UNIVERSIDADE CATÓLICA PORTUGUESA
MULTILAYER PERCEPTRON MODELLING OF
INDUSTRIAL CULTIVATION PROCESSES FOR DNA
VACCINE PRODUCTION CONTROL AND
OPTIMIZATION
Tese apresentada à Universidade Católica Portuguesa para obtenção do grau de doutor em Informática
Por
Daniel Alexandre Felício da Silva
Faculdade de Engenharia
Dezembro 2013
08
Fall
UNIVERSIDADE CATÓLICA PORTUGUESA
MULTILAYER PERCEPTRON MODELLING OF
INDUSTRIAL CULTIVATION PROCESSES FOR DNA
VACCINE PRODUCTION CONTROL AND
OPTIMIZATION
Tese apresentada para obtenção do grau de doutor em Informática
Por Daniel Alexandre Felício da Silva
Sob orientação de Prof. Doutor Tito Lívio dos Santos Silva
Sob co-orientação de Prof. Doutora Cecília Ribeiro da Cruz Calado
Faculdade de Engenharia
MULTILAYER PERCEPTRON MODELLING OF INDUSTRIAL CULTIVATION PROCESSES FOR DNA VACCINE PRODUCTION CONTROL AND OPTIMIZATION
I
Abstract
Bioinformatics is one of the emerging fields in Computer Sciences with an increasingly more impactful role, in a symbiotic-like association with Biology and Bioprocesses, aiding in the knowledge of complex mechanisms and elements in both these fields of knowledge. The permanent and exponential development of equipments that allow large-scale data acquisition, has set-in-motion the need to create methodologies to store and analyze that same data, in a manner that researchers can extract its meaning, with a high degree of confidence and precision, in a viable time-frame, and therefore help them in their research.
However, there are techniques and procedures where the possibility of extracting detailed information in real-time is limited, either by the absence of adequate equipment or by the logistics’ impossibility often times associated with a thorough gathering of information regarding those processes. The industrial cultivation process is one of those cases where environmental values such as Dissolved Oxygen, pH, Temperature and others are available in real-time but the information regarding the complex molecular constituents of the cultivation are missing, only being obtainable by off-line analysis.
In industry, as a way of minimizing the risk of contaminations, the number of samples collected for analysis along the fermentative process is always kept at a minimal level and can even be non-existent in most cases. Because of this, the real knowledge on the cultivation process is limited, most of the times, to the initial state of the cultivation and its final state, as obtaining exact readings along the cultivation is quite difficult. All control decisions on the system are based on indirect evaluations as the rate of oxygen consumption or the pH variation. This limited knowledge may impair the reproducibility of the cultivation process, as cells are living organisms that present a natural variability. That natural variability is further enhanced by slight variations of the environmental cultivation conditions. This is crucial in case of biopharmaceutics production due to the high regulatory constraints.
DNA plasmid vaccines are increasingly moving to the forefront of pharmaceutical products due to their potential advantage over viral vectors, and due to the theoretical advantages of DNA-vaccines over subunit and whole cells vaccines. The
II MULTILAYER PERCEPTRON MODELLING OF INDUSTRIAL CULTIVATION PROCESSES FOR DNA VACCINE PRODUCTION CONTROL AND OPTIMIZATION
plasmid vaccine production consists in the growth, in bioreactors, of bacteria such as Escherichia coli containing the plasmid vector with engineered DNA that is afterwards extracted. However, as previous referred, it is highly relevant to control the whole cultivation process, as there is still a great need for process optimization. This optimization can result in high-yield production with reduced production costs.
One solution that has been presented for this kind of control and optimizations is based on computational simulation of the processes. Computer simulations, or in silico, are often used to quickly test multiple scenarios without the need to allocate specific resources, human or material, as for instance high-cost reagents, turning these processes into more viable ones. With the more complex work occurring in the early stages of model development. Furthermore, mathematical models may also be useful to estimate, along extensive periods of time, the complex molecular constituents of a cultivation process by using the real time analysis gathered by the sensors generally used in industry.
This work’s objective is to use computational methodologies to determine the behavior of a recombinant E. coli culture designed to produce plasmids for DNA vaccination. This work was performed in the Engineering Faculty of the Catholic University of Portugal and the Instituto de Medicina Molecular.
In this work we propose the use of a Multilayer Perceptron (MLP) in order to monitor and understand the behavior of E.coli DH5- containing the vector pVAX-LacZ plasmid, during different batch and fed-batch cultivations. The focus of this work consisted in studying the behavior of cultivations with different initial pre-set conditions concerning the carbon-source, pH and feeding strategy, and with intermediate perturbations determined experimentally. With this goal, a set of cultivations were defined as examples, in order to allow us to explore a wide universe in terms of variables, as well as establishing a comparison between cultivations with similar initial conditions.
MLPs are part of a larger universe referred as Artificial Neural Networks (ANNs). They are considered universal approximators, allowing for the identification of complex patterns by learning training examples. These examples will influence future state predictions. This characteristic allows a great adaptability to different models as
MULTILAYER PERCEPTRON MODELLING OF INDUSTRIAL CULTIVATION PROCESSES FOR DNA VACCINE PRODUCTION CONTROL AND OPTIMIZATION
III
the main limitation of MLPs is centered in the quality and quantity of training examples, rather than pre-determined functions and parameters.
Unlike conventional modelling techniques, MLPs rely on the data rather than theoretical assumptions. This means that the possibility of introducing bias in the pattern recognition is less likely. Moreover, MLPs can serve as hypothesis validators.
In this work we were able to obtain model fit values (R2) that in most cases were superior to 0.7. These values are even more interesting when we take into account the number of variables we attempted to predict and cross it with the number of training examples we were able to produce. In order to achieve our goal we defined the following real time and off-line variables. The off-line variables were: concentration of Biomass, Plasmid, Glucose, Glycerol and Acetate. These variables are not quantified in real time, as it is required to extract a sample from the bioreactor and subsequently analyzed it. The on-line variables, acquired in real time were: Dissolved Oxygen Concentration, pH, Stirring Rate and Feeding Rate.
The technical and logistics inability to quantify each variable at the same exact rate illustrates two fundamental issues with the basic cultivation monitoring process: the standardization of the moment in which the variables are quantified; and the determination of the next state of the cultivation. In this work, we establish that the prediction was made using 1-hour spaced intervals using a cross-validation training methodology. This 1-hour spacing was determined by analyzing data available from Martins (2008) and observing no significant increase in network prediction with 15 minute, 30 minute or 60 minute intervals.
Finally, we present a possible methodology for optimizing fed-batch cultivations based on Genetic Algorithms (GA). In this approach, information and parameters of the trained MLP are used to create a cultivation policy that will be applied during the industrial process.
Genetic Algorithms are evolutionary algorithms based on computational adaptations of biological evolutionary theories. Our Genetic Algorithm approach is based on a chromosome representation of a decision tree designed to determine the course of experimental action according to the state of the controlled variables. These
IV MULTILAYER PERCEPTRON MODELLING OF INDUSTRIAL CULTIVATION PROCESSES FOR DNA VACCINE PRODUCTION CONTROL AND OPTIMIZATION
evaluations are based on the values of Glycerol, Glucose and Acetate and according to their values a feeding rate is determined for the next time-point. This methodology in an early stage could allow the definition of a wider example space and then translate into a cultivation strategy closer to the optimal solution.
This research work aims to answer this emerging need and contribute to the advance of the knowledge in the area, opening new paths for further research that natural and desirably will follow.
Key-Words
Artificial Neural Networks (ANN), Multilayer Perceptron (MLP), Cultivation, Escherichia coli, pVAX-LacZ, Plasmid DNA, Vaccine, Metabolism, Genetic Algorithm (GA), Bioinformatics, Biomedical Engineering
MULTILAYER PERCEPTRON MODELLING OF INDUSTRIAL CULTIVATION PROCESSES FOR DNA VACCINE PRODUCTION CONTROL AND OPTIMIZATION
V
Resumo
A Bioinformática é uma das áreas emergentes das Ciências da Computação que vem desempenhando um papel cada vez mais premente, numa associação quase simbiótica com a Biologia e com os Bioprocessos, auxiliando na compreensão de elementos e mecanismos complexos nestas duas áreas do conhecimento. O permanente e exponencial desenvolvimento de equipamentos que permitem a aquisição e tratamento de dados em volumes elevados e com grande precisão, desencadeou a necessidade da criação de metodologias de armazenamento e de análise desses mesmos dados, de forma a que os investigadores possam extrair um significado, com elevado grau de confiança e precisão, em tempo útil, auxiliando-os na sua investigação.
No entanto, existem técnicas e procedimentos onde a possibilidade de obtenção de informação detalhada e em tempo real é limitada, seja pela ausência de equipamentos adequados, seja pela impossibilidade logística que muitas vezes está associada a um levantamento minucioso de informação desses processos. O processo de fermentação industrial é um desses casos. Os processos de fermentação industrial são um desses exemplos onde variáveis ambientais como Oxigénio Dissolvido, pH, Temperatura e outros se encontram disponíveis em tempo real mas informação relativa a constituintes moleculares complexos da cultura não são possíveis de determinar em tempo real sendo necessário uma análise a posteriori.
Na indústria, por forma a minimizar o risco de contaminações, o número de amostras extraídas para análises a serem efectuadas durante o processo fermentativo é sempre mantido a um nível mínimo, podendo mesmo serem inexistentes na maioria dos casos. Desta forma, o conhecimento efectivo sobre o processo fermentativo está limitado, na maior parte das vezes, ao estado inicial da fermentação e ao seu estado final, dado que nas fases intermédias se revela difícil a determinação exacta do estado da fermentação. Todo o trabalho de controlo sobre o sistema é baseado em avaliações indirectas como sejam o ritmo de consumo de oxigénio, ou a identificação do valor exacto do pH. Este conhecimento limitado
VI MULTILAYER PERCEPTRON MODELLING OF INDUSTRIAL CULTIVATION PROCESSES FOR DNA VACCINE PRODUCTION CONTROL AND OPTIMIZATION
dificulta a reprodutibilidade do processo fermentativo, na medida em que as células são organismos vivos que apresentam uma variabilidade natural, sendo essa ainda mais amplificada por pequenas variações das condições da fermentação. Este factor é crucial no caso de produção de produtos biofarmacêuticos devido ao elevado número de requerimentos de qualidade exigido pelas entidades reguladoras.
Vacinas de ADN plasmídico têm vindo a ganhar destaque no universo dos produtos farmacêuticos devido às suas potenciais vantagens quando comparados com vectores virais, e devido às vantagens, teóricas, de vacinas de DNA quando comparadas com vacinas celulares ou de sub-unidades do agente infeccioso. A produção de uma vacina de plasmídeo consiste no crescimento em bioreactores de bactérias, como por exemplo Escherichia coli, que por sua vez contêm um vector plasmídico com ADN manipulado que é posteriormente extraído. Contudo, como referido anteriormente é imperativo controlar todo o processo de fermentação na medida em que ainda existe uma grande necessidade em termos de optimização do processo de forma a se conseguir obter rendimentos, em termos de produto, mais elevados reduzindo, simultaneamente, os custos.
Uma das soluções para este tipo de controlo e optimização consiste na simulação computacional de processos. O recurso a simulações computacionais, ou in silico, é uma forma frequentemente usada para testar múltiplos cenários sem a necessidade de alocar recursos específicos sejam eles humanos ou materiais, como por exemplo reagentes de elevado custo, tornando desta forma estes processos mais controláveis e viáveis. Efectivamente, o grande custo deste tipo de abordagem centra-se na fase inicial de desenvolvimento, tornando-se o custo cada vez menor com o evoluir do processo. De igual forma, a modelações matemáticas podem ser igualmente úteis para estimar, durante períodos temporais largos, os constituintes moleculares complexos existentes num processo fermentativo simplesmente através de análises em tempo real fornecidas pelos sensores e sondas usados na indústria.
O objectivo deste trabalho consiste em implementar metodologias computacionais de forma a determinar o comportamento de uma cultura de E. Coli recombinante cujo objectivo é produzir plasmídeos destinados a serem usados em vacinas de ADN. Este trabalho foi desenvolvido na Faculdade de Engenharia da Universidade Católica Portuguesa e no Instituto de Medicina Molecular.
MULTILAYER PERCEPTRON MODELLING OF INDUSTRIAL CULTIVATION PROCESSES FOR DNA VACCINE PRODUCTION CONTROL AND OPTIMIZATION
VII
Neste trabalho é proposta a utilização de um Multilayer Peceptron (MLP) de forma a compreender o comportamento de uma cultura de E.coli DH5-, durante diversas fermentações batch e fed-batch, contendo o plasmideo pVAX-LacZ que irá funcionar como vector de ADN. O foco deste trabalho consiste em estudar o comportamento de fermentações com condições iniciais de fontes de carbono, pH, e estratégia de alimentação pré-definidas e adicionar perturbações intermédias determinadas experimentalmente. Para atingir este objectivo um conjunto de fermentações foram definidas como exemplos, de forma a permitir explorar um universo abrangente em termos de variáveis e simultaneamente permitindo estabelecer uma comparação entre fermentações com condições iniciais semelhantes.
Os MLPs fazem parte de um conceito mais amplo que é denominado de Artificial Neural Networks - Redes Neuronais Artificiais (ANN). Os MLPs são considerados aproximadores universais, permitindo a identificação de padrões complexos através de uma aprendizagem supervisionada por exemplos. Estes exemplos irão influenciar as previsões de estados futuros. Esta característica permite uma grande adaptabilidade a diferentes modelos na medida em que a principal limitação dos MLPs reside na quantidade e qualidade dos exemplos de treino já que estes têm o impacto mais significativo na qualidade da aproximação dos dados reais e teóricos.
Ao contrário de métodos de modelação convencionais, os MLPs baseiam os seus resultados em dados reais ao invés de conceitos teóricos. Isto significa que a possibilidade de ser introduzido preconceito (bias) no reconhecimento de padrões é menos provável. De igual forma os MLP, podem funcionar como ferramentas de validação de hipóteses quando conseguem atingir os mesmos resultados.
Neste trabalho conseguimos obter valores de previsão (R2) que na sua grande maioria foram superiores a 0.7. Estes valores são ainda mais interessantes quando considerarmos o elevado número de variáveis que foram tentadas prever e cruzarmos esse número com o número de exemplos que foram possíveis determinar em laboratório. De forma a alcançar o objectivo deste trabalho foram definidas as seguintes variáveis on-line e off-line. As variáveis off-line foram as seguintes: concentrações de Biomassa, Plasmídeo, Glucose, Glicerol e Acetato. Estas variáveis não são quantificadas em tempo real. Para efectuar a sua quantificação é
VIII MULTILAYER PERCEPTRON MODELLING OF INDUSTRIAL CULTIVATION PROCESSES FOR DNA VACCINE PRODUCTION CONTROL AND OPTIMIZATION
necessário extrair uma amostra a partir do bioreactor durante a fermentação e posteriormente analisá-la. As variáveis on-line, por sua vez, são adquiridas em tempo real usando as sondas e sensores disponíveis no bioreactor e foram as seguintes: Oxigénio Dissolvido, pH, Ritmo de Agitação e Ritmo de Alimentação.
A incapacidade técnica e logística para quantificar cada variável em simultâneo demonstra dois problemas fundamentais: a uniformização do momento em que as variáveis são quantificadas e a determinação do estado seguinte da fermentação. Neste trabalho estabelecemos que as previsões seriam feitas tendo como objectivo determinar o estado da fermentação 1 hora depois da amostra extraída usando uma metodologia de validação cruzada (cross-validation) no treino do MLP. Este espaçamento temporal de 1 hora foi determinado analisando os dados disponíveis em Martins (2008) e observando que não existia ganho de desempenho de previsão usando intervalos de 15 ou 30 minutos quando comparados com os intervalos de 60 minutos.
Finalmente, é apresentada uma possível metodologia para a optimização de fermentações fed-batch usando Algoritmos Genéticos (AG). Nesta abordagem, a informação e parâmetros do MLP previamente determinado são usados para criar uma politica de alimentação que será aplicada durante o processo industrial.
Algoritmos Genéticos são algoritmos evolutivos baseados em adaptações das teorias evolutivas biológicas. A abordagem de Algoritmos Genéticos apresentada é baseada numa representação, sob o formato de um cromossoma, de uma árvore de decisão cujo objectivo consiste em determinar as acções a serem desempenhadas experimentalmente de acordo com o estado actual da fermentação. Estas avaliações são baseadas nos valores de Glicerol, Glucose e Acetato e consoante esses valores um ritmo de alimentação é determinado para o próximo intervalo entre extracção de amostras funcionando assim como uma política dinâmica de fermentação. Esta metodologia numa fase inicial permite ainda a definição de um espaço de exemplos mais amplo através da exploração dos limites dos dados existentes, evoluindo a política de alimentação para parâmetros que originem uma solução óptima.
MULTILAYER PERCEPTRON MODELLING OF INDUSTRIAL CULTIVATION PROCESSES FOR DNA VACCINE PRODUCTION CONTROL AND OPTIMIZATION
IX
Palavras Chave
Artificial Neural Networks (ANN), Multilayer Perceptron (MLP), Fermentação, Escherichia coli, pVAX-LacZ, Plasmídeo ADN, Vacina, Metabolismo, Algoritmo Genético (AG), Bioinformática, Engenharia Biomédica.
MULTILAYER PERCEPTRON MODELLING OF INDUSTRIAL CULTIVATION PROCESSES FOR DNA VACCINE PRODUCTION CONTROL AND OPTIMIZATION
XI
List of abbreviations
ADN (Portuguese version of DNA) - Deoxyribonucleic Acid
ADP
– Adenosine DiphosphateAI - Artificial Intelligence
AIDS – Acquired Immunodeficiency Syndrome ANN - Artificial Neural Networks
ATP – Adenosine Triphosphate
BISTIC
– Biomedical Information Science and Technology Initiative ConsortiumDNA (English version of ADN) - Deoxyribonucleic Acid
FADH
2– Reduced Flavin Adenine Dinucleotide FTIR - Fourier Transform Infrared Spectroscopy GAVI – Global Alliance for Vaccines and ImmunizationHPLC
– High-performance Liquid Chromatography MLP - Multilayer PerceptronNAD
+- Oxidized Nicotinamide Adenine DinucleotideNADH
–Reduced Nicotinamide Adenine DinucleotideO.D.
– Optical DensityPCR - P
ol
ymerase Chain ReactionPERT - Product-Enhanced Reverse Transcriptase R&D – Research and Development
RNA
- Ribonucleic AcidSOD
- Superoxide Dismutase TCA - Tricarboxylic Acid CycleUNICEF – United Nations Children’s Fund WHO – World Health Organization
MULTILAYER PERCEPTRON MODELLING OF INDUSTRIAL CULTIVATION PROCESSES FOR DNA VACCINE PRODUCTION CONTROL AND OPTIMIZATION
XIII
Index
Abstract ... I Key-Words ... IV Resumo ... V Palavras Chave ... IX Acknowledgments ... XXIII 1 Objectives ... 1 1.1. Bioinformatics ... 3 1.2 Background... 5 2 Vaccine Relevance ... 17 2.1 History ... 182.2. Overview of vaccine costs ... 19
2.3 Plasmids ... 23 2.3.1 Cloning Vectors ...23 2.3.2 Plasmids ...24 2.3.3 Plasmid Production ...26 3. Microbial cultivations ... 28 3.1 Cell cycle ... 28 3.2 Metabolism ... 30
3.3 Cell cultivation conditions ... 35
3.4 cultivation strategies ... 38
3.4.1 Batch culture ...39
3.4.2 Continuous and Fed-Batch Cultures ...44
4 Artificial Intelligence ... 46
4.1 Artificial Neural Networks ... 47
4.1.1 Biological Neural Networks ...48
4.1.2 Computational (Artificial) Neural Networks ...49
4.1.3 Different Types of Artificial Neural Networks ...50
4.1.4 General Structure of Artificial Neural Networks ...50
08
Fall
XIV MULTILAYER PERCEPTRON MODELLING OF INDUSTRIAL CULTIVATION PROCESSES FOR DNA VACCINE PRODUCTION CONTROL AND OPTIMIZATION
4.1.5 Training an Artificial Neural Network ...51
4.1.6 Multilayer Perceptron - MLP ...52
4.2 Genetic Algorithms ... 59
4.2.1 The Computational View ...59
5. Materials and Methods ... 64
5.1 Cultivation Prediction Algorithm using Artificial Neural Networks ... 64
5.2 Laboratory Work ... 75
5.2.1 Cultivation ...76
5.2.2 Process Bottlenecks and Broth sampling ...81
5.2.3 Analyses of C-sources, plasmids and by-products ...83
5.3 Fed-Batch optimization using Genetic Algorithms ... 85
5.3.1 General Features ...87 5.3.2 Chromosome Structure...88 5.3.3 Branches ...89 5.3.4 Selection ...90 5.3.5 Crossover ...90 5.3.6 Mutation ...92 5.3.7 Environmental conditions ...93
5.4 Experimental use of the selected chromosome ... 94
6. Results... 96
6.1 Batch and Fed-Batch Cultivations ... 99
6.2 Simulations ... 115
6.2.1 Self-test ... 115
6.2.2 Cross-validation (Leave-one-out) ... 117
6.2.3 Testing with other author’s cultivations ... 118
6.3 Optimization ... 119 6.3.1 Implementation ... 119 7. Discussion ... 136 7.1 Simulations ... 142 7.2 Optimization ... 143 8. Conclusions ... 146 8.1 Final Considerations... 147 References ... 149
MULTILAYER PERCEPTRON MODELLING OF INDUSTRIAL CULTIVATION PROCESSES FOR DNA VACCINE PRODUCTION CONTROL AND OPTIMIZATION
XV Appendix I ... 171 Cultivation DA ... 172 Cultivation DB ... 182 Cultivation DD ... 194 Cultivation DE ... 205 Cultivation DF ... 216 Cultivation DH ... 227 Cultivation DM ... 238 Fermentation DX ... 249 Cultivation DY ... 260 Cultivation DZ ... 271 Appendix II ... 282 Cultivation SA ... 283 Cultivation SB ... 292 Cultivation SC ... 301 Cultivation SD ... 310 Cultivation SE ... 319
Appendix III – Equipment ... 328
High-performance Liquid Chromatography, VWR- Hitachi-Elite Lachrom ... 328
Base equipment ... 328 Bioreactor ... 328 Appendix IV – HPLC Methods ... 331 HPLC Method Plasmid ... 331 Eluents ... 331 Injection ... 331 Oven ... 332 UV1 ... 332 HPLC Method Metabolites ... 333 Eluents ... 333 Injection ... 333 Oven ... 334 UV1 ... 334 RI2 ... 335
XVI MULTILAYER PERCEPTRON MODELLING OF INDUSTRIAL CULTIVATION PROCESSES FOR DNA VACCINE PRODUCTION CONTROL AND OPTIMIZATION
Appendix V - Software ... 336
HPLC ... 336
Simulations ... 336
MULTILAYER PERCEPTRON MODELLING OF INDUSTRIAL CULTIVATION PROCESSES FOR DNA VACCINE PRODUCTION CONTROL AND OPTIMIZATION
XVII
Index of Figures
FIGURE 1STAGES OF VACCINE RESEARCH AND DEVELOPMENT ... 20
FIGURE 2PRODUCTION COST CALCULATED ACCORDING TO THE PRODUCTION BATCH ... 22
FIGURE 3COST ASSOCIATED WITH PRESENTATION OF VACCINES ... 22
FIGURE 4E.COLI CELL CYCLE ... 29
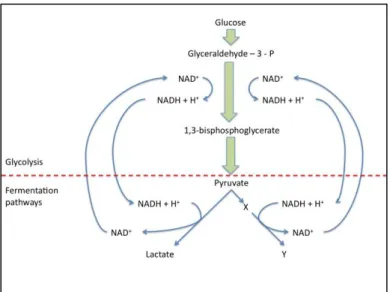
FIGURE 5TRANSITION FROM GLYCOLYSIS TO FERMENTATION PATHWAY ... 31
FIGURE 6MODEL OF THE AEROBIC OVERFLOW METABOLISM IN E. COLI. ... 33
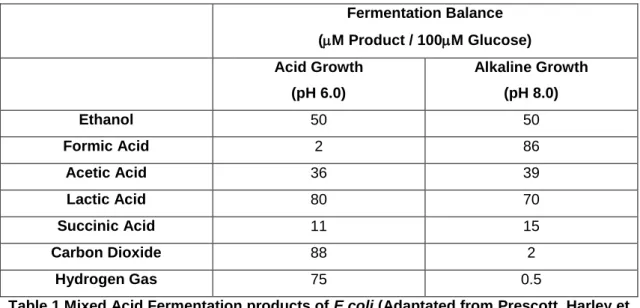
FIGURE 7GRAPHIC REPRESENTATION OF THE METABOLIC PATHWAY INVOLVED IN THE AEROBIC DEGRADATION OF GLUCOSE AND OVERFLOW METABOLISM; AND THE ANAEROBIC FERMENTATION OF MIXED ACIDS IN E. COLI. ... 34
FIGURE 8MICROBIAL GROWTH CURVE IN A CLOSED SYSTEM ... 40
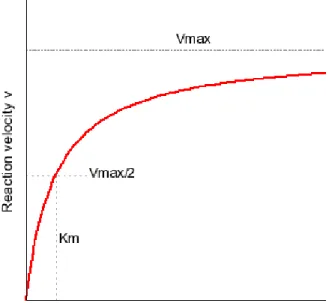
FIGURE 9MICHAELIS-MENTEN KINETICS REPRESENTATION OF THE DEPENDENCE OF ENZYME ACTIVITY UPON SUBSTRATE CONCENTRATION. ... 42
FIGURE 10REPRESENTATION OF A SIMPLE ARTIFICIAL NEURON ... 51
FIGURE 11EXAMPLE OF A SIMPLE PERCEPTRON WITH 5 INPUTS AND 3 OUTPUTS ... 53
FIGURE 12THE SIGMOID FUNCTION ... 54
FIGURE 13COMPARING TRAINING ERROR VS GENERALIZATION ERROR ... 56
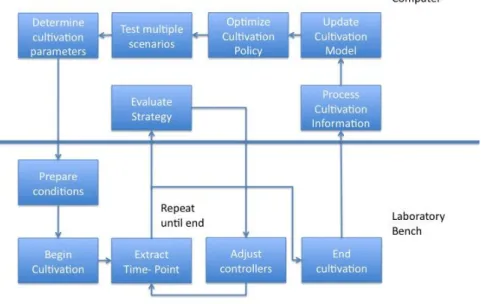
FIGURE 14OPTIMIZATION WORKFLOW ... 64
FIGURE 15CHEMICAL STRUCTURE OF GLUCOSE ... 66
FIGURE 16CHEMICAL STRUCTURE OF GLYCEROL ... 66
FIGURE 17REPRESENTATION OF OPTICAL DENSITY READING USING A SPECTOPHOTOMETER ... 68
FIGURE 18CALIBRATION OF THE FEEDING PUMP USING THE FEEDING SOLUTION. ... 69
FIGURE 19MLP REPRESENTATION ... 75
FIGURE 20 BIOSTAT PLUS CONTROLER OPERATING DURING A CULTIVATION SETUP. ... 79
FIGURE 21 BIOREACTOR-SETUP BEFORE INOCULATION. ... 80
FIGURE 22 REPRESENTATION OF THE WORKFLOW ASSOCIATED WITH THE CULTIVATION. ... 81
FIGURE 23REPRESENTATION OF THE POPULATION EVOLUTION DURING A GA IMPLEMENTATION ... 85
FIGURE 24SEQUENTIAL LEVEL APPROACH ... 88
FIGURE 25PROXIMITY-ASSOCIATION APPROACH ... 90
FIGURE 26TWO EXAMPLES OF CROSSOVER STRATEGIES. ... 92
FIGURE 27FEEDING RATE DETERMINATION FUNCTION. ... 97
FIGURE 28CULTIVATION DA ... 99
FIGURE 29CULTIVATION DB ... 100
FIGURE 30CULTIVATION DD ... 101
FIGURE 31CULTIVATION DE ... 102
XVIII MULTILAYER PERCEPTRON MODELLING OF INDUSTRIAL CULTIVATION PROCESSES FOR DNA VACCINE PRODUCTION CONTROL AND OPTIMIZATION
FIGURE 33CULTIVATION DH ... 104 FIGURE 34CULTIVATION DM ... 105 FIGURE 35FEB-BATCH CULTIVATION DX ... 107 FIGURE 36FED-BATCH CULTIVATION DY. ... 108 FIGURE 37FED-BATCH CULTIVATION DZ. ... 109
FIGURE 38EVOLUTION OF PH CONDITIONS ALONG CULTIVATIONS ... 110 FIGURE 39CULTIVATION AVERAGE PH. ... 111 FIGURE 40EVOLUTION OF DISSOLVED OXYGEN ALONG CULTIVATIONS ... 112 FIGURE 41EVOLUTION OF STIRRING RATE ALONG CULTIVATIONS. ... 113 FIGURE 42COMPARISON BETWEEN THE AVERAGE VALUES OF DOC(%) AND ITS STDEV ... 114 FIGURE 43AVERAGE STIR FOR EACH CULTIVATION. ... 114 FIGURE 44 EVALUATION PART OF THE CHROMOSOME REPRESENTED AS DECISION TREE ... 121 FIGURE 45COMPARISON BETWEEN BIOMASS CONCENTRATION FOR CULTURE DW CULTURE AND
PREDICTED VALUES. ... 124
FIGURE 46COMPARISON BETWEEN PLASMID CONCENTRATION FOR CULTURE DW CULTURE AND PREDICTED VALUES. ... 124 FIGURE 47COMPARISON BETWEEN GLUCOSE CONCENTRATION FOR CULTURE DW CULTURE AND
PREDICTED VALUES. ... 125 FIGURE 48COMPARISON BETWEEN GLYCEROL CONCENTRATION FOR CULTURE DW CULTURE AND
PREDICTED VALUES. ... 125 FIGURE 49COMPARISON BETWEEN ACETATE CONCENTRATION FOR CULTURE DW CULTURE AND
PREDICTED VALUES. ... 126 FIGURE 50COMPARISON OF DWBIOMASS AND THE SIMULATED DATA BY INPUTTING T TIME-POINT IN ORDER TO DETERMINE TIME POINT T+1 ... 128 FIGURE 51COMPARISON OF DWPLASMID AND THE SIMULATED DATA BY INPUTTING T TIME-POINT IN ORDER TO DETERMINE TIME POINT T+1 ... 129 FIGURE 52COMPARISON OF DWGLUCOSE AND THE SIMULATED DATA BY INPUTTING T TIME-POINT
IN ORDER TO DETERMINE TIME POINT T+1 ... 129 FIGURE 53COMPARISON OF DWGLYCEROL AND THE SIMULATED DATA BY INPUTTING T TIME-POINT IN ORDER TO DETERMINE TIME POINT T+1 ... 130 FIGURE 54COMPARISON OF DWACETATE AND THE SIMULATED DATA BY INPUTTING T TIME-POINT IN
MULTILAYER PERCEPTRON MODELLING OF INDUSTRIAL CULTIVATION PROCESSES FOR DNA VACCINE PRODUCTION CONTROL AND OPTIMIZATION
XIX
Index of Tables
TABLE 1MIXED ACID FERMENTATION PRODUCTS OF E.COLI ... 32 TABLE 2VARIOUS TRIALS DESIGNED TO DETERMINE OPTIMAL NETWORK TOPOLOGY ... 71
TABLE 3COMPARISON OF TRAINING AND VALIDATION ERRORS BETWEEN 2 HIDDEN LAYER
TOPOLOGIES ... 72 TABLE 4COMPARISON BETWEEN THE NUMBER OF EPOCHS REQUIRED TO STOP TRAINING WITHOUT
OVERFITTING ... 72 TABLE 5COMPARISON OF THE AVERAGE R2 OBTAINED BY EACH TOPOLOGY OVER A 25 SIMULATION
SET ... 72 TABLE 6COMPARISON OF THE MAXIMUM R2 VALUE OBTAINED BY EACH TOPOLOGY FOR EACH
VARIABLE ... 73 TABLE 7COMPARISON OF THE AVERAGE R2 OF EACH VARIABLE AT DIFFERENT TIME-POINT
INTERVALS ... 74 TABLE 8COMPARISON OF THE MAXIMUM R2 OBTAINED IN ONE SIMULATION FOR EACH VARIABLE .. 74 TABLE 9POSSIBLE CARBON SOURCE STRATEGIES USED TO DETERMINE THE MOST ROBUST
CHROMOSOME ... 93 TABLE 10COMPARISON OF CARBON SOURCE INITIAL CONDITION FOR CULTIVATIONS DX AND DW 94 TABLE 11GENERAL COMPARISON BETWEEN CULTIVATIONS ... 98 TABLE 12R2ANALYSIS IN SELF-TEST CONDITIONS ... 116 TABLE 13R2ANALYSIS OF DDCULTIVATION (SELF-TEST). ... 116 TABLE 14AVERAGE R2 WITH A CROSS-VALIDATION STRATEGY. ... 117 TABLE 15AVERAGE R2 ANALYSIS WHEN TESTING CULTIVATION VALUES FROM OTHER AUTHORS . 118 TABLE 16R2 RELATIVE TO THE REAL DATA ... 126 TABLE 17FED VALUES USED IN CULTIVATIONS DX,DY,DZ AND DW ... 127 TABLE 18FITNESS VALUES WHEN PREDICTING THE FOLLOWING TIME-POINT BASED ON THE REAL
DW CULTIVATION DATA. ... 131 TABLE 19IMPACT OF ZEROED INITIAL CONDITIONS VS REAL DATA FROM DW ... 132 TABLE 20COMPARISON OF THE MAXIMUM PLASMID CONCENTRATION (MG/L) OBTAINED THE
“Believe you can and you’re halfway there” Theodore Roosevelt
MULTILAYER PERCEPTRON MODELLING OF INDUSTRIAL CULTIVATION PROCESSES FOR DNA VACCINE PRODUCTION CONTROL AND OPTIMIZATION
XXIII
Acknowledgments
I would like to acknowledge the many people that in some way or another have helped and influenced me during my PhD.
First of all to my supervisors: Professors Tito Silva and Cecília Calado, for their patience, friendship and guidance during this whole process and their continued efforts to help me in this journey.
To Professor Carmo-Fonseca who was responsible for allowing me to pursue my PhD in Bioinformatics at the Instituto de Medicina Molecular.
To all the people at IMM I was privileged to know and many of whom I consider great friends. To the people at UBCSI and it’s group leader Professor Luís Moita, for teaching me that in science you must be meticulous and have the ability to block the outside distractions. An extended thank you to the whole group: Catarina, Rui, Pedro Alves, Helena, Pedro Simões, Bruno, Raquel, Nuno and Teresa for a wonderful first year in science.
To Marta Agostinho and Inês Crisóstomo, that in different stages, were responsible for the IMM PhD programme. In both of you I found always the support I needed in solving the “outlier” case of the computer scientist who was on a biomedical doctoral programme.
To my friends and co-workers at USI: Pedro, Daniel, Emanuela and Ruben. For helping me during these 5 years and always being there. You are some of the best co-workers a person can ask for.
To Drª Margarida Pinto-Gago, also for her support during this period. For allowing me the flexibility to spend so many long hours at the Faculdade de Engenharia da Universidade Católica. Without that flexibility none of this work would be possible.
To João Carriço and Francisco Pinto, for their good talks and friendship even outside the scope of IMM tutors.
XXIV MULTILAYER PERCEPTRON MODELLING OF INDUSTRIAL CULTIVATION PROCESSES FOR DNA VACCINE PRODUCTION CONTROL AND OPTIMIZATION
To Marta Lopes for helping me with some of the cultivations, namely serving as another set of hands to collect some of the time-points.
To everyone else at Professor’s Cecilia Lab who has helped me: Inês Vitoriano, Andreia Couto and Kevin Sales.
To professor Barata Marques, the director of the faculty, for his institutional support mainly in the later stages of this PhD.
A special thank you to all my friends at the GDIMM and “Rapazes da Aldeia” both great experiences with great friends that were ultimately responsible for helping me keep my sanity over these years. You are too many to mention by name but all have had a very important role.
To everyone involved with the “Cientistas de pé” project: David, Romeu, Sandra, Sofia Vaz, Sofia Leite, Bruno, Cheila, João and Ivette. Thank you for the laughs and for helping me find the confidence necessary to do one of the hardest, but also more exciting, experiences of my life.
To the people (children and adults) at “Escola da Paz” for their friendship and work with under-privileged children. Their ability to love and nurture helps me everyday to be more tolerant and open-minded.
To the great people of Lisboa Navigators, you helped my regain my competitive edge and the will to overcome all obstacles by preparing and working hard. You are true champions.
To João, my oldest and dearest friend, and his wife Ana. Your friendship and your love is one of the things I most cherish and you are a big part of my life.
To my family for their support, from my cousins to my godfathers I love you all very much.
MULTILAYER PERCEPTRON MODELLING OF INDUSTRIAL CULTIVATION PROCESSES FOR DNA VACCINE PRODUCTION CONTROL AND OPTIMIZATION
XXV
And finally, to my parents for all your love and support. All I am it is because of you. You are the light of my life, my inspiration and my rock. I hope I keep making you proud. Love you both.
This work was partially supported by PTDC/BIO/69242/2006 research grant, FCT, Portugal and by IMM/BD/30/2006 PhD Fellowship Grant, IMM, Portugal.
MULTILAYER PERCEPTRON MODELLING OF INDUSTRIAL CULTIVATION PROCESSES FOR DNA VACCINE PRODUCTION CONTROL AND OPTIMIZATION
1
1 Objectives
The objective of this work is to study, model, simulate and optimize the production of DNA-vaccines (based on plasmids) conducted by cultivation of the cell host Escherichia coli.
The fundamental idea behind DNA vaccines (also known as genetic vaccines) (Aurisicchio and Ciliberto 2011) is to induce immune responses against the expressed in vivo of recombinant antigens encoded by genetically engineered DNA vectors. After immunization, host cellular machinery facilitates the expression of vector-encoded genes (Flingai, Czerwonko et al. 2013). DNA vaccines have the ability to stimulate both facets (humoural and cellular) of the adaptive immune system. This represents an advantage when comparing to protein vaccines that in turn although promoting the humoural response it also impairs the immune protection against viral infections. Vaccines, as whole cells, have maintained a very strong safety profile. Nevertheless, live-attenuated and inactivated pathogens used in traditional vaccines carry the potential to return to virulence, which may cause pathogenic infections in vivo. DNA vaccines, on the other hand, do not use microorganisms and therefore avoid the risk of reversion (Flingai, Czerwonko et al. 2013).
Plasmids are highly sought out vectors for gene therapy and DNA vaccination, because of their multiple advantages over viral vectors, including large packaging capacity, stability without integration and reduced toxicity (Stoll and Calos 2002). This, distinguishes them from viral or bacterial vectors, which frequently induce anti-vector immunity, which makes boosting with the same anti-vector unsuccessful (Flingai, Czerwonko et al. 2013). The past decade has produced four successful DNA plasmid products licensed for animal use: one for the treatment of West Nile virus in horses (Davis, Chang et al. 2001); two hormones, one growth hormone-releasing hormone (GHRH) designed for gene therapy in swine (Draghia-Akli, Ellis et al. 2003) and another against hematopoietic necrosis virus in salmon (Garver, LaPatra et al. 2005) and finally, one for the treatment of melanoma in dogs (Bergman, Camps-Palau et al.
2 MULTILAYER PERCEPTRON MODELLING OF INDUSTRIAL CULTIVATION PROCESSES FOR DNA VACCINE PRODUCTION CONTROL AND OPTIMIZATION
2006). In the case of the West Nile virus vaccine it has since undergone clinical trials for human application (Martin, Pierson et al. 2007).
Recombinant Escherichia coli cells have been used to produce (by various cultivation processes) the largest bulk of plasmid vectors currently used in clinical trials. (Tejeda-Mansir and Montesinos 2008). The production of large-scale doses of plasmid is done in bioreactors. Such bioreactors are designed to control and monitor large volumes of E. coli cultures. However, the plasmid production process is quite different from the production of heterologous proteins. Therefore, one major drawback related to vaccines based on plasmids, is that it is missing methodologies to produce large quantities of plasmids at industrial scales. Those methodologies include the development of mathematical or computational models that describe the plasmid production process, and evaluate how the cultivation environment may affect plasmid production. This information is vital, not only to control product end quality, but also to optimize the cultivation process.
We propose to develop an Artificial Neural Network Algorithm that monitors and predicts the growth of specific strains of E. coli DH5- with-in a 1-hour time frame. This 1-hour spacing was determined by analyzing data available from (Martins 2008) and observing no decrease in network prediction with 15 minute, 30 minute or 60 minute intervals.
This work will allow for the understanding of how each monitored variable influences the system. Additionally the development of an Optimization Algorithm that uses the knowledge provided by the ANN and designs a cultivation strategy adequate for industrial production of plasmid with higher plasmid production yields is proposed.
Although this thesis’s work is related to the computer science field we must also take into account the bioprocess aspect of the work performed. In order to bridge the gap between Computer Scientists, Bio-engineers and other fields of knowledge some concepts, while general, are explained in some detail in the introduction section.
MULTILAYER PERCEPTRON MODELLING OF INDUSTRIAL CULTIVATION PROCESSES FOR DNA VACCINE PRODUCTION CONTROL AND OPTIMIZATION
3
1.1. Bioinformatics
In the year 2000 the BISTIC Definition Committee defined BioInformatics as the: “Research, development, or application of computational tools and approaches for expanding the use of biological, medical, behavioral or health data, including those to acquire, store, organize, archive, analyze, or visualize such data.” Whereas Computational Biology is: “The development and application of data-analytical and theoretical methods, mathematical modelling and computational simulation techniques to the study of biological, behavioral, and social systems.”
Although the definitions seem to overlap one thing is certain: technology as allowed for great advances in the medical research field but also greater challenges in terms of data understanding and applicability.
Bioinformatics and Computational Biology span through various fields and applications such as:
- Data integration - Networked Science
- Biological Modelling (Morris, Bean et al. 2005; Swedlow, Lewis et al. 2006)
Biological modelling has provided very interesting insights towards understating the complexity of life.
Semantic networks are developed to group and classify concepts that help create a base of knowledge (Alonso-Calvo, Maojo et al. 2007; Deus, Stanislaus et al. 2008; Pesquita, Faria et al. 2009). Because of the wide the range of some of these concepts, it is required to narrow the scope. Different computation applications (or projects) have been developed to address various biological issues such as: FGF (Zheng, Shi et al. 2007) that determines familiarity between genes; IRESite (Mokrejs, Masek et al. 2010) determines internal ribosome entry sites; JASPAR (Portales-Casamar, Thongjuea et al. 2010) a open-access database for transcription factor binding profiles; deepBase (Yang, Shao et al. 2010) a database for deep sequencing data; tacg (Mangalam 2002) for DNA pattern matching; Exonmine (Mollet, Ben-Dov
4 MULTILAYER PERCEPTRON MODELLING OF INDUSTRIAL CULTIVATION PROCESSES FOR DNA VACCINE PRODUCTION CONTROL AND OPTIMIZATION
et al. 2010) a database for alternative splicing events; 3D-footprint (Contreras-Moreira 2010) a database of binding specificity for protein-DNA complexes.
The development of high-throughput techniques has allowed for a wider and more detailed view of cellular mechanisms. One of the most explored aspects consists in determining and predicting protein interactions (Wojcik and Schachter 2001; Wojcik, Boneca et al. 2002; Wu and Lonardi 2008). Another method consists in linking publications’ data (Kersey and Apweiler 2006). These different and vast sources of information, require systematic organizing in order to retrieve relevant information for researchers (Albeck, MacBeath et al. 2006).
Protein-protein interaction datasets contain an abundance of data but the knowledge of the interactome remains incomplete due to a lack of uniformity in the data, both a consequence of differences in the origins and the managing of the different datasets (Hakes, Pinney et al. 2008). In order to use Protein-protein interactions to experimentally change cellular function a better understanding of the cellular protein interactions network is required. This would allow the creation of novel biological responses through engineered proteins or small molecules (Pawson and Nash 2003). This means an increase in the level of detail and comprehension of the descriptions of interatomic forces is essential to accurately integrate features such as the salt effects of pH to better mimic experimental conditions as well as expand the timescale of simulations (Dodson, Lane et al. 2008) in a way that can be semantically significant.
The development and application of advanced techniques for modelling, optimizing and controlling bioprocesses, in order to support decisions in their design and operation, is another relevant field in bioinformatics. This is particularly pertinent as the high costs of biopharmaceutics are in part due to the production costs. Modelling and simulation of the bioprocess may be used to control the process itself, leading to a more economic product that is in accordance to the regulatory requirements.
Artificial Neural Networks and Evolutionary Computational Algorithms, for example, are being used in order to design and optimize a new pneumococcal conjugate vaccine customized to Brazilian most prevalent PS serotypes (Nicoletti, Bertini et al. 2013).
MULTILAYER PERCEPTRON MODELLING OF INDUSTRIAL CULTIVATION PROCESSES FOR DNA VACCINE PRODUCTION CONTROL AND OPTIMIZATION
5
1.2 Background
Biopharmaceutics, such as the plasmid-DNA used in vaccination and gene therapy, are complex molecules difficult to characterize, and its isoforms and purity degree depend on the production process and on the characteristics of living cells such as Escherichia coli. In other words, the end product quality will depend on the host cell cultivation reproducibility.
The need to control and optimize bioprocess has led to many different approaches. These approaches have ranged from trying to optimize the initial cultivation conditions, such as cultivation medium, pH, temperature, dissolved oxygen, or the cultivation strategy (i.e. continuous, batch or fed-batch), all with the single purpose to achieve a higher yield in production while limiting the typical problems associated with cultivations. The most commonly used optimization strategies are the ‘‘one variable at a time’’, orthogonal array design, or response surface methodology. However, the ‘‘one variable at a time’’ strategy is time consuming and fails to acknowledge the combined effect of all the variables and internal or external factors involved in most of these complicated bioprocesses (Tian, Liu et al. 2013). Moreover, the kinetic models, based on mass balance equations, using the main variables of the process, most of the times are not able to represent critical non-linear and complex interrelationships that exist in a recombinant culture. On this scenario neural networks may enable a more productive data analysis.
Characteristics of recombinant cultures
Recombinant cultures require a high degree of sterility and are strongly sensitive to environmental changes (Johnson 1987; Rani and Rao 1999). The products are generated in low concentrations and consequently even marginal improvements can be economically significant (Patnaik 2002; Calado, Ferreira et al. 2004). Furthermore, biological processes are both time-variant and non-linear, because of the physiological and morphological changes, such as normal genetic mutations and plasmid instability, and the complex interrelationships that exist between the cell host
6 MULTILAYER PERCEPTRON MODELLING OF INDUSTRIAL CULTIVATION PROCESSES FOR DNA VACCINE PRODUCTION CONTROL AND OPTIMIZATION
growth, plasmid stability, consumption of nutrients and production and consumption of inhibitory products (Karim, Yoshida et al. 1997).
Another problem resides within the kinetics (Eungdamrong and Iyengar 2004) of cellular growth and product formation (Klein, Hou et al. 2002; Goesmann, Linke et al. 2003). The kinetics can be linear or non-linear, single-phase or multiphase Linear kinetic models include constant rate and first order kinetics. Non-linear kinetic models comprise exponential, logistic or second order (Eungdamrong and Iyengar 2004; Mitchell, von Meien et al. 2004).
Real-time state quantification is made very difficult by the numerous environmental (Patnaik 2002). And even if some technological advances have allowed for on-line measurements of extra-cellular environments there is still the issue of intra-cellular conditions (Karim, Yoshida et al. 1997). Biomass concentration and metabolic state conditions are only available off-line with a significant time delay (Glassey, Ignova et al. 1997; Karim, Yoshida et al. 1997). Biomass, for example, is very easy to calculate on a small scale but it still requires the measurement to be done off-line (Diaz, Lelong et al. 1999).
Limitations associated with the mixing devices and measuring instruments (including cost) (Royce 1993) as well as the weaknesses of noise filtering methods (Patnaik 1997) make it harder to achieve either a perfect mixing or a complete removal of noise. These problems escalate when we transfer our problem base to an industrial framework. Consequently novel techniques are required to cope with these necessities. Indeed, large reactors (30 to 50 L capacity) present less than ideal macroscopic homogeneity, when compared with the smaller-scale bioreactors (Mayr, Horvat et al. 1992; Pedersen, Bundgaard-Nielsen et al. 1994; Larsson, Tornkvist et al. 1996), and the magnitude of this problem only increases when we scale further up to undustrial production reactors with volumes larger than 50 L.
The Escherichia coli bacteria and fed-batch cultivation strategies
The use of bacteria, such as E.coli, in bioprocesses in industrial pharmaceutical production is well established and widespread as its genetics are well understood making it simpler to manipulate. Moreover they possess the capability to produce
MULTILAYER PERCEPTRON MODELLING OF INDUSTRIAL CULTIVATION PROCESSES FOR DNA VACCINE PRODUCTION CONTROL AND OPTIMIZATION
7
high-density cultivations on inexpensive media (Rocha, Neves et al. 2005; Gnoth, Jenzsch et al. 2008; Keseler, Bonavides-Martinez et al. 2009). However, growing recombinant E. coli in high-cell density cultures requires a high degree of control of the process variables during a period of time that can exceed 50h of operation (Nicoletti, Bertini et al. 2013). In order to fully optimize the cultivation process skilled operators must supervise the cultivation during its full duration in order to determine the responses to each phase of the metabolic growth and, when required, determine the moment where the shift from the batch to fed-batch phase occurs (Kim, Lee et al. 2004). Furthermore, cultivations are subject to distortions that may result from deviations in the initial conditions or along the process (Jenzsch, Simutis et al. 2006).
Fed-batch cultivations are the most used cultivation strategy to produce pharmaceutics with recombinant E. coli, as they provide a method to preserve the cultivation’s metabolic activity by introducing fresh medium while providing a dynamic range of operating conditions rather than moving towards steady states (Karim, Hodge et al. 2003). A fed-batch culture is a batch culture subsequently fed continuously, or sequentially, with substrate without the removal of culture broth. Recombinant fed-batch cultures are generally superior to batch and continuous cultures, and are especially beneficial when changing nutrient concentrations. This affects the productivity of the desired products (Luli and Strohl 1990; Liu, Du et al. 2008; Soini, Ukkonen et al. 2008). The major advantage of fed-batch applications is minimizing by-product production, as the introduction of appropriate feed rate strategies is believed to minimize substrate inhibition and catabolite repression (Skolpap, Nuchprayoon et al. 2008). However, the optimization of feeding medium is a relevant issue, with different medium combinations resulting in various productivity values.
Controlling and optimizing fed-batch cultivations has become a growing objective within the industry and has led to the development of mathematical and computational models that attempt to find a representation of the biological processes, usually based on a series of mass balances(Yamane and Shimizu 1984; Kell and Sonnleitner 1995). That, however, offers numerous constraints given that, frequently, they are not able to represent critical, complex and non-linear behaviors. Mainstream modern manufacturing processes are subjected to product quality assessments and several measurements of process states. But a large portion of
8 MULTILAYER PERCEPTRON MODELLING OF INDUSTRIAL CULTIVATION PROCESSES FOR DNA VACCINE PRODUCTION CONTROL AND OPTIMIZATION
these data is often overlooked or considered redundant, and relevant information existing in the data is not utilized (Karim, Hodge et al. 2003). Additionally, deviations from predicted behavior have a significant impact in the productivities of fed-batch cultivations and hence all information should be gathered and processed instead of suppressed (Patnaik 2002). On these cases, artificial neural networks approaches may offer a clarification to what really happens during fed-batch fermentations.
A feeding strategy to avoid the accumulation of glucose could consist in feed-back control using the input of the pH and dissolved oxygen controls (Prather, Sagar et al. 2003). A pH-stat feeding strategy was proposed to address the issue of glycerol oscillations that occur in repeated batch cultivation (Garcia-Arrazola, Dawson et al. 2005). This implementation of a pH-stat cultivation strategy was based on the principle that rapid growth on carbon sources such as glucose and glycerol lead to the formation of organic acids in particular acetate (Lee 1996). (Chen, Graham et al. 1997) reported an E.coli cultivation process for the production of super-coiled plasmid DNA, using a computer-aided processing system to control interactively both the glucose feed-rate and agitation speed based on maintaining a constant level of dissolved oxygen.
Nonlinear regression techniques were also used in order to generate an optimum feed rate for a fed batch process by (Cruz, Silva et al. 1999).
Neural network models
Before selecting and using neural networks in biotechnology one should consider how data will scale, the selection of an appropriate network structure, and the objective of the network (Karim, Yoshida et al. 1997). Another factor that limits most of the data presented to the network to on-line information consist on the logistics involved in quantifying off-line data (Duan, Shi et al. 2006).
One common attempt at modelling cultivations consists in splitting the culture into separate phases and afterwards proceeding to model them individually (Konstantinov and Yoshida 1990; Johansen and Foss 1995). Konstantinov and Yoshida (1990) designed, to that effect, a detector of structural variations using a number of variables including respiratory quotient, substrate uptake and growth rate. However,
MULTILAYER PERCEPTRON MODELLING OF INDUSTRIAL CULTIVATION PROCESSES FOR DNA VACCINE PRODUCTION CONTROL AND OPTIMIZATION
9
the biggest problem with this approach occurs when we attempt to obtain a general picture by grouping all the different models because of the difficulty of determining when the phases start and finish. Thus, there is the need to consider quantitative mathematical models, capable of describing the process dynamics and the interrelation amongst relevant variables (Rocha, Neves et al. 2005).
Because of its complexity, most of the work done so far is limited to on-line variable estimation (pH, Temperature, etc.) and tends to be a compromise between data acquisition periods and the number of variables. However to obtain information regarding biomass, researchers extract Optical Density information with as much as a minimal 20 minute interval between samples. That allows them to detect the transitions between growth phases with specific model parameters being estimated by non-linear regressions (Diaz, Lelong et al. 1999). Besides being more complex to quantify, off-line variables, are less accurate (Patnaik 1997). But the on-line control algorithms (P, PI, PID controllers) provide also limited control on recombinant cultivations as their nonlinearity requires a technician to be present at all time and adjust the different variable thresholds(Jenzsch, Simutis et al. 2006). When trying to simultaneously optimize several objective functions, typically the best strategy is to find a compromise solution (i.e. Pareto optimal solution) where none of the objectives can get a better value without deterioration to at least one of the other objectives (Luque, Miettinen et al. 2009).
Statistical techniques, such as multiple linear regression (MLR), principal component regression (PCR), partial least squares (PLS) are some of the most commonly used approaches for bioprocess prediction. However Artificial Neural Networks are gaining more interest from researchers because of their supervised learning capabilities.
Artificial Neural Networks (ANNs) have proved to be successful in modelling actual bioprocess data (Karim and Halme 1989; Ungar 1990; Linko and Zhu 1991; Karim and Rivera 1992; Glassey, Montague et al. 1994; Bachinger, Martensson et al. 1998; Warnes, Glassey et al. 1998; Tian, Liu et al. 2013) more specifically growth rates in microorganisms (T. Silva, P. Lima et al. 2009; Schubert, Mourad et al. 2010) or microarray classification (Wang, Zineddin et al. 2013). ANNs such as Back-propagation (Rumelhart, Hinton et al. 1986) or Radial Base Function (Moody and Darken 1989) are currently the most popular artificial learning tools in biotechnology.
10 MULTILAYER PERCEPTRON MODELLING OF INDUSTRIAL CULTIVATION PROCESSES FOR DNA VACCINE PRODUCTION CONTROL AND OPTIMIZATION
Besides the prediction facet of Neural Networks, another common application resides in classification (Narasingarao, Manda et al. 2009). In this kind of application ANNs are used as a way of extracting statistical significance from surveys regarding a classification of quality of life in diabetes (Narasingarao, Manda et al. 2009). This can often become a simpler application of ANNs as they provide a limited solution space.
ANNs were used to model a fed-batch cultivation of Riboflavin (vitamin B2) where the following variables were used: Feed rate, CO2 evolution rate, added Nitrogen, used Glucose, cumulative amount of CO2 and pH in order to predict the cumulative amount of biomass and cumulative amount of riboflavin (Kovarova-Kovar, Gehlen et al. 2000). In this implementation of the MLP consisted in 5 input neurons, 1 hidden layer, of 20 neurons, and 2 output neurons. Riboflavin quantification was done by HPLC with samples being extracted in 3-hour intervals, the same interval that was used for biomass evaluation using optical density. As in many other examples, variables like O2 or CO2 are monitored at a much quicker pace (almost continuous) (Kovarova-Kovar, Gehlen et al. 2000). But that same work uses samples extracted with a 3-hour interval. Experimentally, the length of this interval may mean that sensitive information, especially during the exponential growth phase of the cultivation, is omitted from the model. The fact that such long intervals are used is a reference of the general technical difficulty derived from the lack of equipment that allows technicians to monitor the cultivation in real-time.
Kovarova-Kovar et al. (2000) also references the difficulty that some mathematical models have of fully capturing the normal perturbations that naturally occur inside the bioreactor. They refer to the use of gradient methods, dynamic programming techniques or the application of Pontryagin’s maximum principle as examples of deterministic mathematical models being used that rely in trial-and-error approaches with the objective of mapping every nuance of the system which can be a very extensive and time-consuming process (Schubert, Simutis et al. 1994). ANNs, because of their ability to learn from examples and not be pre-determined by theoretical assumptions (Karim, Yoshida et al. 1997), are able to adapt to the small perturbations of the cultivation and extract relevant variables and relationships from them (Montague and Morris 1994). The fact that Kovarova-Kovar et al. (2000)’s work only has two output neurons (in the main implementation) results in a topology
MULTILAYER PERCEPTRON MODELLING OF INDUSTRIAL CULTIVATION PROCESSES FOR DNA VACCINE PRODUCTION CONTROL AND OPTIMIZATION
11
simplification within the hidden layer, which in this case requires only a single layer and 20 neurons.
The determination of the optimal topology is often a trial-and-error task (Karim, Yoshida et al. 1997) with MLP networks, Recurrent Neural Networks (RNN) and Cascade Correlation Networks providing the best prediction capabilities, whereas RBF networks are unsuitable when extrapolation is desired. Over-parameterization may have a significant negative impact on the performance of neural networks (Gaume and Gosset 2003) as the smaller architecture usually allows to obtain better generalization properties (Haykin 1999). Recurrent Neural Networks allow for a neuron to be connected to itself. The RNN allows the dynamics of the network to be considered, and it is thus useful for temporal association. In the case of the Cascade Correlation Networks connections and nodes are added as required (Karim, Yoshida et al. 1997).
RBFs on the other hand provide simple and fast convergences but lack in their ability to predict values outside the training scope. This occurs because they locate centers among the input/output pairs such that the sum of the squares of the distance from the center to the training data set is minimized. Problems with global optimization are very frequent and the risk of reaching local minima is ever present (Mladenovic, Drazic et al. 2008).
Karim et al. (2003) addressed the application of ANNs with inadequate recombinant bacterial protein batch cultivation data sets. The problem of data unevenness limits the performance of the model. When the size of the data set is considered small it produces less robust predictions. In their work they used 7 batches in order to predict the optical density as a function of other measured variables that would allow them to infer biomass concentration. This approach limits the amount of off-line quantification required and because they only have one prediction objective variable, that will allow for a faster and better prediction. Moreover the data was normalized between 0 and 1, which further increases the capability of convergence, however it limits the optimization aspect. This enables the development of a much simpler network (in this case 1 hidden layer with 10 nodes). The training examples were also very limited with 4 batches used for training, 1 for validation and 1 for testing.
12 MULTILAYER PERCEPTRON MODELLING OF INDUSTRIAL CULTIVATION PROCESSES FOR DNA VACCINE PRODUCTION CONTROL AND OPTIMIZATION
Biomass formation was modeled successfully with a 6-8-2 network, and the network was capable of biomass prediction with an R2-value of 0.983. The predictive power of the neural networks was superior to the kinetic models, which could not be used in predictive modelling of arbitrary batch cultivations (Kiviharju, Salonen et al. 2006). This approach was more complex in the sense that they used 5 inputs (time, substrate, DO, pH, Temperature and Respiration Quotient) but only 2 outputs (log of a viable biomass and an output to compare the performance of biomass estimation). The input of time is normally avoided when using ANNs as it creates a bias in terms of organization. Although this approach is more complex it still lacks significant off-line information and the prediction aspect is limited to the biomass. The number of examples is still very limited (i.e. 103) and when we take into account they are the result of 13 cultivations we realize they correspond to an average lower than 10 examples per cultivation.
Zelic, Bolf et al. (2006) were able to introduce information regarding off-line variables (biomass, glucose, acetate and pyruvate concentrations) transforming them into state variables and then inputting glucose and acetate feed rates. They however, limited the output prediction to biomass values in one network and pyruvate concentration in a second network. This implementation consisted of 4 and 8 hidden nodes in each of the implementations. In this case, however, we have a much greater number of examples (680) than what is normal in these kind of studies.
Patnaik (1997) simulated fed-batch cultivation for -galactosidase production by a recombinant Escherichia coli with data of 12h cultivations using a 6-12-4 Elman neural network with .pH, temperature, CO2 evolution rate, substrate feed rate and the starting concentrations of plasmid-bearing and plasmid-free cells serving as inputs in order to predict the concentration and mass fraction of plasmid- containing cells and the intracellular plasmid DNA and -galactosidase concentrations. Each simulation consisted of 100 points sampled uniformly over 12h cultivations.
Generalized Regression Neural Networks were used to monitor and predict fed-batch cultivations using E.coli to produce pVax-LacZ plasmid (T. Silva, P. Lima et al. 2009). Although GRNNs were able to produce very satisfying results in predicting fed-batch behavior there are several drawbacks to this strategy. GRNNs use the same number of neurons in the intermediate layer than the number of training examples, which can
MULTILAYER PERCEPTRON MODELLING OF INDUSTRIAL CULTIVATION PROCESSES FOR DNA VACCINE PRODUCTION CONTROL AND OPTIMIZATION
13
lead to very large networks and the requirement to dynamically redesign the network topology. GRNNs also “memorize” the training examples therefore adjusting test cases to that training. When the test examples are sufficiently close to the training examples this adjustment can be observed as the capability to correct errors in observation. The biggest problem resides with outliers, as the network tends to view them more as errors than novel information. GRNNs therefore have the ability to learn much quicker than MLPs and with increased accuracy in smaller example spaces but limits the exploration of wider example spaces.
After the monitoring and control stage the next step is the optimization of the process and for that purpose Genetic Algorithms (GAs) present a very interesting solution to this complex problem. They can simultaneously handle multiple objective functions with linear, nonlinear equality and inequality constrains. Evolutionary Computation approaches are, however, at least not better than the gradient-based algorithms in terms of ANN model performance and are of course much slower(Ilonen, Kamarainen et al. 2003; Socha and Blum 2007). A Genetic Algorithm (GA) is an artificial intelligence-based stochastic non-linear optimization method that mimics the principles of biological evolution (i.e., the ‘‘survival of the fittest’’ and ‘‘random exchange of data during propagation’’), followed by biologically evolving species (Simutis and Lubbert 1997). GAs are a powerful technique that has been used to optimize bioprocesses without the need for statistical designs and empirical models (Moriyama and Shimizu 1996; Angelov and Guthke 1997; Roubos, van Straten et al. 1999; Wang, Feng et al. 2008; Tian, Liu et al. 2013).
Another approach consisted in using Evolutionary Algorithms to optimize the starting conditions and feeding trajectory in fed-batch cultivation and then use it to control on-line variables (Rocha, Neves et al. 2005). In this case, the Evolutionary Algorithm consisted on differential equations that represent the mass balances of the sate variables (i.e. substrate feeding rate, cultivation weight, glucose, biomass, dissolved oxygen, dissolved carbon dioxide and acetate) along a period of 25 hours. The problem with this solution resides in the impact of the noise, as small perturbations influence the scope of the differential equations.
In the case of Kovarova-Kovar et al. (2000) their attempt at process optimization consisted in the implementation of a ZNet model with 5000 association cells and a