FAST REAL TIME ANALYSIS OF WEB SERVER MASSIVE LOG FILES USING AN IMPROVED WEB MINING ARCHITECTURE
Texto
Imagem

Documentos relacionados
Applied to a physical pages object containing an attribute with the items list, the operator Sets returns a node object where each node represents an element of the sets
The main objective of this thesis is comprised by the design and development of s-WIM, a scalable data model with an algebra which allows for fast Web mining prototyping, after the
In tradition approach association rule mining and probabilistic models are commonly used. Models like sequential modeling are effective in the recommendation [2]. Markov
extraction solution, able to extract data from different source types in particular from the Figure 9: The FFD Editor ETD tabs [1].. As such the data type extracted in
This dissertation intends to explore the possibility and prove the concept that, with the help and junction of different technologies such as parsing, web crawling, web mining
In this paper, we study the web usage mining with pattern recognition techniques and carried out experimental work on web log data collected from NASA web server to find out
Experiments have been conducted on Web log files of NASA Web site and results shows that the proposed ART1 algorithm learns relatively stable quality clusters compared to K-Means
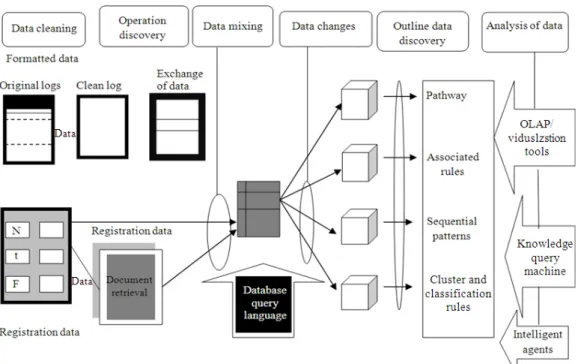
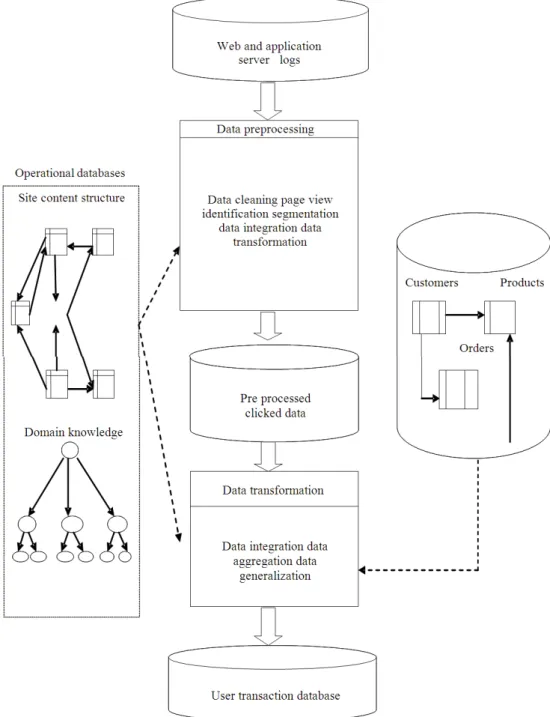
After Data Cleaning.. Referrer-Time and Semantically-Time-Referrer are discussed below. 1) Time Oriented Session Identification: Time oriented session identification
