i
Criação de Clusters dos Clientes de uma Empresa
de Logística e Distribuição Alimentar recorrendo
ao Self-Organizing Map
Marta Isabel Correia da Silva
Influência da Criação de Clusters em toda a cadeia de
Supply Chain
Trabalho de Projeto apresentado como requisito parcial para
obtenção do grau de Mestre em Gestão de Informação
i
Título: Criação de Cluster dos Clientes de Uma empresa de Logística e Distribuição Alimentar Recorrendo ao Self-Organizing Maps
Subtítulo: Influência da criação de Clusters em toda a cadeia de Supply chain
Marta Isabel Correia da Silva
MGI
201
ii
NOVA Information Management School
Instituto Superior de Estatística e Gestão de Informação
Universidade Nova de Lisboa
CRIAÇÃO DE CLUSTERS DOS CLIENTES DE UMA EMPRESA DE
LOGÍSTICA E DISTRIBUIÇÃO ALIMENTAR RECORRENDO AO
SELF-ORGANIZING MAP
INFLUÊNCIA DA CRIAÇÃO DE CLUSTERS EM TODA A CADEIA DE SUPPLY CHAIN
Por
Marta Isabel Correia da Silva
Trabalho de Projeto apresentado como requisito parcial para a obtenção do grau de Mestre em Gestão de Informação, Especialização em Gestão do Conhecimento e Business Intelligence
Orientador/Coorientador: Roberto Henriques, PhD
iii
iv
AGRADECIMENTOS
Antes de mais, gostaria de agradecer ao Sr. José Cruz por ter-me concedido a autorização para analisar os dados da sua empresa, sem isso muito provavelmente, este mestrado não chegaria ao fim. Em segundo lugar gostaria de agradecer ao meu coordenador, Professor Roberto Henriques, que decidiu acreditar em mim e, aceitou continuar a ser o meu coordenador, mesmo sabendo que eu tinha decidido mudar de projeto e de pais.
v
RESUMO
O aumento do tamanho e da dimensionalidade dos repositórios de dados, obriga a que as empresas se adaptem às novas tecnologias e criem novas formas de análise de dados. O clustering é uma das formas mais importantes e provavelmente mais popular de análise de dados. Ao longo deste projeto o clustering será explorado recorrendo ao Self-Organizing Map.
Este trabalho irá debruçar-se essencialmente na criação dos clusters dos clientes de uma empresa de logística e distribuição alimentar. O segundo objetivo deste trabalho projeto prende-se a com as conclusões que se podem tirar a partir dos clusters obtidos, isto é, baseado nos diferentes perfis de clientes criados, pretende-se analisar se, é possível melhorar a gestão de stocks, melhorar a estratégia de marketing, antever alguns imprevistos e melhorar a cadeia de supply chain onde a empresa se encontra inserida.
Neste âmbito, foi possível concluir que o SOM, é uma ferramenta adequada, para a sua implementação na empresa, uma vez que foi possível diminuir a dimensionalidade e gerar os diferentes grupos de clientes. Com base nestes resultados, concluiu-se que seria possível melhorar a gestão de stocks da empresa e melhorar a estratégia de marketing.
Relativamente a toda a cadeia de supply chain onde a empresa se encontra inserida, também esta, será influenciada, uma vez que ao melhorar a gestão de stocks, e aumentando as vendas recorrendo a estratégias de marketing mais eficientes, todos os elementos da cadeia de supply chain sairão beneficiados.
PALAVRAS-CHAVE
Redes Neuronais Artificiais 1; Self-Organizing Map 2; Clustering 3; Supply Chain 4; logística e Distribuição Alimentar 5; Segmentação de Clientes 6; Gestão de Stocks 7
vi
ABSTRACT
Increasing the size and dimensionality of data repositories, forces companies to adapt to new technologies and create new ways of data analysis. Data clustering is one of the most important and probably most popular forms of data analysis. Throughout this project, data clustering will be explored using the Self-Organizing Maps.
This project will focus essentially on the creation of client clusters of a food logistics and distribution company. The second objective is the conclusions that can be drawn from the clusters obtained based on the consumptions of the clients, we intend to analyse if it is possible to improve the stock management, to improve the strategy of marketing, anticipate some unexpected events and improve the supply chain where the company is inserted.
In this context, it was possible to conclude that the SOM is an appropriate tool for its implementation in the company, since it was possible to decrease dimensionality and generate the groups of clients. Based on these results, it was concluded that it would be possible to improve the company's stock management and improve the marketing strategy.
Regarding the entire chain of supply chain where the company is inserted, this will also be influenced, since by improving the management of stocks, and increasing sales using more efficient marketing strategies, all elements of the chain of supply chain will benefit.
KEYWORDS
Artificial Neural Network 1; Self-Organizing Map 2; Clustering 3; Supply Chain 4; Logistics and Food Distribution 5; Customer Segmentation 6; Inventory Management 7
vii
ÍNDICE
1.
Introdução ... 1
1.1.
Enquadramento ... 1
1.1.1.
Logística e Distribuição Alimentar ... 2
1.1.2.
Empresa em Análise ... 2
1.2.
Objetivos do Estudo ... 2
1.3.
Motivação ... 3
1.4.
Formulação das Questões ... 3
1.5.
Organização do Trabalho de Projeto ... 4
2.
Revisão da Literatura ... 5
2.1.
Contextualização ... 5
2.2.
Redes Neuronais Artificiais ... 6
2.2.1.
Self-Organizing Maps (SOM) ... 6
3.
Metodologia ... 12
3.1.
Extração e pré-processamento dos dados ... 13
3.1.1.
Extração da Base de dados ... 13
3.1.2.
Análise descritiva das Variáveis Iniciais ... 14
3.1.3.
Preparação e pré- processamento dos dados ... 14
3.1.4.
Escolha das variáveis finais ... 17
4.
AnÁlise dos resultados ... 19
4.1.
Segmentação por Produto ... 19
4.2.
Segmentação por Valor ... 23
4.1.
Concatenação das segmentações por valor e por produto ... 26
5.
Discussão dos resultados Obtidos ... 30
5.1.
Segmentação por Produto, Por valor, e Influência de cada um destes segmentos na
segmentação final ... 30
5.2.
Influência dos Resultados obtidos, na gestão de stocks da Empresa ... 34
5.3.
Influência dos Resultados obtidos na estratégia de Marketing ... 35
5.4.
Influência dos resultados obtidos em toda a cadeia de Suply-CHain ... 35
5.5.
Respostas as questões iniciais ... 36
6.
Conclusões ... 37
7.
Limitações e Recomendações para Trabalhos Futuros ... 39
8.
Bibliografia ... 40
viii
ÍNDICE DE FIGURAS
Figura 1- Circuito longo de distribuição alimentar (Santos, 2014). ... 2
Figura 2 - Espaço de output a duas dimensões e espaço de input a três dimensões (Henriques,
R., 2010) ... 7
Figura 3 - Fase de Treino do SOM (Henriques, R., 2010) ... 8
Figura 4 - Processo desdobramento e ajuste fino do SOM (Bação, F., 2014). ... 8
Figura 5 - Tipologia Som: a) Topologia quadrada, com quatro vizinhos b) tipologia hexagonal
com 6 vizinhos. Adaptado de (Henriques, R., 2010) ... 9
Figura 6 - Metodologia do Trabalho Projeto ... 12
Figura 7 - Gráfico de componentes planas para as variáveis SumIncome e SumQuantity ... 17
Figura 8- Matriz U, com os 5 clusters gerados a partir do SOM ... 19
Figura 9 - Mapa de coordenadas paralelas cluster 1, segmentação por produto. ... 21
Figura 10 - Mapa de coordenadas paralelas cluster 2, segmentação por produto. ... 21
Figura 11 - Mapa de coordenadas paralelas cluster 3, segmentação por produto. ... 22
Figura 12 - Mapa de coordenadas paralelas cluster 4, segmentação por produto. ... 22
Figura 13 - Mapa de coordenadas paralelas cluster 5, segmentação por produto. ... 23
Figura 14 - Matriz U, com os 4 clusters gerados a partir do SOM. ... 23
Figura 15 - Mapa de coordenadas paralelas cluster 1, segmentação por valor. ... 24
Figura 16 – Mapa de coordenadas paralelas cluster 2, segmentação por valor. ... 25
Figura 17 – Mapa de coordenadas paralelas cluster 3, segmentação por valor. ... 25
Figura 18 - Mapa de coordenadas paralelas cluster 4, segmentação por valor. ... 25
Figura 19 – Concatenação dos clusters das segmentações por produto e por valor. ... 26
Figura 20 - Concatenação da segmentação por produto e por valor, cluster 1. ... 27
Figura 21 - Concatenação da segmentação por produto e por valor, cluster2. ... 27
Figura 22 - Concatenação da segmentação por produto e por valor, cluster 3. ... 28
Figura 23 - Concatenação da segmentação por produto e por valor, cluster 4. ... 28
Figura 24 - Concatenação da segmentação por produto e por valor, cluster5 ... 29
Figura 25 - Classificação dos clientes da empresa ... 30
Figura 26 - Quadro resumo da segmentação por produto ... 31
Figura 27 - Quadro resumo da segmentação por valor ... 31
Figura 28 - Quadro resumo concatenação da segmentação por produto e por valor ... 32
Figura 29- Influência dos clusters por produto, na segmentação final (%) ... 32
Figura 30- Influência dos clusters por valor, na segmentação final (%) ... 32
Figura 31 - Influência das segmentações por produto e por valor, no cluster 1 da segmentação
final. ... 32
ix
Figura 32 - Influência das segmentações por produto e por valor, no cluster 2 da segmentação
final. ... 32
Figura 33 - Influência das segmentações por produto e por valor, no cluster 3 da segmentação
final. ... 33
Figura 34 -Influência das segmentações por produto e por valor, no cluster 4 da segmentação
final. ... 33
Figura 35 - Influência das segmentações por produto e por valor, no cluster 5 da segmentação
final. ... 33
Figura 36 - Resumo simplificado da melhoria da cadeia de Supply Chain ... 35
x
ÍNDICE DE TABELAS
Tabela 1 - Algumas abordagens de clustering ao longo da literatura - adaptado de
(Chattopadhyay, Sengupta, & Sahay, 2016) ... 10
Tabela 2- Descrição das variáveis Iniciais ... 14
Tabela 3- Estatísticas das variáveis intervalares ... 14
Tabela 4 - Estatísticas intervalares após aplicado o filtro ... 15
Tabela 5 – Tabela descritiva das variáveis criadas ... 17
Tabela 6 - Variáveis finais escolhidas ... 18
Tabela 7 – Médias das variáveis dos 5 clusters gerados pelo SOM. ... 20
Tabela 8 - Média das variáveis dos 4 clusters gerados pelo SOM ... 24
xi
LISTA DE SIGLAS E ABREVIATURAS
ANN Artificial Neural Network
BMU Best Matching Unit
CFPR Collaborative Forecasting Planning & Replenishment
SOM Self-Organizing Maps
1
1. INTRODUÇÃO
“Clustering constitutes one of the most popular and important tasks in data analysis. This is true for
any type of data” (Henriques et al., 2012).
Com a evolução das tecnologias de informação, associado ao aumento do tamanho e da dimensionalidade dos repositórios de dados os métodos estatísticos utilizados para sintetizar os dados deixam progressivamente de conseguir responder às necessidades do utilizador (Henriques, R., 2010). Infelizmente esta coleta de grandes quantidades de dados não significa uma maior extração do conhecimento. Existe a necessidade de analisar estes dados e transformá-los em conhecimento, em tempo útil. A vasta quantidade de dados, associadas às ineficientes técnicas estatísticas tradicionais (ou ferramentas de segmentação orientadas para as estatísticas), estimularam a que os investigadores encontrassem novos métodos de análise. A utilização de técnicas de Data Mining poderá ser a solução para este problema. Uma das técnicas de Data Mining, que poderá ser a resposta a este problema é o
Self-Organizing Map (SOM).
O SOM é uma técnica bastante utilizada em redução de dimensionalidade, classificação e amostragem (Bação, F., 2014). Ao logo deste trabalho de projeto o SOM será explorado como ferramenta de
Clustering.
Este capítulo está organizado em 5 subcapítulos. No subcapítulo 1.1 é feito um pequeno enquadramento do trabalho projeto, a apresentação da empresa e uma pequena descrição de logística e distribuição alimentar. No Subcapítulo 1.2 será descrito o objetivo do estudo, seguido do subcapítulo 1.3 referente à motivação que levou à concretização deste trabalho, no subcapítulo 1.4 encontra-se a formulação das questões e o capítulo 1.5 corresponde à organização do trabalho de projeto.
1.1. E
NQUADRAMENTO“Logistics Management is that part of Supply Chain Management that plans, implements, and controls the efficient, effective forward and reverse flow and storage of goods, services and related
information between the point of origin and the point of consumption in order to meet customer’s requirements” (Lambert, D., 2008)
Understanding downstream demand is prerequisite to accomplishing the overall supply chain objective. (Carbonneau, Laframboise, & Vahidov, 2008)
A gestão de uma cadeia de suprimentos de negócios é um processo extremamente abrangente e complexo, aumentando as dificuldades na fase de logística e distribuição alimentar, devido às dificuldades não só de manter a qualidade do produto, como entregá-lo no tempo adequado. Inúmeros fatores podem influenciar o processo de logística e distribuição alimentar, pelo que, todas as tarefas que possam antever a parte da procura, irão certamente melhorar toda a cadeia de suprimentos.
2
1.1.1. Logística e Distribuição Alimentar
Existe ao longo da literatura vários conceitos para distribuidor e distribuição. Segundo Leal (2006) o distribuidor é a empresa transportadora que vende em grandes quantidades, relativamente a distribuição, de acordo com Cotta (1978), a distribuição corresponde ao processo que permite eliminar a distância física entre a fase final de produção e o local onde existe a procura.
Já Rousseau (2008), defende um conceito de distribuição um pouco mais abrangente, sendo que, a distribuição corresponde ao “conjunto de todas as entidades singulares ou coletivas que, através de múltiplas transações comerciais e operações logísticas, desde a fase de produção até à fase de consumo, colocam produtos ou prestam serviços, nas condições de tempo, lugar e do modo mais conveniente para satisfazer as necessidades dos consumidores” (Santos, 2014).
De acordo com Christhopher (2017), logística é o processo de gerenciamento estratégico da compra, do transporte e de armazenamento de matérias-primas, parte e produtos acabados (além dos fluxos de informação relacionados) por parte da organização e de seus canais de marketing, de tal modo que a lucratividade atual e futura sejam maximizadas mediante a entrega de encomendas com o menor custo associado.
No mercado competitivo atual, no qual os consumidores são cada vez mais exigentes na qualidade, disponibilidade, preço, e menos fiéis ás marcas, os produtos apenas possuem valor se puderem ser adquiridos no tempo e lugar que o consumidor pretende (Maekin, 1971).
1.1.2. Empresa em Análise
A empresa em análise, corresponde ao distribuidor em grosso e é responsável pelo processo logístico do produto desde que este sai do produtor até chegar ao retalhista. É possível observar pela figura 1, o circuito de distribuição alimentar, referente à empresa em estudo.
Figura 1- Circuito longo de distribuição alimentar (Santos, 2014).
A empresa em questão, adquire o produto diretamente aos produtores que se encontram em Portugal, no Brasil e em Espanha, e é a responsável por todo o transporte dos bens alimentares até ao Reino Unido. Quando os produtos alimentares se encontram no Reino Unido, é a responsável pela distribuição dos bens alimentares a um conjunto de restaurantes, pequenas mercearias e algumas superfícies de grande retalho.
1.2. O
BJETIVOS DOE
STUDOO clustering de clientes permite criar grupos homogéneos, de acordo com as suas características em comum. Porém, os resultados da segmentação, poderão ser usados de uma forma transversal, de forma a melhorar vários departamentos dentro de uma empresa.
Neste contexto este trabalho de projeto surge da dificuldade que a empresa tem sentido em gerir a relação com os seus clientes e na necessidade de os fidelizar. Um dos problemas que tem sobressaído
3 na empresa, é o facto de não conseguir prever a demanda por parte do cliente e deste modo, nem sempre as quantidades dos stocks conseguem satisfazer a necessidade dos mesmos.
Se por um lado, é importante integrar novas estratégias de marketing para conquistar novos mercados, por outro lado não é menos importante a fidelização dos clientes antigos, através do reforço da confiança na empresa. Uma forma de reforço da confiança por parte dos clientes é através da atualização constante dos stocks respondendo sempre a demanda do cliente.
Posto isto, este trabalho tem dois objetivos fundamentais: o primeiro consiste na criação dos clusters dos clientes da empresa, recorrendo ao SOM, de forma a definir perfis de cliente o que permite prever a demanda e antecipar as necessidades dos clientes de acordo com as suas preferências pelos produtos fornecidos.
O segundo objetivo prende-se com a conclusão que se pode tirar dos clusters obtidos, isto é, analisar se com a criação dos clusters será possível melhorar a gestão de stocks, melhorar a estratégia de marketing, antever alguns imprevistos e melhorar a cadeia de supply chain onde a empresa se encontra inserida.
1.3. M
OTIVAÇÃODesde julho de 2017, sou técnica de Marketing na empresa em análise e devido á minha inexperiência, é comum surgirem dúvidas, nomeadamente de como direcionar as campanhas de marketing, como extrair e tratar os dados, ou retirar informações valiosas da informação analisada. Dada a alta competitividade no mundo da distribuição alimentar, a empresa em questão, depara-se com as dificuldades de extrair conhecimento a partir da base de dados existente e conquistar a sua liderança neste sector. Com o crescimento, com o qual a empresa se deparou nos últimos anos, as ferramentas tecnológicas existentes na empresa deixaram de ser eficientes havendo a necessidade de inovar, e criar métodos para extração do conhecimento. Além disto, deparamo-nos diariamente, com uma gestão de stocks ineficiente, o que afeta diretamente as campanhas de marketing. Sabendo que o SOM, é “one of the best-known unsupervised-learning neural network” (Kohonen, T., 1982), acredito que a implementação do SOM na empresa seria uma mais valia.
Posto isto, e de forma a especializar-me numa das ferramentas de análise de elevada dimensão e de visualização (Kohonen, T., 1982), optei por utilizar os dados da empresa, para elaboração deste projeto, pois são dados com o qual me encontro bastante familiarizada.
Dado o pequeno leque de clientes fidelizados à empresa, as análises irão incidir em todos os clientes (ativos e não ativos), que fornecemos nos últimos 6 anos. Têm sido desenvolvidas estratégias de recuperação de clientes, pelo que será bastante valioso saber o valor que cada um dos clientes inativos representou para a empresa. De forma a não perder os clientes atuais da empresa, é bastante importante desenvolver estratégias para manter a satisfação dos clientes ativos atuais. No âmbito deste trabalho projeto, uma dessas estratégias, passa por, criar perfis de consumo dos clientes, de forma a antever a procura por parte do cliente, garantindo sempre os produtos que este procura.
1.4. F
ORMULAÇÃO DASQ
UESTÕES4 • O clustering recorrendo ao SOM, será uma boa solução para a empresa, quando comparado
com os métodos existentes atualmente na empesa?
• Poderão os clusters de clientes, influenciar de forma positiva a gestão de stocks, ao mesmo tempo que melhora a estratégia de marketing?
• Poderá o clustering dos clientes finais, influenciar toda a cadeia de supply chain?
1.5. O
RGANIZAÇÃO DOT
RABALHO DEP
ROJETOA organização deste trabalho de projeto é feita do seguinte modo:
Capítulo 1 - Corresponde a um capítulo introdutório, onde é feito um breve enquadramento do
trabalho projeto e da área de atuação da empresa em análise, são definidos os objetivos do trabalho, a motivação e a formulação das questões.
Capítulo 2 - Este capítulo corresponde à revisão da literatura, aqui são abordados alguns conceitos de
supply chain e do método de análise que será utilizado, o self-organizing maps.
Capítulo 3 - Corresponde a metodologia de investigação utilizada ao longo do trabalho de projeto e
apresenta o modo como se procedeu a análise exploratória dos dados.
Capítulo 4 - Neste capítulo será documentada a parte prática do trabalho de projeto. Capítulo 5 - É neste capítulo onde é feita a discussão final dos resultados obtidos.
Capítulo 6 – Ao longo deste capítulo serão realizadas as principais conclusões deste projeto.
Capítulo 7 - Expõe as limitações encontradas ao longo do trabalho projeto e sugere recomendações
para futuras pesquisas.
Capítulo 8- Apresentação da bibliografia do trabalho projeto Capítulo 9 – Anexos de consulta facultativa
O próximo capítulo, corresponde a revisão da literatura, é onde, como foi mencionado anteriormente, serão abordados os conceitos teóricos necessários para o desenvolvimento deste trabalho projeto.
5
2. REVISÃO DA LITERATURA
O self-organizing maps, é parte de um grupo de técnicas conhecidas como redes neuronais artificiais (RNAS), também conhecidas como redes neuronais computacionais. Estas, tem uma reputação de desempenho surpreendentemente bom (Agarwal, P., Skuping, A., 2008).
Este capítulo é composto por 3 subcapítulos: em 2.1 é feita uma contextualização, começando por abordar alguns conceitos de supply chain, assim como duas estratégias para melhorar a cadeia de supply chain, de seguida no capítulo 2.2 é explorado o conceito de redes neuronais, no qual se enquadra o self-organizing maps. Dentro da temática de SOM, é ainda abordada a parametrização em SOM, e o self-organizing maps na análise de clustering. Por fim, no capítulo 2.3 é feito um balanço final da literatura, com as principais vantagens do SOM.
2.1. C
ONTEXTUALIZAÇÃOO objetivo geral de uma cadeia de suprimentos (supply chain) é transportar materiais ou produtos, agregar valor e satisfazer a demanda de cada etapa do processo (Janvier-James, 2012). Face a concorrência, e a competitividade do mundo global, surge a necessidade de identificar, melhor as necessidades dos clientes, perceber os seus perfis de consumo, e antecipar as suas exigências. Um distribuidor, já não realiza apenas as atividades de distribuição de produtos, mas torna-se o responsável pelo aconselhamento e consultoria de produto. Collaborative Forecasting Planning & Replenishment (CFPR) e Vendor Managed Invetory (VMI) são duas estratégias em que a responsabilidade de previsão é transferida para o fornecedor (Matthias, H., 2005, Murray, P., Agard, B., Barajas, 2015).
Collaborative Forecasting Planning & Replenishment (CFPR)
De forma a melhorar a competitividade no mercado, é imprescindível a comunicação entre os membros da cadeia de suprimentos (Vachon, S., Halley, A., Beaulieu, 2009). As informações a jusante são transmitidas de cliente para fornecedor através de uma variedade de formas, nomeadamente troca eletrónica de dados, previsões e interação entre o os elementos da cadeia de suprimentos. A colaboração é a chave para o sucesso CFPR. Embora a revisão da literatura, mostre que CFPR tem inúmeros benefícios, a realidade é que na prática a colaboração não prevalece (Matthias, H., 2005). Um fator que inibe o CFPR é a falta de tecnologia de informação com suficiente sofisticação para permitir o compartilhamento de dados entre os membros da cadeia. Um outro fator bastante significativo do CFPR, é a confiança e as relações pessoais entre o pessoal das organizações parceiras (Wanga, Zhiqiang, Ye, 2014). A ausência de relações de confiança dificulta o compartilhamento de informações (Murray, P., Agard, B., Barajas, 2015).
Vendor Managed Inventory (VMI)
No caso da VMI, a responsabilidade pela previsão corresponde inteiramente ao fornecedor. Idealmente, o fornecedor em uma estratégia VMI tem acesso a fontes de informação a jusante, incluindo taxas de consumo, níveis de inventário e previsões (Achabal, D., 2000). Segundo (Achabal, D., 2000) e (Jung, S., 2005) as estratégias da VMI são eficazes para aumentar a eficiência da cadeia de abastecimento, reduzindo custos globais e aumentando a competitividade da cadeia de suprimentos.
6 Embora haja uma ligação direta entre a performance da cadeia de suprimentos e o compartilhamento de informações (Forslund, H., & Jonsson, P., 2007), os parceiros muitas vezes não estão dispostos a partilhar a informação ou então não estão autorizados (Kembro, J. & Näslund, 2014). (Matthias, H., 2005).
Fazer uma previsão de stocks, é uma tarefa árdua, nem sempre os membros da cadeia de abastecimento a jusante compartilham a informação necessária, para apoiar a construção da previsão (Matthias, H., 2005). O compartilhamento de informações entre os membros da cadeia de suprimentos pode ser dificultado por uma relutância geral ou incapacidade dos parceiros da cadeia de suprimentos para compartilhar dados de previsão (Kembro, J. & Näslund, 2014). Também fatores externos, como aprisionamento de stocks nas fronteiras, mudanças atmosféricas ou acidentes de aviação poderão dificultar a previsão de stocks.
Esta contextualização, surge precisamente das dificuldades com que a empresa se depara, no dia-a-dia para realizar a previsão de stocks, e manter sempre os stocks atualizados de forma a fornecer aos seus clientes os produtos que estes procuram.
Neste trabalho de projeto irão ser aplicadas técnicas de data mining, mais propriamente o
self-organizing maps para identificar segmentos de clientes com os mesmos padrões de comportamento
pela parte da procura. Uma vez que os segmentos se encontrem identificados, será possível detetar padrões de consumo, antecipar encomendas, o que irá influenciar diretamente as encomendas feitas ao fornecedor, melhorar o target em marketing o que irá influenciar toda a cadeia de supply chain.
2.2. R
EDESN
EURONAISA
RTIFICIAISAs redes Neuronais Artificiais baseiam-se no princípio básico de funcionamento do cérebro, em que pequenos neurónios, interconectados, comunicam entre si, através de sinapses, transmitindo e processando informação, de forma a resolver o problema mais complicado, da forma mais rápida possível (Henriques, R., 2010). A estrutura geral de um ANN consiste em um conjunto de nós de input e um conjunto de nós de output, interconectados entre si. Estes também podem ser conhecidos como neurónios ou unidades. Os dados multivariados apresentados aos nós de input são processados de modo a que os nós de output sejam ativados de acordo com pesos associados a cada ligação recebida. O sucesso do treino da rede neuronal está em grande parte relacionado com a definição correta desses pesos (Agarwal, P., Skuping, A., 2008).
Existem dois tipos de redes neuronais: as redes supervisionadas, em que é necessário orientar o processo de aprendizagem, dando um output ou target, e as redes não supervisionadas como é o caso do self-organizing maps em que não é necessário definir qualquer target ou output (Kohonen, 1990, Bação, F., 2014).
2.2.1. Self-Organizing Maps (SOM)
A principal referência do self-organizing maps é Teuvo Kohonenn, que foi o inventor deste tipo de rede neuronal em 1982 (Kohonen, T., 1982).
A ideia básica do SOM, segundo Kohonen, é o mapeamento de dados com elevada dimensionalidade em uma ou duas dimensões, mantendo as relações topológicas entre os padrões dos dados (Henriques, R., 2010). Esquematicamente o SOM pode ser visto como uma matriz de unidades
7 (neurónios), também designados por mapa topológico ou espaço de output (Bação, F., 2014). O espaço de output geralmente é bidimensional, podendo ser representado por uma camada em forma retangular ou hexagonal. A maior vantagem do SOM é o facto de permitir ter uma ideia geral da estrutura dos dados, observando o gráfico de dados. O SOM pode ter dimensionalidade n, no entanto, devido as questões relacionadas com a possibilidade de visualização do espaço de output, os mais frequentes são os SOM 2D e 1D.
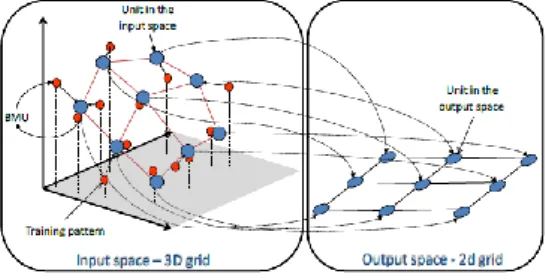
Na figura abaixo, é possível observar um exemplo de um SOM de duas dimensões com 3 x 3 unidades adaptado de um conjunto de dados tridimensional. Cada uma das unidades do SOM, corresponde a um vetor de valores. A camada de input, corresponde ao espaço original, onde se encontram os padrões de dados, em oposição tem-se o espaço de output. (Henriques, R., 2010)
Figura 2 - Espaço de output a duas dimensões e espaço de input a três dimensões (Henriques, R., 2010)
Os círculos a azul representam as unidades do SOM enquanto que os círculos a vermelho correspondem aos padrões de Input.
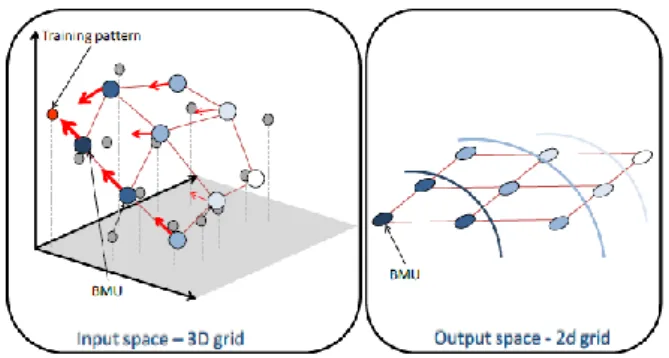
Antes de iniciar a fase de treino, são gerados aleatoriamente os vetores que definem cada unidade de SOM (Bação, F., 2014). Durante a fase de treino, um determinado padrão de treino x é apresentado a rede (Henriques, R., 2010), procedendo-se de seguida à avaliação das distancias entre o padrão de treino e todas as unidades da rede, sendo que a unidade mais próxima ganha a representação do individuo, esta unidade tem o nome de Best-Matching UnIit (BMU) (Bação, F., 2014). Os valores vetoriais da unidade e da vizinhança são então modificados para aproximar-se do padrão de dados x, de acordo com a função:
𝑚𝑖 = 𝑚𝑖 + 𝑎(𝑡)ℎ𝑐𝑖(𝑡)(𝑥 − 𝑚𝑖)
Equação iOnde
𝑎(𝑡)
é a taxa de aprendizagem no tempo t, e hci(t) é a função vizinhança centrada em c, em que i identifica cada unidade (Henriques, R., 2010).A Figura 3 mostra uma iteração da fase de treino SOM, onde um padrão de treinamento (ponto vermelho) é apresentado à rede e a unidade mais próxima é selecionada (BMU).
8 Figura 3 - Fase de Treino do SOM (Henriques, R., 2010)
Dependendo da taxa de aprendizagem, essa unidade move-se em direção ao padrão de input (representado pela seta vermelha). A taxa de aprendizagem define a magnitude da aproximação, isto é, se a taxa de aprendizagem, for elevada então a unidade mover-se à bastante em direção ao objeto, se pelo contrário a taxa de aprendizagem for próxima de zero, então a unidade permanecerá exatamente na mesma posição. Com base na BMU e na função de vizinhança, o espaço vizinhança é selecionado no espaço de output (a intensidade do azul representa o grau de vizinhança). Este espaço vizinhança também será atualizado, embora menos, para o padrão de input.
Ao longo do treino o SOM “preserva a topologia dos dados” isto significa que os objetos (padrão de
input) que se encontram próximos no espaço de input serão mapeados para as unidades próximas, no
espaço de output. Esta diferença entre a posição de um dado padrão de input e a unidade em se encontra mapeada, é designada como erro de quantização.
O processo de treino do SOM é constituído por duas fases: a fase de desdobramento e a fase de ajuste
fino. Durante a primeira fase, as unidades são espalhadas de forma a cobrir o espaço de output, na
fase de afinação o SOM procura que as unidades se aproximem o máximo dos padrões de input que representam, minimizando o erro de quantização. É possível observar na Figura 4 o processo de desdobramento do SOM. Inicialmente as unidades encontram-se todas agrupadas, sendo que, com o decorrer do treino, elas vão-se espalhando por todo o quadrado. Nas ultimas três imagens é possível observar a fase de afinação (Bação, F., 2014).
9
2.2.1.1. Parametrização do SOM
Vários parâmetros que afetam o resultado final, devem ser definidos antes da fase de treino do SOM, estes incluem a definição da estrutura SOM (tamanho, topologia, forma e inicialização do mapa utilizado) e os parâmetros de treino (número de iterações, taxa de aprendizagem inicial, raio vizinhança inicial e o tamanho da rede).
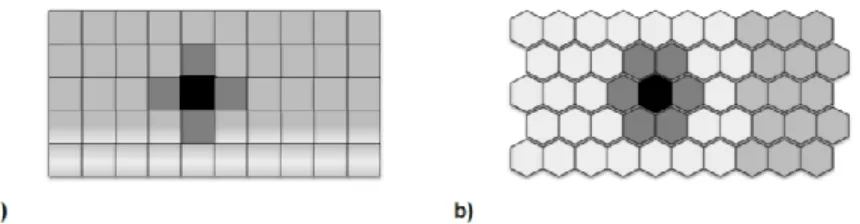
O SOM utiliza principalmente dois tipos de topologia, quadrada e hexagonal (Figura 5). No primeiro caso, cada unidade está conectada aos seus quatro vizinhos (com exceção das unidades de borda). No segundo caso, cada unidade está conectada aos seus seis vizinhos (novamente, com exceção das unidades de borda) (Henriques, R., 2010). Normalmente, é preferida a topologia hexagonal, embora, se o treino for suficientemente longo, o desempenho da rede é independente da topologia usada (Agarwal, P., Skuping, A., 2008).
Figura 5 - Tipologia Som: a) Topologia quadrada, com quatro vizinhos b) tipologia hexagonal com 6 vizinhos. Adaptado de (Henriques, R., 2010)
Algumas considerações ao longo do treino de SOM:
➢ Ambos os parâmetros, raio de vizinhança e taxa de aprendizagem, decrescem ao longo do treino, de forma a garantir a convergência do SOM para uma solução ótima (ou semi-ótima). De forma a que o SOM convirja para uma solução estável, tanto a taxa de aprendizagem como o raio da vizinhança devem convergir para zero (Bação, F., 2014).
➢ O mapeamento em SOM tenta sempre preservar as relações topológicas, ou seja, os padrões que estão próximos no espaço de input serão mapeados para as unidades que estão próximas no espaço de output, e vice-versa. O SOM Preserva a topologia dos dados, dentro do possível, sendo que os vizinhos são preservados durante o processo de mapeamento (Bação, F., 2014).
➢ Independentemente da fase de treino, haverá sempre alguma distância residual entre o padrão de treino e a sua unidade representativa. Esta diferença é conhecida como erro de quantização. Este valor é usado para medir a acurácia da representação dos dados no mapa (Henriques, R., 2010).
➢ O algoritmo de SOM é robusto à presença de outliers.
2.2.1.2. Self-Organizing Maps na Análise de Clusters
A ideia base por trás do agrupamento por clustering é a tentativa de organizar os dados em grupos de acordo com as suas características em comum (Agarwal, P., Skuping, A., 2008). Existem duas formas de utilizar o SOM para fazer a análise de clusters, a primeira consiste em utilizar um SOM com muitas unidades e com base na informação da Matriz-U, proceder ao agrupamento das unidades mais
10 próximas num único (Miranda, H., Henriques, R., 2013). A segunda consiste na utilização de um SOM pequeno, e realiza-se o agrupamento com o número de unidades semelhante ao número de clusters pretendidos. (Bação, F., 2014). O clusterig envolve a busca de estruturas e o agrupamento, e não deve ser confundido com classificação, que classifica itens desconhecidos em categorias previamente definidas. (Agarwal, P., Skuping, A., 2008). O clustering é provavelmente a interpretação e implementação mais frequentes do método de SOM, porém é útil compará-lo com algumas das abordagens mais populares, nomeadamente o agrupamento hierárquico e o k-means. Para uma leitura mais aprofundada de várias técnicas de agrupamento consultar por exemplo: (Sneath, P. H. A., and R. R. Sokal., 1973). A diferença mais importante entre o SOM e o k-means, traduz-se na influência que as unidades exercem sobre as posições dos seus vizinhos. Enquanto que no k-means, o movimento dos centroides são independentes entre si, no SOM as unidades encontram-se ligadas entre si, no espaço de output. Esta particularidade do SOM impõe uma ordenação às unidades que não existe em outros métodos. O SOM, pode ser utilizado como um substituto do K-means, sendo que, para um número pequeno de clusters, é aconselhado utilizar um SOM 1d. Regra geral os resultados do SOM, são bastante mais fiáveis e robustos do que os obtidos pelo algoritmo k-means. Ao contrário do k-means, no SOM os ótimos locais são menos prováveis, a inicialização não é tão determinante na qualidade dos resultados e os outliers não condicionam o algoritmo de forma tão decisiva (Hajek, P., Henriques, R., Hajkova, V.,2014)
Existe ao longo da literatura, vários exemplos da utilização de segmentação por cluster:
➢ No trabalho apresentado em (A. Seret, T. Verbraken, 2014), foi utilizado o SOM para determinar a priori, os números de clusters, e o ponto de partida, para realizar uma segmentação de mercado, com o objetivo de aplicar ao marketing direto.
➢ Yu, G., Wang, S., Liang, Y. e Chen (2009) aplicaram o algoritmo de self-organizing maps para agregar em clusters, vários clientes de uma cadeia de suprimentos eletrónicos.
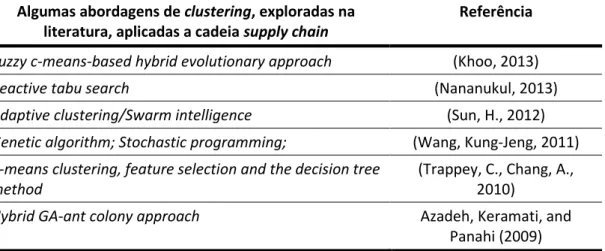
➢ Azadeh, A. e A. Keramati (2009) utilizaram o algoritmo de SOM, para conferir e analisar dados de 90 empresas, da cadeia de suprimentos, e agrupar em um único problema de clustering. É possível observar na tabela 1 várias técnicas de clustering, exploradas ao longo da literatura, aplicadas para a resolução de problemas na cadeia de supply chain.
Algumas abordagens de clustering, exploradas na literatura, aplicadas a cadeia supply chain
Referência
Fuzzy c-means-based hybrid evolutionary approach (Khoo, 2013)
Reactive tabu search (Nananukul, 2013)
Adaptive clustering/Swarm intelligence (Sun, H., 2012)
Genetic algorithm; Stochastic programming; (Wang, Kung-Jeng, 2011)
K-means clustering, feature selection and the decision tree method
(Trappey, C., Chang, A., 2010)
Hybrid GA-ant colony approach Azadeh, Keramati, and
Panahi (2009)
Tabela 1 - Algumas abordagens de clustering ao longo da literatura - adaptado de (Chattopadhyay, Sengupta, & Sahay, 2016)
11 Segundo Chattopadhyay, et al. (2016), a literatura não encontra uma solução adequada para a integração da cadeia de valor de diferentes funções que possam agregar benefício para a cadeia de suprimentos total a partir de soluções globais ótimas. Para preencher esta lacuna foi explorada em (Chattopadhyay et al., 2016), uma solução efetiva, com um modelo de agrupamento hierárquico visual baseado em SOM.
2.2.1.3. Balanço Final
Este capítulo foi iniciado com uma pequena contextualização, relativamente ao supply chain, uma vez que a empresa em análise, atua na área de logística e distribuição alimentar, e qualquer alteração na sua gestão irá certamente influenciar toda a cadeia de supply chain onde se encontra inserida. De seguida procedeu-se a revisão da literatura das redes neuronais, mais especificamente do self-organizing maps. Por fim, foi caracterizado o SOM, as suas especificidades e procurado na literatura casos em que o SOM tenha sido utilizado para o clustering de dados em supply chain. Foram ainda procuradas outras técnicas de clustering em termo de comparação com o SOM, como é o caso do
k-means.
Sumariamente conclui-se que o SOM possui, entre outras, as seguintes vantagens:
➢ Permite ter uma ideia geral da estrutura dos dados, observando o gráfico de dados; ➢ Capacidade de diminuição do espaço de input;
➢ Redução da dimensionalidade do problema;
➢ Facilidade de visualização da proximidade entre clusters; ➢ Robustez à presença de outliers;
12
3. METODOLOGIA
De forma a atingir os objetivos propostos neste trabalho de projeto, foi estabelecida e seguida uma metodologia de investigação de trabalho.
Figura 6 - Metodologia do Trabalho Projeto A seguir, será analisado detalhadamente cada uma das etapas deste projeto.
➢ 1º fase
O primeiro passo neste trabalho projeto, consistiu numa procura exaustiva sobre o método de SOM e a sua forma de atuação. Baseado nesta procura, foi então decidido o tema final, e planeado o trabalho a desenvolver. Após esta procura exaustiva, e devido a dificuldade em adquirir dados para análise, foi solicitado na empresa onde trabalho, a autorização para a análise dos mesmos, que foi concedida.
➢ 2º fase
A segunda fase e a quarta fase, foram provavelmente as fases mais longas e exaustivas. Como a área de logística e distribuição alimentar e o os conceitos de supply chain são termos novos, que me eram completamente desconhecidos, foi necessários uma grande investigação e um aprofundamento na revisão da literatura. Seguidamente foi então investigado o conceito de SOM.
A revisão da literatura foi feita com base nas pesquisas realizadas nos serviços de documentação Online da Nova IMS, porém grande parte da documentação acabou por ser obtida, recorrendo ao
ScienceDirect, à aquisição de livros e com base nas aulas teóricas dadas em Data Mining.
➢ 3º fase
A terceira fase corresponde a extração de dados a utilizar. Uma vez que a empresa não tem um departamento de IT, a tempo inteiro, foi concedida a mim a autorização para retirar os dados diretamente da base de dados. Esta fase teve a sua complexidade, não existe na empresa uma descrição de variáveis, e a base de dados é constituída por inúmeras tabelas. Foi necessária a investigação de cada uma dessas tabelas até conseguir concentrar todos os dados que pretendia. Foi desenvolvida a query a partir de uma view já existente, e retirados os dados necessários, para a análise pretendida.
➢ 4º fase
A quarta fase correspondeu a uma das fases mais delicadas. O conjunto de dados era muito extenso o que implicou, uma redução da estrutura dos dados, através do agrupamento de algumas variáveis em comum. Este agrupamento foi realizado recorrendo maioritariamente ao Excel e ao software SAS
1º Fase : Preparação • Definição do tema • Planificação do trabalho • Pedido de autorização do dados • Pesquisa exaustiva sobre o tema 2º Fase: Revisão da literatura • Distribuição e Logistica Alimentar • Supply Chain • Redes Neuronais • Self-Organizing Map • Aplicações do clustering ao longo da literatura 3º Fase: Extração e Análise dos Dados a utilizar • Analise da base de dados da Empresa • Extração dos dados
necessários 4º Fase: Tratamento dos Dados • Redução da estrutura de dados • Agrupamento de variáveis • Tratamento de dados. 5º Fase-Desenvolvimento das Análises • Estudo do Software
GeoSom Suite Tool • Desenvolvimento dos clusters 6º Fase-Discussão dos resultados obtidos e conclusões finais
13
Enterprise Miner, para construção de novas variáveis. Também o tratamento de dados foi realizado
com recurso a este software. ➢ 5º fase
Para que a análise de clusters decorresse da forma mais correta possível, foi necessário estudar primeiro o modo de funcionamento do software a utilizar. O software a utilizar é o GeoSom Suite Tool (Henriques, R., Bação, F., Lobo, V., 2011). Após perceber o seu modo de funcionamento, foram criadas as respetivas análises.
➢ 6ºFase
Por último foram realizadas a discussão e as conclusões do trabalho projeto.
De seguida será apresentado, um subcapítulo que engloba o modo como ocorreu a extração dos dados a partir da base de dados, a análise descritiva das variáveis que serão estudadas e as alterações que foram necessárias fazer a toda estrutura de dados.
3.1. E
XTRAÇÃO E PRÉ-
PROCESSAMENTO DOS DADOSEste capítulo é constituído por 4 subcapítulos. No capítulo 3.1.1 é apresentada uma pequena explicação de como foi realizado o processo de extração da base de dados, em 3.1.2 apresenta-se a análise descritiva das variáveis, seguida do capítulo 3.1.3 que corresponde á preparação e pré-processamento dos dados. A preparação e pré-pré-processamento dos dados é ainda constituído por mais dois subcapítulos: em 3.1.3.1 são explicadas as transformações que foram necessárias fazer aos dados, seguido de 3.1.3.2, que corresponde as correlações das variáveis.
Por fim em 3.1.4 é apresentada a escolha das variáveis finais.
3.1.1. Extração da Base de dados
Após a autorização, para a utilização dos dados neste trabalho projeto, procedeu-se a extração dos mesmos. Este processo, não foi fácil. A base de dados da empresa, é bastante extensa, e não existe atualmente uma descrição das variáveis. Pelo que foi necessário percorrer todas as tabelas/views da base de dados até encontrar os dados pretendidos. Após identificadas as tabelas necessárias, foi desenvolvida uma query e extraídos os dados. Foi definido uma análise a 6 anos dos dados da empresa, o que implica mais de um milhão de linhas. Para que os dados fossem exportados da forma mais correta possível, os mesmos foram exportados de acordo com o ano a que pertenciam as compras dos clientes. Começou-se por extrair os dados referentes ao ano de 2011, seguido de 2012, e por aí adiante até 2016. A estrutura da base de dados, não é muito “user friendly”. Os dados encontram-se organizados por invoice ou credit note, revelando que para o mesmo invoice, por exemplo, poderão existir mais de 20 linhas, se o cliente tiver feito uma compra de 20 produto diferentes. De modo a reduzir o número de linhas do problema, e de forma a facilitar a análise dos dados, irão ser excluídas da análise campos como credit notes, que corresponde às devoluções de produtos, Product_name, que corresponde ao nome do produto, e Product_Code, que corresponde a referência do produto, e decidido que o problema irá ser analisado de acordo com a categoria de produto.
14
3.1.2. Análise descritiva das Variáveis Iniciais
Na Tabela 2, é possível observar as 10 diferentes variáveis em estudo. Existiam inicialmente mais variáveis, tais como, UnitSellingPrice, CostPrice, TradingProfit, entre outras, mas devido a sua irrelevância para o trabalho de projeto, foi optado logo inicialmente por excluí-las.
De forma a manter a máxima confidencialidade do cliente, foi optado por criar um ID cliente, em vez de manter o código cliente existente na empresa.
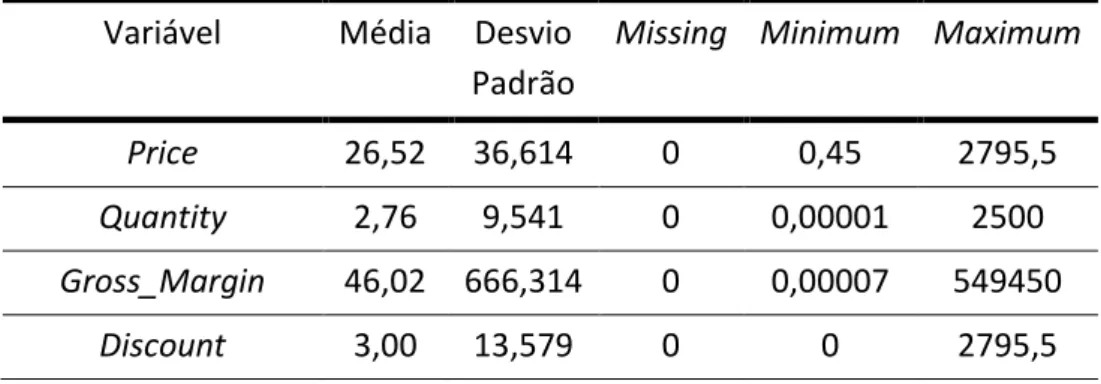
Variáveis Tipo Unidades Descrição
InvoiceNo Ordinal - ID do Invoice
CustomerID Ordinal - ID do Cliente
Category Nominal - Corresponde ao nome de cada
categoria de produto
Price Intervalar £ Valor monetário referente a
cada produto
Quantity Intervalar £ Número de unidades compradas
pelo cliente
Gross_Margin Intervalar £ Margem em grosso para cada
produto
Discount Intervalar £ Desconto por produto em libras
DateCreatedCompany Ordinal Data Data de criação da conta cliente
InvoiceCreditDate Ordinal Data Data da criação do Invoice
PostCode Ordinal - Código postal do Cliente
Tabela 2- Descrição das variáveis Iniciais
3.1.3. Preparação e pré-processamento dos dados
A preparação dos dados consiste na “limpeza” dos dados originais. Inclui procedimentos como a remoção ou não, de dados inconsistentes ou outliers e o tratamento de valores omissos. Este tratamento previne que haja um enviesamento dos resultados do estudo a realizar.
Recorrendo ao SAS Enterprise Miner, é possível observar no nó StateExplorer as estatísticas constantes, conseguindo-se avaliar a relevância de cada uma das variáveis em estudo. Os resultados, para as variáveis intervalares encontram-se expostos na Tabela 3.
Variáveis intervalares
Média Desvio Padrão
Missings Mínimo Máximo
Price 26.6096 36.160 0 0.45 2795.5
Quantity 2.645 8.564 0 -273.855 2500
Gross_Margin 42.816 583.94 0 -5480 549450
Discount 4.1999 13.632 0 -598.499 2795.5
15 É possível observar na tabela 3 a presença de valores negativos para as variáveis Quantity,
Gross_Margin e Discount. Foram analisadas mais profundamente as variáveis com valores negativos,
e procurado saber o porquê destes valores.
Relativamente a variável Quantity, estes valores negativos correspondiam a notas de crédito realizadas ao cliente, pelo que estes valores negativos foram retirados da análise. Ao remover estes valores, a maioria dos valores negativos presentes nas outras variáveis foram também removidos. Estes valores negativos representam uma percentagem muito pequena dos dados totais (-1%).
Após o filtro, é possível observar na tabela 4 os resultados obtidos:
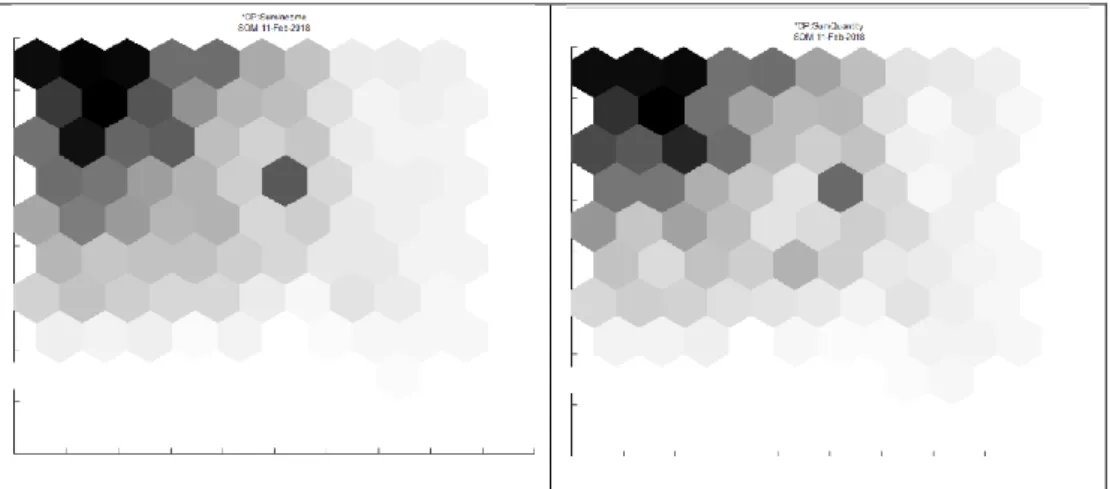
Variável
Média
Desvio
Padrão
Missing
Minimum
Maximum
Price
26,52
36,614
0
0,45
2795,5
Quantity
2,76
9,541
0
0,00001
2500
Gross_Margin
46,02
666,314
0
0,00007
549450
Discount
3,00
13,579
0
0
2795,5
Tabela 4 - Estatísticas intervalares após aplicado o filtro
É possível observar para as variáveis Quantity, ou Gross_Margin, a existência de dados inconsistentes ou incorretos. Quantidades com valores iguais a 0.00001 são claramente um erro de inserção de dados. Estes valores ocorrem maioritariamente para produtos que são vendidos ao quilo como é o caso do queijo ou da charcutaria, no entanto optou-se por manter estes valores na análise, de forma a não excluir outras variáveis que poderão ser de interesse.
Relativamente aos valores de outliers, para as variáveis acima, é possível observar uma elevada discrepância entre os valores máximos e os valores mínimos. Foi criado um gráfico de boxplots para a variável Quantity (anexo 1), e foi possível observar que existe uma maior concentração nos menores valores. Embora existam alguns valores mais elevados, que saiam fora do valor padrão, estes na verdade, não correspondem a outliers e exclui-los significaria excluir os valores que representam maior valor monetário para a empresa, pelo que numa primeira abordagem estes valores não serão excluídos. Estes valores mais elevados correspondem a compras esporádicas, por parte do cliente, maioritariamente de material promocional e cerveja em grandes quantidades. Isto poderá, por exemplo, ocorrer ocasionalmente, para o fornecimento de um evento.
Não existem valores omissos para as variáveis intervalares. Relativamente as variáveis não intervalares, revelaram uma elevada percentagem de valores omissos para as variáveis Post_Code e
DateTime Created. Parte destes valores omissos devem-se sobretudo a clientes da empresa, que não
possuem ficha cliente. Começou-se por aplicar um filtro ao CustomerID e retirar da amostra todos estes clientes que realizam compras, sem criar primeiro uma ficha cliente na empresa. Uma vez que o objetivo final é criar clusters de clientes, não fará sentido manter uma variável que engloba diferentes clientes, dos quais não se detém histórico de dados.
Foram ainda retirados da análise os “Customer ID” de pequenos negócios pertencentes ao mesmo grupo da empresa e que são fornecidos pela empresa em questão.
16 Foi possível observar que os clientes que foram retirados da análise, correspondem aqueles que apresentam maior frequência. Este filtro irá reduzir significativamente os dados a analisar, passando para cerca de 710 00 linhas.
3.1.3.1. Transformação de variáveis
Tendo em conta que um dos objetivos do estudo é a criação de clusters dos clientes, baseado no seu consumo e no valor que representam para a empresa, é de notar que a estrutura da base de dados, não será a melhor para o objetivo proposto. A estrutura atual dos dados não permite visualizar a correlação entre as diferentes categorias de produto, uma vez que estas, se encontram todas na mesma variável “Categoria de Produto”. Outro ponto a ter em conta é as limitações do software. Foram realizadas variadas tentativas, para observação dos dados no software GeoSom Suite (Henriques, R., Bação, F., 2009), porém, a quantidade de dados era muito extensa, pelo que o mesmo não tinha capacidade de resposta. Portanto, foram pensadas em duas alternativas: uma delas seria a construção de uma amostra dos dados da empresa, a outra seria a transformação dos dados. A construção de uma amostra, acabou por ser descartada, pois embora a empresa em análise apresente muitas linhas para análise, o número de clientes, não é muito vasto, cerca de 1500 clientes, pelo que a criação de uma amostra, iria reduzir significativamente o número de clientes.
Posto isto, foi realizado uma transformação aos dados da empresa. Os dados que inicialmente se encontravam em função da Invoice, passaram a encontrar-se em função do cliente. A variável “product_category”, continha cerca de 121 categorias diferentes de produto, de forma a reduzir o número de categorias, foram agrupados na mesma categoria os produtos que apresentam maior similaridade entre si, reduzindo-se desta forma para 20 categorias diferentes. Embora estes agrupamentos, piorem os níveis de detalhe são necessários, para uma análise mais homogénea. Antes de agrupadas as categorias, foi ainda criada uma variável chamada Income, que corresponde ao valor
Price*Quantity.
Para se poder avaliar a correlação entre as diferentes categorias de produto, foi necessário transpor de linha para coluna, esta variável, e foi associado o valor Income a cada uma das categorias. De forma a não se perder muita informação com a alteração da estrutura da base de dados foram ainda criadas várias variáveis, nomeadamente AntiguidadeEmpresa, SumDiscount, SumQuantity, NrInvoices,
SumIncome, Prods_menor500, Prods5000_20000 e Prods20000. É possível observar na tabela 6, a
descrição das variáveis criadas.
Variável Tipo Unidades Descrição
AntiguidadeEmpresa Intervalar Anos Corresponde ao número de anos que é cliente da empresa. SumDiscount Intervalar £ Soma monetária dos descontos que o cliente teve nos últimos 6
anos.
SumQuantity Intervalar Soma da quantidade de produtos comprados nos últimos 6 anos.
NrInvoices Intervalar Número de compras realizadas por cada cliente, nos últimos 6 anos.
SumIncome Intervalar £ Soma do Valor de Income, de todos os produtos comprados nos últimos 6 anos.
Prods_menor5000 Binária 0 ou 1 Total de produtos em que a sua soma seja inferior a 5 000£ Prods5000_20000 Binária 0 ou 1 Total de produtos em que a sua soma esteja entre 5 000£ e 20
17
Prods20000 Binária 0 ou 1 Total de produtos em que a sua soma seja superior a 20 000£
Tabela 5 – Tabela descritiva das variáveis criadas
3.1.3.2. Correlações
Uma vez que existe a possibilidade de existirem variáveis com uma elevada correlação entre si, foi criada e analisada uma matriz de correlação de Pearson (ver anexo 2), apenas com as variáveis intervalares. Através desta análise é possível identificar as variáveis que de certa forma expressam a mesma informação, de modo a serem excluídas as variáveis consideradas redundantes. Foi estabelecido o critério que apenas seriam excluídas as variáveis cuja a correlação estivesse acima dos 80%.
3.1.4. Escolha das variáveis finais
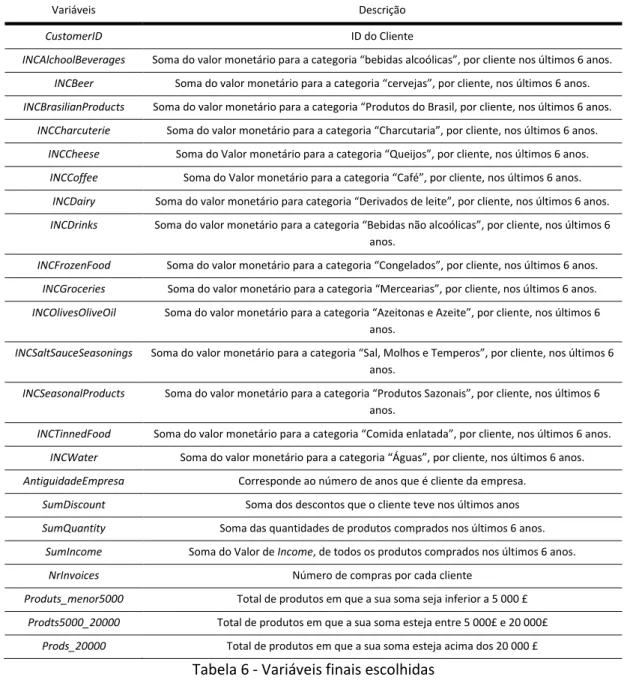
A escolha das variáveis finais, não foi um processo simplificado. Foram feitos vários testes de correlação, sendo que, a matriz de correlações obtidas do Software SAS Enterpise Miner, em conjunto com o mapa de componentes planas, provenientes do Software GeoSOM Suite Tool, ajudaram imenso na escolha final. Os dados iniciais continham o campo Grossin_Margin, no entanto optou-se por fazer a análise em função do valor de SumIncome em vez de Grossin_Margin, e excluiu-se esta última. É possível observar pelos gráficos da figura 7, que as variáveis SumQuantity e SumIncome apresentam uma elevada similaridade, porém numa primeira abordagem, e devido a sua elevada importância no estudo, estas duas serão mantidas.
Figura 7 - Gráfico de componentes planas para as variáveis SumIncome e SumQuantity
Tanto no Software GeoSom Suite Tool, como no SAS Enterprise Minner, as categorias de produto, não mostraram nenhuma correlação entre si acima dos 80% (Anexo 3), existindo apenas uma pequena correlação, para as variáveis INCWater e INCOthers, pelo que, numa primeira abordagem optou-se por manter estas duas.
Optou-se por juntar as categorias INCMaterial_Promotional, INCCatering, INCOthers, e agrupar todas estas na categoria INCOthers uma vez que estas, apresentam pouca procura, evitando excluir estes dados.
Por fim, e após realizar vários testes com e sem as categorias INCOthers e INCSpainProducts, chegou-se a conclusão que estas duas variáveis não acrescentavam nenhum valor a análichegou-se final e foram excluídas.
18 Relativamente as variáveis AntiguidadeEmpresa e DateCreatedCompany estas, na prática transmitem a mesma informação, pelo que foi optado por manter só a variável AntiguidadeEmpresa.
É possível observar na tabela 6, as variáveis finais escolhidas.
Variáveis Descrição
CustomerID ID do Cliente
INCAlchoolBeverages Soma do valor monetário para a categoria “bebidas alcoólicas”, por cliente nos últimos 6 anos. INCBeer Soma do valor monetário para a categoria “cervejas”, por cliente, nos últimos 6 anos. INCBrasilianProducts Soma do valor monetário para a categoria “Produtos do Brasil, por cliente, nos últimos 6 anos.
INCCharcuterie Soma do valor monetário para a categoria “Charcutaria”, por cliente, nos últimos 6 anos. INCCheese Soma do Valor monetário para a categoria “Queijos”, por cliente, nos últimos 6 anos.
INCCoffee Soma do Valor monetário para a categoria “Café”, por cliente, nos últimos 6 anos. INCDairy Soma do valor monetário para categoria “Derivados de leite”, por cliente, nos últimos 6 anos. INCDrinks Soma do valor monetário para a categoria “Bebidas não alcoólicas”, por cliente, nos últimos 6
anos.
INCFrozenFood Soma do valor monetário para a categoria “Congelados”, por cliente, nos últimos 6 anos. INCGroceries Soma do valor monetário para a categoria “Mercearias”, por cliente, nos últimos 6 anos. INCOlivesOliveOil Soma do valor monetário para a categoria “Azeitonas e Azeite”, por cliente, nos últimos 6
anos.
INCSaltSauceSeasonings Soma do valor monetário para a categoria “Sal, Molhos e Temperos”, por cliente, nos últimos 6 anos.
INCSeasonalProducts Soma do valor monetário para a categoria “Produtos Sazonais”, por cliente, nos últimos 6 anos.
INCTinnedFood Soma do valor monetário para a categoria “Comida enlatada”, por cliente, nos últimos 6 anos. INCWater Soma do valor monetário para a categoria “Águas”, por cliente, nos últimos 6 anos. AntiguidadeEmpresa Corresponde ao número de anos que é cliente da empresa.
SumDiscount Soma dos descontos que o cliente teve nos últimos anos SumQuantity Soma das quantidades de produtos comprados nos últimos 6 anos.
SumIncome Soma do Valor de Income, de todos os produtos comprados nos últimos 6 anos. NrInvoices Número de compras por cada cliente
Produts_menor5000 Total de produtos em que a sua soma seja inferior a 5 000 £ Prodts5000_20000 Total de produtos em que a sua soma esteja entre 5 000£ e 20 000£
Prods_20000 Total de produtos em que a sua soma esteja acima dos 20 000 £
Tabela 6 - Variáveis finais escolhidas
Foram decididos realizar dois diferentes tipos de segmentações, um por produto e outro por valor. Para a segmentação por produto foram utilizadas, todas as variáveis referentes ao produto em si, nomeadamente INCAlchoolBeverages, INCBeer, INCBrasilianProducts, INCCharcuterie, INCCheese,
INCCoffee, INCDairy, INCDrinks, INCFrozenFood, INCGroceries, IncSeasonalProducts, INCOlivesOliveOil, INCSaltSauceSeasonings, INCTinnedFood, INCWater.
Relativamente a segmentação por valor, foram utilizadas todas as variáveis restantes. Por se considerar que a categoria NrInvoices, apresentava uma elevada influência nas duas segmentações, optou-se por manter a mesma em ambas segmentações.
19
4. ANÁLISE DOS RESULTADOS
Neste capítulo serão apresentadas as análises obtidas, do problema que foi proposto resolver com este trabalho projeto.
O principal objetivo deste trabalho é criação de clusters dos clientes de uma empresa de logística e distribuição alimentar, através do Self-Organizing Maps. De forma a obter uma análise mais completa, optou-se por elaborar dois diferentes tipos de segmentações: por produto e por valor. Por fim foi feita a concatenação destes dois grupos e apresentadas as conclusões finais.
Deste modo, este capítulo é composto por três subcapítulos, sendo que o primeiro é referente as análises obtidas para a segmentação por produto, o segundo corresponde as análises obtidas para a segmentação por valor e por último a concatenação das duas segmentações.
4.1. S
EGMENTAÇÃO PORP
RODUTONeste subcapítulo, são analisados os grupos de clientes criados, a partir das variáveis selecionadas para a segmentação por produto. Estes clusters foram definidos através do agrupamento dos elementos da vizinhança que apresentavam a mesma cor (ou cores semelhantes) e recorrendo ao auxílio dos mapas de coordenadas paralelas. De forma a validar os resultados obtidos foram ainda realizadas várias vezes a mesma análise, e realizados vários testes, agrupando diferentes elementos da vizinhança. Por fim chegou-se a conclusão que seria possível definir 5 clusters diferentes.
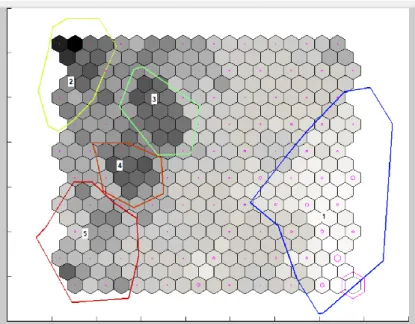
É possível observar na figura 8, a Matriz U, gerada com o algoritmo de SOM, onde se encontram os cinco clusters representados.
Figura 8- Matriz U, com os 5 clusters gerados a partir do SOM
A Matriz-U é uma representação do espaço de output de um SOM, onde as distâncias, no espaço de
20 Se a distância entre os diferentes membros da vizinhança é pequena, as unidades são representadas por cores claras (como branco ou cinzento claro), e isso significa que os membros da vizinhança possuem características semelhantes. Por outro lado, se as unidades possuem características diferentes, as unidades são representadas por cores escuras.
Posto isto é possível observar que os critérios para a seleção, dos elementos da vizinhança constituintes de cada cluster, foram diferentes. Para o cluster número 1, foram selecionados os elementos da vizinhança, caracterizados por uma cor clara, estes apresentam hábitos de compra semelhantes, correspondem ao perfil maioritário dos clientes da empresa e apresentam valores de
income mais baixos. Para os clusters 2, 3 e 4, foram selecionados os membros da vizinhança que
apresentavam cores mais escuras, uma vez que estes representam os valores de income mais altos, e não faria sentido excluí-los. Embora estes apresentem perfis de consumo diferentes, tem em comum o facto de fazerem compras com elevado valor de income. Para a constituição do cluster número 5, foram selecionados os elementos que apresentavam um tom de cinza, correspondendo a valores intermédios.
Foram calculadas as médias das variáveis para cada cluster e explanadas na tabela 7, desta forma é mais fácil a sua caracterização. Para alem desta tabela, os gráficos de coordenadas paralelas ajudaram a desenvolver as análises dos cincos grupos criados.
Foram identificados na tabela 7, com uma bandeira vermelha os valores médios mais baixos para cada variável, sendo que os valores mais altos se encontram sinalizados com uma bandeira verde e as bandeiras a amarelo correspondem aos valores intermédios. Nesta tabela, cada cluster esta identificado com a cor correspondente na Matriz U da figura 8.
Tabela 7 – Médias das variáveis dos 5 clusters gerados pelo SOM.
Pela tabela 7, é possível observar que para a segmentação por produto, 32% dos clientes da empresa não foram classificados em nenhum grupo.
➢ Cluster 1
O Cluster 1 engloba o maior número de clientes, com 50.10% dos clientes totais. É neste grupo que se encontram os clientes com um menor número de Invoices. É possível observar pelo mapa de
1 2 3 4 5 50.10% 5.25% 3.50% 2.96% 6.66% Variáveis NrInvoices 9.02 360.19 193.06 144.82 67.07 INCAlchoolBeverages £540.44 £30,073.99 £19,946.43 £5,339.17 £2,794.36 INCBeer £507.67 £50,463.61 £9,839.12 £6,804.05 £1,549.31 INCBrasilianProducts £91.56 £8,535.74 £5,548.86 £381.20 £4,802.49 INCCharcuterie £90.43 £19,660.21 £7,323.32 £3,621.93 £1,204.03 INCCheese £32.02 £5,665.07 £846.80 £4,377.01 £436.29 INCCoffe £231.81 £10,613.78 £1,742.65 £598.19 £595.33 INCDairy £21.30 £3,109.26 £268.05 £874.53 £641.61 INCDrinks £118.54 £10,226.84 £1,731.87 £5,207.41 £1,252.75 INCFrozenFood £241.17 £29,399.04 £15,629.95 £4,754.75 £2,090.74 INCGroceries £87.08 £13,160.55 £2,855.14 £3,153.54 £4,088.01 INCOlivesOLiveOil £26.06 £3,976.45 £1,107.70 £749.24 £1,158.54 INCSaltSauceSeasonings £6.90 £731.98 £131.99 £65.91 £125.46 INCSeasonalProducts £21.15 £1,314.91 £349.76 £305.81 £692.65 INCTinnedFood £89.11 £13,060.81 £2,334.48 £3,254.88 £3,107.68 INCWater £33.92 £6,023.63 £1,111.19 £1,487.30 £234.87 Cluster Médias Percentagem de Clientes