RS
àv
o
UNIVERSIDADE DE
ÉVORA
MESTRADO DE ENGENHARIA
INFORMÁTICA
Luís
CarlosMorcira
Borrcgoorientador:
Prof. Doutor
Paulo QuaresmaEI
CrÍação
de
uma
ontologia e
respectiva
povoação
a
partir
do
processameáto
d.e
relatórios'
nédiêos
UE
t77
951
Prefácio
Este documento contém
uma
dissertaçãointitulada
"Criação
deuma
onto-Iogia e respectiva povoação
a
partir
do
processamento de relatórios médicos", umtrabalho
do aluno Luís Carlos MoreiraBorregol,
estudante de Mestrado emEnge-nharia
Informática
na Universidade de Evora.O
orientador destetrabalho
éo
ProfessorDoutor
Paulo Quaresma2, doDe-partamento de Informática da Universidade de Évora.
O
autor
dotrabalho
é licenciado em EngenhariaInformática,
pelaUniversi-dade de
Éroru. A
presente dissertaçãofoi
entregue emOutubro
de 2010.-/\
*
'J., - -.-r\'r
FvO:
,ll:-
1r)
I [email protected] [email protected] IAgradecimentos
Após concluir com
toda
a dedicação esta longa etapa, quero deixar umaspa-lawas de apreço e gratidão a todas as pessoas que contribuíram para o sucesso deste
trabalho.
Um
reconhecimento especial ao ProfessorDoutor
Paulo Quaresma, meu ori-entador, pela sua disponibilidadena
discussãodo trabalho, e por todo
o
apoio eincentivo prestado.
Agradeço ao Hospital do
Espírito
Santo de Évora, emparticular
aoDirector
Clínico
Doutor
Manuel Carvalho e à equipa do Laboratório de Ultrassons Cardio eNeurovascular, pelo fornecimento dos relatórios médicos bem como
toda
a disponi-bilidade que demonstraram no esclarecimento de dúvidas.Agradeço também aos Professores
do
Departamento deInformática da
Uni-versidade de Evora, que directa ou indirectamente contribuíram no desenvolvimento deste trabalho.
Um especial agradecimento à minha famflia que sempre me apoiou e incenti-vou a seguir em
frente.
Obrigado Pai, Mãe, Lena, Avós e Virgínia!À
Jourru Correia agradeçoo
apoio incondicional e compreensão que sempredemonstrou. Obrigado
por
tudo!Nã,o podia deixar de agradecer a todos os amigos e colegas pelo apoio
pres-tado ao longo desta caminhada académica. Um especial obrigado aos amigos Gaspar Brogueira e Bruno Antunes!
Parte deste trabalho
foi
realizado no âmbito doprojecto "MEDON
-
Ontolo-gi,as para a moilelaçõ,o de dados e procedimentos médi,cos
PTDC/EIA/80722/2006",
tendo recebido uma bolsa de investigação
cofinanciada
pelaFCT/FEDER
através do programaPOCI
2010.Resumo
A
evolução tecnológicatem
provocadouma
evoluçãona
medicina, atravésde sistemas computacionais voltados para
o
armazenamento,captura
edisponibi-lizaqã.o de informações médicas. Os relatórios médicos são, na maior parte das vezes,
guardados num
texto livre
não estruturado e escritos com vocabulário proprietário,podendo ocasionar falhas de interpretação.
Através das linguagens da Web Semântica, é possível
utilizar
ontologias como modo deestruturar
e padronízar a informação dos relatórios médicos,adicionando-lhe
anotações semânticas.A
informaçã,ocontida
nos relatórios pode desta formaser
publicadana
Web,permitindo
às máquinas o processarnento automático dain-formação. No entanto, o processo de criação de ontologias é bastante complexo, pois existe o problema de
criar
uma ontologia que não cubra todo o domínio pretendido.Este
trabalho
incide
na
criaçãode
uma ontologia
e
respectiva povoação, através de técnicasde
PLN
e
AprendizagemAutomática
quepermitem
extrair
ainformação dos relatórios médicos. Foi desenvolvida uma aplicação, que permite ao
utilizador
converter relatórios do formatodigital
para o formato OWL.Palavras
chave:
Ontologiasna
Saúde, Extracçãode
Informação,Processa-mento de Linguagem
Natural,
AprendizagemAutomática,
Web SemânticaCreation
of
an ontology
and
its
population
fron the
processing
of
medical
reports
ABSTRACT
Technological evolution has caused an medicine evolution
through
computer systems which allow storage, gathering andavailability
of medicalinformation.
Me-dical reports are, most of the times, stored
in
a non structured freetext
andwritten
in
a personal way sothat
misunderstandings may occur.Through
Semantic Web languages,it's
possibleto
use ontology asa
wayto
structure
and standardize medicalreports information
by
adding semantic notes.The information
in
thosereports
can,by
these means, be displayedon
the
web,allowing machines automatic
information
processing. However,the
processof
cre-ating
ontologyis very
complex, as thereis a risk
creatingof
an ontologythat
notcovering the whole desired domain.
This
work is about creationof
an ontology andits
population through
NLP and Machine Learning techniquesto
extract information
from medicalreports. An
application was developed which allows the user
to
convert reports fromdigital
for-mat
to
OWL
format.Keywords:
Health
Ontology,Information Extraction, Natural
Language Pro.cessing, Machine Learning, Semantic Web
Conteúdo
Prefácio
Agradecimentos
Resumo
Abstract
Lista
de Figuras
Lista
de
Tabelas
Lista
de
Abreviaturas
1-
Introdução
1.1
Motivação e Enquadramento .L.2
Objectivos1.3
Contribuições desta DissertaçãoL.4
Estrutura
da Dissertação. .
.
.2
f\rndamentação Teórica
2.I
Web Semântica2.L.1
Objectivo ll llliv
vll
ix
x
1 1 2 3 3 ô b 6 7 8 10 10 11 11 13 19 20 2L 22 23 252.L.2
Mudanças da WebActual
para a Web Semântica2.1.3
Arquitectura
da Web Semântica .2.2
Ontologia2.2.L
Componentes de uma Ontologia2.2.2
Tipos
de Ontologia2.2.3
Metodologias para Construção de Ontologias2.2.4
Linguagens de Representação de Ontologias2.2.5
Ferramentas2.3
2.2.6
Jena2.2.7
Ontologias Médicas Mineração de Textos2.3.L
Processamento de LinguagemNatural
2.3.2
AprendizagemAutomática
.3
Thabalho Relacionado
3.1
Ontologias na Saúde3.2
Criação de Ontologias em Relatórios Médicos27
27
28
v
4
Proposta de
Arquitectura
4.L
Apresentação 32 32 33 33 34 35 4.24.L.L
Objectivos
.4.L.2
MetodologiaArquitectura
.4.2.1
Plataforma5
Análise
dos
documentos
5.1
Documentos em análise .5.2
5.1.1
Descrição dos documentos Enumeração dos termos5.2.L
Termos específicos dos documentos5.2.2
Termos médicos6
Criação da Ontologia
6.1
Ontologia e Web Semântica6.1.1
Escolha da Linguagem Criação das Classes6.2.1
Classes dos Termos Específicos .6.2.2
Classes dos Termos MédicosCriação dos Relacionamentos e das Restrições entre Classes
7
Extracção da Informação e Povoamento da Ontologia
7.L
O
Sistema de Extracção de Informação7.2
Preenchimento dos Campos Vazios7.3
Criação e Preenchimento da Base de Dados7.4
Processamento da Informação e Criação das InstânciasI
Utilização
do Sistema
8.1
Interface8.2
TestesI
Conclusão
9.1
ThabalhoFuturo.
A
Código da Ontologia
B
Relatório
no Formato
Digital
C
Árvore
de
Decisão
Anexo
A -
Relatório
Neurovascular
Bibliografia
6.2 6.3 42 42 42 43 43 49 Db 62 62 62 64 66 36 36 36 37 37 39 81 81 82 90 91 92 LL7 119 118 v1L20
Lista
de Figuras
Estruturação dos recursos e links na Web actual e na Web Semântica
[41]
.
.Utilização de Agentes Computacionais na Web Semântica [2]
Arquitectura
da Web Semântica [4]2.4
Tipos de Ontologias2.5
Passos da Metodologia para a Criação da Ontologia2.6
Camadas das Linguagens de Ontologias2.7
Interface da Ferramenta Protégé. .
.2.8
Etapas da Mineração de Têxtos [53]2.9
Metodologia de ldentificaçã,o de Tokens [34]2.10
Exemplo de Arvore de Decisã,o .2.t
2.2 2.3 7 8I
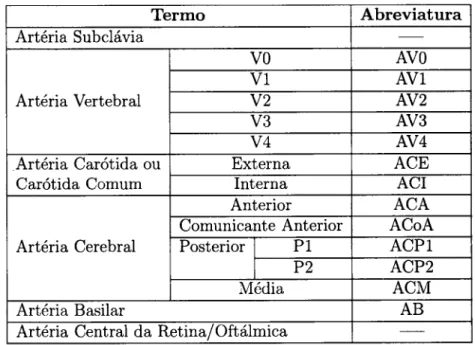
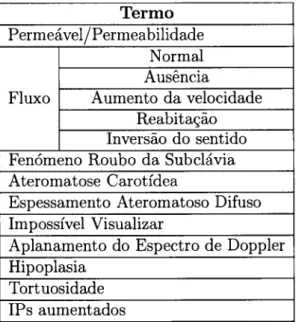
11 L2 13 20 23 25 26 29 30 33 34 37 44 45 46 48 49 51 53 54 56 58 64 66 70 7L 72 73 3.1 3.2Exemplo de um Relatório Radiológico
tl]
.
. Ontologia de Relatórios Radiológicos4.L
4.2
Fases de Desenvolvimento do Thabalho
5.1
Arquitectura.
Identificação do Paciente nos relatórios
6.1 6.2 6.3 6.4 6.5 6.6 Hierarquia das Hierarquia das Hierarquia das Hierarquia das Hierarquia das Hierarquia das Anatómicas para os termos para os termos para os termos para os termos para os termos para os termos classes classes classes classes classes classes
do caleçalho dos relatórios . da identificação do paciente
do cabeçalho dos exames
do rodapé dos relatórios
das Entidades
Anatómicas
.':':"1'"*::
:":.
*
::':*":
6.7
Hierarquia das classes para os termos das Observações6.8
Hierarquia das classes para os termos dos Diagnósticos6.9
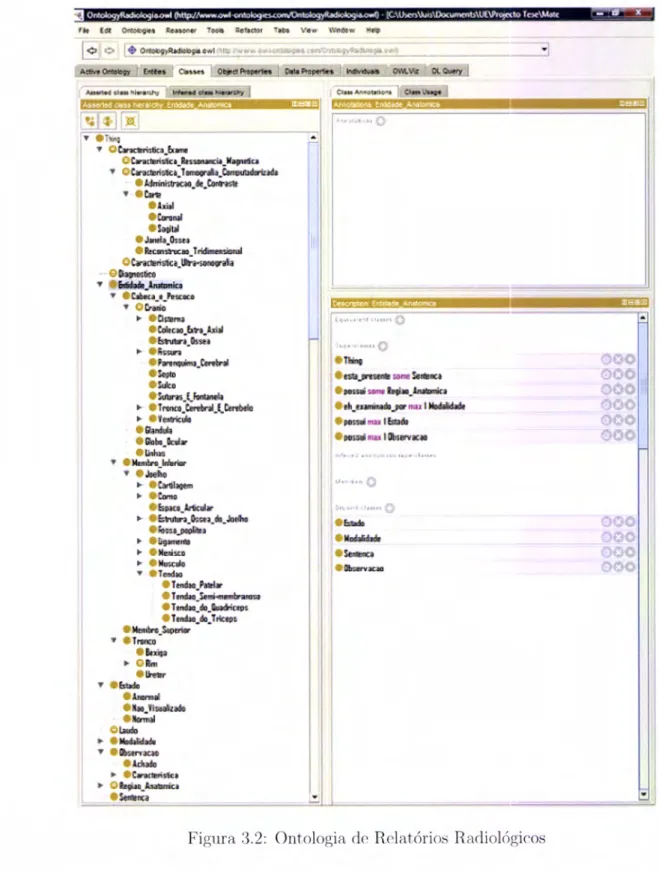
Relações com a classe que possuí o objectoArtéria
6.10
Relações entre classes que representam o esquema global do domínio .7.t
7.2Esquema do Módulo
do
Sistema paxao
Preenchimento dos Campos VaziosEsquema
do Módulo do
Sistema parao
Preenchimentoda
Base de Dados7.3
Estrutura
de classes7.4
7.5
7.6
Vector com as Instâncias do Parágrafo
Algoritmo
que relaciona as instâncias Lado e Entidades AnatómicasAlgoritmo
que relaciona as instâncias Zona e Entidades Anatómicas7.7
7.8 7.9
Algoritmo
que relaciona as instâncias Stent e Entidades AnatómicasAlgoritmo
que relaciona as instâncias Entidades Anatómicase
Di-agnóstico
Algoritmo
que relaciona as instâncias Entidades Anatómicase
Ob-Exemplo da Utilização da Aplicação
Mensagens Exibidas pela Interface . Instância do Relatório
Instâncias do Paciente
Instância do Médico
Instâncias do
Primeiro
ExameInstâncias do
Primeiro
Grupo do Conteúdo do Primeiro Exame Instâncias do Segundo Grupo do Conteúdo do Primeiro Exame . Instância do TécnicoInstâncias do Segundo Exame
Instâncias do Conteúdo do Segundo Exame
Instância da Conclusão
74 75
servações
7.10
Algoritmo
que relaciona as instâncias Observação e Diagnóstico7.11 Esquema do Módulo do Sistema para o Processamento da Informação e Criação de Instâncias 75 78 80 81 82 83 83 84 84 85 86 86 87 88 89 8.1 8.2 8.3 8.4 8.5 8.6 8.7 8.8 8.9 8.10 8.11 8.L2
vlu
Lista
de
Tabelas
Termos do cabeçalho dos relatórios Termos da Identificação do Paciente .
Termos do cabeçalho dos exames Termos do rodapé dos relatórios Termos das Entidades Anatómicas.
5.6
Termos relacionados com as Entidades Anatómicas5.7
Termos das Observações5.8
Termos dos DiagnósticosDescrição de alguma sintaxe do
OWL
43Especificação das Relações e Restrições da classe com o objecto
Arté,ri'a
57Especificação das Relações e Restrições do esquema global do
domínio
59 38 38 38 39 39 40 40 4L 5.1 5.2 5.3 5.4 5.5 6.1 6.2 6.3lx
Lista
de
Abreviaturas
Concept Name
Concept Unique ldenti,fi,er
DARPA
Agent Markup LanguageDARPA
Agent Markup Language*Ontology Inference Layer HyperTert Markup LanguageExtracção de Informação
Inteligência
Artificial
Medical Subject Headings Mineração de TextosOptical Character Recogniti,on Ontology Inference Layer Ontology Web Language
Processamento de Linguagem
Natural
Resource D es cripti,on Framework
Resource Description Framework Schema
Standard Generalized Markup Language Simple
HTML
Ontology ErtensionsSystematized Nomenclature oJ Medicine
Structured Query Language
Unified Medical Language System
UMLS Knowledge Sources
Uniform Resource
ldentifier
Uni,f orm Res ourceLou,tor
Ertensi,ble Marleup Language
World
Wide Web ConsortiumCN
CUI
DAML
DAML+OIL
HTML
EI
IA
MeSH
MT
OCR
oIL
owL
PLN
RDF
RDFS
SGML
SHOE
SNOMED
SQt
UMLS
UMLSKS
URI
URL
XML
w3c
x
Capítulo
1
Introdução
Neste capítulo é
feita a
introdução sobrea
área que abrangeo trabalho
ex-posto nesta dissertaçã,o.
Na
secção 1.1 é descritaa
motivação eo
enquadramento desta dissertação. Nas outras secções são descritos os objectivos (1.2), as principais contribuições (1.3) no desenvolvimento da dissertação, e a suaestrutura
(1.4).1-.1
Motivação
e
Enquadramento
A
maiorparte
das informações disponíveisna
Web actual, estão representa-dasnum formato
textual
e
escritos em línguanatural,
destinadosà
análise, com-preensão e interpretação do ser humano. Deste modo, o processamento automáticoda
informaçãoé
um
processo bastantedifícil,
poistais
documentos não possuema
informação de modoestruturado e com
anotação semântica que possibilitem o processamento àsmáquinas.
Este problemaé
bem visível quando,por
exemplo, realizamos uma pesquisa num qualquermotor
de pesquisa e o que ele nos devolve são dezenasou
centenas de documentos e páginas, muitas vezes sem possuírem a informação que desejamos obter.Com
o
intuito
de ultrapassar estalimitação,
estáa
ser planeada uma novaWeb q:u,e será uma evolução
da
Web actual, que se dá pelo nome de Web Semântica.Esta
nova
Web, apostana
estruturação dos recursos de informação acrescentando anotação semântica aos dadosdo
seuconteúdo.
Assim, todos os recursosda
Websã,o passíveis de ser processados automaticamente
por
máquinas que passam ater
acesso à semântica dos dados.
Uma das formas de conseguir este objectivo, é através do uso de ontologias, que
permitem estruturar e modelar conceitos e relações de um dado domínio, fornecendo
uma base de conhecimento orientada para as máquinas e respectivo processamento
automático.
Parafacilitar o
preenchimentoda
ontologiaa
partir
deum
conjuntode textos de determinado domínio, podem ser empregues processos automáticos ou
semi-automáticos.
A
área da Mineração de Textos pode ser aqui utilizada.A
Mineração de Textos veioajudar
alidar
com a sobrecarga de informação causada pelo crescente volume de informaçãona
Web, pois era uma tarefa bastantecomplicada quando se pretendia analisar,
localizar e
acedera
essa informação dectpÍruto
t.
tNrnoouçÃo
modo manual.
A
Mineraçãode
Textos permite
extrair
informaçãode
textos,
através de técnicas, métodos e algoritmos de algumas áreas,tais
como, processamento de lin-guagemnatural
e aprendizagem automática.A
crescente evolução que tem ocorrido na área da informática, provoca consequentemente uma evolução na área da medicina, nomeadamente através da criação de sistemas que permitem um melhor tratamento da informação médica. Por
outro
Iado, cada vez mais nos deparamos com
a
descoberta de novas patologias, com o aparecimento de novos medicamentos, etc, que tem provocado uma grande expansãoda informação da área médica.
A
integraçãoda
informaçãoda
área médicaé um
dos grandes desafios dainformática na
saúde.
Entre outros,
os examese
consequentemente os relatóriosmédicos são
muitas
vezes efectuados em diversas instituições, queutilizam
voca-bulários proprietários, e se esta informação não
for
devidamente preparada e apre-sentada de maneira apropriada, pode ocasionar falhas de interpretação.Para
solucionar este problema pode-se recorrerao
usode
ontologias, queirão
permitir
estruturar
e adicionar anotação semântica à informação dos relatóriosmédicos. Desta forma, a informação contida nos relatórios pode ser publicada nesta
nova Web,
permitindo
que as diversas instituiçõesutilizem
sistemas que processemautomaticamente essa informaçã,o, ttazendo consequentemente uma melhor manu-tenção do cuidado de saúde do paciente. Essa informação pode ainda ser usada para
fins de investigação ou para
criar
sistemas de auxilio aos médicos no apoio à decisão diagnóstica.A
criação de ontologias não é uma tarefatrivial.
Quando se pretendecons-truir
uma nova ontologia surgem dificuldades pois não existe uma solução universal.Além disso, existe o problema de se criar uma ontologia que não consiga cobrir todo
o domínio pretendido, tornando a sua utilização pouco viável.
L.2
Objectivos
O
propósito geral desta dissertação étratar
a problemática da criação e pre-enchimento de ontologias, emparticular,
de relatórios médicos,utilizando
técnicas de processamento de Iinguagemnatural
e de aprendizagem automática.Foram analisados relatórios médicos neurovasculares, provenientes
do
labo-ratório
LUSCAN do Hospital do Espírito Santo de Évora, com o propósito deextrair
todos os termos que irão
permitir
formar o domínio da ontologia.O
objectivo principal
destetrabalho
écriar
uma
ontologia quepermita
re-presentar a informação expressa nos relatórios neurovasculares, ecriar
mecanismosautomáticos que
extraiam a
informação e efectuem a referida "povoação"daonto-Iogia.
Destemodo,
iremosobter
uma
basede
conhecimentopara
este domínio,tornando possível uma nova utilização dos dados textuais através do processamento
automático
por
máquinas.ctpÍruto
t.
tNrnoouçÃo
1.3
Contribuições
desta
Dissertação
As principais contribuições apresentadas nesta dissertação são:
o
Criação de uma ontologia para o processamento de relatórios médicos neuro-vasculares, e em particular:-
Enumeração dos termos;-
Definição de classes, propriedades e restrições sobre as classes.o
Aplicação das Árvores de Decisão para extracção de informação dos relatóriosmédicos;
o
Desenvolvimentode um
conjunto
de
algoritmos que permitem
atribuir
asrelações entre os termos médicos presentes em cada frase dos relatórios
(ob-servações, diagnósticos, entidades anatómicas, etc);
o
Desenvolvimentode
uma
aplicação,que permite
aos utilizadores converterautomaticamente
um relatório
médico neurovascular doformato
digital
para o formato OWL.L.4
Estrutura
da
Dissertação
A
dissertação está organizada do seguinte modo:Capítulo
LNo
presente capítulo éfeita
a motivação eo
enquadramento do problema asolucionar, tais como os seus objectivos.
E
apresentada a estrutura da dissertação eas sua,s principais contribuições.
Capítulo
2Neste capítulo é efectuada uma revisã,o da
literatura
das áreas referentes aoproblema em análise. Em concreto é descrita a Web Semântica, as ontologias como
forma
deestruturar a
informação e publicá-lana
Web,e
a
áreada
Mineração de Textos como forma deextrair
a informação.CapÍtulo
30
trabalho realizado no âmbito da área do problema é descrito neste capítulo,quer de
um
modo mais geral,quer de
um
modo
maispróximo
do
problema em análise.Capítulo
4Neste capítulo é descrito o problema, e é apresentada uma proposta que visa
ctpÍruto
t.
tNrnoouçÃo
solucionrí-lo. Esta proposta é aplicada nos capítulos seguintes
Capítulo
5São analisados os documentos utilizados, que correspondem a relatórios médicos.
É feita
uma descrição geral dos documentos, e são enumerados todos os termos ne-cessários à criação da ontologia (capítulo 6).Capítulo
6A
criação da ontologia que permiteestruturar
a informação proveniente dosrelatórios é feita neste
capítulo.
A partir
da enumeração dos termos, são criadas asclasses, as suas propriedades e respectivos relacionamentos.
Capítulo
7É
criado
um
sistemade
extracçãode
informação, queextrai a
informação dos relatórios através do processamento de linguagem natural, de técnicas de apren-dizagem automática e de alguns algoritmos desenvolvidos, que permitem povoar a ontologia.Capítulo
8Neste capítulo é apresentada uma aplicação, que permite uma interacção com
o utilizador de forma simples e efrcaz. São também realizados alguns testes, de modo a avaliar as instâncias criadas na ontologia após a conversão dos relatórios.
Capítulo
9Por fim, são apresentadas as principais conclusões e descrevem-se os problemas em aberto para uma investigação futura.
Capítulo
2
Rrndamentação
Teórica
Este
capítulo
f.az uma introdução aos conceitos teóricose à
área em que seenquadra o
trabalho
apresentado nesta dissertação.A secçã,o 2.1 descreve a Web Semântica, onde são descritos quais os seus
objec-tivos (2.1.1), as suas mudanças em relação
à
Web actual(2.I.2)
e a sua arquitectura(2.1.3).
A
secção 2.2 corresponde ao conceito ontologia, onde são descritos os com-ponentesde uma ontologia
(2.2.t),
osvários
tipos
(2.2.2),
as metodologias para construção de ontologias (2.2.3), as linguagens ontológicas (2.2.4), algumas ferra-mentas usadasnesta
ârea (2.2.5),um
frameworkpara
manipulação de ontologias(2.2.6) e o uso de ontologias na área médica ou da saúde (2.2.7).
Na secção 2.3 é feita uma breve descrição à área da Mineração de Textos, e o
seu uso na área da Inteligência
Artificial
através de algoritmos e técnicas das áreasdo
Processamentode
LinguagemNatural
(2.3.1)e da
AprendizagemAutomática
(2.3.2).
2.L
Web
Semântica
Actualmente,,
a
Web assume-se como o meio mais utilizado para comunicação, publicação epartilha
de informação. As redes sociais, o comércio e os serviços têmprovocado
um
crescimento exponencialda Internet,
que conta cada vez com mais utilizadores.A
Web pode ser vista como uma rede de servidores que proporcionam o acessoa um conjunto de documentos ou páginas ligadas entre
si.
O constante aumento donúmero de servidores e de páginas Web f.az com que a rede de informação assuma dimensões gigantescas, tornando
a
Web no maior repositório de informaçãoda
ac-tualidade.
A
informação contidana
Web, tem sido pensada apenas paraleitura
por partedas pessoas, fazendo com que
a
Web seja voltada apenas paxa o consumo humanoe não para os computadores
[13].
Tais factores, aliados ao grande crescimento daWeb tem provocado com que
o
ser humano nã,o consiga aproveitartodas
as sua,spotencialidades, perdendo-se facilmente entre documentos que possuem endereços
URL
(Uni,foryn Resource Locator)e
que referemmuitas
vezesoutros
documentosctpÍruto
z.
FU.rvDAMElvru,çÃo
TE)RICA
com links para os respectivos endereços.
Mesmo com o auxilio dos motores de pesquisa, torna-se
difícil
ao ser humanoencontrar aquilo que deseja ou necessita, pois o número de resultados devolvidos é
exageradamente grande e
impreciso.
Tal
acontece, poisa
Web actud, não fornece condições quepossibilitem
a
estes motores de pesquisadistinguir
entre os vários significados semânticos que um termo pode comportar.Com
o
objectivo de
ultrapassar estas limitações estáem
cursouma
nova geraçãoda
Web, a Web Semântica, que aposta na estruturação dos recursos dein-formação acrescentando informação complementar que represente
a
semântica do seu conteúdo, através de linguagens específicas que permitem o processamento pormríquinas, facilitando assim a sua consulta através de aplicações desenvolvidas para o efeito.
Segundo Bernes-Lee
[3],
o
primeiro
passopara
o
desenvolvimentoda
Web Semântica é a inclusão dos dados numformato
cujos sistemas computacionais pos-sam compreender de forma directa ou indirecta.Mais tarde
surgiu uma nova definição, onde Berners-Leeet
al.
[2] afirmamque
"a
Web Semântica é uma extensãoda
Webactual,
ondea
informação possuium significado claro e definido, possibilitando uma melhor interacçã,o entre compu-tadores e pessoas".
É
assim evidente, que o grandeobjectivo
da Web Semântica épermitir
que as pessoas aproveitem ao máximotodo
o potencialda
Web, mas paraisso torna-se necessário o uso de máquinas para o processamento automático da
in-formação.
Para que
a
Web inclua a perspectiva das máquinas, há que encontrar soluçõesde estruturação, integração,
troca e
compreensão semânticada
informação,tanto
na
óptica
dos humanos comona
óptica
das máquinas, através dos seus agentesinteligentes [55].
2.L.L
Objectivo
A
Web Semântica é umainiciativa/projecto
liderado peloW3C
(World
Wid,eWeb Consoúium), que se
tem
dedicado ao desenvolvimento de tecnologias esúan-dards, com
o
objectivo decriar um
meio paratroca
de inforrnação,atribuindo
sig-nificado semântico ao conteúdo
da
Web,permitindo
que esse significado seja com-preendido não só por humanos comopor
máquinas.Os objectivos principais deste projecto são [41]:
o
Construir
uma estrutura comum de representação dos dados de modo afacili-tar
a integração de diversas fontes de informaçã,o e a e.xtrairum
novo conhe-cimento;o
Aumentar autilidade
da informação conectandoa aos seus conceitos e a,o seucontexto;
o
Descoberta e análise da informação mais eficiente.Deste modo, ao efectuar-se uma pesquisa os resultados serão mais precisos e
de acordo com as pretensões e necessidades do
utilizador.
cApÍTULo
2.
FUr\rDÁÀíElüTAÇÃo
TEIRI:A
Actualmente,
já
existem documentosna
Web no formato da Web Semântica, mas é um quantidade insignificante para o tamanho que hoje em diaa
Web possui. No entanto, grande parte dos utilizadoresda
Webjá
está consciente da importância quea
Web
Semânticapode
ter
no futuro,
permitindo
quea
longo
prazoa
Web Semântica possaatingir
as dimensõesda
Web actual.2.L.2
Mudanças da Web
Actual
para
a
Web
Semântica
Um
dos princípios básicos que constituem a Web Semântica, é oprincipio
de que as pessoas, os animais, os lugares, os objectos e tudo o que existe no mundo podeser identificado por um
URI
(Uni,form Resource ldenti,fier) [41]. Através desteiden-tificador,
é possível especificarum
conjunto de características sobre uma entidade. Pode-se entãoidentificar um lugar,
como a Universidade de Éuotu, referindo-se aoURI
da sua página Web, setdo também possível referir entidades de modo indirecto,como
por
exemplo, utilizando-se oURI
da caixa de e-mail de uma pessoa.A
Web actual possui documentos pensados para a análise humana, semmeta-informação a explicar a suA relação com outros documentos.
E
relativamente fácilao ser humano
identificar
ltm
li,nk num documento e perceber qual é a informaçãodo
seuconteúdo.
Porém,tais
informações não estão acessíveispara
as máquinas, pois os linlcsna
Weba<'ilal
não in<licarn rluais os tipos de rclações errtre os recursos.Na Web Semântica os li,nles podem possuir diferentes
tipos,
possibilitando a definição de conceitos epermitindo
que as máquinas façam o processamento dessainformaçáo.
A
figura 2.1, mostra como são referenciados os Jinlçsna
Web actual e algunstipos
de relacionamentos possíveis na Web Semântica.WeB ACTUAL WeB SEMÂNTICA
hrLr [rr h:r \l ertrrul ItrrJ.' 1,, l-l I rI I 'Io I l ;J 1..í I
Figura
2.1:
Estruturação dos recursos elinks
na Web actual ena
Web Semântica[41] 7 I I 7 'i .r 1; r 'rL .-,r --:! i ,l',: -..i
7?
'Í,í I 'l! l ' ,.ll'r"i..:" {. LIBÊÂFI -I \'Brxdoa\""'
\
r\s I â > DolCITMErrIT{7Y{
' Í(}Ptc TOPIC I,,
relc..
a PLACÉ{7
li'-í,.l" rc,q,pÍruLo
2.
FUr\rDÁ^fElüTAÇÃo TEoRIc
A
A
Web Semântica engloba as tecnologiasda
Webactral
com a representaçãoformal do
conhecimento[24]. O
conhecimentona
Web Semântica deverá ser for-madoutilizando
conceitos de meta-informação, agentes, ontologias, Web Seruices,linguagens e ainda outra tecnologias, possibilitando o processamento da informação
t6l.
Para Bern<:r-Lce
et
al.
[2], a Wcb Scrnântir:a po<Ierá scr melhor explorarla apartir
do desenvolvimento de agentes computacionais que possibilitem armazenar a,sinformações vindas de diversas fontes, relacioná-las automaticamente e retorná-las de maneira mais organizada aos utilizadores.
A
figura
2.2mostra
como os agentes computacionais podem ser usados na recuperação de informação na Web Semântica.Ârü crdrllon B -t
ry
)F
/
\
I
Urtt
HI
ftffigü CruürrÊon fod.+'\l-.r..r
/I)F
{r}
*
-tt ú, rar{>
\
tt.üfuf}lr\
GD
i-leCÍ]it frrynç Aglldr Iefrdrlr Rcgüsrtüy Cüiltrrt, FrTI I,Sfrr0.AmürEr
IootFigura
2.2:
IJttLização de Agentes Computacionais na \Àreb Semântica [2]2.L.3
Arquitectura
da Web
Semântica
Com o objectivo de
facilitar
o desenvolvimento e padronização das tecnologiasrelacionadas com a Web Semântica, o W3C divulgou uma arquitectura para a Web Semântica baseada em camadas sobrepostas, onde cada camada ou tecnologia deve
obrigatoriamente ser complementar e compatível com as camadas inferiores, e não depender das camadas superiores.
A
figura 2.3, representa as camadas lógicas da arquitectura da Web Semântica.h
.L, a'J, L ri rr , t D '*1, .l ) t çr )?c.q,pÍruLo
2.
Ft/
rDAÀ,fE^rrAÇÃo
TE)RI1A
futes
Figura
2.3:Arquitectura
da Web Semântica [4]As
camadas inferiores destaarquitectura
podem ser designadas de Camada Esquema (SchemaLayer)que
é responsávelpor estruturar
os dados edefinir
o seusignificado [7][9][35][40]. Esta caurada gcnérica, engloba as camaclas Unicode, URI,
XM L + N S +rmlscherna e RD F +rdfschema.
A
camadaURI
permite referir documentos, objectos e eventos através dores-pectivo endereço e de acordo com a norma Unicode.
A
camadaXML
permite representar a estrutura dos dados baseada emstan-darts
XML.
narnespo,ces eXML
Schema fornecendoum
formato parâ intercâmbiode informação.
Já a carrra<la
RDF
eRDF
Schema engloba as linguagens da Web Semântica, fornecendoum
conjunto
deprimitivas
quepermitem
criar
vocabulário ontológico (Ontology uocabulary)e representar o conhecimento de um determinado domínio.A
camada ontologia (OntologyLayer)é
portanto constituída pelo vocabulárioontológico que fornece
o
significado dos termosde
determinada áreado
conheci-mento.As camadas superiores Logic,
Proof e
Trust permitem definir um conjunto deregras lógicas que fornecem a
troca
de provas.A
camada Trzsú possuí mecanismos que permitem confiar ou não em determinada prova, tais como, o uso de assinaturasdigitais
corno garantia da irloneirlarle rla infbrrnação [21].Nos
últilnos
anos estaarquitectura tern sofrido
pequerla"salterações.
Foiacrescentado
a criptografia para garantir, juntamente
coma
assinaturadigital,
aconfidencialidade das informações na Web Semântica. Uma das
últimas
alteraçõesdiz
respeitoà
introduçãoda
linguagemOWL
quefigura
actualmente como reco-mendação para o desenvolvimento de ontologias, e foram também incorporadas tec-nologias comoSPAR}L (RDF Qr"ry
Language and Protocol) eDPL
(Descri'ptionLogic Programs)que proporcionam uma
estrutura
de conhecimento mais flexível eque
facilitam
a realização de consultas semânticas [10].I
o l-= +t o g ol) aI-VI-
o .= UI.a-ô
Data Data Trust Proof Ontology vocabutary URI UnicodeSetf-detc.
doc. Logic RDF + rdfschema)ür{-+NS+xmlschema
cApÍruLo
z.
FUrüDÁÀíElüTAÇÃo
TEIRI:A
10Numa
Webfilura,
muitas camadas e muitas tecnologias serão acrescentadasa
estaarquitectura,
de modoa
ser possívelcriar
documentos com informaçãoes-truturada
e com conteúdo semântico, possibilitando o processamento da informaçãopor máquinas sem ser necessário a intervenção humana.
A
sccção scguinte asscnta na camada ontologia.2.2
Ontologia
Ontologia é uma palavra que tem origem no campo da filosofia e pode ser in-terpretado como o estudo (-logi.a)da existência ou
do
ser(onto-).
Segundo Gruber,este terrno significa "descrição explícita cla existêrrcia"[25].
O termo ontologia
foi
posteriormente adoptado na área da InteligênciaArti-ficial
(IA)
para designar artefactos usados como modelos formais de domínio [26].As
ontologias vêm sendomuito
utilizadas na
intcgração de informação, re-cuperação de informação e Web Semântica, sobreum
determinado domínio ou nasdiversas áreas do conhecimento [37],
tais
como a medicina.Existem diversas definições para ontologia, porém há um consenso, as ontolo-gias pernritern estruturar e rrr<.rdelar conccitos e relações de Íbrma correcta, evitando
ambiguidades e estruturando o conhecimento existente de um dado domínio [51].
2.2.L
Componentes
de uma
Ontologia
Na
Web Semântica, as ontologias são de grandeutilidade, utilizando
osse-guintes componentes:
o
classes para representar conceitos deum
domínio que são geralmente organi-zadas em taxonomiasl, podendo haver herança de classes;o
proprie«la«les de cada conccito(atributos
que reprcscrrtarn características clasclasses e relações que correspondem aos
tipos
de associações entre classes do domínio);o
instâncias das classes.As ontologias são de facto um modo de representar o conhecimento de um dado domínio, orientadas para as máquinas e para o respectivo processamento automático
da infonnação, prirrcipalrnente a
partir
da scruântica exprcssa errr clocurnentos Web.ctpÍruLo
2.
FUrüDAÀrElüTAÇÃo
TEIRI:A
112.2.2
Tipos
de Ontologia
Segundo
Guarino
[26], as ontologias podemter
diferentes níveis,de
acordo com os conceitos representados.As chamadas ontologias de
alto
nível (top-leuel ontologi,es)ot
ontologiassupe-riores (upper ontologi,es), representam conceitos gerais, independentes do domínio.
As
ontologiasde domínio
representamo
conhecimentode
um
domínio
es-pecÍfico.
As ontologias de tarefa descrevem como as tarefas ou actividades são condu-zidas (independentemente do domínio).
Por fim,
as ontologiasde
aplicação descrevem conceitos que dependem deigual modo de urn domínio específico ou do
tipo
de tarefa.A
figura 2.4 representa a relação entre os quatro tipos de ontologias, do topo(mais geral) para
baixo
(mais específico).Figura 2.4:
Tipos
de OntologiasNo trabalho apresentado nesta dissertação são utilizadas ontologias de domÍnio,
llois
o ob.lcctivo ti cornpartilhar o conht:cirrrctrt«r solrre rurr dornínio delirnitado.2.2.3
Metodologias para
Construção
de
Ontologias
Quando se pretende construir o esquema de uma ontologia, deve-se ter sempre
em conta
a
utilização de uma
ontologia pré-existenteao
invésde construir
uma ontologianova. No
entanto, e para
ambos os casos) deve-se sempreaplicar
umametodologia
durante
o
processode desenvolvimento.
Em
seguida, sã,o descritas duas das principais metodologias para a construção de ontologias.Orroloorl DE ALTO NíVEL Or*tor.oorl DE TAREFA OntoroorA DE Dorríxp OrtoloolA oE APLTCAçrto
cApÍruLo
2.
FU
rDAÀ,rE^rrAÇÃo
TEIRI:A
t2
As metodologias de desenvolvimento de ontologias podem ser classificadas de
acordo com
a
abordagem de desenho ea
partir
dos conceitosdo domínio
[17], doseguinte modo:
o
Bottom-up (de baixo para cima)Começa com a definição das classes mais específicas, com subsequente agru-pamento destas classes em conceitos mais gerais;
o
Top-Down (de cima para baixo)Começa com a definição dos conceitos mais gerais no domínio e posteriormente,
é
feita
a especialização dos conceitos;o
Middle-Ozú (do centro para fora)Começa com a definição dos conceitos mais relevantes para o domínio e segue
tanto
no sentido da generalizaçáo quanto da especializaçáo.Outra
metodologia que é bastarrtc reÍ'ereuciada naliteratura
é a proposta pelogrupo da Universidade de Stanford, que refere que a modelagem de uma ontologia pode ser realizada seguindo alguns passos que representam a sequência de criação e
modelagem da ontologia [45]:
1.
Determinaro
domínio e escopoda
ontologia, que pode ser realizado através das seguintes questões:o
Qual o domínio e uso da ontologia?o
Quais ostipos
de questões que a ontologia deveria responder?o
Quem usará e f.ará a manutenção desta ontologia?2.
Considerar a reutilizaçáo de ontologias existentes;3.
Enumerar termos importantes na ontologia;4.
Definir
as classes e sua hicrarquia:5.
Definir
as propriedades das classes;6.
Definir
ostipos
de valores e cardinalidade das propriedades;7.
Criar
instâncias das classes.A
figura
2.5 corresponde aos passosda
criaçãoda
ontologia destetipo
demetodologia, mas de modo simplificado.
Figura
2.5: Passos da N,{etodologia para a Criação da OntologiaDríioir Deftoir lmblto ternlo§ clrrscs Dcfrnlr re*rlçlel Crler tnstânclar
c,q,pÍruLo
2.
FUIüDAÀ,íE.^\rrAÇÃo
TE)RICA
132.2.4
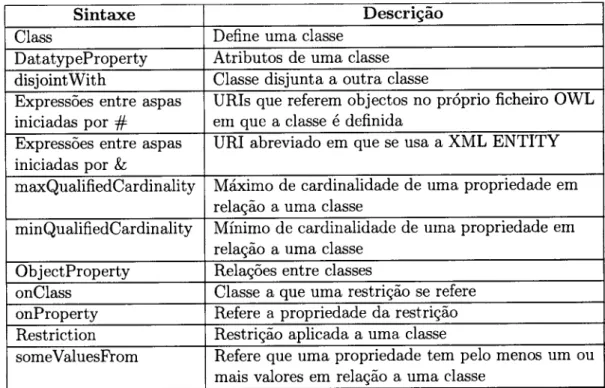
Linguagens de Representação
de
Ontologias
Com a constante evolução da Web Semântica, têm surgindo várias linguagens capazes de representar ontologias.
As principais linguagens ontológicas são:
RDF,
RDFS, SHOE,OIL,
DAML,
DAML+OIL
eOWL. A
figura 2.6 representa as camadas das linguagens de ontologiapara a Web Semântica.
H
Figura
2.6: Camadas das Linguagens de OntologiasA
partir
da análise à figura, percebe-se que oXML
é base do desenvolvimentodas linguagens SHOE,
XOL
eRDF,
enquanto que para oOIL
eDAML*OIL,
alin-guagem R.DF é a base. Por
fim.
a linguagemOWL
é uma evolução deDAML+OIL
e por consequência da linguagem RDF.Em
seguida são descritas as principais linguagens ontológicas, embora alin-guagem
OWL
seja descrita pormenorizadamente porque é hoje em dia a linguagem«1re crrcontra rrraior aceitação por parte rlos utilizarlclres da Web Semârrtir:a, e porque
foi
a linguagemutilizada
notrabalho
descrito nesta dissertação.RDF
A
linguagemRDF2
(Resource Descripti,on Framework) éutilizada
para re-presentar informações sobre os recursos daWorld Wide
Web [38]. Esta linguagemfoi
desenvolvida para descrever meta-informação sobre recursos Web,tais
como otítulo,
autor
erlata
de criação de umapágina
Web.O
uso doRDF tem
maisapli-cabilidade através da generalizaçáo do conceito de um recurso Web, qlue possibilita
o
uso desta linguagem para expressar informações sobre as coisas que possam seridcntificadas
na
Web.A
lirrguagernRDF
perrnite
atroca dc
inforrnação entre aplicações, sem que ocorra perda de significado.oll,
DAITIL+OII SHOExoL
RIIF(S)xtrtt
2http:
cnpÍruro
z.
FUNDAMENT+,çÃo TEoHrcA
t4
A
estrutura RDF
é baseada na identificação de recursosna
Web, e pode servista
como umatripla
constituídapor um
sujeito,um
predicado que descreve umconjunto
de propriedades aoqual
seatribui
um
valor e que expressa uma relação,e
um
objecto.
Tanto o sujeito
comoo
objecto, são identificados através de URIs,embora o objecto possa também ser identificado
por
umliteral.
A
sintaxeRDF
é baseada emXML
(Extensible Markup Language), chamadaRDF/XML,
que permite o processamentopor
máquinas em ambiente Web. Noen-tanto,
asURIs em
RDF
podem referir-sea
qualquer coisa identificável, sem quetenha de ser
um
recurso IVeô. Assim, além de descrever páginas Web, comRDF
épossível descrever pessoas, carros, motas, etc.
RDFS
A
linguagemRDF
permite
expressar sentenças sobre recursos,no
entanto, começou aexistir
a necessidade dedefinir
vocabulários (termos) a serem utilizadosnessas sentenças. Surgiu assim
o RDFS3 (RDF
Schema) que é uma extensão dalinguagem
RDF
mas com vocabulário que permite descrever classes de objectos, assuas propriedades e o
tipo
de dados para o valor dessas propriedades [8].Em RDFS, a definição de classes ocorre através do vocabulário da linguagem:
rdfs:Resource,
rdf:Property
erdfs:Class.
Thdoo
que é descrito emRDF
sãorecursos e são instâncias da classe rdfs:Resource.
A
classerdf:Property
éutilizada
paxa caracterizar as instâncias
de
rdfs:Resource.Por
fim o
rdfs:Classé utilizada
para
definir
conceitos em RDFS.Para as propriedades dos objectos, a linguagem RDFS possuí também
voca-bulário especifico:
rdfs:domain
erdfs:range
representam respectivamente a classeque possuí a propriedade e a classe que está relacionada com a classe de domínio ou
o
tipo
de valor dessa propriedade.RDFS permite descrever conhecimento simples, não sendo uma linguagem
su-ficientemente "poderosa"para representar conhecimento mais complexo, como por exemplo:
afirmar
queum relatório
médicotem um
único paciente,tem
de serrea-lizado
por
um
médico, ser executadopor um
ou vários técnicos e apresentar uma conclusão.SHOE
SHOE4
(SimpleHTML
Ontology Extensions)é uma linguagem pararepre
sentação de conhecimento baseada em ontologias para
a
Web, quefoi
desenvolvidapor
estudantes e investigadores da Universidade deMaryland
121.s http:
//www.w3.org/TR/rdf-schema/
ctpÍruto
z.
FUNDAMENT,I,çÃo
TEIRICA
15A
linguagem SHOE é uma extensão deHTML
(HyperText MarkupLan-guage) com tags que fornecem uma
estrutura
capàz de representar conhecimento, ecomo
tal,
necessárias paraintroduzir
indicações semânticas.Para ser compatível com os padrões
da
Web, a sintaxe SHOE é definida comouma
aplicaçãode
SGML
(Standard General'izedMarkup Language). No
entanto, existe uma versão do SHOE queutiliza
XML
ao invés dooriginal
SGMI
[28].SHOE não possuí uma fundamentação lógica formal, e como
tal,
aspectosfun-damentais como a negação e a cardinalidade não estã,o presentes nesta linguagem.
Actualmente, o projecto SHOE não se encontra em desenvolvimento, mas
fun-cionou como suporte para linguagens posteriores, tais como:
DAML+OIL
e OWL.OIL,
DAML
e
DAML+OIL
A
linguagemOIL5
(Ontology InferenceLayer)
resulta do projecto de inves-tigação On-to-Knowledge financiado pela União Europeia. Surgiu com a necessidadede se
obter
uma linguagem que permitissea
modelagem de ontologiasna
Web,já
que as linguagens antecedentes não possuem formalismos e a semântica necessária de modo a suportarem mecanismos de inferência.A
linguagemDAML6
(DARPA
AgentMarkup
Language)foi
desenvolvidonum projecto da organização americana
DARPA. O
objectivo da linguagem éfaci-litar
a actividade de interacção de agentes de software autónomosna
Web 1291.DAML
permiterestringir
os valores de uma propriedade, além de contar comum
conjunto de
novas propriedadestais como: daml:samePropertyAs, daml:
equirralentTo, daml:inverseOf
edaml:TbansitiveProperty.
DAML+IOL7
DARPA
Agent Marleup Language*Ontology Inference Layersurge nos
finais
de 2000 e resultada
cooperação entre os investigadores america-nose
europeus que desenvolveramo DAML e OIL
respectivamente.O
papel doDAML
no
DAML*OIL
é fornecerum conjunto
deprimitivas
(classes, subclasses,restrições,
etc.)
para marcar
informaçõese
localizáelasdentro
da
estrutura
con-ceitual do
domínio.
Já a
funçãodo
OIL
é fornecer os meios para que possam serrealizadas inferências [20].
owL
A mais recente linguagem ontológica é a
OWL8
(Ontology Web Language), qrrcpermite
incluir
a descrição das classes, as suas propriedades e respectivosrelaciona-mentos. Esta linguagem é uma evolução das suas antecessoras
RDF
eDAML+OIL,
e é hoje uma recomendaçã,o daW3C
principalmente devido à sua semântica formalcapaz de processar conteúdo semântico
na
Web. shttp://www.ontoknowled ge.ory I oil
/
6http: //www.daml.org/ Thttp: //www. w3.org/TR/daml+oil-reference 8 http : //www.w3.org/TR/owl-ref/
cepÍruto
z.
FUNDAMENT,q,ÇÃo
rnóruc1,
16OWL foi
desenvolvida como intuito
de
permitir
àr,s aplicações processar ainformação , em vez de apenas apresentá-la aos utilizadores.
A
linguagemOWL
permite uma maior interoperabilidade entre máquinas do quea
suportada pelos seus antecessoresXML,
RDF
e RDFS, pois forneceum
vo-cabulário adicional para definição de elasses e suas propriedades
e
apresenta umasemântica
formal.
Esta
linguagem fornecetrês
sub-linguagens, cadauma
oferece níveis de expressividade diferentes [39]:r
OWL
Lite
-
Suporte aos utilizadores que necessitamde uma
classificaçãohierárquica e restrições simples. Em relação àrs restrições de cardinalidade, só
permite valores de cardinalidade 0
ou
1.o
OWL DL
-
Suporte aos utilizadores que querem o máximo de expressividade,mantendo completude computacional
(todas
as deduções são computáveis).OWL DL
inclui todo
o vocabulário da linguagemOWL,
mas com certasres-trições (por exemplo, uma classe não pode ser uma instância de outra classe).
E
ainda baseado em lógicas de descrição, que são formalismos paraa
repre-sentaçã,o de conhecimento.
o OWL
full
-
Suporte aos utilizadores que querema
miíxima expressividade e liberdade sintrícticado RDF,
sem preocupações computacionais. Com esta subJinguagem é possível expandir o significado do vocabulárioprêdefinido
doRDF
e da OWL.De acordo com McGuinness et
al.
[39],OWL
F\rll
pode ser considerada uma extensão doRDF,
enquantoOWL
Lite
eDL
podem ser vistos como extensões deconjuntos restritos do RDF.
O
OWL
Lite
tem
vocabulário para:o
igualdades: equivalentClass, equivalentProperty e sameAs;o
ilesi,gualdades:
difrerentFrom, distintMembers e AllDifferent ;o
propriedades: inverseOf, TYansitiveProperty, SymmetricProperty,F\rnctional-Property
e InverseFunctionalProperty;o
restri,ções:minCardinality,
maxCardinality, cardinality;o
intersecçã,o de classes: intersectionOf.Para o
OWL
DL
eFull
é acrescentado o seguinte vocabulário:o
axiomas: oneOf,disjointWith
e equivalentClass;o
expressões booleanas: unionOf, complementOf e intersectionOf;cepÍruto z.
FUIvDÁMElvrl,çÃo TEIHICA
L7Uma
ontologiaem
OWL
é
compostapor
classes, que podem ser definidas como objectos, e pelas suas instâncias. Assim, uma classe descreve um objecto, que podeter
um conjunto de propriedades e relações com outros objectos.No código de uma ontologia
OWL,
as classes são representadas com o prefixoowl:Class.
Esta linguagemutiliza
como predefinição a classeowl:Thing
que é aclasse
raiz
de qualquer hierarquia, epor
isso, todas as classes criadas são membros desta classe.Em seguida é apresentado um exemplo da linguagem OWL para representação de classes, onde a classe
Carro
é uma subclasse deVeículo,
onde é visível a adopção de algumvocabulírio
das suas linguagens antecedentes.<owl:Class
rdf:ID:t'
Carrott ><rdfs:subClassOf
rdf:resourss:t'
f
Veículo" />
</owl:Class>
Em
relaçã,o às propriedades das classes estas dividem-se em dois tipos:o
Object
Properties -
correspondem às relações entre instâncias de duasclas-ses.
o DataType Properties
-
correspondem às relações entreuma
instância deuma classe e
um
literal
outipo
de dados. Por outras palavras, correspondem aosatributos
de uma classe.Continuando o exemplo anterior, se acrescentarmos a classe Pessoa à
hierar-quia
e as propriedadesproprietrírio
ecor,
estas são representadasna
linguagemOWL
do seguinte modo:< owl:
ObjectProperty
rdf lp :tt
proprietiirio"
><rdfs:domain rdf:resource:"
#Pessoa" / ><
rdf:range rdf:resourss:tt
f
Carro)
</owl:
ObjectProperty>
<owl:DataTypeProperty
rdf:ID:"
cor" ><rdfs:domain rdf:resource:tt #
C.arro" f ><rdfs:range
rdf:resource:tt
&xsd;stringt'
/>
<
/owl:DataTypeProperty)
Como se pode verificar, e
tal
como na definição de classes, éutilizado
voctt-bulário
das suas linguagens antecedentes.Na
linguagemOWL
é possívelcriar
instâncias de uma classe. Também cha-madosde
indiuiduals, as instâncias representamum individuo ou objecto
de umaclasse.
Seguindo o exemplo anterior, as instâncias na linguagem
OWL
sãocl,pÍruto z.
FUivDÁMENr,l,çÃo
TE)RICA
18<owl:Thing rdf:abou1:"
fl,uis"
)
<rdf:type rdf:resourgs:tt
fPessoa"
/>
<proprietario rdf:resource:tt #oMeuCarro"
/>
</owl:Thing>
(Carro
rdf:about:t,
f
oMeuCarro"
><rdf:type rdf:resource:t' &owl;Thing"
/>
<cor>preto<f cor>
</Carro>
O código OWL acima, representa uma instância da classe Pessoa, identificada
por
Luis,
que é proprietário da instânciaoMeuCarro,
que é uma classe deCarro,
que
por
sua vez tem uma cor que está descrita com astring
preto.
Em 2009 surgiu a nova versão do
OWL,
oOWL2e
que ainda está em fase dedesenvolvimento, estando nesta
altura
como candidata a recomendação pela W3C.A
versão OWL2 possui três novos perfis:o OWL
2 EL
-
Destina-sea
aplicações que possuamum
grande número de propriedadese/ou
classes;r
OWL
2
qL
-
Destina-se a aplicações queutilizam
grandes volumes de dados;o OWL
2
LR -
Destina-sea
aplicações que exigem raciocínio evolutivo, semsacrificar demais o poder expressivo.
Além
dos novos perfis,a
nova versãodo
OWL
possuí mais funcionalidadestais
como:o
chaves (keys);o
redes de propriedades;o
tipos de dados mais ricos, intervalos entre dados;o
restrições de cardinalidade qualificada;.
novas propriedades tais como: asymmetric e reflexivelo
melhores capacidades de anotação.Pretendeu-se apena"s fazer uma pequena introdução a esta nova versão, pois esta versão ainda está em desenvolvimento
e
actualmente a versão antiga éa
lin-guagem para representar ontologias recomendada pela
W3C.
Comotal,
para uma descrição mais pormenorizada desta nova versão, recomenda-se aleitura do
docu-mento referido ao longo do texto.
e
ctpÍruto
z.
FUNDAMENTI,çÃo
TEIRICA
192.2.5
Ferramentas
Actualmente,
existem diversas ferramentas quepermitem ao
utilizador
deforma
fácil,
construir
e
manipular
ontologias.
Estas ferramentaspermitem
defi-nir
classes,atributos
para classes, a>riomas e restrições.Muitas
destas ferramentas possuemuma
interface gráfica, quevai
ao encontro dos padrões de conformidadeutilizados
na
Web 1371.Existem muitas ferramentas para o desenvolvimento de ontologias, tais como:
Protégé,
OntoEdit,
Ontolingua,
WebODE, SymOntoX,WebONTO,
OilEd,
DOE, OntoBuider entre muitasoutras.
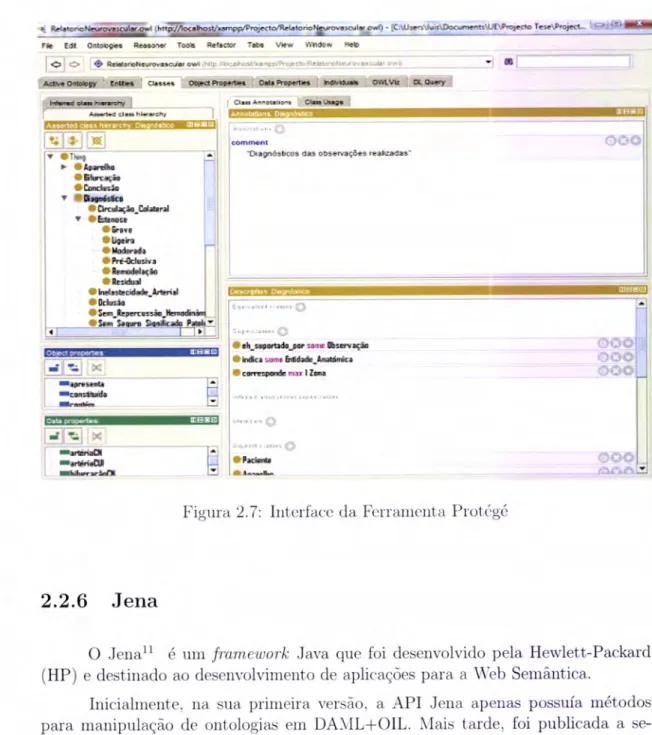
Nesta secção é apresentada a ferramenta Protégé, porque segundo Cardoso [13] é a ferramenta maisutilizada
no desenvolvimento de ontologias, e porquefoi
a ferramenta utilizada no desenvolvimento do trabalho apre-sentado nesta dissertação.Protégé
O
Protégélo
é uma ferramenta de desenvolvimento de ontologias,desenvol-vido
pelo
departamentode informática
médicada
Universidadede Stanford,
naCalifórnia, Estados Unidos, e está disponível para a,cesso
livre
e em vários sistemasoperacionais tais como Windows,
Linux, Unix,
entre outros. Esta ferramentaauxilia
os utilizadores na construção de bases de conhecimento e ontologias.
Desenvolvido em Java, possuí uma interface, como exibida na figura 2.7,
qte
permite
o
acessoà
barra de
menuse barra
de ferramentas, alémde
módulos de navegação e edição de classes,atributos,
relações, instâncias e pesquisas na base de conhecimento, propiciando a entrada de dados e a recuperação das informações [48].Por
seruma
ferramentacom
códigoaberto, permite a
sua integração com diversas aplicações [46]. Além disso, permite que os utilizadores adicionem módulos(Plug-ins) com funcionalidades que não estão definidas no Protégé.
Um
dosrecur-sos aproveitados e que é hoje em
dia um
dos módulos do Protégé, é o Ontoviz, umcomponente que
faz
com que o gerador de gráficos Graphviz produza gráficos comas heranças, instâncias e outros
tipos
de relacionamento.O
Protégépermite
aindaimportar
ou exportar
ontologiasde/para
diversos formatostais
comoRDF(S),
XML,
XML
Schema e OWL.lohttp:
c,q,pÍruLo
2.
Ft/tüDAÀíElü TAÇÃo
TE)RI1A
20.q r.tr.!lÉEÉ r@EqÉ!4 - tE"rhtorrr,iiF.-.!,ü$f,\r'lrtíís re\e.i!sr,- tgdllE
rh ln onbto.r |tGxtr Íbot ltatlô. Íü vht lÍvlxha íÜr
<) (& ?il ClrltÇi ClaE Ai.Otaitlrrt l^
oôo
ôa
ô{}
0ti
ô{3ô
-Orâ lrrôücoE drt o0rcnnçücr
ralhtldÜ}-É cr ., rlrnl t r rrrçr {O J t!r .-rcEnsl|lur IraníÉr rrrüric0U rHlurrllalll -v I ú-rpctrürlr ron: lcrvrflo lhtce rnr tú*-ldrb |JcltçoÉmrr lh .:. r .: tr.clrn I lasrL
Figura 2.7: Irrter'Íacc da FerratIICIIta Protcigó
2.2.6
Jena
O
Jenall
étm
framework
Java quefoi
desenvolvido pela Hewlett-Packard(HP)
e destinado ao desenvolvimento de aplicações para a \Meb Semântica.Inicialmente, na
suaprimeira
versão,a
API
Jena apenas possuía métodospara
manipulação de ontologias emDAML+OIL.
Mais tarde,
foi
publicadaa
se-gunda versão do
API
Jena, onde foram acrescentados métodos que vêmpermitir
amanipulação de ontologias em RDFS e
OWL
[1a].Esta segunda versão da
API
Jena forneceum
pacote específico denominadoAPI
Jena2
Ontology, que dispõe de duas classes específicas para manipulação deontologias:
a
OntClasse
a
ObjectProperty
que correspondem respeetivamente à classe Java que representa a classeOWL
e as propriedades de uma classeOWL
[32].Na
API
Jena, para cada uma das linguagens de ontologias existentes,exis-tem
parâmetros com sintaxes diferentes,por
exemplo, no parâmetro da linguagemDAML, o URI
para uma
propriedadedo objecto é
daml:ObjectProperty
e
nalinguagem
OWL
éowl:ObjectProperty
[32].ri
v rl|Éil lOrcdrdo-GjlrJ OÊ{ffirr afrdlr$ tHC Ohd;Iot*-&§idaH.
V r'.aliçrl # lloder-dr Y lBrom e brYr -fa 11http:I
ljena.sourceforge. \etf
coÍnntGnI Oltàt > Ofurúr f lfrcT-(lbrdrrar a, _tlcApÍruLo
2.
FUIüDAÀ,íE^ITAÇÃo
TEIRI:A
2LCom este framework,
é
assim possível realizar inferências emanipular
umaontologia que possua as especificações da Web Semântica como
RDF
e a linguagemowl.
2.2.7
Ontologias Médicas
A
constante evolução das tecnologias,tem
provocadoum
grande aumentode informação
na
áreada
saúde, originandouma
base de conhecimento cada vezmaior.
Esta informação está naturalmente descentralizada e a sua integração é umdos grandes desafios para a área da informática em saúde. O facto de muitas
insti-tuições/médicos
utilizarem
vocabulários próprios ou simplesmente não codificarem algumas informações, aumenta a complexidade deste problema.A
necessidade de aproveitar a informação desta área,tem feito
com que nosúltirnos anos sc vcnha a procurar soluções para padrorrizar essa ilrformação. Urna das
soluções encontradas é através do uso de ontologias [43]. Além disso, têm também
sido
desenvolvidosuma
enorme variedadede
sistemase
vocabuláriosde modo
aagrupar
c
categorizar tcrmos rnédicos,tais
corno:UMLSl2
(Un'ified MedicalLan-gul,ge System),
MeSH13
(Medi,cat Subject Headings),SNOI\'IEDIa
(Systemati,zedNomenclature of Medici,ne), entre outros.
Apesar destes sistemas e vocabulários serem classificados
por
muitos autores como ontologias [43], são utilizados na maior parte das vezes como classificadores determos, no
auxilio
à construção de ontologias e à paclronização dos termos médicosdentro destas ontologias.
Nesta secção é apresentado o UMLS, por ser um dos classificadores de termos com maior dimensão e dos mais utilizados e referidos na
literatura,
e porquefoi
oclassificador utilizado no descrrvolvirnento do trabalho apresentaclo nesta dissertação.
UMLS
O Unified Medical Language System (UMLS) tem sido desenvolvido pela
Nati-onal
Library
of Medicine(NLM)
desde 1986. E um sistema que resolve os problemasda semântica na área médica, através de milhares de conceitos provenientes de
di-versos vocabulários biomédicos [5].
Este sistema destina-se
a ajurlar
os profissionais de saúdec
investigadores biomédicosa utilizar
informações de diferentes fontes atravésdo
mapeamento demilhares de terminologias [50].
A
NL\,Í,
permite
o
acessoà
basede
dadosdo UMLS,
atravésde
chama-das
ao
UMLSKS
(UMLS
Knowledge Sources)quc
ó
cornpostopor
três
bases rleconhecimento:
o
Metathesaurus, uma rede semântica eum
especialistaléxico. A
padronização da informaçãoda
área médica ocorre através do Metathesaurus, que12http: I I www.nlm.nih.gov/research/umls/ 13http: I I www.nlm. nih.gov/mesh lahttp: I I www.snomed.org/
![Figura 2.2: IJttLização de Agentes Computacionais na \Àreb Semântica [2]](https://thumb-eu.123doks.com/thumbv2/123dok_br/15230724.1021771/19.830.92.745.233.1064/figura-ijttlização-de-agentes-computacionais-na-àreb-semântica.webp)

![Figura 2.8: Etapas da Vlineração de Têxtos [53]](https://thumb-eu.123doks.com/thumbv2/123dok_br/15230724.1021771/34.828.183.721.78.567/figura-etapas-da-vlineração-de-têxtos.webp)
![Figura 3.1: Exemplo de um Relatório Radiológico [1]](https://thumb-eu.123doks.com/thumbv2/123dok_br/15230724.1021771/40.831.228.649.95.737/figura-exemplo-de-um-relatório-radiológico.webp)