Aglomerac~ao n~ao Hierarquica em
Sistemas Distribudos de
Recuperac~ao de Informac~ao
Jos
e Luis Padr ~
ao Exposto
Mestrado em Informatica
Dissertac~ao submetida a Universidade do Minho para obtenc~ao do
grau de Mestre em Informatica.
Area de Especializac~ao em Sistemas Distribudos, Comunicac~oes por
Computador e Arquitecturas de Computadores
The search for relevant documents in huge collections requires very high computer load and storage overhead.
Although, many research has been made towards the minimization of the document overall space overhead through stoplist techniques and stemming, the storage needed to support so big colections is still very high.
Putting together the decomposition of big colections using clustering algorithms, and their distribution in a high speed network, it would be possible to divide the total document space by each of the network machines, and yet to get concurrent computational processing resources from those same machines.
Resumo
A procura de documentos relevantes em colecc~oes de grandes dimens~oes e um processo que envolve uma carga computacional muito elevada e uma enorme necessidade em termos de capacidade de armazenamento de dados.
Apesar de toda a investigac~ao feita, no sentido de minimizar o espaco fsico ocupado pelos documentos, atraves de tecnicas de ltragem, eliminac~ao de palavras comuns e ra-dicalizac~ao, s~ao ainda exigidas grandes necessidades de armazenamento devido ao grande numero de documentos das colecc~oes.
Se aliarmos as tecnicas de aglomerac~ao a distribuic~ao de cada um dos aglomerados, por maquinas ligadas por uma rede de grande velocidade, podemos repartir o espaco ocu-pado pela totalidade da colecc~ao e tirar ainda partido da utilizac~ao concorrente do poder computacional de varias maquinas, quer no processo de classi cac~ao, quer no processo de selecc~ao de documentos relevantes a pedidos de utilizadores.
Agradecimentos
Ao meu orientador, Professor Vasco Freitas, pelo tema de investigac~ao e pela opor-tunidade que me facultou em trabalhar numa area que tanto me motivou.
Ao meu pai, a minha m~ae e ao meu irm~ao que permitiram a minha chegada ate aqui e sempre me motivaram para continuar em frente.
Aos colegas de mestrado, especialmente ao Ru no pelas dicas de revis~ao, ao Albano e a Maria Jo~ao, agora colegas de pro ss~ao, pela ajuda e o bom ambiente de trabalho proporcionado.
A Ana e a Elsa que souberam dar o apoio certo na altura certa.
A todos os meus amigos que conseguiram viver sem mim nos tempos crticos. Ao Fernando Mina pela revis~ao do texto.
A Escola Superior de Tecnologia e Gest~ao do Instituto Politecnico de Braganca, pelas facilidades concedidas durante o perodo de elaborac~ao desta tese.
Indice
1 Introduc~ao
1
1.1 Informac~ao . . . 1
1.2 A difus~ao da informac~ao . . . 2
1.3 A Biblioteca Universal . . . 2
1.4 Descoberta de recursos na WWW . . . 4
1.4.1 Servicos integrados . . . 4
1.4.2 Servicos n~ao integrados . . . 6
1.5 Objectivos da tese . . . 6
1.6 Resumo dos captulos seguintes . . . 7
2 Recuperac~ao de Informac~ao
9
2.1 De nic~oes . . . 102.2 Estatstica na RI . . . 11
2.3 Estrutura de um sistema de RI . . . 12
2.4 Estruturas de dados . . . 14
2.4.1 Ficheiro Invertido . . . 14
2.5 Indexac~ao Automatica . . . 15
2.5.1 Analise Lexica . . . 15
2.5.2 Dicionario negativo . . . 16
2.5.3 Radicalizac~ao . . . 16
2.5.4 Atribuic~ao de Pesos . . . 17
3 Modelos conceptuais dos sistemas de Recuperac~ao de Informac~ao 18
3.1 Modelo de padr~oes de texto . . . 193.2 Modelo Booleano . . . 19
INDICE ii
3.3 Modelo Probabilstico . . . 20
3.4 Modelo do Espaco Vectorial . . . 20
3.5 Modelo de Aglomerac~ao . . . 23
3.5.1 Analise de aglomerados . . . 23
3.5.2 Aglomerac~ao de documentos . . . 23
3.5.3 Metodos de aglomerac~ao . . . 24
3.6 Avaliac~ao de sistemas de RI . . . 26
3.6.1 E ci^encia . . . 26
3.6.2 E cacia . . . 26
3.6.3 Colecc~oes de teste . . . 27
3.6.4 Precis~ao e totalidade . . . 28
3.6.5 Metodos para o calculo da curva media . . . 29
4 Sistema de Indexac~ao e Aglomerac~ao Distribuda (
SInAD)
31
4.1 Sistemas disponveis . . . 314.2 Raz~oes para a criac~ao de uma plataforma propria . . . 32
4.3 Considerac~oes para a implementac~ao de um sistema . . . 33
4.3.1 Tecnicas utilizadas . . . 34
4.3.2 Modelo conceptual . . . 35
4.3.3 Conjugac~ao do modelo de aglomerac~ao . . . 36
4.4 Implementac~ao do SInAD . . . 38
4.4.1 Organizac~ao das estruturas de dados . . . 41
4.4.2 Comunicac~ao entre as entidades . . . 44
4.4.3 Aquisic~ao de novos documentos . . . 46
4.4.4 Consulta ao sistema . . . 48
5 Experimentac~ao com a colecc~ao
Craneld49
5.1 A colecc~ao Craneld . . . 505.2 Experimentac~ao base . . . 51
5.2.1 E ci^encia . . . 52
5.2.2 E cacia . . . 55
5.3 Experimentac~ao com a aglomerac~ao . . . 56
INDICE iii
5.5 Experimentac~ao da aglomerac~ao distribuda . . . 63
6 Conclus~oes e trabalho futuro 67 6.1 Conclus~oes . . . 67
6.1.1 SInAD . . . 67
6.1.2 Modelo de Aglomerac~ao . . . 68
6.1.3 Distribuic~ao . . . 69
1.1 Evoluc~ao do numero de maquinas e domnios na internet. . . 3
2.1 Modelo de caixa preta para um sistema de RI . . . 12
2.2 Esquema funcional de um Sistema de RI . . . 13
2.3 Estrutura de um cheiro invertido . . . 15
3.1 Categorizac~ao das tecnicas de RI . . . 19
3.2 Modelo do espaco vectorial . . . 21
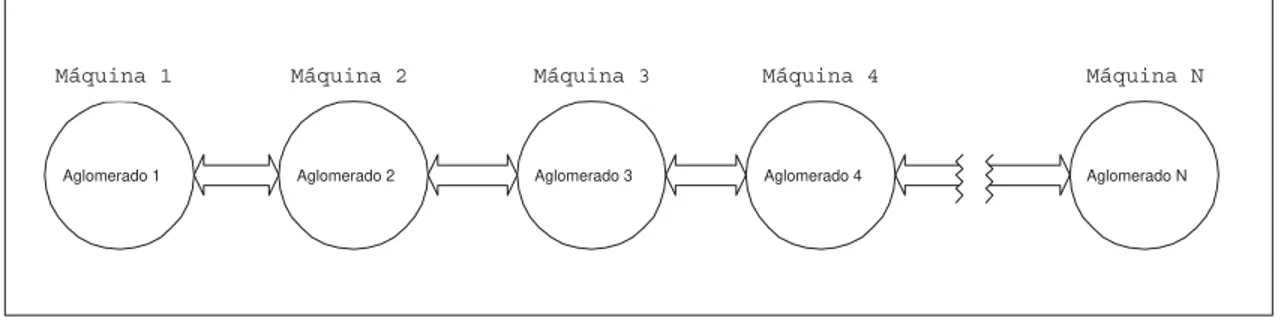
4.1 Distribuic~ao de aglomerados numa rede de computadores . . . 36
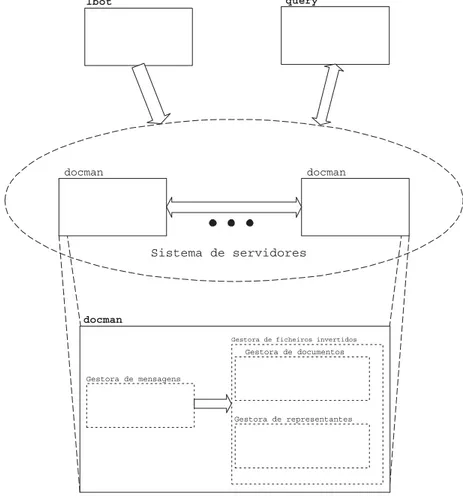
4.2 Diagrama das entidades do SInAD . . . 40
4.3 Relacionamento entre os objectos do SInAD . . . 42
4.4 Estrutura das mensagens processados pelo docman . . . 45
4.5 Mensagem de resposta a uma interrogac~ao . . . 46
5.1 Exemplo de documento da colecc~ao Craneld. . . 51
5.2 Exemplo de uma interrogac~ao da colecc~ao Craneld. . . 51
5.3 Tempos de inserc~ao de documentos da colecc~ao Craneld. . . 54
5.4 Tempos de resposta as interrogac~oes. . . 55
5.5 Curva P-T para a colecc~ao Craneld sem aglomerac~ao. . . 56
5.6 Comparac~ao dos desempenhos para variac~oes no numero de aglome-rados. . . 57
5.7 Comparac~ao dos desempenhos para variac~oes no limite de bloqueio com 5 aglomerados na colecc~ao Craneld. . . 60
5.8 Distribuic~ao dos documentos pelos aglomerados para a colecc~ao Cran-eldcom 5 aglomerados. . . 61
LISTA DE FIGURAS v
5.9 Comparac~ao dos desempenhos para variac~oes no limite de bloqueio com 4 aglomerados na colecc~ao Craneld. . . 62
5.10 Distribuic~ao dos documentos pelos aglomerados para a colecc~ao Cran-eldcom 4 aglomerados. . . 63
5.11 Variac~ao de tempos de resposta em modo local e distribudo com 5 naipes de interrogac~oes para a colecc~aoCraneld com 4 aglomerados
e limite de bloqueio igual a 0,5. . . 65 5.12 Percentagens de distribuic~ao do espaco ocupado nas maquinas para a
colecc~ao Craneld com 4 aglomerados e limite de bloqueio igual a 0,5. 66
5.13 Percentagens de distribuic~ao do espaco ocupado nas maquinas para a colecc~ao Craneld com 4 aglomerados e limite de bloqueio igual a
2.1 Comparac~ao entre a Recuperac~ao de Informac~ao e a Recuperac~ao de Dados . . . 10 3.1 Declarac~ao de variaveis para a de nic~ao de precis~ao e totalidade . . . 28 5.1 Percentagens de reduc~ao do numero de termos em relac~ao ao
docu-mento original. . . 50 5.2 Tempo medio de inserc~ao de documentos para a colecc~ao Craneld
sem aglomerac~ao. . . 53 5.3 Tempo medio de resposta as interrogac~oes para a colecc~ao Craneld
sem aglomerac~ao. . . 55 5.4 Percentagens da distribuic~ao de tempo pelas operac~oes realizadas na
inserc~ao de um documento. . . 62
Introduc~ao
1.1 Informac~ao
Informac~ao pode ser de nida como o conhecimento que reside no cerebro humano, em qualquer registo escrito ou electronico ou noutro meio fsico. Actualmente, a informac~ao e um alimento indispensavel a qualquer elemento de uma sociedade moderna e em constante mudanca. A transmiss~ao e armazenamento de informac~ao, para alem do cerebro humano, remonta a invenc~ao da propria escrita, entre 3000 e 2000 a.C., altura em que surgiram as primeiras bibliotecas. Todavia, foi com o Renascimento, no Seculo XV, que a procura e a oferta de informac~ao cresceu consideravelmente, devido n~ao so as tend^encias intelectuais da epoca, mas tambem devido a invenc~ao da tipogra a que, revolucionou a difus~ao do material escrito. No Seculo XIX, surgiram novos meios de uxo de informac~ao, tais como publicac~oes periodicas e documentos cient cos. Mas e no Seculo XX que a difus~ao da informac~ao comeca a envolver as grandes massas da populac~ao. Iniciam-se as emiss~oes de radio e televis~ao e a informac~ao ca disponvel de uma forma cada vez mais rapida e envolvente.
O aparecimento dos computadores veio revolucionar completamente a forma de encarar a informac~ao. Neste contexto, emerge a ci^encia Informatica, sendo tomada, comummente, por todos os que a ela est~ao ligados, como aquela que se encarrega do processamento automatico da informac~ao.
Entretanto, as quantidades de informac~ao processada e armazenada foram lar-gamente ultrapassadas com a ajuda da evoluc~ao tecnologica na area da microelec-tronica. A variedade de ramos que emergiram da informatica leva a necessidade da criac~ao de uma ci^encia que chame a si as tarefas de colectar, organizar, armazenar, recuperar e disseminar o conhecimento. Surgiu ent~ao a ci^encia da informac~ao.
A crescente necessidade bibliogra ca, acompanhada pelo avanco tecnologico do Seculo XX, levou a informatizac~ao da quase totalidade das bases de dados, catalogos
Captulo1. Introduc~ao 2
e colecc~oes. E neste sentido que a ci^encia da informac~ao comecava a dar os seus frutos.
Mas se a utilizac~ao do computador veio, por um lado, trazer enormes vantagens na concretizac~ao dos objectivos da ci^encia da informac~ao, veio por outro permitir o aumento desmesurado dos repositorios de informac~ao e alguma perda de controlo sobre a sua localizac~ao e conteudo.
1.2 A difus~ao da informac~ao
A industria dos computadores, apesar da sua juventude, rapidamente se inseriu noutras areas, tais como meios de transporte, comunicac~oes, servicos, industrias de fabrico, etc. O crescimento da aquisic~ao, processamento e distribuic~ao da informac~ao aumenta com uma sociedade cada vez mais empresarial e competitiva, necessitando-se de um tratamento mais so sticado da mesma.
O aparecimento das comunicac~oes por computador trouxe consigo uma nova vis~ao do mundo. O aumento rapido do poder computacional dos processadores ja prometia a sua utilizac~ao por varias pessoas. A interligac~ao dos computadores foi o passo essencial para que tal se concretizasse.
Adicionalmente, o aumento da largura de banda proporcionou o acesso a infor-mac~ao remota em tempos comparaveis ao acesso a um disco local. A rede de compu-tadores tranformou-se numa extens~ao dos perifericos locais de um computador. O computador potente e isolado que satisfaz as necessidades computacionais dos seus utilizadores, da agora passo a um numero mais elevado de computadores distantes, no entanto, interconectados. Torna-se, assim, possvel a partilha de recursos e de dados, e a distribuic~ao da carga computacional por varios computadores.
A conectividade dos computadores veio efectivamente bene ciar todas as areas que apostaram na sua industria. A partilha de informac~ao e o seu interc^ambio entre secc~oes diferentes de uma empresa tornou-se viavel por exemplo, as dist^ancias entre liais deixam de ser um factor signi cativo. Por outro lado, veio assegurar a continuidade da informac~ao atraves da sua replicac~ao, permitindo o funcionamento contnuo de tarefas de alto risco.
Mas se o mundo empresarial saiu bene ciado, mais bene ciados, ainda, sairam os investigadores e cientistas, que v^em assim uma forma rapida e pratica de difundir as suas ideias e partilhar informac~ao.
1.3 A Biblioteca Universal
Captulo1. Introduc~ao 3
criac~ao da World Wide Web (WWW) BLCL
+94]. A partilha da informac~ao feita ate
ent~ao atraves dos protocolos telnet, ftp, e-mail, gopher e wais, passa a ser feita por um sistema de visualizac~ao de paginas que d~ao acesso a outras paginas remotas ou locais atraves de hiperligac~oes, em que e possvel a conjugac~ao de todos os meios multimedia disponveis (imagem, som, vdeo). Esta integrac~ao foi possvel gracas a implementac~ao de um novo protocolo ao nvel da aplicac~ao designado por HyperText Transfer Protocol (HTTP) FGM+97] e da criac~ao de uma linguagem de etiquetas
orientada para a multimedia e para as hiperligac~oes, designada por HyperText Mar-kup Language (HTML) BLC95].
A WWWveio permitir a disponibilizac~ao de uma serie de recursos aos quais todos
os utilizadores da Internet t^em acesso. O sistema WWW veio afectar a Internet de
tal maneira, que o crescimento de computadores chega aos 9% mensais. A receita foi simples: a visualizac~ao da informac~ao de forma gra ca, possibilitando observar simutaneamente texto, imagens, som e vdeo, foi aliada a interacc~ao atraves de hiperligac~oes incorporadas no texto. Desta forma, o utilizador pode \movimentar-se"facilmente de recurso em recurso. Tendo em conta que todos os recursos podem ter uma ligac~ao remota, obtemos uma teia 1 complexa de informac~ao, na qual, um
utilizador uma vez emaranhado no meio dela, sente serias di culdades em se orientar. O crescimento de informac~ao na WWW e deveras prodigioso. Repare-se na
evo-luc~ao do numero de maquinas na internet ate Julho de 1997 no gra co da gu-ra 1.1 Wiz97]. Se estimarmos o numero de utilizadores que a elas est~ao ligados, imagine-se a quantidade de informac~ao que poder~ao publicar!
0 5.000.000 10.000.000 15.000.000 20.000.000 25.000.000
jan-93 jul-93 jan-94 jul-94 jan-95 jul-95 jan-96 jul-96 jan-97 jul-97
Máquinas Domínios
Figura 1.1: Evoluc~ao do numero de maquinas e domnios na internet.
A facilidade de publicac~ao e a liberdade de express~ao existentes na Internet
Captulo1. Introduc~ao 4
atraiu tambem um grande numero de empresas que aproveitam o potencial enorme numero de clientes para divulgar e vender os seus produtos. Todo este cenario permitiu um aumento t~ao desmesurado da quantidade de informac~ao, que a sua procura se manifesta uma tarefa difcil.
Resumindo, a WWW e, por excel^encia, a biblioteca universal. O seu crescimento
surpreendeu tudo e todos. As suas dimens~oes e o seu conteudo ultrapassam o co-nhecimento de qualquer ser humano e, por isso, assume um papel muito valioso em termos de disseminac~ao do conhecimento. Mas todo este poder de fogo, de nada serve se a informac~ao pretendida por um utilizador n~ao for encontrada facilmente e com ^exito. Da a constante preocupac~ao com a pesquisa na WWW.
1.4 Descoberta de recursos na WWW
Nesta secc~ao s~ao mencionados alguns dos servicos de descoberta de recursos de informac~ao na WWW. S~ao categoricamente divididos em sistemas integrados e n~ao
integrados, para marcar a distinc~ao entre aqueles que pretendem abordar o problema directamente com as infra-estruturas relacionadas com o funcionamento protocolar da WWW e os outros que assumem os recursos como documentos, passando por cima
de pormenores intrnsecos a WWW e que constituem a soluc~ao colocada em pratica
actualmente. Esta ultima vis~ao e colocada a um nvel superior, dependente da camada protocolar, e qualquer modi cac~ao que seja efectuada no funcionamento interno da WWW, pode criar serios problemas, que poder~ao levar a reimplementac~ao
de raiz deste tipo de sistemas. Esta divis~ao apesar de um pouco rude, tem como objectivo facilitar a analise do estado da arte nesta materia, de forma a distinguir aquilo que esta disponvel actualmente e o que seria ideal colocar em funcionamento. Seria de todo fundamental que fosse colocada \ordem na WWW" ao nvel do
pro-tocolo, isto e, recorrendo a mecanismos directamente integrados dentro do proprio sistema de devoluc~ao de recursos WD94]. O sistema de resoluc~ao de nomes univer-sais vem precisamente prop^or esta soluc~ao Sol97]. Por ser uma proposta radical, a sua aceitac~ao deve ser feita de forma atomica e cuidadosa, isto e, duma vez so.
Enquanto n~ao s~ao tomadas decis~oes relativas ao funcionamento do fulcro daWWW,
novas soluc~oes de pesquisas t^em vindo a ser desenvolvidas como forma de dar um novo f^olego a descoberta de recursos. Os chamados \motores de pesquisa"t^em feito grande furor dentro da comunidade daWWW, devido a ^ansia em encontrar uma soluc~ao
que vise a procura de recursos em quantidade e qualidade su cientes.
1.4.1 Servicos integrados
A pesquisa e organizac~ao da informac~ao na WWW foi uma quest~ao desde sempre
Captulo1. Introduc~ao 5
Para a identi cac~ao universal de cada rescurso que se encontra na WWW e utilizada
um Localizador Universal de Recursos2(
URL)BLMM94]. No entanto, estes identi
-cadores n~ao s~ao tolerantes a faltas, torna-se difcil a sua manutenc~ao, para alem de n~ao disporem de qualquer informac~ao de qualidade de servico. Como alternativa foi pensado o Nome Universal de Recursos3(
URN)SM94] que permite uma identi cac~ao
persistente, unica, independente da localizac~ao e com possibilidade de refer^encia a multiplos recursos permitindo ainda varios criterios na decis~ao do melhor recurso disponvel em determinada altura. A convers~ao de um URNpara URLpressup~oe um
servico de resoluc~ao semelhante ao Servico de Directoria DNS. Para que sejam
fei-tas decis~oes para a escolha do URN existe ainda um outro Identi cador Universal
de Caractersticas4(
URC)RDM95], que contem a informac~ao particular a cada URL.
Este identi cador para alem de conter a meta-informac~ao (informac~ao sobre a infor-mac~ao) das localizac~oes do recurso, pode ainda conter informac~oes sobre o tipo de recurso, vers~ao, datas de criac~ao e modi cac~ao, dist^ancia na rede e inclusivamente dados bibliogra cos e autenticac~ao.
Existem actualmente varios sistemas que implementam o servico de resoluc~ao de
URNs, n~ao tendo ainda nenhum sido adoptado na pratica. Destaca-se oWHOIS++DFM95]
pela sua qualidade como servico de directoria generico, o Simple Discovery Protocol (SDP) HK95] que tira partido do Multicast IP para resoluc~ao deURNs e o Resolver
Discovery Service (RDS) Slo97] que tem sido abordado recentemente.
O princpio de funcionamento destes sistemas consiste na delegac~ao da infor-mac~ao entre servidores inseridos dentro de uma rede de servidores. A tecnica de propagac~ao e procura de informac~ao e baseada num servico de directoria com maior generalizac~ao que o DNS.
Facilmente se depreende que a criac~ao de sistemas deste tipo, prometem seria-mente a resoluc~ao das lacunas referidas para a exist^encia de apenas URLs, podendo
tambem contribuir para a pesquisa de informac~ao mais pormenorizada, tais como enderecos de correio electronico, documentos publicados electronicamente e ate mes-mo paginas da WWW. Torna-se ainda possvel a ltragem de informac~ao, o controlo
de acesso de acordo com regras estipuladas, a manutenc~ao de privaciade e a auten-ticac~ao dos recursos, tema t~ao em voga actualmente.
O servico deURCs e um tema que tem levado algum tempo a ser concretizado uma
vez que, devido ao seu grau de integrac~ao, a sua estabilizac~ao envolve a de nic~ao de uma serie de normas e generalizac~oes e de modi cac~oes que afectam o proprio funcionamento da WWW.
2
Doingl^esUniversal Resource Locator. 3
Doingl^esUniversal Resource Name. 4
Captulo1. Introduc~ao 6
1.4.2 Servicos n~ao integrados
Dentro dos servicos n~ao integrados incluem-se os catalogos e os motores de pesquisa. Nos primeiros s~ao feitas divis~oes estanques sobre assuntos de interesse geral. Estes servicos envolvem uma forte componente humana, constituindo um forma bastante e ciente de procurar aquilo que se pretende, carecendo no entanto de totalidade, ou seja, e bem possvel encontrar algo que se pretende, mas longe de encontrar tudo o pretendido.
Os motores de pesquisa baseiam-se no princpio da busca exaustiva da informac~ao atraves de robots que a colectam e que sera indexada em bases de dados locais. A
grande di culdade destes servicos e a gest~ao das gigantescas bases de dados geradas, apesar da eliminac~ao de grande parte da informac~ao atraves das tecnicas que veremos mais a frente. Actualmente os motores de pesquisa constituem o ponto de partida principal para a pesquisa na WWW.
1.5 Objectivos da tese
A descoberta de recursos de informac~ao e um tema que tem que ser tomado com bastante preocupac~ao dado o crescimento veri cado na WWW. Talvez por isso, os
investigadores tenham sido apanhados de surpresa ao n~ao preverem a situac~ao cari-caticamente caotica existente actualmente.
Os servicos integrados constituem, sem duvida, a soluc~ao por excel^encia, ja que, conseguem abordar o problema da procura de recursos, e incluir outro tipo de meta-informac~ao. Por outro lado, e sabido que a WWW sofrera alterac~oes, se bem que n~ao
se sabe ate que ponto. Fazendo uma abordagem de fundo, e possvel resolver as quest~oes actuais e evitar que outros problemas surjam no futuro.
Os motores de pesquisa baseiam-se num conceito muito simples: a concentrac~ao, ou seja, percorrer a WWW e concentrar a informac~ao. Actualmente as empresas de
desenvolvimento de motores de pesquisa na WWW est~ao a concentrar os seus esforcos
no sentido de colocar em pratica a melhor utilizac~ao das tecnicas de Recuperac~ao de Informac~ao 5 (RI) Cro95].
Em ambos os tipos de servicos aqui apresentados, a necessidade em adquirir informac~aoe uma caracterstica comum. Informac~ao essa que precisa de ser indexada de alguma forma, de tal modo que permita a pesquisa em tempos aceitaveis. Este e um problema que ja tem sido abordado muito antes da exist^encia da WWW pela
ci^encia de Recuperac~ao de Informac~ao
O presente trabalho tem como orientac~ao a descoberta de recursos de informac~ao na WWW, partindo dos conceitos associados a RI e tendo em vista um possvel
apro-veitamento das conclus~oes que sejam retiradas deste trabalho, por qualquer um dos
5
Captulo1. Introduc~ao 7
servicos de descoberta de recursos referidos, ou seja o aproveitamento de tecnicas de indexac~ao e a disseminac~ao de informac~ao numa rede de servidores que constituem o sistema. Para isso, foram tomadas como ideias base os aspectos fundamentais que cada um dos servicos aproveita melhor.
Pretende-se, ent~ao, construir e veri car o desempenho de um sistema que alie o poder de aquisic~ao e concentrac~ao de informac~ao de um motor de pesquisa, a uma divis~ao de documentos, comparavel aclassicac~aorealizada pelos catalogos, tirando
todo o partido de uma base de dados distribuda.
Note-se que os resultados deste trabalho poder~ao servir de base tanto para in-vestigac~oes ao nvel dos servicos integrados, uma vez que e focado o aspecto da distribuic~ao de ndices, e para os servicos n~ao integrados pois a classi cac~ao au-tomatica e a distribuic~ao das bases de ndices constituem uma inovac~ao a este nvel, sendo esta uma das maiores lacunas destes sistemas.
O sistema sera construdo como um banco de teste, a m de poderem ser ti-radas as conclus~oes necessarias para a possibilidade de viabilidade em ambiente laboratorial. Naturalmente, alguns pormenores ser~ao desprezados, dada a extens~ao de materias abrangidas pelo estudo. E dada particular import^ancia aos resultados experimentais, pois so atraves destes sera possvel extrair algum tipo de conclus~oes. Sera o objetivo nal confrontar a diferenca de tempos de desempenho, quer em calculos quer em transporte pela rede, e o desempenho das tecnicas utilizadas entre um sistema centralizado e distribudo a m de veri car a possibilidade de sucesso da distribuic~ao das bases de dados.
1.6 Resumo dos captulos seguintes
O texto que se segue, toma uma sequ^encia logica desde a introduc~ao aos sistemas de RI ate a apresentac~ao dos resultados e respectivas conclus~oes.
Assim, no captulo 2 e apresentado o pano de fundo que rodeia a RI, de nindo conceitos actualizados e apresentando o esquema geral de recuperac~ao de informac~ao, descrevendo os passos necessarios para uma aquisic~ao de informac~ao e sua devoluc~ao efectiva.
No captulo 3 s~ao descritos os modelos conceptuais disponveis na RI e as suas caractersticas, dando particular relev^ancia ao modelo do espaco vectorial e ao mo-delo de aglomerac~ao. E ainda, referido o processo de avaliac~ao de sistemas de RI e a forma como devem ser apresentados os resultados para uma melhor comparac~ao entre as tecnicas.
Captulo1. Introduc~ao 8
selecc~ao das tecnicas de RI nas suas diversas fases e, ainda, os pormenores de im-plementac~ao que tiveram que ser tomados em conta para a optimizac~ao do sistema. O captulo seguinte e dedicado a descric~ao e analise de todos os testes efectuados com a colecc~ao Craneld. S~ao apresentados resultados da e ci^encia e e cacia do
sistema.
Captulo 2
Recuperac~ao de Informac~ao
A Recuperac~ao de Informac~ao (RI) e a area que tem como nalidade a aquisic~ao, armazenamento e devoluc~ao de informac~ao perante uma especi cac~ao dada por um utilizador.
Apesar de n~ao ser explcito no nome, as tecnicas inerentes a RI t^em caracter automatico, colocando de parte, desde logo, qualquer interacc~ao humana no processo de devoluc~ao de informac~ao. N~ao confundir, no entanto, uma das tecnicas utilizadas na RI, chamada realimentac~ao de relev^ancia1 que tira partido de informac~oes dadas
pelo utilizador depois de ja ter sido disponibilizada a informac~ao pretendida. O tipo de recursos envolvidos podem ir desde texto, imagens, som ou video Man97]. No entanto, no que respeita ao tema da tese, apenas sera abordado o primeiro tipo.
O aspecto mais importante da RI e que esta n~ao informa o utilizador acerca do assunto a que o seu pedido se refere, mas sim acerca da exist^encia ou n~ao desse assunto e a sua localizac~ao em algum recurso que o sistema re ra vR79].
Frequentemente a RI e confundida com Recuperac~ao de Dados (RD). Vejamos as principais diferencas esquematizadas na Tabela 2.1 FBY92, vR79].
Ao contrario do que sucede num sistema de Recuperac~ao de Dados (RD), os sistemas de RI executam operac~oes de comparac~ao entre os objectos de dados de forma parcial, ou seja, a comparac~ao e feita com base na optimizac~ao de uma func~ao de dois argumentos, que s~ao substitudos pelos objectos de dados. A metrica de comparac~ao e baseada em dados estatsticos, como seja a frequ^encia de palavras em cada objecto de dados. Como resultado obtemos ent~ao a devoluc~ao de um conjunto de itens considerados relevantes, enquanto que no sistema de RD, s~ao devolvidos os itens resultantes de uma comparac~ao precisa, sendo por isso sensvel a falhas.
No que respeita as interrogac~oes, nos sistemas de RI, para alem de n~ao neces-sitarem de uma especi cac~ao completa, podem tambem ser descritas atraves de linguagem natural.
1
Doingl^esrelevancefeedback.
Captulo 2. Recuperac~ao de Informac~ao 10 Recuperac~ao de Dados Recuperac~ao de Informac~ao
Objecto de Dados Tabela Documento
Comparac~ao Exacta Parcial, Melhor
Infer^encia Deduc~ao Induc~ao
Modelo Determinstico Probabilstico
Linguagem da Arti cial Natural
interrogac~ao
Especi cidade da Completa Incompleta interrogac~ao
Itens Desejados Por comparac~ao Por relev^ancia
Resposta a Erros Sensvel Insensvel
Tabela 2.1: Comparac~ao entre a Recuperac~ao de Informac~ao e a Recuperac~ao de Dados
2.1 Denic~oes
Para se compreender melhor o funcionamento e a constituic~ao estrutural de um sistema de RI, vamos assentar algumas de nic~oes importantes que ser~ao usadas ao longo deste texto.
Um documento e o elemento fundamental de um sistema de RI, e este que o utilizador pretende adquirir. A descric~ao da informac~ao que o utilizador deseja e chamada a interrogac~ao. Os documentos que cont^em informac~ao relacionada com uma interrogac~ao s~ao designados documentos relevantes. Um conjunto elevado de documentos constitui uma colecc~ao. Como apenas ser~ao abordados documentos textuais, estes podem ser cheiros de texto, recursos da WWWou apenas um conjunto
relativamente pequeno de paragrafos, como e o caso de algumas colecc~oes de teste, que s~ao utilizadas na avaliac~ao do desempenho de um sistema de RI. Num sistema de RI, os documentos assumem duas formas: o documento original que constitui a colecc~ao, e que e o objectivo do utilizador e a representac~ao interna que e feita do documento, que naturalmente e uma simpli cac~ao do primeiro. Enquanto n~ao surgir o risco de confus~ao chamar-lhe-emos documento a ambas as formas. Cada documento e constitudo por um conjunto de termos, ou seja, por palavras, as quais, para se obter a representac~ao do documento, s~ao sujeitas a um tratamento especial, como veremos na secc~ao 2.5.
A construc~ao de um sistema de RI e sempre feito tendo em vista a optimizac~ao dos algoritmos que manipulam as estruturas de dados que conter~ao a informac~ao necessaria para o seu funcionamento. A optimizac~ao e feita sob dois pontos de vista: eci^encia2e ecacia3. Enquanto que a primeira mede o modo como s~ao aproveitados
os recursos computacionais, como o tempo de processamento, memoria necessaria
2
Doingl^eseciency.
Captulo 2. Recuperac~ao de Informac~ao 11 e espaco em disco para armazenar as estruturas, a segunda mede a forma como o sistema responde positivamente aquilo que se pretende. Neste caso, a devoluc~ao do maior numero de documentos relevantes, evitando a devoluc~ao de documentos n~ao-relevantes. A e cacia de um sistema e medida em termos de precis~ao
4 e
to-talidade
5. A precis~ao e dada pelo numero de documentos devolvidos considerados
relevantes, sobre o numero total de documentos devolvidos. A totalidade e dada pelo numero de documentos devolvidos considerados relevantes sobre o numero de documentos realmente relevantes (devolvidos ou n~ao). Estes aspectos ser~ao vistos mais em pormenor na secc~ao 3.6
2.2 Estatstica na RI
Para nos humanos, a leitura de um texto permite-nos identi car facilmente os as-pectos mais importantes do seu conteudo. Para um computador o processo ja n~ao se torna t~ao simples. Se bem que se tem feito investigac~ao na area da Intelig^encia Arti cial no sentido de analisar e compreender textos atraves do processamento de linguagem natural (PLN) RL94], as tecnicas utilizadas possuem um consumo computacional muito elevado, pelo que a sua utilizac~ao e bastante restrita e n~ao vulgarizada em casos praticos reais. Resta ent~ao pegar na soluc~ao mais viavel, transparente e inerte - a analise da palavra. Como n~ao e feita qualquer conotac~ao sem^antica, uma vez que e utilizada a palavra so por si, podemos ter um grau de generalidade muito maior, possibilitando a sua aplicac~ao a variac~oes de conteudo e mesmo criar alguma independ^encia em relac~ao as variac~oes lingusticas.
A palavra pode ser considerada o elemento basico de um sistema de RI, uma vez que e atraves dela que o sistema realiza as operac~oes basicas de comparac~ao, tanto entre documentos entre si, como entre documentos e interrogac~oes. Quanto mais palavras houver em comum maior relacionamento existe entre os objectos formados pelas palavras. Se adicionalmente for contabilizada a frequ^encia com que essas palavras ocorrem no documento, facilmente somos conduzidos a formulac~ao de um modelo estatstico.
Esta caracterstica permite desenvolver, nos sistemas de RI, o seu maior potencial - a quanti cac~ao dos objectos -, permitindo a utilizac~ao de metricas quantitativas e respostas distribudas segundo um grau de relev^ancia. Isto signi ca que, perante uma interrogac~ao, os documentos s~ao ordenados por similaridade, podendo assim criar-se dois grandes grupos de documentos: relevantes e n~ao relevantes. Os pri-meiros ser~ao aqueles que servir~ao como resposta ideal, enquanto que os segundos dever~ao car excludos, restringindo assim, o numero de soluc~oes para o utilizador.
4
Doingl^esprecision.
5
Captulo 2. Recuperac~ao de Informac~ao 12
Entrada de Documentos
Entrada de Interrogações
Saída de Documentos
Figura 2.1: Modelo de caixa preta para um sistema de RI
2.3 Estrutura de um sistema de RI
Um sistema de RI pode ser visto, grosso modo, atraves de um modelo de caixa preta, com duas entradas e uma sada. Uma das entradas e o canal por onde e armazenada toda a informac~ao relativa a colecc~ao de documentos. Estes podem permanecer de forma estatica, sem actualizac~ao, ou ent~ao de forma din^amica, sendo assim possvel a sua renovac~ao ou incrementac~ao gradual. Esta entrada n~ao esta directamente relacionada com o utilizador do sistema, cabendo apenas ao gestor a decis~ao do tipo e numero de documentos que ser~ao la introduzidos.
Os restantes canais s~ao aqueles que t^em actividade directa com o utilizador. Pela outra entrada e encaminhada a interrogac~ao, a qual o sistema respondera pelo canal de sada com os documentos relevantes ao seu pedido.
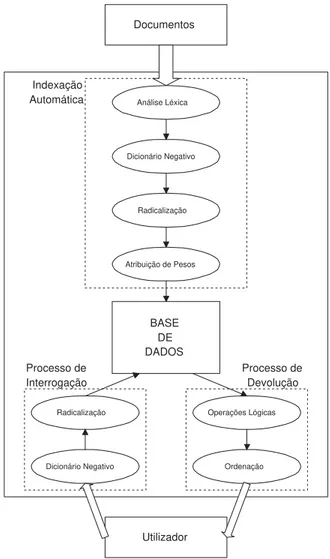
Observando agora o conteudo da caixa ( gura 2.1), a cada canal e correspondido com um modulo de processamento. Para sustentar este conjunto de processos, o sistema disp~oe ainda de uma base de dados central que contem as representac~oes dos documentos.
Para conseguir retirar a informac~ao mais signi cativa do texto dos documentos originais e colocar o resultado em estruturas de dados su cientemente e cientes, e necessario proceder a um processo de transformac~ao dos documentos nos seus representantes. Este processo pode ser decomposto em duas fases: o processamento de texto e a indexac~ao automatica. A primeira fase encarrega-se de decomp^or o texto em palavras, evitando as repetic~oes e caracteres sem signi cado, como por exemplo pontuac~ao ou caracteres de controlo. A segunda tem por objectivo integrar os termos dos documentos da forma mais optimizada possvel na estrutura de dados do sistema de RI. As palavras s~ao confrontadas com uma lista de paragem, ou seja, lista de palavras comuns, e eliminadas do documento. Posteriormente, s~ao sujeitas a um processo de radicalizac~ao, resultando na uni cac~ao de palavras que tenham cado com o mesmo radical. Este processo pode ser visto mais detalhadamente nas secc~oes 2.4 e 2.5.
Captulo 2. Recuperac~ao de Informac~ao 13
Análise Léxica
BASE DE DADOS Documentos
Dicionário Negativo Radicalização Atribuição de Pesos
Radicalização Dicionário Negativo
Operações Lógicas Ordenação
Utilizador Indexação
Automática
Processo de Interrogação
Processo de Devolução
Figura 2.2: Esquema funcional de um Sistema de RI
interrogac~ao e tambem sujeita ao mesmo processo de eliminac~ao de palavras comuns e de radicalizac~ao, para garantir uniformizac~ao dos termos em ambos (documentos e interrogac~oes).
Apos ter sido calculado o conjunto soluc~ao, o terceiro processo encarrega-se de devolv^e-la ao utilizador, ordenado por ordem de relev^ancia.
Captulo 2. Recuperac~ao de Informac~ao 14
2.4 Estruturas de dados
As estruturas de dados de qualquer programa de computador s~ao o suporte funda-mental para a obtenc~ao de algoritmos poderosos e e cientes. No caso dos sistemas de RI, a parte das estruturas de dados tem obtido particular interesse devido a dimens~ao extremamente enorme que as colecc~oes de documentos podem atingir.
Os avancos tecnologicos do hardware, nomeadamente na area de armazenamento
de dados, t^em contruibuido para o aperfeicoamento e aumento da capacidade da memoria central.
Devido ao tamanho das colecc~oes e a sua caracterstica persistente, e necessario recorrer a utilizac~ao de suportes secundarios de armazenamento.
A utilizac~ao de discos duros e sem duvida a mais diversi cada uma vez que permite uma velocidade de acesso bastante elevada. O discos opticos s~ao uma tec-nologia que tem vindo a ser utilizada gradualmente. As vantagens v~ao desde a sua imensa capacidade de armazenamento e durabilidade dos dados ate a uma maior portabilidade.
2.4.1 Ficheiro Invertido
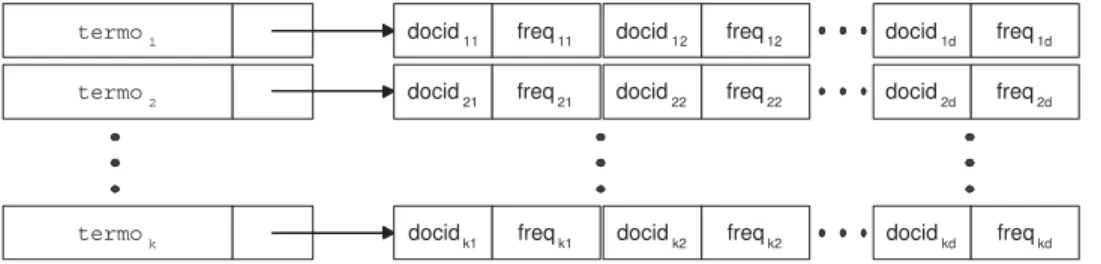
Os cheiros invertidos s~ao dos tipos de estruturas de cheiros mais utilizadas nos sistemas de RI , n~ao so pela sua simplicidade na implementac~ao, mas principalmente pelo seu desempenho.
O armazenamento da informac~ao nos cheiros invertidos, contraria a organizac~ao logica do documento em si. A gura 2.3 apresenta uma representac~ao de um cheiro invertido. Em vez de se guardarem os documentos sequencialmente juntamente com o conjunto de termos respectivos, soluc~ao que tornar-se-ia demasiado ine ciente, guardam-se os termos individualmente e uma refer^encia para os documentos que cont^em esse termo, conjuntamente com outra informac~ao adicional, constituda pela frequ^encia desse termo no documento.
Para manter esta estrutura, por raz~oes obvias de dimens~ao e persist^encia, ela e armazenada em disco atraves de um array ordenado, arvores-B ou arvores PAT FBY92]. As arvores-B, apesar de necessitarem de mais espaco, cerca de 10% a 100% do tamanho do texto original, possuem uma maior facilidade de actualizac~ao CP92]. A ordem de complexidade para o tempo de pesquisa e O(logn). As arvores PAT
Captulo 2. Recuperac~ao de Informac~ao 15
termo1
termo2
termo
k
docid11 freq11 docid12 freq12 docid1d freq1d docid21 freq21 docid22 freq22 docid2d freq2d
docidk1 freqk1 docidk2 freqk2 docidkd freqkd
Figura 2.3: Estrutura de um cheiro invertido
2.5 Indexac~ao Automatica
A indexac~ao automatica e um processo em que se realiza a transformac~ao do texto original em termos. O principal objectivo da indexac~ao e extrair do texto a sua ess^encia, ou seja, as palavras que contribuem mais para a sua descric~ao. Por outro lado, pretende-se tambem reduzir ao maximo o seu conteudo por forma a diminuir o espaco necessario para o seu armazenamento, tentando eliminar palavras que em nada contribuem para a sua interpretac~ao.
O texto e primeiramente decomposto em palavras, as quais s~ao retiradas aque-las consideradas sem signi cado sem^antico, apos o que s~ao reduzidas ao seu radical mnimo atraves de regras previamente de nidas. Por ultimo, cada termo e afectado de um valor que reicta a import^ancia desse termo no documento. Em muitos siste-mas s~ao ainda utilizados dicionarios de sinonimos com o objectivo de reduzir ainda mais a quantidade de termos resultantes. No entanto a sua construc~ao automatica torna-se bastante complexa, n~ao sendo ainda muito utilizado nos sistemas de RI JC93]. O resultado e um conjunto mnimo de pares termos / frequ^encia, que e calculado durante o processo, sendo armazenados na estrutura de dados adequada. A de nic~ao de dicionarios negativos e a criac~ao das regras de radicalizac~ao s~ao passos dependentes da lngua que o texto original se encontra.
2.5.1 Analise Lexica
A preparac~ao do texto original, para que seja possvel a sua transformac~ao em termos indexados, passa por uma primeira fase de separac~ao atomica da unidade textual -a p-al-avr-a. Um texto e um-a sequ^enci-a de c-ar-acteres que, p-ar-a -alem de constituirem palavras, podem servir como separadores ou controlo. Dentro dos caracteres separa-dores e controlo podemos incluir a pontuac~ao que e utilizada na escrita convencional, os espacos, quebras de linha e marcas que permitem a formatac~ao do texto. Todos estes elementos t^em uma func~ao espec ca e necessaria no respectivo contexto. Na analise lexica ajudam na separac~ao das palavras, acabando por ser ltrados, uma vez que n~ao contribuem para a compreens~ao sem^antica do texto.
Captulo 2. Recuperac~ao de Informac~ao 16 por vezes situac~oes ambguas, que podem levar a interpretac~ao errada do texto. E por exemplo, a distinc~ao entre uma maiuscula forcada por um incio de frase e um nome proprio, ou ent~ao a distinc~ao entre um ponto nal e um ponto de um numero real ou de uma abreviatura. Muitos destes problemas podem ser minimizados re-correndo a aplicac~oes como olexouex, que permitem a ltragem sucessiva atraves
da utilizac~ao de express~oes regulares GT94].
2.5.2 Dicionario negativo
O dicionario negativo6 e um conjunto de palavras, que s~ao, normalmente,
enumera-das manualmente, ou criaenumera-das automaticamente atraves da analise de frequ^encia de palavras em colecc~oes. As palavras com maior frequ^encia s~ao supostamente as que far~ao parte do dicionario negativo. N~ao sendo, no entanto, garantida uma margem de erro de 0%, uma vez que podem ser includas palavras com utilidade contextual. A ideia basica dos dicionarios negativos e eliminar palavras sem contexto se-m^antico, tais como determinantes, pronomes, preposic~oes, conjunc~oes e adverbios, de modo a optimizar tanto o tempo de pesquisa, como o espaco ocupado pelos documentos, que pode ser reduzido entre 30% e 50% vR79], sem comprometer demasiado a e cacia do sistema.
E muito comum veri car, em alguns sistemas de RI, a eliminac~ao de palavras mais frequentes apenas na fase de atribuic~ao de pesos (ver secc~ao 2.5.4), pois e nesta fase que e obtida uma quanti cac~ao mais precisa da palavra contida em determinado documento.
2.5.3 Radicalizac~ao
A radicalizac~ao7 e um processo lingustico de reduc~ao de palavras ao seu radical
mnimo. Entende-se por radical mnimo a forma morfologica que existe em co-mum entre as palavras, que na maioria dos casos apresentam o mesmo signi cado sem^antico. Por exemplo, as palavras industrial, industrialisation e industries s~ao
reduzidas a um unico radical, pois todas elas, apesar de serem morfologicamente distintas, referem-se ao mesmo conceito. Assim, torna-se possvel a reduc~ao do ta-manho do cheiro de dados em cerca de 20% a 50% para colecc~oes pequenas. Em termos de e cacia, os varios estudos que foram feitos revelam que n~ao existe uma variac~ao signi cativa . Tambem n~ao se manifesta importante a escolha do tipo de radicalizac~ao utilizada. As variac~oes s~ao, isso sim, mais dependentes da natureza das colecc~oes e do seu tamanho HG96].
6
Doingl^esstop list. 7
Captulo 2. Recuperac~ao de Informac~ao 17
2.5.4 Atribuic~ao de Pesos
O processo de atribuic~ao de pesos vem complementar as tecnicas anteriores de cac~ao de documentos e acrescentar informac~ao util acerca dos termos que comp~oem esses documentos. A enumerac~ao dos termos que existem num dado documento, apesar de fazer uma cobertura bastante e caz, n~ao se torna su ciente para descre-ver a import^ancia desses termos no seu conteudo pelo que, a simples informac~ao da exist^encia, ou n~ao, de um termo no documento, sendo um processo simples de implementar, carece de informac~ao util que permita ao sistema uma resposta mais e caz.
Como e possivel, ent~ao, quanti car automaticamente o peso que cada termo exerce em cada documento? A frequ^encia com que um termo surge no documento parece ser uma soluc~ao promissora. Basta reparar que, num documento quando, uma determinada palavra aparece mais frequentemente, a partida, essa palavra sera mais importante que outra que surja menos vezes. Manipula-se aqui o jogo da estatstica, ao se pretender obter informac~ao das palavras com base na sua repetic~ao ao longo de um texto. O importante e conciliar o maior numero de dados disponveis ao menor custo. Quando estamos perante uma situac~ao em que a analise sintactico-sem^antica e posta de lado, esta informac~ao e de extrema import^ancia. Este tipo de atribuic~ao de peso designa-se por frequ^encia do termo (FT).
Foi Luhn Luh58] quem inicialmente prop^os ja esta ideia, estabelecendo, no en-tanto, limites no que respeita a palavras com frequ^encias muito altas e muito baixas. No entanto, o aumento de frequ^encia das palavras n~ao e linear em relac~ao a sua im-port^ancia para o documento. Para ultrapassar este problema, a soluc~ao e utilizar uma func~ao de atenuac~ao para valores mais elevados de frequ^encia.
A atribuic~ao de pesos pode chegar ainda mais longe. Em documentos que pos-suam caracteres de controle de formatac~ao de texto, como e o caso das lingua-gens com marcas8 em que e possvel identi car facilmente palavras com conteudo
sem^antico, pode atribuir-se-lhe um aumento de import^ancia relativa.
A FT n~ao e a unica condic~ao que inuencia a discriminac~ao de um documento. O peso de um termo pode tambem ser afectado pela sua distribuic~ao por toda a colecc~ao de documentos, o que e designado vulgarmente pela Inversa da Frequ^encia de Documentos (IFD).
Outro factor a ter em conta e o tamanho do documento, que podem afectar signi cativamente o desempenho de um sistema de RI, e que e concretizado atraves de func~oes de normalizac~ao.
A atribuic~ao de pesos depende do modelo de RI utilizado. Como se vera no captulo seguinte o modelo probabilstico efectua uma deduc~ao matematica destes pesos, ao passo que o modelo do espaco vectorial, efectua-a de uma forma emprica.
Captulo 3
Modelos conceptuais dos sistemas
de Recuperac~ao de Informac~ao
No captulo anterior, vimos como era possvel transformar o texto contido nos do-cumentos em termos armazenaveis em cheiros de facil acesso atraves da indexac~ao automatica. Vamos abordar agora, o nucleo de um sistema de RI, onde s~ao realiza-das as operac~oes de decis~ao de quais documentos ser~ao devolvidos ao utilizador.
Quando estamos perante um sistema de RI, pretende-se que este devolva o maior numero de documentos relevantes em relac~ao a uma interrogac~ao e consiga ignorar aqueles que n~ao s~ao relevantes.
Uma vez que n~ao e feita qualquer analise sem^antica ao texto original, contamos apenas com o numero de palavras que os documentos t^em em comum, conjugado com o factor de relev^ancia (peso) que cada uma tem associado. O processo de indexac~ao automatica vem possibilitar a simpli cac~ao dos algoritmos de comparac~ao, tentando manter equilibrada a relac~ao desempenho/espaco.
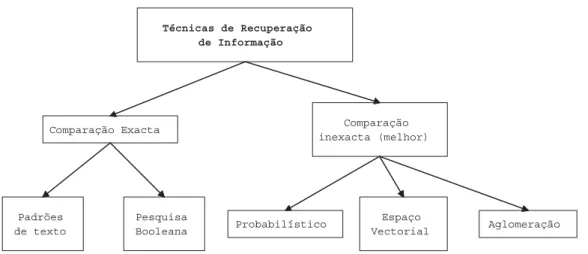
O processo de como esta selecc~ao e feita, de ne o tipo de modelo conceptual de cada sistema. A gura 3.1 ilustra a decomposic~ao das tecnicas utilizadas nos sistemas de RI mais comuns BC87].
Segundo este autor, a maior subdivis~ao reside no tipo de comparac~ao feita entre os documentos, a que correspondem dois grupos: comparac~ao exacta e comparac~ao inexacta com melhor aproximac~ao. Na comparac~ao exacta, podem identi car-se as comparac~oes feitas com padr~oes de texto e as pesquisas booleanas. Nestes dois modelos, os documentos s~ao devolvidos por simples presenca de termos contidos na interrogac~ao, resultando apenas uma decis~ao binaria. Um documento ou e ou n~ao e relevante.
Quando nas tecnicas de RI e usada uma comparac~ao inexacta, surge a necessida-de necessida-de obter um modo necessida-de ponecessida-der confrontar os documentos e maximizar uma func~ao de similaridade entre eles. Deixa, assim, de ter-se um modo preciso de procurar
Captulo 3. Modelos conceptuais dos sistemas de Recuperac~ao de Informac~ao 19
Técnicas de Recuperação de Informação
Comparação Exacta Comparação
inexacta (melhor)
Padrões de texto
Pesquisa Booleana
Espaço Vectorial
Probabilístico Aglomeração
Figura 3.1: Categorizac~ao das tecnicas de RI
informac~ao nas colecc~oes, e passa a disp^or-se de uma forma de obter, para cada in-terrogac~ao, um conjunto de documentos potencialmente validos, ordenados por um valor de semelhanca, consoante o resultado da metrica de comparac~ao.
N~ao existe uma divis~ao estanque entre as varias tecnicas, podendo ser utilizadas em conjunc~ao umas com as outras.
3.1 Modelo de padr~oes de texto
Este modelo tem como base a comparac~ao directa entre as interrogac~oes e os docu-mentos. Nele podem incluir-se utilitarios de pesquisa que facam uso de express~oes regulares, como por exemplo ogrep, o awke ainda o mais poderosoagrep WM92],
que para alem das potencialidades de utilizac~ao com padr~oes de texto, permite uma comparac~ao aproximada de texto e ainda notac~ao booleana na pesquisa.
Os modelos de padr~oes de texto s~ao normalmente utilizados em aplicac~oes pes-soais de pequena envergadura, ou ent~ao como base para aplicac~oes mais complexas, as quais adicionais funcionalidades e tiram partido do tipo de ferramentas deste modelo. Repara-se que as raz~oes destas limitac~oes est~ao relacionadas com o facto de este modelo operar directamente com os objectos de pesquisa, e n~ao com algum tipo de representante ou simplicac~ao.
3.2 Modelo Booleano
Captulo 3. Modelos conceptuais dos sistemas de Recuperac~ao de Informac~ao 20 Tal como o modelo anterior, o resultado de sistemas baseados nestes modelos, ape-nas indicam a relev^ancia ou n~ao de um documento, numa escala binaria. Uma caracterstica que permite fazer alguma distinc~ao entre modelos e o anterior, e a sua utilizac~ao em colecc~oes de grandes dimens~oes, dado que ja e implementado o conceito de base de dados de termos, onde s~ao armazenadas as representac~oes dos objectos a pesquisar.
Tornou-se bastante comum a utilizac~ao deste modelo suportado pelo cheiro invertido, pois torna-se muito pratica a concretizac~ao das operac~oes logicas entre os termos e a organizac~ao do cheiro invertido.
A ttulo de exemplo de uma aplicac~ao do modelo booleano, re ra-se o glimp-se MW93] que usa o agrep como motor de pesquisa.
Os modelos booleanos devido a simplicidade na de nic~ao das interrogac~oes exi-gem que estas sejam muito limitativas e, por isso, mais adequadas em casos onde o vocabulario dos objectos a pesquisar e restrito ou conhecido a partida.
Para ultrapassar este tipo de problemas, foram desenvolvidos modelos em que a comparac~ao entre os objectos e a interrogac~ao e feita de forma inexacta, atribuindo aos objectos uma ordem de relev^ancia, como se podera observar como os modelos das secc~oes seguintes.
3.3 Modelo Probabilstico
O modelo probabilstico assume uma abordagem puramente matematica Sal78] a RI, baseado no estudo da distribuic~ao dos termos pela colecc~ao de documentos, de forma a poder calcular a probabilidade de relev^ancia de um determinado documento face a um conjunto de termos (interrogac~ao).
O desenvolvimento matematico deste modelo situa-se fora do ^ambito dos objec-tivos do presente trabalho vR79], sendo a sua refer^encia importante para colocar em evid^encia o aparecimento de algumas relac~oes que s~ao vulgarmente usadas na RI, uma vez que s~ao deduzidas a partir deste modelo FB93]. S~ao, nomeadamente, as variac~oes que surjem na atribuic~ao de pesos.
3.4 Modelo do Espaco Vectorial
Captulo 3. Modelos conceptuais dos sistemas de Recuperac~ao de Informac~ao 21 e semanticamente associados. E, no entanto, este pressuposto que permite utilizar os modelos matematicos associados a espacos euclidianos, de que esta tecnica tira partido. Assim sendo, torna-se difcil, ao MEV captar as relac~oes inerentes a palavras sinonimas e polionimas, uma vez que, n~ao permite descrever relacionamente entre os termos.
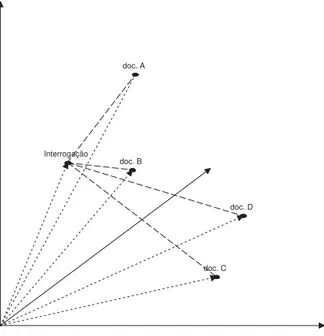
A gura 3.2 apresenta a representac~ao feita de uma interrogac~ao e de alguns documentos, atraves da analogia vectorial. Assumindo o espaco euclidiano, facil-mente se encontra o documento que se encontra a menor dist^ancia da interrogac~ao (o documento B, neste caso).
Apesar dos obstaculos, o MEV continua a ser um modelo bastante utilizado e bem aceite na comunidade cient ca. Os resultados extrados deste modelo, continuam a agradar a quem os utiliza, sendo, no entanto, importante a sensibilizac~ao de uma transic~ao para metodos mais perfeitos a curto prazo, tal como o desenvolvimento do modelo probabilstico e a introduc~ao de metodos inteligentes .
O melhoramento do MEV e feito dando uma import^ancia diferente aos termos com base em deduc~oes feitas pelo modelo probabilstico ou, inclusivamente, de forma intuitiva, da a raz~ao de existirem variac~oes nas metricas de similaridade WS79].
doc. D doc. B
doc. A
doc. C Interrogação
Figura 3.2: Modelo do espaco vectorial
Na secc~ao 2.5, vimos que no nal do processo de indexac~ao obtemos uma repre-sentac~ao dos documentos atraves de pares termo/peso. Uma vez que cada termo e unico, podemos identi car um documento como um vector, em que cada elemento e o peso de cada termo. Da mesma forma, as interrogac~oes, uma vez que tambem s~ao um conjunto de termos, podem igualmente ser representadas por um vector.
Assim, representando uma interrogac~ao porQ
ie um documento por D
Captulo 3. Modelos conceptuais dos sistemas de Recuperac~ao de Informac~ao 22 de nir os vectores:
Qi = (qi1qi2:::qim)Dj = (dj1dj2:::djn) (3.1)
em que qim e o elemento do vector que representa o termo m da interrogac~ao i.
Dado que a interrogac~ao e representada por um vector, n~ao existente limitac~ao em relac~ao ao seu tamanho.
Tomando por hipotese que o espaco vectorial e linearmente independente, po-demos efectuar o calculo da proximidade entre documentos, ou entre documentos e interrogac~oes, atraves do coseno do ^angulo formado entre os dois vectores.
cos = QiDj kQikkDjk
(3.2) Sendo a norma dada por:
kDjk = q
d2
j1+
+d 2 jn = v u u t n X k=1 d2 jk
Daqui conclumos que a func~ao de similaridade traduz-se por:
sim(QiDj) =
P
nk=1qikdjk q
P
nk=1q
2
ik
q
P
nk=1d
2
jk (3.3)
Como ja referimos, a suposic~ao de que os termos s~ao independentes trata-se de uma simpli cac~ao, ja que num texto as palavras est~ao inter-relacionadas pelas frases que o constituem. No entanto, sem esta simpli cac~ao n~ao seria possvel proceder ao calculo da proximidade entre documentos pelo coseno do ^angulo formado pelos vectores representantes.
Captulo 3. Modelos conceptuais dos sistemas de Recuperac~ao de Informac~ao 23
IFD= log N
n
i
(3.4) em que N e o numero de documentos da colecc~ao en
i o numero de documentos que
cont^em o termo i.
3.5 Modelo de Aglomerac~ao
O calculo da func~ao de similaridade, realizado para o modelo do espaco vectorial, veio trazer inovac~oes no que respeita a comparac~ao dos documentos com as interrogac~oes, mas tambem na comparac~ao entre os proprios documentos. Ficando a disposic~ao uma forma de compararar documentos, ent~ao e possvel estabelecer um grau de proximidade entre eles.
3.5.1 Analise de aglomerados
A medida de associac~ao e a base da tecnica de analise de aglomerados1 que e uma
tecnica de analise estatstica multivariante, justamente para gerar categorias de elementos similares num espaco multidimensional JRSW95]. A estas categorias designamos por aglomerados2. Os elementos pertencentes a um aglomerado t^em
um grau de associac~ao maior entre eles do que em relac~ao a outro elemento de um aglomerado diferente. A analise de aglomerados pode ser encarada como uma forma de classi cac~ao automatica e tem tido bastante aceitac~ao na comunidade cient ca para alem da RI, nomeadamente na construc~ao de bibliotecas de software MBK91]. O termo classi cac~ao deve, no entanto, ser tomado com cuidado, uma vez que o processo de classi cac~ao pressup~oe a exist^encia prede nida dos grupos, o que n~ao acontece na classi cac~ao automatica, ja que os grupos s~ao criados a medida que os elementos s~ao associados.
3.5.2 Aglomerac~ao de documentos
A aplicac~ao da analise de aglomerados na RI, e utilizada na repartic~ao de docu-mentos em grupos. Cada um destes contera docudocu-mentos que ser~ao de certa forma semelhantes, pois e utilizada uma metrica de similaridade atraves da qual os docu-mentos podem ser comparados.
A divis~ao dos documentos de uma colecc~ao em conjuntos mais pequenos e de-signado por aglomerac~ao de documentos3, em que cada um possui uma relac~ao de
1
Doingl^escluster analysis. 2
Doingl^esclusters. 3
Captulo 3. Modelos conceptuais dos sistemas de Recuperac~ao de Informac~ao 24 semelhanca entre si. A aglomerac~ao de documentos e uma tecnica que e aproveitada da analise de aglomerados, sendo baseada na chamada hipotese do aglomerado. Esta hipotese a rma que documentos associados por aproximac~ao tendem a ser relevantes para os mesmos pedidos vR79]. Colocando as coisas nestes termos, um sistema de RI, baseado no modelo de aglomerac~ao, pode ser acrescido de um forte aumento em termos de e ci^encia. Basta pensar que, sendo feita a decomposic~ao de uma colecc~ao em n aglomerados, poderiamos chegar a um limite de optimizac~ao do sistema em
termos de e cacia, devolvendo ao utilizador o aglomerado de documentos que mais se aproximasse da interrogac~ao, sendo apenas necessario executar n+
t
n comparac~oes.
No entanto, e necessario tambem ter em conta a e ci^encia do sistema.
A selecc~ao do aglomerado mais promissor implica o calculo de um representan-te que conrepresentan-tera, em certa medida, toda a informac~ao necessaria a substituic~ao do aglomerado. Desta forma, e possvel executar comparac~oes entre documentos (ou interrogac~oes) e aglomerados, utilizando o seu representante, que assume a forma de um documento especial. Este representante e tambem designado por centroid, nome que deriva da forma como e calculado.
Seja D 1
:::D
j os documentos de um aglomerado e d
j1 :::d
jn o vector que
representa cada documento, o representante do aglomerado de ne-se por:
C = 1 j j X i=1 D i kD i k (3.5) em que kD
i k= q d 2 i1+ +d 2 in.
3.5.3 Metodos de aglomerac~ao
Consoante a estrutura de aglomerados que e criada, e de nido o metodo de aglo-merac~ao. A cada metodo de aglomerac~ao corresponde um algoritmo proprio que e caracterizado pela sua e ci^encia, requisitos computacionais e complexidade. A dis-truibuic~ao dos documentos, pelos aglomerados, e dependente, n~ao so pelo metodo utilizado, mas tambem pela natureza da colecc~ao. Existem dois metodos de aglo-merac~ao principais: n~ao hierarquicos e hierarquicos. Os metodos n~ao hierarquicos organizam os documentos em aglomerados numa estrutura plana. Nos metodos hierarquicos, os aglomerados s~ao criados dinamicamente, obtendo-se uma estrutura hierarquica resultante da subdivis~ao sucessiva dos documentos em aglomerados.
Metodos n~ao hierarquicos
Captulo 3. Modelos conceptuais dos sistemas de Recuperac~ao de Informac~ao 25 uma serie de par^ametros que e necessario de nir a partida, tal como o numero de aglomerados, um limite mnimo de inclus~ao de documentos nos aglomerados e a possibilidade de sobreposic~ao.
Os algoritmos dos metodos n~ao hierarquicos s~ao baseados num algoritmo deno-minado de passagem unica (APU)4, que pode ser descrito por:
1. Atribuir o primeiro objecto a um aglomerado, cando este o seu representante 2. Cada novo objecto e comparado com todos os representantes dos aglomerados
que existam na altura do processamento
3. O objecto e atribudo a um aglomerado (ou mais, caso exista sobreposic~ao) baseado numa metrica de comparac~ao
4. Calcular de novo o representante do aglomerado em que o objecto foi atribudo. 5. Se o objecto n~ao obtiver um valor mnimo de nido a partida para os
represen-tantes existentes, e atribudo a um novo aglomerado
A simplicidade deste algoritmo permite, no entanto, criar algumas variac~oes, nomeadamente na alterac~ao de par^ametros de nidos a partida, nas func~oes de com-parac~ao ou no calculo do representante.
O seu caracter iterativo leva este algoritmo a deixar que a estrutura dos aglome-rados dependa da ordem pela qual os documentos s~ao processados. Por outro lado, a sua simplicidade permite obter O(NM) em termos de desempenho onde N e o
numero de documentos e M o numero de aglomerados. Para suplantar o problema
da depend^encia da ordem pode ser utilizado um algoritmo de re-colocac~ao que e iniciado depois da estrutura de aglomerados estar concluda. O objectivo e minimi-zar os desajustes provocados pela sequ^encia em que os documentos s~ao inseridos e ter uma vis~ao mais global da estrutura, movendo os documentos para aglomerados mais similares.
Metodos hierarquicos
Nos metodos hierarquicos, a estrutura que resulta da decomposic~ao dos objectos tem a forma de uma arvore. Alem da estrutura resultante, uma diferenca fundamental entre estes metodos e os n~ao hierarquicos, e a necessidade de criar uma estrutura de dados, que albergue o grau de semelhanca entre todos os pares de documentos, denominada matriz de similaridade, o que leva a que o problema da depend^encia de ordem seja eliminada. No entanto, o tempo necessario para a gerac~ao da estru-tura hierarquica, chega a atingir O(N
2) podendo chegar a O(N
3) se for utilizado
4
Captulo 3. Modelos conceptuais dos sistemas de Recuperac~ao de Informac~ao 26 um acesso simples a matriz de similaridade. Em termos de armazenamento pode-se chegar a um aumento na ordem de O(N
2) se a matriz de similaridade for
armaze-nada em disco. N~ao sendo armazearmaze-nada em disco, a ordem de complexidade para os requisitos de armazenamento, ca em O(N), havendo, no entanto, sempre a
ne-cessidade de re-calcular a matriz que tem requisitos em termos de tempo deO(N 2)
Voo86, FBY92].
Existem varios metodos de aglomerac~ao hierarquica Bur95] que se distinguem, principalmente, pelo metodo de associac~ao feita na altura de aglomerac~ao dos do-cumentos. Todos eles se baseiam no seguinte algortmo:
1. Identi car os dois pontos mais proximos e agrupa-los num aglomerado 2. Identi car e agrupar os dois pontos mais proximos seguintes, tomando os novos
aglomerados como pontos.
A matriz de similaridade e de vital import^ancia, pois contem valores numericos resultantes de uma func~ao de comparac~ao entre todos os pares de documentos. Em cada iterac~ao do algoritmo, o objectivo e calcular o maior dos valores da matriz, sendo o par de documentos associado a esse valor combinado num aglomerado, baseado num valor limite pre-de nido. A estrutura e formada de forma natural pela associac~ao sucessiva entre documentos ou documentos e aglomerados ja existentes.
3.6 Avaliac~ao de sistemas de RI
Apos a observac~ao dos modelos da RI e das tecnicas a eles associados, e necessario um metodo que permita a comparac~ao dessas tecnicas ou de outras propostas, de forma absoluta, em termos de e ci^encia e e cacia. Esta secc~ao descreve a forma como deve ser feita esta avaliac~ao, a m de se obterem resultados que permitam tirar conclus~oes concretas acerca da validade de novas alterac~oes introduzidas.
3.6.1 Eci^encia
Em relac~ao a e ci^encia, pretende-se medir da forma mais rigorosa possvel os tempos de execuc~ao dos algoritmos e a variac~ao no incremento do espaco ocupado pelas bases de dados. No caso concreto, do presente trabalho, dadas as cactersticas distribudas do sistema, s~ao, ainda, analisados os tempos de propagac~ao dos dados pela rede.
3.6.2 Ecacia
Captulo 3. Modelos conceptuais dos sistemas de Recuperac~ao de Informac~ao 27 A quest~ao coloca-se em de nir aquilo que e relev^ancia. Sera que o conceito de relev^ancia e id^entico para toda a gente? A partida, quem procura sabe aquilo que pretende, mas este pressuposto pode variar, quando alguem quer analisar o que outra pessoa pretende. Mais difcil, se torna quando e uma maquina a realizar essa tarefa. Daa complexidade inerente as tecnologias da RI. Antes de qualquer tecnica milagrosa para resolver o problema da procura de informac~ao, o seu sucesso depende de quem formula a pesquisa e a forma como o faz. O utilizador deve, antes de mais, ser sensvel na criac~ao da sua interrogac~ao e traduzir de forma clara o que pretende. Este contexto, leva-nos a concluir que o melhor metodo para a avaliac~ao de um sistema seria o proprio utilizador. E evidente, que este processo de avaliac~ao torna-se dispendioso em termos de implementac~ao, necessitando de um acrescimo de recursos logisticos, que nem sempre s~ao faceis de concretizar. N~ao so se torna complexa a aquisic~ao das opini~oes, como se torna impraticavel a sua comparac~ao, pela natureza divergente de conceitos sobre os temas de pesquisa por parte dos utilizadores.
Colocando de parte esta perspectiva, resta a avaliac~ao atraves da simulac~ao por computador. Para que isso seja possvel e necessario:
1. Colecc~oes de documentos, e um conjunto de interrogac~oes pre-estabelecidas e para as quais s~ao ja conhecidos os documentos relevantes
2. Uma medida de qualidade, baseada nos dados disponveis nas colecc~oes de documentos.
O processo de avaliac~ao decorre, tendo em conta, para cada interrogac~ao, quais os documentos relevantes devolvidos pelo sistema, que existem no conjunto de do-cumentos relevantes ja de nidos para essa mesma interrogac~ao.
3.6.3 Colecc~oes de teste
As colecc~oes de teste constituem um dos principais meios para a avaliac~ao de sistemas de RI. Apesar de serem um metodo um pouco arti cal, a sua utilizac~ao permite a comparac~ao entre os varios sistemas, ou variac~oes nos par^ametros das tecnicas a um nvel laboratorial. De modo algum, as colecc~oes de teste traduzem condic~oes reais dos sistemas. As dimens~oes dos documentos e das interrogac~oes, podem n~ao condizer com a realidade. Por outro lado, o conjunto de documentos relevantes que fazem parte das colecc~oes de teste, s~ao fruto do trabalho de um indivduo (ou grupo) e, para o qual, n~ao ha garantias de que a sua opini~ao acerca da relev^ancia dos documentos seja universal.
Captulo 3. Modelos conceptuais dos sistemas de Recuperac~ao de Informac~ao 28 acerca do espaco poupado com as tecnicas de indexac~ao. A informac~ao qualitativa, permite a a avaliac~ao do sistema em termos de e cacia. Entre estas caractersticas, destacam-se:
1. O numero total de documentos 2. O tamanho dos documentos. 3. O assunto a que se refere
4. O tamanho e a quantidade de interrogac~oes
5. A quantidade de documentos relevantes para cada interrogac~ao e a sua iden-ti cac~ao
3.6.4 Precis~ao e totalidade
Uma utilizac~ao generica de um sistema de pesquisa de informac~ao tem em vista, por parte do utilizador, um conjunto limitado de documentos. Dentro desse conjunto, e possvel identi car quais os documentos relevantes e n~ao relevantes para o seu pedido. O objectivo de um sistema e maximizar a quantidade de documentos relevantes devolvidos dentro do conjunto total de documentos. Com base nestes dados podemos de nir precis~ao e totalidade da seguinte forma:
Relevantes N~ao Relevantes
Devolvidos r n;r n
N~ao devolvidos R;r N ;n;R+r N ;n
R N ;R N
Tabela 3.1: Declarac~ao de variaveis para a de nic~ao de precis~ao e totalidade Sendo P a precis~ao e T a totalidade a sua de nic~ao e feita da seguinte forma:
P = r
n T =
r
R (3.6)
Captulo 3. Modelos conceptuais dos sistemas de Recuperac~ao de Informac~ao 29 uma interrogac~ao em curvas de precis~ao-totalidade (P-T), em que cada ponto pode ser calculado estipulando um nvel de refer^encia, como por exemplo, o numero de documentos devolvidos, ou ent~ao em valores standard de totalidade.
3.6.5 Metodos para o calculo da curva media
As curvas P-T s~ao calculadas em relac~ao a cada uma das interrogac~oes. Para se efectuar o calculo do desempenho global do sistema, e necessario utilizar um esquema de interpolac~ao das varias curvas. Das tecnicas mais conhecidas destacam-se vR79]:
Micro-avaliac~ao
Macro-avaliac~ao.
A primeira baseia-se no calculo do somatorio das variaveis intervenientes nas formulas de precis~ao e totalidade em cada nvel pretendido. Esta tecnica e utilizada quando se pretende calcular os valores de precis~ao e totalidade para um determinado nvel. ConsiderandoSo conjunto de pedidos eo nvel pretendido, podemos de nir
para o conjunto S:
R= X s2S R s (3.7) n = X s2S n s (3.8) r = X s2S r s (3.9)
Podemos agora calcular os valores da totalidade e precis~ao no nvel :
T = X s2S r R (3.10) P = X s2S r n (3.11)
Captulo 3. Modelos conceptuais dos sistemas de Recuperac~ao de Informac~ao 30 Assumindo que corresponde ao nvel de documentos relevantes devolvidos (tal
como no caso da micro-avaliac~ao) e s e uma interrogac~ao pertencente a totalidade
das interrogac~oes S, a precis~ao em cada valor xo de totalidade e dado por:
G
s = ( T
s P
s) (3.12)
P
s(
T) = fsupP :T 0
T ^(T 0
P)2G s
g (3.13)
Para calcular a media em todos os pontos xos:
P(T) = X
s2S P
s( T)
jSj
(3.14) Por outras palavras, a precis~ao e de nida num ponto xo de totalidade com o valor maximo em cada par com totalidade maior que o nvel pretendido.
Estes s~ao alguns dos metodos utilizados para a avaliac~ao de um sistema de RI. Quer por comparac~ao dos valores de precis~ao e totalidade para um determinado
Captulo 4
Sistema de Indexac~ao e
Aglomerac~ao Distribuda (
SInAD)
Este captulo e dedicado a descric~ao da plataforma que foi desenvolvida conjun-tamente com a investigac~ao sobre a classicac~ao automatica e indexac~ao de
infor-mac~ao. E feita uma sucinta abordagem ao estado actual dos sistemas de RI, s~ao descritas ainda as raz~oes que levaram a criac~ao de um sistema de raiz, e ainda fei-to o desenvolvimenfei-to que conduziu a selecc~ao dos modelos conceptuais que foram considerados mais adequados para que fosse possvel a melhor optimizac~ao para a concretizac~ao dos objectivos propostos, procedendo de seguida a descric~ao dos as-pectos de implementac~ao referentes a escolha das tecnicas utilizadas e tambem ao nvel de optimizac~oes algortmicas.
O sistema foi construdo para a validac~ao e experimentac~ao das tecnicas aqui apresentadas e teve em vista a optimizac~ao dos processos de calculo. A sua utili-zac~ao tem como base a criac~ao de um banco de testes. Pretens~oes para tornar a aplicac~ao um utilitario, apenas necessitaria de uma ligeira a nac~ao da exibilidade na modi cac~ao dos par^ametros das tecnicas de RI, da criac~ao de uma fachada de interface mais interactivo e da sua interligac~ao a um navegador automatico daWWW.
Isto porque o objectivo aplicacional da ferramenta tem em vista a indexac~ao de paginas da WWW, situac~ao esta que foi ja simulada com sucesso, requisitando assim
apenas pequenas alterac~oes a nvel do codigo para o seu funcionamento perfeito.
4.1 Sistemas disponveis
Existem actualmente a disponibilidade dos investigadores de RI, alguns programas que fornecem infraestruturas para o teste e experimentac~ao das tecnicas de RI. S~ao exemplo o smart Buc85],o inquery CCH92] e ookapi RWHB+93]. As grandes
vantagens na utilizac~ao deste tipo de sistemas s~ao a exibilidade, versatibilidade,