Pró-Reitoria de Pós-Graduação e Pesquisa
Programa de Pós-Graduação Stricto Sensu em Mestrado em
Gestão do Conhecimento e Tecnologia da Informação
A PREDIÇÃO DA EVASÃO DE ESTUDANTES DE
GRADUAÇÃO COMO RECURSO DE APOIO FORNECIDO POR
UM ASSISTENTE INTELIGENTE
Brasília - DF
2014
ÁTILA PIRES DOS SANTOS
APREDIÇÃODAEVASÃODEESTUDANTESDEGRADUAÇÃOCOMORECURSO DEAPOIOFORNECIDOPORUMASSISTENTEINTELIGENTE
Dissertação apresentada ao Programa de Pós Graduação Strictu Senso em Mestrado em Gestão do Conhecimento e Tecnologia da Informação da Universidade Católica de Brasília, como requisito parcial para a obtenção do Título de Mestre em Gestão do Conhecimento e Tecnologia da Informação da Universidade Católica de Brasília.
Orientador: Profº Dr. Vandor Roberto Vilardi Rissoli
Dissertação de autoria de Átila Pires dos Santos, intitulada “A PREDIÇÃO DA EVASÃO DE ESTUDANTES DE GRADUAÇÃO COMO RECURSO DE APOIO FORNECIDO POR UM ASSISTENTE INTELIGENTE”, apresentada como requisito parcial para obtenção do grau de Mestre em Gestão do Conhecimento e Tecnologia da Informação da Universidade Católica de Brasília, em (data da aprovação), defendida e aprovada pela banca examinadora abaixo assinada.
____________________________________________
Profº Dr. Vandor Roberto Vilardi Rissoli
Orientador
Universidade Católica de Brasília
____________________________________________
Profº Dr. Rodrigo Pires de Campos
Universidade Católica de Brasília
____________________________________________
Profº Dr. Hércules Antônio do Prado
Universidade Católica de Brasília
____________________________________________
Profº Dr. Fabiano Cavalcanti Fernandes
Instituto Federal de Brasília
Brasília
RESUMO
SANTOS, Átila Pires dos. A predição da evasão de estudantes de graduação como recurso de apoio fornecido por um assistente inteligente. 2014. 64 f. Dissertação (Mestrado em Gestão do Conhecimento e Tecnologia da Informação) – Universidade Católica de Brasília, Brasília, 2014.
A evasão no ensino superior tem sido objeto frequente de estudo. Pesquisas de enfrentamento
à evasão escolar estão acontecendo com apoio de recursos computacionais, como, por
exemplo, técnicas de mineração de dados. Nesta presente proposta, almejou-se combinar esta
tecnologia a um Sistema Tutor Inteligente (STI) para o processamento adequado ao seu
contexto de estudo (evasão no ensino superior), tendo como objetivo potencializar seus
resultados. Isso resultou na criação de um novo módulo, denominado Assistente de Predição
da Evasão (APE), para o STI denominado Sistema de Apoio Educacional (SAE). Ele faz uso
da base de dados desse sistema e a analisa em tempo real utilizando um comitê de preditores
criado a partir do conhecimento fornecido por algoritmos de mineração de dados.
ABSTRACT
Dropout in higher education has been the subject of frequent study. Computer resources, such
as data mining techniques, has been employed by educational dropout researches. This
proposal aimed to combine this technology with an Intelligent Tutor System for appropriate
processing on this study context (dropout in higher education), aiming to maximize their
results. That resulted in a new module Dropout Prediction Assistant for the Intelligent
Tutoring System called Educational Support System. It uses this database system and
analyzes in real time using a predictor created from the knowledge provided by data mining
algorithms.
LISTA DE FIGURAS
Figura 1 – Representação da arquitetura tradicional dos STI (Fonte: Shiguti e Rissoli, 2012). ... 24
Figura 2 – Representação simplificada da arquitetura ITA (Fonte: Shiguti e Rissoli, 2012). ... 24
Figura 3 – Representação das variáveis e seus termos linguísticos possíveis nas inferências do SAE (Fonte: Barbosa et al., 2012). ... 25
Figura 4 – Janela do SAE mostrando as opções no Cadastro de Questões. ... 26
Figura 5 – Janela do SAE fornecendo orientações pedagógicas diretamente ao aluno. ... 27
Figura 6 – Janela do SAE mostrando os resultados momentâneos apurados por suas variáveis linguísticas. ... 27
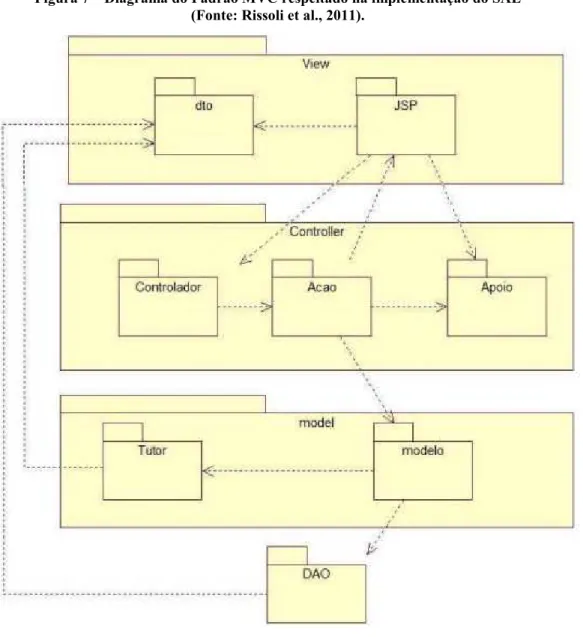
Figura 7 – Diagrama do Padrão MVC respeitado na implementação do SAE (Fonte: Rissoli et al., 2011). ... 35
Figura 8 – Representação da Interação do Módulo APE que será integrado ao SAE. ... 36
Figura 9 – Representação gráfica dos resultados dos oito momentos com os valores de parâmetros propostos. ... 50
Figura 10 – Representação gráfica dos resultados dos oito momentos com os valores de parâmetro alternativos. ... 51
Figura 11 – Diagrama de Atividades do módulo APE. ... 57
Figura 12 – Simplificação do Diagrama de Classe do módulo APE para representação do projeto a ser implementado junto ao SAE. ... 57
Figura 13 – Diagrama de Caso de Uso simplificado do módulo APE. ... 58
LISTA DE QUADROS Quadro 1 – Comparação entre a definição de cada autor para Evasão. ... 12
Quadro 2 – Principais causas da evasão indicadas por discentes e gestores de IES (Gaioso, 2005). ... 14
Quadro 3 – Principais causas para a evasão apontadas pela Comissão Especial de Estudos sobre Evasão nas IES Públicas (BRASIL/MEC, 1997). ... 15
Quadro 4 – Principais causas da evasão segundo Morosini et al. (2011). ... 16
Quadro 5 – Trabalhos de predição da evasão por meio da mineração de dados e seus principais atributos analisados. ... 22
LISTA DE TABELAS Tabela 1 – Relação entre clusters e disciplinas para o SimpleKMeans. ... 38
Tabela 2 – Relação entre clusters e disciplinas para o EM... 38
Tabela 3 – Relação entre clusters e idade (acima de 30 anos) para os seis semestres. ... 40
Tabela 4 – Relação entre clusters e idade (abaixo de 30 anos) para os seis semestres ... 40
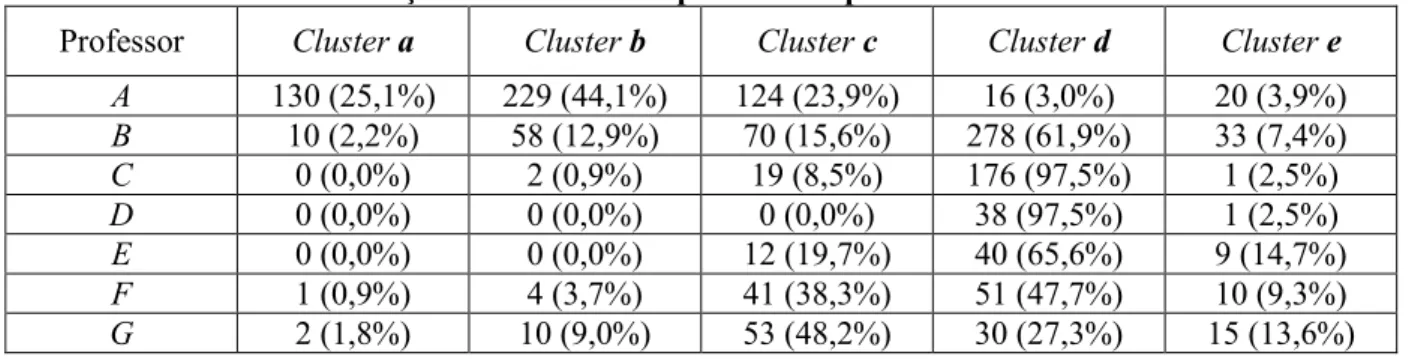
Tabela 5 – Relação entre clusters e professores para os seis semestres analisados. ... 40
Tabela 6 – Relação entre clusters e professores para a base de dados total. ... 43
Tabela 7 – Relação entre as classes da validação e as idades dos alunos. ... 44
Tabela 8 – Relação entre classes e clusters do EM para cada professor. ... 44
Tabela 9 – Relação entre classes e clusters do SimpleKMeans para cada professor. ... 45
Tabela 10 – Relação entre os erros “cluster evadido/classe não-evadido” e os professores. ... 47
Tabela 11 – Relação entre valores da variável iii e os clusters segundo o algoritmo OneR. ... 48
Tabela 12 – Resultados dos valores de incentivo e proporcionalidade. ... 52
Tabela 13 – Validação da predição do comitê de preditores simples por professor. ... 53
Tabela 14 – Médias dos valores de incentivo e proporcionalidade e comparação com o erro “cluster evadido/classe não-evadido”. ... 54
LISTA DE ABREVIATURAS
APE - Assistente de Predição da Evasão
BCC - Bacharelado em Ciência da Computação
BES - Bacharelado em Engenharia de Software
BSI - Bacharelado em Sistemas de Informação
CS - Conselho Superior
EM - Expectation-Maximization
IES - Instituição de Ensino Superior
ITA - Intelligent Teaching Assistant
KDD - Knowledge Discovery in Databases
MEC - Ministério da Educação
MVC - Model-View-Controller
NE - não propensão à evasão
NNge - Non-Nested Generalised Exemplars ou Nearest Neighbor with Generalization
OneR - One Rule
PE - propensão à evasão
SAE - Sistema de Apoio Educacional
STI - Sistema Tutor Inteligente
WEKA - Waikato Environment for Knowledge Analysis
SUMÁRIO
1. INTRODUÇÃO ... 7
1.1. CONTEXTUALIZAÇÃO ... 7
1.2. DELIMITAÇÃO DO PROBLEMA ... 8
1.3. RELEVÂNCIA DA PESQUISA ... 9
1.4. OBJETIVOS ... 9
1.4.1 Objetivo Geral ... 9
1.4.2 Objetivos Específicos ... 9
2. REFERENCIAL TEÓRICO ... 10
2.1 CONCEITO DE EVASÃO ... 10
2.2 CAUSAS DA EVASÃO ... 13
2.3 PREDIÇÃO DA EVASÃO ... 17
2.4 MINERAÇÃO DE DADOS ... 18
2.5 PREDIÇÃO DA EVASÃO PELA MINERAÇÃO DE DADOS ... 21
2.6 SISTEMA DE APOIO EDUCACIONAL ... 23
3. METODOLOGIA ... 29
4. RESULTADOS E DISCUSSÃO ... 37
4.1 RESULTADOS PARA OS SEMESTRES 2010-1, 2010-2, 2011-1, 2011-2 E 2012-1... 39
4.2 RESULTADOS PARA A BASE DE ALUNOS COMPLETA ... 41
4.3 VALIDAÇÃO DOS RESULTADOS DE CLUSTERING ... 43
4.4 RESULTADOS PARA A ETAPA DE CLASSIFICAÇÃO ... 47
4.5 RESULTADOS PARA A ETAPA DE CRIAÇÃO DO COMITÊ DE PREDITORES ... 49
4.6 DISCUSSÃO ACERCA DOS RESULTADOS ... 54
4.7 IMPLEMENTAÇÃO DO MÓDULO APE ... 55
5. CONCLUSÃO ... 59
1. INTRODUÇÃO
1.1. CONTEXTUALIZAÇÃO
A educação no nível superior tem enfrentado alguns entraves que prejudicam seu
êxito, destacando-se, entre eles, a evasão discente. Diante desta realidade, seus gestores
procuram tomar decisões estratégicas visando sanar esse problema no âmbito educacional. No
entanto, a eficácia destas decisões tem níveis variados de sucesso, sendo geralmente
relacionados à quantidade e qualidade das informações disponíveis em tempo adequado ao
seu apoio decisório. Andriola et al. (2006, p. 368) questionam o grau de êxito que as gestões
de Instituições de Ensino Superior (IES) vêm obtendo no contexto da evasão, uma vez que os
“dados acerca da evasão discente no ensino superior são pouco explorados, acarretando,
consequentemente, diminuta compreensão do fenômeno e de suas causas”.
Pesquisas têm sido realizadas buscando resolver estes entraves ao sucesso escolar,
onde recursos tecnológicos estão sendo empregados como ferramentas de apoio às atividades
educacionais. Entre estes recursos, empregados no acompanhamento da situação de
aprendizagem de cada estudante, os softwares educacionais, classificados como Sistemas
Tutores Inteligentes (STI), tem alcançado interessantes resultados como apoio complementar
ao ensino-aprendizagem.
Uma implementação desse tipo de software, utilizada por algumas universidades
brasileiras, é denominada SAE (Sistema de Apoio Educacional), STI que emprega a
tecnologia ITA (Intelligent Teaching Assistant) para fornecer orientação adequada a cada um
de seus usuários-estudantes a partir de suas interações com o próprio sistema (YACEF, 2002).
O SAE trabalha ainda com os vários “pontos de vista” de outros agentes humanos (monitores
e docentes) colaboradores com o êxito deste intrincado processo educacional
(ensino-aprendizagem) (RISSOLI, 2007).
Este tipo de STI, reconhecido como Assistente Virtual de Ensino Inteligente (ITA),
coleta informações que podem ser usadas em decisões estratégicas quanto às posturas
didático-pedagógicas que devem ser assumidas por esses outros agentes humanos em relação
às características individuais de cada aprendiz. Por meio da coleta e armazenamento contínuo
de dados significativos a modelagem dos aspectos cognitivos de cada aprendiz é possível agir,
O SAE, no entanto, não realiza uma análise explícita acerca da evasão escolar,
abordando este tema indiretamente, ao enfrentar algumas de suas causas. Por outro lado,
foram realizadas abordagens diretas ao tema da evasão por meio de processos de mineração
de dados (data mining). O objetivo da mineração de dados neste contexto (evasão) tem sido
encontrar padrões existentes em grandes quantidades de dados armazenados, de maneira
persistente (banco de dados), por meio de sistemas computacionais (WITTEN; FRANK,
2005). Por intermédio desse processo de mineração sobre os dados disponíveis em um
universo, torna-se possível identificar comportamentos de componentes deste universo que
compartilham características em comum, por exemplo, nos aspectos relacionados à evasão
discente e sua possível predição.
1.2. DELIMITAÇÃO DO PROBLEMA
As abordagens de enfrentamento à evasão discente, por meio de sua predição
envolvendo a mineração de dados, geralmente, fazem uso das informações provenientes das
bases de dados de registros acadêmicos armazenados sobre os estudantes. O que é então
fornecido por estas bases à mineração para análise da evasão é um conjunto de dados
cadastrais, que pouco variam ao longo do tempo (como, por exemplo, o sexo, o endereço,
etc.), ou uma coleção de informações acerca das notas finais e controle de frequência destes
alunos matriculados em uma disciplina, que são renovados a cada período letivo
(normalmente semestral no ensino superior brasileiro).
Desta forma, estas abordagens, ao invés de predizer a evasão, podem estar muitas
vezes detectando um problema que já ocorreu, uma vez que estas se baseiam em dados que
são atualizados, normalmente, uma vez a cada período letivo. Assim, ao longo de um período
letivo, se o contexto de um aluno se alterar, de maneira a incentivá-lo a evadir de seu curso, a
mineração de dados possivelmente terá detectado esta situação após o estudante ter evadido.
A abordagem ao problema da evasão discente pode ter resultados mais promissores,
caso possa ser acompanhada de dados que sejam atualizados com maior frequência.
Considerando STIs (como o SAE, por exemplo) como potenciais fornecedores de dados
atualizados para uma ferramenta de mineração de dados, questiona-se: ao combinar estas
tecnologias (STI e Mineração) de maneira adequada ao processamento conjunto em um
mesmo contexto do ensino superior, quais serão os benefícios e sinergias obtidos desta união
1.3. RELEVÂNCIA DA PESQUISA
Martins et al. (2012) realizaram dois experimentos de predição de evasão valendo-se
dos dados contidos em um STI chamado Alice (RAABE; GIRAFFA, 2006), comparando
então seus resultados. Os autores (p. 9) concluíram que o experimento de predição de evasão
baseado em mineração de dados “resultou em uma melhor identificação e maior precisão nos
resultados”. Os autores também ressaltam que a predição de evasão feita por meio de dados
provindos de um STI possibilita a emissão de alertas sobre evasão “desde o início da
disciplina”, ou seja, assim que o problema é identificado. Desta forma, poderia ser evitada a
abordagem típica da análise sobre evasão, onde a mineração de dados ou outra técnica realiza
um trabalho de apuração sobre o problema que possivelmente já ocorreu, sem chance de
alterar sua realidade a tempo de procurar beneficiar os envolvidos no processo educacional.
1.4. OBJETIVOS
1.4.1 Objetivo Geral
O presente estudo busca dar meios para a ação interventiva sobre o problema da
evasão por meio da predição do abandono de uma disciplina por seus alunos, sendo esta etapa
um pré-requisito para a evasão discente. Para este fim, serão combinados dois tipos de
tecnologias, STI e Mineração de dados, de maneira adequada ao processamento conjunto em
um mesmo contexto do ensino superior, com o objetivo de potencializar seus resultados no
enfrentamento da evasão e a promoção do ensino eficiente e de qualidade.
1.4.2 Objetivos Específicos
Como objetivos específicos, o trabalho pretende:
1) Analisar quais atributos dos alunos que, ao serem examinados, possibilitam melhor
predição à provável evasão;
2) Identificar os algoritmos de mineração de dados e técnicas de predição que
demonstrem um maior poder preditivo para o problema da evasão discente;
3) Iniciar o desenvolvimento de um módulo Assistente de Predição da Evasão (APE),
que será incorporado ao SAE;
4) Promover a educação personalizada apoiada por tecnologias que colaborem com
os principais agentes humanos (discente e docente) participantes do processo
2. REFERENCIAL TEÓRICO
2.1CONCEITO DE EVASÃO
O primeiro passo para compreender o problema da evasão é buscar por uma definição
desse fenômeno. Dore e Lüscher (2011, p. 775) discorrem sobre o problema da definição do
termo evasão, tendo este sido associado a diversas situações, como “a retenção e repetência
do aluno na escola, a saída do aluno da instituição, a saída do aluno do sistema de ensino, a
não conclusão de um determinado nível de ensino, o abandono da escola e posterior retorno”
e também “àqueles indivíduos que nunca ingressaram em um determinado nível de ensino,
especialmente na educação compulsória, e ao estudante que concluiu um determinado nível de
ensino, mas se comporta como um dropout”, ou seja, como um aluno evadido. Desta maneira,
torna-se difícil desassociar a evasão do fracasso escolar.
Tinto (1975, p. 89-90) aborda o problema da definição da evasão no nível superior
destacando que esta palavra costuma ser aplicada a fenômenos distintos. O autor contrastou o
abandono provocado pelo fracasso escolar e a “evasão voluntária”, por um lado, e o abandono
temporário e a “evasão permanente”, por outro. Desta forma, o autor definiu a evasão em seu
estudo como sendo apenas o fenômeno de abandono voluntário (não motivado pelo fracasso
escolar) e permanente. Da mesma forma, esse autor também excluiu transferências (de curso
ou instituição) da definição de evasão.
A Comissão Especial de Estudos sobre Evasão nas IES Públicas (BRASIL/MEC,
1997, p. 19), acerca da “ambiguidade do próprio conceito de evasão”, abordou estas mesmas
dimensões descritas anteriormente e acrescentou a elas uma nova dimensão: os “diferentes
níveis ou locus dentro do sistema” de educação de nível superior; ou seja, “a pergunta inicial,
portanto, é de qual evasão estamos falando: evasão de curso? evasão da instituição? ou evasão
do próprio sistema?”.
Desta forma, a Comissão Especial concluiu que não há unanimidade em relação ao
conceito da evasão, considerando fundamental que cada estudo explicite o conceito que será
adotado. Para seu estudo, a Comissão Especial admitiu o conceito de evasão no nível superior
como sendo a “saída definitiva do aluno de seu curso de origem, sem concluí-lo”, mas sem
abrir mão de “incluir como objeto do estudo não apenas a evasão mas igualmente as taxas de
diplomação e de retenção dos alunos dos diferentes cursos analisados” (BRASIL/MEC, 1997,
Martins (2007, p. 28) pondera sobre as conclusões da Comissão Especial acerca da
evasão, trazendo a seguinte escrita alternativa do conceito de evasão no nível superior da
Comissão Especial: “a diferença entre ingressantes e concluintes, após uma geração
completa”. Por geração completa, entende-se como a “situação do conjunto de ingressantes
em um dado curso, em um ano/período-base, ao final do prazo máximo de integralização
curricular” (BRASIL/MEC, 1997, p. 23). Desta forma, Martins (2007, p. 29) argumenta que,
baseando-se neste conceito de evasão, ao considerar como evadido apenas o “aluno que, ao
prazo máximo, não tenha concluído o curso, pode-se perder a oportunidade de reverter o
fenômeno.”.
Essa autora (p. 29) sintetiza a questão abordada pela Comissão Especial sobre a evasão
nos diferentes locus do nível superior, ou seja, caracteriza três estágios da evasão no nível superior, sendo eles: i) evasão de curso: “quando o estudante desliga-se do curso superior em
situações diversas tais como: abandono (deixa de matricular-se), desistência (oficial),
transferência ou reopção (mudança de curso), trancamento, exclusão por norma institucional”;
ii) evasão da instituição: “quando o estudante desliga-se da instituição na qual está matriculado”; e iii) evasão do sistema: “quando o estudante abandona de forma definitiva ou
temporária o ensino superior”. Existe uma sequência de pré-requisitos entre estes três níveis
de evasão: para que a evasão da instituição aconteça, é necessário evadir também do curso ou
programa. Da mesma forma, para haver a evasão do sistema, o aluno também deverá evadir
da instituição, que implica na evasão do curso ou programa.
Para seu estudo, Martins (2007, p. 29) definiu a evasão como “a saída do aluno de uma
IES ou de um de seus cursos de forma temporária ou definitiva por qualquer motivo, exceto a
diplomação”. De maneira semelhante, Gaioso (2005, p. 9) define a evasão como sendo a
“interrupção no ciclo de estudo”. Na pesquisa elaborada por esta autora (p. 38), considerou-se
o aluno como evadido quando o mesmo “deixou o curso por qualquer motivo que não seja a
obtenção da titulação”, listando como alternativas à conclusão do curso como sendo:
abandono, ou seja, “a matrícula não foi efetuada no curso dentro do prazo estabelecido”;
transferência interna ou mudança de curso; transferência externa; matrícula em curso de outra
instituição via aprovação em processo seletivo; e “desistência, re-opção ou jubilamento”.
Laguardia e Portela (2009, p. 353) definiram evasão para seu estudo como “a saída do
aluno de um curso ou programa educacional sem tê-lo completado com sucesso”, dividindo a
evasão em quatro categorias: stopout, ou interrupção temporária; attainer, ou saída para aquisição de conhecimentos; non-starter, “abandono sem começar”; e dropout, o “abandono
mobilidade do aluno, ou seja, a mudança do curso e/ou da IES; e a real, que é o “abandono
definitivo do sistema de ensino”, possuindo uma aura de “exclusão e fracasso”. Os conceitos
dos autores citados anteriormente são sintetizados no Quadro 1.
Quadro 1 – Comparação entre a definição de cada autor para Evasão.
Autor Permanente ou
Temporária
Voluntária ou Involuntária
Curso, Instituição ou Sistema
Tinto (1975) Permanente apenas Voluntária apenas
(sem interseção com o fracasso escolar)
Sistema apenas (não admite transferência
como evasão)
Cardoso (2008) Permanente apenas Ambas Sistema apenas
(não admite transferência como evasão)
BRASIL/MEC (1997), Laguardia e Portela
(2009)
Permanente apenas Ambas Curso (por consequência,
Instituição e Sistema também)
Gaioso (2005), Martins (2007), Baggi e Lopes (2011)
Ambas Ambas Curso (por consequência,
Instituição e Sistema também)
O Documento Orientador para a Superação da Evasão e Retenção na Rede Federal de
Educação Profissional, Científica e Tecnológica (BRASIL/MEC, 2014, p. 20), traz o seguinte
conceito para evasão: “situação em que o estudante abandonou o curso, não realizando a
renovação da matrícula ou formalizando o desligamento/desistência do curso”. Diante dos
objetivos da proposta desse trabalho, este conceito não foi incluído no Quadro 1, uma vez que
ele não está centrado sobre a figura do aluno e sim sobre seu processo de matrícula somente.
Desta forma, um mesmo aluno pode possuir múltiplas matrículas e ser, assim, múltiplas vezes
um evadido. Apesar desta não estar no Quadro 1, sua abordagem está contemplada nas
demais, que consequentemente não resultarão na renovação da matrícula.
É importante ressaltar que mais problemático que definir a evasão discente é definir a
retenção discente. Este termo tem sido empregado com, pelo menos, três conotações distintas
em diferentes estudos. Enquanto Martins (2007), Campello e Lins (2008) e Hatos e Suta
(2011) fazem uso do termo retenção como o termo oposto à evasão (ou seja, quanto mais alta
a taxa de retenção, menor a de evasão) e Laguardia e Portela (2009, p. 353) conceituam
retenção como “às ações, políticas e estratégias da instituição para manter o aluno no curso”,
Freitas (2010, p. 1) define a retenção como “mecanismo de suspensão da progressão regular”,
que é “comumente empregado como sinônimo de reprovação” e, nesse contexto, é o oposto à
A Comissão Especial, por sua vez, conceitua a retenção como “a situação em que,
apesar de esgotado o prazo máximo de integralização curricular e mesmo não tendo concluído
o curso, o aluno se mantém ou consta como matriculado na Universidade” (BRASIL/MEC,
1997, p. 25), ou seja, o aluno que deveria ter sido jubilado pela IES, mas não o foi. O
Documento Orientador para a Superação da Evasão e Retenção na Rede Federal de Educação
Profissional, Científica e Tecnológica (BRASIL/MEC, 2014, p. 21) traz também seu próprio
conceito de retenção, que, como seu conceito de evasão, não está centrado no aluno e sim em
sua matrícula. Desta forma, a retenção representa as “matrículas que permanecem ativas com
a situação “em curso” ou “integralizado” após a data prevista para o término do ciclo de
matrícula do curso”, ou seja, “estudantes que ainda não concluíram o curso, mesmo tendo
transcorrido o tempo previsto de conclusão”. Este conceito difere daquele apresentado pela
Comissão Especial, pois enquanto um leva em conta o prazo máximo de integralização, o
outro trabalha com o tempo mínimo (ou seja, o tempo esperado) de integralização.
2.2CAUSAS DA EVASÃO
Andriola et al. (2006, p. 369) entrevistaram 86 evadidos de cursos de graduação entre
os anos de 1999 e 2000, com o objetivo de conhecer suas opiniões acerca das causas que os
motivaram a abandonar seus cursos. A causa mais citada, por 64,2% dos entrevistados, foi a
falta de “gosto, interesse e afinidade pessoal com a área do curso ou da carreira escolhida”,
seguida por incompatibilidade entre horários de trabalho e de estudo (39,4%), aspectos
familiares (20%) e precariedade das condições físicas do curso ou inadequação curricular
(10%).
Em sua pesquisa, Gaioso (2005) entrevistou 35 alunos evadidos de nível superior,
questionando as causas do abandono do curso. A autora também entrevistou 29 dirigentes
e/ou representantes de IES, públicas e privadas, que, além de apontar as mesmas causas
indicadas pelos discentes, também incluíram outros fatores. Os resultados obtidos estão
Quadro 2 – Principais causas da evasão indicadas por discentes e gestores de IES (Gaioso, 2005).
Principais causas para a evasão apontadas pelos próprios discentes e gestores de IES
Falta de orientação vocacional / profissional e imaturidade
Necessidade de trabalhar / horário de trabalho incompatível com o do curso
Falta de perspectivas de trabalho
Falta de laços afetivos na universidade
Reprovações sucessivas
Casamentos não planejados / nascimento de filhos
Busca de desafio a si mesmo (ou seja, buscar ser admitido em um curso sem a intenção de
cursá-lo, apenas para demonstrar sua capacidade em ser admitido para aquele curso)
Herança profissional (ou seja, matricular-se em um curso escolhido pela família do discente, não
por ele mesmo)
Falta de um referencial na família
Principais causas para a evasão apontadas apenas pelos gestores de IES
Desconhecimento da metodologia do curso
Deficiência da educação básica
Mudança de endereço
Problemas financeiros
Concorrência entre as IES privadas
Estes achados obtidos por Gaioso (2005) e Andriola et al. (2006) são compatíveis com
a hipótese levantada pela Comissão Especial (BRASIL/MEC, 1997, p. 137-139) para
possíveis causas da evasão discente. Essa comissão dividiu as causas em três ordens:
relacionadas ao próprio estudante; relacionadas ao curso e a instituição; e os fatores
Quadro 3 – Principais causas para a evasão apontadas pela Comissão Especial de Estudos sobre Evasão nas IES Públicas (BRASIL/MEC, 1997).
Fatores referentes às características individuais do estudante
Relativos à habilidade de estudo
Relacionados à personalidade
Decorrentes da formação escolar anterior
Vinculados à escolha precoce da profissão
Relacionados as dificuldades pessoais de adaptação à vida universitária
Decorrentes da incompatibilidade entre a vida acadêmica e as exigências do mundo do trabalho
Decorrentes do desencanto ou da desmotivação dos alunos com cursos escolhidos em segunda ou
terceira opção
Decorrentes de dificuldades na relação ensino-aprendizagem, traduzidas em reprovações
constantes ou na baixa frequência as aulas
Decorrentes da desinformação a respeito da natureza dos cursos
Decorrente da descoberta de novos interesses que levam à realização de novo vestibular
Fatores internos às instituições
Peculiares às questões acadêmicas: currículos desatualizados, alongados; rígida cadeia de
pré-requisitos, além da falta de clareza sobre o próprio projeto pedagógico do curso
Relacionados as questões didático-pedagógicas: por exemplo, critérios impróprios de avaliação do
desempenho discente
Relacionados à falta de formação pedagógica ou ao desinteresse do docente
Vinculados à ausência ou ao pequeno número de programas institucionais para o estudante, como
Iniciação Científica, Monitoria, programas PET (Programa Especial de Treinamento), etc.
Decorrentes da cultura institucional de desvalorização da docência na graduação
Decorrentes de insuficiente estrutura de apoio ao ensino de graduação: laboratórios de ensino,
equipamentos de informática, etc.
Inexistência de um sistema público nacional que viabilize a racionalização da utilização das vagas,
Fatores externos às instituições
Relativos ao mercado de trabalho
Relacionados ao reconhecimento social da carreira escolhida
Afetos à qualidade da escola de primeiro e no segundo grau
Vinculados a conjunturas econômicas específicas
Relacionados à desvalorização da profissão, por exemplo, o “caso” das Licenciaturas
Vinculados as dificuldades financeiras do estudante
Relacionados às dificuldades de atualizar-se a universidade frente aos avanços tecnológicos,
econômicos e sociais da contemporaneidade
Relacionados a ausência de políticas governamentais consistentes e continuadas, voltadas ao
ensino de graduação
A partir do levantamento de sete outros estudos, Morosini et al. (2011, p. 8) sintetizam
oito relevantes causas da evasão, sendo estas representadas no Quadro 4.
Quadro 4 – Principais causas da evasão segundo Morosini et al. (2011).
Aspectos financeiros relacionados à vida pessoal ou familiar do estudante
Aspectos relacionados à escolha do curso, expectativas pregressas ao ingresso, nível de satisfação
com o curso e com a universidade
Aspectos interpessoais – dificuldades de relacionamento com colegas e docentes
Aspectos relacionados com o desempenho nas disciplinas e tarefas acadêmicas – índices de
aprovação, reprovação e repetência
Aspectos sociais, como o baixo prestígio social do curso, da profissão e da universidade elegida
Incompatibilidade entre os horários de estudos com as demais atividades, como, por exemplo, o
trabalho
Aspectos familiares como, por exemplo, responsabilidades com filhos e dependentes, apoio familiar
quanto aos estudos, etc.
Martins (2007, p. 35) ressalta que o problema da evasão é “complexo”, ou seja,
“resultante de uma conjunção de vários fatores que pesam na decisão do aluno de permanecer
ou não no curso”. Desta forma, “não há razões isoladas para tal decisão, sempre um motivo se
associa a outro” (GAIOSO, 2006, p. 55). Tinto (1975) sintetiza esta situação como uma
análise de custos e benefícios realizada pelo aluno. Caso os benefícios pesem mais que os
custos, o aluno permanecerá; caso contrário, ele evadirá.
2.3PREDIÇÃO DA EVASÃO
Uma das primeiras tentativas de explicar o fenômeno da evasão por meio de um
modelo teórico foi feito por Tinto (1975). Ele argumenta que a decisão de um estudante pela
permanência ou evasão se baseia na integração deste estudante ao ambiente do curso que ele
ingressa. Esta integração, por sua vez, influencia e é influenciada pelas intenções, objetivos e
compromissos que o mesmo possui. As duas principais dimensões desta interação são de
ordem acadêmica (ou seja, sua relação com seu curso) e social (ou seja, sua relação com
outros estudantes). Dekker et al. (2009) e Hatos e Suta (2011) argumentam sobre a aparente
predominância do modelo de Tinto no campo de estudos acerca da evasão estudantil.
Entretanto, os autores Hatos e Suta criticam a capacidade preditiva deste modelo para muitos
casos e Andriola et al. (2006, p. 367) ressalta que este modelo “tal como foi proposto, não se
aplica, em sua totalidade, à realidade brasileira”, uma vez que vários fatores, como o
financeiro, são completamente desconsiderados.
Como alternativas viáveis ao modelo de Tinto (1975), que vem sofrendo críticas,
Hatos e Suta (2011) trazem o modelo econométrico da persistência estudantil de Manski e
Wise (1983) e a teoria dos comprometimentos de Morgan (2002). Manski e Wise (1983)
construíram sua abordagem ao redor do fator financeiro para a persistência do aluno em uma
IES. Dessa forma, a escolha de evadir ou persistir baseia-se em um sistema de decisões em
quatro níveis: a escolha entre os estudos ou o trabalho; a escolha entre IES; a escolha de uma
universidade em admitir ou rejeitar um candidato e a escolha desta IES de fornecer ou não
auxílio financeiro ao aluno. Este modelo, no entanto, sofre críticas por desconsiderar fatores
que sejam não monetários (HATOS; SUTA, 2011). Morosini et al. (2011, p. 9) concluem que
“há um consenso de que os fatores econômicos não são os únicos responsáveis pelo abandono
A abordagem de Morgan (2002) considera que as decisões tomadas por um indivíduo
em sua trajetória educacional se baseiam na força de seus comprometimentos pré-figurativos.
Estes comprometimentos pré-figurativos são as expectativas de um indivíduo para o seu
futuro, que necessitarão de comprometimentos preparatórios, ou seja, decisões tomadas ao
longo de sua trajetória que o conduzirão para mais próximo de atingir suas expectativas.
Morgan (2002) categoriza três tipos de comprometimentos pré-figurativos:
premeditado (aquilo que ele almeja); normativo (aquilo que os outros significantes a ele
almejam para ele); e imitativo (aquilo que outros semelhantes a ele almejam). Quanto mais
fraco é seu comprometimento, menor é a probabilidade dele tomar decisões que o conduzam
ao cumprimento deste comprometimento.
Em seu levantamento, a maioria dos trabalhos encontrados por Hatos e Suta (2011)
eram de natureza quantitativa que buscavam testar estes modelos teóricos apresentados nos
parágrafos anteriores. Outros trabalhos encontrados pelos autores buscavam, por meio de
técnicas estatísticas, novas relações entre as variáveis disponíveis e a tendência à evasão. Uma
variação desta abordagem é o uso de técnicas de mineração de dados ao invés de técnicas
estatísticas.
2.4MINERAÇÃO DE DADOS
Witten e Frank (2005, p. 5) definem mineração de dados como o “processo de
descobrimento de padrões em dados”. Tan et al. (2009, p. 3) definem mineração de dados
como o “processo de descoberta” semiautomática “de informações úteis em grandes depósitos
de dados”, “com o intuito de descobrir padrões úteis”. Estes autores (2009) ainda fazem a
ressalva de diferenciar mineração de dados de recuperação de dados, como no caso da busca
por registros individuais, por exemplo.
Fayyad et al. (1996, p. 28) também corrobora com estas definições apresentadas
anteriormente, trazendo outros sinônimos usualmente encontrados na literatura, como
“extração de conhecimento, descoberta de informação, colheita de informação, arqueologia de
dados e processamento de padrões de dados”. Estes autores (1996), assim como Tan et al.
(2009), diferenciam mineração de dados de descoberta de conhecimento em banco de dados,
ou KDD (Knowledge Discovery in Databases), sendo que a mineração de dados é apenas uma
As outras duas etapas do KDD definidas por Tan et al. (2009, p. 4) são:
pré-processamento e pós-pré-processamento, sendo que a primeira transforma “os dados de entrada
brutos em um formato apropriado para análises subsequentes”, sendo esta talvez “o passo
mais trabalhoso e demorado no processo geral de descoberta de conhecimento”. A segunda
etapa preocupa-se em filtrar os resultados, assegurando “que apenas resultados válidos e
úteis” sejam encontrados, eliminando “resultados não legítimos da mineração de dados”.
Witten e Frank (2005, p. 42) descrevem algoritmos utilizados para o aprendizado de
máquina na mineração de dados. Eles são divididos em quatro conceitos, que são:
Aprendizagem Classificatória, Aprendizagem Associativa, Agrupamento ou Clustering e Predição Numérica (WITTEN; FRANK, 2005). O problema da evasão discente é tratado,
usualmente, pela aplicação de algoritmos do primeiro ou do terceiro grupo, sendo ambos
capazes de classificar alunos em categorias (ou classes) de acordo com suas características
(DEKKER et al., 2009).
Os algoritmos de classificação são também conhecidos como algoritmos de
aprendizagem supervisionada, uma vez que há a necessidade que classes estejam
pré-definidas antes de sua aplicação. Por outro lado, os algoritmos de agrupamento ou clustering
são chamados de algoritmos de aprendizagem não-supervisionada, uma vez que eles não
possuem esta limitação característica dos algoritmos de classificação, sendo eles mesmos
capazes de criar categorias (clusters) e associar seus elementos a elas (WITTEN; FRANK,
2005).
Segundo Witten e Frank (2005, p. 137), k-means é a “técnica de clustering clássica”.
Estes autores, assim como Tan et al. (2009, p. 593), explicam que o primeiro passo no
funcionamento do k-means clássico é a escolha do valor do parâmetro k, que explicita quantos
clusters o usuário deseja que sejam criados. Então, um número de pontos igual ao valor definido para k é escolhido aleatoriamente, sendo estes os centros dos clusters. Todos os outros pontos são, então, designados para o cluster mais próximo, usando como métrica a distância euclidiana. Um novo ponto é então escolhido, chamado centroide, que corresponde
ao ponto médio entre os pontos que fazem parte deste cluster. Este torna-se o novo centro do
cluster e o processo é repetido até que não haja mais mudanças nos centros dos clusters.
Embora seja um método “simples e efetivo”, não há garantias que o melhor resultado
alcançado ao final do processo seja o melhor resultado possível para a amostra utilizada,
sigla para Expectation-Maximization. Ele é descrito por Witten e Frank (2005, p. 265) como
sendo capaz de “convergir para um máximo de maneira garantida”, ainda que este seja um
máximo local e não global. Ele calcula as funções de verossimilhança dos clusters criados (fase de Expectation) e então busca maximizar seus valores (fase de Maximization).
O OneR, forma reduzida de One Rule, é um exemplo de algoritmo de classificação baseado em regras. Ele é descrito por Witten e Frank (2005, p. 408) como um algoritmo
simples, que seleciona uma regra simples dentre várias (a com maior grau de acurácia) e a
utiliza para predições, baseada em uma única variável. Ele é considerado por estes autores,
junto ao algoritmo ZeroR (que simplesmente usa a classe mais comum para todas as
instâncias) como pontos de referência básicos (WITTEN; FRANK, 2005).
OneR é também considerado útil para obter uma impressão inicial de um grupo de
dados, uma vez que ele é extremamente rápido e razoavelmente preciso. Embora o OneR
muitas vezes obtenha resultados “surpreendentemente – até mesmo embaraçosamente – bons”
em comparação com técnicas mais elaboradas, ela está muitas vezes propensas ao sobreajuste
(overfitting), ou seja, a inclusão do ruído nas regras utilizadas pelo classificador. Embora estas
regras funcionem bem para a amostra utilizada, ela terá resultados menores com dados que
não foram usados para a criação das regras (WITTEN; FRANK, 2005, p. 88).
Outro exemplo de algoritmo de classificação baseado em regras é o NNge, ou Non-Nested Generalised Exemplars ou ainda Nearest Neighbor with Generalization. Ele é descrito por Martin (1995) como uma extensão do algoritmo NGE (Nested Generalised Exemplars),
embora o NNge não permita nem o aninhamento (nesting) e nem a sobreposição de
hiper-retângulos. Witten e Frank (2005, p. 238) descrevem os exemplares generalizados como
regiões retangulares no espaço amostral, “chamados de hiper-retângulos porque eles são
hiper-dimensionais”. Ou seja, assumindo cada variável (coluna) de uma base de dados como
uma dimensão e cada instância (linha) como um ponto representável em um plano cartesiano,
para uma amostra com duas variáveis, os exemplares generalizados seriam retângulos; e para
uma amostra com três variáveis, eles seriam paralelepípedos.
Todos os pontos contidos nestes hiper-retângulos deverão corresponder a uma mesma
classe. Instâncias vizinhas da mesma classe poderão ser incluídas neste hiper-retângulo, que
aumenta de tamanho para incluí-las. Pontos que não tenham um hiper-retângulo vizinho, mas
tenham outras instâncias vizinhas de mesma classe poderão iniciar um novo hiper-retângulo.
hiper-retângulo, o tamanho deste é diminuído de forma a excluir a instância de classe diferente do
espaço englobado pelo hiper-retângulo (MARTIN, 1995).
Witten e Frank (2005) comparam classificadores baseados em regras e árvores de
decisão, considerando que, ao menos superficialmente, ambas estratégias são semelhantes.
Uma diferença entre as duas estratégias ressaltadas pelos autores é que enquanto os
algoritmos de árvore consideram todas as classes ao criar uma divisão, os algoritmos baseados
em regras consideram apenas uma classe por vez. No entanto, é possível extrair um conjunto
de regras a partir de uma árvore de decisão, cada uma correspondendo uma cadeia de decisões
até um nó folha desta árvore. Exemplos de algoritmos classificatórios baseados em árvores de
decisão incluem o algoritmo C4.5 e suas implementações (como o J48) e o Random Tree.
2.5PREDIÇÃO DA EVASÃO PELA MINERAÇÃO DE DADOS
Dekker et al. (2009, p. 42) consideram o uso de técnicas de mineração de dados para
predição da evasão discente como sendo “relativamente nova”. Durante o levantamento de
trabalhos relevantes sobre este tema foi confirmada tal afirmação, pois nenhuma publicação
foi encontrada antes do ano 2000. Além disso, grande parte da bibliografia utilizada por estes
trabalhos, como referencial teórico, é composta por conteúdos que não tratam diretamente o
problema da evasão discente, tendo como objeto de estudo o fracasso escolar. Os trabalhos
que foram encontrados que efetivamente abordam a evasão discente, com emprego de
Quadro 5 – Trabalhos de predição da evasão por meio da mineração de dados e seus principais atributos analisados.
Pesquisa Notas Sexo Idade Profissão Renda Endereço 2ºGrau Vestibular Pais
Amorim et
al. (2008) X X
Bayer et
al. (2012) X X X X
Campello e Lins (2008)
X X X
Cobbe et
al. (2011) X X X X X X X
Dekker et
al. (2009) X X
Manhães et al. (2011, 2012) X Martins et
al. (2012) X X
Nassar et
al. (2004) X X X X
Penedo e Capra (2012)
X X X X
Santos et
al. (2012) X
Souza
(2008) X
Superby et
al. (2006) X X X X X X X
Total 10 5 5 4 3 3 3 2 1
A abordagem utilizada por estes artigos é semelhante, variando principalmente no
quesito de quais atributos foram trabalhados e qual ou quais algoritmos de mineração de
dados foram aplicados. Os atributos dos estudantes mais frequentemente encontradas nesses
estudos foram: situação/notas do aluno em disciplinas já cursadas (incluindo aqui o total de
reprovações que o aluno já teve e sua frequência), sexo/estado civil, idade, profissão, renda
familiar, o endereço residencial e o colégio onde o aluno cursou seu ensino médio.
A escolha dessas variáveis é justificada por Cobbe et al. (2011) pelo levantamento
superior: a necessidade de trabalhar / horário de trabalho incompatível com o de estudo,
problemas financeiros, casamento / nascimento de filhos, desconhecimento da metodologia do
curso escolhido, deficiência da educação básica e reprovações sucessivas.
Vale ressaltar que há ainda outras variáveis, presentes em apenas alguns estudos: nota
do aluno no processo seletivo de admissão na IES e o nível de escolaridade do pai e/ou mãe
do estudante. Superby et al. (2006) vão além, trazendo como variável em seu estudo a
estrutura familiar do aprendiz e até mesmo o fato do estudante ser fumante ou não.
Quanto à escolha do algoritmo de mineração de dados, a maioria dos trabalhos
pesquisados utiliza mais do que um tipo e os compara e/ou os agrega em um comitê. Dekker
et al. (2009) concluíram que, possivelmente, os algoritmos de classificação por árvore de
decisão sejam as melhores escolhas e que os algoritmos de clustering podem auxiliar na criação das classes e categorização dos estudantes dentro destas classes, como feito por
Campello e Lins (2008).
O experimento de Martins et al. (2012, p. 9), que combina a abordagem de mineração
de dados com um STI para a predição da evasão, obteve resultados que indicaram uma baixa
capacidade de predição: “para cada aluno identificado corretamente, aproximadamente dois
são identificados incorretamente”. Os autores sugerem que os resultados obtidos estavam
abaixo das expectativas porque a predição estava baseada apenas em fatores relacionados à
aula, ou seja, suas notas, sua participação em aula e sua postura como aluno. Assim, fatores
como sua condição financeira e seu histórico escolar foram desconsiderados. Ainda existe a
possibilidade dos algoritmos utilizados para a predição (OneR e NNge) não serem os mais
adequados para este tipo de problema.
2.6SISTEMA DE APOIO EDUCACIONAL
Yacef (2002) contrasta STI e ITA, sendo o primeiro conceito mais geral e inclusivo e
o segundo, mais específico e incluído no primeiro. Enquanto STIs têm seu foco sobre o
estudante, ITAs têm seu foco tanto sobre o estudante quanto o professor. Enquanto STIs
“buscam auxiliar o aprendizado seguindo um currículo confeccionado para as necessidades
individuais de cada estudante” e então recebendo feedback individualizado, o objetivo dos ITAs é “facilitar o processo de ensino/aprendizagem como um todo, auxiliando tanto
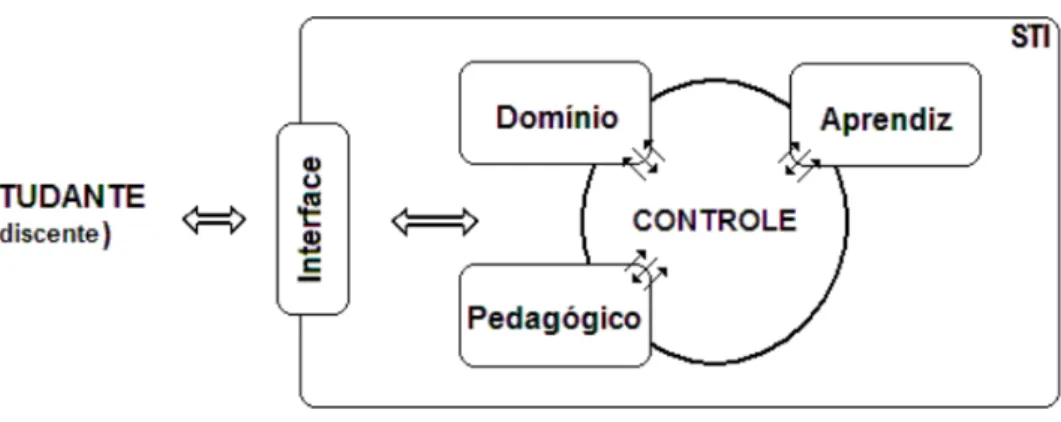
A Figura 1 apresenta os componentes principais da arquitetura do STI mais
tradicional, enquanto a Figura 2 mostra a arquitetura do ITA.
Figura 1 – Representação da arquitetura tradicional dos STI (Fonte: Shiguti e Rissoli, 2012).
Figura 2 – Representação simplificada da arquitetura ITA (Fonte: Shiguti e Rissoli, 2012).
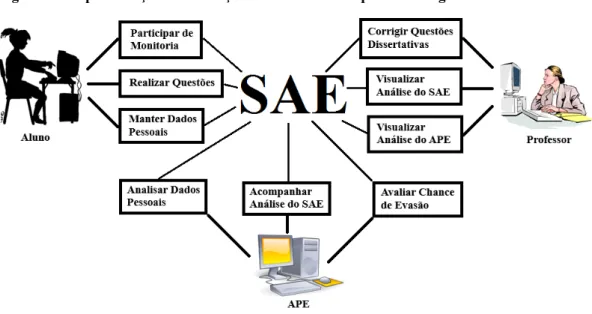
No Sistema de Apoio Educacional (SAE) cada estudante interage com os recursos
fornecidos por este ITA, que utiliza a Lógica Fuzzy em seus processos de inferência para
modelar os aspectos cognitivos de cada aprendiz. Esse assistente inteligente (SAE) serve de
tutor virtual aos aprendizes durante os seus momentos mais propícios de dedicação ao estudo
e a fixação do conteúdo a ser assimilado, por meio da observação do comportamento
interativo de cada um na realização de exercícios e tarefas, contatos com os monitores e a
participação de atividades colaborativas com os demais estudantes de sua turma, além de seu
próprio professor. No ambiente virtual do SAE cada aprendiz pode acompanhar seu próprio
esforço e desempenho obtido sobre cada conteúdo de aprendizagem, sendo indicado por este
sistema a possível necessidade de maior atenção e mais tempo no estudo sobre os tópicos
específicos de um conteúdo em que estão sendo detectadas deficiências momentâneas de
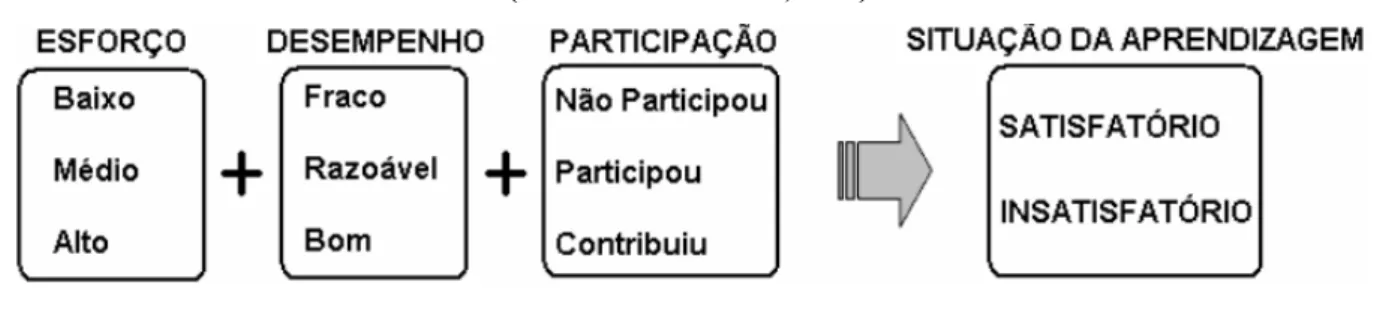
As análises e as variáveis linguísticas acompanhadas pelo SAE, sobre a realidade de
cada aprendiz, são explicitadas por Rissoli e Santos (2011), sendo seu principal foco a
averiguação dos termos linguísticos mais coerentes as variáveis: participação, esforço e
desempenho do aprendiz. A primeira variável, participação, infere “a participação de cada
aprendiz nas atividades interativas propostas pelo docente”, que “poderão acontecer por meio
de fóruns ou chats (bate-papo) envolvendo assuntos relacionados aos conceitos pertinentes a
cada conteúdo”. A variável esforço averigua “o número de exercícios resolvidos e a
quantidade de visitas que cada estudante efetuou na monitoria estudantil” por tópico ou
conceito abrangido por cada conteúdo, enquanto que o desempenho “envolve o resultado
obtido na solução da quantidade de exercícios apurados pela variável esforço” ou pelas
tarefas solicitadas pelo próprio SAE e pelo docente (RISSOLI; SANTOS, 2011, p. 7-9).
Os possíveis valores (termos linguísticos) que cada uma destas variáveis podem
assumir no SAE são representados na Figura 3.
Figura 3 – Representação das variáveis e seus termos linguísticos possíveis nas inferências do SAE (Fonte: Barbosa et al., 2012).
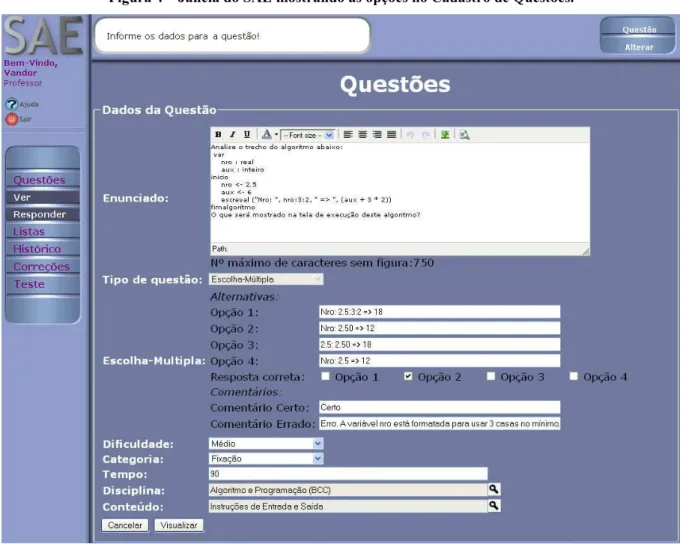
Esses autores subdividem os aspectos relacionados a qualidade obtida na variável
desempenho em: tipo de questão (verdadeira ou falsa, múltipla escolha, escolhas múltiplas,
lacuna e aberta ou dissertativa); nível de dificuldade (fácil, médio e difícil) e categoria da
questão (revisão, fixação e avaliativa), como pode ser observado na Figura 4. Cada registro de
uma questão no SAE pode assumir um único valor em cada um destes três aspectos
responsáveis pela apuração fuzzy que qualifica o resultado obtido. Por exemplo, uma questão
do tipo aberta, que seja avaliativa e possua nível de dificuldade difícil, poderia representar um
valor expressivo à inferência fuzzy para esta variável linguística (desempenho) apurada pelo
SAE. É importante ressaltar que cada tipo de questão, nível de dificuldade e categoria
trabalham uma habilidade e capacidade de reflexão condizente com a assimilação do
de análise do SAE, conforme a expectativa de aprendizagem desejada em cada conceito que
compõe um conteúdo (ou disciplina).
Figura 4 – Janela do SAE mostrando as opções no Cadastro de Questões.
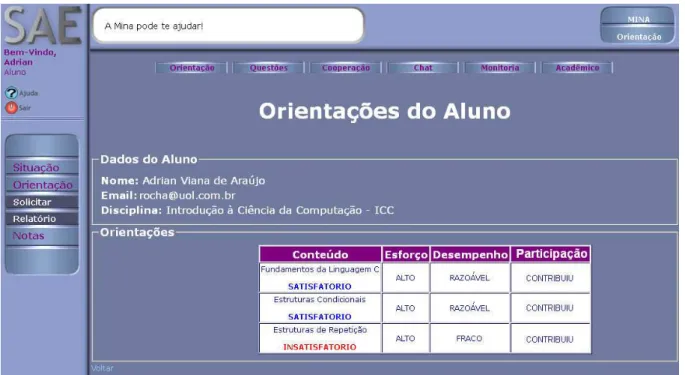
Além de orientar pedagogicamente os aprendizes, conforme pode ser observado na
Figura 5, esse ITA (SAE) ainda coleta dados que são relevantes à assistência adequada para as
possíveis mudanças de estratégias didáticas na atuação mais coerente do docente e dos
monitores estudantis. Alguns desses dados coletados possibilitam a apuração das variáveis
linguísticas, como mostrado na Figura 6, tornando-se possível uma intercessão mais objetiva
Figura 5 – Janela do SAE fornecendo orientações pedagógicas diretamente ao aluno.
Rissoli (2007, p.30) ressalta que “estas dificuldades podem contribuir ainda mais com
a falta de motivação do estudante” e que isto pode promover o “acumulo de conteúdo a ser
estudado, timidez em expressar suas dúvidas em sala de aula, principalmente pela dificuldade
em formular suas questões, além da não participação efetiva nos trabalhos elaborados em
grupo”, e que, desta maneira, poderia contribuir com “a evasão escolar”. Sendo assim, por
meio do SAE e de informações sobre o contexto do aprendiz dentro e fora da sala de aula, é
possível predizer, com maior segurança, um quadro de possível evasão em tempo real,
possibilitando uma ação de maior intervenção docente e do próprio ITA junto a cada
3. METODOLOGIA
A pesquisa elaborada neste trabalho classifica-se como experimental e aplicada. O
estudo experimental, segundo Martins e Theóphilo (2009), é uma estratégia de pesquisa que
busca a construção do conhecimento por meio da verificação das variáveis identificando as
relações causais entre elas. A pesquisa aplicada, por outro lado tem ênfase prática na solução
de problemas (COOPER; SCHINDLER, 2011).
Para este estudo adota-se o conceito de evasão proposto por Gaioso (2005, p. 38) e
corroborado por Martins (2007) e Baggi e Lopes (2011), já apresentado anteriormente: a
evasão ocorre quando o estudante “deixou o curso por qualquer motivo que não seja a
obtenção da titulação”, sendo que a evasão não necessariamente possui caráter permanente.
Adotam-se ainda os três locus de evasão propostos pela Comissão Especial (BRASIL/MEC,
1997), ou seja, o curso, a instituição e o sistema de ensino. Acrescentam-se neste trabalho
mais dois atributos que são o semestre (ou módulo) em curso e a própria disciplina de estudo
onde o aluno está matriculado.
Desta forma, o estudante evadido, ou em processo de evasão, realiza uma série de
abandonos, em cinco etapas: 1) abandono da disciplina que está cursando; 2) abandono do
semestre ou módulo; 3) desistência do curso; 4) saída da instituição (IES); 5) abandono do
nível superior como um todo. Depreende-se que a segunda etapa tem como pré-requisito a
primeira (seja ela ao longo de um período letivo, seja ela entre um período letivo e outro). Da
mesma forma, para alcançar a terceira etapa, ele deverá ter realizado a segunda, que implica
ter realizado a primeira. O mesmo vale para a quarta e quinta etapas. Assim, um estudante que
alcance as últimas etapas de abandono deverá ter passado antes pela primeira etapa.
Diante dessas constatações, o presente estudo busca dar meios para a ação interventiva
sobre o problema da evasão por meio da predição da primeira etapa do abandono, sendo este
um pré-requisito para o alcance das outras etapas. Para tanto, valeu-se dos dados armazenados
pelo SAE acerca de seus alunos. Como este ITA está restrito apenas ao contexto do
acompanhamento educacional de cada aluno, sem conter dados pertinentes a um sistema de
registro acadêmico, este estudo limita-se à predição do abandono de disciplinas durante o
transcorrer do período letivo.
Para as etapas iniciais deste projeto foi utilizada a base de dados dos estudantes de
semestres já concluídos armazenados pelo SAE. A primeira etapa do experimento foi a fase
atributos se baseia nas escolhas de estudos anteriores e na disponibilidade de dados de alunos
contidos no SAE. Desta forma, os dados que foram selecionados são: i) total de questões obrigatórias respondidas pelo aluno (listas de exercícios solicitadas pelo docente), ii) total de
questões obrigatórias respondidas corretamente pelo aluno, iii) total de questões avulsas respondidas pelo aluno (realizadas de maneira proativa pelo estudante), iv) total de questões
avulsas respondidas corretamente pelo aluno, v) número de acessos realizados ao SAE pelo
aluno, vi) nome da disciplina, vii) nome do professor, viii) idade do aluno, ix) sexo do aluno, x) número de visitas do aluno à monitoria e xi) número de solicitações de orientações feitas por aluno ao SAE.
Vale ressaltar que os itens i a v, x e xi não foram apenas analisados na mineração de dados realizada neste trabalho que utilizou seus valores “brutos” referentes a cada estudante.
Foram usados também os dados resultantes das análises efetuadas pelo SAE com aplicação da
Lógica Fuzzy sobre as variáveis linguísticas mencionadas anteriormente. Duas destas variáveis, chamadas Esforço e Desempenho, são utilizadas pelo SAE na composição do grau
de pertinência da apuração fuzzy realizada e que receberá a denominação de Relativo. A média dos valores desse Relativo, obtidas pelo estudante ao longo da disciplina, foi utilizada
como a variável xii nessa análise.
Outros atributos, que não estão disponíveis no SAE, não puderam ser analisados na
base histórica desse ITA relacionados aos semestres já transcorridos. No entanto, eles foram
considerados na última etapa deste estudo, no desenvolvimento de um novo módulo para o
SAE, que solicitará aos alunos que informem estes dados, geralmente de registros pessoais, ao
sistema. Estes atributos são: xiii) endereço, xiv) estado civil, xv) número de horas semanais reservadas para sua profissão, xvi) tipo de colégio de nível médio cursado pelo aluno (particular, público ou militar), xvii) nível de instrução do pai do aluno e xviii) nível de instrução da mãe do aluno. Desta maneira, estão contemplados quase todos os atributos
descritos no Quadro 5 para uma averiguação mais completa e segura na predição almejada.
Para as duas etapas seguintes, de clustering e classificação, foi usada a suíte de mineração de dados WEKA (Waikato Environment for Knowledge Analysis), ferramenta
genérica e livre para a mineração que suporta diferentes abordagens de aprendizagem de
máquina (WASHIO et al., 2007). Como observado por Dekker et al. (2009) e executado por
Campello e Lins (2008), fez-se uso de clusters para agrupar instâncias similares, com o objetivo de criar categorias para classificar a situação de cada aluno. Dois algoritmos
clustering foram usados com suas configurações padrões, exceto pelo valor do parâmetro k, configurado para criar cinco clusters. Também foi permitido ao EM sugerir valores para k.
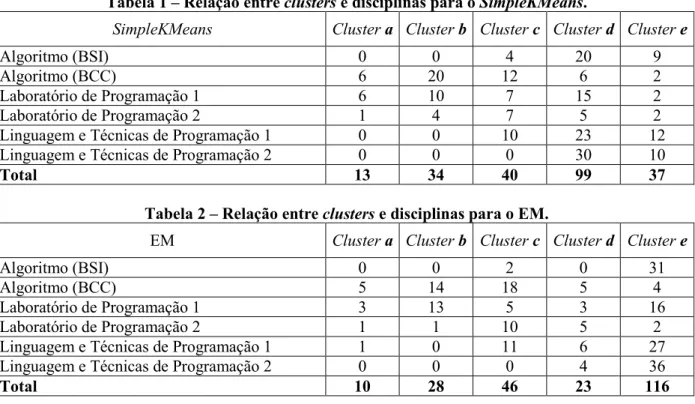
As variáveis de i a v foram utilizadas para a divisão do universo de alunos em clusters,
como foi feito em Santos et al. (2013). Apenas estas cinco variáveis foram utilizadas por se
acreditar que elas evidenciam o processo de evasão mais claramente do que outras variáveis
disponíveis, como x e xi. Assim, um aluno participativo e não propenso à evasão poderia não
solicitar ajuda de um monitor, mas ele dificilmente deixaria de realizar tarefas que refletirão
em sua nota final. As variáveis vi a ix podem ser causas da evasão, mas não consequências.
A escolha pelo uso de algoritmos de clustering se deve a necessidade de classificar as
instâncias extraídas do banco de dados do SAE. Por um lado, esta necessidade acontece pelo
fato de não haver uma classificação nativa ao SAE acerca da evasão discente, sendo essencial,
portanto, que este dado seja fornecido por outra fonte. Por outro lado, independente da fonte
consultada, esta classificação estará dividida em apenas duas classes (evadido ou não
evadido), não sendo possível assim observar as nuances dentro de cada classe. Esta etapa foi
executada na base de dados dos estudantes fornecida pelo SAE, amostra que inclui 1509
instâncias de um universo de 1721, cada uma representando um aluno que cursou uma
disciplina em um dos dois semestres dos anos de 2010, 2011 ou 2012. Dando continuidade ao
experimento apresentado em Santos et al. (2013), esta etapa foi aplicada também a todos os
semestres, individualmente.
Os estudantes da base fornecida pelo SAE cursavam o Bacharelado em Sistemas de
Informação (BSI), o Bacharelado em Ciência da Computação (BCC) ou o Bacharelado em
Engenharia de Software (BES), sendo identificados, respectivamente, neste trabalho como
alunos de BSI (94 em 2011-1, 99 em 2011-2, 163 em 2012-1 e 118 em 2012-2, total de 474
alunos), de BCC (224 em 2010-1, 146 em 2010-2, 178 em 2011-1, 125 em 2011-2, 147 em
2012-1 e 105 em 2012-2, total de 925 alunos) e de BES (49 em 2011-2 e 61 em 2012-1, total
de 110 alunos). Os cursos BSI e BCC foram oferecidos e coordenados por uma IES, enquanto
o curso BES pertence à outra IES. As disciplinas analisadas foram: Algoritmo (82 alunos de
BSI e 390 alunos de BCC), Introdução à Ciência da Computação (110 alunos de BES),
Laboratório de Programação 1 (315 alunos de BCC), Laboratório de Programação 2 (220
alunos de BCC), Linguagem e Técnicas de Programação 1 (219 alunos de BSI) e Linguagem
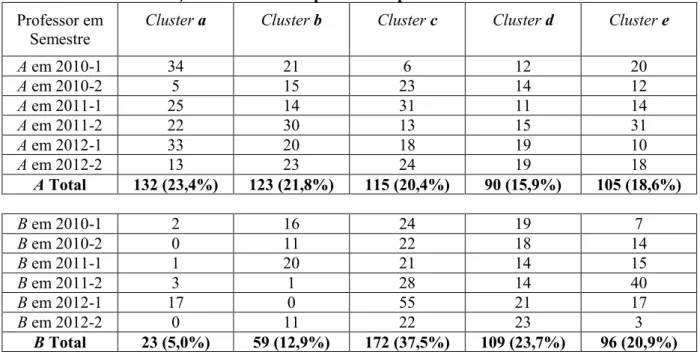
e Técnicas de Programação 2 (173 alunos de BSI). Àqueles quatro professores atuantes em
Em seguida, com o objetivo de validar os clusters criados na etapa anterior, estes foram comparados à situação real dos alunos, baseando-se em seu total de faltas ao final de
uma disciplina. Todos os alunos com até 25% de faltas foram considerados não-evadidos
nesta disciplina. Alunos com mais de 25% e até 50% de faltas foram classificados como
possíveis evadidos e, acima desta faixa, evadidos.
Na etapa seguinte foram usados os algoritmos de classificação sobre a base de dados.
Uma vez que eles são algoritmos de aprendizagem de máquina supervisionada (enquanto os
algoritmos de cluster trabalham com aprendizagem não-supervisionada), há a necessidade que
as classes estejam pré-definidas antes de sua utilização (WITTEN; FRANK, 2005). Desta
forma, eles podem ser utilizados apenas depois que as instâncias já foram associadas aos
clusters, empregados aqui como classes.
O objetivo desta etapa é aprender por meio de um algoritmo de classificação as boas
estratégias para associar uma instância da base de dados ao seu cluster correspondente. Desta
forma, foi necessária a utilização de algoritmos de classificação capazes de explicar suas
escolhas realizadas no processo classificatório, ou seja, o porquê uma instância foi
classificada de uma determinada forma. Uma família de algoritmos classificatórios e
reconhecidamente possuidores dessa característica são os baseados em regras, como o OneR e
NNge. Ambos são utilizados por Martins et al. (2012) em seu experimento semelhante para
predizer a evasão escolar por meio de uma base de dados fornecida por um ITA.
Outra família de algoritmos classificatórios e possuidor da capacidade de explicar suas
escolhas, recomendada por Dekker et al. (2009) para o problema da predição da evasão, são
os baseados em árvores de decisão, como o J48 e o Random Tree. Estes quatro algoritmos,
dois baseados em regras e dois em árvores de decisão, foram utilizados nesta etapa do
experimento. Todos eles foram usados com suas configurações padrões. Empregou-se o
método de cross-validation (10-fold) nesta etapa do experimento, com a justificativa dele possibilitar uma melhor estimativa da margem de erro de classificação (WITTEN; FRANK,
2005). Para o algoritmo OneR, cada variável foi testada em separado, a fim de verificar seu
poder preditivo dentro do contexto do funcionamento deste algoritmo. As variáveis i a xii foram utilizadas para a etapa de classificação.
Após as verificações necessárias, realizadas com os algoritmos de mineração de dados
no WEKA, teve início a etapa de desenvolvimento do módulo APE (Assistente de Predição da
Evasão), que será incorporado ao SAE. Este módulo incorpora o conhecimento descoberto na
forma de um preditor simples para cada variável utilizada no experimento. Estes preditores
têm, cada um, como entrada um parâmetro que será o valor aplicado para definir a fronteira
da classificação. Portanto, este valor dividirá o universo analisado por um preditor entre
estudantes evadidos e não-evadidos.
Os preditores criados estão organizados como um comitê de classificadores. A
importância de organizar os preditores simples em um comitê deve-se ao teorema NFL
(WOLPERT; MACREADY, 1997). Uma vez que, de acordo com o teorema, não há nenhum
melhor algoritmo para todas as possíveis situações de um determinado problema, decidiu-se
unir os esforços destes vários preditores. Desta forma, cada um dará um veredito sobre a
situação de um aluno, de acordo com suas características em um dado momento. Será então
realizada uma votação e se definirá a classe à qual aquele estudante pertence.
Como o SAE analisa vários dados, provenientes de diferentes perfis de usuários
(aluno, monitor, professor), e infere, continuamente, novas informações sobre seus estudantes,
o processamento de classificação do potencial de evasão discente pode acontecer em tempo
real, como proposto por Martins et al. (2012). Desta forma, será possível acompanhar a
evolução de cada aprendiz ao longo de seu período letivo, sendo cada um assistido sobre a
situação de transição entre as possíveis classes de evasão. Para tanto, os dados fornecidos pelo
ITA (SAE) deverão ser organizados em uma linha do tempo, que evidencia o progresso de
cada aluno ao longo do semestre.
Neste estudo, o semestre de 2012-2 será utilizado para a criação de uma linha do
tempo com o objetivo de verificar a acurácia do comitê de preditores simples com os dados
disponíveis antes do fim de um semestre. Este semestre será dividido em oito momentos
posteriores ao momento zero, que corresponde ao início do semestre e não há dados
disponíveis sobre um aluno em uma disciplina que está iniciando. Todos os momentos têm
entre si e o próximo momento um período de duas semanas e o oitavo momento corresponde
ao final de uma disciplina, quando todos os dados estão disponíveis.
Nos estudos de Santos et al. (2013) é ressaltada a discrepância aparente na relação
entre alunos percebidos pela mineração de dados como evadidos, onde o professor apenas
evidenciava que estes docentes discrepantes (C e D) não incentivam seus alunos a fazer uso do ambiente SAE durante o período letivo analisado. Desta forma, percebeu-se a necessidade
de uma medida de confiança para a predição realizada pelo comitê de preditores simples do
módulo APE. Valeu-se, então, das técnicas de medição da utilização do SAE apresentadas em
![Referências técnicas para atuação de psicólogas(os) em Programas de Atenção à Mulher em situação de Violência [2013] - CREPOP CREPOP](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACH5BAEAAAAALAAAAAABAAEAAAICRAEAOw==)