José Pedro Machado Cunha
Column-Based Databases: Estudo exploratório
no âmbito das Bases de Dados NoSQL
José Pedro Machado Cunha
outubro de 2015 UMinho | 2015 Column-Based Dat abases: Es tudo e xplor atór io
no âmbito das Bases de Dados NoSQL
Universidade do Minho
Escola de Engenharia
outubro de 2015
Dissertação de Mestrado
Ciclo de Estudos Integrados Conducentes ao Grau de
Mestre em Engenharia e Gestão de Sistemas de Informação
Trabalho efectuado sob a orientação do
Professor Doutor José Luís Mota Pereira
José Pedro Machado Cunha
Column-Based Databases: Estudo exploratório
no âmbito das Bases de Dados NoSQL
Universidade do Minho
Escola de Engenharia
v
Agradecimentos
Esta secção do documento destina-se a agradecer a todos aqueles que estiveram presentes ao longo da elaboração desta dissertação assim como de todo o meu percurso académico. Foram cinco anos de trabalho e dedicação, nos quais foi necessário ultrapassar uma série de dificuldades e contratempos de forma a atingir os objetivos traçados, em que a presença e apoio daqueles que me são mais próximos foi fundamental e contribuiu para que esta etapa pudesse ser concluída, assim como para o meu crescimento pessoal e académico. Quero por isso deixar o meu profundo agradecimento aos meus pais, pelo esforço que fizeram para me poderem proporcionar um curso superior e pelo apoio e incentivo que me deram ao longo de todo o curso.
Agradeço também a todos os meus colegas de curso, com quem compartilhei várias experiências, em especial ao Pedro Matos, Rui Rocha, André Braga, David Baía e Marco Rodrigues que ao longo destes cinco anos foram verdadeiros companheiros de caminhada e que graças à entreajuda existente entre todos foi possível ultrapassar as várias dificuldade que foram surgindo.
Quero também agradecer a todos os meus professores, com quem ao longo deste percurso académico tive a possibilidade de aprender e trocar experiências. O meu agradecimento especial ao professor José Luís Pereira que me acompanhou durante todo este ano letivo, pela sua disponibilidade e por toda a motivação e apoio que me deu ao longo desta dissertação.
Por fim, quero também agradecer à minha namorada por toda compreensão, apoio e motivação dada ao longo deste ano letivo, assim como aos meus amigos, avós e familiares que estão presentes em todos os momentos da minha vida.
vii
Resumo
Depois de várias décadas de grande sucesso e bons serviços prestados às organizações, a tecnologia relacional de bases de dados tem vindo a ser desafiada por uma nova classe de tecnologias de bases de dados a que se deu a designação genérica de NoSQL (Not only SQL). Para este facto contribuíram decisivamente os recentes desenvolvimentos na área a que se tem vindo a chamar Big Data em que o aumento da quantidade de dados gerados diariamente em diversos domínios de aplicação como a Web e principalmente as redes sociais, entre outros, está atualmente na ordem das centenas de Terabytes e como tal, tendo em conta o volume e complexidade dos dados a gerir a tecnologia relacional começa a demonstrar fragilidades substanciais. Em particular, a necessidade de gerir dados cujos formatos são dificilmente acomodáveis em sistemas relacionais, dispersos por múltiplos servidores, levou ao aparecimento das ditas Bases de Dados NoSQL sendo que estas são principalmente focadas na performance permitindo o processamento de dados de forma rápida e eficiente e possuem um modelo de dados que não necessita de seguir os padrões rígidos do modelo relacional pelo que armazenam tanto dados estruturados como não estruturados.
Dentro desta nova classe de tecnologias de Bases de Dados surgiram diferentes propostas, com distintas proveniências e áreas de aplicação, vulgarmente classificadas em quatro grupos, de acordo com o seu modelo de dados: Column, Document, Key/Value e Graph-based databases, sendo que cada um destes modelos possui uma grande diversidade de propostas no mercado. Assim, e tendo em consideração que esta dissertação é focada nas bases de dados do tipo column-based foram selecionadas para análise e exploração as duas soluções desta área, que tendo em conta o seu prestígio e documentação existente, apresentam ser as mais relevantes no mercado. Essas soluções são o Cassandra e o HBase. Palavras-chave: Big Data; NoSQL; Base de Dados relacionais; Column-Based
ix
Abstract
After several decades of great success and good services to the organizations, relational databases have been challenged by a new class of database technologies, which is commonly known as NoSQL (Not only SQL). The recent developments in the area, which has been called Big Data, contributed decisively to it. In fact, the increase of data generated daily in different fields of application (such as the Web and especially social networks), is currently in the hundreds of Terabytes. Taking these facts into account and given the volume and complexity of data to manage, the relational technology began to show substantial weaknesses.
The need to handle data, whose formats are hardly accommodated in relational systems (spread across multiple servers), led to the raise of the NoSQL databases. These are mainly focused on performance, allowing the quick and efficient processing of data. These also possess data model which do not need to follow the strict standards of the “relational model”, to the extent that they allow the storage of structured and unstructured data.
Within this new class of database technologies, there have been various proposals with different backgrounds and areas of application, commonly classified into four groups, according to their data model: Column, Document, Key/Value and Graph-based databases. Each one of these models has a wide range of offers on the market. Therefore, taking into account that this dissertation is focused on Column-based databases, it was selected, for analysis and exploration, the two most relevant solutions in this area on the market today, given its prestige and existing documentation, namely Cassandra and HBase.
Key-Words: Big Data; NoSQL; relational databases; Column-Based databases; Cassandra; HBase; MySQL
x
Índice
Declaração ... iii Agradecimentos ... v Resumo ... vii Abstract ... ix Índice ... xLista de Figuras ... xiv
Lista de Tabelas ... xvi
Lista de Abreviaturas, Siglas e Acrónimos ... xvii
Capítulo 1 - Enquadramento do Trabalho Proposto ... 1
1.1. Enquadramento e Motivação ... 1
1.2. Objetivos da Dissertação e Resultados Esperados ... 2
1.3. Abordagem Metodológica ... 2
1.4. Estratégia de Revisão de Literatura ... 3
1.5. Estrutura do Documento ... 3
Capítulo 2 - Revisão de Literatura ... 5
2.1. Big Data e o aparecimento das Bases de Dados NoSQL ... 5
2.1.1. Caraterísticas das bases de dados NoSQL ... 6
2.2. Conceitos ... 8 2.2.1. Teorema CAP ... 8 Consistência ... 8 Disponibilidade ... 9 Tolerância à partição ... 9 2.2.2. Eventual Consistency ... 10 2.2.3. Modelos de distribuição ... 12
xi
2.2.3.1. Sharding ... 12
2.2.3.2. Replicação ... 13
Replicação Master-Slave ... 14
Replicação Peer-to-Peer... 14
2.2.3.3. Combinação de sharding e replicação ... 15
2.2.4. ACID VS BASE ... 16
2.2.5.MapReduce ... 17
2.3. Tipos de Bases de dados NoSQL ... 18
2.3.1. Key/Value-based ... 18
2.3.2. Document-based ... 19
2.3.3. Graph-based ... 20
2.3.4. Column-based ... 22
2.4. Bases de Dados Column-based ... 22
2.4.1. Cassandra ... 22 2.4.1.1. Modelo de Dados ... 23 2.4.1.2. Modelo de Consulta ... 25 2.4.1.3. Arquitetura do sistema ... 26 Particionamento ... 26 Consistência ... 28 Replicação ... 30
Armazenamento Físico de writes ... 32
Disponibilidade ... 32
2.4.2.HBase ... 33
2.4.2.1. Modelo de Dados ... 34
2.4.2.2. Modelo de Consulta ... 35
xii
Armazenamento Físico HBase ... 36
Sistema de Ficheiros Distribuídos Hadoop ... 37
Replicação ... 38 Consistência ... 40 2.5. Cassandra vs HBase ... 40 Capítulo 3 – Benchmarking ... 43 3.1. Descrição do dataset ... 44 3.2. Ferramentas utilizadas ... 46
3.3. Modelo de dados MySQL vs Cassandra ... 46
3.3.1. Modelo de Dados Conceptual... 48
3.3.2. Modelo Físico Base de Dados MySQL ... 49
3.3.3. Modelo de dados Cassandra ... 49
3.4. Descrição do estudo de caso ... 52
3.4.1. Ambiente de teste ... 52
3.4.2. Descrição do processo de trabalho ... 53
3.4.3. Consultas a efetuar às bases de dados ... 55
3.5. Resultados Obtidos ... 57
Capítulo 4 - Conclusões ... 69
4.1. Conclusões do trabalho realizado ... 69
4.2. Trabalho futuro ... 71
Referências ... 72
Anexos ... 75
Anexo A - Instalação do MySQL e MySQL Workbench ... 75
Anexo B - Criação e carregamento das bases de dados no MySQL ... 77
Anexo C - Instalação do Talend Open Studio for Big Data ... 83
xiii
Anexo E - Tratamento dos dados no Talend Open Studio for Big Data ... 88
Anexo F - Instalação do Cassandra ... 91
Anexo G - Criação de keyspace, tabelas e carregamento de dados no Cassandra ... 92
xiv
Lista de Figuras
Figura 1 - Teorema CAP (retirado de Silva, 2011) ... 9
Figura 2 - Combinação de sharding com replicação (retirado de P. Sadalage & Fowler, 2013) ... 15
Figura 3 - Exemplo prático da framework MapReduce (retirado de Sadalage & Fowler, 2013) ... 18
Figura 4 - Funções do MapReduce (retirado de Dean & Ghemawat, 2004) ... 18
Figura 5 - Modelo de dados de uma base de dados do tipo graph-based (retirado de Sadalage & Fowler, 2013) ... 21
Figura 6 - Estrutura de uma família de colunas do Cassandra (Sadalage & Fowler, 2013) ... 23
Figura 7 - Família de Coluna (retirado de Datastax, 2015) ... 25
Figura 8 - Estrutura de Cluster Cassandra antes e pós versão 1.2 (retirado de Datastax, 2015) ... 27
Figura 9 - Estrutura de armazenamento de writes (retirado de Datastax, 2015) ... 32
Figura 10 - Modelo de Dados HBase (retirado de Silva, 2011) ... 34
Figura 11 - Visão geral de como o HBase armazena os seus ficheiros no HDFS (retirado de Lars, 2011) ... 36
Figura 12 - Processo de Replicação HBase (retirado de HBase, 2015) ... 39
Figura 13 - Modelo de Dados Conceptual ... 48
Figura 14 - Modelo Físico de Dados MySQL ... 49
Figura 15 - Esquema da família de colunas origin_cancelled... 50
Figura 16 - Esquema da família de colunas airports_by_delay ... 51
Figura 17 - Esquema da família de colunas tail_by_time ... 52
Figura 18 - Resultados da Consulta 1 para Dados1 ... 58
Figura 19 - Resultados da Consulta 1 para Dados2 ... 59
Figura 20 - Resultados da Consulta 1 para Dados3 ... 60
Figura 21 - Resultados da Consulta 1 para Dados4 ... 60
Figura 22 - Figura 22- Visão geral dos resultados da consulta 1 ... 61
Figura 23 - Resultados da Consulta 2 para Dados1 ... 62
xv
Figura 25 - Resultados da Consulta 2 para Dados1 ... 63
Figura 26 - Resultados da Consulta 2 para Dados4 ... 63
Figura 27 - Visão geral dos resultados da consulta 2 ... 64
Figura 28 - Resultados da Consulta 3 para Dados1 ... 65
Figura 29 - Resultados da Consulta 3 para Dados2 ... 66
Figura 30 - Resultados da Consulta 3 para Dados3 ... 66
Figura 31 - Resultados da Consulta 3 para Dados4 ... 67
Figura 32 - Visão geral dos resultados da consulta 3 ... 67
Figura 33 - Execução do MySQL no terminal Ubuntu ... 76
Figura 34 - Menu inicial de Talend Open Studio for Big data ... 84
Figura 35 - Job criado no Talend para efetuar os joins às tabelas do MySQL ... 88
Figura 36 - Menu do Componente TMap ... 89
Figura 37 - Joins efetuados no componente TMap... 89
Figura 38 - Execução do job criado no Talend ... 90
Figura 39 - Execução do Cassandra no terminal do Ubuntu ... 91
Figura 40 - Adicionar library no JMeter ... 97
Figura 41 - Configuração do cluster Cassandra a utilizar ... 97
Figura 42 - Configuração da consulta a testar no Cassandra ... 98
Figura 43 - Configuração da base de dados MySQL a utilizar ... 98
Figura 44 - Configuração da consulta a testar no MySQL ... 99
xvi
Lista de Tabelas
Tabela 1 - Cassandra Vs HBase ... 41
Tabela 2 - Informação relativa aos voos ... 44
Tabela 3 - Informação relativa aos aviões ... 45
Tabela 4 - Informação relativa às companhias aéreas ... 45
xvii
Lista de Abreviaturas, Siglas e Acrónimos
ACID Atomicidade, Consistência, Isolamento, Durabilidade API Application Programming Interface
BASE Basically Available, Soft-state, Eventual consistency BSON Binary JSON
CQL Cassandra Query Language
CRM Customer Relationship Management DBMS Database Management System HDFS Hadoop Distributed File System HTTP Hypertext Transfer Protocol
IDC International Data Corporation
JSON JavaScript Object Notation NoSQL Not only SQL
RDBMS Relational Database Management System REST Representational State Transfer
SQL Structured Query Language
1
Capítulo 1 - Enquadramento do Trabalho Proposto
1.1. Enquadramento e Motivação
Tendo em conta o enorme aumento verificado da quantidade de dados gerados diariamente em diversos domínios de aplicação, atualmente a rondar as centenas de Terabytes e toda a sua complexidade levou a que a tecnologia relacional demonstrasse bastantes fragilidades no armazenamento e manuseamento dos mesmos o que levou ao aparecimento das bases de dados NoSQL. Estas caraterizam-se entre outras coisas, por processarem grandes quantidades de dados de forma rápida e eficiente, por possuírem um modelo de dados que não segue os padrões rígidos do modelo relacional, o que significa que podem armazenar vários tipos de dados sejam eles estruturados ou não estruturados, pela sua escalabilidade horizontal e por possuírem uma arquitetura distribuída tolerante a falhas que se baseia na distribuição dos dados por vários servidores de forma a garantir elevados índices de disponibilidade. Dentro desta nova classe de tecnologia de base de dados surgiram várias propostas classificadas por quatro grupos distintos, cada um com áreas de aplicação diferentes, nomeadamente, as key-value databases, document databases, column-based databases e as graph databases.
Sendo esta ainda uma área com bastante por explorar, e dada a diversidade de propostas existentes em cada um dos modelos apresentados, torna-se pertinente analisar as caraterísticas e áreas de aplicação dos mesmos. Para este projeto de dissertação foram selecionadas como alvo de estudo as bases de dados NoSQL orientadas a colunas que têm como base o projeto BigTable desenvolvido pela Google, e que foi posteriormente adaptados por várias organizações que desenvolveram as suas próprias versões. Este tipo de bases de dados são as que mais se aproximam do modelo relacional ao nível do modelo de dados e são também as mais adequadas para lidar com quantidades elevadas e complexas de dados, sendo bastante flexíveis e escaláveis. Torna-se assim importante analisar e explorar, entre as várias soluções desta área disponíveis no mercado aquelas que são consideradas mais relevantes e com maior prestígio, com base na sua utilização por parte de grandes organizações, documentação disponível e ainda referências bibliográficas.
2
1.2. Objetivos da Dissertação e Resultados Esperados
Esta dissertação pretende dar resposta a um conjunto de objetivos, nomeadamente:
Caraterizar o papel das bases de dados NoSQL no contexto do Big Data;
Caraterizar detalhadamente alguns dos produtos NoSQL mais representativos entre as Column-Based Databases;
Analisar e comparar estes produtos com base no estudo qualitativo realizado;
Explorar e analisar estes produtos com base num estudo de caso;
Identificar vantagens e desvantagens das bases de dados NoSQL relativamente às bases de dados relacionais;
Espera-se assim, inicialmente caraterizar o papel das bases de dados NoSQL no contexto do Big Data e de seguida efetuar uma análise aos produtos mais representativos entre as Column-Based databases. Com base no prestígio, na documentação existente, no número de citações em artigos científicos e na sua implementação por parte de organizações de grande dimensão foram selecionadas como alvo de estudo as bases de dados NoSQL Cassandra e HBase. Outro dos objetivos a atingir passa por, com base num estudo de caso, explorar, analisar e comparar o desempenho de uma destas ferramentas relativamente à tecnologia relacional.
1.3. Abordagem Metodológica
A abordagem metodológica a seguir durante a realização deste projeto de dissertação é do tipo exploratória que segundo (Vergara, 2005) tem como objetivo explorar uma área onde existe pouco conhecimento acumulado e sistematizado. Sendo a área das tecnologias NoSQL algo ainda tão pouco definido no que diz respeito às soluções existentes para cada tipo de base de dados NoSQL torna-se pertinente explorar as várias ofertas existentes no mercado de forma a fazer uma análise acerca do que cada uma pode oferecer e em que aspetos algumas são mais ou menos vantajosas que outras e quando comparadas com a tecnologia relacional de bases de dados, tendo como base um estudo de caso.
3
1.4. Estratégia de Revisão de Literatura
No âmbito deste projeto de dissertação foi necessário fazer uma revisão de literatura de forma a abordar as temáticas relacionadas com o tema em questão e perceber o estado atual da situação. Assim foram selecionados alguns conceitos chave a utilizar na estratégia de pesquisa em repositórios académicos e científicos como o “Google Scholar”, “B-On”, “SpringerLink”,“Web of Knowledge” e “RepositóriUM”. Os conceitos chave utilizados na pesquisa efetuada foram:
NoSQL databases Big Data ACID vs BASE Replication Sharding Column-based databases Cassandra HBase Eventual consistency
Aquando da pesquisa foram levados em conta como critério de seleção das publicações o ano de publicação dos artigos, a relevância dos mesmos de acordo com o seu número de citações e ainda em alguns casos a relevância dos autores na área.
1.5. Estrutura do Documento
Este documento encontra-se organizado segundo a seguinte ordem de capítulos:
Capítulo 1 - Enquadramento do Trabalho Proposto – este capítulo dá uma breve introdução acerca das razões que motivaram o surgimento deste projeto e que necessidades este vem suprimir. Está também presente neste capítulo a estratégia de pesquisa utilizada para redigir a revisão de literatura, quais os objetivos e resultados esperados para esta dissertação e ainda faz referência à abordagem metodológica utilizada. Para além disto este capítulo contém também a estrutura do documento. Capítulo 2 - Revisão de Literatura – este capítulo aborda as temáticas relacionadas com o projeto a desenvolver, e faz uma revisão da literatura de cada uma delas. Em primeiro lugar é abordado o surgimento das bases de dados NoSQL no contexto do Big Data sendo de seguida abordados alguns conceitos como teorema CAP, eventual consistency,
4 modelos de distribuição, ACID, BASE e Map-reduce. Posto isto é feita uma pequena análise aos quatro tipos de bases de dados NoSQL existentes nomeadamente, as key-value, as graph, as document e as column-based. Dado que este documento é referente a esta última categoria de seguida é feita uma análise às duas ferramentas consideradas como mais relevantes desta área nomeadamente o Cassandra e o HBase.
Capítulo 3 – Benchmarking – este capítulo diz respeito ao estudo de caso realizado. Contêm a descrição do dataset escolhido, as ferramentas utilizadas, os modelos de dados das bases de dados pertencentes ao estudo de caso e ainda uma descrição do mesmo. Contém também os resultados obtidos no estudo de caso
Capítulo 4 – Conclusões – Este capítulo destina-se às conclusões acerca do trabalho realizado. Aborda também o trabalho futuro a realizar de forma a complementar o trabalho realizado nesta dissertação.
5
Capítulo 2 - Revisão de Literatura
2.1. Big Data e o aparecimento das Bases de Dados NoSQL
Segundo informações fornecidas pela Intel (Intel, 2012) a população mundial criou até ao ano 2003 cinco exabytes de dados, o mesmo volume que atualmente é criado em apenas dois dias. A mesma fonte relata que em 2012 o universo digital de dados cresceu 2,72 zetabbytes verificando-se uma duplicação desse valor a cada dois anos, atingindo em 2015 os oito zetabbytes. Verifica-se assim uma grande quantidade de dados gerados atualmente provenientes de diversas fontes como redes sociais, imagens, vídeos, dispositivos móveis, documentos, aplicações de gestão, entre outros. É neste contexto que surge o termo Big Data para o qual não existe ainda uma definição que seja considerada consensual mas que é utilizado com muita frequência nos dias de hoje para descrever o exponencial crescimento do volume de dados associados a algumas áreas de negócio.
Foram assim ao longo dos anos citadas várias definições para o termo Big Data por parte de vários autores. A International Data Corporation (IDC) foi a organização pioneira no estudo do Big Data e do seu impacto, tendo em 2001 definido as tecnologias Big Data como uma nova geração de tecnologias destinadas a extrair valor de forma económica a partir de grandes volumes de dados, de vários tipos, permitindo uma alta velocidade na captura de dados e análise dos mesmos. Esta definição deu origem ao termo “4V’s” muito utilizado para caraterizar o Big Data, que faz alusão àquelas que são as suas principais caraterísticas nomeadamente volume, variedade, velocidade e valor (Gantz & Reinsel, 2011).
Também em 2001 o analista do grupo META, Doug Laney aquando de um estudo acerca dos desafios enfrentados pelas organizações na gestão dos dados definiu os desafios associados ao crescimento dos dados como tridimensionais fazendo alusão ao volume (grandes quantidades de dados), velocidade (a necessidade de captar, armazenar e analisar dados de forma rápida auxiliando assim as atividades operacionais) e variedade (capacidade de tratar de forma integrada dados com diferentes caraterísticas) (Laney, 2001). Apesar de alguns autores já terem acrescentado novas dimensões a este modelo dos “3V’s”, tais como o valor ou a veracidade, este ainda é o modelo mais utilizado na indústria para descrever o Big Data.
6 O Big Data representa assim um crescimento na complexidade dos dados, fazendo com que os sistemas de gestão de base de dados baseados no modelo relacional não tenham capacidade para os recolher, armazenar, gerir e analisar. Fazendo uma analogia comparativa entre o Big Data e os dados tradicionais, tendo como base o modelo 4V’s, pode-se verificar que desde logo o “volume” dos dados é um fator crítico para discriminar ambos, sendo que os dados tradicionais andam na ordem dos Gigabytes enquanto o Big Data, muito por culpa das redes sociais e dados gerados pela web em geral, andam atualmente na ordem das centenas de terabytes. Relativamente à “variedade”, enquanto os dados tradicionais são normalmente estruturados e encontram-se devidamente classificados e armazenados, no Big Data dada a diversidade de fontes das quais os dados podem ser provenientes podem ser identificadas diferentes estruturas de dados nomeadamente, estruturados, semiestruturados ou não estruturados. A terceira caraterística está relacionada com a alta “velocidade” com que os dados são gerados, sendo que aqui o grande desafio passa por conseguir recolhê-los e armazená-los em tempo útil de forma a maximizar o seu valor e suportar as decisões operacionais. Por último o “valor” está relacionado com a importância que a análise dos dados armazenados pode ter na tomada de decisão por parte das empresas de forma a obterem benefícios comerciais e vantagens face aos seus concorrentes (Hu et al., 2014).
Assim, neste contexto e depois de várias décadas de grande sucesso e bons serviços prestados às organizações, a tecnologia relacional de bases de dados tem vindo a ser desafiada por uma nova classe de tecnologias de bases de dados a que se deu a designação genérica de NoSQL (Not only SQL) e que surgiu devido à necessidade de processar de forma rápida todo este volume de informação derivado de diversas fontes de dados e que se apresenta em vários formatos. Dentro desta nova classe de tecnologias de Bases de Dados surgiram diferentes propostas, com distintas proveniências e áreas de aplicação, vulgarmente classificadas em quatro grupos, de acordo com o seu modelo de dados: Column-based, Document-based, Key/Value-based e Graph-based databases.
2.1. Caraterísticas das bases de dados NoSQL
O termo NoSQL foi utilizado pela primeira vez em 1998 por Carlo Strozzi ao fazer referência a uma base de dados relacional criada por si denominada “Strozzi SQL” que tinha a particularidade de não utilizar a linguagem SQL para efetuar consultas aos dados. O termo voltou a ser utilizado mais tarde em 2009 numa conferência organizada por Johan
7 Oskarsson acerca de bases de dados do tipo open-source com o nome “NoSQL meetup”, sendo que a partir daí passou a ser o termo da moda para referir bases de dados não-relacionais (Abramova et al., 2014).
Assim, a necessidade de gerir dados cujos formatos são dificilmente acomodáveis em sistemas relacionais, dispersos por múltiplos servidores, levou ao aparecimento das Bases de Dados NoSQL, sendo que estas são principalmente focadas no desempenho permitindo o processamento de dados de forma rápida e eficiente e possuem um modelo de dados que não necessita de seguir os padrões rígidos do modelo relacional, pelo que armazenam tanto dados estruturados como não-estruturados. Esta ausência de esquema permite adicionar campos aos registos da base de dados sem que antes tenham que ser feitas alterações na estrutura da mesma. No entanto, ao contrário do modelo relacional, as bases de dados NoSQL não suportam consultas aos dados armazenados através da linguagem SQL. Contudo esta abordagem permite facilmente armazenar e recuperar os dados de forma rápida e eficiente independentemente da sua estrutura e conteúdo (Leavitt, 2010). De forma a evitar a perda de dados, as bases de dados NoSQL possuem uma arquitetura distribuída tolerante a falhas que se baseia na distribuição dos dados por vários servidores pelo que, caso um servidor deixe de funcionar, o sistema manter-se-á em funcionamento garantindo assim elevados índices de disponibilidade. Outra das principais caraterísticas destas bases de dados não-relacionais é a escalabilidade horizontal que consiste em aumentar o número de máquinas do sistema dividindo o processamento dos dados conforme as necessidades do mesmo de forma a obter sempre elevados níveis de desempenho, sendo uma das técnicas utlizadas para garantir isto denominada de sharding. Relativamente à consistência, enquanto o modelo relacional segue as propriedades ACID que entre outras coisas providência uma consistência forte dos dados, no caso das bases de dados NoSQL pode verificar-se apenas uma eventual consistency conforme as necessidades do sistema em questão e tendo em consideração o teorema CAP (Leavitt, 2010).
Estas definições e caraterísticas serão abordadas de uma forma mais detalhada na secção seguinte deste documento.
8
2.2. Conceitos
Nesta secção são abordados conceitos importantes que estão relacionados com as bases de dados NoSQL e que servirão como suporte para a análise efetuada às mesmas mais à frente neste documento, com especial destaque para as do tipo column-based.
2.2.1. Teorema CAP
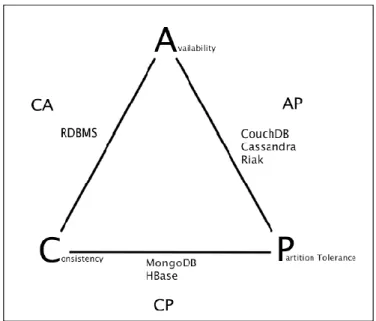
O teorema CAP surgiu, ainda como hipótese, no ano 2000 pelo cientista computacional Eric Brewer no decorrer de um colóquio acerca dos princípios da computação distribuída, tendo sido provado em 2002 por Seth Gilbert e Nancy Lynch (Shim, 2012). Este teorema faz alusão às limitações existentes nos sistemas distribuídos, como é o caso típico das bases de dados NoSQL, e tem como principais propriedades a consistência, a disponibilidade e a tolerância à partição. Assim, o ideal dos sistemas distribuídos seria poder obter as três propriedades em simultâneo, sendo que isso apenas pode acontecer relativamente a duas dessas propriedades, tendo sempre que abdicar de uma pelo que o teorema CAP deve ser levado em conta aquando do desenvolvimento de sistemas distribuídos (Brewer, 2012).
Posto isto, no contexto das bases de dados NoSQL torna-se importante compreender cada uma das propriedades mencionadas neste teorema.
Consistência
No contexto de sistemas distribuídos consistência significa que todos os nós do sistema podem aceder aos mesmos dados ao mesmo tempo (Gilbert & Lynch, 2002). Assim, o sistema garante que quando é realizada uma atualização aos dados num dos nós do sistema e estes são guardados num determinado estado, essa mudança também ocorre nos restantes nós do sistema. Ao contrário do que se pode verificar num sistema não distribuído, em que é fácil obter consistência total, num sistema distribuído isto nem sempre se verifica e por vezes é algo não desejável pois o próprio desempenho do sistema pode diminuir à medida que o número de nós aumenta sendo necessário recorrer à rede para a comunicação entre os nós de forma que estes partilhem os mesmos dados. Assim grande parte dos sistemas distribuídos fornecem um modo de baixa consistência designado de eventual consistency que será abordado mais à frente neste documento (Silva 2011).
9 Disponibilidade
Disponibilidade significa que o sistema se deve manter operacional durante um determinado período de tempo, pelo que em caso de ocorrência de falhas em algum nó os restantes devem continuar a operar (Gilbert & Lynch, 2002). Uma das principais vantagens de um sistema distribuído é o facto de fornecer alta disponibilidade pois sendo o sistema composto por vários nós que partilham dados, torna-se mais tolerante a certas falhas, ao contrário dos sistemas centralizados em que este deixa de ser capaz de operar. Assim, todos os pedidos enviados a um nó operacional devem obter resposta (Silva, 2011).
Tolerância à partição
Esta propriedade refere-se à capacidade de um sistema continuar a trabalhar mesmo após uma falha na rede ou no sistema. Num sistema distribuído os nós que o constituem, de forma a garantir o bom funcionamento do mesmo devem comunicar entre si e partilhar dados e estados pelo que em caso de ocorrência de, por exemplo uma falha na rede alguns dos nós deixam de ser capazes de comunicar ficando o sistema dividido, ou seja, particionado durante um período de tempo (Gilbert & Lynch, 2002). Assim, se o sistema for tolerante a este tipo de falhas deve ser capaz de funcionar normalmente apesar desta partição temporária, sendo igualmente capaz de realizar operações read e write. Um sistema que possui uma grande tolerância à partição é considerado altamente escalável. Por outro lado, no caso de um sistema não tolerante à partição, quando particionado torna-se inutilizável ou então apenas disponível para operações read.
10 Tal como já foi mencionado anteriormente, um sistema distribuído apenas é capaz de garantir duas destas propriedades em simultâneo pelo que se verifica a existência de três tipos de sistemas (Hewitt, 2010, página 22):
Sistemas CA: este tipo de sistemas possui uma forte consistência e alta disponibilidade, abdicando assim da tolerância à partição o que implica que apenas um nó tenha alta disponibilidade. Neste tipo de sistemas caso ocorra a falha de uma partição todo o sistema pode ficar indisponível até que o membro do cluster regresse.
Sistemas CP: dado o forte grau de consistência e a tolerância à partição que este tipo de sistemas possui torna-se necessário abdicar um pouco da disponibilidade pelo que podem acontecer casos em que por exemplo um pedido de write é rejeitado. Alguns exemplos deste tipo de sistemas são o BigTable, HBase ou MongoDB.
Sistemas AP: este tipo de sistemas têm como principal caraterística o facto de não poderem ficar offline pelo que optam por sacrificar o nível de consistência sendo que neste tipo de sistemas podem-se verificar casos de inconsistência pois caso um utilizador efetue algum write na base de dados do sistema, este não irá sincronizar imediatamente os dados com os restantes nós do sistema. Exemplos deste tipo de sistemas são Amazon Dynamo, Cassandra ou Riak.
A figura 1 ilustra estes três tipos de sistemas e faz referência a algumas das tecnologias NoSQL que seguem as suas caraterísticas.
2.2.2. Eventual Consistency
Tendo em consideração o teorema CAP apresentado por Eric Brewer que afirma que num sistema distribuído, entre as três propriedades consistência, disponibilidade e tolerância a partição apenas duas delas podem ser garantidas ao mesmo tempo e tendo em conta que num sistema distribuído partições de rede são uma constante, e como tal é necessário que o sistema seja tolerante às mesmas, a grande discussão que se coloca tem a ver com a preferência entre consistência e disponibilidade, mediante o cenário em questão e as suas necessidades. Em casos em que a consistência dos dados seja a grande prioridade então opta-se por abdicar um pouco da disponibilidade pelo que o sistema pode sob certas condições não estar disponível, mas caso a disponibilidade seja um fator crucial de um sistema então a melhor opção é relaxar um pouco os níveis de consistência dos dados. Os
11 níveis de consistência e disponibilidade podem assim ser regulados conforme as necessidades do sistema em questão e é neste contexto que se insere a chamada eventual consistency (Vogels, 2009).
Existem dois tipos diferentes de consistência, a denominada strong consistency em que quando um dado objeto é atualizado, qualquer acesso posterior ao mesmo retorna imediatamente o valor atualizado e a weak consistency, em que após a atualização de um objeto, é necessário que certas condições sejam satisfeitas para que o valor atualizado seja retornado a qualquer utilizador que consulte o objeto (Vogels, 2009). Assim, neste caso verifica-se a existência de um período de tempo em que os utilizadores podem aceder a dados inconsistentes, sendo esse período de tempo denominado inconsistency window e normalmente nas bases de dados NoSQL este período de tempo verifica-se muito curto, normalmente inferior a um segundo (Sadalage & Fowler, 2013, página 51).
A designada eventual consistency insere-se dentro da weak consistency e baseia-se no seguinte: após uma atualização a um objeto de dados, se mais nenhuma atualização ocorrer entretanto o sistema de armazenamento garante que eventualmente todas as réplicas irão convergir para o valor mais atual do mesmo. Se nenhuma falha ocorrer a duração da inconsistency window pode ser determinada com base em fatores como atrasos na comunicação, a carga do sistema e o número de réplicas envolvidas no processo de replicação (Shapiro & Kemme, 2009).
Dentro do modelo eventual consistency existem algumas variações a considerar nomeadamente:
Causal Consistency – se um utilizador comunicar a outro utilizador a atualização de determinado ficheiro de dados, um posterior acesso deste ao ficheiro irá retornar o valor atualizado, sendo garantida uma nova write para substituir a anterior. O acesso ao ficheiro por parte de um terceiro utilizador sem relação causal com o primeiro está sujeito às normas da eventual consistency.
Read-your-writes consistency – neste modelo a partir do momento que um utilizador atualiza qualquer ficheiro de dados, qualquer acesso posterior ao mesmo irá sempre retornar o valor atualizado e nunca um valor anterior. Este é considerado um caso especial do modelo causal consistency.
Session Consistency – este modelo está relacionado com o anterior, sendo que quando um utilizador acede ao sistema de armazenamento no contexto de uma sessão a consistência read-your-writes consistency está limitada ao tempo de
12 duração dessa sessão. Caso a sessão termine por algum motivo é criada uma nova e as garantias de consistência não se sobrepõem.
Monotomic read consistency – neste caso, se um utilizador lê um determinado valor para um objeto, qualquer acesso posterior ao mesmo por parte desse utilizador deve sempre retornar o mesmo valor ou um valor mais recente e nunca valores obsoletos.
Monotomic write consistency – neste caso o sistema garante que as operação write para o mesmo utilizador são feitas de forma sequencial, ou seja, uma nova operação write só pode ser executada quando a anterior estiver completa.
Algumas destas propriedades podem ser combinadas e apesar de poderem ser criados vários cenários tendo em conta as necessidades de uma aplicação, do ponto de vista de um sistema eventualmente consistente aquelas que são mais desejadas são as monotomic reads e read-your-writes pois torna-se mais simples aos programadores desenvolverem aplicações com alta disponibilidade, relaxando um pouco a consistência (Vogels, 2009).
2.2.3. Modelos de distribuição
Um dos principais pontos de interesse no NoSQL é a sua capacidade de suportar bases de dados num cluster grande. Com o aumento da quantidade de dados verificado nos últimos anos torna-se difícil e muito dispendioso comprar um servidor maior para suportar a base de dados de um sistema, pelo que uma opção mais atraente passa por distribuir a base de dados num cluster de servidores.
Assim, dependendo do modelo de distribuição utilizado, é possível obter um data store com a capacidade de lidar com grandes quantidades de dados, processar mais reads e writes e ainda obter mais disponibilidade face a falhas na rede sendo que apesar destas vantagens implica custos pelo que só deve ser feito quando acarreta benefícios claros (Sadalage & Fowler, 2013, página 37).
Posto isto, existem duas formas de distribuição de dados nomeadamente a replicação e o sharding, sendo que estas duas técnicas podem ser utilizadas em conjunto.
2.2.3.1. Sharding
O volume de dados com que lidam as bases de dados NoSQL pode ser tão elevado que torna-se necessário recorrer à escalabilidade horizontal de forma a distribuir diferentes
13 partes dos dados por diferentes servidores, sendo esta técnica designada de sharding (Hauck, 2014).
Os dados são assim, divididos por diferentes servidores denominados de fragmentos, de acordo com uma chave de distribuição que especifica o intervalo de valores que cada um deve conter (Hohenstein & Jaeger, 2014). Neste contexto, um aspeto muito importante é que o volume de dados entre os vários servidores seja equilibrado, pelo que garantir que os dados que normalmente são acedidos em conjunto sejam agregados no mesmo nó é uma medida importante para atingir esse equilíbrio. A agregação de dados é uma unidade utilizada para distribuição, sendo importante que estes agregados estejam organizados nos nós de forma a melhorar o acesso aos dados (Sadalage & Fowler, 2013, página 38). De forma a reduzir custos muitas bases de dados NoSQL permitem um auto-sharding aos dados, tendo a responsabilidade de alocar os dados para fragmentos e garantir que os acessos aos mesmos seja efetuado no fragmento correto utilizando para isto mecanismos como o hashing (Hauck, 2014).
Para além do aumento da disponibilidade, uma das principais vantagens do sharding é a capacidade de crescer linearmente à medida que mais servidores vão sendo adicionados ao sistema pelo que outro aspeto positivo é o facto de cada fragmento poder ser colocado em diferente hardware, permitindo a distribuição dos dados por várias máquinas o que resulta numa menor concorrência de recursos ao nível do CPU, memória e disco (Hohenstein & Jaeger, 2014).
Segundo (Sadalage & Fowler, 2012, página 40), algumas bases de dados estão desde logo destinadas a utilizar a técnica sharding sendo que outras a utilizam como um ato refletido, começando com uma configuração de servidor único e à medida que o volume de dados vai aumentando e o espaço livre diminuindo decidem mudar. No entanto segundo os autores esta técnica deve ser utilizada antes de ser tornar uma necessidade, caso contrário pode tornar-se uma complicação.
2.2.3.2. Replicação
O processo de replicação consiste em fazer uma cópia de determinados dados e armazena-los por vários nós da rede, sendo o número de cópias definido pelo fator de replicação. Este método melhora a confiabilidade do sistema pelo que ajuda a combater falhas que possam ocorrer em determinados nós ou até mesmo num cluster inteiro. A replicação debate-se com um problema relacionado com a consistência dos dados replicados, sendo
14 que caso as réplicas sejam atualizadas de forma síncrona o tempo de resposta do sistema aumenta mas caso sejam atualizadas de forma assíncrona irá haver um intervalo de tempo em que as réplicas estarão num estado de inconsistência (Kuznetsov & Poskonin, 2014). A replicação pode ser feita de duas formas: master-slave e peer-to-peer.
Replicação Master-Slave
Numa distribuição master-slave os dados são replicados por vários nós onde um deles é designado como master, sendo a fonte dos dados e o responsável pelo processamento de todas as atualizações nos mesmos e os restantes nós são considerados slave, estando em sincronização constante com o master. Este tipo de replicação é mais adequado para casos em que se verifica, por exemplo, um dataset com um elevado número de pedidos reads, pelo que adicionar mais nós slave ao sistema e encaminhar os pedidos para os mesmos é uma maneira eficaz de garantir a disponibilidade dos dados. Em caso de falha do nó master os nós slave podem igualmente lidar com os pedidos read, sendo que o sistema deixa de manusear operações write até que o nó master seja restaurado ou substituído por um slave (Sadalage & Fowler, 2013, página 42).
Neste tipo de replicação as atualizações por parte do nó master para os slaves podem ser feitas quer de forma síncrona como assíncrona. Assim, apesar de ter bastantes benefícios, este tipo de replicação possui algumas fragilidades ao nível da consistência caso a propagação das atualizações seja feita de forma assíncrona, pelo que existe o risco de utilizadores ao acederem a nós slave diferentes consultarem valores diferentes pelo facto das atualizações feitas pelo nó master ainda não se terem registado em todos os nós slave. Este tipo de replicação também não é muito aconselhado quando se verificam conjuntos de dados com elevado tráfego de operações write (Kuznetsov & Poskonin, 2014). Replicação Peer-to-Peer
Neste tipo de replicação não existe nó master pelo que todos os nós têm as mesmas responsabilidades, podendo realizar operações write e propagá-las para outros nós, sendo que a falha de um dos nós não impede o acesso aos dados e novos nós podem ser adicionados ao cluster de forma a melhorar o desempenho. Neste método é difícil implementar uma replicação síncrona e os atrasos devido ao congestionamento na rede podem ser significativos. Outra dificuldade que se pode verificar neste método diz respeito à consistência pelo que existe o risco de, por exemplo, diferentes utilizadores tentarem atualizar os mesmos dados em simultâneo gerando-se um conflito relacionado
15 com as versões dos dados que devem ser resolvidos recorrendo a um conjunto de técnicas (Kuznetsov & Poskonin, 2014).
2.2.3.3. Combinação de sharding e replicação
Figura 2 - Combinação de sharding com replicação (retirado de P. Sadalage & Fowler, 2013)
Replicação e sharding são estratégias que podem ser combinadas e utilizadas em simultâneo. Ao utilizar uma replicação master-slave em conjunto com sharding verifica-se a existência de vários nós master, verifica-sendo que cada conjunto de dados apenas possui um único master. Nesta situação é possível configurar nós para a função exclusiva de master ou slave de determinados fragmentos de dados assim como definir um nó como sendo master de um fragmento de dados e simultaneamente slave de outro, tal como representa a figura 2.
Uma estratégia comum que se verifica nas bases de dados do tipo NoSQL é a utilização de sharding em conjunto com a replicação peer-to-peer, sendo que num cenário destes se pode verificar a existência de dezenas ou centenas de nós num cluster com fragmentos de dados distribuídos por eles. O fator de replicação da replicação peer-to-peer deve ser no mínimo de valor três de modo que cada fragmento de dados seja replicado em três nós, sendo que em caso de falha de algum nó os fragmentos presentes nesse nó devem ser construídos nos outros nós (Sadalage & Fowler, 2013, página 44).
16
2.2.4. ACID VS BASE
De forma a otimizar o seu desempenho tanto as bases de dados relacionais como as NoSQL baseiam-se num conjunto de princípios que derivam do teorema CAP e das suas propriedades, já mencionadas neste documento.
Normalmente as bases de dados relacionais seguem as propriedades ACID que são um conjunto de propriedades que garantem que as operações de base de dados sejam processadas de forma fiável e que a base de dados se encontra sempre num estado consistente perante acessos simultâneos e falhas de sistema. As propriedades ACID são as seguintes (Haerder & Reuter, 1983):
Atomicidade - uma transação é dada como completa quando todas as operações são executadas, sendo que caso um falhe a transação inteira também falha, dando-se uma operação denominada rollback em que a base de dados volta a um estado consistente.
Consistência – garante que apenas dados válidos são registados na base de dados, sendo que esta deve transitar sempre de um estado consistente para um novo estado consistente. Caso se verifique algum erro no decorrer da transação, dá se um rollback e a base de dados volta ao estado de consistência anterior.
Isolamento – uma transação que ainda não tenha sido validada na base de dados deve permanecer isolada das restantes, pelo que a execução de uma transação não deve influenciar a execução de transações concorrentes, sendo estas independentes umas das outras. Esta propriedade é importante pois garante que o sistema se mantenha sempre num estado consistente.
Durabilidade - garante que qualquer transação confirmada na base de dados, operação também conhecida como commit, é permanente e não pode ser desfeita. Assim o sistema da base de dados deve ser capaz de recuperar transações confirmadas caso ocorra uma falha no sistema a nível de hardware ou software.
Estas são propriedades importantes que tornam uma base de dados forte e robusta. No entanto quando o volume de dados é muito elevado e a distribuição da base de dados é uma realidade estas propriedades são muito difíceis de alcançar, sendo por isso que as bases de dados NoSQL se focam nas propriedades BASE. As propriedade BASE dizem respeito a (Wang & Tang, 2012):
17
Basically Available – estando os dados distribuídos, mesmo que ocorra uma falha o sistema continua a funcionar.
Soft State – Não são dadas garantias de consistência forte.
Eventual Consistency – os dados não necessitam de estar consistentes a toda a hora, mantendo-se eventualmente consistente com garantias de que caso não ocorram novas atualizações todo o sistema ficará consistente. A grande diferença entre BASE e ACID está na consistência, sendo que as propriedades BASE seguem uma abordagem otimista focando-se no desempenho e na disponibilidade, abdicando um pouco dos níveis rígidos de consistência. Por sua vez as propriedades ACID seguem uma abordagem pessimista, forçando uma consistência forte em todas as operações (Pritchett 2008).
2.2.5.MapReduce
O MapReduce é uma abordagem concebida para o processamento de grandes conjuntos de dados, tendo sido desenvolvido por Jeffrey Dean e Sanjay Ghemawat e introduzido pela Google em 2004 (Dean & Ghemawat, 2004).Após esta proposta inicial, surgiram várias iniciativas de implementação deste modelo em várias linguagens de programação, sendo que aquele que se verificou mais relevante foi a implementação open-source da Apache Software Foundation denominada Hadoop (White, 2012). O MapReduce coloca em prática os princípios da computação paralela e distribuída tendo sido desenvolvido para processar grandes volumes de dados, distribuindo o seu processamento por várias máquinas e com um tempo de resposta aceitável. Esta distribuição implica um processamento paralelo visto que a mesma função é aplicada em todas as máquinas mas em conjuntos de dados diferentes de forma a dividir as etapas do processamento, ou seja, cada componente é responsável por processar completamente um pequeno conjunto de dados em vez de processar todos os dados na mesma etapa de computação. Outra das principais propriedades do MapReduce consiste na sua alta escalabilidade, que permite processar petabytes de dados por milhares de máquinas (Dean & Ghemawat, 2004).
18
Figura 3 - Exemplo prático da framework MapReduce (retirado de Sadalage & Fowler, 2013)
Tendo como base uma programação funcional, o MapReduce consiste em duas funções de ordem superior nomeadamente map e reduce. A função map aceita um par como input e produz um conjunto de pares chave/valor intermédio, sendo estes agrupados e organizados através de associações efetuadas aos valores das suas chaves. A função reduce recebe uma chave intermédia e um conjunto de valores associados a esta, sendo que efetua cálculos para formar o menor número possível de subconjunto de dados. A figura 3 representa um exemplo destas duas funções. Normalmente por cada invocação da função reduce apenas são produzidos os valores zero e um (Dean & Ghemawat, 2004). A figura 4 representa as funções do MapReduce. Os pares de input relativos à função map assim como os pares que a função reduce produz estão armazenados num sistema de ficheiros distribuídos, sendo que os pares intermédios encontram-se no disco do nó que os produziu.
Figura 4 - Funções do MapReduce (retirado de Dean & Ghemawat, 2004)
2.3. Tipos de Bases de dados NoSQL
Nesta secção serão abordados os quatro tipos de bases de dados NoSQL existentes, as suas principais caraterísticas e ainda exemplos do tipo de utilização prática para as quais a sua aplicação é considerada ideal.
2.3.1. Key/Value-based
Entre as propostas de bases de dados NoSQL existentes no mercado destacam-se as do tipo Key-value como sendo as mais simples e onde se pode verificar um melhor desempenho. Cada campo é constituído por uma chave e um valor e funciona como uma tabela hash, sendo que o conteúdo do valor pode ser armazenado em qualquer formato de
19 dados. O acesso aos dados é sempre efetuado através da sua chave primária que é única e através das operações get, put e delete, sendo que em geral não são suportadas operações que abranjam conjuntos de valores (Atzeni et al, 2014). Este tipo de armazenamento suporta uma elevada quantidade de dados e tem como principais vantagens a boa escalabilidade horizontal, simplicidade e o alto desempenho, sendo particularmente adequadas para situações em que os dados não se relacionam. Por outro lado não é apropriado para realizar consultas complexas aos dados dado que este modelo não possui uma boa capacidade de indexação efetuando apenas operações read e write básicas (Kuznetsov & Poskonin, 2014).
Num contexto real, este tipo de bases de dados são apropriadas para, por exemplo, gerir stock e armazenar informação relativa a perfis de utilizador ou compras em plataformas online dada a sua simplicidade e velocidade na recuperação dos dados (Abramova et al., 2014).
As bases de dados do tipo key-value mais relevantes são o Riak, o Redis e o Voldmort (Sadalage & Fowler, 2013, página 79).
2.3.2. Document-based
As bases de dados NoSQL do tipo document-based baseiam-se em modelos de dados semiestruturados onde a informação é armazenada em forma de conjuntos de documentos que podem ter diferentes formatos tais como XML, JSON ou BSON. Cada documento é constituído por um conjunto de campos armazenados de forma não-estruturada e que estão associados a uma chave única que os identifica. Este tipo de sistemas oferecem um modelo de consulta superior ao das restantes categorias de base de dados NoSQL, pelo que permitem consultar conjuntos de documentos, efetuar consultas agregadas, incluir restrições sobre o campo de valores pretendido, ordenar resultados, entre outras coisas (Atzeni et al., 2014).
Este tipo de bases de dados não suportam as propriedades ACID e variam de umas para as outras no que diz respeito à consistência dos dados, disponibilidade de operações atómicas e métodos de controlo de acesso simultâneo aos documentos, entre outras coisas (Kuznetsov & Poskonin, 2014). Para sistemas que necessitem de ter operações atómicas aos seus dados, as bases de dados do tipo document-based podem mesmo não ser o modelo mais adequado apesar de existirem algumas como o RavenDB que suportam este tipo de operações (Sadalage & Fowler, 2013, página 89).
20 Assim sendo, este tipo de base de dados são apropriadas para problemas que envolvem ambientes variados, ou seja, em que o utilizador não sabe ao certo o tipo de dados com que vai trabalhar e não são propriamente focadas no alto desempenho relativamente a operações read e write concorrentes mas sim em garantir o armazenamento de grandes volumes de dados e um bom desempenho na consulta dos mesmos (Kuznetsov & Poskonin, 2014).
Além disto, outras das vantagens deste tipo de bases de dados referem-se à ausência de esquema que diminui a complexidade dos dados, a alta escalabilidade e o manuseamento tanto de dados estruturados, semiestruturados ou não-estruturados (Kaur et al., 2013). Num contexto prático, as bases de dados do tipo document-based representam uma boa opção para trabalhar com aplicações web com grandes quantidades de documentos que podem ser armazenados em ficheiros estruturados tais como documentos de texto, emails, sistemas XML ou sistemas CRM. São também uma boa opção para aplicações de comércio eletrónico (Abramova et al., 2014).
Os sistemas de bases de dados desta categoria mais adotados são o MongoDB e o Apache CouchDB;
2.3.3. Graph-based
É considerado o modelo mais complexo entre os tipos de bases de dados NoSQL mencionados pelo facto de se basear em alguns modelos matemáticos de grande complexidade, sendo considerado o modelo ideal para analisar dados de redes sociais pela sua capacidade em armazenar informação obtida através da relação entre nós. É hoje em dia o modelo que tem suscitado mais interesse, sendo considerado por vários investigadores um desafio em curso não só pela importância atual das redes sociais mas também porque os grafos se encontram por todo o lado e a manipulação destes pode permitir às organizações a extração de informação valiosa que permita gerar conhecimento e obter vantagem competitiva relativamente aos seus concorrentes. Tal como os restantes modelos já mencionados, não possui uma estrutura definida pelo que pode armazenar qualquer tipo de dados (Robinson et al., 2013)
21
Figura 5 - Modelo de dados de uma base de dados do tipo graph-based (retirado de Sadalage & Fowler, 2013)
O seu modelo é baseado em nós que se relacionam entre si por meio de uma aresta, sendo que os nós contêm propriedades na forma de pares chave/valor e os relacionamentos têm sempre um nome associado e uma direção contendo um nó remetente e um nó destinatário. As relações também podem conter propriedades (Robinson et al., 2013). A organização do grafo permite que os dados depois de armazenados sejam interpretados de forma diferente com base nas diversas relações, sendo que um nó pode ter um número ilimitado de relações (Sadalage & Fowler, 2013, página 113).
Relativamente à escalabilidade uma das técnicas mais utilizadas pelas bases de dados NoSQL é o sharding, sendo que neste tipo de base de dados esta técnica é mais difícil de implementar pois não são orientadas a agregados mas sim a relacionamentos entre os nós. Uma vez que qualquer nó pode estar relacionado com qualquer outro nó o ideal é mesmo que estejam armazenados no mesmo servidor de forma a não prejudicar o desempenho, pelo que de forma a providenciar a escalabilidade são utilizadas outras técnicas. Outro aspeto a salientar relativamente às bases de dados do tipo graph é que estas têm tendência para suportar a semântica ACID tal como as bases de dados relacionais (Sadalage & Fowler, 2013, página 116).
Num contexto prático este tipo de bases de dados são as mais apropriadas para lidar com dados interligados, como por exemplo, analisar relacionamentos existentes entre utilizadores de redes sociais, analisar sistemas de transportes e até aplicações que sugerem produtos aos utilizadores com base nos seus gostos e preferências (Abramova et al., 2014).
22 As bases de dados do tipo graph-based mais relevantes do mercado são o Neo4J e o InfoGrid.
2.3.4. Column-based
As column-based databases são um modelo desenvolvido de forma a suportar grandes quantidades de dados. Ao contrário dos tradicionais modelos relacionais, uma linha corresponde a um conjunto de colunas associadas à mesma chave primária, não existindo um esquema previamente definido em que cada coluna de uma linha tem o seu espaço atribuído mesmo que seja do tipo NULL, pelo que cada linha pode conter um conjunto diferentes de colunas, o que se traduz num menor esforço computacional e contribui para aumentar o desempenho do sistema. Cada coluna é constituída pelo par nome e valor, sendo que o nome funciona como a chave da coluna. Além disto cada um destes é armazenado em conjunto com um valor timestamp que fornece informações acerca do valor temporal em que aqueles dados foram inseridos ou atualizados, permitindo entre outras coisas, resolver conflitos relacionados com writes e lidar com dados que estejam desatualizados. Para além disto as colunas podem ser armazenadas por famílias de colunas, de forma a facilitar a organização e a distribuição dos dados. Este modelo é o ideal para lidar com estruturas de dados complexas e de grande volume.
Num contexto prático, as bases de dados desta categoria são ideais para lidar com grandes volumes de dados, principalmente quando o número de operações write é superior às reads como é o caso de sistemas onde se verifica um elevado registo de eventos (Abramova et al., 2014).
2.4. Bases de Dados Column-based
Existem várias soluções de bases de dados do tipo Column-based disponíveis no mercado entre as quais: o Cassandra, HBase, Cloudera, Cloudata, Hypertable, Accmulo entre outros. Para esta proposta de dissertação foram escolhidas para análise aquelas que consoante o prestígio, recomendações baseadas em artigos científicos e documentação disponível se destacam das restantes, nomeadamente o Cassandra e o HBase.
2.4.1. Cassandra
O Facebook é talvez a maior rede social existente nos dias de hoje, tendo em horários de maior tráfego que atender a biliões de utilizadores em simultâneo, recorrendo para isso a milhares de servidores espalhados por todo o mundo. A plataforma Facebook tem por
23 isso que garantir altos níveis de desempenho, confiabilidade, eficiência, disponibilidade e ser altamente escalável de forma a poder suportar o constante crescimento da mesma. De forma a garantir tudo isto o Facebook desenvolveu o Cassandra cujo lançamento ocorreu em 2008 como um projeto open-source com o intuito inicial de melhorar o mecanismo do motor de busca da plataforma, tendo sido em 2009 adotado pela Apache Software Foundation, e sendo hoje em dia utilizado por grandes empresas como o Ebay, o Twitter e a Cisco Systems para além de órgãos governamentais como a NASA (Weber & Strauch, 2010).
Assim, os seus criadores, Avinash Lakshman e Prashant Malik, definem-na como uma base de dados distribuída e altamente escalável criada para armazenar grandes quantidades de dados distribuídos por vários servidores, oferecendo uma alta disponibilidade e uma eventual consistência dos dados (Laksham & Prashant, 2010) 2.4.1.1. Modelo de Dados
Figura 6 - Estrutura de uma família de colunas do Cassandra (Sadalage & Fowler, 2013)
Ao contrário das bases de dados relacionais o modelo de dados do Cassandra não se baseia no relacionamento entre tabelas mas sim no desempenho de consultas, sendo que “uma tabela no Cassandra é um mapa multidimensional distribuído indexado por uma chave”(Laksham & Prashant, 2010). O modelo de dados Cassandra é muito semelhante ao BigTable e é constituído por (Datastax, 2015):
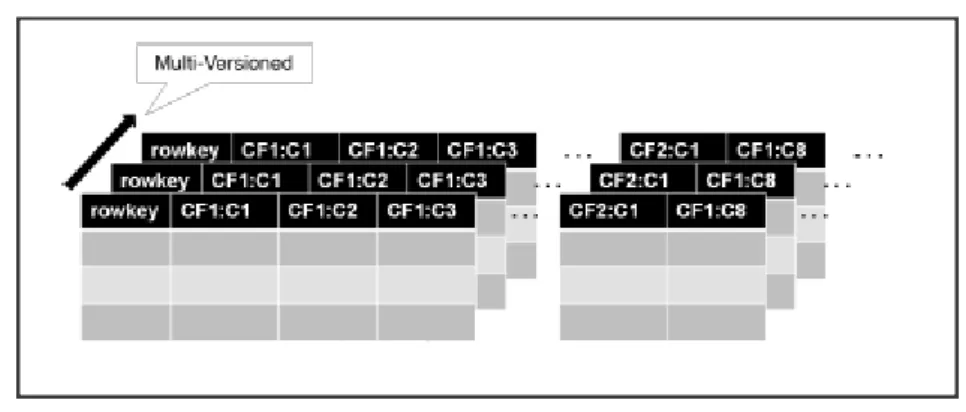
Coluna: No cassandra a unidade básica de armazenamento é a coluna. Uma coluna é constituída pelo par nome e valor, sendo que o nome funciona como chave da coluna. Além disto cada coluna possui um valor timestamp que fornece informações acerca do valor temporal em que os dados foram inseridos ou
24 atualizados, permitindo entre outras coisas resolver conflitos em operações write ou lidar com dados que estejam desatualizados. Caso os dados de colunas estejam um longo período de tempo sem serem utilizados, o espaço que estão a ocupar pode ser reclamado mais tarde durante uma fase de compactação (Sadalage & Fowler, 2013). Uma coluna pode ser interpretada como um registo numa base de dados relacional.
Super Coluna: Pode ser vista como uma coluna com sub-colunas. Tal como uma coluna, uma super coluna contem um par chave/valor embora neste caso o valor esteja associado a um mapa que contem várias colunas.
Linha: Ao contrário do que acontece num modelo relacional, uma linha é um conjunto de colunas associadas à mesma chave primária, sendo que relativamente ao armazenamento dos dados enquanto num modelo relacional existe um esquema previamente definido em que cada coluna de uma dada linha tem o seu espaço atribuído mesmo que o seu valor seja NULL, neste caso só é atribuído espaço às colunas presentes nessa linha o que se traduz num menor esforço computacional e contribui para um melhor desempenho.
Cada linha possui uma row key ,sendo que esta é uma string que não tem restrições ao nível do tamanho e todas as operações realizadas sobre uma row key “são consideradas atómicas por réplica independentemente do número de colunas que estão a ser atualizadas ou consultadas” (Laksham & Prashant, 2010).
Famílias de colunas: são constituídas por um número infinito de linhas, sendo que cada linha contem uma row key e um conjunto de colunas ordenadas pela sua chave. A partir da versão 2.2 do Cassandra as famílias de colunas passaram também a ser designadas por tabelas.
Uma família de colunas pode ser comparada a um conjunto de linhas de uma tabela do modelo relacional em que cada linha possui uma chave e está associada a um conjunto de colunas sendo, que a grande diferença entre os dois modelos é o facto de no modelo não relacional não existir nenhum esquema pré-definido, pelo que as linhas não têm que ter exatamente as mesmas colunas e estas podem ser adicionadas a uma só linha a qualquer instante sem que seja necessário que isso aconteça nas restantes linhas( Sadalage & Fowler, 2013, página 100).
Super Família de Colunas: Semelhante a uma família de colunas, uma super família de colunas é constituída por um conjunto de super colunas, sendo que são
25 úteis para manter dados que estão relacionados juntos (Sadalage & Fowler, 2013, página 101).
Keyspace: é semelhante a uma base de dados no sistema relacional onde se encontram armazenadas todas as famílias de colunas relacionadas com uma mesma aplicação. Como se comprovará mais à frente o keyspace possui também informações acerca de como os dados são replicados ao longo do cluster.
A figura 7 representa um exemplo de uma família de colunas, sendo que estas se assemelham a uma tabela de uma base de dados do modelo relacional. Os nomes das colunas pertencentes à família de colunas são relativamente estáticos, como se pode verificar na figura 7, onde normalmente depois de criadas não são associadas novas colunas. Apesar das linhas conterem normalmente o mesmo conjunto de colunas, esse não é um requisito obrigatório. Cada coluna de uma família de coluna possui normalmente uma coluna de metadados pré-definida associada (Datastax, 2015).
Figura 7 - Família de Coluna (retirado de Datastax, 2015)
2.4.1.2. Modelo de Consulta
No Cassandra o acesso aos dados pode ser feito de diferentes formas. Durante algum tempo a API Thrift surgiu como a forma mais comum de interagir com o Cassandra. No entanto, atualmente a maneira mais comum e recomendada para interagir com o Cassandra é a linguagem CQL – Cassandra Query Language (Svaljek, 2015, página 46). Uma vez que a sua syntax é muito similar ao SQL torna-se mais fácil aos utilizadores interagir com os dados armazenados, verificando-se uma curva de aprendizagem reduzida (Abramova & Bernardino, 2013). No entanto CQL não possui tantas funcionalidades como o SQL, não permitindo efetuar joins ou subconsultas dos dados (Sadalage & Fowler, 2013, página 108).
Através da linguagem CQL é possível efetuar um variado conjunto de operações à base de dados, sendo que o acesso aos dados é feito com base na chave primária da família de