Classificação automática de páginas Web Multi-label via MDL e Support Vector Machines
124
0
0
Texto
(2) Universidade de Bras´ılia Instituto de Ciˆencias Exatas Departamento de Ciˆencia da Computa¸c˜ao. Classificação Automática de Páginas Web Multi-label via MDL e Support Vector Machines. Rodrigo de La Rocque Ormonde. Disserta¸ca˜o apresentada como requisito parcial para conclus˜ao do Mestrado em Inform´atica. Orientador Marcelo Ladeira. Bras´ılia 2009.
(3) CIP — Cataloga¸c˜ ao Internacional na Publica¸c˜ ao Ormonde, Rodrigo de La Rocque. Classificação Automática de Páginas Web Multi-label via MDL e Support Vector Machines / Rodrigo de La Rocque Ormonde. Bras´ılia : UnB, 2009. 122 p. : il. ; 29,5 cm. Disserta¸ca˜o (Mestrado) — Universidade de Bras´ılia, Bras´ılia, 2009. 1. Classificação de Páginas Web, 2. Classificação Multi-label, 3. Support Vector Machines, 4. SVM, 5. MDL, 6. Codificação de Huffman CDU 004.8. Endere¸co:. Universidade de Bras´ılia Campus Universit´ario Darcy Ribeiro — Asa Norte CEP 70910-900 Bras´ılia–DF — Brasil.
(4) Universidade de Bras´ılia Instituto de Ciˆencias Exatas Departamento de Ciˆencia da Computa¸c˜ao. Classificação Automática de Páginas Web Multi-label via MDL e Support Vector Machines. Rodrigo de La Rocque Ormonde. Monografia apresentada como requisito parcial para conclus˜ao do Mestrado em Inform´atica. Marcelo Ladeira (Orientador) CIC/UnB. Nelson Francisco F. Ebecken COPPE/UFRJ. Célia Ghedini Ralha CIC/UnB. Li Weigang Coordenador do Mestrado em Inform´atica. Bras´ılia, 28 de Agosto de 2009.
(5) Agradecimentos Agradeço a todos os que me apoiaram ao longo de todo este período em que estive desenvolvendo esta pesquisa. Em especial, agradeço à minha esposa Roberta, que sempre me apoiou e me incentivou, mesmo quando eu não lhe podia dar a atenção que ela necessitava e merecia.. iv.
(6) Abstract In this research, it is developed the extension of a new classification algorithm, called CAH+MDL, previously conceived to deal only with binary or multi-class classification problems, to treat directly multi-label classification problems. Its accuracy is then studied in the classification of a database comprised of Web sites in Portuguese and English, divided into seven multi-label categories. This algorithm is based on the principle of the Minimum Description Length (MDL), used together with the Huffman Adaptive Coding. It has already been studied for binary classification in SPAM detection and has presented good results, however, to the best of my knowledge, it had never been studied before for the multi-label case, which is much more complex. In order to evaluate its performance, its results are compared with the results obtained in the classification of the same database by a linear SVM, which is the algorithm that usually presents the best results in pattern classification and, specially, in text classification.. v.
(7) Resumo Nesta pesquisa é feita a extensão de um novo algoritmo de classificação, chamado de CAH+MDL, anteriormente desenvolvido para lidar apenas com problemas de classificação binários ou multiclasse, para tratar diretamente também problemas de classificação multilabel. Foi estudado então seu desempenho para a classificação de uma base de páginas Web em Português e Inglês, divididas em sete categorias multi-label. Este algoritmo é baseado no princípio da Minimum Description Length (MDL), utilizado juntamente com a Codificação Adaptativa de Huffman e foi anteriormente estudado para a classificação binária na detecção de SPAM, tendo apresentado bons resultados. Não foram encontradas citações na literatura, entretanto, de sua utilização para o caso multi-label, que é bem mais complexo. Para avaliar seu desempenho, os resultados são comparados com os resultados obtidos na classificação da mesma base de dados por uma SVM linear, que é o algoritmo que normalmente apresenta os melhores resultados na classificação de padrões e, especialmente, na classificação de textos.. vi.
(8) Sum´ ario Abstract. v. Resumo. vi. Lista de Figuras. x. Lista de Tabelas. xi. Glossário 1. Introdução 1.1 Definição do Problema . . . . . . 1.2 Justificativa do Tema . . . . . . . 1.3 Contribuição Científica Esperada 1.4 Organização deste documento . .. xii. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. 1 1 2 2 3. 2. Classificação de Dados 2.1 Tipos de classificação . . . . . . . . . . . . . . 2.1.1 Binária . . . . . . . . . . . . . . . . . . 2.1.2 Multiclasse . . . . . . . . . . . . . . . 2.1.3 Multi-label . . . . . . . . . . . . . . . 2.2 Métodos de Decomposição . . . . . . . . . . . 2.2.1 Um contra todos . . . . . . . . . . . . 2.2.2 Um contra um . . . . . . . . . . . . . . 2.2.3 Grafos de Decisão Acíclicos Orientados 2.3 Treinamento de Classificadores Multi-label . . 2.3.1 Rótulo Único . . . . . . . . . . . . . . 2.3.2 Ignorar Multi-label . . . . . . . . . . . 2.3.3 Nova Classe . . . . . . . . . . . . . . . 2.3.4 Treinamento Cruzado . . . . . . . . . . 2.4 Medidas de Desempenho . . . . . . . . . . . . 2.4.1 Precisão . . . . . . . . . . . . . . . . . 2.4.2 Recall . . . . . . . . . . . . . . . . . . 2.4.3 F-Measure . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . . .. 4 4 5 5 6 6 6 7 8 8 9 10 10 11 12 12 13 14. . . . .. vii. . . . .. . . . .. . . . .. . . . .. . . . ..
(9) 3. Classificação de textos e páginas Web 3.1 Representação de documentos textuais . . . . . . . . . 3.1.1 Binária . . . . . . . . . . . . . . . . . . . . . . . 3.1.2 Freqüência dos termos . . . . . . . . . . . . . . 3.1.3 Freqüência dos termos - inversa dos documentos 3.2 Propriedades da Classificação de Textos . . . . . . . . . 3.2.1 Alta Dimensionalidade . . . . . . . . . . . . . . 3.2.2 Vetores Esparsos . . . . . . . . . . . . . . . . . 3.2.3 Complexidade Lingüística . . . . . . . . . . . . 3.2.4 Alta Redundância . . . . . . . . . . . . . . . . . 3.3 Pré-processamento . . . . . . . . . . . . . . . . . . . . 3.3.1 Normalização . . . . . . . . . . . . . . . . . . . 3.3.2 Stemming / Lematização . . . . . . . . . . . . . 3.3.3 Remoção de Stopwords . . . . . . . . . . . . . 3.3.4 Remoção de palavras raras . . . . . . . . . . . . 3.4 Seleção de Atributos . . . . . . . . . . . . . . . . . . . 3.5 Ponderação de Termos . . . . . . . . . . . . . . . . . . 3.6 Classificação de páginas Web . . . . . . . . . . . . . . . 3.6.1 Particularidades . . . . . . . . . . . . . . . . . . 3.6.2 Estrutura de uma página Web . . . . . . . . . . 3.6.3 Abordagens de classificação de páginas Web . . 3.6.4 Tipos de classificação . . . . . . . . . . . . . . . 4. Support Vector Machines 4.1 Hard-Margin SVM . . . . . . . . . . . . . 4.1.1 Formalização . . . . . . . . . . . . 4.2 Soft-Margin SVM . . . . . . . . . . . . . . 4.2.1 Formalização . . . . . . . . . . . . 4.3 SVM Não lineares . . . . . . . . . . . . . . 4.3.1 Formalização . . . . . . . . . . . . 4.4 Outros tipos de SVM binárias . . . . . . . 4.4.1 SVM ponderada . . . . . . . . . . . 4.4.2 Nu-SVM . . . . . . . . . . . . . . . 4.5 SVM Multiclasse . . . . . . . . . . . . . . 4.5.1 M-SVM de Weston e Watkins . . . 4.6 Treinamento de SVM . . . . . . . . . . . . 4.6.1 Condições de Karush-Kuhn-Tucker 4.6.2 Algoritmo Chunking . . . . . . . . 4.6.3 Algoritmo de Decomposição . . . . 4.6.4 Algoritmo SMO . . . . . . . . . . .. . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . .. 5. Minimum Description Length e Código de Huffman 5.1 O Princípio Minimum Description Length . . . . . . . 5.1.1 MDL de Duas Partes . . . . . . . . . . . . . . . 5.1.2 MDL Refinado . . . . . . . . . . . . . . . . . . 5.1.3 MDL para Classificação de Dados . . . . . . . .. viii. . . . . . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . .. . . . .. . . . . . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . .. . . . .. . . . . . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . .. . . . .. . . . . . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . .. . . . .. . . . . . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . .. . . . .. . . . . . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . .. . . . .. . . . . . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . .. . . . .. . . . . . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . .. . . . .. . . . . . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . .. . . . .. . . . . . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . .. . . . .. . . . . . . . . . . . . . . . . . . . . .. 16 16 17 18 18 18 19 19 19 20 20 20 21 21 22 22 23 24 24 25 26 27. . . . . . . . . . . . . . . . .. 29 29 29 32 32 35 35 38 38 39 39 39 41 41 42 42 42. . . . .. 45 45 45 46 46.
(10) 5.2 5.3. Codificação Adaptativa Algoritmo CAH+MDL 5.3.1 Treinamento . . 5.3.2 Classificação . .. de Huffman . . . . . . . . . . . . . . . . . . . . .. 6. Problema e Metodologia 6.1 Problema a ser resolvido . . . . 6.2 Metodologia a ser utilizada . . . 6.2.1 Domínio . . . . . . . . . 6.2.2 Como os resultados serão. . . . .. . . . .. . . . .. . . . .. . . . . . . . . . . . . . . . . . . avaliados. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. 7. Experimentos Realizados 7.1 Comparativo SVM Linear X Não Linear . . . . . . . . . 7.1.1 Descrição do Experimento . . . . . . . . . . . . . 7.1.2 Resultados Obtidos . . . . . . . . . . . . . . . . . 7.1.3 Análise dos Resultados . . . . . . . . . . . . . . . 7.2 Aumento do Peso para Meta-Dados . . . . . . . . . . . . 7.2.1 Descrição e Resultados do Experimento . . . . . . 7.2.2 Análise dos Resultados Obtidos . . . . . . . . . . 7.3 Algoritmo CAH+MDL sob Hipótese de Mundo Fechado . 7.3.1 Descrição do Experimento . . . . . . . . . . . . . 7.3.2 Resultados Obtidos . . . . . . . . . . . . . . . . . 7.4 Algoritmo CAH+MDL sob Hipótese de Mundo Aberto . 7.4.1 Descrição do Experimento . . . . . . . . . . . . . 7.4.2 Resultados Obtidos . . . . . . . . . . . . . . . . .. . . . .. . . . .. . . . . . . . . . . . . .. . . . .. . . . .. . . . . . . . . . . . . .. . . . .. . . . .. . . . . . . . . . . . . .. . . . .. . . . .. . . . . . . . . . . . . .. . . . .. . . . .. . . . . . . . . . . . . .. . . . .. . . . .. . . . . . . . . . . . . .. . . . .. . . . .. . . . . . . . . . . . . .. . . . .. . . . .. . . . . . . . . . . . . .. . . . .. . . . .. . . . . . . . . . . . . .. . . . .. 46 47 48 51. . . . .. 56 56 56 58 59. . . . . . . . . . . . . .. 61 61 61 63 63 64 65 67 69 69 71 72 72 73. 8. Conclusão e Trabalhos Futuros 76 8.1 Conclusão . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76 8.2 Trabalhos Futuros . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 77 Apêndice A. Documentação do Classificador A.1 Interface com o Usuário . . . . . . . . . . . . . . . . . A.1.1 Sequência de Comandos Usados Nesta Pesquisa A.2 Sintaxe dos arquivos . . . . . . . . . . . . . . . . . . . A.2.1 Arquivos de Páginas Web . . . . . . . . . . . . A.2.2 Arquivos VSM . . . . . . . . . . . . . . . . . . A.3 Implementação . . . . . . . . . . . . . . . . . . . . . . A.3.1 Interfaces . . . . . . . . . . . . . . . . . . . . . A.3.2 Classes . . . . . . . . . . . . . . . . . . . . . . . Referˆ encias. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. 79 79 82 83 84 84 85 86 91 104. ix.
(11) Lista de Figuras 2.1 4.1 4.2 4.3 4.4 4.5 5.1 5.2 A.1. Grafo de decisão para encontrar a melhor entre 4 classes . . . . . . . . . . Separação linear pelo hiperplano ótimo . . . . . . . . . . . . . . . . . . . . Separação linear pelo hiperplano ótimo, com erro . . . . . . . . . . . . . . Transformação dos dados de uma dimensão baixa em uma dimensão maior Exemplo do uso do kernel RBF para a separação não linear de dados . . . Restrições dos multiplicadores de Lagrange em duas dimensões . . . . . . . Exemplo de árvore de Huffman para o alfabeto Σ = [A..G] . . . . . . . . . Funções de densidade de probabilidade para as categorias 7 e 5/7 . . . . . Diagrama de Classes do Classificador CAH+MDL e SVM . . . . . . . . . .. x. 8 31 33 35 38 43 47 53 86.
(12) Lista de Tabelas 2.1 2.2 2.3 2.4 2.5 2.6 2.7 2.8 2.9 7.1 7.2 7.3 7.4 7.5 7.6 7.7 7.8 7.9 7.10 7.11 7.12 7.13 7.14. Exemplo de um conjunto de documentos multi-label com 4 classes . . . . . Uma possível transformação da Tabela 2.1 de multi-label para multiclasse . Transformação da Tabela 2.1 de multi-label para multiclasse ignorando os documentos multi-label . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Transformação da Tabela 2.1 de multi-label para multiclasse, criando uma nova classe para cada intersecção de classes existente na tabela original . . Separação do conjunto original da Tabela 2.1 em 4 subconjuntos para o treinamento de classificadores independentes . . . . . . . . . . . . . . . . . Matriz de Confusão de uma classificação binária . . . . . . . . . . . . . . . Resultados possíveis da classificação de um documento pertencente às classes 1 e 2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Resultados de Precisão para a Tabela 2.7 . . . . . . . . . . . . . . . . . . . Resultados de Recall para a Tabela 2.7 . . . . . . . . . . . . . . . . . . . . Documentos da base Webkb nas quatro categorias estudadas . . . . . . . . Percentual de documentos classificados corretamente sem normalização dos dados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Percentual de documentos classificados corretamente com normalização dos dados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Base de páginas Web usada nos experimentos das Seções 7.2 e 7.3 . . . . . Precisão da classificação com o número máximo de repetições igual a 1 e 3 Precisão da classificação com o número máximo de repetições igual a 5 e 10 Precisão da classificação com máximo de 5 repetições e variação de pesos . Precisão da classificação com máximo de 10 repetições e variação de pesos Precisão da classificação com máximo de 15 repetições e variação de pesos Precisão da classificação com máximo de 18 repetições e variação de pesos Resultados da classificação pelos classificadores SVM e CAH+MDL . . . . Base de páginas Web incluindo documentos marcados como “indefinidos” . Resultados da classificação da base com intervalo de confiança de 77% . . . Resultados da classificação da base com intervalo de confiança de 75% . . .. xi. 9 9 10 11 12 12 13 13 14 62 63 63 65 66 66 67 68 68 69 71 73 74 74.
(13) Glossário CAH: Codificação Adaptativa de Huffman (ver Seção 5.2). DDAG: Decision Directed Acyclic Graph. Em português Grafo de Decisão Acíclico Orientado (ver Seção 2.2.3). DF: Document Frequency, i.e., a freqüência que um termo aparece nos documentos de uma base de dados (ver definição 3.4). HTML: Hypertext Markup Language. É a linguagem mais usada para a criação de páginas Web. IR: Information Retrieval, i.e., recuperação de informação. KKT: Karush-Kuhn-Tucker. São condições que possuem um papel central na teoria e prática de otimizações limitadas (ver Seção 4.6.1). MDL: Minimum Description Length (ver Seção 5.1). RBF: Radial Basis Function. É um tipo de kernel que pode ser utilizado com SVMs não lineares (ver Seção 4.3). SMO: Sequential Minimal Optimization. É um dos algoritmos mais eficientes para treinamento de SVMs. (ver Seção 4.6.4). SVM: Support Vector Machine. TF: Term Frequency (ver Seção 3.1.2). TFIDF: Term Frequency-Inverse Document Frequency (ver Seção 3.1.3). URL: Uniform Resource Locator, i.e., Localizador de Recursos Universal. Ele representa o endereço de um recurso disponível em uma rede. No caso da Internet, ele designa um servidor e um caminho dentro deste servidor.. xii.
(14) 1. Introdução Com o crescimento explosivo que a Internet apresenta desde seu lançamento como rede comercial e em especial nos últimos anos, estão se tornando cada vez mais necessários mecanismos que facilitem o acesso às informações desejadas, bem como aqueles que impeçam o acesso de certos usuários a sites com conteúdos considerados impróprios. Como exemplo desta última situação, está o caso de um pai que não deseja que seu filho pré-adolescente tenha acesso a sites de conteúdo pornográfico ou que estimulem a violência ou o vício. Para desempenhar ambas as tarefas, e em especial a segunda, métodos de classificação automática de páginas Web vem sendo estudados há vários anos [DC00, KR01, GTL+ 02, CWZH06, CM07, DS07]. A razão básica é que o número de páginas Web disponíveis na rede mundial não pára de crescer e atinge números assombrosos, inviabilizando completamente qualquer tipo de classificação manual. De acordo com os dados disponíveis em Setembro de 2008, o número de servidores Web na Internet ultrapassou a marca de 180 milhões [Web08]. O número de URLs diferentes indexadas pela base de dados do Google, passou de 26 milhões em 1998, para 1 bilhão em 2000 e atingiu em Julho de 2008 a marca de 1 trilhão [AH08]. Apesar de não haver nenhum estudo atualizado que apresente o número de páginas Web escritas no idioma Português, ele é o sexto de uso mais freqüente na Internet, representando 3,6% dos usuários [Wor08]. Se utilizarmos esta proporção para fazer uma estimativa, chegaríamos ao número aproximado de 36 milhões de páginas. Apesar disso, muito poucos estudos na área de classificação de textos ou de páginas Web foi feito levando-se em conta as particularidades desta língua.. 1.1. Definição do Problema. Esta pesquisa aborda o problema da classificação automática de páginas Web, utilizando técnicas de aprendizagem de máquina. Será comparada a acurácia de um novo algoritmo, baseado no princípio da Minimum Description Length (MDL), com o algoritmo de Support Vector Machines . SVM é freqüentemente apontado como o algoritmo que produz os melhores resultados na classificação de padrões e, em especial, na classificação de textos [CV95, DPHS98, YL99, Joa02, CCO03, ZL03], na classificação de sites Web em Português e Inglês. Este problema de categorização ou simplesmente classificação, como mais freqüentemente é denominado, pode ser visto como o processo de atribuição de forma dinâmica de uma ou mais categorias para páginas da Web. Ele é normalmente classificado como aprendizado supervisionado [Mit97], no qual um conjunto de dados pré-categorizados é. 1.
(15) utilizado para treinar um classificador, que, a partir destes dados, consegue inferir a classificação de dados futuros. A classificação de páginas Web pode ser abordada de várias formas diferentes: através de seu conteúdo textual, imagens, hyperlinks ou combinações destes elementos, dentre outras possibilidades. Aqui o problema será abordado como uma particularização da classificação de textos, onde serão utilizados não apenas o conteúdo textual das páginas a serem classificadas, mas também informações não disponíveis nos problemas de classificação de textos em geral, como metadados e informações semi-estruturadas, de modo a melhorar a precisão do classificador.. 1.2. Justificativa do Tema. Métodos de classificação automáticos, adequados para a categorização de páginas Web são cada vez mais necessários em virtude do explosivo crescimento da Internet, como mencionado na Seção 1.1. O algoritmo SVM é considerado atualmente como o estado da arte na classificação de dados e regressão. Entretanto, este algoritmo ainda demanda grande poder computacional para realizar seu treinamento e não o realiza de forma incremental. Isso pode ser um problema no caso de classificação multi-label (ver Seção 2.1) com um grande número de categorias, já que se necessita treinar um classificador para cada uma das categorias existentes e isso pode demandar grande quantidade de tempo. O algoritmo baseado no princípio da Minimum Description Length com a codificação adaptativa de Huffman (CAH+MDL) possui a vantagem de exigir poucos recursos computacionais, tanto para o treinamento quanto para a classificação de dados, e permite a realização de treinamento incremental. Este algoritmo, baseado na abordagem proposta por [BFC+ 06], foi utilizado com sucesso para a identificação de SPAM em [BL07], porém ele ainda não foi estudado para a classificação de dados multi-label.. 1.3. Contribuição Científica Esperada. As principais contribuições científicas deste trabalho são: • Proposição e avaliação de um classificador multi-label, baseado no algoritmo CAH+MDL, compatível com a hipótese de mundo aberto, i.e., onde não é necessária a atribuição obrigatória de ao menos uma categoria para cada documento. • Proposição de uma extensão do algoritmo de classificação CAH+MDL para a classificação multi-label e sua avaliação na classificação de uma base de dados de sites Web, tomando como base o desempenho de um classificador baseado em Support Vector Machines linear. • Criação de uma base de sites Web multi-label, em Português e Inglês, composta de sites manualmente classificados em 7 categorias, que posteriormente poderá ser utilizada na realização de experimentos de classificação em geral.. 2.
(16) • Identificação das combinações de ponderações de termos extraídos de partes específicas de páginas Web que produzem os melhores resultados na classificação de páginas Web, tanto no algoritmo CAH+MDL quanto em uma SVM linear. • Como contribuição secundária, é feita uma apresentação unificada das técnicas utilizadas para classificação de dados multi-label, em especial para o caso de textos e páginas Web.. 1.4. Organização deste documento. Nos primeiros capítulos, é feita inicialmente uma análise do estado da arte da classificação de sites Web de forma incremental. No Capítulo 2 é analisado o problema da classificação de padrões de forma geral, mostrando os diferentes tipos que ele pode assumir (binário, multiclasse e multi-label), as técnicas utilizadas para se decompor um problema multiclasse ou multi-label em subproblemas e as medidas de análise de acurácia de classificadores. O Capítulo 3 descreve o problema da classificação de textos e de páginas Web, mostrando as suas principais especificidades e as técnicas que podem ser utilizadas para lidar melhor com estes problemas. O Capítulo 4 explica em detalhes o funcionamento do algoritmo SVM, mostrando em detalhes sua evolução desde sua concepção original até a formulação atual. Também são discutidas as SVM multi-classe e os algoritmos concebidos para realizar seu treinamento. O Capítulo 5 introduz o princípio do Minimum Description Length, a Codificação Adaptativa de Huffman e o funcionamento do algoritmo de classificação CAH+MDL. Após a análise do estado da arte, apresentada nos Capítulos de 2 a 5, o Capítulo 6 descreve em detalhes o problema que será abordado neste trabalho, a metodologia utilizada, o domínio e como os resultados serão avaliados. O Capítulo 7 descreve os resultados obtidos e a análise dos dados, enquanto que o Capítulo 8 apresenta a conclusão e descreve possíveis trabalhos futuros que podem ser desenvolvidos a partir desta pesquisa. Por fim, o Apêndice A documenta a ferramenta, desenvolvida como parte desta pesquisa, que implementou os classificadores CAH+MDL e SVM.. 3.
(17) 2. Classificação de Dados Neste capítulo será abordado o estado da arte sobre a resolução do problema de classificação de dados em geral. A Seção 2.1 mostra os subproblemas de classificação conhecidos enquanto a Seção 2.2 descreve técnicas que permitem que problemas mais complexos, i.e., multiclasse e multi-label, sejam resolvidos por classificadores binários através de técnicas de decomposição. A Seção 2.3 descreve abordagens para tratar o problema de classificação multi-label, alvo desta pesquisa. Por último, a Seção 2.4 descreve como os resultados dos algoritmos de classificação podem ser avaliados e comparados.. 2.1. Tipos de classificação. Os problemas de aprendizagem de máquina e classificação de dados em geral podem ser divididos em três abordagens distintas [ZG09]: 1. Supervisionada: Neste caso, na fase de treinamento, o algoritmo de aprendizagem recebe como entrada um conjunto de dados pré-classificados (geralmente por algum especialista humano), onde cada exemplo está associado a um ou mais rótulos. Finalizado o treinamento, o algoritmo consegue generalizar a partir dos exemplos recebidos e pode, com algum grau de confiança, associar rótulos a novos dados, até então desconhecidos. 2. Não-Supervisionada: Neste tipo de treinamento, o algoritmo recebe um conjunto de dados sem nenhum rótulo e seu objetivo é determinar como estes dados estão organizados. Tipicamente esta abordagem é utilizada para a realização de agrupamento (clustering) de dados. 3. Semi-Supervisionada: Esta abordagem é um meio termo entre a supervisionada e a não supervisionada. A idéia é que o algoritmo receba como treinamento um pequeno conjunto de dados rotulados e um conjunto grande sem rótulos. Vários algoritmos já foram propostos para que com o auxílio dos dados não rotulados se produza um aumento da acurácia do classificador em comparação ao caso onde apenas o pequeno conjunto já classificado fosse usado. Informações sobre este tópico podem ser encontradas em [BM98, LDG00, LLYL02, YHcC04]. Nesta pesquisa será abordado apenas o caso da aprendizagem supervisionada, que pode ser enunciada, de maneira genérica, como se segue: Seja um conjunto de p exemplos, extraídos de forma independente e identicamente distribuídos (i.i.d), de acordo com uma distribuição de probabilidade desconhecida mas 4.
(18) fixa, a serem utilizados para treinar o algoritmo de aprendizagem. Estes exemplos são informados ao algoritmo associados, cada um, a um conjunto de rótulos, atribuídos por um especialista humano: (x1 , y1 ), (x2 , y2 ), · · · , (xp , yp ). (2.1). Em sua forma mais freqüente, cada exemplo xi consiste de um vetor que descreve um determinado documento. O formato dos rótulos yi varia de acordo com o tipo de classificação a ser efetuada, conforme descrito nas seções a seguir, porém ele sempre indica a(s) classe(s) que um documento pertence. Definição 2.1. Uma classe consiste em uma abstração para um grupo de documentos que contém determinadas características em comum. Cada classe é representada, para fins de classificação, por um valor discreto distinto.. 2.1.1. Binária. O problema de classificação binária é o mais simples de todos, porém ainda assim é considerado o mais importante. Com algumas pequenas suposições, qualquer um dos problemas mais complexos pode ser reduzido a ele (veja a Seção 2.2). No caso binário, existem exatamente duas classes. Assim sendo, os rótulos são definidos da seguinte maneira: yi ∈ {−1, 1} (outros valores como yi ∈ {0, 1} poderiam ser usados, mas nesta pesquisa se supõe sempre a primeira forma). A interpretação do significado, entretanto, de cada uma das duas classes pode variar bastante. Um exemplo bastante usual é o caso da filtragem de SPAM, onde o algoritmo teria que decidir se uma determinada mensagem é (y = 1) ou não SPAM (y = −1). Para filtragem de páginas Web, poderíamos interpretar uma das categorias como permitida e outra como não permitida.. 2.1.2. Multiclasse. Muitos dos problemas de classificação envolvem mais de uma classe. Podemos facilmente pensar no caso de páginas Web onde poderíamos ter, por exemplo, as categorias de “Material Adulto”, “Páginas Infantis” e “Esportes”. Uma classificação de documentos textuais também poderia estar agrupada por assunto, de forma semelhante à classificada em uma biblioteca, onde cada assunto estaria atribuído a exatamente uma categoria diferente. No caso geral, vamos considerar que existam p categorias diferentes. Desta forma, sem perda de generalidade, vamos assumir que yi ∈ {1, · · · , p}. As categorias são assumidas como independentes e isso significa que a ordem na qual elas se apresentam é arbitrária. Existem algumas versões de algoritmos de classificação, em especial de Support Vector Machines (leia a Seção 4.5), que permitem que se resolva este problema diretamente, entretanto, em geral elas são computacionalmente ineficientes [Joa02] e ainda são objetos de estudos mais aprofundados [Gue07]. O mais usual para se resolver problemas de classificação multiclasse (e também multilabel) é decompor o problema em vários subproblemas de classificação binária. Isso está descrito na Seção 2.2.. 5.
(19) 2.1.3. Multi-label. Vários dos problemas de classificação, especialmente textuais e de imagens, são problemas multi-label, ou seja, que podem pertencer a mais de uma categoria simultaneamente. Por exemplo, um artigo de jornal falando sobre o jogo Brasil X Alemanha na final da copa do mundo poderia estar nas categorias “Esportes”, “Brasil” e “Alemanha”, asim como uma reportagem sobre um novo pacote econômico lançado por um determinado governo poderia pertencer as categorias de “Política” e “Economia”. Formalmente, a definição de multi-label significa que, ao invés de estar restrito a uma única categoria, cada documento pode pertencer a várias, a uma ou a nenhuma. Sendo assim, temos que para um conjunto de p categorias, os rótulos pertenceriam ao conjunto das partes deste conjunto de rótulos, i.e., yi ∈ 2{1,··· ,p} . Apesar de serem muito freqüentes, problemas deste tipo foram menos estudados que os dois anteriores e são considerados como mais complexos. Desta forma, embora existam alguns poucos algoritmos que possam tratar o caso multi-label diretamente, como os propostos por [dCGT03] (decision-trees), [Zha06] (redes-neurais) e [ZZ07] (K-NN), eles ainda são objetos de estudos recentes e não foram utilizados em problemas práticos. Desta forma, o método mais comum de resolução de problemas de classificação multilabel é o de separação do classificador geral em vários sub-classificadores, cada um capaz de identificar uma determinada classe. Isso está descrito na Seção 2.2.. 2.2. Métodos de Decomposição. Esta seção descreve os métodos que podem ser utilizados para quebrar um problema de classificação multiclasse ou multi-label em vários problemas menores, tratados por classificadores binários. Isso é útil quando o algoritmo de classificação a ser utilizado não suporta diretamente o problema de classificação da forma como é especificado ou quando, para que ele suporte, são necessárias modificações que o tornam ineficiente sob algum aspecto.. 2.2.1. Um contra todos. Este é o mais simples e antigo método de decomposição de problemas. Ele consiste na criação de k classificadores binários, cada um capaz de identificar uma classe em relação às demais. Desta forma, para se classificar um determinado documento, ele é apresentado aos k classificadores e o(s) rótulo(s) atribuído(s) ao documento vão depender do tipo de problema de classificação: • Multiclasse: Neste caso, deve-se atribuir um único rótulo ao documento. Normalmente usa-se a abordagem de atribuir ao documento a classe cujo respectivo classificador produziu a maior nota. • Multi-label: Para este tipo de problema, em geral usa-se a abordagem de atribuir ao documento todas as classes que foram reconhecidas pelos k classificadores. Caso nenhuma tenha sido identificada, o documento será marcado como “desconhecido”. Uma variação deste método é atribuir no mínimo uma classe a todo documento,. 6.
(20) mesmo que nenhuma tenha sido identificada. Neste caso, a classe com a maior nota será utilizada. Apesar deste método de decomposição ter sido criticado por alguns autores por apresentar resultados inferiores aos de outros métodos [Für02, wHjL02], ele foi analisado posteriormente por Rifkin e Klautau [RK04], que concluíram que ele apresenta resultados estatísticos tão bons quanto os demais métodos de decomposição, desde que usado com SVMs bem parametrizadas. Uma importante ressalva em relação a estes estudos, entretanto, é que todos foram realizados apenas para a classificação multiclasse, não tendo, nenhum deles, analisado as particularidades dos problemas multi-label. A principal vantagem desta abordagem em relação à “Um contra um” e “Grafos de Decisão Acíclicos Orientados” é que o número de classificadores a serem treinados é linear em relação ao número de classes, enquanto nos outros casos é quadrático. Além disso, a decomposição “DDAG” não pode ser usada no caso multi-label e a “Um contra um”, apesar de poder ser utilizada, precisa de uma definição melhor de como as classes serão atribuídas aos documentos.. 2.2.2. Um contra um. Este método de decomposição, originalmente desenvolvido por Knerr et al. [KPD90], consiste em utilizar um classificador para cada dupla de categorias, i.e., o classificador K(i, j), 1 ≤ i < j ≤ k saberia distinguir a i-ésima categoria da j-ésima. Desta forma, cada classificador K(i, j) seria treinado apenas com dados das classes i e j, produzindo, classificadores distintos. portanto, k(k−1) 2 Para se classificar um determinado documento, ele é apresentado aos k(k−1) classifi2 cadores e o(s) rótulo(s) atribuído(s) ao documento vão depender do tipo de problema de classificação: • Multiclasse: Neste caso, deve-se atribuir um único rótulo ao documento. Normalmente usa-se a estratégia “Max Wins”, onde se atribui ao documento a classe que obteve a maior soma dos votos dos classificadores. • Multi-label: Não existem estudos conhecidos tratando especificamente a distribuição de rótulos para a decomposição “Um contra um” em um problema de classificação multi-label. Uma das possibilidades é definir um número mínimo de votos para que um dado rótulo seja atribuído a um documento. Outra é atribuir a um documento todos os rótulos que estiverem a uma distância mínima do mais votado. De qualquer forma, este tópico ainda é um estudo em aberto. O principal problema deste método de decomposição é que ele cresce de forma quadrática em relação ao número de categorias. Desta forma, se este número for alto, sua utilização se torna inviável. Além disso, conforme apontado por Platt et al. [PCSt00], se os classificadores individuais não forem “cuidadosamente” regularizados (como são no caso das SVMs), o sistema de classificadores tende a produzir overfitting.. 7.
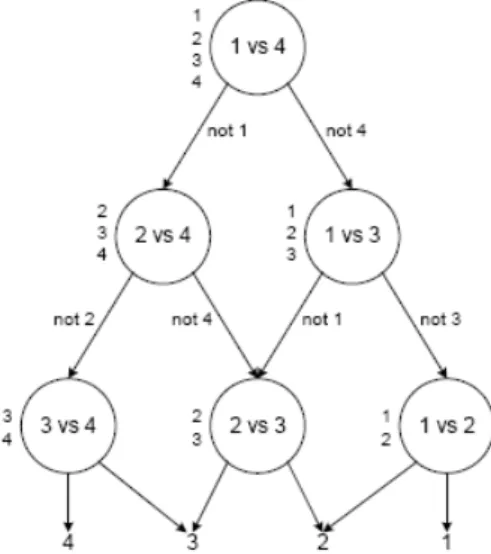
(21) 2.2.3. Grafos de Decisão Acíclicos Orientados. Esta abordagem foi proposta por Platt et al. [PCSt00] e consiste na disposição de classificadores em um grafo binário, direcionado, acíclico e com uma raiz, i.e., um nó único para o qual não existem arcos apontando. Para a criação deste grafo, inicialmente se decompõe classificadores distintos, onde cada classificador é o problema de classificação em k(k−1) 2 capaz de distinguir entre duas classes, da mesma forma que descrito na decomposição “Um contra um” (Seção 2.2.2). Para se avaliar o resultado de classificação de um determinado documento, inicia-se no nó raiz e avalia-se a função de decisão: se ela for negativa prossegue-se pela aresta esquerda do grafo, caso contrário prossegue-se pela direita. No nó seguinte do grafo o procedimento é repedido, até que se chegue a uma de suas folhas. O valor do rótulo associado ao documento será o valor referente à folha atingida. Um grafo, retirado de [PCSt00], para a separação de 4 classes está mostrado na Figura 2.1.. Figura 2.1: Grafo de decisão para encontrar a melhor entre 4 classes A vantagem deste método é que o número de funções de decisão consultadas para a classificação de um determinado documento é igual a k −1, onde k é o número de possíveis classes, já que para cada classe apenas um classificador é consultado. Já na estratégia “Um contra um” o número de classificadores consultados é k(k−1) . A “Um contra todos” 2 consulta k classificadores, porém como cada um deles foi treinado com mais dados, pode ocorrer (dependendo do algoritmo utilizado) que o tempo levado para avaliar todas estas k funções de decisão seja maior que no caso dos grafos de decisão. O grande problema, entretanto, do uso desta estratégia é que com ela não é possível se resolver problemas de classificação multi-label, apenas multiclasse.. 2.3. Treinamento de Classificadores Multi-label. Normalmente, exceto para os poucos algoritmos que o suportem diretamente, um problema de classificação de documentos multi-label é separado em vários sub-problemas, 8.
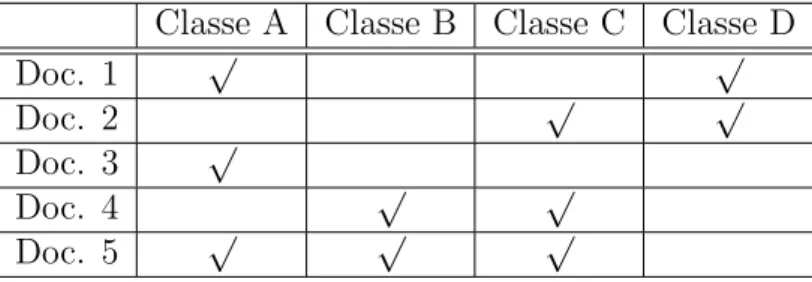
(22) conforme mostrado na Seção 2.2. A questão é decidir como realizar o treinamento destes sub-classificadores, de modo a resolver o problema inicial de classificação e obter os melhores resultados possíveis. Esta seção descreve as várias abordagens diferentes que existem para realizar esta classificação, conforme levantado por [BLSB04, TK07]. Para melhor exemplificar cada um dos métodos, será utilizada a Tabela 2.1, que descreve a distribuição de rótulos em uma hipotética base de dados de documentos multi-label.. Doc. Doc. Doc. Doc. Doc.. 1 2 3 4 5. Classe A √. Classe B. Classe C √. Classe D √ √. √ √. √ √. √ √. Tabela 2.1: Exemplo de um conjunto de documentos multi-label com 4 classes. 2.3.1. Rótulo Único. Esta abordagem, que é uma das primeiras a serem usadas, consiste em transformar os dados a serem treinados de multi-label para multiclasse, i.e., cada documento com um rótulo único. Desta forma, para cada documento que possui mais de um rótulo, apenas um deles é escolhido para lhe ser atribuído. Esta escolha pode ser feita de modo arbitrário ou através de algum critério, possivelmente subjetivo, que caracteriza determinado documento como mais característico de uma classe que de outra. Usando esta abordagem, o conjunto de documentos da Tabela 2.1 seria transformado, entre outras possibilidades, na Tabela 2.2, mostrada a seguir:. Doc. Doc. Doc. Doc. Doc.. 1 2 3 4 5. Classe A √. Classe B. Classe C. Classe D √. √ √ √. Tabela 2.2: Uma possível transformação da Tabela 2.1 de multi-label para multiclasse Esta abordagem possui dois grandes problemas: 1. Muitas vezes é complicado se definir um critério de atribuição da classe única para cada documento, já que, quase sempre, ele é subjetivo. Além disso, se a atribuição for aleatória ou automática (sempre pegar a menor classe, por exemplo), a distribuição de classes nos documentos pode ser seriamente afetada. 2. Se boa parte dos documentos a serem classificados possuir mais de uma classe, esta abordagem vai descartar uma boa quantidade da informação presente no problema original. 9.
(23) Na prática, esta abordagem só pode ser utilizada em conjuntos onde um percentual bastante pequeno de documentos possui mais de um rótulo (ou seja, seriam na verdade problemas de classificação multiclasse com alguns poucos documentos multi-label).. 2.3.2. Ignorar Multi-label. Esta abordagem também visa transformar um problema multi-label em multiclasse, como a de rótulo único (Seção 2.3.1), porém a forma de se realizar esta transformação é mais radical: todos os documentos multi-label são simplesmente descartados ao se realizar o treinamento. Usando esta abordagem, o conjunto de documentos da Tabela 2.1 seria transformado na Tabela 2.3, mostrada a seguir:. Doc. 3. Classe A √. Classe B. Classe C. Classe D. Tabela 2.3: Transformação da Tabela 2.1 de multi-label para multiclasse ignorando os documentos multi-label O grande problema desta abordagem é que ela produz resultados desastrosos se os documentos a serem treinados possuirem em sua maioria mais de um rótulo. Este é o caso do exemplo da Tabela 2.3 onde praticamente todos os documentos seriam eliminados, já que ele é um conjunto onde quase todos os documentos possuem mais de um rótulo. Na prática, ainda mais que à de rótulo único, esta abordagem só pode ser utilizada em conjuntos onde um percentual insignificante de documentos possui mais de um rótulo (ou seja, seriam na verdade problemas de classificação multiclasse com muito poucos documentos multi-label).. 2.3.3. Nova Classe. Este método também visa transformar um problema de classificação multi-label em multiclasse, como os dois apresentados anteriormente, porém seu objetivo é fazer esta transformação sem perda de informação. Desta forma, ao invés de atribuir uma determinada classe para cada documento multi-label ou simplesmente descartá-los (como nos métodos anteriores), a idéia desta abordagem é criar uma nova classe para cada interseção de classes existente no conjunto de documentos original. Estas novas classes seriam então treinadas da mesma forma que as originalmente existentes. Com esta abordagem, o conjunto de documentos da Tabela 2.1 seria transformado na Tabela 2.4: Esta abordagem possui dois grandes problemas: 1. Muito comumente os dados pertencentes às novas classes criadas são demasiadamente esparsos, i.e., muito pouco freqüentes, para que se possa utilizá-los para o treinamento. Neste caso, o efeito prático resultante desta abordagem seria o mesmo de que ignorar os documentos multi-label ou, pelo menos, um subconjunto deles.. 10.
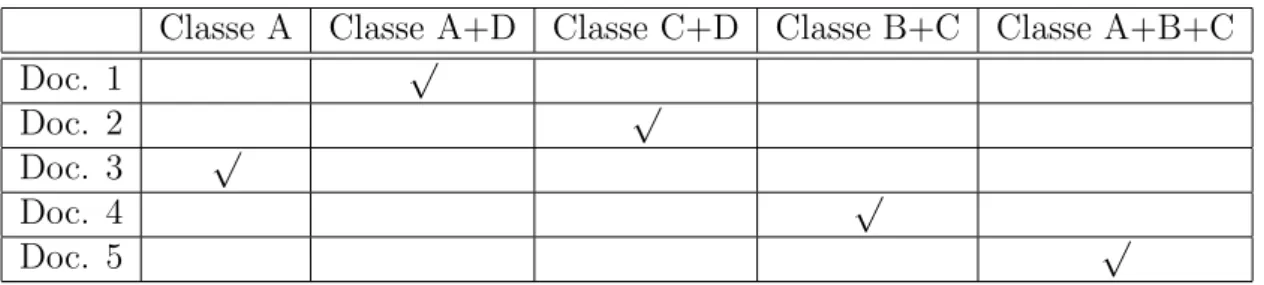
(24) Classe A Doc. Doc. Doc. Doc. Doc.. 1 2 3 4 5. Classe A+D √. Classe C+D. Classe B+C. Classe A+B+C. √ √ √ √. Tabela 2.4: Transformação da Tabela 2.1 de multi-label para multiclasse, criando uma nova classe para cada intersecção de classes existente na tabela original 2. Ainda que os dados não sejam esparsos, pode ocorrer de existirem muitas interseções distintas entre classes. Desta forma, o número total de classes a serem treinadas pode aumentar exponencialmente, inviabilizando o uso desta abordagem. Na prática, esta abordagem pode ser utilizada sempre que o número de interseções entre classes do conjunto de treinamento não seja demasiadamente grande e que exista um número significativo de exemplos em cada uma destas interseções, para que o treinamento possa ser realizado.. 2.3.4. Treinamento Cruzado. Esta abordagem, que visa resolver os problemas das abordagens anteriores e evitar a perda de informação, foi proposta por Boutell et al. [BLSB04] e, segundo seus estudos, apresentou melhores resultados do que as anteriores na classificação de imagens multilabel por Support Vector Machines, apesar da diferença em geral ser pequena (em torno de 2 pontos percentuais) em relação aos demais métodos. O treinamento cruzado consiste em dividir o conjunto de dados em k subconjuntos, onde k é o número de classes distintas, e realizar o treinamento separado de k classificadores binários. Documentos serão usados como exemplos positivos durante o treinamento das classes às quais eles fazem parte e como exemplos negativos para as demais. Com esta abordagem, o conjunto de documentos da Tabela 2.1 seria transformado em 4 subconjuntos, um para realizar o treinamento independente de cada uma das classes originais, conforme mostrado na Tabela 2.5:. Doc. Doc. Doc. Doc. Doc.. 1 2 3 4 5. Classe A √. ¬ Classe A. Classe B Doc. Doc. Doc. Doc. Doc.. √ √ √ √. a) Treinamento para o classificador 1. 1 2 3 4 5. ¬ Classe B √ √ √. √ √. b) Treinamento para o classificador 2. Esta abordagem também pode ser utilizada da mesma forma para a separação de um problema de classificação multiclasse em vários sub-classificadores binários. A única diferença é que na classificação multiclasse é necessário escolher o rótulo reportado por 11.
(25) Classe C Doc. Doc. Doc. Doc. Doc.. 1 2 3 4 5. ¬ Classe C √. Doc. Doc. Doc. Doc. Doc.. √ √ √ √. c) Treinamento para o classificador 3. 1 2 3 4 5. Classe D √ √. ¬ Classe D √ √ √. d) Treinamento para o classificador 4. Tabela 2.5: Separação do conjunto original da Tabela 2.1 em 4 subconjuntos para o treinamento de classificadores independentes um dos classificadores como o que será atribuído para o documento sendo classificado, enquanto no multi-label se necessita um método para escolher o conjunto de rótulos a atribuir a tal documento.. 2.4. Medidas de Desempenho. Para a avaliação do desempenho de classificadores, não se pode simplesmente utilizar o número de erros como uma medida. Isso é causado em virtude de que freqüentemente as bases a serem classificadas são desbalanceadas. Sendo assim, um suposto classificador que respondesse sempre -1 (ou não pertence) para cada documento a ser classificado e tivéssemos uma base onde apenas 10% dos documentos efetivamente pertencessem à dada classe, teríamos um classificador com uma excelente taxa de acertos, 90%, porém que é completamente inútil. Desta forma, para a avaliação da acurácia de classificadores, tradicionalmente utilizamse as medidas de Precisão, Recall e F-Measure, que é uma média harmônica ponderada das duas primeiras. Aqui serão apresentadas as definições tradicionais, que em seguida serão estendidas, de acordo com [GS04], para tratar o caso de classificação multi-label. Para a definição das medidas em sua forma tradicional, binária, será usada a Tabela 2.6, que é normalmente conhecida como “Matriz de Confusão”. Nesta tabela, a diagonal principal representa os acertos, enquanto as demais células representam os erros de classificação. Rótulo = 1 Previsão = 1 VP (Verdadeiros Positivos) Previsão = -1 FN (Falsos Negativos). Rótulo = -1 FP (Falsos Positivos) VN (Verdadeiros Negativos). Tabela 2.6: Matriz de Confusão de uma classificação binária. 2.4.1. Precisão. Precisão é a probabilidade de um dado documento, escolhido aleatoriamente, que esteja classificado como pertencente a uma dada categoria, seja realmente membro desta categoria. 12.
(26) Algebricamente, para o caso binário, ela pode ser definida para uma determinada categoria da seguinte forma: VP (2.2) VP + FP Para o caso multi-label, é importante considerar que não existem apenas acerto e erro absolutos, como no caso binário ou multiclasse, e sim uma graduação de erros. Como ilustração está o caso da classificação de um hipotético documento pertencente às classes 1 e 2, no qual alguns possíveis resultados desta classificação estão mostrados na Tabela 2.7: Precisão =. f (x) = {1, 2} f (x) = {1} f (x) = {2} f (x) = {1, 3} f (x) = ∅ f (x) = {3, 4}. (correto) (parcialmente correto) (parcialmente correto) (parcialmente correto) (incorreto) (incorreto). Tabela 2.7: Resultados possíveis da classificação de um documento pertencente às classes 1e2. Desta forma, estendemos a definição da Precisão para o caso da classificação multilabel de uma determinada categoria da seguinte forma: Precisão =. n | yi ∩ zi | 1X n i=1 | zi |. (2.3). Onde n é o número de documentos classificados, yi ⊆ 2{1,··· ,p} é o conjunto de classes atribuído ao i-ésimo documento e zi ⊆ 2{1,··· ,p} é o conjunto de classes previsto pelo classificador para o i-ésimo documento. Assim sendo, para a Tabela 2.7, teríamos os seguintes valores de Precisão: f (x) = {1, 2} f (x) = {1} f (x) = {2} f (x) = {1, 3} f (x) = ∅ f (x) = {3, 4}. (Precisão (Precisão (Precisão (Precisão (Precisão (Precisão. = = = = = =. 1) 1) 1) 0,5) 0) 0). Tabela 2.8: Resultados de Precisão para a Tabela 2.7. 2.4.2. Recall. Recall é a probabilidade de um documento qualquer, escolhido aleatoriamente, que pertença a uma determinada categoria seja classificado como realmente pertencente a esta categoria. 13.
(27) Em Português, este termo é algumas vezes traduzido como “Abrangência”, “Cobertura” ou “Revocação”. Como não existe uma nomenclatura padrão, para evitar confusão, será utilizado sempre o termo na sua formulação original, em Inglês. Algebricamente, para o caso binário ou multiclasse, Recall pode ser definido para uma determinada categoria da seguinte forma: VP (2.4) VP + FN Para o caso multi-label, novamente é importante considerar que não existem apenas acerto e erro absolutos, como no caso binário, e sim uma graduação de erros, conforme ilustrado na Tabela 2.7. Recall =. Desta forma, estendemos a definição de Recall para o caso da classificação multi-label de uma determinada categoria da seguinte forma: Recall =. n | yi ∩ zi | 1X n i=1 | yi |. (2.5). Onde n é o número de documentos classificados, yi ⊆ 2{1,··· ,p} é o conjunto de classes atribuído ao i-ésimo documento e zi ⊆ 2{1,··· ,p} é o conjunto de classes previsto pelo classificador para o i-ésimo documento. Assim sendo, para a Tabela 2.7, teríamos os seguintes valores de Recall: f (x) = {1, 2} f (x) = {1} f (x) = {2} f (x) = {1, 3} f (x) = ∅ f (x) = {3, 4}. (Recall (Recall (Recall (Recall (Recall (Recall. = = = = = =. 1) 0,5) 0,5) 0,5) 0) 0). Tabela 2.9: Resultados de Recall para a Tabela 2.7. 2.4.3. F-Measure. Apesar das medidas de Precisão e Recall descreverem com exatidão o desempenho de um classificador, freqüentemente se necessita de um único número para melhor poder comparar dois classificadores quaisquer. Assim sendo, Van Rijsbergen [Rij79] criou a FMeasure, que é uma média harmônica ponderada dos valores de Precisão e Recall, definida da seguinte forma: Fβ =. (1 + β 2 ) · P recisão · Recall β 2 · P recisão + Recall. (2.6). Em (2.6), o valor de β corresponde ao maior peso que se deseja atribuir a Precisão ou ao Recall. Para β > 1, Recall tem uma importância maior, enquanto que para 0 < β < 1, a Precisão recebe maior peso. Um caso particular e o mais comum da F-Measure é quando se resolve atribuir o mesmo peso para Precisão e Recall, passando a chamá-la de F1 . Sua definição é a seguinte: 14.
(28) 2 · P recisão · Recall (2.7) P recisão + Recall Outros valores também encontrados com alguma freqüência para F-Measure são a F2 , que atribui o dobro de peso ao Recall em relação à Precisão e a F0,5 , que atribui duas vezes mais peso à Precisão em relação ao Recall. F1 =. 15.
(29) 3. Classificação de textos e páginas Web Neste capítulo será abordado o estado da arte da classificação de textos e de páginas Web, que são subproblemas da classificação geral de dados, discutida no capítulo anterior. Serão mostradas as particularidades da classificação textual e como cada uma delas pode ser abordada. O capítulo começa com a descrição da maneira pela qual os documentos textuais podem ser representados e tratados pelos algoritmos de classificação (Seção 3.1). A seguir, a Seção 3.2 descreve algumas propriedades importantes da classificação de textos, que têm que ser observadas por qualquer algoritmo de classificação. A seguir, a Seção 3.3 mostra algumas técnicas de pré-processamento que podem ser aplicadas a textos em geral, com o objetivo de aumentar a acurácia dos classificadores, enquanto a Seção 3.4 apresenta métodos de seleção de atributos, que normalmente são utilizados para reduzir as dimensões dos documentos e prevenir a ocorrência de overfitting. A Seção 3.5 descreve a ponderação de termos, que pode ser utilizada para aumentar a importância de determinadas palavras ou termos oriundos de partes específicas de um documento (de um resumo, no caso de documentos que o contenham, ou de palavras-chave, no caso de páginas Web, por exemplo). Por último, a seção 3.6 descreve as particularidades e o estado da arte na classificação de páginas Web.. 3.1. Representação de documentos textuais. Antes que qualquer documento possa ser classificado, ele deve ser transformado em alguma representação que possa ser utilizada pelos algoritmos classificadores. Existem várias maneiras de se fazer esta representação e a mais simples e substancialmente mais utilizada delas é conhecida como Vector Space Model (VSM) ou bag-of-words, que será descrita nesta seção. Apesar de outras representações mais sofisticadas que agreguem maior conteúdo semântico do documento original serem possíveis, nenhuma dela apresentou até o momento avanços significativos e consistentes. Além disso, apesar de poderem capturar um maior significado do documento, sua complexidade adicional degrada a qualidade dos modelos estatísticos baseados nelas. Desta forma, a representação bag-of-words apresenta um bom compromisso entre expressividade e complexidade dos modelos [Joa02]. A representação bag-of-words pode ser vista como uma sacola onde elementos repetidos normalmente são permitidos (exceto no caso da representação binária, discutida na Seção 3.1.1). Desta forma, um documento é representado como uma coleção das palavras que ele 16.
(30) contém, ignorando-se a ordem na qual estas palavras aparecem e os sinais de pontuação existentes. É evidente que esta representação se traduz na perda de informação léxica e/ou gramatical, bem como na impossibilidade de se desambiguar palavras homônimas ou usadas em sentido figurado. Ainda assim, assume-se que o número de tais palavras seja pequeno o suficiente para não gerar ruídos que possam impactar de forma significativa o algoritmo de classificação. Para formalizar a representação bag-of-words , são necessárias as seguintes definições: Definição 3.1. Uma palavra ou termo consiste em uma seqüência contígua de caracteres de um determinado alfabeto. Espaços, sinais de pontuação e demais caracteres que não fazem parte do alfabeto são considerados como separadores das palavras. Definição 3.2. Um dicionário consiste em todas as palavras válidas e que poderão ser utilizadas para a classificação de uma determinada base de dados de documentos. O dicionário pode ser pré-definido, porém mais comumente é gerado a partir das palavras presentes nos documentos usados para o treinamento do algoritmo. Sendo assim, se determinada palavra não estiver presente em nenhum documento usado no treinamento ela será ignorada no momento da classificação. Definição 3.3. Uma representação vetorial de um documento consiste em um vetor de dimensões iguais ao número de palavras presentes no dicionário, onde cada possível palavra é representada em uma dimensão diferente. A ausência de uma palavra no documento sendo representado implica em que a dimensão correspondente a ela receba o valor 0, enquanto a presença de uma ou mais instâncias de uma palavra faz com que a dimensão correspondente receba um valor positivo. Definição 3.4. A freqüência de documentos, ou DF, para uma determinada palavra representa a fração de documentos nos quais a palavra aparece. Ela é dada pela fórmula p , onde Np é o número de documentos nos quais a palavra aparece e Nt é o número Df = N Nt total de documentos. Com estes conceitos definidos, serão mostradas agora as diferentes sub-formas de representação que podem ser usadas dentro da representação bag-of-words .. 3.1.1. Binária. Neste tipo de representação, apenas a presença ou ausência de uma determinada palavra é determinante para a classificação de um documento. Desta forma, os valores possíveis para cada dimensão do vetor que representa um documento são 0, caso a palavra correspondente não esteja presente, e 1, caso existam no documento uma ou mais palavras correspondentes à dimensão. Formalmente, o valor binário de um termo ti em um documento dj é o seguinte: Bin(ti ) =. 0,. se ti não ocorre em dj 1, caso contrário. 17. (3.1).
(31) 3.1.2. Freqüência dos termos. Nesta representação, cada dimensão do vetor de representação de um documento contém o número de vezes que a palavra correspondente apareceu em tal documento. Esta é a maneira de representação mais comumente utilizada para a classificação de sites Web, porém a representação TFIDF (Seção 3.1.3) é mais comumente utilizada para a classificação de documentos textuais puros. Formalmente, o valor TF de um termo ti em um documento dj é o seguinte: T F (ti ) = N (ti , dj ). (3.2). Onde N (ti , dj ) representa o número de vezes que ti ocorreu em dj .. 3.1.3. Freqüência dos termos - inversa dos documentos. Esta á a representação mais comum para a classificação de documentos textuais. Ela leva em conta não apenas a freqüência de cada termo em um documento, porém também o número de documentos em que cada um destes termos aparecem. A idéia intuitiva por trás desta representação é a seguinte [Seb99]: • Quanto mais freqüente um termo aparecer em um documento, mais representativo de seu conteúdo ele é. • Em quantos mais documentos um termo aparecer, menos descriminante ele é. A fórmula mais usual para o cálculo de TFIDF de um termo ti para um documento dj é a seguinte: T F IDF (ti , dj ) = N (ti , dj ) · log(. Nt ) Nti. (3.3). Onde N (ti , dj ) representa o número de vezes que ti ocorreu em dj , Nt é o número total de documentos e Nti é o número de documentos nos quais ti ocorreu ao menos uma vez. Outra fórmula, chamada de coleção de freqüência inversa probabilística, que também pode ser usada para o cálculo de TFIDF é a seguinte [Joa02]: T F IDF (ti , dj ) = N (ti , dj ) · log(. Nt − Nti ) Nti. (3.4). Em (3.4), novamente termos que aparecem em muitos documentos recebem pesos menores.. 3.2. Propriedades da Classificação de Textos. Algumas propriedades da classificação de documentos textuais serão mostradas nesta seção. Elas são comuns a todos os documentos de texto, em maior ou menor escala, dependendo do tipo de documento analisado.. 18.
(32) 3.2.1. Alta Dimensionalidade. A representação de documentos textuais sob a forma de vetores, conforme mostrado na Seção 3.1, faz com a dimensão destes vetores atinja facilmente o valor de dezenas de milhares. Caso se esteja trabalhando com documentos longos e escritos em diferentes línguas, o tamanho da dimensão dos vetores pode até mesmo ultrapassar a centena de milhar. É possível se reduzir um pouco esta dimensão através de técnicas de pré-processamento (Seção 3.3) ou seleção de atributos (Seção 3.4), porém ainda assim seu valor será bastante elevado. Desta forma, ao se escolher um algoritmo de classificação para textos, deve-se assegurar que ele consiga tratar vetores com alta dimensionalidade ou então fazer um trabalho agressivo de redução de atributos, de modo a impedir a ocorrência de overfittingou estouro da capacidade de memória.. 3.2.2. Vetores Esparsos. Apesar dos vetores de representação de documentos serem de dimensões muito grandes, a ampla maioria das dimensões possui valor 0, ou seja, correspondem a palavras que não estão presentes no documento. Isso ocorre em virtude do número de palavras distintas em um único documento ser em geral medido na ordem de centenas, ou seja, entre duas e três ordens de grandeza menor que a dimensão dos vetores. Joachims [Joa02] mediu o número médio de palavras únicas por documento de três bases de dados textuais conhecidas e obteve os seguintes dados: • Ohsumed [HBLH94]: Média de 100 palavras distintas por documento. • Reuters [Lew97]: Média de 74 palavras distintas por documento. • Webkb [DLR00]: Média de 130 palavras distintas por documento. Apesar destas bases serem um pouco antigas, nada indica que o número de palavras únicas por documento de bases mais atuais seja substancialmente diferente. Sendo assim, é interessante que o algoritmo de classificação utilizado possa usar esta alta esparcidade em seu favor, de modo a melhorar sua velocidade e diminuir a necessidade de uso de memória.. 3.2.3. Complexidade Lingüística. As línguas naturais são bastantes ricas em termos de sinônimos, figuras de linguagens e ambigüidade. É, portanto, perfeitamente possível se selecionar diferentes artigos, páginas Web, mensagens e outros tipos de documentos textuais que tratem de um mesmo tema e ainda assim possuam poucos termos comuns, exceto por aqueles termos extremamente freqüentes e que são considerados stopwords (ver Seção 3.3.3), que não servem como discriminantes de categorias. Isso também pode ocorrer com documentos que sejam a tradução um do outro: ambos tratam exatamente do mesmo tema porém não têm (praticamente) nenhuma palavra em comum. Uma situação oposta, mas também bastante comum é a chamada de ambigüidade léxica, i.e., uma mesma palavra possuir diferentes significados, dependendo do contexto ou 19.
(33) da forma com que é empregada. Isso pode ocorrer também entre línguas: uma palavra ser escrita de forma igual em dois idiomas quaisquer, porém tendo significados completamente distintos. Assim sendo, é importante que um bom algoritmo de classificação de textos consiga trabalhar com esta complexidade diretamente sem a exigência que algum tipo de seleção de atributos (ver Seção 3.4) seja realizado a priori, já que, em virtude do exposto acima, isso pode diminuir bastante sua acurácia.. 3.2.4. Alta Redundância. As linguagens naturais são extremamente redundantes. É perfeitamente possível que um ser humano compreenda uma frase ou um parágrafo mesmo que determinadas palavras lhes sejam removidas ou que não sejam entendidas (no caso de um idioma estrangeiro ou em uma ligação telefônica com ruído, por exemplo). Desta forma, é evidente que os vetores de representação de documentos possuirão várias dimensões com distribuições idênticas ou muito semelhantes. É fundamental, portanto, que um bom algoritmo de classificação de textos consiga trabalhar com esta redundância sem a necessidade de fortes suposições a respeito da independência entre termos (que é o principal problema do Naïve Bayes e de outros algoritmos probabilísticos).. 3.3. Pré-processamento. Nesta seção serão mostradas técnicas simples que podem ser aplicadas aos documentos textuais antes deles serem repassados ao algoritmo de classificação, com o objetivo de melhorar sua eficiência de processamento ou produzir ganho em sua acurácia.. 3.3.1. Normalização. Um importante aspecto para melhorar a representação VSM é assegurar que documentos contendo palavras semanticamente equivalentes sejam mapeados para vetores similares [STC04]. Na representação de documentos utilizando Freqüência dos termos (Seção 3.1.2) ou Freqüência dos termos - inversa dos documentos (Seção 3.1.3), é natural que documentos grandes apresentem maiores freqüências de palavras e, portanto, vetores com normas maiores. Isso pode induzir a erros de classificação. No caso da classificação textual, como o tamanho de um documento não é relevante para sua classificação em uma ou outra categoria, podemos anular seu efeito normalizando os vetores que representam cada documento. Isso pode ser feito dentro do próprio kernel de uma SVM não linear (ver Seção 4.3) ou, mais comumente, como uma transformação inicial que pode ser aplicada a qualquer algoritmo. A normalização de um vetor é expressa pela seguinte equação: ~xnormal =. ~x ~x =√ k~xk ~x · ~x. 20. (3.5).
Imagem

+7



![Figura 5.1: Exemplo de árvore de Huffman para o alfabeto Σ = [A..G]](https://thumb-eu.123doks.com/thumbv2/123dok_br/19186066.947616/60.892.157.780.641.938/figura-exemplo-de-árvore-huffman-para-alfabeto-σ.webp)
Documentos relacionados
O objetivo deste estudo foi avaliar o comporta- mento clínico de lesões de dermatite digital bovina após tratamento cirúrgico, uso local e parenteral de oxitetraci- clina e passagem
No Cap´ıtulo 3, mostramos alguns m´etodos de resolu¸c˜ao para tipos especiais de equa¸c˜oes diferenciais ordin´arias, como por exemplo o m´etodo de vari´aveis separ´aveis,
O texto refaz um pouco a trajetória da Biblioteca Pública Benedito Leite, sediada no Maranhão e instituída com a finalidade de proporcionar uma nova
No sexto Capítulo – História da Legislação Florestal – Após Constituição de 1988, os recursos florestais e todo o meio ambiente onde ele se insere ganhou proteção na
Segundo a autora, as palavras só tem sentido como parte de um todo; elas não tem sentido se faltam a elas outras semelhantes ou opostas, pois “as palavras formam um campo
As características referenciais para a construção e utilização de um repositório de recursos educacionais digitais reutilizáveis elencadas neste trabalho, serviram de
Neste tipo de situações, os valores da propriedade cuisine da classe Restaurant deixam de ser apenas “valores” sem semântica a apresentar (possivelmente) numa caixa
Por exemplo, Rancho Grande (1940), de Frank MaDonald, para a Republic, com Gene Autry como astro, faz alusão não ape- nas à famosa canção popular mexicana Allá en el Rancho Grande,
