center for Computacional Vision and Control. Esta base contem 165 imagens em escala de cinza de 15 indivíduos - 11 imagens por indivíduo. Estas imagens foram capturadas sob diferentes condições de iluminação, diferentes expressões faciais e com e sem óculos. Por questões de custo computacional as imagens originais foram reduzidas para o tamanho de 112 x 92 pixels.
A base de faces da AT&T (anteriormente conhecida como "ORL database of Faces") contém um conjunto de imagens de rostos tomadas entre abril de 1992 e abril de 1994 pelo AT&T Laboratories Cambridge. Neste conjunto existem 10 imagens diferentes de cada um dos 40 indivíduos. Para a maioria dos indivíduos as imagens foram tiradas em momentos diferentes, com diferentes condições de iluminação, expressões faciais e detalhes faciais (com óculos / sem óculos). Todas as imagens foram tiradas contra um fundo homogêneo escuro com os sujeitos em uma posição vertical. As variações nas imagens incluem posição, idade e expressão facial. O tamanho original de cada imagem é 92x112 pixels, com 256 níveis de cinzento por pixel.
A base de imagens Georgia Tech, é um banco contendo 750 imagens (15 por pessoa) capturadas entre 06/01/1999 e 15/11/1999 pelo Center for Signal and Image Processing at Georgia Institute of Technology. As imagens contam com variações de iluminação, expressão facial, posição e aparência. Em adição a isto, as imagens foram
4 Disponível em <http://vision.ucsd.edu/content/yale-face-database> Acessado em 09/10/2014.
36
capturadas em diferentes escalas e orientações. Para este trabalho foi utilizada uma versão do banco de imagens onde as imagens tiveram o fundo recortado, esse recorte teve como base a determinação manual da posição de cada face. Esta base de imagens exigiu um trabalho adicional de pré-processamento. Devido ao tamanho variável da imagens, estas tiveram de ser redimensionadas para o tamanho de 91 pixel de largura por 98 de altura (tamanho da menor imagem do banco). Porém, em decorrência da variação da proporção entre as imagens, foi necessária a inclusão de uma borda branca nas imagens que ficaram com largura ou altura inferior a definição anterior. A inclusão dessa borda foi feita de modo a manter a imagem original centralizada e garantir que todas as imagens tenham o mesmo tamanho.
Cada um dos bancos de imagens foi importado para o aplicativo Matlab7, e
armazenada numa única matriz. Esta matriz foi construída da seguinte forma, primeiro cada linha de pixels da imagem de entrada é concatenada com as demais para formar uma única linha de tamanho 𝑎 ∗ 𝑙, onde 𝑎 é a altura e 𝑙 é a largura da imagem. Em seguida essas linhas são agrupadas em uma única matriz representando toda a base de imagens. Por fim, o valores dos pixels são normalizados para o intervalo fechado [0,1].
3.3 Teste de Visualização
O primeiro teste realizado foi um teste de visualização, neste teste foi explorado a capacidade de separação dos dados quando estes são representados em um subespaço de dimensão muito menor (em geral duas ou três dimensões). No nosso caso, tomamos o espaço definido por um conjunto de imagens e o representamos em subespaço de dimensão d=2. Ou seja, cada imagem de uma face passou a ser representada por um ponto num espaço bidimensional.
A meta aqui neste teste é obter a projeção dos dados que gere a melhor distinção entre as classes, ou seja, obter uma projeção que agrupe as imagens de um mesmo indivíduo, mas que, ao mesmo tempo, afaste-as das imagens dos demais. Esse ação pode
37
ser chamada de aumento da separabilidade (ou discriminação) entre as classes. Essa proximidade entre das imagens de uma mesma pessoa é um reflexo dos traços de semelhanças que estas naturalmente guardam entre si. Essa é a propriedade que temos interesse de explorar neste teste. Este tipo de teste também foi aplicado em (BARSHAN et al, 2011) para avaliar o SPCA em relação a outros métodos disponíveis na literatura.
Este teste tem um caráter mais ilustrativo do que avaliativo, uma vez que submeter os dados obtidos a uma avaliação de agrupamento foge ao escopo deste trabalho.
Como conjunto de dados foram tomadas as imagens dos quatro primeiros indivíduos da base YALE (11 imagens por pessoa). A partir da matriz formada por essas imagens foram extraídas as duas primeiras autofaces (componentes principais). Em seguida, foi calculada a projeção de cada uma das imagens em um novo espaço de dimensão 2.
Nos testes a seguir, foi utilizado um valor de 𝑟 = 0,1 para o FE e para o SFE. Nas Figuras 2 a 5 são exibidos os resultados do teste de visualização. Aqui cada objeto representa uma imagem e sua forma identifica o indivíduo. Os valores presentes nos eixos representam apenas o valor das coordenadas dos pontos no plano, porém o objetivo aqui explorar apenas os agrupamentos criados.
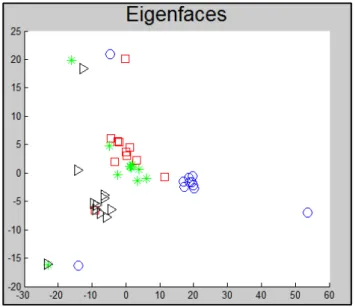
Na Figura 2 temos o resultado obtido com Eigenfaces na projeção das imagens. Podemos observar na figura que foram criados alguns grupos com parte das imagens, em especial o situado no centro à direta (referente ao indivíduo representado pelo círculo). Porém esse grupo apresenta três imagens que foram projetadas em locais mais distantes (no contexto de Estatística esse tipo de ponto é chamado de outliers (SAMMUT e WEBB, 2011)). Os demais indivíduos tiveram suas imagens relativamente agrupadas porém ainda sem uma boa separação entre elas.
38
na distância destes pontos, mas é um fato interessante que isso pode ser explorado de forma positiva em métodos de remoção de outliers (técnica essa usada no contexto de pré-processamento de dados).
Figura 2. Projeção bidimensional de um conjunto de faces com uso do Eigenfaces. Foram usados 4 símbolos para denotar cada um dos 4 indivíduos presentes nas
imagens.
39
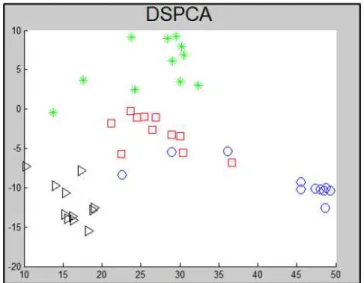
Figura 4. Projeção Bidimensional com DSPCA. Foram usados 4 símbolos para denotar cada um dos 4 indivíduos presentes nas imagens.
Observando a Figura 4, podemos ver que, em relação aos métodos anteriores, o DSPCA apresentou uma separação mais clara entre as projeções de pessoas diferentes. Foram criados dois grupos (representados pelos triângulos e pelos asteriscos) bem separados em relação aos demais. Porém algumas imagens do indivíduo representado pelo círculo foram projetadas muito próximas de um outro grupo. Esse resultado foi bastante satisfatório considerando-se que este método ainda não havia sido testado no contexto de redução de dimensionalidade em imagens.
40
Por fim, conforme mostra a Figura 5 o SFE obteve uma melhor separação entre os indivíduos representados pelas formas quadrado e círculo. Além disso, foi mantida a boa separação obtida pelo DSPCA para os demais (triângulo e asterisco). Ainda na Figura 5, podemos ver que o SFE não está livre do efeito de outliers. Porém, mesmo para estes pontos, o método teve um bom resultado, pois os principais outliers foram projetados em posições cujos pontos vizinhos mais próximos ainda correspondem a imagens do mesmo indivíduo.
Na Figura 6 temos quatro exemplos extraídos dentre as imagens usadas nos testes. Como foi dito antes neste conjunto existem 11 imagens diferentes de cada indivíduo e conforme definição da base YALE estas imagens possuem variação de expressão facial, iluminação e presença ou não de óculos.
Figura 6. Exemplo de imagens usadas no teste de visualização.
Já na Figura 7 temos as primeiras quatro autofaces extraídas por cada um dos algoritmos. Fato interessante a ser observado é que, por haverem exatas 4 pessoas no conjunto de testes, algumas das autofaces extraídas podem ser visivelmente relacionadas a algum dos indivíduos. Curiosamente o FE teve como sua primeira autoface, uma representação quase exata de uma das imagens originais, mas esse fato apenas mostra que essa imagem representa a direção de maior variância no conjunto de dados. Lembrando que como o teste de visualização projeta as imagens em um espaço de duas dimensões, apenas as duas primeiras autofaces foram utilizadas neste experimento.
41
experimento pode ser definido como uma representação das imagens das faces como uma combinação linear das autofaces utilizadas.
Figura 7. Primeiras 4 autofaces extraídas no teste de visualização com cada um dos algoritmos. Foram usadas as 44 imagens dos primeiros 4 indivíduos da base YALE.
42
3.4 Teste de Classificação – Reconhecimento Facial
Nesta seção, vamos focar em problemas de classificação para reconhecimento de faces e estudar o comportamento do SFE em comparação com os métodos de redução de dimensionalidade dos quais este é derivado.
Nos experimentos realizados foi utilizado o método de amostragem conhecido como holdout ou amostragem aleatória, nesta abordagem os dados (imagens) são divididos em dois conjuntos de proporção 𝑝 de treinamento e (1 − 𝑝) para teste. (FACELI et al, 2011).
Como forma de melhorar a representatividade dos conjuntos de treino e teste gerados a cada holdout, foi utilizada uma amostragem estratificada. Por este método, busca-se que cada conjunto gerado mantenha as mesmas proporções entre a quantidade de objetos (faces) em cada classe (individuo).
Durante os testes a amostragem foi feita de forma que 50 por cento das imagens fossem usadas para treino dos algoritmos e os demais 50 por cento fossem usados para teste. Esse processo foi repetido 50 vezes para cada algoritmo em cada base de imagens, ou seja, para cada execução de um dos algoritmos em uma base de imagens foram realizados 50 holdout estratificados.
A cada teste o conjunto de treino selecionado no holdout é submetido como entrada para o algoritmo de redução de dimensionalidade. Como saída deste algoritmo temos as autofaces que nos permitem fazer a projeção das imagens em um subespaço de menor dimensionalidade. Para a projeção dos dados neste subespaço efetuamos a multiplicação das imagens pela matriz formada pelas autofaces (conforme o passo final em cada um dos algoritmos apresentados nas Seção 2.5.1 e no Capítulo 3).
43
estiver mais próxima. Dado que objetivo principal deste experimento é avaliar os algoritmo de extração de características, o 1-NN foi escolhido devido a ser o mais simples algoritmo de classificação.
O objetivo desta etapa é avaliar o quanto cada um dos algoritmos de redução de dimensionalidade melhora o desempenho do classificador. Para fins de comparação a métrica utilizada para avaliar o desempenho do classificador será a taxa de erro de classificação.Sendo a taxa de erro definida como o número de instâncias que não foram classificadas corretamente divido pelo número total de instâncias no conjunto de teste.
Nos testes a seguir, foi utilizado um valor de 𝑟 = 0,1 para o FE e para o SFE. Esse valor para 𝑟 foi escolhido a partir da comparação das taxas de erro para diferentes valores da constante. Os experimentos foram realizados na IDE Matlab usando uma implementação própria dos quatro algoritmos avaliados (Eigenfaces, DSPCA, FE, SFE).
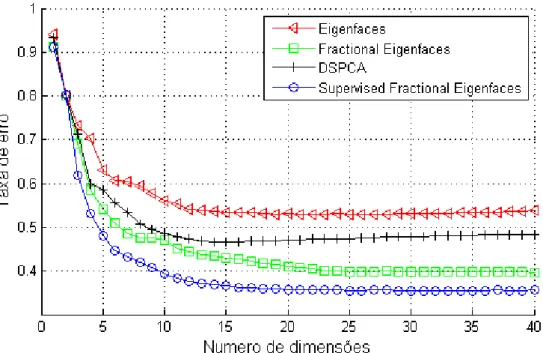
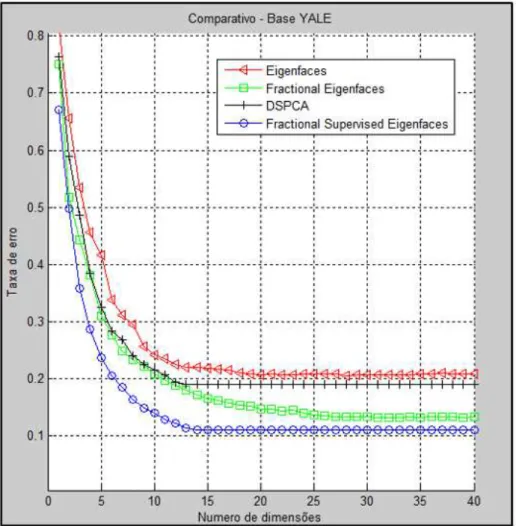
As Figuras 8 a 10 mostram os resultados das taxas de erro de acordo com o número de dimensões (autofaces) utilizadas para cada classificador. Note que no caso DSPCA e do SFE o número de autofaces é limitado ao número de classes presentes nos dados, devido a isso na base de imagens YALE (Figura 9) os resultados de ambos tornam-se constantes para um número de dimensões maior ou igual a 15.
Como pode ser vistas nos gráficos o SFE apresentou as menores taxas de erro nas três bases de imagens testadas. Sua taxa de erro chegou a ser, aproximadamente, sete pontos percentuais menor que o segundo melhor resultado na base Georgia Tech, considerando as taxas para 10 dimensões (Figura 8). Ainda nesta base, o segundo melhor resultado foi obtido pelo FE. Os resultados obtidos pelo DSPCA o colocaram em terceiro lugar, com destaque para um comportamento onde as taxas de erro passaram a crescer quando o número de dimensões se torna maior que 20. O Eigenfaces teve o pior resultado nesta base, apresentando taxas de erro superiores a 50 por cento.
44
manter à frente do FE.
Figura 8. Taxas de erro de classificação na base Georgia Tech para projeções com diferentes quantidades de dimensões. Algoritmos utilizados: Eigenfaces, Fractional
Eigenfaces, DSPCA e Supervised Fractional Eigenfaces.
45
Figura 9. Taxas de erro de classificação na base YALE para projeções com diferentes quantidades de dimensões. Algoritmos utilizados: Eigenfaces, Fractional Eigenfaces,
DSPCA e Supervised Fractional Eigenfaces.
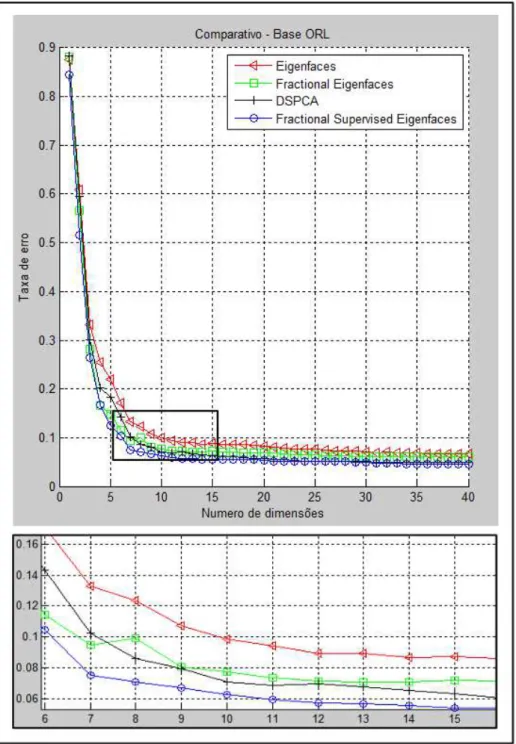
Nas Tabela 1 a 3 temos um resumos dos resultados obtidos neste teste (a tabela completa dos resultados pode ser consultada no Apêndice A). Estas tabelas permitem comparar de forma quantitativa os resultados, mostrando inclusive o desvio padrão registrado.
46
Figura 10. Taxas de erro de classificação na base YALE para projeções com diferentes quantidades de dimensões. Algoritmos utilizados: Eigenfaces, Fractional Eigenfaces,
47
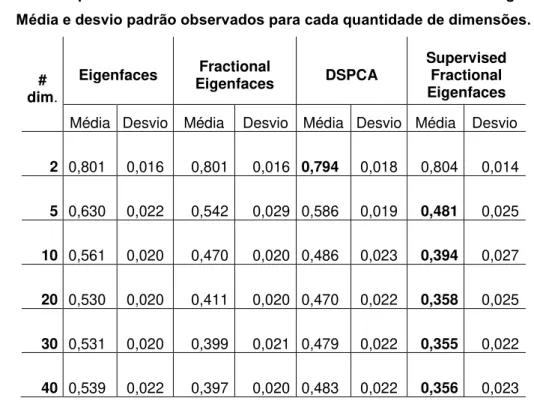
Tabela 1. Comparativo das médias das taxas de erro obtidas na base Georgia Tech. Média e desvio padrão observados para cada quantidade de dimensões.
# dim.
Eigenfaces Eigenfaces Fractional DSPCA
Supervised Fractional Eigenfaces
Média Desvio Média Desvio Média Desvio Média Desvio
2
0,801 0,016 0,801 0,016
0,794 0,018 0,804 0,014
5
0,630 0,022 0,542 0,029
0,586 0,019 0,481 0,025
10
0,561 0,020 0,470 0,020
0,486 0,023 0,394 0,027
20
0,530 0,020 0,411 0,020
0,470 0,022 0,358 0,025
30
0,531 0,020 0,399 0,021
0,479 0,022 0,355 0,022
40
0,539 0,022 0,397 0,020
0,483 0,022 0,356 0,023
Tabela 2. Comparativo das médias das taxas de erro obtidas na base YALE. Média e desvio padrão observados para cada quantidade de dimensões.
# dim.
Eigenfaces Fractional
Eigenfaces DSPCA
Supervised Fractional Eigenfaces
Média Desvio Média Desvio Média Desvio Média Desvio
2
0,657 0,045 0,518 0,050
0,589 0,050 0,498 0,047
5
0,417 0,038 0,310 0,042
0,324 0,047 0,237 0,034
10
0,242 0,032 0,209 0,036
0,216 0,041 0,141 0,032
20
0,207 0,030 0,147 0,031
0,190 0,037 0,110 0,025
30
0,206 0,032 0,133 0,028
0,190 0,037 0,110 0,025
40
0,209 0,030 0,133 0,032
48
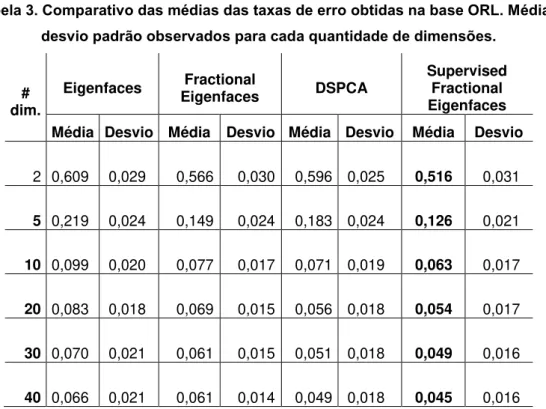
Tabela 3. Comparativo das médias das taxas de erro obtidas na base ORL. Média e desvio padrão observados para cada quantidade de dimensões.
# dim.
Eigenfaces Fractional
Eigenfaces DSPCA
Supervised Fractional Eigenfaces
Média Desvio Média Desvio Média Desvio Média Desvio
2
0,609 0,029 0,566 0,030 0,596 0,025 0,516 0,031
5
0,219 0,024 0,149 0,024 0,183 0,024 0,126 0,021
10
0,099 0,020 0,077 0,017 0,071 0,019 0,063 0,017
20
0,083 0,018 0,069 0,015 0,056 0,018 0,054 0,017
30
0,070 0,021 0,061 0,015 0,051 0,018 0,049 0,016
40
49
4
Conclusão e Trabalhos Futuros
Neste trabalho foram estudadas algumas técnicas de extração de características para redução de dimensionalidade e suas respectivas aplicações a problemas de reconhecimento facial.
Com base nos estudos realizados foi desenvolvida uma proposta de método para extração de características que combina técnicas usadas nos algoritmos DSPCA e Fractional Eigenfaces. O Supervised Fractional Eigenfaces - nome dado a proposta - foi então submetido a um extenso teste de classificação usando três bases de imagens amplamente utilizadas para avaliação de reconhecimento facial.
Os resultados do teste realizado mostraram que o SFE foi o algoritmo mais eficiente, tendo taxas de erro inferiores aos demais em todas as situações testadas. Isso foi um resultado muito positivo e serviu para validar os esforços realizados ao longo deste projeto.
Além disso, neste mesmo testes foi possível avaliar o desempenho do algoritmo DSPCA em extração de característica de faces, situação onde este ainda não havia sido testado. O DSPCA teve bons resultados quando comparado a métodos mais antigos como o Eigenfaces. No entanto, neste mesmo teste, seu resultado ficou abaixo do FE, método este de publicação mais recente.
O teste de visualização realizado, embora tenha caráter ilustrativo, serviu para mostrar os eficácia dos algoritmos testados para projeção bidimensional de dados. Este teste também mostrou que, embora o DSPCA tenha tido desempenho inferior nos testes de classificação, se mostrou um dos melhores algoritmos no teste de visualização. Esse efeito deve-se, em parte, ao fato deste algoritmo ser um método supervisionado e portanto dispor de mais informação discriminante que o Eigenfaces e o FE. O SFE também foi muito bom neste teste e, na situação testada, pôde ser avaliado como tendo obtido o melhor resultado.
50
deixado como trabalho futuro junto com mais algumas sugestões avaliadas como interessantes:
• Aplicação do algoritmo SFE para extração de características a partir de outros tipos de conjunto de dados (genes, indicadores econômicos, dados clínicos, etc.);
• Avaliar o desempenho combinado do SFE com diversos algoritmos de classificação e comparar o desempenho obtido em relação ao uso de outros métodos de extração de características;
• Explorar variações do SFE usando matrizes de kernel 𝐿 obtidas por meio de métodos não-lineares, a exemplo dos trabalhos realizados em (BARSHAN et al, 2011) com o SPCA.
51
Referências Bibliográficas
ANTON, Howard; RORRES, Chris. Álgebra linear com aplicações – 8 ed.. Bookman, 2001.
ARASHLOO, Shervin Rahimzadeh; KITTLER, Josef. Class-Specific Kernel Fusion of Multiple Descriptors for Face Verification Using Multiscale Binarised Statistical Image Features. In: Information Forensics and Security, IEEE Transactions on (Volume:9 , Issue: 12). 2014. p. 2100 – 2109.
BARSHAN, Elnaz et al. Supervised Principal Component Analysis: Visualization, Classification and Regression on Subspaces and Submanifolds. Pattern Recognition, v. 44, n. 7, 2011. p. 1357-1371.
BELHUMEUR, P. N.; HESPANHA, J. P. ; KRIEGMAN, D.. Eigenfaces vs. Fisherfaces: Recognition using Class Specific Linear Projection. In: Computer Vision — ECCV '96, 4th European Conference on Computer Vision Cambridge, UK, April 15–18, 1996 Proceedings, Volume I. p. 43-58.
BELLMAN, Richard Ernest. Dynamic Programming. Princeton, University Press, 1957.
BISHOP, Christopher M.. Pattern Recognition and Machine Learning. Springer, 2006.
CARVALHO, T.B.A. de et al. Fractional Eigenfaces. In: IEEE ICIP 2014 The International Conference on Image Processing. Paris, 2014.
CHELLAPPA, Rama; ZHAO, Wenyi (eds). Face Processing: Advanced Modeling and Methods: Advanced Modeling and Methods. Academic Press, 2011.
BAIR, Eric et al. Prediction by Supervised Principal Components. Journal of the American Statistical Association, v. 101, n. 473, 2006.
FACELI, Katti et al. Inteligência Artificial: Uma abordagem de Aprendizagem de Máquina. LTC, 2011.
52
GHODSI, Ali. Dimensionality Reduction A Short Tutorial. Department of Statistics and Actuarial Science. University of Waterloo, 2006.
IEZZI, Gelson; MURAKAMI, Carlos. Fundamentos de Matemática Elementar 1: Conjuntos, Funções. Editora Atual, 1977.
JOLLIFFE, I. T.. Principal Component Analysis. Springer, 2002.
KANADE, Takeo. Computer Recognition of Human Faces. Birkhäuser, 1977.
KELLY, Michael David. Visual Identification of People by Computer. Stanford Univ Calif Dept Of Computer Science, 1970.
KIRBY, Michael; SIROVICH, Lawrence. Application of the Karhunen-Loeve Procedure for the Characterization of Human Faces.Pattern Analysis and Machine Intelligence, IEEE Transactions on, v. 12, n. 1, 1990. p. 103-108.
KUMAR, Neeraj et al. Attribute and Simile Classifiers for Face Verification. In: Computer Vision, 2009 IEEE 12th International Conference on. IEEE, 2009. p. 365-372.
LI, Weiyong. Supervised Principal Component Analysis. U.S. Patent n. 8,359,164, 22 jan. 2013.
MILLER, Alan. Subset Selection in Regression. Chapman & Hall/CRC, 2002.
PERANTONIS, Stavros J.; PETRIDIS, Sergios; VIRVILIS, Vassilis. Supervised Principal Component Analysis using a Smooth Classifier Paradigm. In: Pattern Recognition, 2000. Proceedings. 15th International Conference on. IEEE, 2000. p. 109-112.
QUINLAN, John Ross.C4. 5: Programs for Machine Learning. Morgan Kaufmann, 1993.
ROKACH, Lior. Pattern Classification Using Ensemble Methods. SGP: World Scientific Publishing Co., 2009.
53
SANTIAGO-MOZOS, Ricardo et al. Supervised-PCA and SVM Classifiers for Object Detection in Infrared Images. In: Advanced Video and Signal Based Surveillance, 2003. Proceedings. IEEE Conference on. IEEE, 2003. p. 122-127.
SEVCENCO, Ana-Maria. LU, Wu-Sheng. Extended 2-D PCA for Face Recognition: Analysis, Algorithms, and Performance Enhancement. In: Face Recognition: Methods, Applications, and Technology. Nova Science Publishers, 2012. P. 29-55.
THEODORIDIS, Sergios; KOUTROUMBAS, Konstantinos. Pattern Recognition (4rd Edition). Academic Press, 2009.
TURK, Matthew A.; PENTLAND, Alex P. Face Recognition using Eigenfaces. In: Computer Vision and Pattern Recognition, 1991. Proceedings CVPR'91., IEEE Computer Society Conference on. IEEE, 1991. p. 586-591.
WAINER, Jacques. Métodos de Pesquisa Quantitativa e Qualitativa para a Ciência da Computação. Atualização em informática, p. 221-262, 2007.
54
Apêndice A – Resultado Analíticos do Teste de Classificação.
Seguem abaixo as tabelas com os resultados completos do teste de classificação, são fornecidas as médias das taxas de erro e desvio padrão para cada quantidade de dimensões testada.Base YALE
# dim
Eigenfaces Fractional
Eigenfaces DSPCA
Supervised Fracional Eigenfaces
55
37 0,209 0,029 0,133 0,031 0,190 0,037 0,110 0,025 38 0,209 0,030 0,133 0,033 0,190 0,037 0,110 0,025 39 0,208 0,031 0,133 0,032 0,190 0,037 0,110 0,025 40 0,209 0,030 0,133 0,032 0,190 0,037 0,110 0,025
Base ORL
# dim Eigenfaces
Fractional
Eigenfaces DSPCA
Supervised Fracional Eigenfaces