Comparação entre modelos de previsão de
séries temporais
Diogo Medeiros, Lucas André e Willams Costa Julho 2018
Centro de Informática (CIn)
Universidade Federal de Pernambuco (UFPE) Recife–PE, Brasil
Roteiro
1. Descrição do problema
2. Base de Dados
3. Objetivo
4. Metodologia
5. Resultados
6. Conclusão
Descrição do problema
• Uma prática comum, geralmente seguida no mundo do automotivo, é a chamada manutenção periódica do carro. • Nesse contexto, o carro deve ser submetido periodicamente a
uma rotina de serviços e manutenção.
Problema
Ninguém tem certeza se alguma peça ou fluído, realmente, precisa ser substituída/trocado. Isso normalmente leva a peças ou fluídos, que estão em boas condições, serem substituídas/trocados, resultando em custos de serviço desnecessários.
• Uma característica desejada nos sistemas de diagnóstico automotivo é a previsão de falhas para evitar quebras inesperadas do veículo e minimizar os gastos do proprietário com manutenção.
Base de Dados
• Dados veículares foram coletados de um Fiat Palio Fire 1.0 8V Flex 2007.
• Dados obtidos da ECU (Engine Control Unit) do veículo a partir do sistema OBD (On-Board Diagnostic).
Objetivo
Previsão de falhas em automóveis
• Temperatura do líquido de arrefecimento do motor. • AFR (Air Fuel Ratio) na combustão interna do motor. • Tensão da bateria do automóvel.
Como essa previsão pode ser realizada?
• Modelos de previsão de séries temporais.
Metodologia
Modelos Simples
• Autoregressive Integrated Moving Average (ARIMA) • Multilayer Perceptron (MLP)
• Support Vector Machines (SVM)
• Least Squares Support Vector Machines (LS-SVM)
Modelos Híbridos
• Modelos híbridos Combinados Linearmente (CL) • Modelos híbridos Combinados Não Linearmente (CNL)
Metodologia
Métricas de avaliação
• RMSE (Root Mean Squared Error) • MAE (Mean Absolute Error)
• MAPE (Mean Absolute Percentage Error) • IA (Index of Agreement)
Métricas Comparativas
• MASE (Mean Absolute Scaled Error) - Compara com a previsão ingênua.
• ARV (Average Relative Variance) - Compara com a média da série.
Teste de hipótese
• Wilcoxon Signed Rank Test
Metodologia
Wilcoxon Signed Rank Test
• O objetivo agora éprovar estatisticamenteque os erros de previsão do modelo híbrido escolhido são menores do que os erros do respectivo modelo simples.
• Foram tomados osvalores absolutosdos erros de previsão, pois quanto menores forem as amplitudes desses erros absolutos, menores serão os erros de previsão para o modelo.
• Os testes de normalidade,Kolmogorov-SmirnoveShapiro-Wilk, nos erros absolutos de previsão para cada modelo, indicam
p−valor<2.2−16.
• OWilcoxon Signed Rank Testtrata-se de um teste estatístico de hipótesenão paramétricopara duas amostras pareadas.
Metodologia
Wilcoxon Signed Rank Test
Foram estabelecidas as seguintes hipóteses para um teste
unilateral:
• H0: (As amostras dos erros absolutos de previsão do modelo
híbrido)=(As amostras dos erros absolutos de previsão do
modelo individual)→A diferença entre os pares segue uma
distribuição simétrica em torno de zero.
• H1: (As amostras dos erros absolutos de previsão do modelo
híbrido)<(As amostras dos erros absolutos de previsão do
modelo individual)→A diferença entre os pares segue uma
distribuição com valores menores que zero.
Metodologia
Table 1:Abordagens de previsão utilizados neste trabalho com os métodos correspondentes e os respectivos acrônimos.
Abordagem Método Acrônimo
ARIMA A
Modelo MLP M
simples SVM S
LS-SVM L
ARIMA+MLP CLAM
Modelo ARIMA+LS-SVM CLAL
híbrido CL MLP+ARIMA CLMA
LS-SVM+ARIMA CLLA
MLP (ARIMA,MLP) CNL-MAM
MLP (ARIMA,LS-SVM) CNL-MAL
LS-SVM (ARIMA,MLP) CNL-LAM
LS-SVM (ARIMA,LS-SVM) CNL-LAL
SVM (ARIMA,MLP) CNL-SAM
Modelo SVM (ARIMA,LS-SVM) CNL-SAL
híbrido CNL MLP (MLP,ARIMA) CNL-MMA
LS-SVM (MLP,ARIMA) CNL-LMA
SVM (MLP,ARIMA) CNL-SMA
MLP (LS-SVM,ARIMA) CNL-MLA
LS-SVM (LS-SVM,ARIMA) CNL-LLA
Resultados
Resultados para a Temperatura do Líquido de Arrefecimento do Motor
Table 2:Medidas de avaliação obtidas para o conjunto de teste da série de temperatura do líquido de arrefecimento do motor.
Modelo
Inicial Abordagem RMSE MAE MAPE IA POCID - ARIMA 0.10403 0.05931 13.60 0.8347 56.79 - MLP 0.10469 0.06096 13.23 0.8493 57.01 - SVM 0.10660 0.05291 12.39 0.8500 56.36 - LS-SVM 0.10319 0.05964 12.99 0.8481 58.57
CLAM 0.10126 0.05796 12.77 0.8561 56.75
CLAL 0.10126 0.05828 12.91 0.8547 56.49
CNL-MAM 0.10198 0.05779 12.74 0.8569 56.75
ARIMA CNL-MAL 0.10102 0.05763 12.87 0.8525 56.62
CNL-LAM 0.10101 0.05706 12.72 0.8500 56.49
CNL-LAL 0.10102 0.05718 12.90 0.8431 55.97
CNL-SAM 0.10218 0.05931 12.93 0.8540 57.14
CNL-SAL 0.10223 0.06125 13.09 0.8460 56.36
CLMA 0.10068 0.05636 12.63 0.8671 58.70
MLP CNL-MMA 0.10066 0.05625 12.61 0.8619 58.83
CNL-LMA 0.10040 0.05357 12.40 0.8583 56.88
CNL-SMA 0.09940 0.05552 12.52 0.8582 58.96
CLLA 0.09961 0.05433 12.29 0.8697 57.40
LS-SVM CNL-MLA 0.09963 0.05444 12.39 0.8643 58.31
CNL-LLA 0.09923 0.05455 12.33 0.8653 58.05
Resultados
Resultados para a Temperatura do Líquido de Arrefecimento do Motor
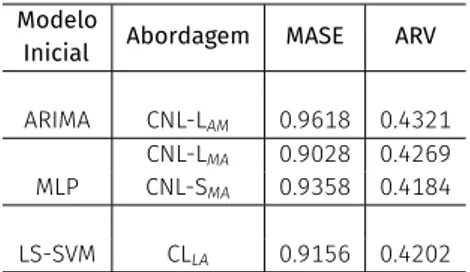
Table 3:Métricas comparativas aplicadas nas abordagens com os melhores desempenhos de acordo com seus respectivos modelos iniciais para a temperatura do líquido de arrefecimento do motor no conjunto de teste.
Modelo
Inicial Abordagem MASE ARV
ARIMA CNL-LAM 0.9618 0.4321
CNL-LMA 0.9028 0.4269
MLP CNL-SMA 0.9358 0.4184
LS-SVM CLLA 0.9156 0.4202
Resultados
Resultados para a Temperatura do Líquido de Arrefecimento do Motor
Table 4:Parâmetros selecionados nogrid-searchpara omodelo híbridoCLLA
eresultado doWilcoxon signed rank testno conjunto de teste dodatasetda
temperatura do líquido de arrefecimento do motor.
m0 Lags na entrada λ γ
LS-SVM 3 9,775625·104 0.25
m1 p d q
ARIMA 17 1 14
Wilcoxon signed Valor−p
rank test 4.572·10−11<0,05
Resultados
Resultados para o AFR na Combustão Interna do Motor
Table 5:Medidas de avaliação obtidas para o conjunto de teste da série do AFR na combustão interna do motor.
Modelo
Inicial Abordagem RMSE MAE MAPE IA POCID - ARIMA 0.10417 0.08126 15.67 0.7292 40.49 - MLP 0.10623 0.08313 16.05 0.7067 37.90 - SVM 0.10587 0.08159 16.10 0.7119 37.23 - LS-SVM 0.10546 0.08180 15.85 0.7223 38.43 CLAM 0.10381 0.08093 15.54 0.7316 41.58
CLAL 0.10375 0.08086 15.54 0.7306 42.23
CNL-MAM 0.10420 0.08144 15.62 0.7214 41.58
ARIMA CNL-MAL 0.10423 0.08150 15.64 0.7201 41.84
CNL-LAM 0.10436 0.08133 15.57 0.7293 41.06
CNL-LAL 0.10367 0.08070 15.47 0.7311 41.45 CNL-SAM 0.10409 0.08117 15.63 0.7241 41.58
CNL-SAL 0.10402 0.08111 15.59 0.7267 41.45
CLMA 0.10371 0.07970 15.45 0.7621 40.82 MLP CNL-MMA 0.10390 0.07983 15.73 0.7406 39.76
CNL-LMA 0.10412 0.08030 15.64 0.7365 40.03
CNL-SMA 0.10403 0.07976 15.76 0.7407 38.96
alertCLLA 0.10462 0.08042 15.58 0.7439 42.95
LS-SVM CNL-MLA 0.10460 0.08036 15.64 0.7362 42.02
CNL-LLA 0.10463 0.08050 15.57 0.7367 41.89
Resultados
Resultados para o AFR na Combustão Interna do Motor
Table 6:Métricas comparativas aplicadas nas abordagens com os melhores desempenhos de acordo com seus respectivos modelos iniciais para o AFR na combustão internada do motor no conjunto de teste.
Modelo
Inicial Abordagem MASE ARV
ARIMA CNL-LAL 0.8699 0.5912
MLP CLMA 0.8686 0.5829
CLLA 0.8763 0.5931
LS-SVM CNL-SLA 0.8743 0.5916
Resultados
Resultados para o AFR na Combustão Interna do Motor
Table 7:Parâmetros selecionados nogrid-searchpara omodelo híbrido
CLMAeresultado doWilcoxon signed rank testno conjunto de teste do
datasetAFR.
m0 Nós na camada Nós na camada Expoente de
de entrada oculta weight-decayα
MLP 21 21 1
m1 p d q
ARIMA 13 1 19
Wilcoxon signed Valor−p
rank test 8,441·10−4<0,05
Resultados
Resultados para a Tensão da Bateria Automotiva
Table 8:Medidas de avaliação obtidas para o conjunto de teste da série de tensão da bateria.
Modelo
Inicial Abordagem RMSE MAE MAPE IA POCID - ARIMA 0.07020 0.04833 8.90 0.9175 42.82 - MLP 0.06970 0.04739 8.83 0.9159 41.28 - SVM 0.07126 0.04799 8.90 0.9143 41.56 - LS-SVM 0.07144 0.04927 9.18 0.9098 42.06 CLAM 0.07091 0.04948 9.10 0.9154 45.32
CLAL 0.07046 0.04953 9.10 0.9159 42.97
CNL-MAM 0.07003 0.04851 8.97 0.9157 43.90 ARIMA CNL-MAL 0.07034 0.04937 9.12 0.9148 42.84
CNL-LAM 0.06986 0.04871 8.97 0.9155 43.12
CNL-LAL 0.06995 0.04863 9.06 0.9140 43.49
CNL-SAM 0.06996 0.04877 9.02 0.9146 44.16
CNL-SAL 0.07087 0.04983 9.30 0.9114 42.45
CLMA 0.06881 0.04739 8.80 0.9192 42.71
MLP CNL-MMA 0.06897 0.04717 8.81 0.9182 42.71
CNL-LMA 0.06925 0.04743 8.86 0.9185 42.71
CNL-SMA 0.06871 0.04715 8.81 0.9172 42.84 CLLA 0.07079 0.04949 9.13 0.9163 41.02
LS-SVM CNL-MLA 0.07036 0.04934 9.10 0.9153 41.28
CNL-LLA 0.06998 0.04904 9.11 0.9142 41.28
Resultados
Resultados para a Tensão da Bateria Automotiva
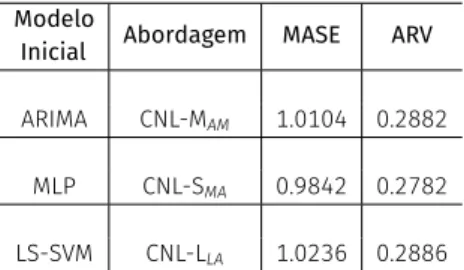
Table 9:Métricas comparativas aplicadas nas abordagens com os melhores desempenhos de acordo com seus respectivos modelos iniciais para a tensão da bateria automotiva no conjunto de teste.
Modelo
Inicial Abordagem MASE ARV
ARIMA CNL-MAM 1.0104 0.2882
MLP CNL-SMA 0.9842 0.2782
LS-SVM CNL-LLA 1.0236 0.2886
Resultados
Resultados para a Tensão da Bateria Automotiva
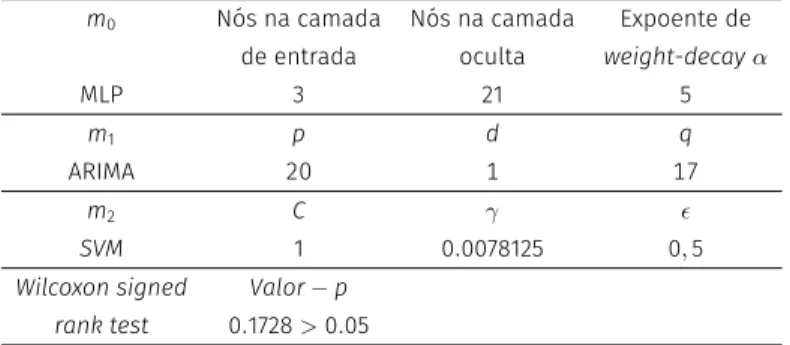
Table 10:Parâmetros selecionados nogrid-searchpara omodelo híbrido
CNL-SMAeresultado doWilcoxon signed rank testno conjunto de teste do
datasetdatensão da bateria automotiva.
m0 Nós na camada Nós na camada Expoente de
de entrada oculta weight-decayα
MLP 3 21 5
m1 p d q
ARIMA 20 1 17
m2 C γ ϵ
SVM 1 0.0078125 0,5
Wilcoxon signed Valor−p
rank test 0.1728>0.05
Conclusão
• Em duas séries,temperatura do motoreAFR, ficou comprovado que o erro de previsão do modelo híbrido é menor que o erro de previsão do modelo simples.
• Isto evidencia quenestas sériesos modelos híbridos são realmente mais precisos que os respectivos modelos individuais.
• Na série datensão da bateriao teste de hipótesefalhouem comprovar que o erro do modelo híbrido é menor que o erro do modelo simples.
• Deve-se investigar outras abordagens para aprimorar a precisão dos modelos híbridos no caso da série datensão da bateria.
FIM.
Estatísticas para
Acidentes de
Avião
Grupo: Matheus Augusto de Lima Freire
Dênio Batista Brasileiro Bezerra
Sumário
Introdução
Teste de Normalidade
Introdução
Base de dados: Acidentes de avião de 1908-2009
Teste de Normalidade
Para a variável 'Aboard':
Shapiro-Wilk normality test
data: dat4$Aboard
W = 0.58099, p-value < 2.2e-16
Teste de Normalidade
Para a variável 'Fatalities':
Shapiro-Wilk normality test
data: dat4$Fatalities
W = 0.52748, p-value < 2.2e-16
Frequência de Acidentes
por Tipo de Avião
Frequência de Acidentes
por Tipo de Avião
(20 maiores)
Quantidade de mortes
por tipo de avião(%)
Wilcoxon signed rank test
data: aviao_porcentagem_mortes$porcentagem
V = 210, p-value = 1.907e-06
alternative hypothesis: true location is not equal to 0
Quantidade de mortes
por tipo de avião(%)
Decisão para comprador de Aviões (Linhas Aéreas)
Chega-se a uma conclusão de que, entre os 20 tipos observados, a melhor
escolha de compra é o modelo "Let 410UVP" com 41% de mortes por
Conclusão
A decisão obtida é útil, no entanto é vaga, pois informações como:
- Capacidade do avião
- Tempo médio de durabilidade
- Preço
UMA ANÁLISE DA PRECIPITAÇÃO
TOTAL MENSAL NA CIDADE DO
RECIFE
ÉVORA LEITE
INTRODUÇÃO
•
O que é precipitação?
•
Qual a importância desse fenômeno para uma sociedade?
OBJETIVO
•
Fazer uso da Análise de Séries Temporais para a previsão da Precipitação
MÉTODO
•
Dados Utilizados
•
Precipitação Total Mensal na cidade do Recife (dados da estação do curado)
•
Dados de Março de 1961 a Abril de 2018 (685 meses)
•
Séries Temporais
•
Análise através do tempo
•
Estacionariedade de uma Série
•
Escolha de um modelo para representar os dados da Série.
MÉTODO
•
Estimação do Modelo Escolhido
•
Box
–
Jenkins
•
Validação do Modelo
•
Ljung-Box Test
•
Shapiro-Wilk Test
•
Previsão
•
Análise da Previsão
RESULTADOS
Medida de Posição/Dispersão
Valor
Media (Desvio Padrão)
192,06 (160,16)
Mediana
146
Moda
30,6
–
112,2
Máximo
770,4
RESULTADOS
•
Modelo ARIMA (1,0,0)
•
Validação
Teste
P-Valor
Ljung-Box
0,6954
RESULTADOS
Previsão
LO 80
HI 80
LO 95
HI 95
Jul 2017
350,06
176,12
523,99
84,04
616,06
Ago 2017
276,29
79,36
473,21
-24,88
577,46
Set 2017
237,13
34,19
440,06
-73,23
547,49
Out 2017
216,34
11,74
420,93
-96,56
529,24
Nov 2017
205,30
0,24
410,36
-108,31
518,92
Dez 2017
199,44
-5,74
404,64
-114,37
513,26
Jan 2018
196,33
-8,89
401,56
-117,53
510,21
RESULTADOS
Teste
Coeficiente / P-valor
Correlação de Spearman
-0,1878
CONCLUSÃO
•
Esse modelo é recomendado para realizar previsões do total de precipitação
mensal na cidade do Recife?
REFERÊNCIAS
•
Análise de Séries Temporais
–
Morettin
•
https://cran.r-project.org/web/packages/forecast/forecast.pdf
Análise estatística de dados da
personalidade com relação ao
gosto musical
Delando Júnior
Flávia Brasileiro
Motivação
● 5 desafios do Spotify
○ O que recomendar para novos usuários?
Arquitetura do Sistema
Personalidade - BigFive
O
penness
C
onscientiousness
E
xtraversion
A
greeableness
N
euroticism
Personalidade - BigFive
O
penness
C
onscientiousness
E
xtraversion
A
greeableness
N
euroticism
Personalidade - BigFive
O
penness
C
onscientiousness
E
xtraversion
A
greeableness
N
euroticism
+
-
Confiáveis
Trabalhadores
Dedicados.
Impulsivos
Dispersos
Personalidade - BigFive
O
penness
C
onscientiousness
E
xtraversion
A
greeableness
N
euroticism
+
-Sociáveis
“Alma da Festa”
Preferem estar
com outras
pessoas
Introvertidos
Inclinação para a
quietude
Personalidade - BigFive
O
penness
C
onscientiousness
E
xtraversion
A
greeableness
N
euroticism
+
-Generosos
Honestos
Preocupados com o
bem-estar dos
outros
Cínicos e
Céticos sobre o
mundo ao seu
redor
Personalidade - BigFive
O
penness
C
onscientiousness
E
xtraversion
A
greeableness
N
euroticism
Spotify Features
Accousticness
Medida de confiança se
uma faixa é Acoustica.
Spotify Features
Accousticness
Medida de confiança se
uma faixa é Acoustica.
Danceability
Analisa o nível de
dançabilidade de uma
música.
Spotify Features
Accousticness
Medida de confiança se
uma faixa é Acoustica.
Danceability
Analisa o nível de
dançabilidade de uma
música.
Energy
Representa a intensidade e
atividade da música.
Spotify Features
Accousticness
Medida de confiança se
uma faixa é Acoustica.
Danceability
Analisa o nível de
dançabilidade de uma
música.
Energy
Representa a intensidade e
atividade da música.
Instrumentalness
Analisa se uma música
possui vocais, ou seja é
instrumental ou não.
Spotify Features
Accousticness
Medida de confiança se
uma faixa é Acoustica.
Danceability
Analisa o nível de
dançabilidade de uma
música.
Energy
Representa a intensidade e
atividade da música.
Liveness
Verifica se a música foi
gravado ao vivo.
Instrumentalness
Analisa se uma música
possui vocais, ou seja é
instrumental ou não.
Spotify Features
Accousticness
Medida de confiança se
uma faixa é Acoustica.
Danceability
Analisa o nível de
dançabilidade de uma
música.
Energy
Representa a intensidade e
atividade da música.
Liveness
Verifica se a música foi
gravado ao vivo.
Tempo
Representa o andamento
da música, ou seja a
velocidade ou ritmo.
Instrumentalness
Analisa se uma música
possui vocais, ou seja é
instrumental ou não.
Spotify Features
Accousticness
Medida de confiança se
uma faixa é Acoustica.
Danceability
Analisa o nível de
dançabilidade de uma
música.
Energy
Representa a intensidade e
atividade da música.
Liveness
Verifica se a música foi
gravado ao vivo.
Tempo
Representa o andamento
da música, ou seja a
velocidade ou ritmo.
Valence
Descreve a positividade de
cada música.
Instrumentalness
Analisa se uma música
possui vocais, ou seja é
instrumental ou não.
Spotify Features
Accousticness
Medida de confiança se
uma faixa é Acoustica.
Danceability
Analisa o nível de
dançabilidade de uma
música.
Energy
Representa a intensidade e
atividade da música.
Liveness
Verifica se a música foi
gravado ao vivo.
Tempo
Representa o andamento
da música, ou seja a
velocidade ou ritmo.
Valence
Descreve a positividade de
cada música.
Instrumentalness
Analisa se uma música
possui vocais, ou seja é
instrumental ou não.
Popularity
Define a popularidade da
música, o quanto ela é
escutada no mundo.
Dados Coletados
18
● Idade entre 18 e 30 anos
● 16 mulheres e 15 homens
● Possuíam em média 32
curtidas.
60 registros
47 usuários completos
I. Teste de Correlação
II. Teste de Normalidade
III. Regressão Multivariada
Testes realizados
Resultados
Estatística descritiva dos dados
Resultados
Estatística descritiva dos dados (SD)
Acousticness
-
0,100766
Conscientiousness
-
0,195710
Danceability
-
0,072069
Neuroticism
-
0,136510
Energy
-
0,070950
Extraversion
-
0,129174
Instrumentalness -
0,171048
Openness
-
0,149890
Liveness
-
0,075641
Agreeableness
-
0,182463
Tempo
-
5,461756
Valence
-
0,091290
Popularity
-
8,664435
I. Teste de Correlação
2 variáveis de entrada e uma de saída
apresentaram correlação com mais de
60%
e
foram excluídas.
Resultados
II. Teste de Normalidade multivariada
➔
H0: Y é normal multivariada
➔
Ha: Y não é normal multivariada
Foi realizado o teste
Shapiro-Wilk
e obteve
um
P-value
0,001023
.
Conclui-se que os dados
não
seguem
normalidade.
Resultados
Resultados
III. Regressão Multivariada
Foi
realizada
uma
regressão
linear
multivariada através da fórmula:
Y = Xβ +
ε
Onde:
Y - Matriz das Respostas
ε
- MSE
X
- Matriz das Regressoras
β - Matriz de coeficientes
Resultados
III. Regressão Multivariada
Foi realizado o cálculo da matriz de
coeficientes através da fórmula:
β = (X
T
X)
-1
X
T
Y
Onde:
β - Matriz de coeficientes
X
- Matriz das Regressoras
Y - Matriz das Respostas
Resultados
III. Regressão Multivariada
β - Matriz de coeficientes
Resultados
III. Regressão Multivariada
Para achar o erro quadrático médio foi
calculado o Ŷ através da fórmula:
Ŷ =Xβ
Onde:
Ŷ - Matriz de resposta ideal
X - Matriz das Regressoras
β - Matriz de Coeficientes
Resultados
III. Regressão Multivariada
Por fim o Erro Quadrático Médio (MSE) é
calculado pela seguinte equação:
ε
= Σ(Y - Ŷ)
2
/n
Onde:
ε
- MSE
n - Tamanho da
Y - Resposta Real
amostra
Ŷ - Resposta Ideal
Resultados
III. Regressão Multivariada
MSE = 0,08014671
Conclusão
● Podemos concluir que utilizando esta
métrica, regressão multivariada, o
modelo tem um bom ajuste para
predição.
Análise e Inferências
dos Dados do SAMU
Equipe
@bao | @gml | @rjos
Dados - Análise Descritiva
Solicitações do SAMU
DATABASE DO SAMU ENTRE
2011-2014
●
Número de variáveis variando entre 21 e 22;
●
Número de amostras variando entre 120k e 170k, dependendo do ano;
É possível inferir as informações mais diversas, como:
●
Bairro com maior número de chamados;
●
Causa do chamado;
●
Idade média dos pacientes;
DATABASE DO SAMU ENTRE
2011-2014
Decidimos analisar:
1. A ocorrência de trotes;
TROTES NO SAMU ENTRE
2011-2014
●
Em uma coluna de descrição, alguns exemplos são descritos como
“trote”, o que permite perceber as ocorrências;
●
É dito que não há paciente no endereço, caracterizando a ocorrência.
Testes de Aderência
Teste de Hipóteses
A média de trotes ao longo dos
TESTE DE HIPÓTESES
H
0
: a média de trotes ao longo dos anos é igual.
H
1
: a média de trotes ao longo dos anos é diferente.
TESTE DE FRIEDMAN
TESTE DE NEMENYI
A um nível de 95%
de confiança,
rejeita-se a hipótese
nula!
Diferença:
Significativa
Teste de Hipóteses
A taxa de solicitações ao SAMU que
necessitam de ambulância nas ruas
O
TREINAMENTO
E A
EXPERIÊNCIA
LEVARAM À
SOLUÇÃO EFICIENTE
DE CASOS QUE PODERIAM TER SIDOS RESOLVIDOS NA ORIGEM DA
CHAMADA.
Concluídas
Descartadas
Duplicação; Desistência;
Removido antes do atendimento;
Recusa de remoção do local; Casa
fechada; > 12H de Solicitação
Regulação por
Telefone
Ocorrências Absolutas
Com ambulância: 40.680
Sem ambulância: 89.943
Ocorrências Absolutas
Com ambulância: 40.989
Sem ambulância: 78.653
Ocorrências Absolutas
Com ambulância: 52.690
Sem ambulância: 91.156
Ocorrências Absolutas
Com ambulância: 105.430
Sem ambulância: 68.470
TESTE DE HIPÓTESES
H
0
: a proporção de ambulâncias necessárias nas ruas é
igual.
H
1
: a proporção de ambulâncias necessárias nas ruas é
diferente.
“
Com 95% de confiança, temos evidências
suficientes para afirmar que a demanda por
ambulâncias muda de acordo com as amostras
“
TESTE DE PROPORÇÃO
2011 - 2012
2012 - 2013
2013 -2014
H
0: p
1> p
2Análise estatística de dados de
Agricultura.
MOTIVAÇÃO
As variáveis ambientais de cultivos em uma estufa estão correlacionadas?
Backward
Elimination.
De acordo com os dados em análise, como podemos predizer a temperatura (estimativa)
dado que esse atributo possui uma importância relevante para o experimento ? -
Regressão
Base de Dados
Os dados utilizados neste projeto são de uma base própria,
a mesma que foi extraída de um ambiente controlado.
Os dados foram coletados de uma WSN, de três modelos diferentes:
•
Irrigação com gotejamento
•
Irrigação com mangueira
Estrutura de dados
•
Três tabelas com 120 amostras cada, com a seguinte estrutura:
ID
hora
fecha
temperatura
Humedad relativ
Luz
CO2 Humedad de suelo
0 397
11:05:15
09/12/2016
25
32
1330
18
620
1 398
11:05:47
09/12/2016
25
32
1291
18
618
2 399
11:06:19
09/12/2016
25
31
3309
18
617
3 400
11:06:51
09/12/2016
25
31
3206
18
616
Procedimentos realizados
Teste de normalidade (Kolmogorov e Shapiro);
Análise de componentes principais
Teste de hipóteses;
Correlação;
Análise de componentes principais PCA
Análise de componentes principais PCA
Análise de componentes principais PCA
Análise de componentes principais PCA
Análise de componentes principais PCA
Análise de componentes principais PCA
Análise de componentes principais PCA
Análise de componentes principais PCA
Análise de componentes principais PCA
Teste de Normalidade
Variáveis
Kolmogorov
Shapiro
Temperatura
1.134e-06
5.372 e-10
CO2
0.001492
2.677e-11
Humidade relativa
0.01035
5.429e-07
Luz
4.766e-06
2.114e-10
Correlação
Variáveis
Pearson
Temperatura
Luz
0.7882072
Temperatura
CO2
-0.1782011
Temperatura
Humidade Relativa
-0.8419033
Regressão
Variáveis
Erro padrão
P-value
Humidade Relativa
0.0201078
5.30e-13
Luz
0.0001097
5.31e-16
CO2
0.0783606
0.000388
Humidade do Solo
0.0014348
0.001424
F-statistics
156.2 df = 4, 81
Resultados:
MSE_gotejamento:
1.4953354808878123
MSE_manguera:
2.0974013096620396
MSE_sem_irrigacao:
0.40128849065914873
R2_score_gotejamento:
0.8283594619803422
R2_score_manguera:
0.8165340107099079
Conclusão
Ao ser aplicada a técnica
Backward Elimination
, foi possível verificar
que nenhuma variável poderia ser descartada, pois todas são
importantes para que o modelo proposto possa realizar uma boa
aproximação da função Temperatura.
Regressão Logística e SVM
para Detecção de Ataque
Cardíaco
Universidade Federal de Pernambuco
Centro de Informática - Cin
Sumário
1.
Introdução
a.
Definição do Problema
2.
Base de Dados
3.
Análise dos Dados
4.
Modelagem
Introdução
●
O músculo cardíaco precisa de um fornecimento constante de sangue rico em
oxigênio.
●
As artérias coronarianas, que se ramificam da aorta assim que esta sai do coração,
fornecem esse sangue.
Problema
●
É possível prever esses problemas utilizando
○
Regressão Logística
○
Máquina de Vetores de Suporte
Base de Dados
Dados coletados de 4 locais:
1.
Cleveland Clinic Foundation
2.
Hungarian Institute of Cardiology, Budapest
3.
V.A. Medical Center, Long Beach, CA
Base de Dados
age
: Idade em anos
sex
: sexo (1 = Homem; 0 = Mulher)
cp
: Tipo de dor no peito (4 tipos diferentes: 1 à 4)
trestbps
: pressão sanguínea em repouso (
milímetro (mm) de mercúrio (Hg)
)
chol
: colesterol
fbs
: (gordura no sangue > 120 mg/dl) (1 = true; 0 = false)
restecg
: resultados do ecg-- 0: normal - 1: anormal tipo 1 - 2: anormal tipo 2
thalach
: frequência cardíaca máxima atingida
exang
: angina (dor no peito ) provocada por exercício (1 = yes; 0 = no)
oldpeak:
depressão ST
slope
: tamanho da depressão 1 à 3
ca
: number of major vessels (0-3)
thal:
3 = normal; 6 = fixed defect; 7 = reversable defect
num:
diagnóstico final (angiographic disease status) --
0:
Sem Problema detectado
Base de Dados
(
Missing values
)
Base de Dados
(
Missing values
)
Remoção pela
mediana
Modelagem (Regressão Logística)
Assumimos que:
●
A saída é binária;
●
Há uma relação linear entre a saída
logit
e cada variável.
a.
logit(p) = log(p/(1-p))
, onde p é a probabilidade de saída.
●
Não há outliers ou valores extremos;
Correlação das
Variáveis
●
Multicolinearidade é um problema
Modelagem (Regressão Logística)
“> model <- glm(num ~.,family=binomial(link='logit'),data=data)
> summary(model)
Modelagem (Regressão Logística)
“> model <- glm(num ~.,family=binomial(link='logit'),data=data[,-c(1)])
> summary(model)
Modelagem (Regressão Logística)
“> model <- glm(num ~.,family=binomial(link='logit'),data=data[,-c(1,4)])
> summary(model)
Modelagem (Regressão Logística)
“> model <- glm(num ~.,family=binomial(link='logit'),data=data[,-c(1,4,8)])
> summary(model)
Modelagem (Regressão Logística)
“> model <- glm(num ~.,family=binomial(link='logit'),data=data[,-c(1,4,8,7)])
> summary(model)
Modelagem (Regressão Logística)
“> model <- glm(num ~.,family=binomial(link='logit'),data=data[,-c(1,4,8,7,5)])
> summary(model)
Modelagem (Regressão Logística)
“> model <- glm(num ~.,family=binomial(link='logit'),data=data[,-c(1,4,8,7,5,6)])
> summary(model)
Modelo 2 (Support Vector Machinne)
“> model_svm <- svm(num~., train, kernel = "radial", cost = 1, gamma=0.01)
> summary(model)
Experimentos
●
30 repetições com 10 fold cada
●
Base de dados contém 294 amostras
●
Treino: 80%
Comparando a Taxa de Acerto Média
Δμ != 0
Conclusão
●
É possível o uso, tanto da Regressão Logística quanto do SVM, para predição de problema arterial
coronário.
●
Os resultados obtidos através dos teste de
Wilcoxon Pareado para diferença das médias
Uma abordagem baseada em PLN e AG para apoiar
a mediação pedagógica em fóruns de discussão
(ABED, 2015, 2016)
(XIA
et al.
, 2013)
Motivação
Consolidação da EAD
Importância dos fóruns
Motivação
(DRINGUS e ELLIS, 2005; SCHEUER, 2008; ALMATRAFI
et al
., 2017)
Dificuldade de
acompanhamento das
discussões por parte
do professor/tutor
Como apoiar a mediação pedagógica em fóruns educacionais
considerando o grande número dúvidas e respostas que surgem
ao longo das discussões?
Problema de pesquisa
Objetivo
Apresentar uma abordagem capaz de
identificar automaticamente os gêneros
das postagens (Dúvida, Neutra e
Resposta) em fóruns educacionais.
Objetivo
Dúvida direta
Poderiam explicar novamente o tema X?
6
Principais características da abordagem
● A montagem dos
bags-of-words
e dos vetores de
características considera classes gramaticais (Verbo,
Substantivo, Pronome, Adjetivo e Advérbio);
7
1. Considerar as classes gramaticais melhora o desempenho
da abordagem?
Perguntas levantadas
8
2. O uso do AG para ajustar os parâmetros do SVM implica em
um melhor índice de classificação das postagens?
Hipótese nula
Hipótese alternativa
H
0
A
f-measure
obtida ao considerar
as funções gramaticais é menor
ou igual à
f-measure
obtida sem
considerar as funções gramaticais
H
a1
A
f-measure
obtida ao considerar
as funções gramaticais é maior
que a
f-measure
obtida sem
considerar as funções gramaticais
Hipóteses levantadas
Hipótese nula
Hipótese alternativa
H
0
A
AG é menor ou igual à
f-measure
obtida com o uso do
f-measure
obtida sem o uso do AG
H
a2
A
f-measure
obtida com o uso do
AG é maior que a
f-measure
obtida sem uso do AG
Hipóteses levantadas
Hipótese nula
Hipótese alternativa
H
0
A
f-measure
obtida com a
abordagem proposta é menor ou
igual à
f-measure
obtida com o
algoritmo proposto em Rolim
et al.
(2016).
H
a3
A
f-measure
obtida com a
abordagem proposta é maior que
a
f-measure
obtida com o
algoritmo proposto em Rolim
et
al.
(2016).
Hipóteses levantadas
Preparação da Base
12
1. Extração do AVA da UFAL (Universidade Federal de
Alagoas)
2. 600 instâncias (200 dúvidas, 200 neutras e 200 respostas)
3. Execução do algoritmo
AG + Classes Gramaticais Sem AG + Classes Gramaticais AG + Sem Classes Gramaticais
0,980 0,985 0,983 0,987 0,983 0,950 0,950 0,955 0,948 0,953 0,858 0,844 0,872 0,825 0,870 0,985 0,983 0,988 0,983 0,982 0,953 0,955 0,955 0,952 0,947 0,870 0,830 0,872 0,855 0,854 0,982 0,982 0,980 0,982 0,985 0,953 0,958 0,953 0,950 0,958 0,740 0,854 0,879 0,848 0,819 0,983 0,985 0,985 0,982 0,983 0,955 0,952 0,952 0,960 0,955 0,822 0,846 0,848 0,866 0,854 0,982 0,982 0,988 0,980 0,977 0,957 0,950 0,955 0,955 0,950 0,828 0,881 0,854 0,817 0,846 0,985 0,983 0,987 0,983 0,982 0,948 0,958 0,957 0,957 0,953 0,861 0,868 0,774 0,852 0,842
Resultados
13
Rolim et al. (2016)
0,980 0,985 0,983 0,987 0,983
0,985 0,983 0,988 0,983 0,982
0,982 0,982 0,980 0,982 0,985
0,983 0,985 0,985 0,982 0,983
0,982 0,982 0,988 0,980 0,977
Análise dos dados
P-value
0.1863
Teste de normalidade Shapiro-wilk
Min
Max
Mediana
Média
Desvio
0.9767
0.9883
0.9833
0.9832
0.0025
AG + Classes Gramaticais
14
Análise dos dados
P-value
0.5246
Teste de normalidade Shapiro-wilk
Min
Max
Mediana
Média
Desvio
0.9466
0.9600
0.9534
0.9535
0.0033
Sem AG + Classes Gramaticais
15
Análise dos dados
P-value
0.0002277
Teste de normalidade Shapiro-wilk
Min
Max
Mediana
Média
Desvio
0.7402
0.8811
0.8527
0.8449
0.0299
AG + Sem Classes Gramaticais
16
Análise dos dados
P-value
0.5918
Teste de normalidade Shapiro-wilk
Min
Max
Mediana
Média
Desvio
0.9317
0.9767
0.9568
0.9563
0.0098
Rolim
et al
. (2016)
17
Testes de Hipóteses
Hipótese nula
Hipótese alternativa
H
0
A
f-measure
obtida ao considerar
as funções gramaticais é menor
ou igual à
f-measure
obtida sem
considerar as funções gramaticais
H
a1
A
f-measure
obtida ao considerar
as funções gramaticais é maior
que a
f-measure
obtida sem
considerar as funções gramaticais
P-value
1.504e-11
Com o nível de significância igual a
0.05, há evidências para rejeitar
H
0
18
Testes de Hipóteses
Hipótese nula
Hipótese alternativa
H
0
A
AG é menor ou igual à
f-measure
obtida com o uso do
f-measure
obtida sem o uso do AG
H
a2
A
f-measure
obtida com o uso do
AG é maior que a
f-measure
obtida sem uso do AG
P-value
2.2e-16
Com o nível de significância de
0.05, há evidências para rejeitar
H
0
19
Testes de Hipóteses
Hipótese nula
Hipótese alternativa
H
0
A
f-measure
obtida com a
abordagem proposta é menor ou
igual à
f-measure
obtida com o
algoritmo proposto em Rolim.
H
a3
A
f-measure
obtida com a
abordagem proposta é maior que
a
f-measure
obtida com o
algoritmo proposto em Rolim.
P-value
3.97e-16
Com o nível de significância igual a
0.05, há evidências para rejeitar
H
0
20