2018
UNIVERSIDADE DE LISBOA FACULDADE DE CIÊNCIAS DEPARTAMENTO DE INFORMÁTICA
A Deep Dive Into Embedding Algorithms For Secure
Network Virtualization
João Manuel Marques Paulino
Mestrado em Segurança Informática
Dissertação orientada por:
Agradecimentos
Ao longo deste ano muitos foram aqueles que, de uma forma ou outra, me ajudaram a atingir mais este objectivo na minha vida. Uns foram essenciais no desenvolvimento do trabalho, outros tiveram um maior impacto na motivac¸˜ao e garantiram que a mesma se mantinha em alta.
Em primeiro lugar, gostaria de agradecer ao meu orientador, o Professor Doutor Fer-nando Manuel Valente Ramos, por me ter acompanhado ao longo deste trabalho. O bom ambiente de trabalho permitiu que as discuss˜oes fossem produtivas, facilitando a con-clus˜ao do mesmo. Ainda relacionado com trabalho, quero tamb´em deixar um agradeci-mento ao Max Alaluna, pois foi quase como outro orientador para mim. As constantes discuss˜oes e a disponibilidade apresentada para qualquer d´uvida que tivesse mostraram-se esmostraram-senciais para o avanc¸o do projecto. Aproveito tamb´em para agradecer ao projecto SUPERCLOUD, onde esta dissertac¸˜ao esteve inserida.
Agradec¸o tamb´em `a minha fam´ılia, que me apoiou do in´ıcio ao fim, e sempre acreditou nas minhas capacidades. Foi tamb´em grac¸as a eles que pude estudar e chegar a este ponto, e seguramente que facilitaram todo o meu trajecto at´e aqui.
Deixo um grande agradecimento `a minha namorada, por toda a paciˆencia que teve para os altos e baixos que ocorreram ao longo deste per´ıodo, e por estar sempre presente quando mais necessitava. Nunca me deixou desistir e fez-me sempre acreditar. Obrigado. Ao pessoal da sala 34, um grande obrigado, por todos os momentos que pass´amos juntos e pela amizade que desenvolvemos. Foi um conv´ıvio di´ario ao longo de um ano, muitas gargalhadas e muito desespero, mas no fim atingimos todos os nossos objectivos, e espero que no futuro esta amizade se mantenha.
Por fim, um grande obrigado a todos os que, de alguma forma, fazem parte da minha vida e me ajudaram a evoluir pessoalmente e profissionalmente.
Resumo
Numa era em que os ambientes em nuvem s˜ao cada vez mais importantes no dia-a-dia dos utilizadores, e tendo em conta a quantidade de dados que tˆem que ser armazenados, melhorar o rendimento dos centros de dados ´e imperativo para a evoluc¸˜ao dos mesmos. Para tal, existe uma necessidade de reduzir custos operacionais, atrav´es de uma melhor taxa de utilizac¸˜ao de recursos. Foi a partir desta necessidade que surgiu a virtualizac¸˜ao. Inicialmente utilizada em servidores, esta tecnologia permite a criac¸˜ao de uma camada de abstrac¸˜ao que permite a partilha dos recursos f´ısicos por diversos sistemas virtuais. Esta partilha apenas ´e poss´ıvel porque a maioria dos sistemas n˜ao utiliza os recursos na totalidade, levando a aumentos de eficiˆencia.
A virtualizac¸˜ao de servidores ´e uma tecnologia muito utilizada em centros de dados para possibilitar uma melhor taxa de utilizac¸˜ao de recursos e, consequentemente, um custo operacional menor. Em grande parte, esta reduc¸˜ao deve-se `a possibilidade de executar diversas m´aquinas virtuais, com diferentes servic¸os, num mesmo servidor, em detrimento da utilizac¸˜ao de servidores dedicados.
Apesar da evoluc¸˜ao desta tecnologia nas ´ultimas d´ecadas, at´e recentemente apenas era poss´ıvel virtualizar um computador, e n˜ao uma rede de computadores. A possibili-dade de virtualizar redes s´o se materializou com a introduc¸˜ao de um novo paradigma: as redes definidas por software (SDN, da sigla inglesa). Este tipo de redes destaca-se pela dissociac¸˜ao entre o plano de controlo e o plano de dados. O plano de controlo cont´em uma entidade logicamente centralizada, o controlador, que tem uma vis˜ao global de toda a rede e ´e respons´avel por toda a l´ogica de controlo.
Num ambiente de virtualizac¸˜ao de redes, as redes virtuais s˜ao consideradas a entidade base, sendo cada uma composta por um conjunto de n´os e ligac¸˜oes virtuais que, juntos, formam a topologia da rede. A rede virtual ´e mapeada no substrato f´ısico, podendo ser considerada um subconjunto do mesmo. No entanto, devido `as limitac¸˜oes dos recursos, o mapeamento deve ser feito de forma optimizada, para maximizar a utilizac¸˜ao dos mesmos. O problema de mapear de forma optimizada as redes virtuais na rede substrato ´e designado por Virtual Network Embedding (VNE).
Existem v´arias formas de resolver este problema. A mais tradicional considera ape-nas as capacidades dos elementos da rede para decidir em que recurso f´ısico mapear cada recurso virtual. Por exemplo, consideremos dois n´os f´ısicos, com capacidade de CPU de
20 e 30 unidades, respectivamente. Na soluc¸˜ao tradicional, um recurso virtual que re-quer 10 unidades de CPU vai ser mapeado no segundo n´o f´ısico, pois ´e o que tem maior capacidade dispon´ıvel. No entanto, esta soluc¸˜ao pode n˜ao ser ´otima em m´ultiplos con-textos, pois podem existir outros requisitos a ter em conta. Por exemplo, se quisermos poupar energia, ´e normalmente melhor usar ao m´aximo os recursos existentes. Das diver-sas soluc¸˜oes propostas at´e `a data, umas focam-se em garantir uma melhor qualidade de servic¸o, enquanto outras tentam maximizar o ganho do provedor da infraestrutura f´ısica.
Ao contr´ario da maior parte do trabalho relacionado, o foco desta tese ´e a seguranc¸a dos recursos virtuais. A nossa motivac¸˜ao ´e o facto de uma rede virtual estar sempre ex-posta a falhas, quer benignas, como por exemplo um n´o f´ısico ir abaixo, quer malignas, como no caso de existir interferˆencia externa numa tentativa de corromper o servic¸o. Al´em da seguranc¸a dos recursos, consideramos tamb´em a disponibilidade, nomeada-mente a possibilidade de uma rede virtual pedir o mapeamento de recursos adicionais, que servem de redundˆancia, para o caso de existirem falhas nos recursos prim´arios. A primeira contribuic¸˜ao desta dissertac¸˜ao ´e um estudo comparativo do desempenho de di-versas soluc¸˜oes para este problema. Para tal, abstra´ımos as v´arias soluc¸˜oes atrav´es de uma func¸˜ao utilidade, que permite escolher os n´os f´ısicos mais adequados a cada n´o virtual, sempre com o objectivo de escolher o n´o “mais barato”. Quanto maior a quantidade de recursos exigidos, maior o custo de mapeamento do n´o. A utilizac¸˜ao de diversas func¸˜oes utilidade, que utilizam diferentes factores no momento da escolha do n´o mais adequado, permitiu-nos fazer um estudo transversal, considerando m´ultiplas soluc¸˜oes.
A maior parte dos algoritmos de VNE com interesse pr´atico s˜ao do tipo online. Estes algoritmos assumem que os pedidos chegam de uma forma dinˆamica e aleat´oria. No entanto, identific´amos um problema comum nestas soluc¸˜oes. Este est´a relacionado com a fragmentac¸˜ao da rede substrato, causada pelas constantes mudanc¸as na mesma, devido `a chegada e partida de redes virtuais. Uma rede fragmentada ´e uma rede cuja utilizac¸˜ao dos recursos n˜ao ´e homog´enea, ou seja, uns s˜ao sobreutilizados e outros n˜ao tˆem utilizac¸˜ao, levando a uma utilizac¸˜ao n˜ao ideal dos recursos.
A segunda contribuic¸˜ao desta dissertac¸˜ao procura reduzir o impacto da fragmentac¸˜ao na qualidade de servic¸o das redes virtuais. A nossa proposta ´e um mecanismo de reconfigurac¸˜ao que comec¸a por ordenar as redes virtuais mapeadas segundo alguns crit´erios e que, de se-guida, as remapeia na rede substrato. Seguimos trˆes abordagens para a ordenac¸˜ao: ordem crescente de tamanho da rede, ordem decrescente de tempo de vida da rede, e ordem crescente de chegada `a rede. O algoritmo de mapeamento ´e sempre o mesmo durante a reconfigurac¸˜ao. O objectivo ´e reduzir o tamanho m´edio dos percursos entre os dois n´os do substrato onde s˜ao mapeados os n´os virtuais. Desta forma, a latˆencia na comunicac¸˜ao vai ser menor, o que contribui para uma melhoria na qualidade de servic¸o.
Para avaliar as v´arias soluc¸˜oes, fizemos simulac¸˜oes em larga escala. Os resultados obtidos mostram que a heur´ıstica baseada numa func¸˜ao utilidade que considera n˜ao s´o
os recursos f´ısicos (CPU e BW), mas tamb´em os requisitos de seguranc¸a e disponibili-dade, ´e consistentemente a que apresenta uma melhor taxa de aceitac¸˜ao de redes virtuais, bem como um custo inferior, para todos os ambientes de teste criados. Neste estudo, conclu´ımos tamb´em que a disponibilidade ´e um requisito mais caro do que a seguranc¸a, no sentido em que leva a taxas de aceitac¸˜ao inferiores. As nossas experiˆencias permitem ainda concluir que a reconfigurac¸˜ao permite atingir os objectivos desejados: o tamanho m´edio dos percursos usados do substrato diminui.
O foco no mapeamento dos n´os seguido pela maior parte do trabalho relacionado le-vou a que existam boas soluc¸˜oes para esse problema. No entanto, negligenciou a pesquisa de soluc¸˜oes para o mapeamento de ligac¸˜oes. Posto isto, como trabalho futuro, seria in-teressante pesquisar novas heur´ısticas para este problema, de forma a optimizar todo o processo de mapeamento de redes virtuais. Para al´em disto, os bons resultados obtidos com o mecanismo de reconfigurac¸˜ao mostram que o mesmo tem potencial, mas precisa de ser melhorado para que tenha uma influˆencia positiva tamb´em na taxa de aceitac¸˜ao. Al´em disso, deve considerar ainda como vari´avel adicional o custo da migrac¸˜ao, algo n˜ao considerado nesta tese.
Palavras-chave: Virtualizac¸˜ao de redes; Seguranc¸a em Redes; Reconfigurac¸˜ao; Mapeamento de Redes Virtuais; Redes Definidas por Software
Abstract
Network virtualization is a technique that aims to improve resource utilization in data-center and cloud environments by enabling multiple virtual networks to run over the same physical infrastructure. Yet, since traditional network infrastructures have limitations, namely the coupling of control and data planes, network virtualization was not possible until recently. The emergence of Software Defined Networks, a new paradigm that de-couples control and data planes, has enabled network virtualization. By using a logically centralized controller with a global view of the network architecture, it became possible to decouple the virtual networks from the physical infrastructure.
Of the various challenges in network virtualization, this work focuses on efficient resource allocation, which affects scalability, resource utilization, and profitability for the infrastructure provider. In order to maximize profitability, resource utilization has to be maximized. Towards that goal, virtual resources have to be mapped to the substrate network in an optimal way. This problem is known as Virtual Network Embedding. There are several approaches for solving VNE: both optimal and heuristics. As optimal solutions are only feasible for small instances of the problem, heuristic or meta-heuristic approaches are needed for large scale, practical networks. Most VNE solutions only consider capacity requirements, like bandwidth or CPU, and neglect other factors, such as security and availability.
In this dissertation we provide two major contributions. The first is a comparative study of several heuristics for VNE that consider security and dependability requirements. The idea is to compare these solutions in terms of acceptance ratio (that translates into revenue) and embedding cost. The second contribution is a reconfiguration mechanism proposed to deal with the fragmentation caused by the constant arrival and departure of virtual networks. The main goal of the reconfiguration mechanism is to reduce the average substrate path length between virtual nodes.
Keywords: Network Virtualization; Virtual Network Embedding; Dynamic Reconfiguration; Security and Dependability.
Contents
List of Figures xv
List of Tables xvii
1 Introduction 1
1.1 Virtual Network Embedding . . . 3
1.2 Context: SUPERCLOUD . . . 3
1.3 Motivation . . . 5
1.4 Goals and Contributions . . . 5
1.5 Structure of the document . . . 6
2 Related Work 9 2.1 Network Virtualization . . . 9
2.1.1 Software Defined Networks . . . 12
2.1.2 Flowvisor . . . 13
2.1.3 OpenVirteX . . . 14
2.1.4 NVP . . . 16
2.1.5 Multi-cloud network virtualization . . . 17
2.2 Virtual Network Embedding . . . 19
2.2.1 Existing solutions . . . 23
2.3 Summary . . . 28
3 Secure Virtual Network Embedding using Periodic Reconfiguration 31 3.1 Problem Description . . . 32
3.2 Network Model . . . 32
3.3 Secure VNE Heuristic Algorithms . . . 34
3.4 Periodic Reconfiguration . . . 40 3.5 Implementation Details . . . 42 4 Evaluation 45 4.1 Simulation Setup . . . 45 4.2 Experiments . . . 46 xi
4.3 Results . . . 48 4.3.1 Embedding Heuristics . . . 48 4.3.2 Reconfiguration Mechanism . . . 50 4.4 Discussion . . . 51 5 Conclusion 55 5.1 Future Work . . . 56 Bibliography 63 xii
List of Figures
1.1 Simplified SDN architecture . . . 2
1.2 SUPERCLOUDconcept . . . 4
2.1 Network Virtualization Environment . . . 10
2.2 Software Defined Network Architecture . . . 12
2.3 FlowVisor operation . . . 14
2.4 OVX system architecture . . . 15
2.5 Architecture of NVP . . . 16
2.6 Multi-tenant multi-cloud network virtualization architecture . . . 18
2.7 Example of an embedding of two Virtual Network Requests in a Substrate Network . . . 20
3.1 Example of a virtual network request being embedded onto a multi-cloud substrate network. . . 33
3.2 Sorting algorithms: Example . . . 40
4.1 Acceptance Ratio and Cost Values for Heuristics . . . 49
4.2 Acceptance Ratio and Cost Values for Utility Functions . . . 50 4.3 Acceptance Ratio and Average Path Length for Reconfiguration Procedures 51
List of Tables
4.1 Notation for the node mapping heuristics under evaluation. . . 47 4.2 Security and Dependability Requirements for the experiments. . . 47 4.3 Reconfiguration Scenarios. . . 48
Chapter 1
Introduction
Virtualization is a technology that allows the execution of several systems, or virtual ma-chines, in the same physical machine. This technology leads to better resource utilization and, consequently, lower operational costs. Similarly, network virtualization has been proposed as a solution for the lack of flexibility in the Internet infrastructure. However, its materialization has proved more difficult [1].
The idea behind network virtualization is to have multiple virtual networks, imple-mented and managed independently, coexisting in the same physical infrastructure. Net-work virtualization leads to potential changes in the Internet business model, with the Internet Service Provider (ISP) no longer playing a major role. Instead, we can now have two entities with distinct objectives. The Infrastructure Provider (InP), responsible for providing and maintaining the underlying physical infrastructure, and for managing the distribution of its resources among the several Service Providers (SPs). These are respon-sible for deploying and managing virtual networks using resources leased from the InP, which will supply end users with multiple services.
A virtual network (VN) is composed of a set of virtual nodes that, when connected by virtual links, form a virtual topology. When a VN is mapped on the substrate network, virtual nodes are allocated to substrate nodes and virtual links are allocated to substrate paths. This allocation, however, has to be performed efficiently, in order to maximize the number of coexisting virtual networks and, consequently, increase the InP’s profit.
As any new technology, network virtualization has its goals and challenges. Design goals can be seen as a set of criteria that is required to perform network virtualization. One of those goals is flexibility, which is not attainable in traditional networking infras-tructures, mainly due to its vertical integration and slow pace of innovation. One of the major causes for this lack of flexibility is the fact that most components are proprietary and specialized, with the control and data planes tightly coupled inside closed equipment.
Chapter 1. Introduction 2
Game Changer: Software Defined Networks
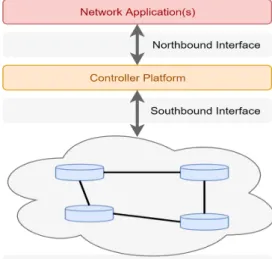
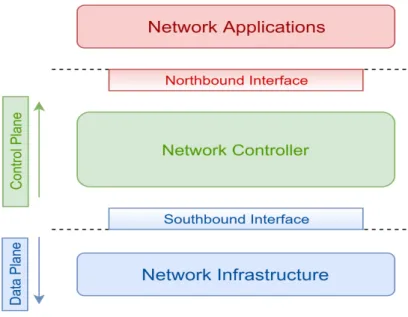
Software Defined Networking (SDN) has proved to be the key to enable network vir-tualization. A base principle of SDN is the decoupling of the control and data planes, which breaks the vertical integration issue. With this separation a new entity emerges: the SDN controller. The communication between the controller and the forwarding ele-ments is done using a protocol, commonly known as the southbound interface. The most commonly used is OpenFlow [2]. SDN facilitates network management by breaking the control problem into smaller instances, making it easier to create abstractions in the net-work. Besides the decoupling of the planes, which removes all control logic away from forwarding elements, this new architecture is comprised of three other key principles [3].
Figure 1.1: Simplified SDN architecture
The first is the way forwarding decisions are made. In traditional networking, forward-ing decisions are destination based, while in SDN forwardforward-ing is flow based. In destination based forwarding, the decision is coarse-grained, based only on the destination address header. All packets with that destination will follow the same path in order to reach it. As for flow based forwarding, packets from the same flow will use the same path to reach their destination. Using sessions, packets from different sources can be assigned to the same packet stream and, therefore, belong to the same flow. The second consists on mov-ing all control logic to a centralized controller, which has a centralized, abstract network view, that facilitates the programming of forwarding devices. Finally, the third principle is network programmability, achieved through software applications running on top of the controller. This is considered to be one of the major values of SDNs.
SDN has enabled cloud-scale network virtualization. Some examples include VMWare NVP/NSX [4], Google’s Andromeda [5], and Microsoft’s Azure [6].
Chapter 1. Introduction 3
1.1
Virtual Network Embedding
In this thesis we focus on one of the main algorithmic challenges of network virtualiza-tion: how to efficiently allocate resources. As mentioned earlier, a virtual network (VN) is composed of nodes and links. In order to be functional, each component of the VN has to be mapped on a working component of the underlying substrate network. This mapping is known as the Virtual Network Embedding (VNE) problem, and is extremely important since it has a direct impact on the performance of the virtual networks and the revenue of the InP. However, this problem is NP-hard [7], which means that exact solutions can only be found for small instances of the problem. Hence, new approaches have to be devised to obtain scalable solutions, including heuristic and meta-heuristic approaches.
The VNE problem consists in the mapping of a virtual network to a substrate network, while ensuring all requirements are satisfied. Although it is usually solved with the goal of maximizing revenue for the InP, it can also take into account other objectives, such as QoS-compliance or survivability. It is important to define specifically the objective of the embedding, since that is what defines the requirements made by the users. For example, QoS-compliance may focus on latency requirements, whereas survivability may target the prevention of service disruption upon failure of substrate resources. As VN requests arrive to the system, this problem can be tackled in two ways. In an off-line manner, where every request is known in advance, as well as the order of arrival, which is not a realistic scenario. Or in an on-line manner, where there is no knowledge of future requests, and these arrive arbitrarily to the system. We consider the second scenario, the on-line VNE problem.
One typical way to simplify the problem is to divide it into two sub-problems: virtual node mapping and virtual link mapping. As the name suggests, each phase is responsible for mapping one of the two main components of the network. Node mapping has to be solved first, because the link mapping phase requires its output to choose the most suitable path. However, there are different ways to coordinate both phases, which affect the final result. The mapping result also depends on the requirements made in the requests, which are specified by the owner of the virtual network. Basically, more requirements increase the cost that it entails. A request is rejected when the substrate network cannot comply with the requirements of the request. The goal is therefore to maximize the acceptance ratio.
1.2
Context: SUPERCLOUD
This dissertation work is integrated in the SUPERCLOUD project [8], which aims to support user-centric deployments across multi-clouds, enabling the composition of inno-vative trustworthy services, to uplift Europe’s innovation capacity and thus improve its competitiveness. SUPERCLOUD goal was to build a security management architecture
Chapter 1. Introduction 4
and infrastructure to fulfill the vision of user-centric secure and dependable clouds-of-clouds.
The starting point of the project is cloud computing. Cloud computing has evolved ex-tensively over the past decade [9] but, although it has revolutionized fundamental aspects of our daily lives (such as health care, financial systems, scientific research, and others), it has limitations. Namely, as critical applications move to the cloud, the requirements with respect to availability and security become crucial. The fact that cloud computing is typically limited to a single administrative domain is one of the main causes of the problem.
SUPERCLOUDproposes to extend the cloud computing paradigm to a multi-cloud: a substrate composed of both public cloud resources and private clouds. This provides several benefits. One of them is locality, which allows a client to connect to the near-est data center in order to obtain the lownear-est latency and highnear-est bandwidth. In addition, by migrating their virtual resources, users can also take advantage of price variation in providers, and lower their costs [10]. The existence of several providers also improves availability, since resources replicated at different providers are more likely to fail inde-pendently than if they are from the same provider. Private clouds could also be used to store sensitive workloads, leading to an increase in security, taking advantage of public resources to perform less sensitive operations, in order to avoid overloading the private cloud resources.
Despite all of its advantages, deploying such a service is difficult, due to the lack of cloud interoperability. For instance, the use of different hypervisors means that not all virtual machine image formats are the same. As a result, user applications and cloud users find themselves locked-in to a specific cloud provider.
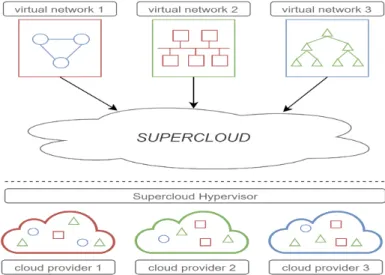
Figure 1.2: SUPERCLOUD concept
prob-Chapter 1. Introduction 5
lem previously described, it uses some form of nested virtualization [11]. With this tech-nique, the SUPERCLOUD hypervisor runs on top of the cloud hypervisor, handling all resources and offering a common abstraction.
Figure 1.2 represents the SUPERCLOUD concept. We can observe the existence of the SUPERCLOUDhypervisor, which is the entity that deals with the heterogeneity between traditional cloud providers, providing a multi-cloud abstraction. The figure also illustrates the use of resources from different providers when creating the networks for the end-users. In this work we explore the SUPERCLOUD model to improve the security and avail-ability of virtual networks.
1.3
Motivation
There are many solutions for the VNE problem [7], that cover a wide range of goals and objectives, from profit maximization to energy efficiency. Some also include availability requirements, but few consider security, and none considers a multi-cloud environment. However, when moving their workloads to the cloud, the tenants expect guarantees in terms of both security and availability. In this respect, the multi-cloud environment we consider enables the extension of networking services with these additional requirements. This is particularly relevant at a moment when the number of cloud incidents that affect the availability of the service and even the security of its workload is growing. This allows the Supercloud provider to assure the user that, in the event of a substrate failure, malicious or not, the service is not disrupted.
To our knowledge, only one solution considers both security and dependability re-quirements in the VNE problem. This solution, proposed in [12] and improved in [13], uses a MILP formulation to find optimal embeddings, which is a setback in terms of scal-ability. As a result, the solution only works for small instances of the problem, due to its long execution times. This motivates us to study heuristic solutions to the problem.
Another problem is related to the dynamics in the arrival and departure of virtual networks. As VNs enter and leave the substrate network, fragmentation of resources may occur, which can lead to QoS issues. In particular, as the substrate is fragmented, path lengths1 tend to increase, leading to increased service latencies. The length of the path
affects the quality of service, since the communication delay is directly proportional.
1.4
Goals and Contributions
In this dissertation we study several heuristics for the secure and dependable VNE prob-lem that are scalable and efficient, i.e., that work for large networks and achieve a good
Chapter 1. Introduction 6
acceptance ratio. Our goal is to compare existing solutions in terms of acceptance ratio, embedding cost, and resource utilization, to understand the trade-offs.
We also argue that reconfiguration of the network can help reduce the fragmentation problem and lead to smaller path lengths when mapping virtual networks. We consider a reconfiguration performed periodically, with every embedded network being remapped on the substrate network, according to some order. Our goal is to devise a reconfigu-ration solution that aims to increase the quality of service by reducing the length of the paths where virtual links are mapped to. We also investigate if reconfiguration affects the acceptance ratio.
The contributions made in this work can be summarized as follows:
• Implementation of various heuristics for VNE, including solutions that consider se-curity and dependability requirements in virtual networks, followed by simulations for comparison, in terms of acceptance ratio and embedding cost.
• Proposal of a new abstraction for VNE algorithms, the utility function, and explo-ration of various such functions to this problem, with the goal of understanding how each variable affects the outcome of the embedding.
• Development of a reconfiguration mechanism to overcome fragmentation of the substrate network, including the design and implementation of three heuristics, fol-lowed by simulations to evaluate their performance.
In short, the results show that the heuristics based on utility function that considers security perform better in our scenario, and with a lower embedding cost. The results also show that periodic reconfiguration decreases the path length, without affecting the accep-tance ratio of the embedding algorithms. The best results were obtained when requests were sorted by network size, possibly as a consequence of better resource distribution.
All the code developed during this work is open-source and available in a github repository2.
1.5
Structure of the document
This document is organized as follows:
• In chapter 2, we introduce the state-of-the-art in network virtualization and virtual network embedding. Most of the virtualization solutions follow the SDN paradigm. As for VNE solutions, we point out those that are in some way related to ours, i.e. those that deal with the on-line embedding problem, with security and dependability requirements, or the dynamic VNE problem.
Chapter 1. Introduction 7
• Chapter 3 begins with an analysis of the problems we tackle in this dissertation. Then, we describe the models used for the substrate network and the virtual net-works, followed by an explanation of each of the embedding heuristics imple-mented. Finally, we present our reconfiguration solution.
• Chapter 4 describes the experiments used to evaluate all solutions and the results obtained. We also present a discussion on the results and whether or not they met our expectations.
• The final chapter contains our conclusions on the produced work and some ideas for future work.
Chapter 2
Related Work
In this chapter, we present the state-of-the-art on network virtualization, in Section 2.1. We also introduce the SDN paradigm, that made possible the full decoupling of the virtual network from the substrate network, and present several SDN-based virtualization plat-forms. On Section 2.2 we describe the VNE problem, and various approaches to solve it.
2.1
Network Virtualization
Network virtualization has been proposed as a solution for the ossification problem of the Internet infrastructure. This ossification was mainly caused by the lack of incentives for Internet Service Providers (ISP) to change their networks. The main idea is to allow the coexistence of several virtual networks on the same physical substrate. This concept, however, is not new in networking.
Namely, Virtual Area Networks (VLAN) have existed for a long time. VLANs allow a set of logically connected hosts to share a single L2 broadcast domain. They facilitate network management and configuration, since no new physical connections are necessary when a host wants to change to another VLAN, for instance. Another example are Virtual Private Networks (VPN). A VPN is a sophisticated technology, consisting of a dedicated network connecting multiple hosts in different locations, using secure tunnels.
These network virtualization primitives are important, but they do not allow the full decoupling of the virtual network from the physical substrate. Overlay networks, on the other hand, allow the creation of logical networks running on top of one or more existing networks, but with the limitation of being implemented in the application layer, i.e., on top of IP.
As network virtualization allows multiple virtual networks to run in the same sub-strate, the business model also changes, with the division of the Internet Service Provider (ISP) role in two distinct ones: Infrastructure Provider (InP) and Service Provider (SP). The first is responsible for managing the physical infrastructure, which contains resources
Chapter 2. Related Work 10
that will be leased by SPs, in order to create and deploy virtual networks. This is the whole idea of network virtualization: to allow multiple SPs to create multiple heterogeneous vir-tual networks that coexist in isolation in the same substrate network.
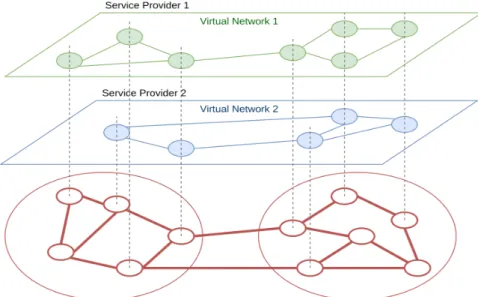
Figure 2.1 illustrates a Network Virtualization Environment (NVE). The basic en-tity of such an environment is the virtual network, which is composed of virtual nodes connected by virtual links. Virtual topologies can be seen as a subset of the underlying network topology, since virtual resources are mapped into the substrate ones. Typically, a virtual node is mapped on a single physical node, while a virtual link is mapped on a physical path. Virtual networks can serve as resource providers for other virtual networks, with the lowest layer composed of physical resources. Also, as the figure shows, a virtual network is managed and operated by a single SP, but it can lease resources from several InPs.
Figure 2.1: Network Virtualization Environment
Four architectural principles make the ground for network virtualization. Coexistence is a key part of an NVE, as it considers the possibility of having multiple VNs from different SPs running on top of the same underlying physical network. Recursion and Inheritanceare related to the possibility of a VN parenting another VN, i.e. a VN func-tioning as the underlying network that leases resources. When this happens, the child VN can inherit some attributes of the parent VN. Finally, Revisitation is what allows a single substrate node to host multiple virtual nodes of the same VN. This last principle is usually discarded in survivable VNE solutions that consider dependability requirements, due to the fate sharing principle.
There is some sort of consensus on the set of design goals that need to be fulfilled in order to realize network virtualization. Some of the most important are: flexibility,
Chapter 2. Related Work 11
scalability, isolation, programmability, heterogeneity, and legacy support. Flexibility al-lows SPs to implement virtual networks swiftly, without affecting other networks, both underlying (physical) or coexisting (virtual). Scalability and isolation are related with the coexistence of multiple networks, in the sense that the underlying network must be capable to cope with three major issues: the growth of coexisting VNs, faults in VNs, and faults in the substrate network. Programmability is key for flexibility and manage-ability, since it is what allows SPs to implement customized protocols and deploy diverse services. The underlying network is usually heterogeneous so that VNs are not restricted to a given technology, and are able to support heterogeneous protocols and algorithms. As for the provided services, they must take into account the variety of end-user devices. Finally, providing backward capability is considered key for deploying the technology.
Besides the goals mentioned atop, researchers have stumbled across several challenges for network virtualization [14], some of which are described below.
• Interfacing - InPs must provide an interface, through which SPs can communicate and express their requirements.
• Resource and Topology Discovery - InPs must be able to determine the topologies of the networks they manage, as well as instantiate cross-domain virtual links. • Admission Control and Usage Policing - InPs have to ensure they can deliver the
guaranteed performance without exceeding the allocated resources.
• Naming and Addressing - Decoupling naming and addressing would enable any end-user to move from one SP to another with a single identity, instead of being connected to multiple VNs.
• Mobility Management - Finding the exact location of any device at a particular moment, and routing packets accordingly, is another complex issue.
• Security and Privacy - Isolation between coexisting VNs is not sufficient for threats, intrusions, and attacks to both physical and virtual networks.
• Resource Allocation - Efficient allocation of resources is very important for the InP, as it maximizes the number of accepted VNs and, therefore, the utilization of the resources and the InP’s revenue. This is the problem we address in this thesis. Until recently, these challenges were not met, mainly due to the inflexibility of tradi-tional network architectures. With the advent of a new networking paradigm - Software Defined Networking [3] - it was finally possible to develop full network virtualization solutions that completely decouple the virtual networks from the substrate. As such, we continue this Section with an introduction to the SDN paradigm in section 2.1.1, and then present the network virtualization platforms enabled by SDN. The first was FlowVisor,
Chapter 2. Related Work 12
presented in Section 2.1.2, followed by OVX is Section 2.1.3. NVP, the first production quality platform (from VMware) is presented in Section 2.1.4. Finally, in Section 2.1.5, we present Sirius, a multi-cloud network virtualization platform that is the target of our work.
2.1.1
Software Defined Networks
Software Defined Networking [3] [15] is a new technology that led to a change in the networking paradigm. SDN is based on four key ideas. First, the control and data planes are decoupled, meaning that switches no longer have any control logic, becoming simple forwarding elements. All control logic is moved to the controller, which is a logically centralized entity that has an overall network view and is able to provide the required abstractions for programming the network. This centralization also makes it easier and faster to respond to problems in the network. In SDN, forwarding decisions are based on flows, and are no longer tied to restrictive destination based forwarding. Finally, the network is programmable through software applications running on top of the controller. This last characteristic is considered as the main contribution of SDN. Programmability provides higher flexibility for implementing network policies, and gives the possibility of changing them dynamically, as the network state changes.
Figure 2.2: Software Defined Network Architecture
Figure 2.2 presents a high level view of the SDN architecture. An SDN architecture is composed of three layers, which can be decomposed in sub-layers. The first layer corre-sponds to the data plane, the network infrastructure. While similar to that of a traditional network (switches, routers, etc.), it differs on the fact that its elements are now simple for-warding elements without (or with minimal) control logic. The second layer is the control
Chapter 2. Related Work 13
plane, that consists of the controller. The controller is responsible for generating the net-work configuration based on the policies defined by the netnet-work operator. The final layer are the network applications. These implement the control logic (routing, access control, load balancing, etc.) that will define the behavior of the forwarding devices.
As illustrated in the figure, two interfaces exist in the SDN architecture. The south-bound API serves as the communication bridge between the controller and the forwarding elements, being crucial in the separation between the planes. The main protocol used as this interface is OpenFlow. The northbound interface is used as a communication bridge between the controller and the network applications. There is not yet a main standard for this interface.
With SDN, networks become easier to manage and control. By moving the control logic to a centralized controller, the forwarding elements do not need to be so complex, meaning that cheaper hardware can be used. This has been key to scale cloud computing infrastructures [16].
2.1.2
Flowvisor
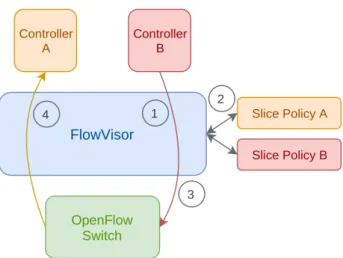
In [17], the authors propose the first platform that virtualizes SDNs. In Flowvisor the same hardware forwarding plane can be shared by multiple logical networks, each with distinct forwarding logic. This is achieved by means of an abstraction similar to the one used in computer virtualization, which permits slicing and sharing of resources among guest operating systems. By having such an abstraction layer, multiple heterogeneous networks are able to run simultaneously on top of the same physical hardware, without interfering with each other.
FlowVisor works as an hypervisor that builds on OpenFlow [2] and acts as a transpar-ent proxy between the forwarding hardware and the tenant controllers (Figure 2.3). Each controller is given an isolated slice of the network, that it is able to observe and control. There are four primary slicing dimensions of hardware resources. The first is topology, with each slice having its own view of network resources and their connectivity. Then, bandwidth and CPU, with each slice having its own fraction within each link and node, respectively. Failing to perform this isolation could contribute to outside interference on a slice’s performance, which would be undesirable. Finally, each slice has a limited amount of possible forwarding rules.
Figure 2.3 depicts FlowVisor operation. When a controller wants to communicate with a switch, it sends a message, which is intercepted by FlowVisor (step 1). Then, after checking the user’s slicing policy (step 2), FlowVisor rewrites the message to enable control of only the tenant’s slice of the network (step 3). This third step is done in a transparent way to the tenant’s controller. As for messages sent by switches, FlowVisor only checks if they match the user’s slicing policy and forwards them to the controller (step 4).
Chapter 2. Related Work 14
Figure 2.3: FlowVisor operation
FlowVisor was designed with three main goals: transparency, isolation and extensible slice definition. First, virtualization should be transparent to the networking hardware and to the controllers. This transparency allows a controller to operate in the virtual network as if it was directly in the real network. By decoupling the network virtualization technology from the controller design, it allows independent updates and improvements, i.e., more flexibility. Implementing isolation between slices is fundamental, since a slice should never be able to drain other slice’s resources. Finally, it is crucial that slicing policies are flexible, extensible, and modular.
2.1.3
OpenVirteX
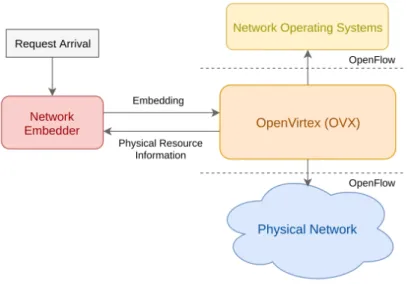
OpenVirteX (OVX) [18] is a network virtualization platform based on FlowVisor. As such, it enables the creation and operation of virtual Software Defined Networks (vSDNs). In addition, this platform provides address virtualization, and topology virtualization to allow tenants to choose arbitrary topologies. As such, unlike FlowVisor, OVX provides each tenant with a fully virtualized network featuring an arbitrary topology, stated by the tenant, and a full header space.
Figure 2.4 represents the architecture of OVX, which follows the same proxy-based approach as Flowvisor. Its operation is as follows. Upon receiving a virtual network request, the network embedder finds a mapping between the virtual network and the sub-strate. For this purpose, it inquires the hypervisor about the state of the physical network, and sends the embedding solution. Then, the hypervisor instantiates the virtual network into the physical network. The authors do not propose a new embedding algorithm, they leverage on existing embedding solutions, and focus on materializing network virtualiza-tion.
phys-Chapter 2. Related Work 15
Figure 2.4: OVX system architecture
ical network elements, which is the main goal of network virtualization. By making each virtual element just a pointer to a physical one, runtime modification is possible. To enable topology virtualization, OVX interprets LLDP messages1. This way, OVX exposes these
virtual topologies by sending fake LLDP messages to the controller in order to create the illusion of virtual links. Since OVX allows address virtualization, differentiation between hosts needs to be performed differently from FlowVisor (which does not allow the same addresses to be used in different virtual networks). The proposed solution is to generate globally unique IDs for tenants, and then, for each host, to generate a physical address encoded with the tenant’s ID. Depending on the virtualization layer, either IP (layer 3) or MAC (layer 2) addresses are used for the physical address. Collision avoidance is achieved as a consequence of the installation of flow rules at the edge switches of the network. Finally, control function virtualization is realized by allowing multiple control planes to control the same substrate, similar to FlowVisor. In terms of virtual topologies, the only restriction imposed by OVX is that physical switches cannot be partitioned into multiple virtual switches.
The possibility of mapping several virtual components into a single physical compo-nents reflects the extensibility provided by OVX, which provides great flexibility on how this mapping can be done. This flexibility is a key factor to SDN, because it allows topol-ogy customization, node and link resiliency, and dynamic reconfiguration of networks.
1LLDP or Link Layer Discovery Protocol is a link layer protocol used by network devices for advertising
Chapter 2. Related Work 16
2.1.4
NVP
In [4], the authors present NVP, a network virtualization platform for multi-tenant dat-acenters (MTD), that is the base of VMware NSX service. An MTD has a set of hosts connected by a physical network, and each host has multiple virtual machines that are sup-ported by the host’s hypervisor. This hypervisor contains a software switch (OVS [19]) that is responsible for forwarding received messages to another local VM or to another hypervisor, through the physical network.
The NVP architecture, Figure 2.5, is based on SDN, and is built around a network hypervisor that provides two network virtualization abstractions: control abstraction and packet abstraction. With the control abstraction, tenants are able to define a set of logi-cal network elements that can be configured as if they were physilogi-cal elements, forming a virtual topology. As for the packet abstraction, it allows packets sent by endpoints to use the same services as they would in the tenant’s home network. These abstractions are provided by logical datapaths, which are implemented in virtual switches on each host. Host-hypervisors are connected through tunnels, so the physical network does not see more than ordinary IP traffic, generated by the network hypervisor. However, these tunnels can only effectively implement point-to-point communication. In order to allow packet replication, for broadcast and multicast services, NVP relies on services nodes. These are additional physical forwarding elements that compose a multicast overlay. In addition, gateway appliances are used to connect a tenant’s virtual networks with the phys-ical network. As said above, NVP makes use of a logphys-ically centralized SDN controller that is responsible for managing the forwarding state of all elements.
Figure 2.5: Architecture of NVP
Two main challenges that had to be dealt by NVP: the need for fast software switching and the scalability of the controller cluster. The first is achieved with the use of traffic
Chapter 2. Related Work 17
locality, i.e. the fact that all packets belonging to a single flow will traverse the same set of flow entries. This is done as follows. Since OVS is composed by a kernel module and a userspace program, the kernel module can send the first packet of each flow to userspace, where it is matched against the full flow table as many times as required. Then, the userspace program installs exact-match flows into a flow table in the kernel, which contains a match for every flow. This way, future packets in the same flow can be matched by the kernel, allowing faster processing. The second challenge is solved by dividing computation into two layers, with each layer being composed of a cluster of processes running on multiple controllers. The first layer consists of logical controllers that compute the flows and tunnels needed to implement logical datapaths. The second layer consists of physical controllers which are responsible for communicating with hypervisors, gateways, and service nodes. This way, the logical controller can avoid location-specific details, which reduces the complexity of the forwarding state computation.
2.1.5
Multi-cloud network virtualization
NVP and OVX give cloud providers the opportunity to extend their models with the offer of complete network virtualization, by providing tenants with the freedom to specify the network topologies and addressing schemes of their choosing, while guaranteeing the required level of isolation between them. Despite this, they are confined to datacenters controlled by a single cloud operator, which can be considered a major limitation since many critical applications are being moved to the cloud.
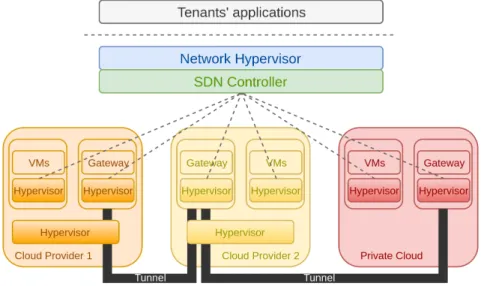
In [20], Alaluna et al. propose a network virtualization platform that supports the creation of virtual networks that span across several datacenters, which may belong to different cloud providers, both public and private. Utilizing several cloud providers is possible due to the addition of a new network layer above the existing cloud hypervisor. Besides hiding the heterogeneity of the resources, this new layer also provides the neces-sary level of control over the whole network, including setting up the links that connect the VMs to enable network virtualization. This multi-cloud network virtualization is the main target of our work. The embedding solutions we investigate in this thesis are to be included as part of the embedding module of this platform.
Adopting a multi-provider architecture provides three important advantages. First, it allows tenants to spread their services across several providers, thus being immune to availability issues caused by cloud or datacenter outages. Second, users can take advan-tage of the existence of multiple providers and different pricing plans to find the most profitable solutions. Another advantage is the possibility of increasing performance by bringing services closer to clients.
The heterogeneity that the use of multiple clouds entails influences both the level of network visibility and the type of configurations that can be made. Consequently, this af-fects the kind of services and guarantees that can be assured. To enable flexible topologies
Chapter 2. Related Work 18
with both software and hardware switching elements, the proposed hypervisor fulfills two requirements. First, it has remote and flexible control over all network elements. Second, it provides full network virtualization, including both topology and address abstractions. It also provides user isolation at two levels: a user does not know another user is sharing the network resources, and the actions of a user must not affect the network behavior of other users.
Figure 2.6: Multi-tenant multi-cloud network virtualization architecture
Figure 2.6 represents the proposed network virtualization architecture. Clouds are connected by tunnels established by special VMs called gateways. In order to minimize the number of tunnels, the authors build a minimum spanning tree. Every tenant can have a different set of applications, and all applications run on top of the network hypervisor.
To fulfill the first requirement referred above, network control, the authors use dif-ferent technologies, for each type of cloud. In public clouds, since the platform cannot access the cloud hypervisor, an additional virtualization layer is created on top of it, in or-der to provide virtualization between tenants. Each virtual machine contains a computer hypervisor (Docker is used), and each hypervisor contains a software switch (OVS [19]) for the data plane. As for private clouds, they can use the same technique or place the hypervisor in a bare metal server.
To fulfill the second requirement, the network hypervisor needs to guarantee isolation between tenants, while providing address and topology abstraction. Isolation is achieved through the interception of flows, and flow rule redefinition, at the edge. Address virtu-alization is obtained by tagging all traffic that originates from tenant VMs, and topology abstraction is achieved through a network embedding process (not specified).
As a summary, none of the network virtualization solutions presented in this section have considered the problem of network embedding, the core of our thesis. We turn to this problem next.
Chapter 2. Related Work 19
2.2
Virtual Network Embedding
Network virtualization could serve as the foundation of a future Internet that allows ser-vice providers to offer customized end-to-end serser-vices over a common physical infras-tructure, which is managed by an Infrastructure Provider (InP). Since the infrastructure is shared, having an effective virtual network embedding (VNE) algorithm is extremely important in order to make an efficient use of the substrate resources.
The VNE problem consists on the efficient mapping of virtual resources onto the sub-strate ones. Formally, the VNE problem can be described as follows. A subsub-strate network is composed of a set of substrate nodes and a set of substrate links. A virtual network request is composed of a set of virtual nodes and a set of virtual links. Substrate resources have capacity values and virtual resources have demand values. Then, there are two func-tions: the virtual node mapping function and the virtual link mapping function. Basically, these functions assign virtual resources to substrate resources based on verification: a vir-tual resource is only suitable to be mapped onto a substrate resource if its demand is lower or equal to the capacity of the destination.
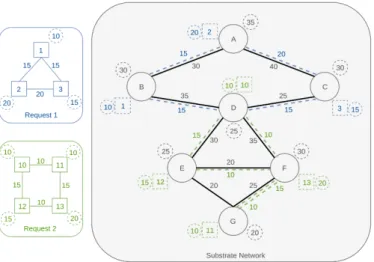
Figure 2.7 shows an example of the embedding of two virtual networks onto a sub-strate. Consider the two requests in the figure. Request 1 contains three nodes {1,2,3} that demand 10, 20 and 15 units of CPU, respectively. Node 1 is connected to node 2 and node 3 by two links that demand 15 units of bandwidth each, and node 2 is connected to node 3 by a link that demands 20 units of bandwidth. As for request 2, it is composed of four nodes {10,11,12,13} that demand 10, 10, 15, and 20 units of CPU, respectively. There are four links connecting the nodes, with links {10,11} and {12,13} demanding 10 units of bandwidth, and links {10,12} and {11,13} demanding 15 units. The substrate network, on which these two requests will be embedded, is composed of seven nodes and nine links. Nodes are represented by circles, and their respective CPU capacity is represented by the smaller dashed circles. As for physical links, they are represented by the thicker lines, and their respective bandwidth capacity is represented by the inner grey values. In this example, we consider that substrate resources only have to meet CPU and bandwidth requirements, but there is a wider set of possible constraints that can be considered.
Before beginning the mapping process, one has to choose how to prioritize resource allocation. In this case, we sort resources by demand in descending order, meaning that nodes with higher CPU demand will be mapped first. With this in mind, we will now describe the embedding of request 1, since the procedure is identical in both cases.
The first node to be dealt with is node 2, since it has the highest CPU demand. After picking the virtual node, the algorithm checks which of all substrate nodes has the highest CPU capacity and enough bandwidth in its adjacent links, to embed it. In this case, it is node A and, therefore, virtual node 2 is mapped onto substrate node A. The next node to be mapped is node 3. Node A is no longer the one with the highest capacity (in fact, in most algorithms this node would not be available, since two nodes from the same virtual
Chapter 2. Related Work 20
network usually cannot be mapped onto the same substrate node). There are now three nodes with the same CPU capacity {B,C,F}. Virtual node 3 is mapped on substrate node C (maybe because it is closer to node A than node F, and this is also considered in some algorithms, and has a higher bandwidth capacity than node B). Due to proximity again, virtual node 1 is mapped onto substrate node B.
Figure 2.7: Example of an embedding of two Virtual Network Requests in a Substrate Network
As mentioned, and is clear from this example, since virtual networks consist of a set of nodes and a set of links, the VNE problem is usually divided into two sub-problems: virtual node mapping (VNoM) and virtual link mapping (VLiM). In the node mapping phase, each virtual node is allocated to a physical node. Two nodes from the same virtual network usually cannot be mapped to the same substrate node. The link mapping phase receives as input the output from VNoM, since nodes are required to form a link. Here, a virtual link is mapped onto a physical path, i.e. a set of physical links that connect the substrate nodes that correspond to the end nodes of the virtual link.
Variants and constraints
There are several variants to the VNE problem, characterized by specific constraints. Each constraint leads to different classes of algorithms, which we can use to classify VNE approaches.
The first constraint considers the requirement of modification or relocation of virtual resources upon necessity. Considering this, VNE approaches can be classified as static or dynamic. While most solutions handle requests as they arrive, static solutions do not pro-vide the possibility of remapping in order to improve the performance of the embedding. A remapping, or relocation, is necessary when one of the following occurs: fragmentation of substrate resources, changes in the virtual network, or changes in the substrate network.
Chapter 2. Related Work 21
Dynamic approaches try to reconfigure the requests in order to reorganize resource allo-cation and optimize the utilization of the resources. Virtual Network Reconfiguration, proposed in [21], is an example of a reactive and iterative algorithm that improves the rejection rate and load balance in the substrate network.
The second constraint is related with the way the algorithm is solved. Here, VNE algorithms can fit into one of two categories: centralized or distributed. In a centralized approach the embedding is performed by a single entity. The main advantage of such solutions is that the mapping entity is always aware of the state of the network, which facilitates optimal embeddings. On the other hand, a single entity is a single point of fail-ure, thus being a less robust solution. Also, scalability problems can arise since there is a limit on the number of requests it can perform on its own. These two problems are dealt with distributed solutions, which use multiple entities to perform the embeddings. How-ever, the required synchronization between the mapping entities generates extra overhead, since each node needs to receive sufficient information about the network state.
The third, and final constraint, concerns failures in the substrate. In a concise ap-proach the embedding uses only the resources needed to meet the demands of the virtual networks without backups. This means that failure recovery cannot be guaranteed, but on the other hand more virtual networks can be mapped on the unused resources. A redun-dantapproach reserves additional resources to be used to recover from failures. This type of approach usually comes with a cost for the provider, which is expected to be be passed on to the customer, since the use of more substrate resources leads to a lower amount of mapped virtual networks in the substrate network. Redundancy can be achieved for either nodes or links, or both.
Coordination
In order to get optimal VNE solutions, coordination between the node and link mapping phases is fundamental. When embedding across several InPs the problem can be further decomposed in a set of IntraInP problems, i.e. a set of embeddings within each InP. There are three possibilities to approach the coordination problem: uncoordinated VNE, where each sub-problem is solved in an isolated and independent way; coordinated VNE, which can be solved in either one or two stages; and InterInP coordination, that aims to split the requests in different sub-requests, and finds the most adequate InP to map each of them.
• Uncoordinated VNE
The lack of coordination implies that the solution is obtained in two different stages. An approach without coordination is presented in [22]. The main goal is to max-imize the long-term average revenue. In the first stage, VNoM is solved using a greedy algorithm that chooses a set of eligible substrate nodes. From this set only one is chosen, being the choice based on the amount of available resources. As for
Chapter 2. Related Work 22
the second stage, VLiM can be solved using the k-shortest path algorithm, or using an MCF (multi-commodity flow) approach. One of the cutbacks of the lack of co-ordination is the possibility of neighboring virtual nodes being widely separated in the substrate topology, which can result in cost increase and performance penalties. • One stage coordinated VNE
In this approach, virtual links are mapped at the same time as virtual nodes. Upon mapping the first two nodes, the virtual link between them is also mapped, and the procedure repeats as each new virtual node is mapped. In [23], Cheng et al. pro-pose an approach for this variant, where the position of a node inside the topology is one of its most important parameters. These types of attributes, known as topo-logical node attributes, have a direct impact on the efficiency of the embedding. Taking this into account, the authors proposed a node ranking approach, based on the well-known algorithm developed by Google, that is used to measure the topol-ogy incidence of a node. By incorporating topoltopol-ogy attributes in node mapping, the acceptance ratio and link mapping efficiency are improved.
• Two stage coordinated VNE
In [24] and [25], Chowdhury et al. propose an approach that follows two stage coor-dination. Its main objective is to minimize the embedding cost. They also consider new constraints that aim at avoiding the neighbor separation problem in uncoor-dinated VNE. The node mapping stage starts with the creation of an augmented graph, introducing a set of meta-nodes, one for each node. Each meta-node is con-nected to a cluster of candidate substrate nodes that fulfill the constraints allowing coordination of the two stages. VNoM is then solved using a Mixed Integer Linear Programming formulation, with the main goal of minimizing the embedding cost. They also propose the relaxation of linear program variables, in order to avoid NP-completeness. Finally, virtual nodes are mapped to substrate nodes by rounding the solution in a deterministic (D-ViNE) or random (R-ViNE) way. VLiM is performed using MCF.
• InterInP coordination
The previously mentioned variants consider the VNE problem in the single-InP scenario. However, there is the case where a VNR has to be mapped on top of a set of substrate networks managed by different InPs, with each InP able to embed parts of the virtual network and which are then interconnected using InterInP links. In order to minimize the cost of embedding, the SP divides the requests into sub-requests and maps each of them in the most convenient substrate network, using one of the previous IntraInP algorithms. A good example of this type of approach is described in [26].
Chapter 2. Related Work 23
Possible approaches
VNE is an NP-hard problem. As such, finding optimal solutions in reasonable time is only possible for small instances of the problem. Due to this fact, heuristic approaches had to be developed, in order to find non-optimal solutions that scale to larger networks [7]. Solutions for VNE can thus be exact, heuristic, or meta-heuristic.
• Exact solutions
These propose optimal techniques to solve small instances of the problem. They are also used to create baseline solutions that represent an optimal bound for heuristic-based solutions. Usually these are achieved using Integer Linear Programming (ILP) or Mixed Integer Linear Programming (MILP). Even though most solutions implemented using this technology are considered NP-complete, there are some algorithms that solve the problem in reasonable time, which are implemented in software tools, called solvers, like GLPK [27] or CPLEX [28]. Examples of exact algorithms can be found in [29] and [30]. The first aims to minimize the embed-ding cost and maximize the acceptance ratio, while the second focuses on energy efficiency by embedding VNs in a small set of equipment and switching off the remaining resources of the substrate network.
• Heuristic solutions
These are algorithms that try to find an acceptable solution in a short execution time. This aspect is crucial for VNE, in order to allow network virtualization to scale. An example for this type of approach is presented in [31], where a backtracking algorithm is proposed based on a subgraph isomorphism search method. Basically, whenever a bad mapping decision is made, the algorithm backtracks to the last valid mapping, which according to the authors is more effective than following the two stage approach. The main limitation of this approach is that algorithms usually stop in a local-optimal solution which can be distant from the optimal solution.
• Metaheuristic solutions
This approach tries to find a near-optimal solution by improving a candidate solu-tion with regard to a given measure of quality, using techniques such as simulated annealing [32], genetic algorithms [33] or particle swarm optimization [34].
2.2.1
Existing solutions
Due to its intractability, researchers have proposed several solutions that try to reduce the problem, by restricting the problem space, and in this way enable efficient heuristics. Others have focused on dependability, as any substrate is always vulnerable to failures. In order to maintain virtual networks operational in those cases, the InP must reserve backup
Chapter 2. Related Work 24
resources that will be used upon failure of the working ones. Other classes of solutions include other objectives, such as energy-efficiency, quality of service, etc. In this section we look at some of the solutions to the VNE problem proposed in the literature.
Traditional Solutions
One of the first attempts at solving the VNE problem, with and without reconfiguration, is introduced in [29]. The basic approach for VN assignment is to consider node stress optimization and link stress optimization as two sub-problems. However, this causes link stress to be ordinarily high as a result of the distance between mapped nodes. With this in mind, the authors propose an approach that tries to optimize both simultaneously. For that, a 3-step approach is proposed. The first step consists on the selection of the cluster center, i.e., the substrate node with the highest number of low stressed neighbor nodes and low stressed links connecting them. The second step consists on the selection of the rest of the substrate nodes for the VN request. In this selection, both node stress and link stress are considered. Finally, the last step is the substrate path selection, where the selected substrate nodes are connected based on the virtual topology.
As previously mentioned, the arrival and departure of virtual networks causes network conditions to change over time. This may lead to inefficient use of substrate resources, as some might be overloaded and others unused: in other words, the network is frag-mented. With reconfiguration, the authors expect to deal with fragmentation by removing virtual components from bottleneck substrate resources, and migrating them to less busy ones. However, since they consider it to be an expensive operation, the authors decided to reconfigure only part of the VNs.
To choose which VNs are worth reconfiguring, the algorithm begins by sorting VNs by criticality level. This is set by the stress level of the substrate resources on which the VN is mapped. The authors set a reconfiguration threshold which can be 0 (zero) or 1. If set to 0, then only maximum stressed resources are considered critical. If set to 1, then all substrate resources are considered critical. If a VN is using critical resources it is marked as suitable for reconfiguration. This marking scheme is executed periodically, which means that each time it is executed different sets of critical VNs are selected. As for the reconfiguration itself, VNs periodically check if they are marked, and in case they are selected they stop operating and are re-mapped using the first algorithm.
The solution proposed in [29] is computationally expensive. In [22], Yu et al. try to simplify the problem by considering a substrate network that is multi-path capable. As such, it became possible to map a single virtual link onto multiple substrate paths, increasing the acceptance ratio. This is only possible due to the flexibility of substrate paths, which can be split without disrupting link properties. The virtual link mapping can now be solved with MCF, making it more tractable. Also, the substrate network can periodically re-optimize the mapping of virtual links (by selecting new paths or adapting
Chapter 2. Related Work 25
the splitting ratio), in order to increase the possibility of acceptance of future requests. The algorithm proposed uses batch processing for all requests within a given time window, and prioritizes revenue: the requests are sorted by decreasing order of revenue, to maximize this metric. The first phase uses a greedy algorithm phase to map nodes on the substrate network, while the others return to the queue to be processed later. In the second phase, virtual links are mapped using MCF or shortest paths (k-shortest path), making efficient usage of the substrate’s bandwidth and leaving more resources available. Path splitting is a technique that enables better resource utilization by harnessing the small pieces of available bandwidth, allowing the substrate to accept more VN requests. As explained, this flexible splitting reduces the link embedding problem to the multi-commodity flow problem, which can be solved in polynomial time. Also, it brings other advantages of using multiple paths, such as load balancing and reliability, besides allow-ing faster recovery from network failures. However, this technique may cause packets to arrive out-of-order. This can be solved using hash-based path splitting, to enforce all packets from the same flow to use the same path.
The authors also propose path migration to deal with the on-line VNE problem. The authors follow an approach on which the substrate network balances itself in order to accept a request, by mapping a virtual link to a different substrate path without chang-ing node mappchang-ing. Done periodically, this allows switchchang-ing from the on-line problem to the off-line problem, since a large collection of requests can be handled together. While migration does not cause service disruption, it introduces a considerable amount of over-head, considering that new paths have to be established, and traffic has to be moved to the new paths. For this reason, migration should only be performed for virtual networks that are expected to have a long time-to-live.
Topology-aware VNE
Earlier VNE solutions used mainly CPU and bandwidth as metrics to choose the most suitable node for the embedding problem, without considering the topological attributes of the virtual networks and the substrate network.
One problem of the original VNE solution, identified in [35], is this disregard of the substrate topology. They claim that including topology-awareness, alongside re-optimization mechanisms, can improve both the acceptance ratio and load balancing.
Towards that goal, this article makes two contributions. First, it proposes a mecha-nism to discriminate substrate resources based on their importance in the network. This differentiation is achieved by assigning weights to substrate nodes and links according to their importance in the substrate topology. This weight, called the scaling factor, is related with the likelihood of that resource becoming a bottleneck, and it consists of two factors: a critical index and a popularity index. A resource is considered critical if its unavailability largely affects the operation of a large part of the substrate network, while