AGRADECIMENTOS
Ao chegar ao fim de apenas mais uma etapa daquela que é a infinita jornada, rumo ao conhecimento, queria em primeiro lugar agradecer à minha orientadora Doutora Marieta Valente, pelo apoio, disponibilidade e acima de tudo pela energia e dedicação para ajudar a realizar esta investigação, sem a qual não seria possível. Professores como a professora, nos fazem lembrar o porquê que o aprendizado nunca é um investimento vão, pois, para além do acréscimo que se dá em termos académicos, também há espaço para o crescimento como seres humanos, que é o legado do verdadeiro mentor. O meu muito obrigado por tudo!
Em segundo lugar, gostaria de agradecer a todas as pessoas que cederam um pouco do seu tempo para contribuir para esta investigação, possibilitando assim que tivéssemos acesso aos dados necessários isto é, gostaria de agradecer a todas pessoas que direta ou indiretamente ajudaram-me nesse desafiador percurso. Com especial ênfase para os meus amigos Lendina Fernandes e Princípe Zanguilo cujo companheirismo e lealdade foram um dos meus maiores pilares e ao Albuquerque Pedro pelo apoio quase que incondicional.
E por último porém não menos importante, gostaria de agradecer aos meus pais, Felícia Walinga cuja coragem e força de vontade não param de me surpreender e são a minha fonte de inspiração. Ao meu pai, Carlos Luís por mais uma vez ter acreditado em mim e me ter permitido voar mais um pouco através do incentivo, motivação e acima de tudo pelo exemplo. Assim como agradeço aos meus queridos irmãos Alcides Paulino, Britaldo Paulino, Cláudio Paulino, Carlos luís, e as minhas sobrinhas Luna Paulino e Luana Paulino cuja existência é nada mais que uma bênção.
Declaração de integridade
Declaro ter atuado com integridade na elaboração do presente trabalho académico e confirmo que não recorri à prática de plágio nem a qualquer forma de utilização indevida ou falsificação de informações ou resultados em nenhuma das etapas conducente à sua elaboração. Mais declaro que conheço e que respeitei o Código de Conduta Ética da Universidade do Minho.
Big data e as empresas: Estudo exploratório sobre a perceção dos consumidores
RESUMO
Quando se fala em contexto de Big data é possível aferir que existe uma grande assimetria em termos de informação entre as empresas e os consumidores.
Desta forma a razão de existência desta dissertação de mestrado prende-se com o objetivo de saber até que ponto os consumidores estão conscientes dos riscos e custos potenciais associados às estratégias empresariais relativas ao Big data. Isto é, saber se os consumidores são míopes ou estratégicos em relação à recolha da sua informação pessoal pelas empresas. Esta tese investiga a perceção dos consumidores acerca do uso da sua informação pessoal pelas empresas. Para a realização do estudo foram recolhidos dados de natureza quantitativa de 203 indivíduos através da aplicação de inquéritos por questionário.
Os resultados revelam que os indivíduos apesar de apresentarem em maior ou menor grau preocupações relacionadas com a partilha da sua informação pessoal, tendem a ser pouco proactivos em tomar medidas que ajudem a protegê-la, mesmo sendo utilizadores bastante ativos da internet e dos seus serviços. Portanto os mesmos apresentam algum grau de miopia em relação à recolha da sua informação pessoal pelas empresas, o que por sua vez, também afeta o nível de consciências dos respondentes relativamente aos potenciais riscos e custos associados às estratégias empresariais relativas ao Big data.
Também foi possível aferir através dos cenários com situações hipotéticas e reais a que os indivíduos foram expostos, que a maioria não está disposta a pagar por serviços que visem a proteção da sua informação. E mesmo quando estão dispostos a pagar por esses serviços, a sua valoração tende a ser baixa fixando-se em cerca de 2 euros mensais no máximo. Por fim os indivíduos mostram-se mais cooperativos na partilha da sua informação pessoal, quando estão envolvidos ganhos para a sociedade.
Palavras-Chave: Big data, empresas, perceção dos consumidores, privacidade online, valoração da informação pessoal.
Big data and business: Exploratory Study on Consumer Perception´
ABSTRACT
When speaking in the context of Big data it is possible to see that there is a great information asymmetry between companies and consumers.
Thus, the reason for the existence of this master's dissertation is to know to what extent consumers are aware of the risks and potential costs associated with Big data business strategies. That is, whether consumers are short-sighted or strategic about companies collecting their personal information.
This thesis investigates consumers 'perceptions about companies' use of their personal information. For the study, quantitative data was collected from 203 individuals through questionnaire surveys.
The results show that individuals to a greater or lesser degree have concerns about sharing their personal information, but tend to be less proactive in taking steps to help protect it, even though they are very active users of the internet and its services. Therefore, they have some degree of myopia regarding to the collection of their personal information by companies.
It has also been possible to ascertain through scenarios with hypothetical and real situations to which individuals have been exposed, that most are unwilling to pay for services aimed at protecting their information. Even when they are willing to pay for such services, their valuations tend to be low at around 2 euros maximum.
Finally individuals are more cooperative in sharing their personal information when gains for society are involved.
Keywords: Big data, companies, consumer perception, online privacy, valuation of personal information.
Índice AGRADECIMENTOS ... iii RESUMO ... v ABSTRACT ... vi ÍNDICE DE TABELAS ... ix ÍNDICE DE GRÁFICOS ... x ÍNDICE DE FIGURAS ... x LISTA DE ABREVIATURAS ... xi 1.INTRODUÇÃO ... 12 2. REVISÃO DE LITERATURA ... 14 2.1 Enquadramento ... 14 2.1.1 Definição ... 14
2.1.2 Big data e o nudging... 16
2.1.3 Benefícios potenciais para a sociedade ... 18
2.1.4 Riscos potenciais para a sociedade ... 21
2.2 Estratégias comerciais das empresas à luz do Big data ... 26
2.2.1 Discriminação de preços ... 27
2.2.2. Diferenciação de produto ... 28
2.2.3. Publicidade alvo ... 30
2.3. Riscos e benefícios potenciais para os consumidores ... 32
2.3.1 Inteligência artificial ... 32
2.3.2. Privacidade ... 33
2.3.3. Discriminação de preços ... 36
2.3.4. Discriminação de preços como barreira à entrada de novas empresas ... 38
2.3.5. Diferenciação de produto ... 39
2.3.6. Publicidade alvo ... 40
2.3.7. Resumo ... 41
2.4 Evidência empírica ... 43
2.4.2. Estudos empíricos sobre o comportamento dos consumidores em contexto de
e-commerce. ... 51
2.4.3. Estudo empíricos sobre cartões de fidelização dos consumidores ... 52
2.5.Regulação do Big data ... 60
3. DADOS E METODOLOGIA ... 64
4. ANÁLISE DE RESULTADOS ... 78
4.1 Caracterização da amostra ... 78
4.2. Comportamentos e utilização da internet ... 79
4.2.2. Cautelas na internet ... 80
4.2.3. Comportamento dos consumidores em contexto de e-commerce ... 81
4.3. Atitudes e perceções sobre preocupações na utilização da internet ... 81
4.4. Atitudes relacionadas com o uso de algoritmos ... 86
4.5. Valoração da informação pessoal ... 87
4.6. Comparação de dados ... 92
4.7. Síntese do capítulo ... 96
5. CONCLUSÃO ... 99
REFERÊNCIAS BIBLIOGRÁFICAS ... 102
ÍNDICE DE TABELAS
Tabela 1. Benefícios e custos do Big data para as empresas ... 41
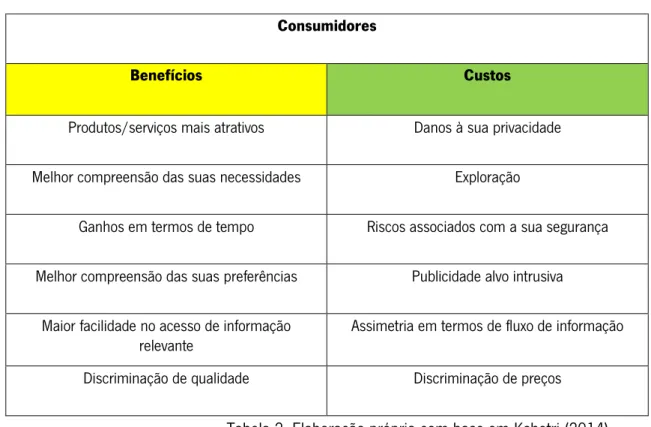
Tabela 2. Benefícios e custos do Big data, para os consumidores ... 42
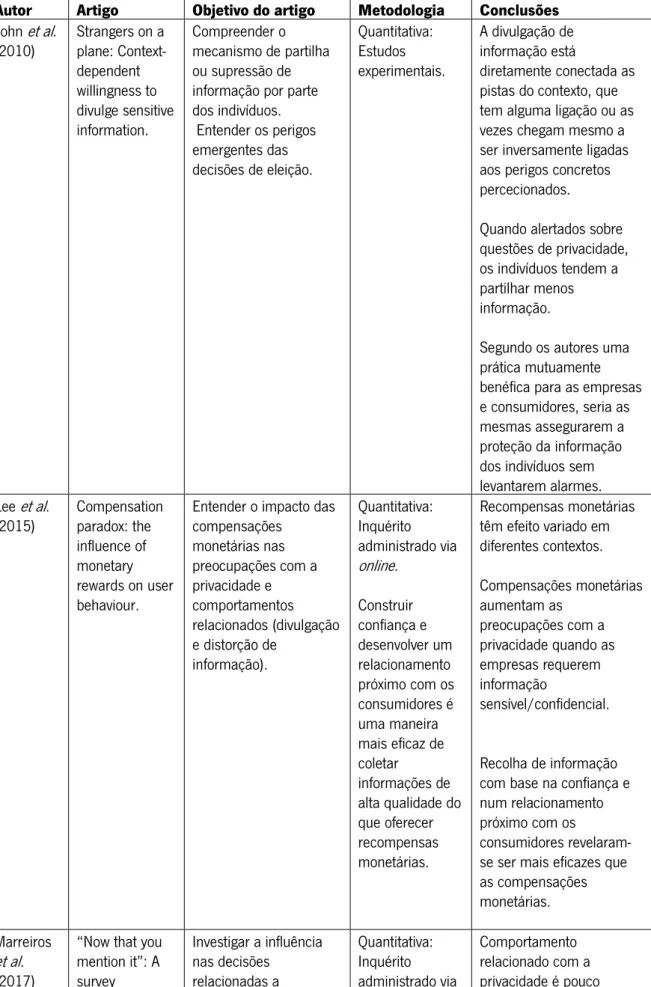
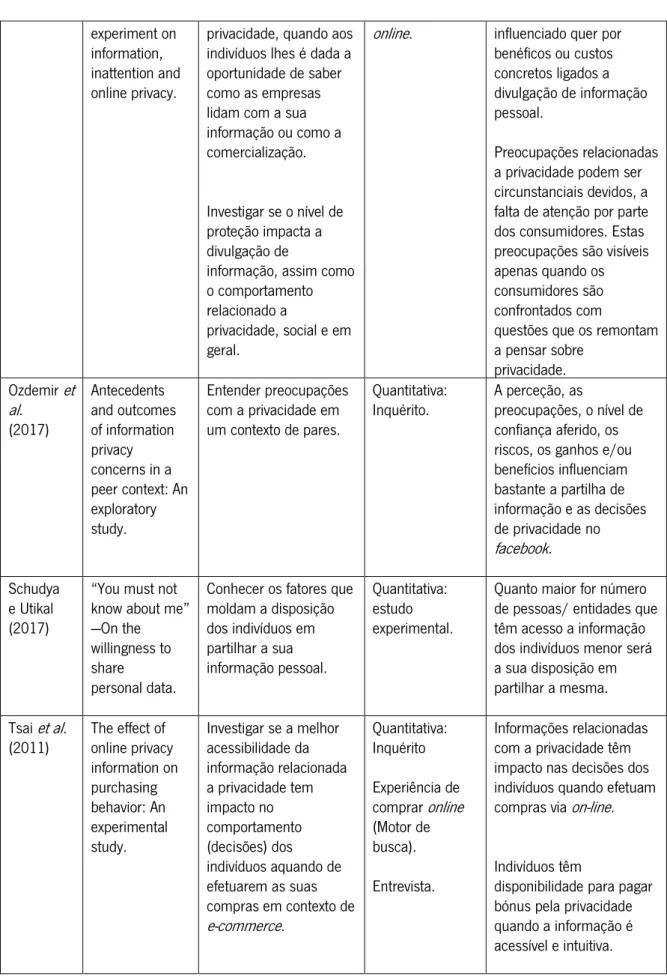
Tabela 3. Estudos sobre privacidade ... 49
Tabela 4. Estudos sobre o comportamento dos consumidores em contexto de e-commerce ... 52
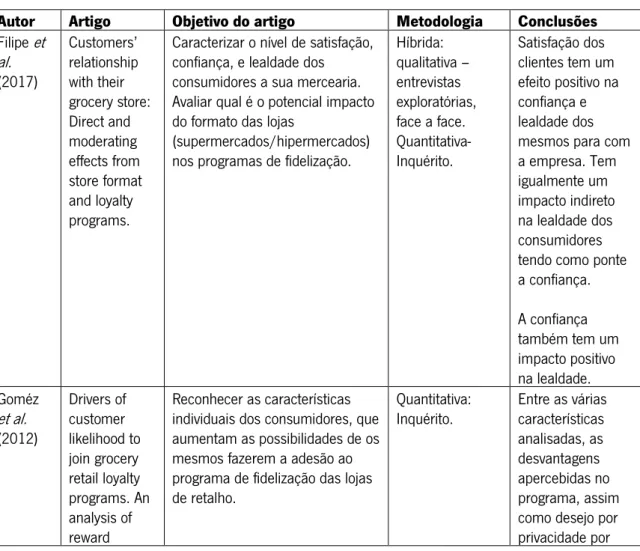
Tabela 5. Estudos sobre programas de fidelização ... 55
Tabela 6. Estudos adicionais de revisão de estudos empíricos ... 58
Tabela 7. Perguntas sobre comportamentos e utilização da internet ... 67
Tabela 8. Perguntas sobre Cautelas na internet ... 68
Tabela 9. Perguntas sobre Atitudes e perceções relacionadas ao uso da informação pessoal ... 69
Tabela 10. Perguntas sobre Atitudes relacionadas ao uso de algoritmos ... 71
Tabela 11. Caracterização socioeconómica ... 76
Tabela 12. Taxa de utilização de serviços online ... 79
Tabela 13. Perceções dos respondentes sobre cartões de fidelidade e práticas comerciais no ambiente de comércio eletrónico. ... 84
Tabela 14. Disposições a pagar por serviço de proteção de informação pessoal ... 88
Tabela 15. Categorias de fatores com mais peso para os diferentes grupos de respondentes ... 94
Tabela 16. Preferências da amostra portuguesa vs. amostra não portuguesa em várias categorias. ... 95
ÍNDICE DE GRÁFICOS
Gráfico 1. Nível de concordância sobre as vantagens do Big data para empresas e consumidores ... 83 Gráfico 2. Quota de respondentes que possuem cartões de loja. ... 84 Gráfico 3. Nível de compreensão relativamente ao Big data. ... 86 Gráfico 4. Concordância relativamente ao controlo do uso de algoritmos, pelas entidades reguladoras na tomada de decisão (frequência de resposta). ... 87 Gráfico 5. Disposições para a partilha de informação ... 90 Gráfico 6. Disposições para a partilha de informação ... 91
ÍNDICE DE FIGURAS
LISTA DE ABREVIATURAS
ADM – Automatic decision making EUA - Estados unidos da américa GPS – Global positioning system IA - Inteligência artificial
RGDP- Regulamento geral de proteção de dados UE- União europeia
1.INTRODUÇÃO
O Big data define-se como o uso em grande escala do poder computacional, bem como o uso de softwares tecnológicos avançados, para recolher, processar e analisar dados caracterizados por um grande volume, velocidade, variedade e valor (OCDE, 2016).
As questões relacionadas com o Big data são extremamente atuais e têm vindo a mudar a forma como as empresas se relacionam com os consumidores, potenciando ganhos em termos de eficiência e de lucros.
É sabido que informação é poder, sendo assim também no contexto económico uma vez que quanto mais informações as empresas têm sobre os clientes, isto é, quanto mais informação as mesmas têm sobre as preferências dos consumidores relativamente aos serviços e produtos, melhor segmentação do mercado e consequentemente melhor diferenciação podem fazer dos consumidores a quem esses produtos e serviços se destinam. A melhor partição do mercado permite que as empresas aufiram maiores lucros e dessa forma as mesmas estão a cumprir com o seu propósito máximo que é o da maximização de lucros. Porém, verifica-se que no contexto do Big data existem assimetrias, mais especificamente em termos de informação entre as empresas e os consumidores.
Desta forma o tema escolhido para esta dissertação permite estudar a relação entre empresas e consumidores num contexto em que a própria regulação está em evolução, e visto que a Economia Industrial e da Empresa é uma área que se dedica em grande parte à compreensão do funcionamento das empresas, dos mercados e como esses dois fatores interagem e se influenciam, o estudo dos desafios colocados pelo Big data relevam a relevância deste tema para o âmbito do Mestrado em Economia Industrial e da Empresa.
Assim sendo, a motivação para realização dessa dissertação é essencialmente a de entender melhor essas questões e os desafios que o Big data coloca à relação entre as empresas e consumidores. Ou seja, é de explorar até que ponto os consumidores estão cientes das potencialidades do Big data para as empresas, e como percecionam o seu papel enquanto clientes das empresas e fornecedores dessa informação.
Portanto, com a realização dessa dissertação pretendemos responder as seguintes perguntas de investigação:
- Em que medida estão os consumidores conscientes dos riscos e custos potenciais associados às estratégias empresariais relativas ao Big data?
- São os consumidores míopes ou estratégicos em relação à recolha dos seus dados pelas empresas?
De forma a explorar o modo como as pessoas disponibilizam informação sobre si, muitas das vezes de forma gratuita, bem como aferir se essas mesmas pessoas estão a ser cuidadosas na partilha da sua informação. Por outro lado, aproveitando a atualidade do tema será realizada também uma análise ao modo como as entidades reguladoras estão a atuar de forma a evitar que as empresas retirem proveito inadequado de tal possível arbitragem.
Deste modo neste documento de dissertação será feita na secção 2 uma revisão de literatura sobre as estratégias comerciais das empresas, os riscos e benefícios potenciais para os consumidores, uma breve revisão da literatura empírica relevante, bem como uma apresentação dos principais desafios regulatórios e regulação já em vigor nesta matéria. Na secção 3 será abordada a metodologia escolhida para desenvolver o trabalho de dissertação, na secção 4 será feita uma breve análise e discussão de resultados e finalmente na secção 5 apresentamos as conclusões alcançadas.
2. REVISÃO DE LITERATURA
“Personal data is the currency of the digital economy”
(The Economist, 2012). 2.1 Enquadramento
2.1.1 Definição
As últimas décadas têm sido marcadas por grandes avanços, quer no domínio das tecnologias de informação, tecnologias puras, bem como no domínio da internet. Esses avanços são caracterizados, pela proliferação das bases de dados eletrónicas, dos computadores pessoais, pela difusão das mensagens de correio eletrónico, etc. (Acquisti et al., 2016). Os avanços sucessivos e cumulativos nas áreas supracitadas levaram à emergência do fenómeno conhecido como Big data e com ele juntamente surgiram problemáticas relacionadas com o uso da informação pessoal pelas empresas.
Tal como foi referido anteriormente, o Big data diz respeito a volumes significativos de dados produzidos, e postos a disposição na internet bem como nos ditos ecossistemas de média digital (Mikalef et al., 2018).
Sendo assim importante mencionar as várias dimensões que agregam o Big data, em que elas são as seguintes:
• Volume – que se prende com a grande quantidade de dados gerados a cada segundo, incluindo análises simples e complexas e que representam desafio de armazená-los bem como de analisá-los.
• Velocidade - essa dimensão prende-se com a rapidez com o qual novos dados são criados e se movem em contraste com a janela de tempo em que os mesmos são traduzidos em decisões estratégicas.
• Variedade - diz respeito aos diferentes tipos de dados que podemos encontrar quando falamos do Big data, sendo eles nomeadamente designados por dados estruturados e não estruturados. Os dados estruturados são aqueles que já receberam algum tipo de tratamento, como, por exemplo, os dados financeiros, enquanto os dados não estruturados são o oposto. Os mesmos são provenientes das redes sociais, sensores (a chamada “internet das coisas”), camaras fotográficas, etc. e apresentam-se nos mais variados
padrões e formatos. Em particular as bases de dados de Big data referem-se essencialmente a um conjunto de dados não estruturados e que podem ser originados de forma anónima ou não.
• Veracidade - essa dimensão diz respeito à certeza que podemos retirar dos dados, uma vez que alguns dados podem ser intrinsecamente imprecisos e outros estão sujeitos a tornaram-se imprecisos devido a erros no seu processamento.
Charles e Gherman (2013) apresentam-nos para além das quatro dimensões tradicionais do Big data mais outras três, nomeadamente o contexto, a conetividade e a complexidade.
A dimensão do contexto prende-se com a capacidade de extrair conhecimento, assim como, a compreensão do ambiente progressivamente complexo pelo maior uso da internet, e em função da melhor compreensão do contexto responder adequadamente aos desafios impostos pelo Big data. Pois tal como os autores nos fazem saber é importante que as empresas e outras entidades que recorrem ao uso do Big data consigam construir narrativas em volta do mesmo que façam sentido. Dos dados não estruturados podem ser obtidos vários significados, isto é, os dados não estruturados podem estar permeados de ambiguidade, e se não forem corretamente tratados podem conduzir-nos a destinos diferentes dos objetivos inicialmente traçados.
Já a conetividade aparece intrinsecamente ligada ao contexto, pois, a mesma tem a ver com a capacidade que as empresas têm de perceber o contexto de forma mais abrangente. Isto é, as empresas devem ser capazes de conseguir cruzar a sua informação com a do mundo exterior de forma a obter melhores resultados.
E por fim a última dimensão, a complexidade que tem a ver com a capacidade de seleção e identificação, por parte das empresas, da informação relevante que impacta a o seu funcionamento.
Ainda a esta dimensão vem associada a aptidão de resposta, e adaptação por parte das empresas as constantes mudanças do ambiente.
Tal como Manyika et al. (2011) nos fazem saber, o Big data está em todo lugar, isto é, em todos os setores, em todas as organizações e em todos os utilizadores de tecnologia digital.
Já em 2010 mais de quatro mil milhões de pessoas faziam o uso de telemóveis, o que corresponde a 60% da população mundial, dos quais 12% utilizavam smartphones, e esse
rede estão presentes nos setores dos transportes, do retalho e no setor industrial de acordo a análise do instituto McKinsey (Manyika et al., 2011). Os avanços proporcionados pelo Big data têm sido tão significativos que no futuro podemos não ter apenas telefones inteligentes, mas também casa, fábricas e cidades inteligentes.
Assim, a quantidade de informação produzida pela humanidade graças às referidas tecnologias tem vindo a crescer de tal forma que está a desafiar a nossa capacidade para processá-la e armazená-la.
2.1.2 Big data e o nudging
Dessa forma somos obrigados a falar também do Nudging que em conjunto com o Big data é chamado de BIGNudging. Alguns autores defendem que a informação pessoal pode ser utilizada para levar as pessoas a tomarem melhores decisões seja a nível pessoal ou social.
O Nudging tem os seus pilares fortemente ancorados no chamado paternalismo libertário. No que diz respeito ao paternalismo, existem vários tipos do mesmo, sendo que podemos ter um paternalismo mais agressivo conhecido como hard paternalism ou um paternalismo menos agressivo, conhecido como soft paternalism.
Podemos ainda classificar o paternalismo com base em outros critérios, tais como, termos em conta se o mesmo pretende influenciar as escolhas em si dos indivíduos ou simplesmente os meios pelos quais os mesmos fazem essas escolhas (Sunstein, 2014).
Assuntos ou decisões que toquem direta ou indiretamente a liberdade, autonomia e capacidade de escolha dos indivíduos dentro das sociedades, sempre foram foco de intensos debates, assim, como de opiniões divergentes. Sustein (2014) contextualiza o debate remetendo, por exemplo para grandes pensadores como Stuart Mill que contribuíram imensamente para as perceções que ainda nos tempos modernos se tem sobre essas questões. Por exemplo o autor em questão era apologista da intervenção do Estado em esferas que por direito eram de jurisdição do indivíduo, apenas quando isso se justificasse. Ou seja, apenas em casos especiais em que o bem-estar social estivesse em causa.
O paternalismo libertário e o seu oposto diferem na sua natureza na medida em que o paternalismo libertário apesar de influenciar as decisões da população, o mesmo tenta fazer com que as pessoas tomem melhores decisões que edifiquem não só a si mais também a sociedade. O mesmo é distinto na medida em que a liberdade de escolha é mantida. Em outras
palavras o paternalismo libertário molda as decisões dos indivíduos mas não é impositivo. Isto é os indivíduos tem sempre a opção de aderi-lo ou não (Sustein, 2014).
Uma multa, por um lado é um bom exemplo de paternalismo agressivo e por outro um sistema tecnológico de localização como o Global Positioning System ou GPS como é mais frequentemente conhecido, pode ser um ótimo exemplo de paternalismo libertário (Sustein, 2014). Ambas as formas de paternalismo aqui em questão reúnem os seus adeptos e os seus não simpatizantes. Embora o paternalismo libertário tenda a ser mais facilmente tolerado, isso não inibe que o mesmo seja criticado e em alguns casos seja olhado com desconfiança.
Os principais problemas relacionados ao Paternalismo libertário aparecem associados as questões de transparência e a facilidade com que o mesmo pode se tornar manipulador. Ou seja as caraterísticas que fazem com o paternalismo libertário seja mais tolerável, constituem também, um problema na medida em que o mesmo pode servir como um pano de fundo para influenciar os indivíduos de formas que muitas das vezes não são percetíveis e em última instância o mesmo pode assumir um caracter manipulador.
Já o paternalismo agressivo embora despolete fortes reações, uma vez que um dos argumentos utilizado pelos opositores do mesmo é que ele fere a autonomia dos indivíduos, porém em comparação ao paternalismo libertário é mais tangível. Pois o mesmo serve-se de instrumentos práticos e mesuráveis tais como multas ou sentenças de prisão, etc. Algumas formas de paternalismo impõem custos materiais, como multas, às escolhas das pessoas para melhorar seu bem-estar. Outras formas impõem custos afetivos ou psíquicos, como no caso das advertências gráficas de saúde, que podem ser planeadas para assustar as pessoas. Porém, tal como foi referido, quando o paternalismo assume uma forma mais suave e por conseguinte quando o mesmo aparenta ser promissor em oferecer oportunidades ou trazer melhorias a nível de bem-estar, etc. sem condicionar a liberdade de escolha, as críticas ou oposição ao mesmo tende a igualmente suavizar-se.
Porém, tal como nos faz saber Sustein (2014), não se pode dizer de forma taxativa que um tipo de paternalismo é melhor que o outro, uma vez que ambos são extremamente dependentes da forma como ecoam no contexto, assim como os resultados que deles emergem.
Para concluir dizer que independentemente do tipo de paternalismo, a verdade é que as pessoas de acordo com a visão do autor citado continuam a ter reações avessas ao mesmo. Uma vez
que há algumas pessoas que acreditam que, independentemente do resultado que as suas decisões tiverem, elas têm o direito de exercer o seu poder de decisão.
A partir de questões como estas podemos construir a ponte entre o Big data e o Nudging, pois as avançadas ferramentas que o Big data possibilita podem permitir não só a governos, mas também a outras entidades enveredem tanto em práticas positivas bem como em práticas menos positivas que podem emergir do Nudging.
2.1.3 Benefícios potenciais para a sociedade
Não obstante, não nos podemos esquecer que o progresso tecnológico sempre existiu, porém o que há de novo é a transformação cada vez mais rápida e contínua de dados em conhecimento significativo. Esse conhecimento tem-se convertido em aplicações concretas, o que por sua vez pode ser uma mais-valia para a sociedade, em que as mesmas têm abrangido os mais variados setores. A título de exemplo, seguem-se alguns casos concretos de forma a serem ilustrativos das oportunidades que o Big data oferece para melhorias sociais.
Os exemplos que se seguem foram baseados em Wang et al. (2018), Michael et al. (2018) , Chui et al. (2018).
• Setor da Saúde
No setor da saúde o Big data está a possibilitar que as entidades de saúde através de algoritmos analíticos construam e analisem padrões no atendimento médico seja pela via de dados estruturados ou não estruturados, e desta forma o Big data tem sido útil no suporte à decisão médica, bem como na capacidade de previsão e de rastreio.
Nos EUA o hospital chamado Texas Health Harris Methodist Hospital Alliance, tem analisado a informação proveniente dos sensores médicos de forma a prever o quadro evolutivo dos seus pacientes, bem como, para fazer a monitorização dos movimentos dos pacientes durante todo o período de internação. Desta forma o hospital em questão consegue obter relatórios, alertas, indicadores-chave de desempenho e visualizações interativas resultantes da análise preditiva. Esta análise permite que o hospital ofereça os serviços adequados e com maior eficiência, melhorando assim as operações já existentes, bem como, a sua capacidade de prevenção de possíveis riscos médicos.
Outro exemplo está relacionado com o trabalho que tem sido desenvolvido por alguns investigadores, em várias universidades, isto é, alguns investigadores das Universidades de Heidelberg e de Stanford construíram um sistema que visa a de deteção de doenças recorrendo ao diagnóstico visual de imagens que segundo a taxonomia são chamadas de naturais. As imagens naturais consistem em imagens como as de lesões de pele, por exemplo, para ajudar a determinar se as mesmas são cancerígenas. De acordo aos dirigentes deste estudo a capacidade de previsão do sistema teve um melhor desempenho quando comparado com os dermatologistas profissionais.
Ainda na mesma pauta de assunto, dizer que alguns dispositivos portáteis que podem ser utilizados em pulsos, etc. podem detetar sinais precoces de indícios de diabetes com uma precisão de até 85%, através da análise da informação da frequência cardíaca recolhida pelos sensores. Os investigadores alertam-nos que se esse tipo de tecnologia for acessível à população, pode ajudar um número significativo de pessoas, sendo mais específicos pode ajudar um número superior a ordem dos 400 milhões de pessoas.
Por um lado, não só a população em geral se veria beneficiada, no sentido de que quanto mais cedo é diagnosticada uma doença melhores são as hipóteses de tratamento. Por outro o estado sairia igualmente beneficiado a medida que poderia reduzir os seus custos relacionados ao tratamento de doenças em estado avançado.
Esses são apenas alguns dos vários exemplos das várias formas que o Big data pode ser utilizado para beneficiar os serviços de saúde, e em última instância a sociedade.
Porém os benefícios que o mesmo pode trazer para a sociedade não ficam por ali. Vejamos agora a área do ambiente.
• Ambiente
Devido aos grandes avanços da sociedade moderna, muitas das vezes o ambiente é forçado a pagar o preço pelo progresso humano. Aspetos como conseguir manter e proteger a biodiversidade existente na natureza, assim como conseguir evitar a exploração excessiva dos recursos naturais levando em última análise à escassez dos mesmos, a poluição assim como as mudanças climáticas são problemáticas atuais e que têm sido foco de grande preocupação por parte da sociedade em geral e dos seus dirigentes.
Sendo assim, tem-se procurado soluções para ajudar a resolver estas questões e daí mais uma vez o papel de relevância do Big data que está a permitir que organizações como a Rainforest Connection, uma organização sem fins lucrativos dos EUA, usem ferramentas de IA (inteligência artificial), como o TensorFlow, do Google, em programas de conservação de recursos naturais nos mais variados lugares a volta do mundo. A Sua plataforma pode detetar atividades ilegais como o abate de árvores para madeira naquelas zonas em que as florestas se encontram mais desprotegidas ou mais suscetíveis a este tipo de ação. Estas atividades podem ser registradas apenas graças a análise da informação proveniente dos sensores de áudio que permitem auscultar em tempo real ou quase real a diversas florestas.
• Auxílio na gestão de crises
As crises em questão variam desde desastres naturais ou incitados pelo homem, em missões de busca e resgate a crises relacionadas ao surgimento de doenças.
No que diz respeito ao auxílio de gestão de crises, surgem exemplos, como o uso de IA combinada com a informação originada em satélites, que têm permitido fazer o mapeamento e previsão da progressão de incêndios florestais. Desta forma esses novos instrumentos têm permitido que a intervenção dos bombeiros seja mais precisa e revestida de maior eficácia. Igualmente têm-se explorado o possível uso de drones, mais uma vez associado, a IA para resgatar pessoas desaparecidas em áreas selvagens.
• Mais justiça social
Os problemas relacionados a justiça social continuam a ser bastante presentes nas nossas sociedades, isto é, os desafios da justiça social estão diretamente relacionados a aspetos como a redução ou eliminação de preconceitos alicerçados na raça, orientação sexual, religião, cidadania, deficiências, etc. Assim sendo têm-se pensado como o Big data pode ser útil na resolução dos problemas em questão.
A título de exemplo, temos o projeto de investigação da universidade Stanford que foi baseado no trabalho de uma entidade designada Affectiva, e em parceria com os laboratórios do MIT Media Lab, e do Autism Glass, desenvolveram um projeto vocacionado para o autismo.
Esse projeto consiste na automatização e reconhecimento de emoções por intermédio da IA para poder dar diretrizes em termos de comportamentos sociais, aos indivíduos com autismo para que a sua integração em convívios sociais seja facilitada.
• Melhor gestão das infraestruturas públicas
O desempenho das infraestruturas públicas pode ser melhorado se recorrermos ao uso de instrumentos de Big data e IA.
Existem alguns desafios ligados as mesmas e que se ultrapassados podem ser uma mais-valia para a sociedade, uma vez, que podem melhorar o funcionamento de setores importantes como o da energia, gestão resíduos e água, transportes, imóveis e planeamento urbano. A título de exemplo, o funcionamento das redes de semáforos pode ser melhorado recorrendo ao uso de informações captadas de câmaras de trânsito em tempo real, bem como, ao uso de informações proveniente de sensores embutidos nos mais diversos aparelhos (ou se preferimos provenientes dos sensores da internet das coisas (Internet of Things) para maximizar o fluxo dos veículos na estrada. A manutenção em antecedência de sistemas de transporte público, como comboios e infraestruturas públicas (incluindo pontes), para identificar e prevenir potenciais anomalias no funcionamento dessas mesmas estruturas.
Assim, o Big data está a criar novas oportunidades para a sociedade em geral e gerar benefícios para todos. Ao mesmo tempo também cria oportunidades para as empresas e, portanto, é um elemento de poder de mercado, pois promete revolucionar a forma como as empresas promoverão estratégias baseadas em dados para inovar, competir e capturar valor de informações profundas e atualizadas em tempo real ou quase real. O Big data permite às empresas ganharem vantagem competitiva. As empresas nunca tiveram tanto conhecimento acerca dos consumidores como correntemente o têm, e dessa forma o Big data apresenta simultaneamente oportunidades e desafios. Exploremos então de mais perto os custos e benefícios oferecidos pelo Big data nomeadamente para os consumidores.
2.1.4 Riscos potenciais para a sociedade
Alguns dos benefícios que podem emergir do progresso tecnológico são claros, porém, esse mesmo progresso tecnológico pode gerar alguns riscos para a sociedade.
Algumas previsões apontam que entre os anos de 2020 a 2060 o poder computacional possa vir a ultrapassar a capacidade humana em quase todas as áreas (Helbing, 2015). Esse facto tem sido alvo de preocupação para alguns dos visionários do ramo da tecnologia, especialistas tais como Bill Gates da Microsoft, Elon Musk da Tesla Motors e o cofundador da Apple Steve Wozniak, bem como para o físico Stephen Hawkings que ao longo do tempo foram deixando
avisos em relação aos aspetos negativos relacionados com a IA. Pois os mesmos a veem como um problema, porque segundo esses especialistas a IA pode submeter a humanidade a um perigo até maior do que o representado atualmente pelas armas nucleares (Helbing et al., 2016).
Mediante a tal situação alguns especialistas como Helbing et al. (2017) defendem que a informação personalizada (personalized information) constrói uma bolha em volta dos indivíduos, uma espécie de prisão digital para o seu pensamento, pois as pessoas estão menos expostas a outras opiniões, o que pode aumentar a polarização dentro das sociedades e por conseguinte potenciar conflitos. Pois a criatividade e o tão aclamado “pensar fora da caixa” não podem fluir propriamente, em condições em que tudo quanto se recebe é a resposta de si mesmo, ou seja, das suas próprias ideias.
A informação personalizada tende a reforçar padrões. Pois tal como Brundage et al. (2018) referem este efeito é conhecido como “câmaras de eco” em que os indivíduos só ouvem e recebem pontos de vistas que estejam alinhados com a sua forma de pensar ou que estejam alinhados com as suas crenças. Em suma, de acordo à Helbing e Pournaras (2015) “a centralized system of technocratic behavioural and social control using a super intelligent system would result in a new form of dictatorship”.
A partir de questões como estas pode-se relacionar o Big data e o Nudging, pois as inovadoras ferramentas do Big data podem apresentar vários usos. Assim, a tecnologia em questão pode ser uma faca de dois gumes, porque a mesma tecnologia pode ajudar na promoção de nacionalismos, bem como incentivar reações avessas as minorias, dar origem a resultados de eleições enviesadas, etc., segundo Helbing (2005).
“The combination of nudging with Big data about everyone´s behaviour, feeling and interest, if ever put in practice could eventually create something close to a totalitarian power” Helbing et al. (2017).
Essas preocupações relativamente a IA são agravadas, pelo facto de atualmente muito do tipo de comunicação que é levada à cabo dentro das sociedades modernas é mediada em algum grau por sistemas automatizados.
Assim, neste contexto, de acordo com Brundage et al. (2018) as características intrínsecas da IA tais como a escalabilidade, a tornam particularmente apropriada para enfraquecer ou distorcer o
discurso público através da produção de conteúdo persuasivo em larga escala, mas simultaneamente falso, o que pode fortalecer por um lado os regimes despóticos e por outro prejudicar o funcionamento correto até das democracias mais desenvolvidas.
Em suma, Big data e IA não são a mesma coisa, porém uma potencia a outra, pois é inegável que o Big data, a IA, cibernética e a economia comportamental (Behavioral economics) estão a moldar e a reformular as nossas sociedades, quer seja de forma mais positiva ou menos positiva.
Logo existe a emergência e a necessidade de submeter essas tecnologias que cada vez mais se difundem, aos valores das nossas sociedades, isto é, fazer delas compatíveis com os valores essenciais que governam as nossas sociedades. Valores tais como igualdade, justiça, equidade, etc. pois doutra forma as mesmas tarde ou cedo causaram dá-nos significativas as próprias sociedades, como nos alertam os especialistas.
As clivagens a nível de opiniões no campo da IA são bastante evidentes, desta forma iremos aprofundar a temática em questão de forma a perceber se serão estas opiniões fundamentadas ou excessivas.
Helbing et al. (2016) é a favor de que há razões para se pensar sobre o assunto de maneira mais crítica, uma vez que alguns países já recorreram ao uso de informação para tentar gerir as suas sociedades. Na década de 1970, o presidente chileno Salvador Allende criou programas informáticos, que incluíam inclusive modelos económicos que tentavam acompanhar o desempenho da economia em tempo real, com objetivo de melhorar a produtividade industrial (Medina, 2011).
Bem como a existência de países como, a título de exemplo, a Singapura que se têm servido do uso de programas como o Risk Assessment and Horizon Scanning que faz parte do centro de coordenação de segurança nacional para ajudar na administração da sociedade de acordo a informação que é obtida. O programa em questão consiste na recolha e análise de grandes volumes de informação, permitindo desta forma uma gestão antecipada de ameaças a integridade nacional do país, assim como ataques terroristas, doenças de natureza infeciosa e finalmente a gestão de crises financeiras (Kim et al., 2014).
A disposição por parte de outros países para emularem o modelo em questão potencia as opiniões mais críticas.
Em geral, os riscos relacionados à IA para o bem social são bastante semelhantes àqueles para usos mais rotineiros. Um dos maiores riscos é que as ferramentas e técnicas da IA podem ser mal utilizadas pelas autoridades e outras pessoas com acesso a elas (Michael et al., 2018). Exemplificando o ponto de vista acima exposto, temos a conduta do governo chinês que tem estado a explorar formas de obter informação online e offline para atribuir uma pontuação aos seus cidadãos (pontuação do cidadão). Essa pontuação varia entre 350 à 950 pontos em que a mesma estão associados custos e benefícios. Por exemplo um cidadão que tenha uma pontuação que exceda os 700 pode pedir um visto de viagem para Singapura não submetendo alguns documentos, de forma a agilizar o processo. Porém em caso de conduta considerada inadequada, os cidadãos podem sofrer custos como por exemplo ser impedidos de tirar um visto de viagem a título ilustrativo.
Porém, se por um lado alguns aspetos acima são conhecidos, por outro a ambiguidade mantêm-se, o pensamento que se segue abaixo exposto por Chen e Cheung (2017,p.357) nos permitem entender melhor esta relação:
“They are uncertain about what contributes to their social credit scores, how those scores are combined with the state system, and how their data is interpreted and used. In short, the big data-driven SCS is confronting Chinese citizens with major challenges to their privacy and personal data”.
Até a data a participação no sistema de creditação é opcional, porém, em 2020 ano em que o programa deixará de ser experimental para ser oficial, todas as entidades a quem a pontuação se destina, empresas, indivíduos a título de exemplo faram parte obrigatoriamente do programa. Várias entidades discordam com essa prática, por exemplo segundo a entidade European Group on Ethics in Science and New Technologies (2018, p.9), o melhoramento dos processos sociais baseados em recursos de IA que envolvam sistemas de pontuação social, violam ideias fundamentais como o da igualdade e liberdade. Pois ao invés de terem em consideração as diferentes características das pessoas, criam diferentes tipos de pessoas a semelhança dos sistemas de castas.
Bem como segundo Michael et al. (2018) e Helbing et al. (2016) o uso generalizado da censura na China exemplifica de forma mais explícita como a tecnologia pode ser instrumentalizada para fins políticos em estados autoritários.
Porém o pêndulo das intenções por detrás das motivações que embasam a IA oscila para os dois lados, isto é, pode ser efetivamente boa, pois, espera-se que o instrumento em causa possa vir a melhorar a governação, imputando mais coerência nas atividades levadas a cabo e em última instância proporcionar mais igualdade.
Bem como não há um consenso no campo em relação a sua natureza, porque, enquanto alguns autores e personalidades da área da tecnologia expressam grande preocupação em relação aos possíveis contornos menos positivos, que a IA pode assumir no futuro, tais como, as máquinas assumirem o controlo, outros vão exatamente no sentido contrário. Isto é esses especialistas acreditam que o debate sobre a inteligências artificial deve cingir-se aos acontecimentos presentes ou que estão em proximidade, para que o debate não seja destorcido e permita que as entidades interessadas concentrem-se em questões que realmente são preponderantes (AlgorithmWatch e Bertelsmann Stiftung, 2019).
Igualmente a falta de consenso na área é bastante patente, devido às ambiguidades que permeiam o próprio termo IA, ou seja, atualmente o debate em torno da IA deve-se maioritariamente aos mecanismos de decisão automática (ADM) e não necessariamente a IA de forma mais abrangente (AlgorithmWatch e Bertelsmann Stiftung, 2019).
Porém independentemente das ambiguidades existentes, há um consenso no sentido de que os cidadãos devem ser educados e /ou equipados com ferramentas, conhecimentos que os permitam navegar de forma mais tranquila nesse novo cenário criado pelas tecnologias em questão (Daten Ethik Kommission, 2018, p.4).
Outro risco potencial para a sociedade que pode ser gerado pelo Big data, prende-se com a privacidade.
Atualmente atividades que eram apenas do círculo íntimo ou partilhadas apenas com poucos indivíduos próximos dos sujeitos, agora quando desempenhadas no mundo digital deixam indícios bastante reveladores, pois, desvendam os interesses dos mesmos, informam sobre traços de personalidade, crenças, bem como quais são as suas possíveis intenções.
Lidar com essa problemática torna-se igualmente importante porque de acordo a Acquisti et al., (2015) o desgaste da privacidade pode ameaçar a nossa autonomia, não apenas como consumidores, mas também como cidadãos. Embora haja uma corrida frenética para a obtenção de volumes de informação cada vez maiores, é importante ter em mente que a partilha
de mais informação não tem de se refletir necessariamente em mais avanços ou progresso, nem tão pouco em melhores condições sociais.
As tecnologias da informação estão cada vez mais presentes nas nossas vidas quer a nível pessoal ou profissional, e portanto, o controle sobre os dados pessoais tornou-se um quesito inerente ligado as questões de escolha pessoal, autonomia e poder socioeconômico.
Os dilemas relacionados a privacidade representam um grande desafio na medida em que esse campo ainda é bastante nubloso, e nem sempre é possível estabelecer a relação direta entre causa e efeito.
2.2 Estratégias comerciais das empresas à luz do Big data
O Big data pode cria valor em várias áreas para as empresas. O conhecimento extraído dos dados permite que as empresas ofereçam produtos inovadores e personalizados. Com recurso a técnicas como a mineração de dados (data mining), o machine learning, análise de sentimentos (sentiment analysis), bem como o acesso a algumas das tecnologias mais avançadas como a metadata, computing cloud, o business intelligence (BI), a visualização, etc. as empresas estão a conseguir distinguir de forma mais precisa quais sãs as preferências dos consumidores (Manyika et al., 2011). Essa melhor perceção acerca dos consumidores está a permitir que as empresas façam uma segmentação mais eficaz dos mercados.
O Big data também tem criado valor na medida em que tem servido como suporte à decisão humana e em alguns casos tem até substituído a mesma por intermédio de algoritmos automatizados. A criação de mais transparência através de uma acessibilidade mais fácil da informação para as várias partes interessadas (stakeholders) tem sido igualmente apontada como uma fonte de valor.
Por exemplo no setor da manufaturação, a integração de informação proveniente da área de desenvolvimento e investigação, assim com da engenharia podem reduzir significativamente o tempo para introduzir um determinado produto no mercado bem como permitir um incremento da sua qualidade.
Finalmente com o Big data é usar uma abordagem experimental de forma a descobrir necessidades, expor vulnerabilidades e arranjar meios de melhorar o desempenho. Por isso, o Big data é apontado como um fator revolucionário para a produtividade, inovação e concorrência nos mercados (Manyika et al., 2011).
Em resumo, para além dos ganhos que as empresas podem adquirir em termos de lucros, as mesmas também podem adquirir ganhos de desempenho, por isso é que na era digital o Big data é percecionado como sendo o novo bem, em que se verifica uma grande procura do mesmo, pois oferece a possibilidade de robustecer os lucros das empresas (Wagner et al., 2018).
Nas secções seguintes, apresentarei de forma mais aprofundada três tipos de estratégia das empresas com potencial para beneficiar do Big data.
2.2.1 Discriminação de preços
A discriminação de preços é uma estratégia de preço e marketing em que a mesma consiste na fixação de preços diferentes para as várias unidades consumidas de um bem de acordo com a disposição a pagar dos consumidores. Assim como pode ser a fixação de diferentes preços para escalões diferentes de consumo ou ainda a fixação de diferentes preços para grupos de consumidores (ou mercados) diferentes (Mateus e Mateus, 2011).
Por um lado, a discriminação de preços revela-se ser uma estratégia atrativa para as empresas na medida em que a mesma quando corretamente implementada pode gerar maiores lucros as empresas. Pois os consumidores fazem diferentes valorações dos produtos que consomem, e portanto, aqueles consumidores que fazem uma valoração mais alta do produto igualmente apresentarão uma disponibilidade a pagar maior. O acesso a este conhecimento permitirá as empresas praticarem um preço mais elevado em comparação se o preço fosse uniforme.
Por outro lado, é uma estratégia exigente, pois determinados pré-requisitos devem ser cumpridos, requisitos tais como a existência de poder de mercado, em que o mesmo consiste na capacidade das empresas praticarem rentavelmente um preço acima do seu custo marginal. A capacidade de segmentar o mercado é igualmente um pré-requisito para a implementação da estratégia acima citada, bem como a capacidade de proibir ou limitar revenda do produto para que as empresas possam oferecer os produtos a um preço específico e único para os consumidores de cada segmento do mercado (Belleflamme e Peitz, 2010).
Quando nos referimos a discriminação de preços é-nos crucial mencionar que a mesma apresenta graus. Existe discriminação de primeiro grau, segundo e terceiro.
A discriminação perfeita também conhecida como discriminação de 1º grau ou ainda conhecida por discriminação de preços personalizados, é aquela em que o vendedor cobra um diferente preço por cada unidade vendida (Shapiro e Varian, 1999). O preço cobrado é exatamente compatível com a disposição máxima a pagar dos consumidores por cada unidade. Esse tipo de discriminação exige uma grande quantidade de informação sobre o consumidor. Antigamente para que a mesma fosse aferida era necessário uma relação muito próxima entre as partes envolvidas, porém o Big data esta a reverter tal situação.
Esse é o tipo de discriminação que seria a ideal para as empresas, porque todo o excedente do consumidor seria extraído. O Big data está a possibilitar que as empresas pratiquem de forma cada vez mais frequente esse tipo de discriminação.
Quando as empresas não conseguem identificar o tipo de consumidor que têm em mãos as mesmas recorrem a mecanismos de autosseleção de forma a ser possível a identificação dos mesmos, bem como as suas disponibilidades a pagar. O preço aplicado a todos os consumidores é o mesmo, porém em função das unidades de produto compradas o preço vária. A título de exemplo temos os descontos de quantidade. Este tipo de discriminação é conhecida como discriminação de 2º grau, ou por discriminação de preços não lineares ou também como discriminação de preços de menu (Belleflamme e Peitz, 2010).
Por último, existe a discriminação de 3º grau ou de preços de grupo (Shapiro e Varian, 1999) que é caracterizada pelo preço praticado por unidade ser uniforme, mas diferir em função das características observáveis dos consumidores. Este tipo de discriminação é aplicável desde que seja possível aferir as disposições a pagar dos consumidores através de algumas características notáveis, tais como idade, localização, etc. Os descontos para estudantes, crianças, seniores, etc. são exemplos do tipo de discriminação em questão.
Ainda no contexto de discriminação de preços, fala-se paralelamente em discriminação de preço tendo em conta a localização geográfica em que a mesma se caracteriza por existir diferenças nos preços dos mesmos produtos que são vendidos em diferentes países ou regiões (Armstrong, 2006).
2.2.2. Diferenciação de produto
De acordo com Chamberlain (1961) a diferenciação de produto consiste numa forma de distinguir os produtos ou serviços de uma empresa em relação às demais, considerando como
base a importância atribuída pelo comprador. Esta é apenas uma das várias definições que existem na literatura para se referir a diferenciação de produto.
Porém, na sua forma mais elementar, diferenciar produtos é conseguir fazer com que o consumidor distinga claramente o produto da empresa dos outros existentes no mercado. Seja através das características que o próprio produto apresenta, ou pela sua localização (em função das preferências dos consumidores).
De notar que no que diz respeito à diferenciação de produto, a mesma pode conter uma dimensão tangível ou real e uma dimensão intangível, isto é, na realidade as diferenças não existem, mas o consumidor consegue as percecionar através do marketing e outras técnicas que as empresas utilizam para dar visibilidade ao produto (Pereira et al., 2017).
A diferenciação de produto também tem a sua taxonomia própria em que a mesma pode ser horizontal ou vertical.
A diferenciação horizontal de forma sucinta é aquela que se prende com a variedade, uma vez que de entre os produtos existentes, cada produto é escolhido apenas por alguns consumidores. Enquanto a diferenciação vertical, tem a ver com a qualidade, pois os consumidores concordam que um produto é preferível em relação ao outro (Belleflamme e Peitz, 2010).
À semelhança da discriminação de preços ambas são estratégias que permitem às empresas praticarem preços superiores em relação a situações em que as mesmas não são implementadas e logo permitem as empresas auferirem maiores lucros e poder de mercado. Tanto um quanto o outro são objetivos bastante desejáveis por parte das empresas.
Recordar que o poder de mercado para as empresas geralmente tem origem naquilo a que Belleflamme e Peitz (2010) apelidaram de Market mix (mistura de mercado), em que o mesmo é constituído pelo preço, produto/s e pela promoção ou comercialização.
O Market mix deve no entanto ser suportado pelo comportamento das empresas como por exemplo, a variável estratégica que utilizam, se o preço é uniforme ou não, diferenciação do produto a sua localização, organização, distribuição, etc., bem como o seu ambiente competitivo, que se refere aos consumidores com diferentes níveis de informação e custos de mudança, a título de exemplo.
Em conclusão, a diferenciação de produto é uma estratégia bastante atrativa para as empresas, pois quando bem-sucedida as mesmas conseguem não só escudar-se da concorrência em preços, que baixa sempre as lucros, bem como permite que as mesmas adquiram poder de mercado. Por isso as empresas têm sempre que possível interesse em diferenciar o seu produto (Calliud, 2016).
2.2.3. Publicidade alvo
A publicidade alvo ou publicidade direcionada consiste na estratégia comercial em que as empresas apenas apresentam publicidades, que estejam de acordo aos interesses/preferências dos consumidores. Isto é, ao contrário da publicidade que é dirigida para o público em geral, a publicidade alvo dirige-se especificamente a um determinado público ou nicho.
Essa estratégia comercial não é uma invenção do Big data, muito pelo contrário a mesma é anterior ao fenómeno em questão, porém, anteriormente ao Big data as empresas praticavam esta estratégia comercial a um nível bastante reduto.
Pois a prática dessa estratégia requer que as empresas disponham de ferramentas para fazer chegar as publicidades personalizadas ou ofertas especiais, ao seu público-alvo segundo Esteves e Resende (2016).
Por isso a mesma é mais suscetível de ser praticada em mercados digitais ou em mercados nos quais as empresas servem-se do uso de aplicações informáticas (Apps), para enviar mensagens específicas aos consumidores. E assim conseguirem ter algum controlo sobre informações relevantes, que acabam por ser cruciais para revelar os padrões de consumo do seu público-alvo. A localização ou o rastro do histórico de consumo enquadram- se nesta categoria de informação (Esteves e Resende, 2016). Uma vez que o Big data ganhou apenas grande destaque nos últimos anos, então somos obrigados a admitir que até não muito tempo atrás a forma de eleição de fazer publicidade foi a forma mais costumeira, ou se preferimos, as publicidades estavam mais vocacionadas aos meios tradicionais e o público em geral sem qualquer distinção (Esteves e Resende, 2016).
Torna-se relevante falar de publicidade, porque em muitos casos ou ainda melhor em alguns mercados, a única forma de sensibilizar os consumidores em relação à existência de determinados produtos e/ou ofertas é através de publicidades, em que as mesmas neste caso assumem um perfil informativo.
Graças às avançadas ferramentas de análise do Big data, é possível enviar cupões a partir de telemóveis, assim como enviar publicidade com base na localização. As publicidades que têm como ponto de referência a localização podem emergir, de uma delimitação geográfica ou assumir uma forma mais agressiva em termos de markting. Prática conhecida como geo-conquesting, uma vez que consiste no envio de publicidade específica, para clientes de outras empresas com base na sua localização. E finalmente, também graças às avançadas ferramentas de análise do Big data é possível recorrer às aplicações que permitem fazer pesquisas de produtos (Esteves e Resende, 2017).
Segue-se abaixo uma citação que ilustra, com mais precisão o ponto de vista exposto: "location via mapping software, their browser and search history, whom and what they like on social networks like Facebook, the songs and videos they have streamed, their retail purchase history, the contents of their online reviews and blog posts." Esteves e Resende (2017,p.2). Todas estas atividades munem as empresas com informações que são muito relevantes para as mesmas. Notar que se a população em geral não fosse adepta de tecnologias como Smartphones, e outros aparelhos portáveis como tablets, etc., como nos fazem saber Esteves e Resende (2017), talvez essa comunicação tão interativa entre empresas e consumidores não fosse tão efetiva e num cenário mais extremo, talvez a mesma não fosse possível.
Com essas tecnologias é possível ter-se uma reação quase que imediata sobre os produtos e/ou serviços que os consumidores preferem ou retiram mais utilidade. De igual modo as empresas conseguem manter um fluxo de informação bastante denso sobre os consumidores e as suas rotinas diárias, o que por sua vez permite que a cadeia de estímulos relacionados a comunicação ocorra de forma contínua e livre de confinamentos temporais e espaciais.
As empresas ganharam mérito ao conseguirem não só melhorar a estratégia em questão, isto é, conseguiram torná-la muito mais eficaz, bem como conseguiram amplificar a escala a que a mesma é praticada.
De forma paralela, a publicidade alvo é peculiar em relação ao outro tipo de publicidade, pois, segundo Esteves e Resende (2016), a mesma permite que o fluxo de informação e portanto os consumidores desinformados (ou se preferirmos os consumidores míopes) beneficiam da maior abundância de informação o que de certa forma permite que as suas escolhas sejam mais otimizadas. Igualmente, segundo as mesmas autoras, a publicidade alvo pode servir como porta
de entrada para a prática de outra estratégia comercial, ou seja, como porta de entrada para a discriminação de preços, sobre a qual nos debruçaremos um pouco nas páginas anteriores. A publicidade alvo pode ser benéfica para os consumidores na medida em que lhes podem ser apresentados serviços e produtos mais relevantes de acordo com as suas preferências, reduzindo-lhes até o custo em termos de dispêndio de tempo em efetuar pesquisas.
As empresas conseguem paralelamente sair beneficiadas, na medida em que as mesmas conseguem minimizar os desperdícios publicitários, bem como permite que publicidade alvo tornar-se mais tangível devido à facilidade das empresas ajustarem as suas mensagens ao perfil dos seus consumidores (Esteves e Resende, 2016; Matz e Netzer, 2017). A publicidade direcionada ou publicidade alvo possibilita ainda que as empresas compreendam com precisão quais são os consumidores interessados nos seus produtos.
2.3. Riscos e benefícios potenciais para os consumidores
Apesar das inúmeras vantagens que o Big data pode oferecer às empresas, existem riscos para os consumidores relacionados com a sua privacidade e a segurança (possibilidade de roubo de identidade a título de exemplo), a propriedade intelectual, desvantagens associadas à discriminação de preços, publicidade alvo, IA, entre outros.
Por questões de afinidade com o tema a ser desenvolvido nessa dissertação, daremos mais ênfase às problemáticas relacionadas com a privacidade, discriminação de preços, publicidade alvo e a IA.
2.3.1 Inteligência artificial
A tomada de decisão por empresas ou Estados com base em grandes bases de dados recorrendo à IA e a algoritmos automáticos é já uma realidade. No entanto, este fenómeno é visto com desconfiança da parte dos indivíduos, no seu papel de consumidores ou cidadãos (Grzymek et al., 2019).
Através das mudanças que IA possibilita a comunicação entre os indivíduos, empresas, Estados, etc. pode sofrer alterações, de modo que cada vez mais essas entidades são mediadas por sistemas automatizados que não só produzem mas também apresentam conteúdo.
Outra opinião que flui no mesmo sentido é a de Shorey e Howard, (2016) que argumentam sobre o facto das tecnologias do Big data permitirem a agregação de grandes quantidades de
informação, muitas das vezes sem o conhecimento dos agentes em questão, sendo que essa informação pode ser utilizada para vários fins.
A partir de questões como estas podemos relacionar o Big data e o Nudging (que foi explorado com mais detalhe na secção 2.1.2), pois o uso das avançadas ferramentas que o Big data possibilita podem permitir que várias entidades que interajam direta ou indiretamente com os consumidores, sigam práticas menos positivas que podem emergir do Nudging.
Desta forma entidades como a The European Consumer Organisation (2018, p.12) através do pensamento que se segue nos faz saber que:
“It is necessary to look at all these and many other questions in detail to analyse the privacy implications of Artificial Intelligence and ensure that it is developed and used in a way that is respectful of consumers’ fundamental rights and the core values of our society. Further to this, enforcers need also to look at the enforcement of data protection and consumer protection law in tandem as these both areas of law seek to empower the user as a data subject (in relation to the collection and use of his or her personal data) and as a consumer (in relation to the protection of his or her economic interests)”.
De notar que o campo da inteligência artificial é um dos mais promissores a nível tecnológico, assim como é um dos campos em cujas descobertas nas últimas décadas tem sido bastantes significativas. Apesar dos avanços, os mesmos não têm sido suficientes para calar as vozes que cada vez de forma mais insistente clamam por sistemas de informação que sejam transparentes, confiáveis, e que sejam controlados pelos utilizadores (antecipado assim uma emancipação digital ou como alguns especialistas preferem chamar, digital-self determination). 2.3.2. Privacidade
O conceito de privacidade não é necessariamente novo, pois já existiam preocupações ligadas à mesma. No entanto, certos adventos históricos, tais como a criação da internet, o avanço das tecnologias, o desenvolvimento das tecnologias da informação, sem nos esquecermos de mencionar da transição que se está a dar para a economia digital, potenciaram o acréscimo de preocupações ligadas à privacidade.
Por um lado, dá-se a inversão de padrões em que os indivíduos deixam de ser meros consumidores de informação e graças às tecnologias passam a ser produtores de grandes
E por outro lado, temos as organizações que têm acesso a essa informação. O uso que é dado à mesma pelas próprias organizações e por terceiros é totalmente desconhecido pelos consumidores.
A questão da economia da privacidade é importante porque a informação que os consumidores partilham, ou não, tem, valor económico e à mesma podemos associar ganhos intangíveis, tais como os ganhos psicológicos (um like dado pelos amigos no facebook, por exemplo) ou tangíveis como o acesso a um desconto imediato que um determinado comerciante esteja a oferecer. Assim, este tema é de particular interesse para esta tese.
Falar de informação torna-se igualmente crucial quando falamos em termos económicos, porque a esses ganhos podemos associar custos de oportunidade. Informação é poder, e a proteção ou partilha da informação pessoal dos consumidores pode influenciar significativamente a concorrência nos mercados.
Contudo, tem-se verificado de uma forma geral um acréscimo de preocupações relacionadas com a privacidade por parte dos consumidores, uma vez que estudos mostram, por exemplo, que 73% do público norte-americano opôs-se aos mecanismos de busca que rastreavam o seu histórico de pesquisas, mesmo que esses mecanismos servissem para melhorar os seus resultados de pesquisa. E 68% do mesmo público igualmente opôs-se à utilização da informação dos consumidores para ajudar os publicitários a desenvolverem publicidades direcionadas (Newman, 2013).
Não obstante essa crescente preocupação dos consumidores em relação à sua privacidade, os mesmos consumidores fazem um uso bastante intensivo de tecnologias que rastreiam e fazem a partilha da sua informação com outras entidades. O que revela um comportamento paradoxal por parte dos consumidores (Acquisti, et al., 2016; Acquisti e Grossklags, 2004).
Lembrar que atualmente as máquinas já têm acesso a uma parte significativa das nossas vidas quotidianas. Portanto, não é má ideia pensar duas vezes antes de compartilhar os nossos dados pessoais, ou melhor a nossa informação pessoal (Helbing et al., 2016).
Esse comportamento paradoxal pode ser explicado por vários fatores que coexistem e, por conseguinte, não são mutuamente exclusivos. Por exemplo, os consumidores podem conscientemente, em troca de alguns benefícios, querer partilhar a sua informação ou retrair a mesma.
Bem como a crescente complexidade das tecnologias de informação e a variedade de atividades que diariamente os consumidores levam a cabo online são fatores que interferem e contribuem para esse paradoxo (Acquisti et al., 2017).
Os estudos sobre estas questões, por um lado apresentam as vantagens da partilha de informação pessoal com as empresas, pois permite que haja um aumento do bem-estar quer do indivíduo quer da sociedade. Por outro lado, em outros cenários o quadro é completamente reverso.
A consequência prática que resulta dessa situação é que não se pode dizer de forma inequívoca, em termos puramente económicos, que a proteção ou partilha de informação pessoal é positiva ou negativa (Acquisti et al., 2016).
Porém independentemente da ambiguidade que todo o contexto em volta da privacidade suscita não podemos negar que a mesma é um ponto crítico na era do Big data ou melhor ainda “ If this is the age of information, then privacy is the issue of our times” Acquisti et al. (2015, p.509). Os problemas relacionados a privacidade representam um grande desafio na medida em que nem sempre é possível estabelecer a relação direta entre causa e efeito, tal como foi anteriormente referido. Por exemplo, os indivíduos de acordo ao nível de preocupação que apresentam em relação a sua privacidade podem ser qualificados como, fundamentalistas, pragmáticos e despreocupados de acordo a classificação de Westin (1991). Esta classificação é bastante interessante, pois, as pessoas que se encontram nas diferentes categorias comportar-se-ão de diferentes formas, ou seja, a quantidade de informação partilhada irá variar.
Naturalmente indivíduos que sejam mais reticentes em relação a sua privacidade terão um comportamento mais reservado em conformidade a partilha de informação. E o inverso também se verifica (John et al., 2010). Também é curioso saber que até a preocupação dos indivíduos em conexão com a privacidade não é uma variável constante ao longo do tempo.
Mais uma vez esse comportamento é derivado da dificuldade que os indivíduos têm perante em saber o que fazer com a sua privacidade, ou explicando melhor a existência de incerteza, bem como a existência de uma relativa dependência do contexto e finalmente a maleabilidade que a informação pode sofrer, faz com que os indivíduos busquem pistas ao seu redor para orientarem o seu comportamento (Acquisti et al.,2015).
A incerteza, a dependência do contexto e a maleabilidade da informação, são variáveis que mutuamente se influenciam. Por exemplo quanto mais incerteza existir maior é a dependência do contexto. Por isso podemos verificar que em determinados períodos a temperatura social pode fazer com que as pessoas estejam mais alertas para questões relacionadas a privacidade e em outras apresentem um maior relaxamento.
Isto aplica-se também as categorias supracitadas, um mesmo indivíduo que se encontre em uma determinada categoria pode ter um comportamento bastante oscilante.
Porém fincar a orientação do comportamento nas pistas emergentes do contexto pode trazer consequências inesperadas, tais como, levar os indivíduos a adotarem um comportamento que vai contra as suas reais intenções.
Contudo, tal como os autores citados nos alertam, não podemos assumir uma posição rígida e negligenciar o facto de que seria incorreto concluir que levar as pessoas a pensarem sobre questões de privacidade necessariamente fará com que elas divulguem ou não informações. Em última instância o seu interesse ainda prevalece.
Ainda com a privacidade vêm associados outros problemas que prendem-se com a constatação de que os consumidores raramente estão completamente conscientes acerca dos benefícios ou malefícios associados com a partilha ou não partilha da sua informação pessoal, devido à posição desvantajosa de possuírem informação incompleta.
Mais especificamente no caso da privacidade, os problemas prendem-se com a constatação que os consumidores raramente estão completamente conscientes de quais são os benefícios ou malefícios associados com a partilha ou não partilha da sua informação pessoal, devido à posição desvantajosa de possuírem informação incompleta.
E por último, apesar da existência das tecnologias que visam reforçar a proteção da privacidade dos indivíduos e que de certa forma conferem algum controlo aos indivíduos, podemos verificar que muitos deles não tem a sofisticação técnica e nem têm consciência do que é necessário para proteger e regular as várias dimensões da sua informação pessoal.
2.3.3. Discriminação de preços
A discriminação de preços relaciona-se com o Big data na medida em que as grandes quantidades de informação que o Big data fornece sobre os indivíduos permite que as empresas