FUNDAÇÃO GETÚLIO VARGAS
ESCOLA DE ECONOMIA DE SÃO SAO PAULO
BÁRBARA CONTE
MODELAGEM
DO
PRODUTO
INTERNO
BRUTO
BRASILEIRO UTILIZANDO MODELOS NÃO LINEARES
BÁRBARA CONTE
MODELAGEM
DO
PRODUTO
INTERNO
BRUTO
BRASILEIRO UTILIZANDO MODELOS NÃO LINEARES
Dissertação apresentada à Escola de Economia de São Paulo da Fundação Getúlio Vargas, como requisito para obtenção do título de Mestre em Economia.
Campo de conhecimento: Macroeconomia
Financeira
Orientador: Prof. Dr. Emerson Fernandes Marçal
Conte, Bárbara..
Modelagem do Produto Interno Bruto Brasileiro Utilizando Modelos Não Lineares / Bárbara Conte. - 2013.
35 f.
Orientador: Emerson Fernandes Marçal
Dissertação (MPFE) - Escola de Economia de São Paulo.
1. Produto interno bruto - Brasil. 2. Modelos não lineares (Estatística). 3. Ciclos econômicos. 4. Algorítmos. I. Marçal, Emerson Fernandes. II.
Dissertação (MPFE) - Escola de Economia de São Paulo. III. Título.
BÁRBARA CONTE
MODELAGEM
DO
PRODUTO
INTERNO
BRUTO
BRASILEIRO UTILIZANDO MODELOS NÃO LINEARES
Dissertação apresentada à Escola de Economia de São Paulo da Fundação Getúlio Vargas, como requisito para obtenção do título de Mestre em Economia.
Campo de conhecimento: Macroeconomia
Financeira
Orientador: Prof. Dr. Emerson Fernandes Marçal
Data de aprovação: 19/08/2013
Banca Examinadora:
__________________________________________ Prof. Dr. Emerson Fernandes Marçal
(Orientador) (EESP – FGV)
__________________________________________ Prof. Rogério Mori
(EESP – FGV)
__________________________________________ Prof. Marislei Nishijima
AGRADECIMENTOS
Gostaria de agradecer aos meus pais e minha irmã pelo incentivo à realização do curso de mestrado e ao incondicional apoio durante toda a realização do mesmo.
Agradeço também aos colegas de classe com quem compartilhei momentos de estudos, debates e distrações. Em especial, às sólidas amizades que construí ao longo desses dois anos de curso e que espero manter por muitos anos.
Não poderia deixar de agradecer à empresa e toda a equipe da Berkana Patrimônio/Iron House Fund pela compreensão com os horários de estudo e pelo apoio financeiro para a realização do curso.
Aos professores da FGV, que tive a oportunidade de conhecer durante o curso, pelos ensinamentos e troca de experiências, faço meu profundo agradecimento. Um agradecimento especial ao meu orientador, Emerson Fernandes Marçal, pela sugestão do tema proposto, ajuda e paciência ao longo do processo de elaboração do trabalho.
RESUMO
O trabalho tem como objetivo aplicar uma modelagem não linear ao Produto Interno Bruto brasileiro. Para tanto foi testada a existência de não linearidade do processo gerador dos dados com a metodologia sugerida por Castle e Henry (2010). O teste consiste em verificar a persistência dos regressores não lineares no modelo linear irrestrito. A seguir a série é modelada a partir do modelo autoregressivo com limiar utilizando a abordagem geral para específico na seleção do modelo. O algoritmo Autometrics é utilizado para escolha do modelo não linear. Os resultados encontrados indicam que o Produto Interno Bruto do Brasil é melhor explicado por um modelo não linear com três mudanças de regime, que ocorrem no inicio dos anos 90, que, de fato, foi um período bastante volátil. Através da modelagem não linear existe o potencial para datação de ciclos, no entanto os resultados encontrados não foram suficientes para tal análise.
ABSTRACT
This paper aims to apply a nonlinear model to the Brazilian GDP. To achieve this goal we tested the existence of non-linearity of the data generating process with
the methodology suggested by Castle and Henry (2010). The test verifies the
persistence of the nonlinear regressors in an unconstrained linear model. Next, the series is modeled as an Autoregressive Model Threshold using the general-to-specifs approach to select the model. Autometrics is the automatic selection algorithm used to choose the nonlinear model. The results indicate that the Gross Domestic Product of Brazil is best explained by a non-linear model with three regime changes that occur in the early '90s, which, in fact, was a period quite volatile. Through modeling nonlinear exists the potential for cycle dating, however the results were not sufficient for such analysis.
LISTA DE FIGURAS
Figura 1 – Série do log da diferença do PIB Brasil...11
Figura 2 – Função de Autocorrelação do log da diferença do PIB Brasil...11
Figura 3 – Período de expansão do PIB ...15
Figura 4 – Período de retração do PIB...16
Figura 4 – Paríodo de crescimento intermediário ...16
Figura 4 – Modelo linear ...21
LISTA DE TABELAS
Tabela 1 – Teste de não linearidade...13
Tabela 2 – Modelo não linear com significância de 0,001...14
Tabela 3 – Resultado testes para modelo não linear com significância de 0,001...14
Tabela 4 – Resultado dos critérios de informação...14
Tabela 5 – Modelo não linear com significância de 0,05...23
Tabela 6 – Resultado testes para modelo não linear com significância de 0,05...24
Tabela 7 – Modelo não linear com significância de 0,01...25
SUMÁRIO
1 Introdução...1
2 Revisão da Literatura...3
3 Metodologia...6
3.1 Teste de Linearidade...6
3.2 Threshold autoregressive regression (TAR)...9
3.3 Algoritmo Autometrics...10
3.4 Base de dados...8
4 Resultados Empíricos...12
4.1 Teste de não-linearidade...12
4.2 Estimação do TAR...13
5 Conclusão...18
Referências...19
1
1 Introdução
A estimação de modelos econométricos é tão importante quanto desafiadora. A investigação em que é medida a série do Produto interno bruto pode ser melhor descrita por processos não lineares. A importância deste tipo de estudo decorre das possibilidades econômicas de ganhos de previsão e melhor entendimento do ciclos econômicos do Brasil.
Neste trabalho, o foco será no potencial da informação que modelos não-lineares podem tazer na datação de ciclos, dado certo interesse na história econômica brasileira.
Há uma forte influência sobre o bem-estar das pessoas causada por oscilações na atividade econômica do país principalmente se forem inesperadas. A melhor compreensão do exato momento do ciclo econômico em que se encontra o país pode auxiliar, por exemplo, as decisões de investimento dos empresários que podem optar por reavaliar projeções de vendas previamente feitas. A política pública, também, pode se beneficiar do prévio conhecimento do início de um novo ciclo econômico a fim de avaliar melhor quais seriam as políticas mais adequadas para o país.
O objetivo deste trabalho é investigar a existência da não linearidade da série trimestral do Produto Interno Bruto do Brasil e modelá-la com um modelo autoregressivo com limiar para verificar a existência de diferentes regimes. A modelagem com limiar será avaliará se é possível realizar a datação de ciclos econômicos. O Autometrics será o algoritmo utilizado para a seleção automática do modelo. Por fim, serão utilizados critérios de informação para método de comparação entre o modelo linear e o não linear com o intuito de encontrar qual melhor representa a variável em análise. O período de análise será de 1980 a 2012. Nos últimos anos, surgiu uma nova abordagem em termos de modelagem. É o conceito geral para específico, que seleciona um modelo a partir das inúmeras variáveis explicativas que em muitos casos chegam a exceder o número de observações. O procedimento para seleção automática do modelo é o algoritmo Automatrics (Doornik, 2009) contido no software Oxmetrics.
2
3
2 Revisão da Literatura
A análise da dinâmica do PIB brasileiro através de uma abordagem não linear ainda não foi muito explorada na literatura brasileira. Castelar, Linhares e Pena (2008) encontraram evidência da existência de relação não linear entre a taxa de crescimento econômico e a taxa de formação bruta de capital fixo brasileira, o que, segundo os autores, sugere que a influência dos investimentos sobre o PIB do país é limitada no longo prazo e, portanto, o Brasil atingiria no máximo um crescimento econômico dos países do leste Asiático e Pacífico.
O trabalho de Lima e Simonassi (2005) utiliza a abordagem não linear para analisar a série de déficit público e contribuir para a temática da sustentabilidade da dívida pública do Brasil. Com isso, encontram evidências que o limiar para atuação do governo via medidas intervencionistas de austeridade fiscal ocorre apenas quando o aumento do déficit orçamentário atinge 1,7% do PIB, de acordo com dados que cobrem o período de 1947 a 1999.
No que tange a abordagem de datação de ciclos no Brasil, Chauvet (2001) é uma das grandes autoras sobre o tema. A autora aplicou diferentes métodos para analisar e datar ciclos econômicos, porém, em particular, utilizou um modelo de mudanças de Markoviana para modelar o PIB brasileiro no período de 1980:01 a 2000:01 para série trimestral e de 1900 a 1999 para a série anual. Os resultados encontrados pelos diferentes métodos apontam uma cronologia similar, porém há assimetrias na duração e amplitude das diferentes fases econômicas do Brasil. No caso, da modelagem Markoviana foi identificado que os ciclos de recessão e baixo crescimento possuem curta duração. Além disso, a autora comparou as previsões fora da amostra do modelo de mudanças de Markov com um modelo linear e encontrou que o modelo não linear apresenta melhor poder de previsão do que um modelo linear.
4
com duração média de 15,9 trimestres entre picos e picos e de 13,5 trimestres de vales e vales. Sendo que, a maior recessão durou 11 trimestres e ocorreu entre o terceiro trimestre de 1989 e o primeiro trimestre de 1992.
A modelagem geral para específico ganhou força com o avanço da capacidade computacional e sendo recente, ainda há pouca literatura explorando tais temáticas.
No Brasil, o trabalho de Stocco (2009) utilizando o modelo de seleção automática Autometrics para averiguar quais os fundamentos macroeconômicos que determinam o comportamento do Q de Tobin. No ambiente internacional a literatura é mais extensa e se divide entre críticas ao método e aplicações práticas.
Castle e Henry (2010) desenvolveram uma estratégia para a seleção de modelos não-lineares atrvés do algoritmo Autometrics. Caso o modelo geral irrestrito (General Unrestrict Model - GUM) rejeite a hipótese nula do teste de linearidade, então eles propõem uma transformação polinomial dos regressores, na qual todas as funções são tiradas da média duplamente antes de serem inseridas no GUM com o intuito de resolver o problema de colinearidade. Além disso, incluem um conjunto de indicadores de impulso no GUM para remover pontos extremos (outliers).
Tal estratégia é aplicada na série de retorno de educação dos EUA retirada do Censo de 1980 e, a conclusão de Castle e Henry (2010) é que a modelagem sem a preocupação com colinearidade e outliers, por exemplo, resulta em modelos pobres em relação ao encontradado utilizando a seleção automática do Autometrics. Reade e Volz (2011) realizaram um estudo com o intuito de modelar a inflação na China aplicando a abordagem geral para específico. Para tanto utilizaram dados dos referentes à economia doméstica e internacional, e o resultado encontrado sugere que a China sofre impactos da política monetária europeia, enquanto consegue se isolar de choques vindo dos EUA para a surpresa dos estudiosos.
Um estudo de Silverstovs, Smirnov e Tsukhlo (2012) também utilizou o processo de seleção automática Autometrics para encontrar um modelo para previsão da produção industrial na Rússia utilizando pesquisas de sentimento do empresariado. O modelo resultante do Autometrics apresentou maior precisão nas projeções do que o modelo-referência que era um autoregressivo univariado.
5
contra um selecionado previamente. A autora ilustra o estudo com três exemplos, sendo um deles a modelagem do consumo no Reino Unido e, conclui que o Autometrics é uma ferramenta capaz de encontrar um modelo parcimonioso quando há existência de muitas possíveis variáveis explicativas.
6
3
Metodologia
A metodologia a ser utilizada para análise da série do Produto interno bruto do Brasil consiste em duas partes. Inicialmente, será realizado um teste para verificar a linearidade da série e caso o resultado aponte a presença de não linearidade, a série será modelada por um modelo com limiar (TAR) através do algoritmo Autometrics. A seguir são explicados em detalhe cada procedimento realizado.
3.1 Teste de linearidade
O teste será baseado no trabalho proposto por Castle e Hendry (2010) que parte de um modelo geral irrestrito não-linear que inclui K candidatos que estão contidos em g de alguma forma não-linear:
(1)
Sendo que, uma boa aproximação para representar a função não linear é a expansão de Taylor (função polonimial), segundo os próprios autores citam:
“[…] Polynomial functions are often used in economics because of Weierstrass’s approximation theorem whereby any continuous function on a closed
and bounded interval can be approximated as closely as one wishes by a polynomial
[…]”
7
(2)
Com isso, a proposta final para utilização é:
(3)
Sendo, K regressores lineares potenciais, , onde um indicador (IIS - explicado a diante) para a observação i-nésima. No entanto, Castle e Henry (2010) ainda fazem algumas sugestões para que o processo de seleção do modelo geral para específico através do Autometrics gere um melhor resultado.
Na estimação da equação dada por (3), para tratar o problema de colinearidade são utilizados dados double de-meaning. Caso a variável colinear adicional fosse incluída, esta agregaria pouca informação de qualidade, e ainda, obstruiria a informação relevante já existente.
A regra double de-meaning aplicada por Castle e Henry (2010) consiste em, inicialmente, calcular a média da variável zi e subtraí-la da própria variável. Com
isso, os termos lineares (zi z)permanecem, mas em seguida é feito o mesmo
procedimento de subtração da média para 2
i
z e, então os termos quadráticos são
2 2 )] ( [ )
(zi z E ziz , resultando em variáveis com média zero.
8
Com o uso destas dummies é possível detectar e remover esses outliers, deixando no modelo apenas as variáveis que, de fato, acrescentam informações relevantes para o modelo.
O método de dummies de saturação é um procedimento proposto por Hendry e Johansen (2008) para analisar a constância do modelo. A realização do teste dos parâmetros ocorre sem que se saiba previamente a duração, magnitude e números de quebras na série, Além disso, tais quebras de série podem ocorrer em qualquer período da amostra. Os indicadores de saturação consistem em dummies com valor zero ou um. É acrescentada uma dummy para cada valor presente na amostra, logo em uma amostra de tamanho N serão acrescentadas N dummies. No entanto, não é viável um modelo no qual o número de dummies é igual ao número de dados na amostra. Por isso, as dummies são incluídas em blocos no modelo e esta é a essência do método de dummies de saturação (IIS).
A seguir, a amostra é divida em dois grupos, por exemplo, e em cada grupo há um conjunto de dummies, que terão suas significâncias avaliadas pelo algoritmo de seleção Autometrics. Após a seleção das dummies significantes de cada grupo, surgem dois modelos parciais para explicar o conjunto de dados.
A junção dos modelos parciais, que contém apenas as dummies relevantes
de cada período da amostra, gera um ”novo” modelo. Por fim, este novo modelo
será submetido ao Autometrics para que seja realizada uma nova seleção das dummies significantes.
Sob a hipótese nula de que não há outliers, a N dummies serão retidas, em média, para um nível de significância . Para mais detalhes sobre o método e propriedades, ver Hendry (2008) e Ericson (2012). Vale resaltar, que o Autometrics lida muito bem com a questão de existirem mais observações do que variáveis, como será revisto mais a frente neste estudo.
9
se ao final da estimação o número total de regressores retidos no modelo for superior a cinco, então muito provavelmente haverá algum regressor relevante.
3.2
Threshold autoregressive regression
(TAR)O modelo TAR desenvolvido por Tong (1978) é um modelo para séries de tempo não-linear com vários regimes. O modelo descreve uma função não-linear aos pedaços, nas quais os parâmetros do modelo auto-regressivo linear são modificados dependendo da região em que as variáveis estão inseridas.
O modelo TAR pode ser escrito como uma composição de L modelos autorregressivos, sendo que cada um se torna ativo dentro da região em que se encontra o valor da variável :
(4)
Sendo, processo da série, a variável de estado unidimensional e ( uma parte do conjunto . O vasto número de modelos possíveis é decorrente da ampla possibilidade de valores que a variável pode ter.
10
3.3
Algoritmo
Autometrics
A ferramenta Autometrics se baseia na abordagem de modelagem denominada geral para específico, sendo um algoritmo que realiza uma seleção automática de um modelo que não possua má-especificação entre inúmeras combinações de regressores que poderiam explicar a variável em estudo.
A partir da definição pelo usuário de um modelo geral irrestrito (GUM) baseado em estudos anteriores ou teorias disponíveis, é preciso especificar as defasagens das variáveis, os testes de diagnósticos e seus respectivos níveis de significância. Esta parte de calibragem do algoritmo é um fator de elevada importância, pois é responsável por direcionar os caminhos de busca do algoritmo.
Considerando isso tudo, o GUM pode ser propriamente utilizado com o intuito eliminar variáveis irrelevantes. O algoritmo começa a testar os modelos até o momento em que uma redução dominante seja selecionada. Por fim, será verificada a adequação do modelo aos dados.
3.4 Base de dados
Inicialmente será testada a presença de não linearidade da série trimestral dessazonalizada do Produto Interno Bruto brasileiro coletado pelo Instituto Brasileiro de Geografia e Estatística (IBGE) para o período de 1980 a 2012. A série ajustada sazonalmente será tradada como logaritmo da diferença, deste modo não haverá problema de não-estacionaridade.
11
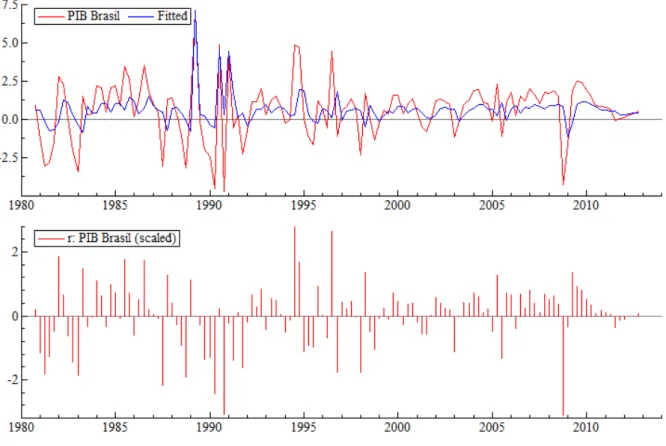
Figura 1 – Série do log da diferença do PIB Brasil
Através do cálculo e análise da função de autocorrelação (figura 2) verifica-se que há baixa evidência de correlação serial.
12
4 Resultados empíricos
A seguir será apresentado o resultado do teste de linearidade, seguido pela modelagem e escolha do melhor modelo para explicar a dinâmica do PIB do Brasil.
4.1 Teste de não-linearidade
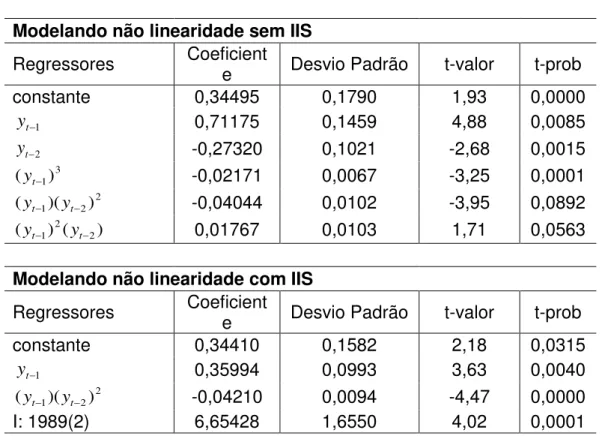
O resultado do teste de não linearidade proposto por Castle e Henry (2010) sugere que o processo gerador dos dados da série do PIB brasileiro possui não linearidade. O teste é realizado em duas etapas. Primeiro é estimado o modelo com constante, regressores defasados e regressores na forma polinomial, cujo resultado pode ser visto na parte superior da tabela 1. A partir do modelo encontrado, é estimado um novo modelo acrescentando as dummies de saturação, com o intuito de verificar se os regressores permanecem no modelo. Caso os regressores encontrados na primeira modelagem não sejam relevantes, eles não resistirão à segunda rodada.
13
Tabela 1 – Teste de não linearidade
Testando não linearidade
Modelando não linearidade sem IIS
Regressores Coeficiente Desvio Padrão t-valor t-prob
constante 0,34495 0,1790 1,93 0,0000
1
t
y 0,71175 0,1459 4,88 0,0085
2
t
y -0,27320 0,1021 -2,68 0,0015
3 1)
(yt -0,02171 0,0067 -3,25 0,0001
2 2 1)( )
(yt yt -0,04044 0,0102 -3,95 0,0892
) ( )
(yt1 2 yt2 0,01767 0,0103 1,71 0,0563
Modelando não linearidade com IIS
Regressores Coeficiente Desvio Padrão t-valor t-prob
constante 0,34410 0,1582 2,18 0,0315
1
t
y 0,35994 0,0993 3,63 0,0040
2 2 1)( )
(yt yt -0,04210 0,0094 -4,47 0,0000
I: 1989(2) 6,65428 1,6550 4,02 0,0001
4.2 Estimação do TAR através do algoritmo
Autometrics
O resultado da modelagem não linear para o PIB do Brasil através da abordagem geral para específico e da seleção automática via Autometrics está apresentado na tabela 2.
Foi utilizado um nível de significância de 0,1% e quando
14
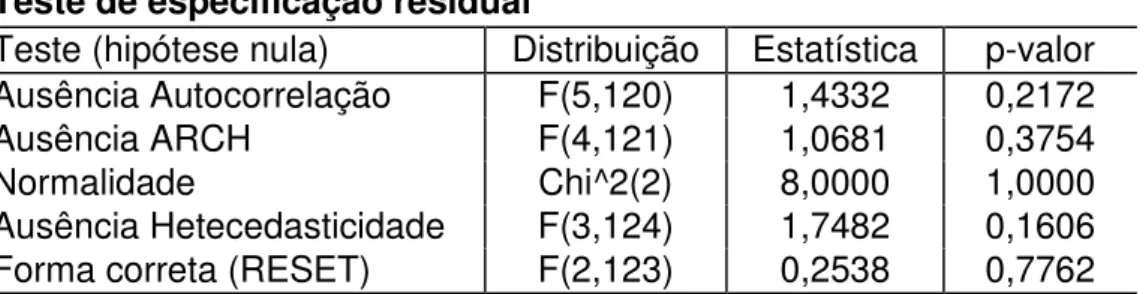
Nesta modelagem também foi considerado o método de dummies de saturação (IIS). No final a dummy referente ao 2º semestre de 1989 foi mantida como também havia sido captada no modelo linear. O modelo proposto passou em todos os testes de especificação propostos. (Ver tabela 3).
Os modelos encontrados com demais níveis de significância estão nas tabelas 5 a 8 no apêndice.
Tabela 2 – Modelo não linear com significância de 0,001
Modelando TAR - versão 1
Com IIS e com significância de 0,001 - Modelo final
Regressores Coeficiente Desvio Padrão t-valor t-prob
Constante 0,30148 0,1545 1,95 0,0532
D3 5,72330 1,2470 4,59 0,0000
D(yt1)130 0,33871 0,0899 3,77 0,0003
I: 1989(2) 6,45488 1,6290 3,96 0,0001
Tabela 3 – Resultado dos testes de especificação
Teste de especificação residual
Teste (hipótese nula) Distribuição Estatística p-valor
Ausência Autocorrelação F(5,120) 1,4332 0,2172
Ausência ARCH F(4,121) 1,0681 0,3754
Normalidade Chi^2(2) 8,0000 1,0000
Ausência Hetecedasticidade F(3,124) 1,7482 0,1606
Forma correta (RESET) F(2,123) 0,2538 0,7762
Por fim, quando comparamos o modelo linear e o modelo não-linear apresentados nas tabelas 1 e 2, respectivamente, por seus critérios de informação é possível concluir pela superioridade do modelo não-linear.
Tabela 4 – Resultado dos critérios de informação
AIC SC HQ
Modelo linear 3,9936 4,0379 4,0116
Modelo não linear 3,8360 3,9247 3,8720
15
O modelo final é um modelo no qual ocorrem três mudanças de regime como pode ser verificado abaixo:
(5)
Os limiares encontrados (7,104688 e -4,6982) são os limiares que ativam e desativam as equações explicativas da série de crescimento do PIB do Brasil. Quando o crescimento econômico é muito elevado em um período , no próximo período haverá certa estabilização no crescimento. Caso haja uma queda no PIB, o próximo período é marcado por uma retomada no crescimento. Por fim, caso o crescimento oscile entre os limiares, a equação explicativa do PIB é a segunda apresentada em (5).
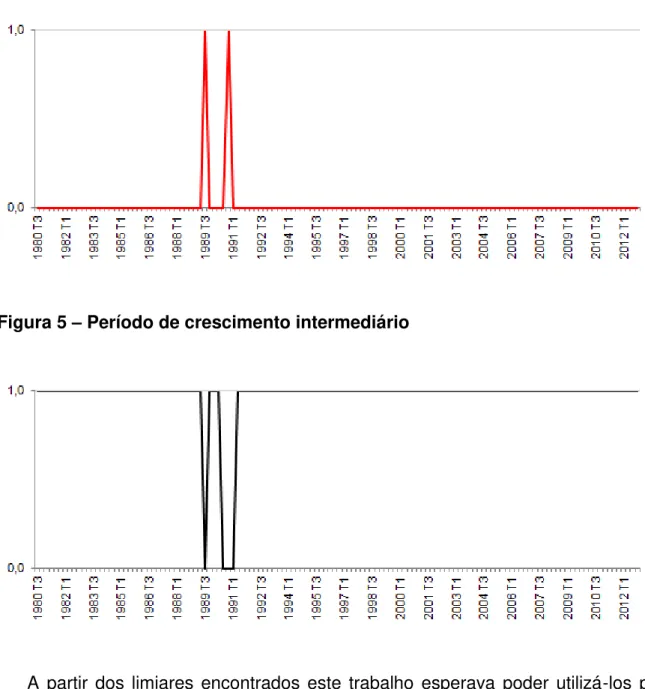
Nas três figuras a seguir é possível perceber o exato momento em que cada equação explicativa do Produto Interno Briuto do Brasil é ativada, ou seja, é representada pelo valor 1 nos gráficos.
16
Figura 4 – Período de retração do PIB
Figura 5 – Período de crescimento intermediário
A partir dos limiares encontrados este trabalho esperava poder utilizá-los para datação de ciclo. O modelo TAR encontrado não foi capaz de localizar os 7 ciclos de negócios completos reportados pelo CODACE.
No entanto, os limiares encontrados correspondem aos períodos do 2º trimestre de 1989 e 4º trimestre de 1990, respectivamente, que são momentos que compreendem ao período da maior recessão brasileira, segundo CODACE. Foi um período de alta volatilidade no Produto Interno Bruto brasileiro que compreende ao período de instabilidade macroeconômica com inflação descontrolada após sucessivos planos econômicos fracassados.
17
18
Conclusão
Neste trabalho foi modelada a série do crescimento do Produto Interno Bruto do Brasil utilizando modelagem não linear e o procedimento de seleção automática através do algoritmo Autometrics. A utilização de um modelo com limiar apontava potencial para datação de ciclos econômicos pelos quais a economia brasileira passou nas últimas décadas. Com a utilização da metodologia do Autometrics foi possível aplicar uma abordagem geral para específico, a qual permite a inclusão de um vasto número de potenciais variáveis capazes de explicar o fenômeno de interesse e ao final da seleção automática apenas as variáreis são retinas.
19
REFERÊNCIAS
CASTELAR, Ivan; LINHARES, Fabrício, PENNA, Christiano. Investimento e os limites da aceleração do crescimento. Encontro Nacional de Economia - Anpec,
2008.
CASTLE, Jennifer L.; HENRY, David F. Automatic Selection for Non-linear Models.
Discussion Paper Series, University of Oxford, n. 473, 2010.
CHAUVET, Marcelle. The Brazilian Business and Growth Cycles. Revista Brasileira de Economia, EPGE/FGV,v. 56, n. 1, p. 75-106, 2002.
CHOW, G. H. Selection of Econometric Models by the Information Criteria.
Proceedings of the Econometric Society European Meeting 1979: Selected
Economic papers, 1981.
DOORNIK, J. A.; Autometrics. In Castle, J.L. and Shephard, N., The Methodologhy
and Practice of Econometrics, Oxford University Press, p. 88-121, 2009.
ERICSON, N. R. Detecting crises, jumps, and changes in regime (Draft). Board of Governors of the Federal Reserve System, Washington, D.C., 2012.
HENDRY, D. F.; JOHANSEN, S.; SANTOS, C. Automatic Selection of Indicators in a Fully Saturated Regression. Computational Statistics, n. 33, p. 317-335, 2008.
KROLZIG, Hans-Martin; HENRY, David F. Computer Automation of General-to-Specific Model Selection Procedures. Journal of Economic Dynamics and Control, v. 25, n. 6-7, p. 831-866, 2001.
LIMA, L.Renato; SIMONASSI, Andrei. Dinâmica não-linear e sustentabilidade da dívida pública brasileira. Pesquisa e Planejamento Econômico, Ipea, v. 35, n. 2,
20
PENG, Sisi. Evaluating Automatic Model Selection. Master thesis in Estatistics
Uppsala Universitet, 2011.
READE, J.James; VOLZ, Ulrich. From the General to the Specific – Modeling Inflation in China. Applied Economics Quarterly, v. 57, n. 1, p. 27-44, 2011.
TONG, Howell. On a threshold model. In Chen, C. Pattern recognition and signal processing, Sijthoff & Noordhoff, p. 575-586, 1978.
SILVERSTOVS, Boriss; SMIRNOV, Sergey; TSUKHLO, Sergey. Assesing Forecasting Performance of Business Tendency Surveys during the Great Recession: Evidence for Russia. WorkingPapers, KOF, n. 306, 2012.
21
APÊNDICE
22
23
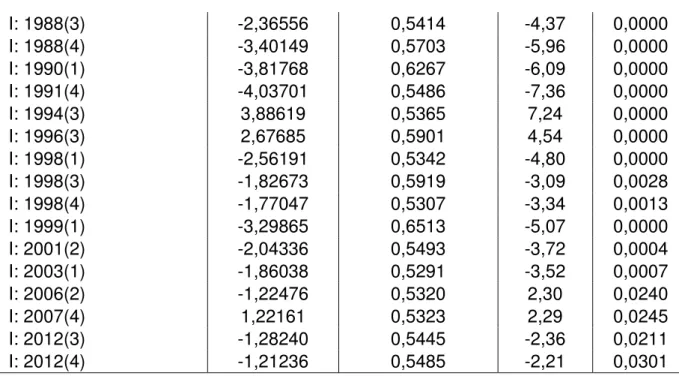
Tabela 5 – Modelo não linear com significância de 0,05
Modelando TAR – versão 2
Com IIS e com significância de 0,005
Regressores Coeficiente Desvio Padrão t-valor t-prob
Constante -0,49334 0,4077 -1,21 0,2300
D18 5,77824 0,5714 10,10 0,0000
D20 -2,17464 0,4488 -4,85 0,0000
D27 3,37844 0,4735 5,02 0,0000
D56 0,93817 0,2823 3,32 0,0014
D89 0,63030 0,2524 2,50 0,0146
D95 5,06807 0,5701 8,89 0,0000
D96 -5,32858 0,5356 -9,95 0,0000
D(yt1)3 -1,40265 0,1223 -11,50 0,0000
D(yt1)9 -2,06314 0,2321 -8,89 0,0000
D(yt1)12 1,11083 0,2879 3,86 0,0002
D(yt1)57 1,60041 0,4697 3,41 0,0010
D(yt1)119 1,52353 0,2455 6,21 0,0000
D(yt1)120 -1,20700 0,2388 -5,06 0,0000
D(yt1)126 0,90423 0,1117 8,10 0,0000
D(yt1)129 -1,06888 0,1269 -8,42 0,0000
D(yt1)130 1,93401 0,1510 12,80 0,0000
D(yt1)131 -0,86830 0,1359 -6,39 0,0000
D(yt2)6 -3,22521 0,4543 -7,10 0,0000
D(yt2)7 2,13614 0,4583 4,66 0,0000
D(yt2)10 -4,73312 1,2160 -3,89 0,0002
D(yt2)13 5,55824 1,1460 4,84 0,0000
D(yt2)32 -1,81436 0,5320 -3,41 0,0010
D(yt2)33 2,27487 0,5305 4,29 0,0001
D(yt2)76 1,53453 0,1782 8,61 0,0000
D(yt2)77 -1,74757 0,1838 -9,51 0,0000
D(yt2)113 0,62402 0,1473 4,23 0,0001
D(yt2)120 -0,72614 0,1546 -4,93 0,0000
I: 1981(1) -1,95408 0,5280 -3,70 0,0004
I: 1982(4) -2,18752 0,5338 -4,10 0,0001
I: 1983(1) -4,74507 0,6379 -7,44 0,0000
I: 1983(3) 1,56760 0,6285 -2,49 0,0148
I: 1985(3) 3,21835 0,5374 5,99 0,0000
I: 1986(1) -1,66556 0,5575 -2,99 0,0038
I: 1986(3) 2,22031 0,5295 4,19 0,0001
24
I: 1988(3) -2,36556 0,5414 -4,37 0,0000
I: 1988(4) -3,40149 0,5703 -5,96 0,0000
I: 1990(1) -3,81768 0,6267 -6,09 0,0000
I: 1991(4) -4,03701 0,5486 -7,36 0,0000
I: 1994(3) 3,88619 0,5365 7,24 0,0000
I: 1996(3) 2,67685 0,5901 4,54 0,0000
I: 1998(1) -2,56191 0,5342 -4,80 0,0000
I: 1998(3) -1,82673 0,5919 -3,09 0,0028
I: 1998(4) -1,77047 0,5307 -3,34 0,0013
I: 1999(1) -3,29865 0,6513 -5,07 0,0000
I: 2001(2) -2,04336 0,5493 -3,72 0,0004
I: 2003(1) -1,86038 0,5291 -3,52 0,0007
I: 2006(2) -1,22476 0,5320 2,30 0,0240
I: 2007(4) 1,22161 0,5323 2,29 0,0245
I: 2012(3) -1,28240 0,5445 -2,36 0,0211
I: 2012(4) -1,21236 0,5485 -2,21 0,0301
Tabela 6 – Resultado testes para modelo não linear com significância de 0,05
Teste de especificação residual
Teste (hipótese nula) Distribuição Estatística p-valor
Ausência Autocorrelação F(5,172) 0,7042 0,6221
Ausência ARCH F(4,121) 0,1683 0,9542
Normalidade Chi^2(2) 1,9523 0,3768
Ausência Hetecedasticidade F(32,65) 0,6663 0,8951
25
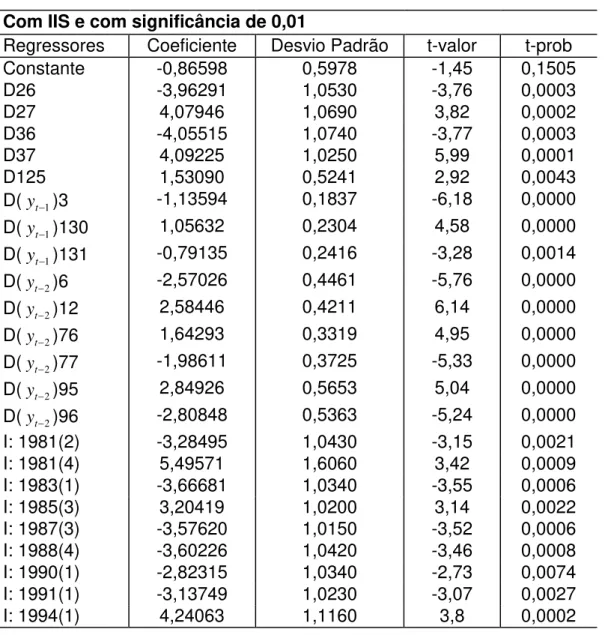
Tabela 7 – Modelo não linear com significância de 0,01
Modelando TAR – versão 3
Com IIS e com significância de 0,01
Regressores Coeficiente Desvio Padrão t-valor t-prob
Constante -0,86598 0,5978 -1,45 0,1505
D26 -3,96291 1,0530 -3,76 0,0003
D27 4,07946 1,0690 3,82 0,0002
D36 -4,05515 1,0740 -3,77 0,0003
D37 4,09225 1,0250 5,99 0,0001
D125 1,53090 0,5241 2,92 0,0043
D(yt1)3 -1,13594 0,1837 -6,18 0,0000
D(yt1)130 1,05632 0,2304 4,58 0,0000
D(yt1)131 -0,79135 0,2416 -3,28 0,0014
D(yt2)6 -2,57026 0,4461 -5,76 0,0000
D(yt2)12 2,58446 0,4211 6,14 0,0000
D(yt2)76 1,64293 0,3319 4,95 0,0000
D(yt2)77 -1,98611 0,3725 -5,33 0,0000
D(yt2)95 2,84926 0,5653 5,04 0,0000
D(yt2)96 -2,80848 0,5363 -5,24 0,0000
I: 1981(2) -3,28495 1,0430 -3,15 0,0021
I: 1981(4) 5,49571 1,6060 3,42 0,0009
I: 1983(1) -3,66681 1,0340 -3,55 0,0006
I: 1985(3) 3,20419 1,0200 3,14 0,0022
I: 1987(3) -3,57620 1,0150 -3,52 0,0006
I: 1988(4) -3,60226 1,0420 -3,46 0,0008
I: 1990(1) -2,82315 1,0340 -2,73 0,0074
I: 1991(1) -3,13749 1,0230 -3,07 0,0027
I: 1994(1) 4,24063 1,1160 3,8 0,0002
Tabela 8 – Resultado testes para modelo não linear com significância de 0,01
Teste de especificação residual
Teste (hipótese nula) Distribuição Estatística p-valor
Ausência Autocorrelação F(5,100) 0,5717 0,7215
Ausência ARCH F(4,121) 0,6557 0,6240
Normalidade Chi^2(2) 3,0582 0,2167
Ausência Hetecedasticidade F(15,99) 0,6269 0,8486