Detecção e Identificação em Tempo Real de Padrões de
Comportamento Anómalo em Grandes Grupos de Utilizadores - Call
Center
Tiago Jorge 1, José Tribolet 2, André Vasconcelos3
1) Instituto Superior Técnico, Lisboa, Portugal tiago.simoes.jorge@gmail.com
2) Instituto Superior Técnico, INESC Inovação, Rua Alves Redol 9, 1000-029, Lisboa, Portugal jose.tribolet@ist.utl.pt
3) Instituto Superior Técnico, INESC Inovação, Rua Alves Redol 9, 1000-029, Lisboa, Portugal andre.vasconcelos@ist.utl.pt
Resumo
As organizações gastam uma quantidade significativa de recursos para mitigar riscos vindos de fora do perímetro organizacional, poucas são as que consideram explicitamente as ameaças vindas dos actores internos. Monitorizar e correlacionar em tempo real, características tecnológicas das actividades que estão a ser realizadas através dos sistemas é uma forma de detectar e identificar a ocorrência de anomalias que podem por em causa a segurança da organização e provocar quebras na receita. Fugas de informação para o exterior pela forma de comunicações via Internet ou através de comunicação com volume de armazenamento de dados externo, são algumas das anomalias que são propostas detectar. Esta investigação tem a sua génese na detecção destes problemas, propondo um sistema automático não supervisionado de detecção de comportamentos anómalos, mais propriamente, num Call Center e através de um conjunto bem definido e limitado de dados A ferramenta gráfica, ROA - Representação Organizacional de Anomalias, que representa o modelo de processos de negócio que decorrem numa organização, permite actualizar dinamicamente o modelo, representando o conhecimento oriundo da detecção das anomalias para uso futuro por parte dos responsáveis do negócio. Esse será construído a partir de uma técnica de levantamento manual de processos de negócio.
Palavras chave: Detecção, Identificação, Monitorização, Modelação, Comportamento Anómalo, Algoritmo Tempo Real, Segurança, Actualização Dinâmica Modelo
1. Introdução
Uma empresa Portuguesa de referência na área das telecomunicações é detentora de uma vasta infra-estrutura de redes e sistemas, destacando-se vários Call Centers espalhados pelo país, que possuem um grande número de indivíduos a interagir com os seus sistemas e aplicações. A monitorização e rápida detecção de anomalias relevantes nestes sistemas são necessárias, dando respostas de origem/causa válidas no menor tempo possível.
A quebra de produtividade ou a tentativa de fraude com a informação interna são alguns dos tipos de anomalias que se pretendem encontrar, tal como os exemplos abaixo mencionados:
IP origem e IP destino fora da banda normal de contactos autorizados
Acesso a volume de Input/Output
Detecção de cluster de IPs com a mesma origem e destino Status de Desktop anormal
Contudo, existem já sistemas instalados e em funcionamento, que restringem à partida o nível de abstracção que pode ser alcançado nesta investigação. Essas restrições são ao nível dos dados que se conseguem capturar, sendo que, apenas se terá acesso a parâmetros bem definidos e conhecidos à priori, por exemplo:
IP: Porta Origem / IP: Porta Destino
Bytes In/Bytes Out
Carga CPU, RAM, SWAP Dispositivos Input/Output Processos Activos
Ferramentas Antivírus, (Open) Office
Marca Temporal
Utilizador/Tipo Actividade
Para resolver os tipos de problemas referidos anteriormente sem alterar significativamente os sistemas operacionais disponíveis e sem violar a privacidade individual, são necessários mecanismos automáticos externos de monitorização e análise de abstracções do comportamento dos vários utilizadores. Estes comportamentos deverão depois ser correlacionados e analisados, em tempo-real, contra padrões esperados e reveladores de anomalias. Esses padrões vão sendo construídos incrementalmente representando a baseline de comportamento normal esperado, respondendo às perguntas, “Quem fala com quem?”, “Quando?”, ”Quanto?” e com que “Status de Desktop?” para a respectiva actividade que se está a monitorizar. Desvios anómalos desta
baseline irão indicar a ocorrência de uma anomalia.
Os dados relativos ao número, tipos de anomalias e aos seus intervenientes directos, devem numa fase posterior ser inseridos no modelo representativo da realidade da organização, uma vez que as anomalias são fenómenos que também pertencem à realidade da organização e que devem ser registados. A realidade de uma organização é definida no seu modelo de processos de negócio As-Is, que é uma representação abstracta da organização no presente, incluindo a sua estrutura, o seu relacionamento com o exterior, os seus fluxos de trabalho, os sistemas de informação e as máquinas que suportam a execução dos processos. As anomalias detectadas
devem ser transformadas em conhecimento útil para a organização, para que possam ser consultadas no futuro, pelos responsáveis interessados, para isso é necessário que esses dados sejam inseridos numa ferramenta apropriada, que seja capaz de representar essa informação de uma forma legível e em tempo útil.
Para isso, é proposto um sistema de detecção de anomalias em tempo real para grandes grupos de utilizadores, alinhado com uma ferramenta que permitirá, reflectir no modelo da realidade da organização, as anomalias detectadas e quem as pratica. Será possível também, identificar as actividades que são prejudicadas de alguma forma com ocorrência dessas anomalias, devido ao actor que está a ter um comportamento anómalo não estar a desempenhar a actividade/processo esperado.
2. Objectivos
Os objectivos desta investigação estão orientados para a resolução dos vários problemas identificados e sem uma resolução concreta na comunidade científica.
Problema 1: Como detectar e identificar em tempo-real padrões de comportamento anómalo em grandes grupos de utilizadores - Call Center?
Como detectar e identificar anomalias na infra-estrutura de suporte a grandes grupos de utilizadores, que é complexa, devido à sua dimensão e quantidade de informação que circula pelos nós de comunicação?
No entanto, devido à sua amplitude poderá ser dividido em:
Sub-Problema 1.1: Como recolher os dados específicos das diversas máquinas que são necessários para efectuar a detecção de anomalias?
Sub-Problema 1.2: Através de que métodos e técnicas poderá ser efectuada a detecção de anomalias neste ambiente, tendo em conta, o grupo restrito de dados, a quantidade de dados e a necessidade de obter uma resposta em tempo-real?
Problema 2: Como reflectir os dados da detecção de anomalias no modelo da realidade da organização?
De que forma é que se pode mapear no modelo de processos e no organigrama da organização o conhecimento obtido a partir das anomalias detectadas?
No entanto, devido à sua amplitude poderá ser dividido em:
Sub-Problema 2.1: Qual ou quais as actividades que estão a ter impacto na sua performance pela ocorrência da anomalia?
Sub-Problema 2.2: Quais os departamentos da organização / níveis hierárquicos onde ocorrem mais anomalias?
O principal contributo será a criação de um sistema de detecção e identificação de comportamentos anómalos em tempo real para um Call Center, através de:
Agente de software com baixa complexidade computacional, que recolhe de forma contínua um conjunto de dados pré-definidos e envia-os para o algoritmo de detecção que funciona centralmente.
Algoritmo machine learning, não supervisionado com funcionamento em tempo real. Serão adaptados métodos descritos na literatura, de forma a obter os melhores resultados de detecção de anomalias neste domínio de problema concreto - Call Center - com as restrições acima enunciadas.
O segundo principal contributo, será o mapeamento no modelo As-Is da organização, dos dados relativos à detecção de anomalias. Isso passará pela implementação de uma ferramenta de representação, tendo como base a ferramenta MAPA, de forma a permitir a actualização dinâmica do modelo de processos de negócio e organigrama. Servirá como base de conhecimento respondendo às perguntas enunciadas nos sub-problemas da secção anterior. Todos estes componentes irão funcionar de forma integrada numa arquitectura apresentada na secção 4.3, representando a proposta para a detecção e identificação em tempo real de padrões de comportamento anómalo em grandes grupos de utilizadores.
3. Trabalho Relacionado
Nesta secção são abordadas as várias áreas onde a investigação se enquadra, assim como os principais trabalhos consultados e tidos como referências e que de alguma forma trouxeram um contributo válido.
3.1. Arquitectura Empresarial
A arquitectura empresarial é considerada por [Vasconcelos, Tribolet e Sousa 2007] como um conjunto de representações descritivas relevantes para que a descrição da empresa possa ser produzida de acordo com os requisitos (qualidade) e que possa ser mantida ao longo do seu tempo útil (mudança).
Figura 1 – Arquitectura Empresarial
Arquitectura Organizacional – Visa representar a componente humana nas organizações. Em [Gama, et al. 2007] os autores defendem que as relações hierárquicas dentro da organização e as relações de negócio, também devem ser incluídas no desenvolvimento de SI, não chegando a relação entre a estratégia, objectivos, processos de negócio, SI e tecnologia [A. Vasconcelos 2001]. Esses autores afirmam que deve ser criado um modelo que capture quem (que actores) deve executar que tarefas e definir assim uma estrutura de responsabilidades entre actores. Para além disto a relação entre os actores e as entidades informacionais também devem ser incluídas no modelo.
Arquitectura de Negócio – Descreve como a organização opera funcionalmente, para isso descreve os processos e os objectivos necessários à implementação da estratégia. Sendo os processos de negócio o termo chave desta arquitectura, pois estes são um conjunto de actividades completas, dinamicamente coordenadas, colaborativas e transaccionais que criam valor para o consumidor, [Smith e Fingar 2003]. Os processos podem ser funcionalmente decompostos em actividades que dão informação acerca do “como”, “quando” e “quem” faz fluir o trabalho.
Arquitectura Informacional – Nesta arquitectura a informação é o termo chave e mais duradoiro, pois embora mudem os processos, a estratégia e a plataforma tecnológica a informação mantêm-se. A informação necessária para o negócio é definida de forma abstracta e independente dos processos e tecnologias, sendo estruturada em forma de entidades informacionais.
Arquitectura Aplicacional – Consiste na modelação das aplicações necessárias para que os processos de negócio possam manipular as entidades informacionais de forma automática. A utilização da matriz de CRUD - Create Read Update Delete - permite a identificação de sistemas que podem ser implementados para dar resposta à relação entre processos e entidades informacionais naquele contexto.
Arquitectura Tecnológica – Esta arquitectura visa à definição da implementação numa plataforma tecnológica das arquitecturas referidas anteriormente de modo a suportar os requisitos identificados.
3.2. Framework CEO 2007
A Framework CEO, apresentada por [Vasconcelos, Tribolet e Sousa 2007] é uma extensão à
Framework CEO 2001 de modelação de arquitectura empresarial, utiliza como linguagem de
modelação standard UML - Unified Modeling Language. Engloba as cinco arquitecturas da arquitectura empresarial, arquitectura organizacional, arquitectura negócio e arquitectura sistemas de informação. A última, é o foco principal da investigação, é composta por arquitectura de informação, aplicacional e tecnológica.
De seguida são descritos os conceitos de suporte para cada uma das arquitecturas da ASI - Arquitectura dos Sistemas de Informação - que são o foco principal da investigação de [Vasconcelos, Tribolet e Sousa 2007]:
Arquitectura Informacional – Identifica quais os principais tipos de dados que suportam o negócio da organização. Usa o conceito de entidade informacional
Arquitectura Aplicacional – Define quais as aplicações que devem ser desenvolvidas para dar suporte ao negócio e gerir os dados. O conceito chave é o bloco aplicacional, este conceito mostra como mecanismos e operações estão ligados entre si e gerem os dados de maneira independente da tecnologia. É também, através dele que serviços são disponibilizados para suportar outros blocos aplicacionais ou processos de negócio.
Arquitectura Tecnológica – São definidas quais as tecnologias necessárias para implementar as aplicações definidas na arquitectura aplicacional e qual a infra-estrutura tecnológica para as suportar. É utilizado o conceito de bloco tecnológico para definir os vários componentes. Esta define ainda os seguintes conceitos relevantes para o trabalho:
o Infra-Estrutura Tecnológica – Servidores, computadores pessoais, etc. o Plataforma Tecnológica – Sistema operativo, servidor Web, etc.
o Aplicação Tecnológica – Software que está instalado numa plataforma tecnológica.
Para uma leitura mais aprofundada das vantagens consultar [Vasconcelos, Tribolet e Sousa 2007], destacando-se pela distinção entre os componentes tecnológicos e o facto de a
Framework ser suportada e formalizada em UML, permitindo a sua extensão, se necessário. Esta
será utilizada na investigação para efectuar a modelação da arquitectura empresarial do Call
Center.
3.3. Modelo Organizacional As-Is e To-Be
Os modelos filtram as actividades irrelevantes do mundo real e mostram as partes mais importantes do sistema em estudo. Assim, modelos de negócio têm o objectivo de informar os seus utilizadores, mostrando que actividades compõem o processo, quem as executa, onde e quando são executadas e que elementos de dados manipulam [Giaglis 2001].
O objectivo da modelação de negócio é a produção de descrições ou abstracções de realidades complexas que capturem as funções core de um negócio. Os motivos apresentados por [Castela e Tribolet 2001] para a modelação de negócio são:
Melhor compreender os mecanismos chave de um determinado negócio. Servir como base de suporte aos sistemas de informação
Melhorar ou mudar radicalmente o negócio através da análise dos worflows.
Identificar novas oportunidades de negócio, como fazer outsourcing de processos não “core”.
Segundo [Giaglis 2001], existem quatro perspectivas de modelação que qualquer técnica de modelação deve representar:
Perspectiva Funcional – Representa os elementos dos processos que estão a ser modelados, as actividades.
Perspectiva Comportamental – Representa como as actividades são executadas no tempo (ciclos, iterações ou condições de tomada de decisão).
Perspectiva Organizacional – Representa o “como?” e o “porquê?” da execução das actividades, os mecanismos de comunicação físicos utilizados para transferência das entidades informacionais, meios físicos e localização das entidades informacionais armazenadas.
Perspectiva Informacional – Representa as entidades informacionais produzidas ou manipuladas pelos processos e respectivos relacionamentos.
O termo modelação de processos de negócio tem sido utilizado para incorporar todas as actividades relacionadas com a transformação do conhecimento acerca do negócio em modelos que descrevem os processos realizados pelas organizações [Reiter e Stickel 1996].
3.3.1.
As-Is
O modelo de processos de negócio As-Is é uma representação abstracta da organização no presente, incluindo a sua estrutura, o seu relacionamento com o exterior, os seus fluxos de trabalho, os sistemas de informação e as máquinas que suportam a execução dos processos [Castela e Tribolet 2008].
O modelo As-Is responde às seguintes questões:
Que actividades são necessárias para caracterizar um processo?
Quando é que as actividades são executadas, e qual a ordem de execução? Porque é que as actividades são executadas, qual é o objectivo do processo? Como é que as actividades são executadas?
Quais os recursos consumidos e produzidos? Como é que as actividades devem ser executadas? Quem é que controla os processos?
Como é que o processo está relacionado com a organização? Como é que os processos se relacionam com outros processos? Que sistemas de informação suportam os processos?
Para responder aos pontos anteriores a construção do modelo persegue os objectivos: Servir de base para a melhoria dos processos (TQM)
Servir de base para a inovação dos processos (BPR) Ponto de partida para a construção de uma ASI
Ponto de partida para a captura de requisitos para o desenvolvimento de SI Servir como repositório de conhecimento comum da organização
Este modelo é uma peça importante para os seus utilizadores, pois promove a compreensão do funcionamento da organização, para isso cada utilizador deve explorar o modelo com diferentes níveis de detalhe. Os gestores utilizam um nível mais alto do modelo enquanto funcionários de uma actividade específica utilizam um nível com mais detalhe.
Funcionários – Representa as actividades, os processos onde estão inseridas e os sistemas de informação que lhes dão suporte.
Gestores – Satisfaz as necessidades destes utilizadores usando representações de mais alto nível, para dar suporte às tomadas de decisão. Exemplos disso são as estratégias, processos de negócio e SI de alto nível.
Equipas de monitorização e gestão de qualidade – Tem documentados os processos existentes.
Equipas de desenvolvimento:
o Arq. Empresarial – Dá entendimento de como as arquitecturas actuais suportam os processos e partir daí para uma nova arquitectura
o Soft. Empresarial – Contêm dos requisitos funcionais e não funcionais
O modelo As-Is é considerado um repositório de conhecimento da organização, trazendo assim as seguintes vantagens [Castela e Tribolet 2008]:
Aumentar o conhecimento do que cada um está a fazer como parte do todo organizacional
Facilitar a comunicação por permitir focar “o ponto de vista certo” Tornar a organização explícita
Servir como base documental para a gestão de qualidade (ISO9000:2001) Definir objectivos para todos os processos
Clarificar quem são os actores nos processos através de: Identificação do relacionamento fornecedor/cliente
Identificar quem está a contribuir com o quê para o processo Clarificar que factores internos ou externos influenciam o processo
3.3.2.
To-Be
Esta investigação abrange a área que se encontra a montante deste, o As-Is organizacional, é feita aqui referência para ressalvar que a maior parte dos métodos de modelação de processos de negócio seguem uma abordagem top-down e que esse método é mais adequado para a criação do modelo To-Be [Castela e Tribolet 2001]. Partindo dos processos de negócio de mais alto nível é feito um drill-down nos processos até se chegar às actividades que os compõem.
3.4. PROASIS
Nesta secção é descrita a metodologia de actualização dinâmica do modelo As-Is PROASIS - Process As-Is. Em [Castela, Zacarias e Tribolet 2010] é dito que, “O modelo de processos de
negócio é normalmente descartado depois da sua utilização inicial, pois deixa de estar actualizado“, sendo esta a motivação para a metodologia PROASIS. As anotações são um
mecanismo para que a experiência da execução dos processos seja capturada. As anotações são realizadas pelos intervenientes nos processos e usada para manter o modelo As-Is actualizado. A execução de certas actividades dentro de uma organização estão a cargo de apenas um indivíduo, sendo que esse detém todo o conhecimento acerca dessa tarefa, é então necessário tornar explícito esse conhecimento para a organização, podendo ser utilizado o mecanismo de anotações para esse fim. Para evitar os desalinhamentos entre o modelo partilhado e a realidade é proposta uma actualização do modelo através de um mecanismo de anotações.
Existem anotações a três níveis:
Processos – Apenas o dono do processo pode realizar anotações no processo de negócio.
Actividades – Actores podem aceder directamente às actividades e aos recursos.
Unidades Organizacionais – As anotações são realizadas por quem é o responsável pelas unidades organizacionais de um dado processo.
As anotações podem ser classificadas como:
Adaptativa – Permite adaptar para um novo contexto de execução de um processo ou actividade.
Perfectiva – Permite melhorar a descrição de actividades ou processos pela recolha de mais informação.
O dono do processo em conjunto com o responsável pela unidade organizacional são as entidades que verificam e validam as anotações propostas pelos actores organizacionais e as inserem no modelo de processos de negócio da organização.
Relativamente a esta investigação, os dados das anomalias poderão ser utilizados por actores e
stakeholders, consoante o nível de detalhe que se quer atingir, pois existem várias necessidades
de informação para cada um desses níveis. Se existirem por exemplo, anomalias que ponham em causa a integridade da organização serão despoletados alarmes, notificando um ou mais actores que possam intervir para resolver a situação. Uma auditoria levada a cabo por uma entidade externa poderá requerer o acesso a informação mais detalhada. As anomalias poderão ainda ser analisadas por um nível hierárquico de topo em conjunto com um especialista, permitindo concluir a existência de mudanças na execução do processo, respondendo a questões como as apresentadas na secção 2.
3.5. Ferramenta Colaborativa para Manutenção e Modelação de PN
As ferramentas de modelação de processos de negócio são cada vez mais utilizadas por organizações que têm de criar e adaptar novos processos de maneira a manterem a competitividade. As actividades necessárias à criação, gestão e reengenharia dos processos de negócio são o desenho de processos, a simulação de processos, a análise de processos e a optimização de processos [Castela e Tribolet 2001].
3.5.1.
Ferramenta MAPA
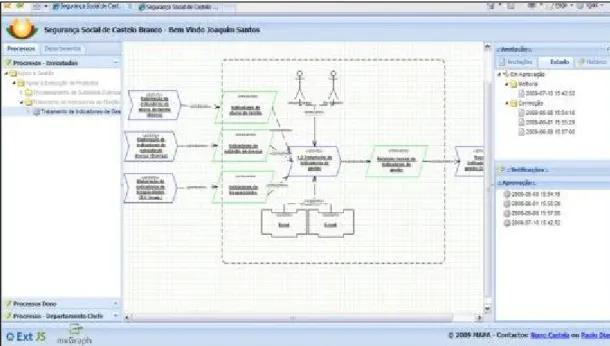
A ferramenta MAPA [Castela, Dias, et al. 2010], Figura 2, tem o propósito de capturar, através de anotações, as alterações ao modelo feitas pelos actores organizacionais. A linguagem BPMN é utilizada para representar os processos de negócio em que o actor está envolvido.
Características principais: Manipular as anotações Anotar qualquer objecto Diferentes níveis de acesso
Possibilita um desacoplamento do modelo em vistas, mas garantindo a sua integridade. A ferramenta ROA tem por base o conceito de vistas sobre os processos de negócio da ferramenta MAPA.
Figura 2 – Screenshot da ferramenta MAPA
3.6. Agente Recolha de Dados
São sistemas de software autónomos com a função de recolher informação do ambiente onde está inserido. Recolhem os dados necessários para que seja deduzida da maneira mais exacta possível se existe ou não uma anomalia no sistema, de acordo com uma especificação prévia de um especialista no negócio. São exemplo disso:
Chamadas de Sistema, Linha de Comandos e Aspectos de Rede
Em [Apap, et al. 2002], utilizaram os acessos ao Windows registry para detectar anomalias, utilizam técnica com conjunto de dados semi-supervisionado.
Em [Shavlik e Shavlik 2004] recolhiam tráfego de rede, velocidade de escrita do utilizador, programas em execução. Dados relativos aos programas em execução eram também captados, por exemplo, número de ficheiros abertos com o Microsoft Excel, o processador consumido pelo comando cmd e a quantidade de impressões realizadas.
3.7. Algoritmo Tempo-Real para Detecção Anomalias
Um algoritmo, cujo funcionamento se diz ser em tempo-real, significa que, esse algoritmo executa dentro de um intervalo de tempo definido para dar uma resposta. A alta dimensionalidade dos dados requer mais tempo de processamento e muitos dos algoritmos requerem que os datasets estejam inteiramente em memória [Yankov, Keogh e Rebbapragada 2008], características que não podem ser utilizadas para processamento em tempo-real.
É necessário o aparecimento de técnicas com grande capacidade de tratamento de dados, capaz de receber dados em streaming para efectuar uma detecção em tempo real da intrusão. Devido à inúmera quantidade de dados produzidos num ambiente deste tipo não é possível guardar todos os dados gerados, apenas os mais relevantes, para isso, técnicas de redução de dimensionalidade permitem definir quais os componentes principais que definem um dado conjunto de dados e guardar apenas, por exemplo, quando existem alterações significativas.
Passamos de seguida a mostrar algumas das técnicas usadas para esse propósito.
3.7.1
Algoritmo Frahst
Em [Teixeira e Milidiú 2010] os autores apresentam um algoritmo não supervisionado com dados em stream. Este sistema efectua uma detecção de anomalias baseada no número de variáveis latentes do sistema, isto é conseguido de forma dinâmica sem ser necessário recorrer a
thresholds definidos antecipadamente.
Devido a grande dimensionalidade dos dados é necessário aplicar técnicas de redução de dimensionalidade: Estes métodos facilitam a análise dos dados, bem como a compressão.
Principal Subspace Tracking – A técnica de subspace tracking é semelhante à de PCA,
tem o mesmo propósito de redução de dimensionalidade. São identificadas as variáveis latentes que melhor representam o subespaço, da mesma forma que no PCA se identificam os componentes principais. Nesta abordagem, a matriz de co-variância não está disponível de uma vez, devido aos dados chegarem em streaming, é feita uma estimação recursiva do subespaço principal, directamente da matriz de co-variância que vai sendo actualizada ao longo do tempo. Em todos os intervalos de tempo vai sendo efectuado uma decomposição para se encontrar as partes dominantes, primeiro os valores próprios dominantes e a partir desses os vectores próprios dominantes que representam o subespaço principal.
Principio Iteração Ortogonal – A iteração ortogonal é uma extensão do power method
- método para encontrar o vector próprio dominante através de incrementos dos expoentes
nos vectores próprios - a aplicação desta técnica ao subspace tracking foi proposta por [Owsley 1978].
A(t) = Q(t)*S(t)
É usada uma factorização QR, apresentada em [Jorge s.d.], onde A(t) é uma matriz auxiliar, Q(t) é a matriz da estimativa dos vectores próprios e S(t) a matriz da estimativa dos valores próprios. Este método é utilizado para garantir que os vectores próprios calculados são sempre ortogonais entre si, esta é uma propriedade importante pois impede que exista propagação de erros para as próximas iterações do algoritmo.
Com base em dados anteriores as matrizes aqui descritas vão sendo calculadas para fornecerem as estimativas do subespaço formado pelos dados actuais.
Foi notado por [Strobach 2009] que se apenas for procurada uma base do subespaço principal, não é necessário calcular toda a matriz S, deste modo a matriz Q deixará de conter os vectores próprios reais, passando a conter um conjunto de vectores que são uma estimativa desses. Servindo para reduzir a complexidade do algoritmo sem afectar o resultado.
Fast Householder Subspace Tracker – Chamam-se de domínio S, devido a contornar o
problema do update da matriz quadrada inversa. Isto é feito através da técnica de
Householder Reflection, garante a ortogonalidade das bases do subespaço e devolve boas
estimativas dos subespaços.
O algoritmo, Figura 3, é uma extensão do algoritmo proposto por [Strobach 2009]. Não sofre de instabilidade numérica, problemas inerentes a outros algoritmos semelhantes – [Yang 1995], apresenta instabilidade devido ao update da matriz inversa no decorrer das suas operações, [Teixeira e Milidiú 2010].
O Frahst funciona com uma baixa complexidade computacional, O(n*r), onde a letra “n” representa o número de dimensões dos dados e o “r” o número streams, é conseguido através da técnica de subspace tracking.
À medida que os streams vão chegando provenientes dos múltiplos agentes espalhados pelos
Call Centers, vai sendo actualizada a matriz que estima o subespaço. Caso exista uma alteração
na dimensão do subespaço é detectada uma anomalia. Características:
Cálculo automático do rank da matriz – O algoritmo consegue detectar automaticamente a dimensão do subespaço, sem necessitar que isso seja passado como argumento. Através do limiar de energia.
Factor de esquecimento – É utilizado no algoritmo para propagar de forma temporal, alterações nos dados.
O autor Pedro Teixeira em [Teixeira e Milidiú 2010], comparou a performance entre três algoritmos online (Frasht, Spirit e Koad) e dois em batch (Ocnm e Q-Pca). O algoritmo Frasht obteve a melhor classificação média para os datasets testados, sendo por isso uma potencial base de partida para esta investigação.
Em suma, é pretendido usar alguns dos métodos aqui mostrados para efectuar a detecção de anomalias no Call Center. As técnicas aqui mostradas serão utilizadas para processamento em tempo-real de anomalias e os respectivos autores mostram resultados positivos, garantindo uma baixa complexidade computacional e taxas elevadas de detecção de anomalias. No entanto, os tipos de dados utilizados por eles são diferentes dos que serão usados nesta tese, bem como as anomalias que queremos detectar são também mais específicas neste problema.
Esta tese procura assim, através da utilização de um destes métodos provar que é possível detectar estes tipos de anomalias num Call Center.
4. Proposta de Solução
Nesta secção será dado ênfase aos desenvolvimentos que foram realizados até à data para esta investigação.
4.1. Visão Global da Arquitectura
A proposta para a arquitectura final é apresentada na Figura 4, sendo explicada a relação entre os diferentes componentes.
Figura 4 – Proposta de arquitectura de solução
Os agentes serão instalados em cada uma das máquinas – pcs -de cada um dos Call Centers da empresa, estes recolhem os dados para a detecção de anomalias, como referido anteriormente e sendo posteriormente enviados pela rede, através do protocolo UDP para a central. Aí será instalado todo o software de suporte à arquitectura cliente/servidor multi-threading e o algoritmo que detecta as anomalias, esse recebe os dados em streaming dos vários agentes e correlaciona-os através de uma técnica própria e detecta a ocorrência ou não de anomalias nos dados. É omisso na Figura 4, mas é possível que seja necessário um mecanismo de buffering, para guardar temporariamente os streams. Em caso de anomalia, é lançado um alarme para o
computador do responsável de serviço e as informações serão actualizadas na base de dados de suporte à ferramenta.
4.2. Recolha de Dados
A fase de recolha de dados é o ponto de partida, pois é com estes conjuntos de dados que são recolhidos por cada um dos agentes em cada uma das máquinas que vai ser inferido a ocorrência ou não de anomalias.
É utilizada a linguagem de programação orientada a objectos C#, que deriva da plataforma .Net da Microsoft. Isto é utilizado em conjunto com o Windows Management Instrumentation (WMI) que fornece uma interface para recolha de dados relativos aos componentes de um sistema. De seguida são especificadas as métricas recolhidas:
O conjunto básico CPU, RAM, SWAP, DISKIO e NETIO da máquina.
Os dados relativos ao CPU, RAM consumidos por determinado processo. O processo ou conjunto de processos sobre os quais se querem obter dados podem ser previamente especificados num ficheiro que será lido pelo programa de que cada vez que este se iniciar. Informação acerca dos acessos IP origem/destino para a máquina, número de bytes trocados, as portas utilizadas e que protocolos são utilizados na comunicação.
As métricas apresentadas são escritas por um agente – daemon - num log file circular, de tamanho fixo e em períodos de tempo pré-estabelecidos. Esse foi implementado de forma a eliminar a necessidade de alocação contínua de espaço de armazenamento para os dados recolhidos. De cada vez que é atingido o tamanho máximo do log file, o programa volta a escrever no início, fazendo um overwrite ao conteúdo existente. A implementação permite ainda que sejam retirados da lista um número desejado de objectos.
Existe ainda outro daemon que em intervalos de tempo pré-definidos, retira dados do log file e produz médias e totais desses dados nesse intervalo de tempo, enviando-os de seguida para um servidor central onde se encontra o algoritmo. Antes de proceder ao envio e de forma a tornar a comunicação o mais eficiente possível, os dados são compactados utilizando tags JSON – que serializa e transmite informação estruturada, sendo uma alternativa ao XML, um exemplo desses dados pode ser consultado em [Jorge s.d.].
Cada um dos objectos contém no cabeçalho, o nome da máquina de origem; o IP que lhe está atribuído e uma marca temporal - timestamp- do momento da captura.
4.3. Algoritmo
A execução do algoritmo é realizada de forma manual, assume-se nesta investigação que existe um indivíduo cuja função é executar o algoritmo em determinados intervalos de tempo para que possa ser detectada a ocorrência de anomalias, pois o algoritmo Frahst está implementado através da Linguagem R e não é o âmbito deste trabalho realizar uma integração do mesmo na arquitectura global de forma a automatizar o processo de forma end-to-end.
De seguida descrevem-se os passos dados para que possam ser detectadas anomalias neste ambiente específico:
Dados recebidos - Todos os streams recebidos no servidor são processados e escritos para dois ficheiros distintos, sendo:
o Input para algoritmo - Armazena dados até à próxima execução do algoritmo, sendo de seguida eliminado do sistema. Estes dados são apenas os necessários para inferir a existência ou não de anomalias.
o Origem dos dados - Regista a origem dos dados e qual o username que estava no pc. Caso tenha sido detectada uma anomalia, este ficheiro permite relacionar o utilizador, a localização e o tipo de anomalia com os processos dos Call
Centers, não sendo possível através deste ficheiro identificar a pessoa que
possui esse username. A relação entre utilizador e Pessoa será inserida na base de dados por uma query específica e completamente imperceptível.
Dados de teste - Relativamente aos dados de teste, foram recolhidos streams produzidos por duas máquinas durante cerca de 60 minutos, com cada máquina a debitar informação de três em três segundos. Foram recolhidos dois perfis de dados que caracterizam extremos comportamentais na utilização de um pc, um que representa uma utilização quase nula do sistema e outro que pelo contrário representa uma carga elevada de todos os parâmetros que estão a ser recolhidos.
Cada um dos streams recebidos corresponde a uma linha do respectivo ficheiro. Para além disso o ficheiro é composto por um conjunto de colunas que representam a métrica indicada na primeira linha do ficheiro.
Teste de detecção - Após a recolha dos dados relativos aos vários cenários comportamentais, foram criados vários ficheiros de teste que visam simular um cenário real, são constituídos por streams obtidos nos ficheiros de comportamento normal e anómalo, capturados anteriormente. Cada um deles corresponde a um cenário de teste diferente, esses testes variam nomeadamente pelos intervalos de tempo onde as streams
de comportamento anómalo surgiam no ficheiro (em que linhas) e a duração (número de linhas consecutivas). Desta forma foi possível simular um cenário quase real, abrangendo vários cenários de teste e permitindo testar a capacidade de detecção do algoritmo.
Figura 5 – Resultado algoritmo sobre dados de teste
Na Figura 5 esta representado o resultado da execução do algoritmo sobre os dados de teste que se encontram em [Jorge s.d.], quando existe um aumento da variável r, significa que foi detectada uma anomalia. A variável tempo indica a linha em que foi detectada a anomalia, é possível constatar que foram detectadas todas as anomalias do ficheiro.
Parametrização do algoritmo: Contudo a detecção de anomalias num ambiente tão dinâmico e variável não se revela uma tarefa trivial, visto que para o algoritmo detectar a totalidade das streams anómalas inseridas no ficheiro de teste, é necessária a optimização dos parâmetros de input do algoritmo o que pode se revelar uma tarefa morosa. Os parâmetros necessários optimizar são:
o Alpha – Factor Esquecimento
o Energy Low e Energy High – Limite mínimo e máximo de energia o Hold Off Time – Tempo de espera
Foram obtidos resultados que confirmaram a ocorrência positiva de anomalias nos intervalos de tempo e para as durações a testar, sendo assim possível detectar em tempo-real a ocorrência de comportamentos anómalos em grandes grupos de utilizadores. De seguida, será assim possível inserir e representar essa anomalia no modelo de As-Is da organização.
Contudo, um aspecto a ter em conta para a correcta detecção deste tipo de anomalias serão as possíveis diferenças entre as máquinas do Call Center, sendo que máquinas com componentes
diferentes possuem níveis de utilização anómalas diferentes, assim assume-se neste trabalho que todas as máquinas são constituídas com o mesmo hardware.
4.4. Vistas e Representação As-Is
A ferramenta de Representação Organizacional de Anomalias (ROA), Figura 6, permite consultar diferentes tipos de vistas sobre o modelo de processos dos Call Centers, sendo elas:
Vistas de processos Vistas de Call Centers Vista de Actores
Vista de Pessoas (Apenas Auditoria)
Figura 6 – Ferramenta ROA
Esta implementação da ferramenta é um protótipo que foi implementado em PHP e MySql e desenvolvido para mostrar as potencialidades e contributos desta investigação, encontrando-se ainda em fase de desenvolvimento.
A ferramenta permite representar cada uma das vistas apresentadas atrás e oferece ainda a possibilidade de navegar através delas, podendo ser efectuadas múltiplas combinações até um máximo de três níveis de profundidade. O drill-down é conseguido através de botões associados a cada objecto em cada uma das vistas. Quando é seleccionado um dado botão, de certo objecto, em determinado nível, essa informação é utilizada para criar uma query dinâmica de forma a produzir os resultados desejados.
De seguida é exemplificada a utilização da ferramenta, para três níveis e com a seguinte ordem: actores, processos e Call Center. O processo inicia-se através da selecção do botão “Actores”, Figura 6, que irá despoletar a “Vista de Actores”, Figura 7, onde são representados todos os actores que fazem parte da organização e respectivos tipos e números de anomalias. Aqui, é possível ainda navegar para mais dois níveis de detalhe, selecciona-se o botão “processos” - um dos dois botões apresentados - referente ao actor “chefe” na Figura 7 e será apresentada uma nova vista com todos os processos de negócio onde intervém esse actor, sendo que agora apenas será possível navegar para mais um nível de detalhe. Se o utilizador desejar pode ainda visualizar em que Call Centers é que existe o processo especificado e no qual participa o actor “chefe”, bastando para isso seleccionar o botão – único – disponível.
Em qualquer um dos níveis, ao pressionar o botão “main” todo o processo é reinicializado, voltando ao ecrã inicial, será ainda implementado um botão que permitirá voltar ao nível anterior facilitando assim a navegação aos utilizadores.
Esta implementação traz limitações, nomeadamente ao nível do layout, onde os “Actores” estão a ser representados como texto, lido directamente da base de dados e idealmente as vistas serão desenhadas como apresentado nas Figuras 8 e 9.
As melhorias no layout serão concretizadas pela utilização de JavaScript com bibliotecas próprias para representações gráficas, proporcionando uma maior qualidade na representação dos modelos para o utilizador final.
Todo este modelo é suportado por uma base de dados onde são registados todos os comportamentos anómalos que são detectados. O Modelo Entidade-Associação e o Modelo Relacional podem ser consultados em[Jorge s.d.].
Figura 8 – Exemplo de hierarquia de processos e representação das anomalias
5. Próximos Passos
Esta investigação foi motivada pela identificação de vários problemas enumerados no início da secção 2, após uma pesquisa e análise crítica na literatura referenciada, é assim intenção que esta investigação venha colmatar essa ausência de uma solução nesta temática e domínio específico, através dos vários contributos referidos no final da secção 2.
Foram identificados os problemas da recolha de dados dos vários Call Centers, a detecção das anomalias em tempo-real e a representação dos dados referentes às anomalias no modelo AS-IS da organização. Relativamente à recolha de dados das várias máquinas e ao algoritmo, os desenvolvimentos encontram-se praticamente concluídos. Quanto à ferramenta de representação serão implementadas as restantes vistas e serão feitos os melhoramentos necessários aos layouts para dar uma experiência mais agradável aos utilizadores. Quando estes tiverem concluído na totalidade, serão integrados numa arquitectura global e apresentar-se-ão completamente alinhados com os objectivos propostos. Será também tido em mente a importância da fase de testes e recolha de dados, de forma a sustentar e validar os resultados obtidos. Trazendo assim um contributo cientifico válido para a detecção e identificação em tempo-real de padrões de comportamento anómalo em grandes grupos de utilizadores – Call Centers e a sua representação no modelo AS-IS da organização.
6. Referências
Apap, Frank, Andrew Honig, Shlomo Hershkop, Eleazar Eskin, e Sal Stolfo. “Detecting Malicious Software by Monitoring Anomalous Windows Registry Accesses.” RAID 2002, LNCS 2516, pp. 36–53, 2002.
Castela, N., e J. Tribolet. “Recolha, Análise e Validação de Informação para a Modelação de Processos de Negócio.” Dissertação para obtenção do Grau de Mestre em Engenharia Informática e de Computadores, Instituto Superior Técnico, Universidade Técnica de Lisboa, Lisboa, 2001.
Castela, N., e J. Tribolet. “Representação As-Is em Engenharia Organizacional.” International
Conference on Enterprise Information Systems. ICEIS 2008, Jun 2008.
Castela, Nuno, M Zacarias, e José Tribolet. “Business Process Model Dynamic Updating.”
Enterprise Information Systems. International Conference, CENTERIS 2010. Viana do Castelo,
Portugal, Outubro 2010.
Castela, Nuno, Paulo Dias, P. Zacarias, e José Tribolet. “MAPA: Monitoring and Annotation of Processes and Activities.” CENTERIS 2010, 2010.
Community, CodePlex Open Source. R.NET. http://rdotnet.codeplex.com/ (acedido em 30 de 06 de 2011).
Gama, N., M. Silva, A. Caetano, e J. Tribolet. “Integrar a Arquitectura Organizacional na Arquitectura Empresarial.” 7ª Conferência da Associação Portuguesa de Sistemas de
Gama, Nelson, Miguel Mira da Silva, Artur Caetano, e José Manuel Nunes Salvador Tribolet. “Integrar a Arquitectura Organizacional na Arquitectura Empresarial.” 7ª Conferência da Associação Portuguesa de Sistemas de Informação, Jan. 2007.
Giaglis, G. “A Taxonomy of Business Process Modeling and Information Systems Modeling Techniques.” International Journal of Flexible Manufacturing Systems, 2001.
Jorge, Tiago. Capsi2011. http://web.ist.utl.pt/tiago.simoes.jorge/IST/capsi.html (acedido em 28 de 06 de 2011).
Mills, Robert F., Gilbert L. Peterson, e Michael R. Grimaila. “Insider Threat Prevention,Detection,and Mitigation.” IGI Global, 2009.
Owsley, N. “Adaptive Data Orthogonalization.” ICASSP'78, 1978. Reiter, B., e E. Stickel. Business Process Modelling. Springer, 1996.
Shavlik, Jude, e Mark Shavlik. “Selection, combination, and evaluation of effective software sensors for detecting abnormal computer usage.” KDD '04 Proceedings of the tenth ACM SIGKDD international conference on Knowledge discovery and data mining, 2004.
Smith, H., e P. Fingar. “Business Process Management (BPM): The Third Wave.” Meghan-Kiffe Press, 2003.
Strobach, Peter. “The fast recursive row-householder subspace tracking algorithm.” Elsevier Journal Signal Processing 89, 2514–2528, 2009.
Teixeira, Pedro Henriques dos Santos, e Ruy Luiz Milidiú. “Data Stream Anomaly Detection Through Principal Subspace Tracking.” SAC '10 Proceedings of the 2010 ACM Symposium on Applied Computing , 2010.
Vasconcelos, A., J. Tribolet, e P. Sousa. “Arquitecturas dos Sistemas de Informação: Representação e Avaliação.” Dissertação para a obtenção do Grau de Doutor em Engenharia Informática e de Computadores, Instituto Superior Técnico, Universidade Técnica de Lisboa, Lisboa, 2007.
Vasconcelos, André. “Arquitectura de Sistemas de Informação no Contexto do Negócio.” Dissertação para a Obtenção do Grau de Mestre em Engenharia Informática e de Computadores, Instituto Superior Técnico, Universidade Técnica de Lisboa, Lisboa, 2001.
Yang, Bin. Projection Approximation Subspace Tracking. Vols. 43, 95 - 107 . IEEE Transactions on Signal Processing, 1995.
Yankov, Dragomir, Eamonn Keogh, e Umaa Rebbapragada. “Disk aware discord discovery: finding unusual time series in terabyte sized datasets.” Springe, Knowledge and Information Systems 17:241–262, 2008.

![Figura 3 – Algoritmo Frahst [Teixeira e Milidiú 2010]](https://thumb-eu.123doks.com/thumbv2/123dok_br/17030960.766691/14.892.213.677.437.1085/figura-algoritmo-frahst-teixeira-e-milidiú.webp)




