UNIVERSIDADE DA BEIRA INTERIOR
Engenharia
Tolerância a Falhas em Infraestrutura de Cloud
-Construção de Aplicações com Elevada
Disponibilidade
José Danilson dos Reis Ferreira
Dissertação para obtenção do Grau de Mestre em
Engenharia Informática
(2º ciclo de estudos)
Orientador: Prof. Doutora Maria Paula Prata de Sousa
Dissertação elaborada no Instituto de Telecomunicações - Delegação da Covilhã e no Depar-tamento de Informática da Universidade da Beira Interior por José Danilson dos Reis Ferreira, Licenciado em Engenharia de Sistemas e Informática pela Universidade Jean Piaget de Cabo Verde, sob orientação da Doutora Maria Paula Prata de Sousa, Investigadora do Instituto de Te-lecomunicações e Professora Auxiliar do Departamento de Informática da Universidade da Beira Interior, e submetida à Universidade da Beira Interior para discussão em provas públicas. Trabalho integrado em projeto parcialmente financiado por:
• Programa Integrado de ICDT “C4 – Centro de Competências em Cloud Computing” com con-trato CENTRO-01-0145-FEDER-000019;
Agradecimentos
Aos meus pais, meus irmãos, minhas irmãs, meus sobrinhos pelo apoio, pela compreensão, pelo incentivo dado. À minha orientadora da dissertação, Professora Doutora Maria Paula Prata de Sousa, por toda a disponibilidade, dedicação, orientação e ajuda que prestou para a materiali-zação deste trabalho. Ao Instituto de Telecomunicações - Delegação da Covilhã pelo apoio. Aos professores do Departamento de Informática da Faculdade de Engenharia. À direção da Escola Secundária de São Domingos. Aos meus colegas da turma e do laboratório, pelo apoio e partilha dos conhecimentos e à Deus por me ter dado vida e saúde.
Dedicatórias
Dedico este trabalho aos meus pais Orlando Ferreira e Elísia dos Reis, aos meus irmãos Paulino Ferreira, Adilson Ferreira, Ivandro Ferreira, Nícia Ferreira, Adalgisa ferreira, Gisele Ferreira e Graça Ferreira, aos meus sobrinhos, Edline Ferreira, Liliane Ferreira, Diego Ferreira e Marlon Ferreira. Em fim à todos os meus familiares, colegas, amigos, professores e a todos aqueles que me apoiaram de uma forma direta ou indireta nesta caminhada.
Resumo
Na atualidade, a computação na cloud é cada vez mais usada, como forma de aceder a recursos de computação à medida das necessidades do utilizador, sem necessidade de grandes investi-mentos. Como qualquer infraestrutura informática a cloud também está sujeitas a falhas. É nesta perspetiva que se desenvolveu um sistema que tolera as falhas numa infraestrutura da cloud Openstack. Foi implementado um cenário que garante a alta disponibilidade de aplica-ções web alojadas neste sistema da cloud. Este trabalho na primeira fase apresenta-se uma revisão bibliográfica dos conceitos de computação na cloud, de tolerância a falhas e de alta disponibilidade. Na segunda fase debruça–se na instalação e configuração da infraestrutura de cloud OpenSatck. Após isso, foi desenvolvida uma aplicação web com redundância neste sis-tema cloud e foi avaliado o seu desempenho sem tolerâncias a falhas e com tolerância a falhas. Concluiu-se que é mais viável ter sistemas com tolerâncias a falhas num sistema de cloud, apesar dos custos que acarretam, a não tê-los.
Palavras-chave
Abstract
Today, cloud computing is increasingly used as a means of accessing computing resources tai-lored to user needs without the need for major investment. Like any computing infrastructure the cloud is also subject to failure. It is from this perspective that a system has been developed that tolerates failures in an Openstack cloud infrastructure. A scenario has been implemented that ensures the high availability of web applications hosted on this cloud system. This work in the first phase presents a literature review of the concepts of cloud computing, fault tolerance and high availability. In the second phase it focuses on the installation and configuration of the OpenSatck cloud infrastructure. After that, a redundant web application was developed on this cloud system and its performance without fault tolerance and fault tolerance was evaluated. It was concluded that it is more feasible to have fault tolerant systems in a cloud system, despite the high costs, than not to have a fault tolerant system.
Keywords
Conteúdo
1 Introdução 1
2 Computação na Cloud 3
2.1 Introdução . . . 3
2.2 Definição e Características . . . 3
2.3 Modelos de Serviços de Computação na Cloud . . . 4
2.3.1 Infraestrutura como um Serviço-IaaS . . . 5
2.3.2 Plataforma como um Serviço-PaaS . . . 5
2.3.3 Software como um Serviço-SaaS . . . 5
2.4 Tipos de Implementação da Cloud . . . 5
2.4.1 Cloud Privada . . . 5
2.4.2 Cloud Pública . . . 6
2.4.3 Cloud Híbrida . . . 6
2.4.4 Cloud Comunitária . . . 6
2.5 A Framework OpenStack . . . 6
2.5.1 Arquitectura dos Componentes do Openstack . . . 7
2.5.2 Serviços do Openstack . . . 8
2.6 Outras Sistemas de Computação na Cloud . . . 11
2.6.1 Amazon Web Services (AWS) . . . 11
2.6.2 Microsoft Windows Azure Plataform . . . 12
2.6.3 Aneka . . . 12 2.7 Virtualização . . . 13 2.8 Trabalhos Relacionados . . . 14 2.9 Conclusão . . . 15 3 Tolerância a Falhas 17 3.1 Introdução . . . 17 3.2 Conceitos . . . 17 3.3 Tipos de Falhas . . . 19
3.4 Técnicas de Tolerância a Falhas . . . 20
3.5 Gestão de Tolerância a Falhas na Computação na Cloud . . . 22
3.5.1 Gestão Exclusiva de Tolerância a Falhas . . . 23
3.5.2 Gestão Colaborativa de Tolerância a Falhas . . . 24
3.6 Elevada Disponibilidade . . . 24
3.6.1 Elevada Disponibilidade na Infraestrutura de Cloud OpenStack . . . 25
3.6.2 Ferramentas de Elevada Disponibilidade . . . 26
3.7 Conclusão . . . 31
4 Ambiente Experimental e Ferramentas de Avaliação de Desempenho 33 4.1 Instalação e Configuração da Cloud OpenStack . . . 33
4.1.1 Ambiente de Instalação . . . 33
4.1.2 Arquitetura e Configuração de Rede . . . 34
4.1.3 Instalação e Configuração dos Nós da Infraestrutura da Cloud OpenStack . 35 4.2 Aplicação Exemplo . . . 36
4.3 Aplicação Exemplo num Cenário de Elevada Disponibilidade . . . 37
4.4 Ferramentas de Avaliação de Desempenho . . . 39
4.4.1 Lado do Cliente . . . 39
4.4.2 Lado do Servidor . . . 40
5 Resultados 43 5.1 Avaliação do Desempenho sem Tolerância a Falhas . . . 43
5.1.1 Avaliação da “Aplicação Exemplo” . . . 43
5.1.2 Avaliação do “Aplicação Exemplo” com HAProxy . . . 44
5.2 Avaliação do Desempenho da Aplicação Web com Elevada Disponibilidade . . . . 46
5.3 Análise da Avaliação dos Cenários . . . 58
5.4 Conclusão . . . 60
6 Conclusão e Trabalho Futuro 61
Lista de Figuras
2.1 Modelos de computação na cloud [9]. . . 4
2.2 Arquitectura dos componentes do Openstack [14]. . . 7
3.1 Percurso para avaria [35]. . . 18
3.2 Cronograma para a precaução de um sistema de detecção de falhas [39]. . . 21
3.3 Arquitectura de computação na cloud [7]. . . 22
3.4 Gestão de tolerância a falhas na computação na cloud. . . 22
3.5 Configuração ativo/passivo [37]. . . 26
3.6 Configuração ativo/ativo [37]. . . 26
3.7 Servidor HAProxy [43]. . . 28
3.8 Alta disponibilidade de servidores ”HAProxy” com ”Keepalived” : cenário sem falhas (adpatado de [45] [46]). . . 29
3.9 Alta disponibilidade de servidores ”HAProxy” com ”Keepalived”: cenário após falha do “HAProxy“ “Master” (adpatado de [45] [46]). . . 29
3.10 Replicação dos servidores do MySQL (adaptado de [47]). . . 30
3.11 Pacemaker [48]. . . 31
4.1 Arquitetura e configuração de rede. . . 34
4.2 Cenário da aplicação na cloud. . . 37
4.3 Cenário de Alta Disponibilidade. . . 38
4.4 Interface do Webpagetest [52]. . . 40
4.5 Exemplo do comando no Apache Bench. . . 40
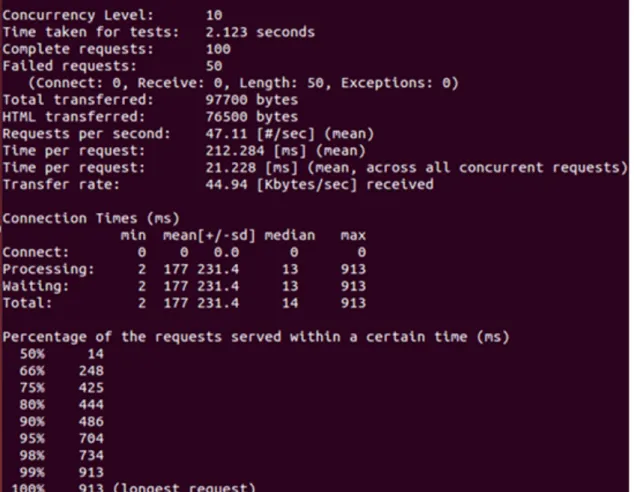
4.6 Exemplo do Output do Apache Bench. . . 41
5.1 Avaliação do desempenho (lado do servidor) sem tolerância a falhas. . . 44
5.2 Resposta do servidor sem tolerância a falhas. . . 44
5.3 Cenário sem tolerância a falhas com HAProxy. . . 45
5.4 Avaliação do desempenho (lado do servidor) sem tolerância a falhas com HAProxy. 45 5.5 Resposta do servidor sem tolerância a falhas com HAProxy. . . 46
5.6 Avaliação do desempenho (lado do servidor) com alta disponibilidade: cenário sem falhas. . . 47
5.7 Ambiente de alta disponibilidade sem falhas. . . 48
5.8 Falha do servidor web da máquina virtual 1. . . 48
5.9 Avaliação do desempenho (lado do servidor) com alta disponibilidade: cenário com falhas do servidor web da máquina virtual 1. . . 49
5.10 Ambiente da alta disponibilidade (falha do servidor web da VM 1). . . 49
5.11 Falha do servidor web da máquina virtual 2. . . 50
5.12 Avaliação do desempenho (lado do servidor) com alta disponibilidade: cenário com falhas do servidor web da máquina virtual 2. . . 51
5.13 Ambiente da alta disponibilidade (falha do servidor web da VM 2). . . 51
5.14 Falha do servidor MySQL “Slave” da máquina virtual 2. . . 52
5.15 Avaliação do desempenho (lado do servidor) com alta disponibilidade: cenário com falhas do servidor MySQL da máquina virtual 2. . . 52
5.16 Ambiente da alta disponibilidade (falha do servidor MySQL “Slave” da máquina
virtual 2). . . 53
5.17 Falha do servidor MySQL “Master” da máquina virtual 1. . . 53
5.18 Avaliação do desempenho (lado do servidor) com alta disponibilidade: cenário com falhas do servidor MySQL da máquina virtual 1. . . 54
5.19 Ambiente da alta disponibilidade (falha do servidor MySQL “Master” da máquina virtual 1). . . 54
5.20 Falha do servidor web da VM1 e do servidor MySQL “Slave” da VM2. . . 55
5.21 Avaliação do desempenho (lado do servidor) com alta disponibilidade: cenário com falha do servidor web da máquina virtual 1 e do servidor MySQL da máquina virtual 2. . . 56
5.22 Ambiente da alta disponibilidade (falha do servidor web da VM 1 e do servidor MySQl ”Slave” da VM 2). . . 56
5.23 - Falha do servidor web da máquina virtual 2 e do servidor MySQL “Master” da máquina virtual 1. . . 57
5.24 Avaliação do desempenho (lado do servidor) com alta disponibilidade: cenário com falha do servidor web da máquina virtual 2 e do servidor MySQL da máquina virtual 1. . . 57
5.25 Ambiente da alta disponibilidade(falha do servidor web da VM 2 e do servidor MySQl ”Master” da VM 1). . . 58
5.26 Cenários sem falhas. . . 59
5.27 Cenários com apenas uma falha. . . 59
Lista de Tabelas
3.1 Mecanismo para mascarar falhas (Adaptado de [36]). . . 21
4.1 Características e dados da configuração da máquina 1 (“Controller”). . . 33
4.2 Características e dados da configuração da máquina 2 (“Compute”). . . 33
4.3 Caraterísticas e dados da configuração da máquina 3 (“Block Storage”). . . 34
4.4 Características e dados da configuração máquina virtual 1 (VM 1). . . 37
4.5 Características e dados da configuração máquina virtual 2 (VM 2). . . 39
5.1 Avaliação do desempenho (lado do cliente) sem tolerância a falhas. . . 44
5.2 Avaliação do desempenho (lado do cliente) sem tolerância a falhas com HAProxy. 45 5.3 Avaliação do desempenho (lado do cliente) com alta disponibilidade: cenário sem falhas . . . 47
5.4 Avaliação do desempenho (lado do cliente) com alta disponibilidade: cenário com falha do servidor web da máquina virtual 1 . . . 49
5.5 Avaliação do desempenho (lado do cliente) com alta disponibilidade:cenário com falha do servidor web da máquina virtual 2 . . . 50
5.6 Avaliação do desempenho (lado do cliente) com alta disponibilidade: cenário com falha do MySQL da máquina virtual 2 . . . 51
5.7 Avaliação do desempenho (lado do cliente) com alta disponibilidade: cenário com falha do MySQL da máquina virtual 1. . . 54
5.8 Avaliação do desempenho (lado do cliente) com alta disponibilidade: cenário com falha do servidor web da máquina virtual 1 e do servidor MySQL da máquina virtual 2. . . 55
5.9 Avaliação do desempenho (lado do cliente) com alta disponibilidade: cenário com falha do servidor web da máquina virtual 2 e do servidor MySQL ”Master” da má-quina virtual 1. . . 56
5.10 Resultados obtidos dos testes efetuados com a ferramenta do desempenho do website (lado do servidor). . . 58
Lista de Acrónimos
Amazon EC2 Amazon Elastic Compute Cloud
AMIs Amazon Machine Images
API Application Programming Interface
AWS Amazon Web Services
CDN Content Delivery Network
CPU Central Process Unit
HA High Availability
HTTP Hypertex Transfer Protocol
IaaS Infrastructure as a Service
IP Internet Protocol
MPI Message Passing Interface
NASA National Aeronautics and Space Administration
NAT Network Address Translation
NIST National Institute of Standarts and Technology
NTP Network Time Protocol
PaaS Platform as a Service
POP Point of Presence
RAM Random Access Memory
REST Representational State Transfer
SaaS Software as a Service
SDN Remote Procedure Call
SDN Software-Defined Networking
SPOFs Single Point of Failure
SSH Secure Shell
TCP Transmission Control Protocol
TI Tecnologia de Informação
TIC Tecnologia de Informação e Comunicação
TTFB Time To First Byte
URL Uniform Resource Locator
Capítulo 1
Introdução
O foco deste trabalho é estudar os conceitos inerentes à computação na cloud, que é uma tec-nologia que atualmente desempenha um papel preponderante no contexto das organizações. A computação na cloud, para além de abarcar todas as características de um sistema informático tradicional, disponibiliza às organizações/empresas vários recursos de computação sem que es-sas façam um investimento em infraestruturas próprias. A elas só cabe pagar pelos recursos consumidos [1] [2]. É um modelo de computação recente [1], que fornece aos utilizadores inúmeros recursos computacionais (hardware, rede, armazenamento, etc.) como um serviço, que é acedido através da internet sem que os utilizadores controlem a infraestrutura [2]. O objetivo deste trabalho é estudar os mecanismos de tolerância a falhas na cloud e implementar uma aplicação na cloud com elevada disponibilidade avaliando o seu desempenho.
Na vertente prática deste trabalho, foi instalado e configurado o sistema cloud OpenStack versão “Mitaka”, foi instalada a versão básica, isto é, com três nós, Controlador (Controller), Compu-tação (Compute) e Armazenamento em Bloco (Block Storage).Como forma de materializar os conceitos de mecanismos de tolerâncias a falhas e alta disponibilidade explanadas no Estado da Arte, foi implementado neste sistema de cloud, um mecanismo de tolerância a falhas a nível das aplicações. Para tal, desenvolveu-se uma aplicação com elevada disponibilidade utilizando as seguintes ferramentas para alta disponibilidade de software, o servidor HAProxy para o ba-lanceamento de carga dos servidores web e a configuração da réplica dos servidores MySQL. O desempenho da aplicação na cloud foi testado com as ferramentas do desempenho de aplicação web, do lado do cliente e do lado do servidor. Os testes do desempenho da aplicação na cloud foram realizados em dois momentos distintos: sem tolerância a falhas e com tolerância a falhas (réplica dos servidores).
As contribuições deste trabalho são um estudo do estado da arte da computação na cloud; um estudo de mecanismos de tolerância a falhas em sistemas de cloud; implementação em OpenStack de uma arquitectura de alta disponibilidade para aplicações web e avaliação de de-sempenho da arquitectura implementada para vários cenários de falhas.
Este trabalho é constituído por seis capítulos. O capítulo I faz a introdução do trabalho, referindo-se ao objetivo e sua organização. O capítulo II aprereferindo-senta os conceitos de computação na cloud, e ainda faz referência aos sistemas de computação na cloud destacando a Framework OpenS-tack. O capítulo III descreve os conceitos de tolerâncias a falhas com enfoque sobre os tipos de falhas, técnicas de tolerância a falhas e alta disponibilidade. O capítulo IV debruça-se sobre o ambiente experimental e ferramentas de avaliação de desempenho descrevendo a instalação da infraestrutura de cloud OpenStack, e o cenário de elevada disponibilidade implementado. O capítulo V apresenta os resultados da avaliação do desempenho da aplicação na cloud. Por último, no capítulo VI são apresentadas as principais conclusões do trabalho realizado, assim como as limitações encontradas e possíveis trabalhos futuros.
Capítulo 2
Computação na Cloud
2.1
Introdução
Este capítulo apresenta os conceitos de computação na cloud, destacando as suas caracterís-ticas, os seus modelos de serviços e os tipos de implementação. Também se debruça sobre a descrição da framework OpenStack que é o sistema cloud implementado neste trabalho. Ainda apresenta o conceito de virtualização que é uma tecnologia utilizada na implementação da cloud e finalmente faz referências a outros sistemas da computação na cloud.
2.2
Definição e Características
Segundo Taurion [3] o termo computação na cloud, surgiu em 2006 numa palestra de Eric Schmidt, do Google, sobre como sua empresa fazia a gestão dos seus data centers. Hoje, com-putação na cloud, se apresenta como o cerne de um movimento de profundas transformações do mundo da tecnologia. A tarefa de definir “cloud computing” está longe de ser consensual entre os especialistas na área. Todavia, de forma cíclica têm surgido várias definições. De seguida são descritas algumas definições interessantes e relevantes encontradas na literatura.
A computação na cloud de acordo com o NIST (National Institute of Standarts and Technology) pode ser entendida como um modelo de computação que permite o acesso, de modo conveni-ente e a pedido, a um conjunto de recursos de computação configuráveis (como por exemplo redes, servidores, armazenamento, serviços web, aplicação e virtualização) que podem ser rapi-damente aprovisionados e libertados com esforço mínimo de gestão ou interação com o provedor de serviços [4].
De acordo com os autores Madani e Jamali [5] a computação na cloud, é vista como um método de computação que fornece aos utilizadores os recursos da tecnologia da informação como um serviço, e permite que eles tenham acesso a esses serviços na Internet sem precisar de infor-mações especializadas ou controlar a infraestrutura.
Dentro deste contexto, pode-se afirmar que a computação na cloud refere-se tanto às apli-cações oferecidas como serviços pela Internet, como também ao software, hardware e sistemas nos data centers que fornecem esses serviços [6]. O objetivo primordial da Computação na cloud é transformar a indústria de Tecnologia da Informação (TI), tornando o software cada vez mais atraente como serviço e moldando a forma como o hardware é projetado e adquirido [6]. Isto porque, desta feita os desenvolvedores com ideias inovadoras para novos serviços de Internet, não necessitam de fazer grandes desembolsos de capitais em hardware para implantar o seu serviço nem para custear a despesa humana para operá-lo.
• On-demand self (auto-atendimento sob demanda): um utilizador pode alocar recursos de computação (instâncias, armazenamento em rede etc.), conforme necessário, automati-camente, isto é, sem a intervenção do provedor do serviço;
• Broad network access (amplo acesso à rede): os recursos disponíveis na rede podem ser acedidos por meio de mecanismos padrão que promovem o uso por plataformas heterogé-neas, como por exemplo, telemóveis, tablets, laptops ou estações de trabalho;
• Resource pooling (agrupamento de recursos): o provedor do serviço disponibiliza os recur-sos (armazenamento, processamento, memória e largura de banda de rede) existentes a diferentes utilizadores, recursos esses, que são reservados e libertados de acordo com a necessidade momentânea de cada utilizador;
• Rapid Elasticity (elasticidade rápida): os recursos podem ser provisionados e libertados de forma elástica, em alguns casos automaticamente. Ou seja, torna-se crucial que os recursos sejam elásticos para que possam ser rapidamente redimensionados consoante o utilizador necessite de ampliar, ou reduzir os mesmos recursos. Para o utilizador, os recursos disponíveis para provisionamento muitas vezes parecem ilimitados e podem ser apropriados em qualquer quantidade e a qualquer momento;
• Measured service (medição dos serviços): os sistemas da computação na cloud controlam e monitorizam automaticamente os recursos para cada tipo de serviço (armazenamento, processamento e largura de banda). Esse monitoramento do uso dos recursos deve ser transparente para o provedor de serviços, assim como para o utilizador do serviço utilizado.
2.3
Modelos de Serviços de Computação na Cloud
A computação na cloud permite aos utilizadores aceder softwares de aplicação e recursos de computação utilizando modelos de serviços [7]. Atualmente, de acordo, com a maioria das literaturas a computação na cloud é composta por três camadas [8], como mostra a figura 2.1, são elas:
Figura 2.1: Modelos de computação na cloud [9].
• Infraestrutura como um Serviço – IaaS • Plataforma como um Serviço – PaaS
• Software como um Serviço – SaaS
2.3.1
Infraestrutura como um Serviço-IaaS
IaaS é a camada inferior do modelo conceitual, nela o provedor tem a capacidade de fornecer ao utilizador recursos fundamentais de computação (como processamento, armazenamento, redes etc.). O consumidor pode implantar e executar diferentes tipos de software, incluindo sistemas operativos [7]. Nesta camada o utilizador não gere e nem controla a infraestrutura física todavia, através de mecanismos de virtualização, tem controlo sobre os sistemas operativos, armazenamento, aplicações instaladas e um controlo limitado dos componentes da rede (como por exemplo, host e firewall) [8].
2.3.2
Plataforma como um Serviço-PaaS
PaaS pode ser entendida como a camada intermediária do modelo conceitual, sendo composta por hardware virtual disponibilizado como serviço. Este modelo permite ao utilizador imple-mentar aplicações criadas por ele mesmo numa plataforma de cloud virtualizada. O modelo PaaS inclui middleware, base de dados, ferramentas de desenvolvimento e algum suporte de execução, como a Web 2.0 e o Java. A plataforma inclui hardware e software integrado com interfaces de programação específicas. O provedor fornece a API (Application Programming In-terface) e ferramentas de software (por exemplo, Java, Python, Web 2.0, NET) [10].
Nesta camada também o utilizador não gere e nem controla a infraestrutura (rede, servido-res, sistemas operativos ou armazenamento), mas tem controlo sobre as aplicações instaladas e definições de configuração para a hospedagem de ambiente de aplicações [8].
2.3.3
Software como um Serviço-SaaS
SaaS é a camada mais externa do modelo conceitual. Neste modelo, o utilizador beneficia da capacidade de utilizar aplicações já implantados no ambiente de cloud por um provedor [7]. Isto é, as aplicações estão hospedadas na cloud e podem ser acedidas por utilizadores para as mais diversas finalidades. Os softwares são acedidos a partir de vários dispositivos, como por exemplo smartphone, smartwatchs e smart tvs. De forma similar aos outros dois modelos referenciados, o utilizador não gere nem controla a infraestrutura subjacente, nem as aplicações individuais, com a possível exceção das suas configurações específicas [8].
2.4
Tipos de Implementação da Cloud
Nem todas as clouds são iguais. Há quem defenda que existem três formas diferentes de imple-mentar os recursos de informática na cloud : cloud pública, cloud privada e cloud híbrida [11]. Outros autores consideram mais um de tipo de implementação que é cloud comunitária [2] [8]. De seguida descrevem-se estes quatro modelos de implementação de Cloud.
2.4.1
Cloud Privada
No modelo de implementação de cloud privada, a infraestrutura de cloud é construída dentro do domínio duma intranet e é utilizada exclusivamente para uma organização [10]. Ela é
admi-nistrada pela própria empresa ou por terceiros, ou por ambas as partes, e pode ser implantada dentro ou fora das instalações da organização [8].
As cloud privadas fornecem aos utilizadores locais uma infraestrutura privada flexível e ágil para executar cargas de trabalho de serviço dentro de seus domínios administrativos. O acesso aos serviços é limitado aos clientes proprietários e os seus parceiros, isto é, são aplicadas as políticas de autenticação e autorização para aceder aos serviços [10]. As cloud privadas são construídas exclusivamente para um único utilizador (uma empresa, por exemplo), com o intuito de maximizar e otimizar os recursos internos existentes, também por motivos de segurança e confiança nas cloud privadas [1].
2.4.2
Cloud Pública
Numa cloud pública, a infraestrutura pertence a uma provedor que vende serviços para o público em geral e pode ser acedido por qualquer utilizador que conheça a localização do serviço, desde que tenha pago pelo serviço usufruído [10]. Nas clouds públicas, o hardware, o software e as outras infraestruturas de apoio são detidas e geridas pelo fornecedor de serviços cloud. O acesso a estes serviços e a gestão da conta são feitos através da conexão online [1].
2.4.3
Cloud Híbrida
As clouds híbridas podem ser entendidas como a combinação das clouds pública e privada, vin-culadas através de uma tecnologia padronizada que permite que os dados e as aplicações sejam partilhados entre elas [1].
O modelo de cloud híbrida possibilita manter sistemas na cloud privada e outros na cloud pública, simultaneamente. Por exemplo, sistemas críticos ou que manipulam informações confidenciais podem ser hospedados internamente enquanto outros sistemas, que não lidam com dados sigi-losos, podem ser utilizados em uma rede pública [11].
As cloud públicas promovem a padronização, preservam o investimento de capital e ofere-cem flexibilidade de aplicação, enquanto que as cloud privadas tentam obter personalização e oferecem maior eficiência, resiliência, segurança e privacidade [10].
2.4.4
Cloud Comunitária
A infraestrutura da cloud pode ser compartilhada por um conjunto de empresas que partilhem os mesmos interesses, características ou preocupações (como por exemplo nas políticas de au-tenticação, requisitos de segurança ou em uma missão), podendo assim partilhar os custos entre elas. Nesta infraestrutura da cloud a administração é feita por uma ou mais empresas partici-pantes da comunidade ou por uma empresa terceira ou ainda por uma combinação entre elas [8].
2.5
A Framework OpenStack
O OpenStack é uma framework “open source” que vem ganhando espaço na comunidade de software livre e na indústria [12]. O OpenStack fornece software para construir uma IaaS, foi
iniciado num projeto em 2010, através da colaboração entre as empresas Rackspace e a agência espacial americana, a NASA [11] [13]. Atualmente, especialistas de computação na cloud de todo o mundo contribuem para o projeto. O OpenStack desenvolve projetos como o OpenS-tack Compute, que oferece recursos de computação para máquinas virtuais e gestão de rede, e OpenStack Object Storage, que proporciona um serviço de armazenamento de objetos escalá-veis [12].
A framework OpenStack inclui vários serviços que são instalados separadamente. Esses serviços funcionam juntos, dependendo das necessidades da cloud. São eles: serviços de computação (compute), identidade (keystone), rede (neutron), imagem (glance), armazenamento em bloco (cinder), armazenamento de objetos (swift), serviços de telemetria (Ceilometer), base de da-dos, horizon (dashboard). Ainda é de realçar que qualquer um desses serviços pode ser instalado e configurado separadamente ou como entidades conectadas.
2.5.1
Arquitectura dos Componentes do Openstack
A arquitectura da plataforma OpenStack depende da sua versão, neste trabalho a versão utili-zada é Openstack ”Mitaka”.
Figura 2.2: Arquitectura dos componentes do Openstack [14].
A versão Openstack ”Mitaka” requer pelo menos dois nós (hosts) conforme a figura 2.2, para ini-ciar uma VM (Virtual Machine) ou instância básica, esses nós básicos são: “Controller” e “Com-pute” . Os outros nós podem ser serviços opcionais, como Armazenamento de Blocos ( “Block Storage”) e Armazenamento de Objetos (“Object Storage”) [14]. Todavia, se a infraestrutura for implementada sem o nó Armazenamento de Blocos ( “Block Storage”), não vai ser possível anexar volumes às máquinas virtuais instanciadas, porque é este nó que disponibiliza o volume de armazenamento. Sendo assim, sem o nó Armazenamento de Blocos ( “Block Storage”) as
máquinas virtuais instanciadas só terão o sistema operativo versão experimental, logo ao serem encerradas (VMs) todos os dados nelas armazenadas serão perdidos, visto que elas (VMs) não tem volume de armazenamento (só têm um disco efémero). Ainda é de realçar, que o drive de volume instalado no Block Storage é o drive LVM, isto porque este drive suporta o sistema Operativo Linux versão Ubuntu 14.04 LTS.Este sistema operativo foi instalado nas máquinas que contêm os nós da infraestrutura de cloud implementada neste trabalho e nas máquinas virtuais nele instanciadas.
Controlador (Controller)
O nó “Controller” executa o serviço de keystone (identidade), o serviço de glance (imagem), e al-guns serviços do Compute. Também faz gestão de vários agentes de rede e o Horizon(dashboard). Ele também inclui serviços de suporte, como base de dados SQL, fila de mensagens e NTP ( Network Time Protocol) [14]. Opcionalmente, o nó “Controller” executa alguns dos serviços dos nós Armazenamento em Bloco e Armazenamento de Objetos, Orquestração e Telemetria. O nó “Controller” requer no mínimo duas interfaces de rede [14].
Computação (Compute)
O nó “Compute” executa a parte do hypervisor do Compute para gestão de máquinas virtu-ais. Pode-se implantar mais de um nó “Compute”. Cada nó requer no mínimo duas interfaces de rede. Por padrão, o Compute utiliza o hypervisor KVM . O nó Compute também executa um agente de serviço de rede que conecta instâncias a redes virtuais e fornece serviços de firewall a instâncias por meio de grupos de segurança [14].
Armazenamento em bloco (Block storage)
O nó opcional “Block Storage” contém os discos que os serviços de Block Storage e sistema de ficheiros compartilhado provisionam para instâncias [14]. O tráfego de serviço entre os nós “Compute” e “Block Storage” é feito através do módulo “Network Management”. Pode-se im-plantar mais do que um nó de “Block Storage”. Cada nó requer no mínimo uma interface de rede [14].
2.5.2
Serviços do Openstack
Como foi dito anteriormente, o projeto OpenStack é uma framework de computação de cloud de código “open source” constituída por diversos serviços. Nessa subsecção serão descritos os serviços mais importantes de OpenStack versão ”Mitaka”. A escolha recaiu sobre a versão “Mi-taka” porque na altura da realização do trabalho, era a versão mais estável e também apresenta uma arquitectura que consume poucos recursos computacionais, isto é, requer no mínimo dois nós. Os principais serviços são [14]:
Ceilometer (Serviço de telemetria)
O Ceilometer (serviço de telemetria) é um serviço que faz a monitorização e métrica de re-cursos para o Openstack.
Cinder (Serviço de armazenamento em bloco)
O Cinder (serviço de armazenamento em bloco) fornece o armazenamento baseado em bloco persistente para instâncias (máquinas virtuais criadas na infraestruturas da cloud OpenStack) em execução. O método sobre a qual o armazenamento é aprovisionado e consumido é deter-minado pelo driver de armazenamento em bloco ou pelos drivers no caso de uma configuração de vários back-ends. Há uma variedade de drivers disponíveis: NAS / SAN, NFS, LVM, Ceph, e muito mais. Neste trabalho foi instalado o driver LVM (Logical Volume Manager) e a conexão com as máquinas virtuais é feita através do protocolo iSCSI(Internal Small Computer System Interface). O iSCSI é usado pra facilitar a transferência de dados pelas intranets e para gerir armazenamento de longas distâncias1, neste caso, entre o Block Storage e as máquinas virtuais.
Glance (Serviço de imagem)
O Glance (serviço de imagem) armazena e recupera imagens de disco da máquina virtual. O OpenStack Compute faz uso do glance durante o provisionamento da instância. Isto é, imagens de disco permitem que uma instância possa ser criada sem perda de tempo com instalação de sistema operativo e configuração de ambiente. Glance permite a criação e registo de imagens pré-configuradas que podem servir como base para a criação de novas instâncias de máquinas virtuais. Ele oferece uma API REST (Representational State Transfer) que permite consultar metadados de imagens de máquinas virtuais e recuperar uma imagem real.
Horizon (Serviço de dashboard)
O Horizon (serviço de dashboard) fornece um portal de auto-atendimento baseado na Web para interagir com os serviços subjacentes do OpenStack, como o lançamento de uma instância, a atribuição de endereços IP e a configuração de controlo de acesso. Isto é, é uma interface da Web que permite aos administradores e utilizadores da cloud gerir vários recursos e serviços (Nova, Neutron, Swift, Glance, etc) do OpenStack, agilizando e facilitando o processo da gestão da Cloud.
Keystone (Serviço de identidade)
O serviço keystone é responsável pela autenticação, gestão de identidades e projetos, e au-torização para aceder a outros serviços do OpenStack. O keystone fornece um ponto único de integração para gerir serviços de autenticação, autorização e catálogo de serviços. Ou seja, cada um dos serviços do OpenStack é registado no Keystone. Cada um dos serviços possui um endpoint2 e um utilizador. O serviço keystone desempenha um papel fundamental para os
ou-tros serviços que utilizam o serviço de keystone como uma API unificada comum do OpenStack. É ele que sustenta a verificação e listagem de serviços disponíveis a todos os outros serviços do OpenStack. Quando um serviço do OpenStack recebe uma solicitação de um utilizador, ele verifica com o serviço de keystone se o utilizador está autorizado a fazer tal solicitação.
Neutron (Serviço de rede)
1https://pt.wikipedia.org/wiki/iSCSI 2
O Neutron (serviço de rede) é o serviço de rede do OpenStack que ativa a conectividade de rede como serviço para outros serviços do OpenStack, como por exemplo o OpenStack Com-pute. Fornece uma API aos utilizadores para definirem as suas próprias redes e associarem interfaces do servidor a ela. A sua arquitectura baseia-se em plugins que permite aos utilizado-res usufruir das vantagens de recursos disponíveis nos dispositivos de rede específicos. Isto é, os plug-ins podem ser implementados para acomodar diferentes equipamentos de rede e software, fornecendo flexibilidade para a arquitectura e implementação do OpenStack.
Qualquer rede configurada deve ter, pelo menos, uma rede externa. Ao contrário das outras redes, a rede externa não é apenas uma rede virtual. Representa uma abstração da rede física, sendo acessível por qualquer endereço IP fora do ambiente virtual que esteja ligado diretamente à rede física ou que possua rota definida.
Além de redes externas, qualquer rede configurada tem uma ou mais redes internas (sub-redes). Estas redes definidas por software conectam-se diretamente às máquinas virtuais (Vir-tual Machines-VMs). Apenas as VMs da rede interna, ou aquelas em sub-redes conectadas através de um router, podem aceder VMs conectados diretamente a essa rede.
Os routers virtuais são necessários para conectar as VMs à rede exterior. Cada router tem uma porta de entrada ligada a uma rede externa e uma ou mais interfaces ligadas a redes internas. Assim como um router físico, sub-redes podem aceder máquinas em outras sub-redes que estão conectados ao mesmo router, e as máquinas podem aceder à rede externa através deste router. Para que uma VM seja acedida externamente é necessário alocar um endereço IP externo, ou endereço público.
Nova (Serviço de computação)
O serviço “nova” gere o ciclo de vida de instâncias de computação no ambiente do OpenStack, ou seja permite iniciar e parar instâncias virtuais, é responsável pela gestão da rede virtual para cada instância que faz parte dum projeto. Também permite criar e editar grupos de segurança e adicionar ou remover volumes. Para o seu funcionamento requer os seguintes serviços básicos do OpenStack: keystone, glance e neutron. Por exemplo, um utilizador autenticado com acesso ao glance e a uma rede configurada para as instâncias de máquinas virtuais no OpenStack já tem todas as condições para criar novas máquinas virtuais. Os requisitos necessários são um par de chaves3 e um grupo de segurança.
O serviço “nova” é composto pelos seguintes componentes:
• Nova-api: aceita e responde a chamadas de API de computação do utilizador final; • Nova-conductor: faz a mediação das interações entre o serviço nova-compute e a base de
dados;
• Nova-compute: cria e encerra instâncias de máquina virtual por meio de APIs do hypervi-sor;
• Nova-scheduler: serviço que determina como responder às solicitações de computação;
3
• Base de dados: efetua o armazenamento dos estados (VMs em execução, redes disponíveis) “build-time” e “run-time” da infraestrutura cloud.
Swift (Serviço de armazenamento de objetos)
O Swift (serviço de armazenamento de objetos) é o serviço responsável pelo armazenamento e recuperação de objetos através de uma API baseada em HTTP RESTful. É escalável e pode gerir grandes quantidades de dados não estruturados a baixo custo. A autenticação e autorização para leitura e escrita de dados é gerida pelo Keystone. O Swift armazena conteúdo de dados, como documentos, imagens, backups, vídeos e assim por diante.
2.6
Outras Sistemas de Computação na Cloud
Esta secção descreve outros sistemas de computação na cloud. Isto é, faz uma breve descrição de outros provedores de serviços de computação na cloud.
2.6.1
Amazon Web Services (AWS)
A Amazon Web Services (AWS) é uma plataforma de serviços na cloud que oferece um conjunto de serviços, nomeadamente computação, armazenamento, base de dados, distribuição de con-teúdo e outras funcionalidades para ajudar as empresas no seu dimensionamento e crescimento [15]. Alguns dos serviços da computação da AWS são: Amazon EC2 (Elastic Compute Cloud), AWS Lambda.
O Amazon EC2 é um serviço web que oferece capacidade de computação redimensionável na cloud. Isto é, o Amazon EC2 pode ser entendido como um ambiente de computação virtual, permitindo aos utilizadores, através de uma interface Web, criar, utilizar e gerir máquinas vir-tuais com sistemas operativos Windows e Linux, ou mesmo iniciar tais máquinas de acordo com as necessidades das aplicações. De acordo com as regras da Computação na cloud, o utilizador paga apenas pelos recursos consumidos, por instâncias e/ou transferência de dados (cobrado por gigabyte de dados transferidos) [16].
O Amazon EC2 fornece uma ferramenta denominada AMIs (Amazon Machine Images), que funcio-nam como uma espécie de template e contém uma pré-configuração de software (por exemplo, sistema operativos e aplicações), a partir das quais se podem criar instâncias (máquinas virtu-ais), que são cópias executáveis da AMI. Essas instâncias, que podem ser múltiplas e inclusive de diferentes tipos, são executadas até que sejam paradas ou finalizadas pelo utilizador; se uma instância falhar por uma razão ou outra, pode-se criar uma nova a partir da AMI seleccionada [16].
O AWS Lambda também é um serviço de computação da AWS, que permite executar todas as aplicações para back-end sem ser necessário possuir ou gerir servidores. Isto é, basta executar a aplicação, o AWS Lambda encarrega-se de todos os itens necessários para executá-lo e alterar a sua escala com alta disponibilidade se for necessário. Neste serviço o utilizador paga consoante o tempo que utilizou os recursos [17].
(EBS), que é um sistema de armazenamento em bloco usado para armazenar dados persistentes. O Amazon EBS é adequado para instâncias do EC2, fornecendo volumes de armazenamento de nível de bloco. Ele possui três tipos de volumes que são: “General Purpose” (SSD), “Provisioned IOPS” (SSD), e “Magnetic”. Esses três tipos de volume diferem em desempenho, características e custo [18].
2.6.2
Microsoft Windows Azure Plataform
O Windows Azure é fornecido pela Microsoft como uma plataforma como um serviço (PaaS). Esta plataforma fornece serviços acessíveis ao desenvolvedor para criar aplicações e armazenar da-dos. Os seus principais elementos são: Windows Azure, SQL Azure e Windows Azure AppFabric [19].
Windows azure
O Windows Azure é composto por cinco componentes [19]:
• Compute: o Windows Azure Compute fornece aos desenvolvedores uma plataforma para execução, armazenamento e gestão de aplicações;
• Armazenamento: o serviço de armazenamento permite armazenar recursos na cloud. Es-ses recursos podem ser ficheiros, como documentos, imagens ou vídeos, juntamente com informações relevantes de metadados, ou podem ser informação estruturada ou semies-truturada;
• “Fabric controller”: a principal tarefa de Fabric Controller é fornecer uma visão única, sobre a qual os serviços de computação e armazenamento estão localizados;
• “Content Delivery Network”- (CDN) [20]: as redes de entrega de conteúdos são redes distribuídas de servidores que podem entregar, de forma eficiente, conteúdos da Web aos utilizadores. As CDNs armazenam os conteúdos em cache em servidores Edge em localizações do ponto de presença (POP) que estão próximas dos utilizadores finais, para minimizar a latência;
• “Connect”: permite aceder aplicações na cloud duma forma segura como se o cliente estivesse dentro da intranet da organização. Também permite criar uma conexão direta entre a plataforma baseada na cloud e a organização da data center.
SQL azure
O elemento SQL Azure da plataforma Azure fornece serviços de armazenamento para bases de dados relacionais.
Windows azure appFabric
O Windows Azure AppFabric funciona como uma camada de middleware baseada na cloud, como forma de integrar aplicações existentes, sendo muito útil em situações de cloud híbridas [19].
2.6.3
Aneka
A Aneka é uma plataforma de computação na cloud desenvolvida pela Manjrasoft, em Melbourne, Austrália. Ela é projetada para suportar o desenvolvimento e implantação de aplicações
distri-buídas em cloud. Isto é, desempenha o papel de PaaS (Plataforma como um Serviço) para a computação na cloud [21]. Ela (Aneka) é composta por uma coleção de recursos físicos e vir-tuais conectados através de uma rede, que pode ser a Internet ou uma intranet privada. Cada um desses recursos hospeda uma instância do Aneka Container representando o ambiente de execução onde as aplicações distribuídas são executadas [21].
2.7
Virtualização
A virtualização na computação é abstração dos componentes físicos em objetos computacionais lógicos [22]. Isto é, os recursos computacionais reias são “transformados” em recursos virtuais, ou seja consiste na criação de um ambiente virtual que simula um ambiente real permitindo o uso de sistemas operativos e aplicações [23]. Pode-se virtualizar uma plataforma de hardware (processadores, memória, armazenamento e conectividade de rede), ou um sistema operativo [24]. A forma de virtualização mais conhecida é através de máquina virtual ou “Virtual Machine (VM) ”. Uma máquina virtual é a simulação de um computador real, ela oferece um ambiente completo, muito semelhante ao de uma máquina física real, tendo o seu próprio sistema ope-rativo, softwares de aplicação e serviços de rede. De uma outra forma, criar uma máquina virtual, é a mesma coisa que criar um computador dentro de outro computador. É executada numa janela do Computador real, tal como qualquer outro programa, dando ao utilizador final a mesma experiência que teria se utilizasse o próprio sistema operativo anfitrião [25]. Para criar uma máquina virtual, antes precisa de se instalar um software que fornece um ambiente sobre o qual as máquinas virtuais se operam. Este software é chamado VMM (Virtual Machine Monitor - Monitor de Máquina Virtual). O VMM é um componente de software que hospeda as máquinas virtuais, também chamado de hypervisor [22].Existem múltiplas soluções de virtua-lização [26], isto é, vários VMMs ou hypervisor, como por exemplo: VMWare, KVM, Xen, QEMU etc. Neste trabalho, o hypervisor utilizado para a virtualização foi KVM (Kernel-based Virtual Machine), visto que é o recomendado pela Infraestrutura Cloud OpenStack Versão ”Mitaka”. A computação na cloud utiliza a virtualização de recursos computacionais disponíveis como por exemplo: máquinas virtuais, armazenamento virtual e redes virtuais. No caso de serviços de computação e da utilização de máquinas virtuais, o backup é um método que não pode faltar em sistemas virtualizados, visto que a imagem virtual contém tudo o que é necessário para executar a aplicação e pode ser transparente para migração entre máquinas físicas [27].
A virtualização oferece inúmeras vantagens, entre as quais se destacam [28]:
• Melhor aproveitamento da infraestrutura existente: ao executar vários serviços num ser-vidor ou conjunto de máquinas, por exemplo, pode-se aproveitar a capacidade de proces-samento destes equipamentos o mais próximo possível de sua totalidade;
• O parque de máquinas é menor: com o melhor aproveitamento dos recursos já existentes, a necessidade de aquisição de novos equipamentos diminui, assim como os consequen-tes gastos com instalação, espaço físico, refrigeração, manutenção, consumo de energia, entre outros;
• Gestão centralizada: dependendo da solução de virtualização utilizada, fica mais fácil monitorar os serviços em execução, já que a sua gestão é feita de forma centralizada; • Diversidade de plataformas: pode-se ter uma grande diversidade de plataformas e, assim,
Todavia, ainda é de realçar que a virtualização também tem as suas desvantagens, nomeada-mente são [28]:
• Sobrecarga das máquinas virtuais: a quantidade de máquinas virtuais que um computa-dor pode suportar não é ilimitada, razão pela qual é necessário encontrar um equilíbrio para evitar sobrecarga, caso contrário, o desempenho de todas as máquinas virtuais será afetado;
• Segurança: se houver uma vulnerabilidade de segurança no VMM, por exemplo, todas as máquinas virtuais poderão ser afetadas pelo mesmo problema;
• Contingência: nas aplicações críticas, é importante ter um computador que possa atuar imediatamente no lugar da máquina principal (como um servidor), pois se esta parar de funcionar, todos os sistemas virtualizados que rodam nela também serão interrompidos;
• Desempenho: a virtualização pode não ter bom desempenho em todas as aplicações, por isso é importante avaliar muito bem a solução antes de sua efetiva implementação.
2.8
Trabalhos Relacionados
Alguns trabalhos já foram desenvolvidos na área de tolerância a falhas e alta disponibilidade na infraestrutura de cloud OpenStack e nos servidores nele alojado.
Um dos exemplos é o trabalho de [MARTINS,2014] [27] intitulado de “Tolerância a Falha em
um Ambiente de Computação em Nuvem open source”. Na sua obra ele desenvolveu um
mecanismo tolerante a falhas no OpenStack. Implementou um mecanismo de redundância nas máquinas virtuais instanciadas nos nós da cloud, em que se um nó apresentar uma falha transi-tória ou intermitente, a máquina virtual ficará armazenada num local seguro, aguardando que o nó recupere da falha. Após a implementação concluiu que o mecanismo desenvolvido é viável e eficiente, isto porque, quando o nó se recuperar duma falha, a máquina virtual nela instanciada não é perdida, voltando a ficar ativa e disponível para o utilizador.
No trabalho de [EMER,2016] [29] com título de “Implementação de alta disponibilidade em
uma empresa prestadora de serviços para Internet”, foi implementado um ambiente de alta
disponibilidade para uma empresa prestadora de serviços para internet utilizando ferramentas de código aberto. Desenvolveu-se uma solução de alta disponibilidade, baseada no uso de um “Cluster” de computadores e virtualização. Para efetuar a implementação foi necessário um software para a replicação e outro para a gestão do “Cluster” das máquinas virtuais. Para a gestão do “Cluster” das máquinas virtuais foi utilizado o software Pacemaker e para a repli-cação dos dados foi utilizado o software DRBD (Distributed Replicated Block Device). Após a implementação foram executados testes para simular falhas de hardware, de energia elétrica e de software, com o objetivo de validar o ambiente de alta disponibilidade desenvolvida. Por fim chegou se a conclusão que o tempo de indisponibilidade dos serviços no ambiente de alta disponibilidade é consideravelmente menor em relação ao antigo ambiente da empresa (sem alta disponibilidade).
2.9
Conclusão
Este capítulo serviu de base para clarificar os conceitos associados a computação na cloud. Tam-bém contribuiu para compreender o funcionamento da infraestrutura da cloud OpenStack, isto é, o OpenStack é framework “open source” que fornece uma solução de infraestrutura como um serviço. A arquitectura do framework OpenStack depende da sua versão, em cada seis meses é lançada uma versão. Neste trabalho foi implementado a versão OpenStack “Mitaka”. Ainda de realçar que existem outros sistemas de cloud, como por exemplo o Amazon Web Services, Microsoft Windows Azure Plataform, Aneka etc. Por fim, concluiu que a tecnologia de virtua-lização está associado a computação na cloud, pois, permite criar máquinas virtuais e outros tipos de virtualização como por exemplo virtualizar processadores, memória etc.
Capítulo 3
Tolerância a Falhas
3.1
Introdução
Este capítulo apresenta os conceitos de tolerância a falhas, listando quais os tipos de falhas e técnicas de tolerância a falhas. Para além dos conceitos de tolerância a falhas, abarca os conceitos de alta disponibilidade, com incidência sobre a alta disponibilidade na infraestrutura da cloud OpenStack, mencionando as tecnologias que permitem a alta disponibilidade através da redundância de hardware, e as ferramentas de alta disponibilidade no software.
3.2
Conceitos
Na tentativa de implementar sistemas mais confiáveis, foram desenvolvidos meios para oferecer mais confiança aos sistemas, este processo chama-se tolerância a falhas. Sabendo que falhas são inevitáveis, procura-se atribuir aos sistemas a capacidade de tolerar a ocorrência de falhas, apresentando funcionamento desejado ou pré-definido, evitando assim danos ao utilizador [30]. A tolerância a falhas pode ser entendida como a capacidade de um sistema continuar a fornecer o seu serviço mesmo na presença de avarias de alguns dos seus componentes [5] [31]. Isto é, são técnicas que fazem com que o sistema continue a funcionar de uma forma satisfatória mesmo na presença de falhas [32].O objetivo primordial de tolerância a falhas é garantir a disponibilidade e a confiabilidade dos serviços, bem como execução das aplicações. Para minimizar o impacto da falha na execução do sistema e das aplicações, as falhas devem ser antecipadas e tratadas proactivamente [33].
No contexto de tolerância a falhas, os termos fault (falha), error (erro), failure (avaria) apre-sentam diferentes significados.
Falha (“fault”): uma falha é uma alteração do funcionamento de um componente (hardware ou
software) do sistema [34]. Uma falha pode ocorrer de forma acidental ou intencional. Podemos classificar as falhas em três grandes grupos [34]:
• Falhas de projeto (hardware ou software): uma falha pode ocorrer em qualquer etapa do desenvolvimento de um sistema: especificação, desenho, implementação;
• Falhas físicas: defeitos de produção, deterioração dos componentes, interferência; • Falhas de interação homem – máquina: inputs errados, ataques ou intrusões.
Erro (“error”): um erro é a manifestação de uma falha [34]. Um erro provoca a corrupção
de elementos de dados (afecta o estado do sistema). Se um erro causa ou não a avaria do sis-tema depende de [34]: composição do sissis-tema (por exemplo, existe redundância que mascare a ocorrência do erro) e atividade do sistema (por exemplo, o estado que contém o erro pode
não ser suficientemente duradoiro para causar uma avaria).
Avaria (“failure”): uma avaria é qualquer alteração do comportamento do sistema em relação
ao esperado (i.é, em relação à sua especificação) [34]. A figura 3.1 demonstra o percurso para a geração de uma avaria.
Figura 3.1: Percurso para avaria [35].
Os atributos de confiança no funcionamento de um sistema são [34]: fiabilidade (reliability), dis-ponibilidade (availability), segurança contra falhas acidentais (safety),confidencialidade (con-fidentiality), integridade (integrity) e facilidade de manutenção (maintainability).
• Fiabilidade: probabilidade de o sistema funcionar de acordo com as especificações, dentro de certas condições, durante um certo período de tempo [34];
• Disponibilidade: probabilidade de o sistema estar operacional num dado instante de tempo [34]; • Segurança contra falhas acidentais: probabilidade de o sistema ou estar operacional
exe-cutando as suas funções corretamente, ou parar as suas funções de forma a não provocar dano a outros sistemas ou pessoas que dele dependam [34];
• Confidencialidade: inexistência de acessos não autorizados à informação [34]; • Integridade: inexistência de alterações incorretas do estado do sistema [34];
• Facilidade de manutenção: probabilidade de um sistema com avarias ser reparado conti-nuando a funcionar [34].
Latência
A latência de falha pode ser entendida como o período de tempo desde a ocorrência da fa-lha até a manifestação do erro devido àquela fafa-lha. Por sua vez, a latência de erro é definido como o período de tempo desde a ocorrência do erro até a manifestação da avaria devida àquele erro. Pode se afirmar que o tempo total desde a ocorrência da falha até o aparecimento do de-feito é a soma da latência de falhas e da latência de erro [36].
Em suma, num sistema de computação as falhas são inevitáveis, porque os componentes fí-sicos envelhecem e sofrem com interferências externas, sejam ambientais ou humanas. O soft-ware, e também os projetos de software e hardsoft-ware, são vítimas de sua alta complexidade e da fragilidade humana em trabalhar com grande volume de detalhes ou com deficiências de especificação.
Nó: é uma máquina (física ou virtual) que executa as operações do servidor independentemente
do seu próprio sistema operativo. Como qualquer nó pode falhar, atender aos objetivos de dis-ponibilidade requer que vários nós operem como parte de um cluster [37].
“Cluster”: são dois ou mais nós interligados por uma rede com o objetivo de aumentar o
de-sempenho ou disponibilidade de um serviço, isto é executam os serviços em coordenação uns com os outros para completar tarefas individuais como parte de um serviço maior, onde o reco-nhecimento mútuo permite que um ou mais nós compensem a perda de outro [37].
“Server failure”: é a incapacidade de um nó (servidor) responder adequadamente às
solici-tações do cliente. Isso pode ser devido a uma falha completa, problemas de conectividade ou porque o servidor foi sobrecarregada devido a uma elevada solicitação [37].
“Failover”: é um processo no qual um outro servidor recebe os serviços que estavam a ser
executados no servidor que falhou, isto é, quando um servidor falha o serviço é redirecionado para outo servidor para preencher a lacuna de serviço [37].
“Failback”: é a restauração de responsabilidades para um nó do servidor conforme ele se
re-cupera de uma falha. Isto é, tem-se um retorno dos serviços para o servidor de origem quando este estiver disponível [37].
Replicação: é a criação de cópias de armazenamentos de dados ou processos críticos para
permitir acesso síncrono confiável entre os servidores que pertencem ao “Cluster” com o in-tuito de garantir a redundância, o que torna o sistema tolerante a falhas, ou seja se um servidor falhar tem um outro servidor para retomar o serviço, contribuindo assim para um maior balan-ceamento de carga e a alta disponibilidade do sistema [37].
“Quorum” : o Quorum especifica o número mínimo de nós que devem ser funcionais num
“Cluster” de nós redundantes para que o “Cluster” permaneça funcional. Quando um nó falha e o “Failover” transfere o serviço para outros nós, o sistema deve garantir que os dados e os processos permaneçam sãos. Para determinar isso, os conteúdos dos nós restantes são compa-rados e, se houver discrepâncias, um algoritmo de regras maioritárias é implementado [38].
3.3
Tipos de Falhas
Quando um sistema apresenta algum tipo de falha, é sinónimo dizer que o sistema não está a proporcionar os serviços de acordo com aquilo que foi preconizado. Todavia, um sistema pode apresentar algumas falhas mais ainda assim funcionar normalmente. Portanto, de acordo com a natureza da falha, deve ser realizada a ação apropriada [5]. As falhas detetadas podem ocorrer em diferentes componentes do sistema [39] [40]:
• Falha de rede: esta falha ocorre quando os dados não chegam ao destino por vários moti-vos, como perda de pacotes, falha de destino, falha de link e assim por diante;
• Falha física: falhas que ocorrem no hardware, como falhas da CPU, falhas de memória e assim por diante;
• Falha de mídia: erros que surgem devido à falta de meios de comunicação;
• Falha de finalização de serviço: ocorre quando a vida útil do recurso se acaba, mas a aplicação ainda requer o uso de recursos.
As falhas podem ser divididas em várias categorias [39] [40]:
• Falha transitória: este tipo de falha ocorre uma vez e depois desaparece. Caso a operação for repetida, a falha não acontecerá novamente. Se a temporização de uma transmissão se esgotar e for executada novamente, provavelmente funcionará desta segunda vez [27]; • Falha intermitente: são falhas que se repetem de forma alternada. Estas falhas não são boas, porque resultam devido à falha de cada componente ou do funcionamento inapro-priado entre os componentes, por exemplo, uma conexão defeituosa;
• Falha permanente: este tipo de falha ainda permanece no sistema,até os sistemas defei-tuosos serem reparados.
3.4
Técnicas de Tolerância a Falhas
Dependendo das políticas e procedimentos, as técnicas de tolerância a falhas podem ser dividi-das em seguintes categorias [8] [33] : tolerância a falhas reativa , tolerância a falhas proactiva e mascaramento de falhas.
Tolerância a falhas reativa
As políticas de tolerância a falhas reativas reduzem o efeito de falhas na execução da aplicação quando a falha realmente se manifesta. Existem várias técnicas baseadas nessas políticas, como “checkpoint”, replicação, migração do trabalho [33] [35].
• Checkpoint: quando uma tarefa falha, é permitido que ela seja reiniciada a partir do seu estado crítico recentemente armazenado e não desde o início. Esta técnica de tolerância a falhas é eficiente no nível de tarefa para aplicações de longa duração [41];
• Replicação: várias réplicas de tarefas são executadas com recursos diferentes, para que a execução possa ter sucesso. A técnica de replicação consiste em facilitar a criação de réplicas ou cópias de um mesmo objeto em meios físicos diferentes, garantindo assim que, no caso de uma falha num dos dispositivos, o cliente seja redirecionado de forma transparente para outro que tenha uma réplica do objeto ativo [30];
• Migração de trabalho: Quando haja falha de qualquer tarefa, a tarefa em causa pode ser migrada para outra máquina. Essa técnica pode ser implementada utilizando o HAProxy para redirecionar os pedidos para outra máquina[20] [35].
Tolerância a falhas proactiva
O objetivo primordial das políticas proactivas de tolerância a falhas é evitar a necessidade de recuperação de faltas, erros e falhas, prevendo-os e proactivamente substituir os componentes suspeitos e trabalhar na manutenção de outros componentes, conforme é ilustrado na figura 3.2. Algumas das técnicas que se baseiam nessas políticas são: rejuvenescimento do software, migração preventiva, etc. [33] [35].
Figura 3.2: Cronograma para a precaução de um sistema de detecção de falhas [39].
• Rejuvenescimento de software: é uma técnica que projeta o sistema para reinicializações periódicas. Isto reinicia o sistema com o estado limpo [6];
• Migração preventiva: a migração preventiva depende de um mecanismo de controlo de “feedback-loop” onde a aplicação é constantemente monitorizada e analisada.
Mascaramento de falhas
O mascaramento de falhas é uma técnica de redundância estrutural que mascara as falhas dentro dum conjunto de módulos redundantes. Vários módulos idênticos executam as mesmas funções, e suas saídas são votadas para remover erros criados por um módulo defeituoso [8]. Esta téc-nica garante resposta correta mesmo na presença de falhas. A falha não se manifesta como erro, o sistema não entra em estado erróneo e, portanto, erros não precisam ser detectados, confinados e recuperados. No entanto, em caso de falhas permanentes, a localização e o re-paro da falha ainda são necessários [36]. A tabela 3.1 exemplifica os mecanismos normalmente utilizados para implementação de mascaramento de falhas.
Tabela 3.1: Mecanismo para mascarar falhas (Adaptado de [36]).
Mecanismo para mascarar falhas Mecanismo Aplicado a:
Replicação de componentes
Qualquer componente de hardware ECC (código de
correção de er-ros)
Informação transmitida ou armazenada
Diversidade, programação n-versões
Especificação, projetos, programas
Blocos de recupe-ração
3.5
Gestão de Tolerância a Falhas na Computação na Cloud
Numa plataforma de cloud são identificáveis três camadas: recursos físicos, VMs (virtual ma-chines) e aplicações, conforme é apresentado na figura 3.3. Cada uma delas (camadas) está sujeita a eventuais falhas. Sendo assim, numa plataforma de cloud pode surgir três tipos de falhas: falha de hardware, falha de VMs e falha de aplicação [7].Figura 3.3: Arquitectura de computação na cloud [7].
Uma das dificuldades para implementar os mecanismos de tolerância a falhas numa arquitec-tura de cloud pode ser resumido por esta pergunta(ver figura 3.4): quais dos intervenientes da cloud (provedor ou cliente) é o mais capaz de gerir as falhas, dependendo de seus direitos de acesso na arquitectura da cloud? Por outras palavras, é razoável deixar exclusivamente a responsabilidade de gerir tolerância a falhas para um dos interveniente de cloud sabendo que: falhas de hardware só podem ser detectadas e reparadas pelo provedor de cloud; falhas de VM podem ser detectadas pelos dois participantes, mas apenas reparadas pelo provedor de cloud; e falhas de aplicação só podem ser detectadas pelo cliente, mas podem ser reparadas pelos dois intervenientes [7].
Figura 3.4: Gestão de tolerância a falhas na computação na cloud.
É de realçar que existem duas visões de gestão de tolerância a falhas (de acordo, com esquema apresentado na figura 3.4) O primeiro consiste em dar as responsabilidades de detecção e reparo para um participante da cloud (exclusivamente), enquanto o segundo é aproveitar as habilida-des dos dois tipos de participantes (colaborativo). De acordo com essas duas visões, serão
apresentadas algumas técnicas de tolerância a falhas para os três tipos de falhas mencionadas anteriormente: hardware, VM e aplicação [7].
3.5.1
Gestão Exclusiva de Tolerância a Falhas
Nessa secção serão apresentadas as técnicas exclusivas de tolerância a falhas para os três tipos de falhas: aplicação, VM e hardware.
Tolerância a falhas na aplicação
AS falhas de aplicação são detectáveis apenas no nível do cliente. Para cada aplicação, o cliente implanta na cloud componentes de software especiais chamados sensores, que monitoram a aplicação. De acordo com o monitoramento, um sensor pode desencadear a execução de um procedimento para reparar a aplicação, quando esta funcione mal. Os procedimentos para reparar uma aplicação com falha são [7]:
• O primeiro procedimento diz respeito à aplicação “stateless” (como loadbalancers, por exemplo, HAProxy). Este reparo consiste em reiniciar o servidor do sistema defeituoso na mesma VM.
• O segundo procedimento diz respeito a servidores “statefull” (por exemplo, a base de dados MySQL). Neste caso, o cliente deve implementar um mecanismo para salvar o estado do servidor para que possa ser restaurado antes que o servidor seja reiniciado.
Tolerância a falhas nas VMs
As falhas de VM podem ser detectadas e reparadas pelos dois participantes (provedor e cli-ente) da cloud. Neste nível as políticas de reparo são implementadas exclusivamente por um deles. O reparo da VM com falha é organizado como segue [7]: o nível do cliente solicita que a cloud libere a VM com falha; aloca uma nova VM; implanta e inicia os servidores que estavam em execução na VM com falha; e restaura o estado desses servidores no caso de servidores “sta-tefull” [7].Quando a gestão é feita pelo cliente, cabe a ele implementar o seu próprio sistema de monitoramento, mas é uma tarefa complexa e leva a desperdício de recursos de redes. Esta tarefa está mais indicado para o provedor de cloud, pois tem acesso direto aos hypervisor de VM, visto que é através do hypervisor recolhe informações detalhadas sobre o status da VM, informações que permitem implementar soluções mais precisas de tolerância a falhas [7].
Tolerância a falhas da máquina física: falhas de hardware
As falhas de hardware são detetadas no nível do provedor de cloud. Neste nível, a tolerân-cia a falhas de hardware é implementado com um sistema de monitoramento composto por sensores implantados em diferentes máquinas físicas. Para reparo, o provedor vai iniciar numa nova máquina (ou várias máquinas de acordo com suas capacidades) o mesmo número de VMs, que foram hospedadas na máquina com falha. Além disso, todos os estados da VM devem ser gravados por pontos de salvaguarda (checkpoint) para que a restauração da VM seja possível [7].
3.5.2
Gestão Colaborativa de Tolerância a Falhas
Nessa secção serão relatadas as técnicas colaborativas de tolerância a falhas para também os três tipos de falhas: aplicação, VM e hardware.
Tolerância a falhas na aplicação
As falhas na aplicação são detectadas através da colaboração entre o cliente e o provedor da cloud [7]. As falhas de software (falhas na programação ou aplicação) podem ser exploradas utilizando métodos estáticos e dinâmicos similares àqueles utilizados para o tratamento de fa-lhas de hardware. Um desses métodos é a programação n-version (diversidade), que utiliza redundância estática na forma de programas independentes [5].
Tolerância a falhas nas VMs
No nível do cliente, uma falha da VM detectada por um sensor pode ser devido a uma falha de hardware (máquina que hospeda a VM), que está fora do âmbito do cliente. Uma detecção de falha da VM no nível da cloud permite obter uma decisão mais precisa [7]. Quando a falha é detectada pelo provedor de cloud, o provedor de cloud inicia uma nova VM com os mesmos recursos (rede, memória, CPU, imagem) e em seguida, chama o cliente para reimplantar, rei-niciar e sincronizar a nova VM [7].
Tolerância a falhas da máquina física: falhas de hardware
Do ponto de vista do cliente, a falha de uma máquina física é idêntica às falhas da VM. Quando detectada pelo provedor de cloud, tal falha pode ser resolvida de forma colaborativa durante o reparo de cada VM hospedada na máquina com falha [7].
3.6
Elevada Disponibilidade
A alta disponibilidade consiste em manter disponível por meio da tolerância a falhas, isto é, utilizando mecanismos que fazem a detecção, mascaramento e a recuperação de falhas, sendo que esses mecanismos podem ser implementados a nível de software ou de hardware [29]. O objetivo de implementar um sistema de alta disponibilidade, é com o propósito de garantir que o sistema esteja sempre disponível para atender as solicitações do utilizador.
Um outro conceito que também não se pode dissociar de alta disponibilidade é o balancea-mento de carga, que é um mecanismo que tem por objetivo atingir a escalabilidade, repartindo a carga de processamento entre duas ou mais máquinas [42]. Uma outra tarefa do balancea-mento de carga é promover a melhoria de desempenho do sistema, através da distribuição de tarefas a serem executadas. Isto é, trabalhar de forma que as diferentes máquinas do “Cluster” funcionam como uma única máquina.
A alta disponibilidade pode ser implementada com hardware redundante executando instân-cias redundantes de cada serviço. Se uma peça de hardware que executa uma instância de um serviço falhar, o sistema poderá então fazer o “Failover” para usar outra instância de um
![Figura 3.2: Cronograma para a precaução de um sistema de detecção de falhas [39].](https://thumb-eu.123doks.com/thumbv2/123dok_br/19174280.942510/41.892.152.785.107.390/figura-cronograma-para-precaução-de-sistema-detecção-falhas.webp)

![Figura 3.5: Configuração ativo/passivo [37].](https://thumb-eu.123doks.com/thumbv2/123dok_br/19174280.942510/46.892.214.634.110.455/figura-configuração-ativo-passivo.webp)
![Figura 3.7: Servidor HAProxy [43].](https://thumb-eu.123doks.com/thumbv2/123dok_br/19174280.942510/48.892.214.638.104.449/figura-servidor-haproxy.webp)
![Figura 3.8: Alta disponibilidade de servidores ”HAProxy” com ”Keepalived” : cenário sem falhas (adpatado de [45] [46]).](https://thumb-eu.123doks.com/thumbv2/123dok_br/19174280.942510/49.892.257.681.164.526/figura-disponibilidade-servidores-haproxy-keepalived-cenário-falhas-adpatado.webp)
![Figura 3.10: Replicação dos servidores do MySQL (adaptado de [47]).](https://thumb-eu.123doks.com/thumbv2/123dok_br/19174280.942510/50.892.214.634.438.684/figura-replicação-dos-servidores-do-mysql-adaptado-de.webp)
![Figura 3.11: Pacemaker [48].](https://thumb-eu.123doks.com/thumbv2/123dok_br/19174280.942510/51.892.257.678.106.351/figura-pacemaker.webp)