Catia Craveiro Pires
Texto
Imagem



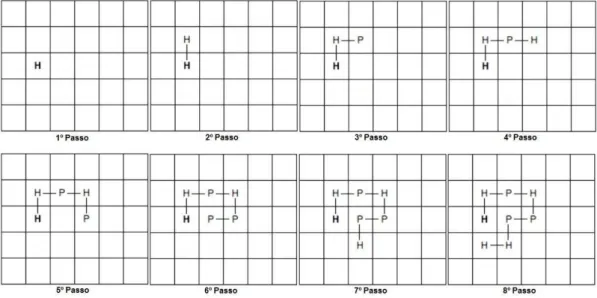
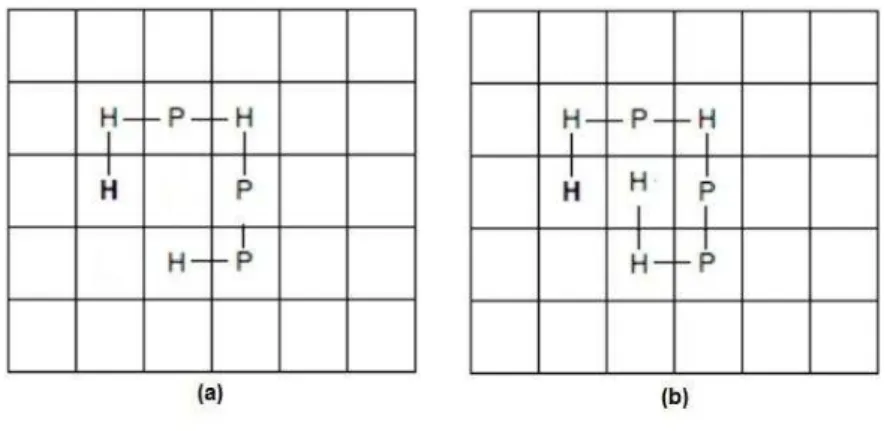





Documentos relacionados
O romance Usina, diferentemente dos demais do conjunto da obra pertencente ao ciclo-da-cana-de-açúcar, talvez em função do contexto histórico em que se insere, não
Embora acreditemos não ser esse o critério mais adequado para a seleção dos professores de Sociologia (ou de qualquer outra disciplina), cabe ressaltar que o Conselho
Atualmente os currículos em ensino de ciências sinalizam que os conteúdos difundidos em sala de aula devem proporcionar ao educando o desenvolvimento de competências e habilidades
O objetivo deste artigo é justamente abordar uma metodologia alternativa para a elaboração de análises contábeis e financeiras, denominada de balanço perguntado e
A psicanálise foi acusada de normatizadora (FOUCAULT, 1996) por haver mantido o modelo familiar burguês nuclear como o centro de sua teoria como é manifestado
a) teste de germinação: as sementes foram distribuídas sobre papel toalha umedecidos com água destilada (testemunha) e sete soluções de NaCl na quantidade
A questão das quotas estará sempre na ordem do dia, porquanto constitui-se como motivo central de discórdia (Vaz, 2008) razão pela qual o desafio principal da administração pública
Para eficiência biológica, de forma geral, utiliza-se a comparação de produtividades entre sistemas (monocultivo e cultivo consorciado), sendo avaliados a partir de
