81,9(56,'$'('2(67$'2'(6$17$&$7$5,1$²8'(6&
&(1752'(&,È1&,$67(&12/Ð*,&$6²&&7
'(3$57$0(172'((1*(1+$5,$(/e75,&$²'((
352*5$0$'(3Ð6*5$'8$d®2(0$8720$d®2,1'8675,$/3*$,
Formação: Mestrado em Automação Industrial
',66(57$d®2'(0(675$'22%7,'$325
Adriano de Andrade Bresolin
Estudo do Reconhecimento de Voz para o
Acionamento de Equipamentos Elétricos via
Comandos em Português
Apresentada em 01 / 08 / 2003, perante a banca examinadora
3URID'UD5HJLQD0'H)HOLFH6RX]D2ULHQWDGRUD&&78'(6& 3URI'U&DUORV$XUpOLR)DULDGD5RFKD8)6&
3URI'U$OFLQGRGR3UDGR-~QLRU&&78'(6& 3URI'U-RVpGH2OLYHLUD&&78'(6&
81,9(56,'$'('2(67$'2'(6$17$&$7$5,1$²8'(6&
&(1752'(&,È1&,$67(&12/Ð*,&$6²&&7
'(3$57$0(172'((1*(1+$5,$(/e75,&$²'((
352*5$0$'(3Ð6*5$'8$d®2(0$8720$d®2,1'8675,$/3*$,
',66(57$d®2'(0(675$'2
0HVWUDQGR$'5,$12'($1'5$'(%5(62/,1²(QJHQKHLUR(OHWULFLVWD
2ULHQWDGRUD3URI
D'UD5(*,1$0$5,$'()(/,&(628=$²&&78'(6&
Estudo do Reconhecimento de Voz para o
Acionamento de Equipamentos Elétricos via
Comandos em Português
DISSERTAÇÃO APRESENTADA COMO REQUISITO À OBTENÇÃO DO TÍTULO DE MESTRE EM AUTOMAÇÃO INDUSTRIAL, DA UNIVERSIDADE DO ESTADO DE SANTA CATARINA, CENTRO DE CIÊNCIAS TECNOLÓGICAS – CCT, ORIENTADA PELA PROFESSORA DRA. REGINA MARIA DE FELICE SOUZA.
7(502'($3529$d®2
(QJ
°°°°
$'5,$12'($1'5$'(%5(62/,1
Estudo do Reconhecimento de Voz para o
Acionamento de Equipamentos Elétricos via
Comandos em Português
Dissertação aprovada como requisito parcial à obtenção do grau de Mestre em Automação Industrial, do Curso de Pós-Graduação em Automação Industrial do Centro de Ciências Tecnológicas da Universidade do Estado de Santa Catarina, pela seguinte banca examinadora:
Orientadora: Profa. Dra. Regina M. De Felice Souza
Departamento de Engenharia Elétrica – CCT/UDESC
Prof. Dr. Alcindo do Prado Júnior
Departamento de Engenharia Elétrica – CCT/UDESC
Prof. Dr. Carlos Aurélio Faria da Rocha Departamento de Engenharia Elétrica - UFSC
Agradecimentos,
Sozinho não se chega a lugar algum!
É com este pensamento que agradeço a todos aqueles que, de uma maneira ou de outra, colaboraram para a conclusão deste trabalho.
Primeiramente agradeço a Deus pela vida.
Agradeço à minha família, em especial à minha esposa Elisabeti pela compreensão nos momentos em que não estive presente. Aos meus pais, Armindo e Delci Bresolin, pelo incentivo que sempre me deram a seguir em busca da educação. Aos familiares de minha esposa: seus pais, Sr. Agenor e Sra. Ermelinda Larsen e sua irmã Magali Larsen, que durante o período de estudos me receberam em sua casa com dedicação, atenção e desprendimento.
Agradeço também ao colega de curso e amigo Eng° Fabrício Novelleto, que foi um companheiro de trabalho na graduação e nesta pós-graduação
SUMÁRIO
/LVWDGH)LJXUDV 9,,, /LVWDGH7DEHODV ; 5HVXPR ;, $EVWUDFW ;,,
,1752'8d®2
80%5(9(+,67Ï5,&2'25(&21+(&,0(172'(92= $,17(5',6&,3/,1$5,'$'('25(&21+(&,0(172'(92=
)81'$0(1726'25(&21+(&,0(172'(92=
02'(/2%È6,&2'(806,67(0$'(5(&21+(&,0(172'(92= $$352;,0$d2$&Ò67,&2)21e7,&$ $$352;,0$d23255(&21+(&,0(172'(3$'5®(6 $$352;,0$d2325,17(/,*Ç1&,$$57,),&,$/,$
352'8d®2(3(5&(3d®2'2620'$)$/$126(5+80$12
352'8d23(5&(3d2'$)$/$ 2$3$5(/+292&$/+80$12 5(35(6(17$d2'$)$/$126'20Ë1,26'27(032('$)5(4hÇ1&,$ $6&$5$&7(5Ë67,&$6'266216'$)$/$ )212/2*,$()21(0$ )RQHPDVGDOtQJXD3RUWXJXHVD &ODVVLILFDomRGRV)RQHPDVGD/tQJXD3RUWXJXHVDGR%UDVLO $V9RJDLV $V6HPLYRJDLV $V&RQVRDQWHV 202'(/2'2289,'2+80$12 $1È/,6(),1$/
26,67(0$'($48,6,d®2'('$'2612&20387$'25
2&21',&,21$0(172'(6,1$/ 2&20387$'25 262)7:$5( $$48,6,d2'('$'26$1$/Ï*,&26 $$PRVWUDJHP $4XDQWL]DomR 3UHFLVmRH([DWLGmR 2(QWUHODoDPHQWR 7UDQVIHUrQFLDGHGDGRVGR³KDUGZDUH´SDUDDPHPyULD 58Ë'2
$75$16)250$'$5É3,'$'()285,(5))7
$66e5,(6'()285,(5 $75$16)250$'$&217Ë18$'()285,(5 $75$16)250$'$',6&5(7$'()285,(5')7 $75$16)250$'$5È3,'$'()285,(5))7 $23(5$d2³%877(5)/<´
%$1&2'(),/7526
02'(/26'($1È/,6((63(&75$/ 202'(/2'2%$1&2'(),/7526 7,326'(%$1&26'(),/752686$'26125(&21+(&,0(172'(92= ,03/(0(17$d2'(80%$1&2'(),/7526 &216,'(5$d®(662%5(2862'26%$1&26'(),/7526
$6´:$9(/(76µ
$75$16)250$'$³:$9(/(7´ $$1È/,6('(08/7,5(62/8d205$3$5$0Ò/7,3/261Ë9(,6
25(&21+(&,0(172'(92=(20$7/$%
2$0%,(17('(352*5$0$d2'20$7/$%
$6)(55$0(17$6'(352*5$0$d2'20$7/$%
26,67(0$'(5(&21+(&,0(172'(92=´3$5/$72´
$48,6,d2'(806,1$/'(620
$$TXLVLomRGR6RPQR0DWODE
$),/75$*(0'26,1$/120$7/$%
3URSULHGDGHVGRILOWURXWLOL]DGR
2&È/&8/2'$))7120$7/$%
*5$9$d2'(80$$02675$'(620
5(&21+(&,0(172'(92=$75$9e6'(3$'5®(6'(5(&21+(&,0(172
$,GHQWLILFDomRGRVLQDO5HFRQKHFLPHQWR /LPLWHV([SHULPHQWDLVGD&RUUHODomR $YLVXDOL]DomRGRVUHVXOWDGRVGR5HFRQKHFLPHQWRGH9R] $75$16)250$'$:$9(/(7 $&,21$0(172'((48,3$0(1726(/e75,&269,$&20387$'25 &LUFXLWR(OHWU{QLFRGH$FLRQDPHQWR
(;3(5,0(172$&,21$0(172(/e75,&2$75$9e6'(&20$1'26'(92=
(;3(5,0(1726'(5(&21+(&,0(172'(3$/$95$6 7HVWHVGH5HFRQKHFLPHQWRFRP))7 7HVWHVGH5HFRQKHFLPHQWRFRP))7'HQVLGDGH(VSHFWUDOH:DYHOHWV 2(VSHFWURJUDPDGDV3DODYUDV (;3(5,0(1726'($&,21$0(172 25RE{.KHSHUD
2V&RPDQGRVQR0DWODESDUDR5RE{.KHSHUD
2V5HVXOWDGRV2EWLGRV
&21&/86®2
5()(5È1&,$6%,%/,2*5É),&$6
/,67$'(),*85$6
'LDJUDPDGHEORFRVGHXPVLVWHPDGHUHFRQKHFLPHQWRGHYR] 'LDJUDPDGHEORFRVGRVLVWHPDGHUHFRQKHFLPHQWRGHYR]DF~VWLFRIRQpWLFR 'LDJUDPDGHEORFRVGRVLVWHPDGHUHFRQKHFLPHQWRGHSDGU}HV 'LDJUDPDGHEORFRFRQFHLWXDOGRVLVWHPDGHHQWHQGLPHQWRGDIDODQRVVHUHVKXPDQRV
'LDJUDPDHVTXHPiWLFRGRSURFHVVRGDSURGXomRHSHUFHSomRGDIDOD 3URFHVVRGDSURGXomRHSHUFHSomRGDIDODHPHVFDODWHPSRUDO 5DLRV;GRDSDUHOKRYRFDOKXPDQR 'LDJUDPDHVTXHPiWLFRGRDSDUHOKRYRFDOKXPDQR (VTXHPDFRPSOHWRGRPHFDQLVPRILVLROyJLFRGDSURGXomRGDIDOD )RUPDVGHRQGDGDH[SUHVVmR³,W¶V7LPH´QRGRPtQLRGRWHPSR (VSHFWURJUDPDVHDPSOLWXGHGDIDOD 0RGHORGR2XYLGR+XPDQR
20RGHORGRVLVWHPDGH$TXLVLomRGH'DGRV 3ODFDGH³KDUGZDUH´GHXPVLVWHPDGH$TXLVLomRGH'DGRV 6LQDOVHQRLGDOGH+]DPRVWUDGRSRUXPTXDQWL]DGRUGHELWV
$2SHUDomR³%XWWHUIO\´ 8VRGD2SHUDomR³%XWWHUIO\´SDUDFRPSXWDUXPD))7GHSRQWRV &RPSDUDomRGRQ~PHURGH0XOWLSOLFDo}HVUHTXHULGDVSHORFiOFXORGLUHWRHSHOD))7
D$SUR[LPDomRSRU5HFRQKHFLPHQWRGH3DGU}HVE$SUR[LPDomRDF~VWLFRIRQpWLFD 0RGHORGHDQiOLVHGHXP%DQFRGH)LOWURV 0RGHORGHDQiOLVH/3& 0RGHORGRDQDOLVDGRUGHXP%DQGRGH)LOWURV DLGHDOEUHDO5HVSRVWDVGHXPEDQFRGHILOWURVGH4±FDQDLVFRPFREHUWXUD
GHXPDIDL[DGHIUHTrQFLDGH)V1òDWp)V14ò (VSHFLILFDomRSDUDXP%DQFRGH)LOWURLGHDOGHFDQDLVGHXPDRLWDYD
1tYHOGHXPDGHFRPSRVLomRGHXPVLQDOSHODV:DYHOHWV ([HPSOLILFDomRGDGHFRPSRVLomRGHXPVLQDOSHOD7UDQVIRUPDGD:DYHOHW1tYHO 'HFRPSRVLomRSDUD0~OWLSORVQtYHLVGDV:DYHOHWV
-DQHODGH&RPDQGRGR0$7/$%
ÈUHDGH0HPyULDGR0$7/$%
7HODFRPSOHWDGRDPELHQWHGHGHVHQYROYLPHQWRGR0$7/$%
-DQHOD³/DXQFK3DG´GR0$7/$%
7HODGR3URJUDPD3DUODWR.
-DQHODGH&RPDQGRGRVLVWHPD3DUODWR
-DQHODGH9HULILFDomRGRVLQDODPRVWUDGRGRVLVWHPD´3DUODWR”
*UiILFRVGRVLQDOGHVRP))7HGHQVLGDGH(VSHFWUDOHPG%GDSDODYUD´3DUH”
*UiILFRVGDUHVSRVWDGRILOWUR3DVVD%DL[DWLSR´%XWWHUZRUWKµGHRUGHPQ
3DUWHGD7HODGRVLVWHPD´3DUODWRµUHVSRQViYHOSHODJUDYDomRGHDPRVWUDVGHVRP
%RWmRTXHH[HFXWDR5HFRQKHFLPHQWRGH9R]
3DUWHGDMDQHODGH&RPDQGRGRVLVWHPD3DUODWRTXHH[LEHRVUHVXOWDGRVGR5HFRQKHFLPHQWRGH9R]
3LQRVGDSRUWDSDUDOHODGHXP&RPSXWDGRU3& &LUFXLWRGHDFLRQDPHQWRHOpWULFR
*UiILFRGRWHVWHGH5HFRQKHFLPHQWRVRPHQWHFRPFRUUHODomRGD))7 &RPSDUDomRJUiILFDGDVSDODYUDV³WUrV´H³VHLV´VLQDO))7H'HQVLGDGH(VSHFWUDO &RPSDUDomRJUiILFDGDVSDODYUDV³WUrV´H³VHLV´:DYHOHWV *UiILFRGRWHVWHGH5HFRQKHFLPHQWRFRPDVFRUUHODo}HVGD))7'HQVLGDGH(VSHFWUDOH:DYHOHWV *UiILFRGRWHVWHGH5HFRQKHFLPHQWRFRPHUURVHDFHUWRV 6LQDODPRVWUDGRH(VSHFWURJUDPDGDSDODYUD³(VTXHUGD´ 6LQDODPRVWUDGRH(VSHFWURJUDPDGDSDODYUD³'LUHLWD´ 5RE{.KHSHUD
/,67$'(7$%(/$6
7DEHOD/LVWDGHVtPERORVIRQpWLFRVGDOtQJXD,QJOHVD$PHULFDQD 7DEHOD/LVWDGHVtPERORVIRQpWLFRVGDVVHPLYRJDLV/tQJXD3RUWXJXHVDGR%UDVLO 7DEHOD/LVWDGHVtPERORVIRQpWLFRVGDVFRQVRDQWHVGD/tQJXD3RUWXJXHVDGR%UDVLO 7DEHOD/LVWDGHVtPERORVIRQpWLFRVGDVYRJDLVGD/tQJXD3RUWXJXHVDGR%UDVLO 7DEHOD&ODVVLILFDomRGDVYRJDLVGD/tQJXD3RUWXJXHVDGR%UDVLO
7DEHOD$V,QWHQVLGDGHVPpGLDVGRVVRQVGRDPELHQWH
5(6802
O mundo globalizado vem derrubando barreiras através da informação. Iniciou-se pelas barreiras comercial e econômica, e num futuro não muito distante poderão ser derrubadas as barreiras dos idiomas, ou seja, pessoas falando em idiomas diferentes, comunicando-se através de equipamentos digitais preparados para traduzir instantaneamente as diferentes expressões lingüísticas pronunciadas pelos mesmos. Esse é o horizonte a ser alcançado pelo reconhecimento de voz.
Nesse novo universo não haveria mais a barreira lingüística entre as pessoas, facilitando a comunicação e os negócios, simplificando o comando de máquinas no ambiente industrial e, acima de tudo melhorando a vida do ser humano como um todo. Além disso, esta ferramenta facilitaria a vida de deficientes físicos, à medida que, com o comando de voz os mesmos teriam acesso a uma infinidade de serviços e empregos, podendo assim ajudar a derrubar a barreira do preconceito.
Este estudo procura pesquisar, descrever e aplicar os conceitos e a teoria envolvida no processo do reconhecimento de voz, deste a aquisição até o reconhecimento do sinal da fala. A meta é desenvolver um sistema que seja capaz de comandar um equipamento elétrico qualquer através de comandos de voz.
$%675$&7
The global world is dropping barriers through the information, began for the commercial and economical barrier, and in a future not very distant we can drop the barriers of the languages, in other words, people speaking in different languages, communicating through prepared digital equipments to translate the different pronounced linguistic expressions instantly for the same ones. This is the horizon to be reached by the voice recognition.
In this new universe there would not be more the linguistic barrier among all the people, facilitating the communication and the businesses, simplifying the command of the industrial machines and above all, improving the human being life as a completely. Besides, this tool can facilitate the life of deficient physical. The voice command can have access the infinity of services and employments could help like this to drop the barrier of the prejudice.
This study seeks to research, to describe and to apply the concepts and the theory involved in the process of the voice recognition, of this the acquisition to the recognition of the speech signal. The goal is to develop a system that is capable to command any electric equipment through voice commands.
,1752'8d®2
O reconhecimento automático da voz por máquinas tem sido a meta de pesquisadores por mais de quatro décadas e tem inspirado maravilhas da ficção científica tais, como o computador HAL de Stanley Kubrick no famoso filme 2001-Uma Odisséia no Espaço e o robô R2D2 de George Lucas no clássico filme Guerra nas Estrelas.
Entretanto, apesar do glamour das máquinas inteligentes que podem reconhecer as palavras faladas e compreender seu significado, e apesar dos enormes esforços e gastos em pesquisas tentando criar tal máquina, nós estamos longe de realizar a desejada meta de uma máquina poder entender um discurso falado de uma pessoa qualquer dentro de um universo de vários falantes e vários ambientes.
80%5(9(+,67Ð5,&2'25(&21+(&,0(172'(92=
Pesquisas sobre o reconhecimento automático da voz têm sido feitas por mais de quatro décadas. A primeira tentativa de arquitetar sistemas de reconhecimento automático de voz pela máquina remonta aos anos 50, quando vários pesquisadores tentaram explorar as idéias fundamentais da acústica e da fonética.
Em 1952, nos laboratórios da Bell, Davis, Biddulph e Balashek construíram um sistema para reconhecimento de um dígito isolado falado por uma pessoa [1].
Em um esforço independente nos RCA Laboratories, Olson e Belar, tentaram reconhecer 10 sílabas diferentes faladas por uma pessoa [2].
No final da década de 50 Fry e Denis, pesquisadores da University College of England, tentaram construir um reconhecedor de fonemas para reconhecer quatro vogais e nove consoantes. Eles usaram um analisador de espectro e uma combinação de padrões para fazer a decisão do reconhecimento. O novo aspecto neste reconhecimento era o uso de informação estatística [3]. Outro esforço notável neste período foi o reconhecedor de vogais Forgie & Forgie, construído no MIT Lincoln Laboratories em 1959. Novamente um analisador de banco de filtros foi usado para prover a informação espectral [4].
Outro esforço japonês na construção de um sistema de reconhecimento de voz foi o trabalho de Sakai e Doshita, da Kyoto University, em 1962, os quais construíram um reconhecedor de fonemas que usava a análise de passagem por zero para fazer o reconhecimento de voz [6].
O terceiro esforço japonês foi o reconhecedor de dígitos de Nagata e seus colegas de trabalho, nos Laboratórios da NEC em 1963 [7]. Este trabalho foi talvez a mais notável tentativa no reconhecimento de voz da NEC, a qual iniciou um longo e altamente produtivo programa de pesquisas.
Na década de 60, três projetos de pesquisa chaves foram iniciados, os quais tiveram uma grande implicação nas pesquisas desenvolvidas no reconhecimento de voz nos 20 anos seguintes. O primeiro foi a pesquisa de Martin e seus colegas dos Laboratórios RCA no final dos anos 60 [8]. Martin desenvolveu um conjunto de métodos elementares de normalização no tempo, baseado na habilidade de detectar o início e o fim da fala. Quase ao mesmo tempo, na União Soviética, Vintsyukn propôs o uso de métodos de programação dinâmica por alinhamento no tempo [9]. Um êxito no final dos anos 60 foi a pesquisa pioneira de Reddyn no campo do reconhecimento da fala contínua através de fonemas dinâmicos [10]. As pesquisas de Reddyn produziram o longo sucesso do programa de pesquisas do reconhecimento de voz da Carnegie Mellon University, a qual permanece nos dias de hoje como líder mundial em sistemas de reconhecimento de voz.
Na década de 70, as pesquisas de reconhecimento de voz tiveram um significante avanço. Primeiro a área de reconhecimento de palavras isoladas ou expressões discretas tornou-se viável com tecnologia baseada nos fundamentos estudados por Velichko e Zagoruyko na Rússia [11], Sakoe e Chiba no Japão [12], e Itakura nos Estados Unidos [13]. Os russos estudaram o uso de padrões de reconhecimento. Os japoneses pesquisaram como métodos de programação dinâmica podiam ser usadas com sucesso. A pesquisa de Itakura apresentou idéias como o LPC (linear predictive coding).
Finalmente os laboratórios AT&T e Bell, iniciaram uma série de pesquisas visando fazer um sistema de reconhecimento de voz que entenda uma pessoa falando.
Ao contrário dos anos 70, onde a meta era reconhecer uma palavra independente, nos anos 80 a meta era reconhecer a fala fluente de frases. Inclui-se nestas pesquisas a de Sakoe da NEC (Nippon Eletric Corporation) [14].
Outra idéia introduzida nos anos 80 foi a aplicação de redes neurais em problemas de reconhecimento de voz [16].
Nos anos 90 as pesquisas continuaram com a busca de um sistema de reconhecimento de voz contínuo. Um exemplo destes sistemas é o DARPA (Defense Advance Research Projetcs Agency), o qual visava reconhecer continuadamente e sem erros palavras dentro de um arquivo de 1000 palavras.
Existem nos dias de hoje várias empresas que comercializam sistemas de reconhecimento de voz. Apesar de nenhum possuir a capacidade de entender 100% das palavras pronunciadas corretamente, dois sistemas destacam-se pelo alto padrão de reconhecimento: O sistema Via Voice da IBM e o sistema Voice da Dragon System .
$,17(5',6&,3/,1$5,'$'('25(&21+(&,0(172'(92=
Um dos mais difíceis aspectos do desenvolvimento das pesquisas no reconhecimento da voz pela máquina é a sua interdisciplinaridade natural. As áreas de conhecimento necessárias à implementação de sistemas de reconhecimentos de voz são:
A) Processamento de Sinais: é o processo de extração de informações relevantes do sinal da fala de uma maneira eficiente e robusta, através da aquisição de dados. Incluindo no processamento de sinais, está a análise espectral usada para caracterizar as propriedades variantes no tempo do sinal da voz, bem como os vários tipos de pré-processamento e pós-processamento do sinal.
B) Aspectos Físicos (acústica): é a ciência que relaciona os sinais físicos e os mecanismos fisiológicos que produzem a fala (o mecanismo vocal do ser humano) e os que percebem a voz (o mecanismo de audição do ser humano).
C) Padrões de Reconhecimento: é o conjunto de algoritmos usados para agrupar dados e criar um ou mais padrões de um conjunto de dados. Estes padrões podem ser posteriormente comparados com um sinal qualquer para efeito de reconhecimento.
D) Análise de Padrões: é o conjunto de procedimentos para estimação de parâmetros de modelos estatísticos.
derivado do significado (pragmático). Incluídos nesta disciplina estão a metodologia da gramática e a análise da linguagem.
F) Fisiologia: Entendimento dos mecanismos do sistema nervoso central do ser humano incluindo a produção e percepção da fala. Muitas técnicas modernas tentam implementar este tipo de conhecimento, como o sistema de redes neurais artificiais.
G) Ciências da Computação: o estudo de eficientes algoritmos para implementar, no software e no hardware, os vários métodos usados num sistema de reconhecimento de voz prático.
O sucesso de sistemas de reconhecimento de voz requer o conhecimento e perícia de um largo campo de disciplinas. No entanto, não é preciso ser um “expert” em todas estas áreas, mais sim ter conhecimento de todas e as suas implicações.
)81'$0(1726'2
5(&21+(&,0(172'(92=
Como descrito no capitulo 1, um sistema de reconhecimento de voz possui a característica da interdisciplinaridade. Com o objetivo de simplificar o entendimento deste sistema complexo, este capítulo apresenta, além do modelo básico de um sistema de reconhecimento de voz, as suas três principais aproximações.
02'(/2%É6,&2'(806,67(0$'(5(&21+(&,0(172'(92=
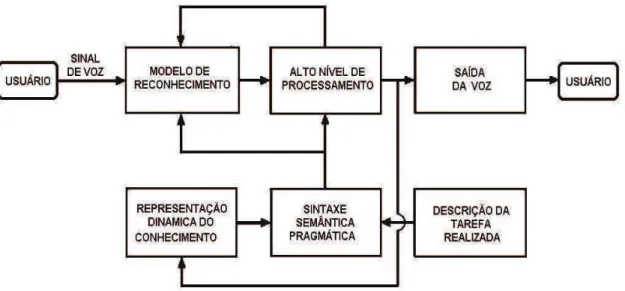
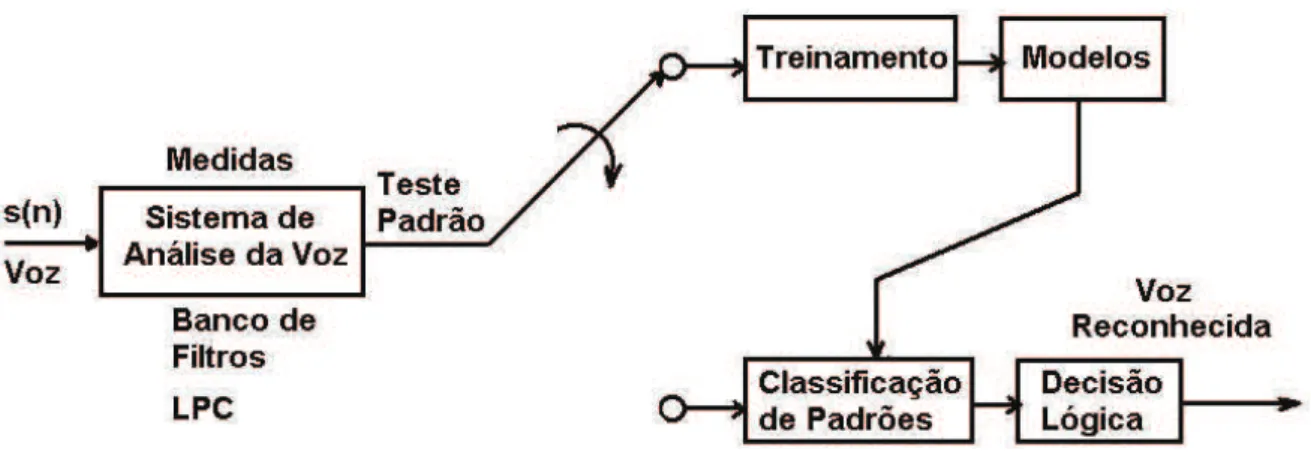
A figura 2.1 apresenta um modelo geral para o reconhecimento de voz. Neste modelo o usuário pronuncia uma palavra (sinal de voz) que passa pelo sistema de reconhecimento onde modelos pré-gravados são testados com o sinal pronunciado. Uma vez encontrados padrões iguais aos gravados o sistema passa pela dinâmica do reconhecimento onde a sintaxe, a semântica e o sentido da palavra são analisados e retorna-se novamente aos modelos gravados para o processamento final e a saída em forma de som (palavra traduzida) ou outra forma qualquer de entendimento do usuário final.
Figura 2.1: Diagrama de blocos de um sistema de Reconhecimento de Voz.
Dentre os diversos sistemas desenvolvidos nas últimas décadas, três aproximações destacam-se no reconhecimento automático da fala por máquinas. O objetivo aqui é prover um entendimento essencial de cada método, bem como os pontos fortes e fracos de cada aproximação.
Genericamente existem três aproximações para o reconhecimento automático da fala, os quais são:
- Aproximação Acústico-fonética.
- Aproximação por Reconhecimento de Padrões. - Aproximação por Inteligência Artificial.
A aproximação acústico-fonética (The acoustic-phonetic approach) é baseada na teoria e postulados da fonética. As distintas unidades fonéticas da linguagem falada geralmente são caracterizadas por um conjunto de propriedades que se manifestam no sinal da fala, ou em seu espectro de frequência. O primeiro passo da aproximação acústico-fonética envolve a segmentação do sinal de voz em regiões discretas no tempo, onde as propriedades acústicas do sinal são representadas por uma (ou possivelmente diversas) unidade fonética (ou classes). Em seguida são nomeados um ou mais rótulos fonéticos para cada região segmentada. O segundo passo é a tentativa de validar a “palavra” na
seqüência de rótulos fonéticos obtidos no primeiro passo.
A aproximação por reconhecimento de padrões (The pattern recognition approach) é basicamente uma aproximação na qual padrões de fala são usados diretamente sem explicitar seu significado. Esse método de aproximação possui dois passos: Treinamento de padrões de fala e o Reconhecimento dos padrões via comparação. O tipo de caracterização da fala via treinamento é chamado de classificação
padrão porque a máquina aprende qual propriedade acústica da classe da fala é confiável e repetível A utilidade deste método está na comparação direta de um sinal de fala desconhecido com um sinal aprendido na fase de treinamento. A aproximação por reconhecimento de padrões é o método mais utilizado nos sistemas de reconhecimento de voz. A escolha deste método se faz pelas seguintes razões:
- Simplicidade de uso. É um método fácil de entender e rico em justificativas, tanto na teoria matemática, quanto na teoria da comunicação.
A chamada aproximação por IA-Inteligência Artificial (The artificial intelligence approach), é uma aproximação híbrida das anteriores, e explora as idéias e os conceitos de ambos os métodos. A inteligência artificial tenta mecanizar o procedimento de reconhecimento de voz através da visualização e análise do sistema e finalmente fazendo a decisão das características acústicas medidas. O conceito principal da inteligência artificial está em estar aprendendo o tempo todo e se adaptando. A IA utiliza redes neurais para aprender as relações entre os eventos fonéticos (acústica, sintaxe, semântica) e o sinal medido, bem como para discriminação de classes de sons.
$$352;,0$d®2$&Ó67,&2)21e7,&$
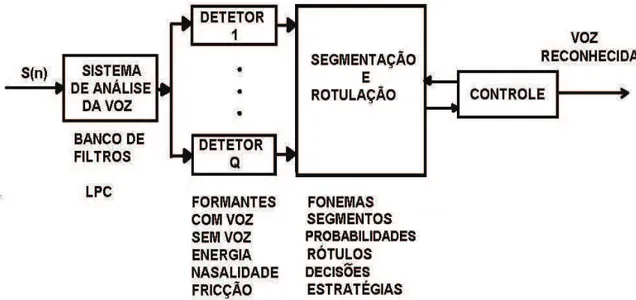
A figura 2.2 mostra o diagrama de blocos da aproximação acústico-fonética para o reconhecimento de voz.
O primeiro passo no processamento é o sistema de análise do sinal de voz (passo comum para todas as aproximações), o qual produz uma representação apropriada (espectro) das características de variação no tempo do sinal de voz. As técnicas mais comuns de análise espectral são: Banco de Filtros, “Linear Predictive Coding” (LPC) e a DFT (Transformada Discreta de Fourier).
Figura 2.2: Diagrama de blocos do sistema de reconhecimento de voz acústico-fonético.
(presença ou não de excitação da fala), formantes (freqüências do sinal e suas três primeiras ressonantes), classificação com ou sem voz (excitação do sinal periódico ou não periódico), porções de alta e baixa energia (amplitude da freqüência). O estágio de deteção das características geralmente consiste de um conjunto de detetores que operam em paralelo e usam o processamento apropriado para fazer a decisão da presença ou não, da característica do som analisado.
O terceiro passo no procedimento é a fase de segmentação e rotulação pelo qual o sistema tenta encontrar regiões estáveis (onde as características mudam muito pouco) e então rotular (marcar) a região segmentada de acordo com as unidades fonéticas individuais.
Muitos problemas estão associados com a aproximação acústico-fonética para o reconhecimento da fala. Estes problemas, em muitos casos, são a causa da falta de sucesso de sistemas de reconhecimento de voz na prática. Entre alguns podemos citar os seguintes:
- O método requer um extensivo conhecimento das propriedades acústicas da unidade fonética. Este conhecimento é, na melhor das hipóteses, incompleto e na pior, totalmente inviável para simples situações, como reconhecimento de vogais.
- A escolha das características é feita principalmente baseada em considerações
ad hoc, ou seja, as escolhas do sistema são baseadas na intuição e não em um bem definido senso de significado.
- O projeto dos classificadores de som não é otimizado.
- Não existe um caminho certo ou real para a rotulação e para o treinamento da fala.
- Falta uniformidade na larga e ampla classe lingüística.
Por causa de todos este problemas, o método acústico-fonético de reconhecimento de voz, apesar de ser uma idéia interessante, precisa de mais pesquisa e entendimento, antes de ser usado com sucesso nos atuais sistemas de reconhecimento de voz.
$$352;,0$d®23255(&21+(&,0(172'(3$'5¯(6
- Características de Medida. Uma seqüência de medidas é feita na entrada do sinal para definir o “teste padrão”. Para sinais de voz, as características de medida são geralmente a saída de algum tipo de analisador espectral, tal como um Banco de Filtros, ou a Transformada Discreta de Fourier (DFT).
- Padrões de treinamento. Um ou mais padrões de teste correspondentes ao sinal da fala são usados para criar um padrão representativo das características deste sinal. O padrão resultante pode ser derivado da média dos sinais, ou um valor estatístico das características.
- Classificação dos Padrões. Aqui um sinal desconhecido (teste) é comparado com cada (som) padrão de referência e a medida de similaridade entre o sinal de teste e cada padrão de referência é computado.
- Decisão Lógica. Neste passo vários padrões de referência com valores similares são usados para decidir qual padrão de referência melhor combina com o sinal de teste desconhecido.
Figura 2.3: Diagrama de blocos do sistema de Reconhecimento de Padrões.
Em geral os pontos fortes e fracos da aproximação por reconhecimento de padrões são:
a) O desempenho do sistema é sensível à soma dos treinamentos dos dados avaliados para criação das classes dos sons. Em outras palavras, quanto maior o treinamento, mais alto é o desempenho na realização da tarefa.
c) Um som de voz não específico e conhecido é usado explicitamente no sistema. Então este método é relativamente insensível à escolha de vocabulários, palavras, perguntas, sintaxe e semântica.
d) A leitura computacional para ambos os padrões de treinamento ou classificação é geralmente linear e proporcional ao número de padrões de treino ou reconhecimento. Então a computação de um grande número de classes de sons torna-se freqüentemente proibitivo.
e) Devido ao sistema ser insensível às classes de sons, as técnicas básicas são aplicadas a uma vasta gama de sons da fala, incluindo frases, palavras e sub palavras. Então um conjunto básico de técnicas desenvolvidas para uma classe de som pode ser diretamente aplicado para diferentes classes de sons, com pequenas ou nenhuma modificações dos algoritmos.
f) É realmente forte a incorporação sintática na estrutura dos padrões de reconhecimento, melhorando a precisão e diminuindo o tempo de computação.
$$352;,0$d®2325,17(/,*È1&,$$57,),&,$/,$
A idéia básica da aproximação por inteligência artificial para o reconhecimento de voz é compilar e incorporar conhecimentos de uma vasta variedade de fontes de conhecimento e resolver o problema. A aproximação por IA usa os conhecimentos acústicos, lexicais, sintáticos, semânticos, e pragmáticos das sentenças. Para melhor explicitar estes conhecimentos, define-se primeiro cada um deles:
- Conhecimento acústico: é a evidência ou não do som, ou seja, o sinal é medido e detecta-se a presença ou não das características do som.
- Conhecimento léxico: a combinação da evidência acústica do som das palavras, especificando um mapa léxico das palavras, ou seja, o significado das mesmas (som da palavra).
- Conhecimento Sintático: a combinação das palavras na forma gramaticamente correta nas sentenças ou frases.
- Conhecimento Semântico: entendido como sendo o significado da palavra, ou seja, o que a palavra quer dizer e se o seu entendimento está de acordo com a sentença.
As diversas fontes de conhecimento precisam ser estabelecidas na aproximação por Inteligência Artificial (IA). Entretanto dois conceitos chaves da Inteligência Artificial são automaticamente conhecidos, a aquisição do conhecimento (aprendizagem) e a adaptação. Um caminho no qual estes conceitos podem ser implementados é via Aproximação por Redes Neurais.
A figura 2.4 mostra um diagrama de blocos de um sistema para o entendimento da fala, baseado no modelo de percepção da fala dos seres humanos.
Figura 2.4: Diagrama de blocos conceitual do sistema de entendimento da fala nos seres humanos.
O sinal de entrada acústico é analisado por um modelo de ouvido humano (Análise Auditiva Preliminar), que providencia a informação espectral sobre o sinal e armazena os dados na memória de armazenamento sensorial (Armazenamento das informações). Ambas as memórias, estática e dinâmica são usadas para armazenar os dados que serão analisados pelos vários detectores de características (audivas, fonéticas etc). Finalmente depois de diversos estágios de refinada detecção das características, a saída final do sistema é uma interpretação da informação da entrada acústica.
352'8d®2(3(5&(3d®2'2
620'$)$/$126(5+80$12
Para um completo entendimento do processamento de um sistema de reconhecimento de voz, inicialmente deve-se compreender como o corpo humano produz e percebe os sons da voz, bem como suas principais características.
352'8d®2(3(5&(3d®2'$)$/$
Inicialmente é necessário mostrar as diferentes classes dos sons da fala, ou fonética, identificando-as através das suas características acústicas as quais são relativamente invariantes através das palavras e locutores.
A figura 3.1 mostra o diagrama esquemático da produção e percepção da fala no ser humano.
Figura 3.1: Diagrama esquemático do processo da produção e percepção da fala
apropriada e na seqüência correta, criando assim o som da fala. Os comandos neuromusculares controlam simultaneamente todos os aspectos do movimento das articulações, incluindo os lábios, a mandíbula, a língua e as saídas de ar pela boca e pelo nariz.
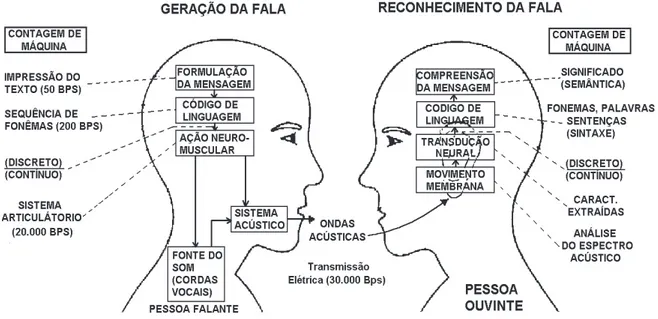
Após a execução da fala pelo locutor, o som produzido propaga-se pelo ar e chega ao ouvinte. Neste momento inicia-se o processo de reconhecimento ou percepção da fala. Primeiro o ouvinte processa o sinal acústico recebido ao longo de uma membrana no interior do ouvido, a qual executa a análise espectral do sinal que chega. Através de um processo de transdução neural, o sinal espectral que sai da membrana no interior do ouvido é transformado em um sinal elétrico no nervo auditivo. A maneira com que o processo ocorre ainda não é bem compreendido pela ciência. O fato é que a atividade neural ao longo do nervo auditivo é convertida em um código de linguagem no cérebro, e finalmente a mensagem é compreendida.
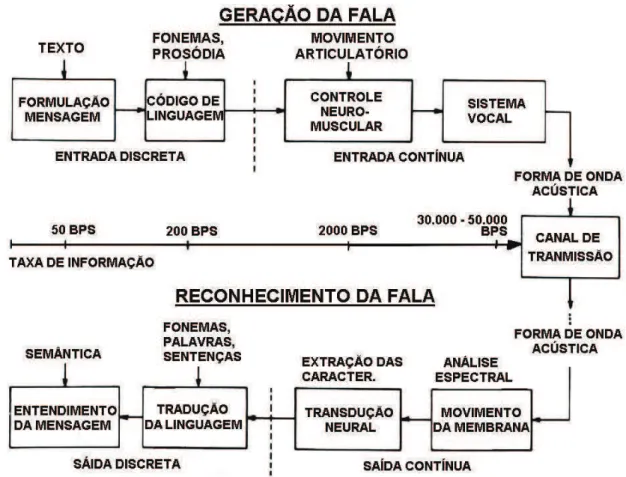
A figura 3.2 mostra os passos dos processos de produção e percepção da fala ao longo de uma linha básica que informa a taxa de tempo nos vários estágios do processo, demonstrando a leve diferença nos processos de produção e percepção da fala
Vê-se que a formulação de uma mensagem (texto) ou o entendimento da mesma pelo cérebro (semântica) tem uma taxa muito baixa de processamento, em torno de 50bps. Já na formulação do código de linguagem (fonemas), a taxa de processamento aumenta para 200 bps, em seguida vem o processo de articulação neuro muscular onde a taxa passa para 2000 bps. No processo final de produção da fala a transmissão é feita na taxa de 30.000 a 50.000 bps.
Os passos do mecanismo de percepção da fala também podem ser interpretados na forma de taxa de processamento, onde seu controle segue um padrão inverso ao do processo de produção da fala. Neste estágio a análise do som é feita rapidamente pelo sistema auditivo, no entanto a medida que o processo de interpretação prossegue a velocidade diminui, ficando em torno de 50 bps (bits por segundo) na fase final de entendimento da mensagem.
2$3$5(/+292&$/+80$12
A figura 3.3 mostra um plano do aparelho vocal humano obtido através do processo de Raios-X. O aparelho vocal humano inicia-se nas “pregas” vocais ou “Glottis” e termina nos lábios.
No ser humano masculino o tamanho do aparelho vocal é de cerca de 17cm. A área do aparelho vocal compreendido pela língua, lábios e mandíbula varia desde zero (totalmente fechada) até cerca de 20cm2. O aparelho nasal inicia-se no “velum” e termina na narina.
O diagrama esquemático do mecanismo vocal humano é mostrado na figura 3.4. O ar entra nos pulmões através do mecanismo de respiração. O ar é expelido dos pulmões através da traquéia, a passagem do fluxo de ar pela laringe provoca a vibração das “pregas” (cordas) vocais.
Figura 3.4: Diagrama esquemático do aparelho vocal humano (Modificada de Lawrence Rabiner, pg 16. [17])
O fluxo de ar é cortado em pulsos quase periódicos, os quais são modulados em freqüência na passagem da faringe, na cavidade da boca e possivelmente na cavidade nasal. Dependendo das varias posições da articulação vocal (boca, língua, mandíbula, véu palatino, etc) diferentes sons são produzidos.
Os pulmões, em associação com a ação dos músculos e a passagem do ar, são responsáveis pela excitação do mecanismo vocal. O músculo força pulsos de ar para fora dos pulmões através dos brônquios e da traquéia.
Quando as “pregas” vocais estão tensas, e o ar flui através delas causando as vibrações, as quais produzem os sons que chamamos de fala ou voz humana.
A fala é produzida como uma seqüência de sons. Então o estado das “pregas” vocais, bem como as posições, formas, e tamanho das varias articulações, mudam constantemente, o que se reflete no som produzido. Este sistema completo é mostrado na figura 3.5.
3.5: Esquema completo do mecanismo fisiológico da produção da fala
5(35(6(17$d®2'$)$/$126'20Ì1,26'27(032('$)5(4hÈ1&,$
O sinal da fala é um sinal que varia vagarosamente no tempo, quando examinado em um curto período (entre 5 e 100 ms). Suas características são razoavelmente estacionárias. Contudo, em longos períodos de tempo (na ordem de 1/5 s ou mais) as características do sinal mudam, refletindo os diferentes sons da pessoa que fala.
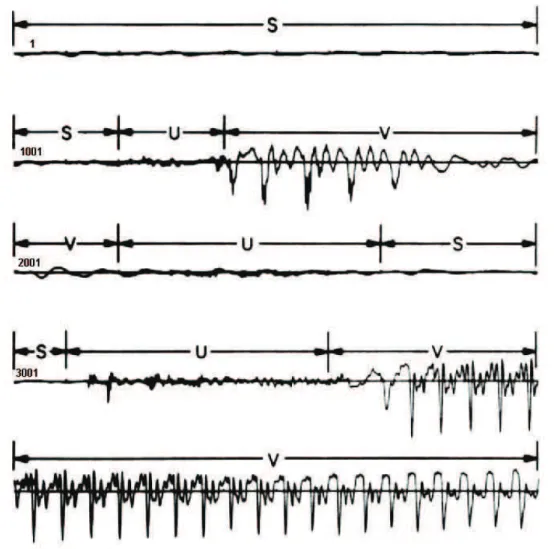
A ilustração destes efeitos está na figura 3.6, na qual as formas de onda mostradas correspondem aos sons iniciais da frase “It’s time ...” , falada por um ser humano
masculino (homem). Cada linha da forma de onda corresponde a 100ms (1/10 s) do sinal; sendo que a linha inteira (todas as 5 linhas) corresponde aproximadamente a 0.5 s.
- Silêncio (S), onde não é produzida a fala.
- Não voz (U) “Unvoiced”, na qual as cordas vocais não estão vibrando, resultando formas de onda não periódicas e naturalmente aleatórias.
- Voz (V) “Voiced”, na qual as cordas vocais estão tensas e ocorre uma vibração periódica quando o ar flui dos pulmões, resultando assim uma forma de onda quase periódica da fala.
Figura 3.6: Formas de onda da expressão “It’s Time”, no domínio do tempo. (Modificada de Lawrence Rabiner, pg 18. [17] )
A primeira linha mostra a variação natural e lenta do sinal nos primeiros 100 ms, e que corresponde a um fundo de silêncio (S) e uma baixa amplitude. Nos próximos 100 ms (segunda linha), a forma de onda mostra um pequeno incremento no nível (S), seguido de um fino incremento (U) e de um grosso incremento no nível da forma de onda (V) (quase periódico). Portanto antes de iniciarmos a fala, a forma de onda é classificada como
ou aspiração). Na seqüência vê-se o período de produção da fala Voiced (V), correspondente à vogal inicial da palavra “It’s”(linhas 2 e 3).
Seguindo a análise na região da fala, região Voiced (V), existe um breve período de
Unvoiced (U) (respiração), seguida por uma região de silêncio (S) (antes do /t/ na palavra It’s), temos em seguida um relativo longo período de Unvoiced (U), região correspondente a liberação do /t/, seguindo pelo /s/ de It’s (linhas 3 e 4).
Finalmente há um longo período de voz (V) Voiced, região correspondente ao ditongo /ai/ da palavra “time”. (linhas 4 e 5).
Deve ser claro que a segmentação da forma de onda da fala em regiões bem definidas de Silêncio (S), Unvoiced (U) e Voiced (V), não é exata. Normalmente é difícil distinguir um fraco som Unvoiced (U) do Silêncio (S), ou ainda, distinguir um fraco som de voz Voiced (V), do som Unvoiced (U). Entretanto, pequenos erros de limite de regiões S, U e V, não afetam significativamente as aplicações.
Um caminho alternativo para caracterizar o sinal da fala, é a representação da informação associada aos sons através da representação espectral. Talvez a representação mais popular deste tipo de espectrograma do som, seja a representação tridimensional da intensidade da fala, em diferentes bandas de freqüência.
Um exemplo deste tipo de representação é mostrado na figura 3.7, a qual mostra um espectro de banda larga no primeiro painel, um espectro de banda estreita no segundo painel, e a forma de onda da amplitude impressa no terceiro painel. A expressão vocal da figura 3.7, é a frase “Every Salt Breeze Comes From the Sea” , pronunciada por um homem.
O espectro de banda larga, corresponde à análise espectral de secções de 15ms da forma de onda, usando na análise um filtro de banda larga (125 Hz banda do filtro), com análises avançando a cada 1ms.
O espectro de banda estreita, (segundo painel da figura 3.7) corresponde à análise espectral de secções de 50ms da forma de onda, usando na análise um filtro de banda estreita (40 Hz banda do filtro), com análises avançando também a cada 1ms.
Nota-se claramente que nos períodos de silêncio, não se vê atividade espectral, devido à redução no nível do sinal.
baseada em modelo de produção da fala. Este método de representação é mais teórico do que prático.
Figura 3.7: Espectrogramas e amplitude da fala “EVERY SALT BREEZE COMES FROM THE SEA”
(Modificada de Lawrence Rabiner, pg 19. [17])
$6&$5$&7(5Ì67,&$6'266216'$)$/$
Tabela 3.1: Lista de símbolos fonéticos da língua Inglesa Americana
)212/2*,$()21(0$
A palavra fonologia é formada pelos elementos gregos: fono- ("som, voz") e -logia ("estudo, conhecimento"). Significa literalmente o "estudo dos sons". Já sabemos porém, que os sons que essa parte da gramática estuda, são os fonemas (novamente o radical grego fono-, e agora ao lado do elemento -ema, "unidade distinta").
Para compreender claramente o que é um fonema, compare as palavras abaixo :
B
ala
G
ala
Cada letra representa, no caso, um fonema, ou seja, uma unidade sonora capaz de estabelecer diferenças de significado. Observe que as demais letras de cada uma das palavras também representam fonemas. Para perceber isso, basta trocá-las sucessivamente por outras que representam sons diferentes - as sucessivas trocas produzem palavras de significados diferentes :
gala - gata - galo - gula - gola - bala - bela
Em todos esses casos, cada letra representa um fonema. Se fizermos, no entanto, as seguintes trocas, surgirão alguns problemas :
gala - gela
bala – barra
Quando trocamos a letra “a” de gala pela letra “e”, estamos produzindo duas modificações de fonemas: observe que, além da mudança óbvia do fonema representado pelo “a” para o fonema representado pelo “e”, há uma mudança no som representado pela letra “g”: em gala, essa letra representa um som comparável ao de gato; em gela, representa um som comparável ao de girafa ou janela. No caso da troca bala por barra, o que ocorre é um fenômeno diferente: observe que em barra há duas letras que representam um único som (“rr”).
Nunca devemos confundir fonemas e letras: os fonemas são sons - portanto, faláveis e audíveis. As letras são sinais gráficos - portanto, visíveis - que procuram representar os fonemas. Essa representação, no entanto, não é perfeita: como vimos, ocorrem muitos problemas de falta de correspondência exata entre os fonemas e as letras que tentam representá-los.
Há letras que representam fonemas diferentes (como o g, em gala e gela), como há fonemas representados por letras diferentes (como o que as letras g e j representam em girafa e janela); há casos em que uma única letra é representada por dois fonemas (como o x de axioma - lê-se "aksioma"); há até mesmo, casos em que a letra não corresponde a nenhum fonema (o h de hora, por exemplo).
Resumindo:
- Fonologia: parte da Gramática que estuda os fonemas.
determinada língua. Note que, com um número relativamente pequeno desses sons, cada língua é capaz de produzir milhares de palavras e infinitas frases. - Letras : são sinais gráficos criados para a representação escrita das línguas.
Não devem ser confundidas com os fonemas, que são sons.
)RQHPDVGD/tQJXD3RUWXJXHVD
Como sabemos, não devemos confundir fonemas e letras, pois não há necessariamente correspondência entre o que se fala e o que se escreve.
Para superar esse problema, criou-se um sistema de símbolos em que cada fonema tem apenas uma representação. Esse sistema é o alfabeto fonético, usado pelos especialistas em seus estudos e também para o ensino de línguas em geral. Em muitos dicionários de línguas estrangeiras são encontrados esses símbolos, que indicam a forma de pronunciar as palavras. A Tabela 3.1, mostra os fonemas da língua Inglesa Americana.
A língua portuguesa do Brasil apresenta um conjunto de 33 fonemas. A cada um deles corresponde um único símbolo escrito em alfabeto fonético.
Convencionalmente, esses símbolos são colocados entre barras oblíquas. Os fonemas estão divididos em vogais, semivogais e consoantes.
Na Tabela 3.2: são mostradas as semivogais da língua Portuguesa do Brasil. Na Tabela 3.3: são mostrados os fonemas das Consoantes.
Na Tabela 3.4: são apresentadas as vogais.
Semivogais
/ j / cai, põe /kaj/, /põj/
/ w / pau, pão /paw/, /pãw/
Tabela 3.2 Lista de símbolos fonéticos das semivogais da Língua Portuguesa do Brasil
O uso de símbolos para a transcrição fonológica evidencia alguns problemas da relação entre fonemas e letras: por exemplo, o símbolo /k/ transcreve com um mesmo fonema o som representado pela letra “c” em cara e pelas letras “qu” em quero.
Consoantes
Símbolo Exemplo Transcrição Fonológica
/ p / paca /paka/ / b / bula /bula/ / t / Tara /tara/ / d / data /data/ / k / Cara, quero /kara/, /k ro/ / g / Gola, guerra /g la/, /g Ra/ / f / Faca /faka/ / v / Vala /vala/
/ s / Sola, assa, moça /s la/, /asa/, /mosa/ / z / asa, zero /aza/, /z ro/ / / mecha, xá /m a/, / a/ / / Jaca, gela / aka/, / la/ / m / Mola /m la/ / n / Nata /nata/ / / Ninho /n o/ / l / Lata /lata/ / / calha /ka a/ / r / Mara /mara/
/ R / Rota, carroça /R ta/, /kaR sa/
Tabela 3.3: Lista de símbolos fonéticos das consoantes da Língua Portuguesa do Brasil
Vogais
/ a / cá /ka/
/ e / mel /m l/
/ e / seda /seda/
/ i / rica /Rica/
/ / sola /s la/
/ o / soma /soma/
/ u / gula /gula/
/ / Tenda /t da/
/ / Cinta /s ta/
/ õ / conta, põe /kõta/, /põj/
/ / Fundo /f do/
Tabela 3.4: Lista de símbolos fonéticos das vogais da Língua Portuguesa do Brasil
&ODVVLILFDomRGRV)RQHPDVGD/tQJXD3RUWXJXHVDGR%UDVLO
Os fonemas da língua portuguesa são classificados em vogais, semivogais e consoantes. Esses três tipos de fonemas são produzidos por uma corrente de ar que pode fazer vibrar ou não as cordas vocais. Quando ocorre vibração das cordas vocais, o fonema é chamado sonoro; quando elas não vibram, o fonema é surdo. Além disso, a corrente de ar pode ser liberada apenas pela boca ou parcialmente também pelo nariz. No primeiro caso, o fonema é oral; no segundo, o fonema é nasal.
$V9RJDLV
As vogais são fonemas sonoros produzidos por uma corrente de ar que passa livremente pela boca. Em nossa língua, desempenham o papel de núcleo das sílabas. Em termos práticos, isso significa que em toda sílaba há necessariamente uma única vogal.
As diferentes vogais resultam do diferente posicionamento dos músculos bucais (língua, lábios e véu palatino). Sua classificação é feita em função de diversos critérios:
A- Quanto à zona de articulação, ou seja, de acordo com a região da boca em que se dá a maior elevação da língua; assim, podem ser anteriores, centrais e posteriores;
B- pela elevação da região mais alta da língua; por este critério, podem ser altas, médias e baixas;
C- quanto ao timbre; podem ser abertas ou fechadas.
determinada vogal, devem ser considerados os diversos critérios: um /a/, por exemplo, deve ser descrito como uma vogal oral, central, baixa.
Classificação Anteriores Centrais Posteriores
Altas /i/ / / - /u/ / /
Médias Fechadas /e/ / / - /o/ /õ/
Médias Abertas / / - / /
Baixas - /a/ /ã/ -
Tabela 3.5: Classificação das vogais da Língua Portuguesa do Brasil
Observação: A distribuição das vogais nesse quadro forma um triângulo. Esse triângulo simula o movimento da língua dentro, da cavidade bucal para a pronuncia das diferentes vogais. Ao se pronunciar todas as vogais orais, começando pelo /i/ e seguindo a ordem do quadro até o /u/, percebe-se que a língua percorrerá o caminho indicado pelo triângulo. Começando pelo /u/ em direção ao /i/, a língua percorrerá exatamente o caminho inverso.
$V6HPLYRJDLV
Há duas semivogais na língua portuguesa, representadas pelos símbolos /j/ e /w/ e produzidas de forma semelhante às vogais altas /i/ e /u/. A diferença fundamental entre as vogais e as semivogais está no fato de que estas últimas não desempenham o papel de núcleo silábico. Em outras palavras: as semivogais necessariamente acompanham alguma vogal, com a qual formam uma sílaba.
Infelizmente, as letras utilizadas para representar as semivogais em português são utilizadas também para representar vogais, o que cria alguns problemas. A única forma de diferenciá-las efetivamente é falar e ouvir as palavras em que surgem. Observe os casos abaixo:
País - pais
baú - mau
facilmente percebido ao se observar como a articulação desses sons é diferente em cada caso; além disso, observa-se que “País” e “baú” têm ambas duas sílabas, enquanto “pais” e “mau” têm ambas uma única sílaba.
$V&RQVRDQWHV
Para a produção das consoantes, a corrente de ar expirada pelos pulmões encontra obstáculos ao passar pela cavidade bucal. Isso faz com que as consoantes sejam verdadeiros "ruídos", incapazes de atuar como núcleos silábicos. Seu nome provém justamente desse fato, pois, em português, sempre somam com as vogais, que são os núcleos das sílabas.
A classificação das consoantes baseia-se em diversos critérios:
A- Modo de articulação: indica o tipo de obstáculo encontrado pela corrente de ar ao passar pela boca. São oclusivas aquelas produzidas com obstáculo total; são constritivas as produzidas com obstáculo parcial. As constritivas se subdividem em fricativas (o ar sofre fricção), laterais (o ar passa pelos lados da cavidade bucal) e vibrantes (a língua ou o véu palatino vibra);
B- Ponto de articulação: indica o ponto da cavidade bucal em que se localiza o obstáculo à corrente de ar. As consoantes podem ser bilabiais (os lábios entram em contato), labiodentais (o lábio inferior toca os dentes incisivos superiores), linguodentais (a língua toca os dentes incisivos superiores), alveolares (a língua toca os alvéolos dos incisivos superiores), palatais (a língua toca o palato duro ou céu da boca) e velares (a língua toca o palato mole, ou véu palatino);
C- As consoantes podem ser surdas ou sonoras, de acordo com a vibração das cordas vocais, e ainda orais ou nasais, de acordo com a participação das cavidades bucal e nasal no seu processo de emissão.
02'(/2'2289,'2+80$12
Grande parte das informações que o ser humano recebe são transmitidas por ondas sonoras. Elas, normalmente, provêm do ambiente que nos cerca e são originadas de diversas fontes sonoras. O sistema auditivo dos seres humanos permite a captação dessas ondas e o reconhecimento do conteúdo de informação que possuem.
Existem modelos de análise espectral que são baseados no entendimento do sistema de processamento do sinal de voz pelo ouvido humano. A figura 3.8 mostra o ouvido humano com suas três principais regiões: Ouvido Externo, Ouvido Médio e Ouvido interno.
Figura 3.8: Modelo do ouvido humano (Modificada de Lawrence Rabiner, pg 132. [17])
A parte do ouvido externo compreende a Orelha e o canal externo onde o som é afunilado. A onda de som alcança o ouvido e é guiada através do ouvido externo para o ouvido médio.
O ouvido interno consiste na “cóclea”, que é um fluido que se encontra dentro da membrana basilar, e o nervo auditivo.
Distribuídos ao longo da membrana basilar encontram-se um conjunto de sensores chamados de “inner hair cells” (IHC), o quais convertem o sinal mecânico em atividade
neural.
Compreender o funcionamento do sistema humano de produção e percepção dos sons é um passo importante no desenvolvimento de sistemas de aquisição e análise dos sons da fala.
$1É/,6(),1$/
26,67(0$'($48,6,d®2'(
'$'2612&20387$'25
Os itens a serem estudados neste capítulo são de fundamental importância para um sistema de reconhecimento de voz, pois correspondem ao primeiro passo de um sistema de reconhecimento de voz prático. Para se realizar um bom reconhecimento de voz com qualidade deve-se ter um sinal amostrado, sem ruídos e sem entrelaçamentos, ou seja, um sinal com o máximo de exatidão e precisão.
O sinal de voz emitido pelo locutor (pessoa que fala ao microfone) é adquirido pelo computador através da placa de som.
Antes de desenvolver qualquer sistema de aquisição de dados, deve-se entender as quantidades físicas que se quer medir, as características dessas quantidades físicas, o sensor apropriado para medição, e o hardware de aquisição de dados apropriado e o software necessário para analisar os dados coletados.
$)Ì6,&$'266216
A Acústica é a parte da Física que estuda o som. O som é a sensação percebida pelo cérebro que se relaciona com a chegada no ouvido de ondas de vibração mecânica. Todo sistema que emite som é uma fonte sonora. Em geral, costuma-se confundir o conceito de som com o conceito de onda sonora. Por isso, pode-se dizer que o som se propaga nos ambientes materiais e elásticos através de ondas. As ondas sonoras são vibrações sincronizadas das moléculas que constituem o meio. Ao vibrarem em conjunto, elas criam em torno da fonte sonora regiões de alta e baixa pressão. Essas variações de pressão se propagam no meio como uma onda mecânica longitudinal.
O modelo do ouvido humano mostrado no capitulo 3, pode detectar freqüências sonoras na faixa de 16 a 17.000 Hz. Todavia estes limites não são fixos, mas variam com a idade e também de um indivíduo para o outro. O limiar de potência sonora capaz de induzir uma sensação dolorosa é, no entanto, mais constante e se situa entre 140 e 160 dB [18].
palavras são pronunciadas influem diretamente na inteligibilidade da frase. Portanto, para que se possa entender corretamente um locutor, o mesmo deve ter uma entonação sem muitas variações na velocidade da pronúncia.
$V&DUDFWHUtVWLFDV)LVLROyJLFDVGR6RP
As qualidades fisiológicas dos sons são: - Altura
- Intensidade - Timbre
Altura: é a qualidade que permite que os sons possam ser classificados em graves (baixa freqüência) e agudos (alta freqüência). Os sons com frequência menor do que 16Hz são chamados de infra-sons, enquanto os de freqüência maior do que 17.000Hz são denominados ultra-sons. Alguns animais são capazes de emitir e de detectar ultra-sons. Entre eles estão muitos insetos, mas o exemplo mais relevante é o do morcego. Esse animal, ao voar, emite, a cada segundo, 10 ou mais pulsos sonoros cuja freqüência está entre 20.000 a 100.000Hz.
Intensidade: Intensidade é a qualidade que permite um som ser percebido a uma maior ou menor distância da fonte sonora. Quanto à intensidade, os sons podem ser fortes ou fracos. Como o ouvido humano não tem a mesma sensibilidade para todas as frequências sonoras, mas é mais sensível aos sons cujas freqüências se situam entre 2.000 e 4.000Hz, a intensidade dos sons ouvidos também varia com a freqüência. Além disso, a intensidade dos sons:
- É proporcional ao quadrado da amplitude da onda sonora;
- É mais intensa quanto maior for a superfície de vibração da fonte sonora; - Aumenta com a densidade do meio em que ele se propaga;
- Decai com o quadrado da distância entre o observador e fonte sonora, quando o som se propaga em meio homogêneo e infinito;
- Depende da proximidade de ressoadores, pois eles reforçam a intensidade do som; - É alterada pelos ventos. Estes interferem na intensidade do som quando a
A tabela 4.1 mostra as intensidades médias de sons do ambiente, desde o limiar da audição, cuja intensidade é em torno de 0 dB, até o limite de lesão do tímpano, em torno de 160 dB.
Tipos de som Intensidade (dB)
Limiar da audição 0
Farfalhar das folhas 10
Ambiente de biblioteca 20
Som ambiental médio 40
Conversação normal 60
Rua com grande tráfego 70
Rádio em volume alto 80
Trem em Movimento 100
Limiar de desconforto 120
Limiar da dor 140
Lesão do tímpano 160
Tabela 4.1: As Intensidades médias dos sons do ambiente
Timbre: é a qualidade que diferencia dois sons de mesma altura e de mesma intensidade, mas que são produzidos por fontes sonoras diferentes. O timbre de um som depende do conjunto dos sons secundários (sons harmônicos) que acompanham o som principal.
26,67(0$'($48,6,d®2'('$'26
O propósito de qualquer sistema de aquisição de dados é proporcionar as ferramentas e recursos necessários para fazer a aquisição de dados confiáveis.
Deve-se pensar em um sistema de aquisição de dados como uma coleção de “software” e “hardware” que conecta um sistema gerenciador (computador) com o mundo físico.
Um sistema de aquisição de dados típico consiste de:
c) Hardware de condicionamento de sinal d) O computador
e) Software
a) Hardware de aquisição de dados: O coração de qualquer sistema de aquisição de dados é o “hardware”. Sua função principal é converter sinais analógicos em sinais digitais, e converter sinais digitais em sinais analógicos.
b) Sensores e atuadores (transdutores):. Um transdutor é um dispositivo que converte energia de entrada em uma outra forma de energia de saída. Por exemplo, um microfone é um sensor que converte energia do som (na forma de pressão) em energia elétrica, enquanto um alto-falante é um atuador que converte energia elétrica em energia de som.
c) Condicionamento de sinal: Sinais de um sensor são freqüentemente incompatíveis com hardware de aquisição de dados. Para superar esta incompatibilidade, deve-se condicionar o sinal. Por exemplo, pode ser preciso condicionar um sinal de entrada, amplificá-lo ou remover as componentes de freqüência não desejadas.
d) O computador: O computador deve prover um processador, um relógio de sistema, um sistema (bus) para transferir dados, memória e espaço de disco para armazenar dados.
e) O Software: O Software de aquisição de dados permite trocar informações entre
o computador e o “hardware”. Por exemplo: um software típico permite configurar a taxa de amostragem da placa de aquisição (hardware), e adquirir uma quantidade de dados predefinida.
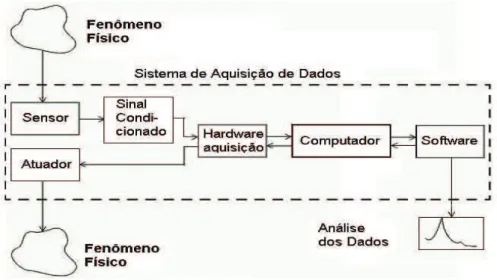
Os componentes da aquisição de dados, e a relação entre eles, são mostrados na figura 4.1. A figura 4.1 mostra ainda as duas características importantes de um sistema de aquisição de dados:
- O Sinal;
- Os Dados.
- O Sinal: é adquirido pelo sistema, condicionado e convertido em dados que um computador pode ler, e finalmente analisado para se extrair informações significantes. Por exemplo, um sinal com níveis de som é adquirido de um microfone, amplificado, digitalizado por uma placa de som, e armazenado para uma subseqüente análise do conteúdo de freqüência. O software MATLAB é capaz de realizar todas estas
tarefas.
- Os Dados: Uma vez processado, o sinal de som se transforma em dados no computador que são convertidos em um sinal analógico e enviados para um atuador (parte final).
Por exemplo, um vetor de dados no programa MATLAB é convertido em sinal
analógico por uma placa de som e enviado para um alto-falante.
2+$5':$5('($48,6,d®2'('$'26
O hardware de aquisição de dados pode ser interno e instalado dentro do computador, ou externo e conectado ao computador por um cabo.
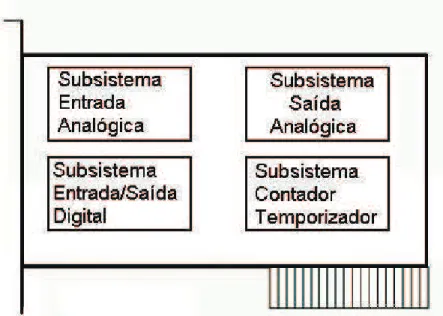
Ao nível mais simples, o “hardware” de aquisição de dados é caracterizado pelos subsistemas que possui. Um subsistema é um componente de “hardware” de aquisição de dados que executa uma tarefa especializada. O dispositivo de hardware que consiste em um subsistema múltiplo é chamado de Placa de “hardware” de multifunção. Este dispositivo é mostrado na figura 4.2.
Basicamente uma placa de “hardware” de aquisição de dados é composta por quatro subsistemas:
- Entrada Analógica
- Saída Analógica
- Entrada e Saída Digital
- Subsistema de Entrada analógica: converte sinais de entrada analógicos de um sensor em bits que podem ser lidos pelo computador. São chamados de subsistemas de AI (Analog Input), conversor de A/D, ou ADCs .
Figura 4.2: Placa de “hardware” de um sistema de Aquisição de Dados
- Subsistema de Saída analógica: convertem dados digitais armazenados no computador para um sinal analógico. Este subsistema executa a conversão inversa do subsistema de entrada analógica. São chamados de subsistemas de AO (Analog Output), conversor de D/A, ou DACs.
- Subsistemas de Entrada/Saída Digitais : Também chamados de DIO (digital input/output), são projetados para fazer a entrada ou a saída de sinais digitais (níveis lógicos) para o “hardware”.
- Subsistema de Contagem e Temporização: O subsistema de contagem e temporização “counter/timer” (C/T) é usado para contar tempo, freqüência, e medir o período de um trem de pulsos.
266(1625(6
- Sensores digitais: produzem um sinal de que é uma representação digital do sinal de entrada analógico, e tem valores discretos de magnitude e medidas de tempos discretos. - Sensores analógicos: produzem um sinal que é diretamente proporcional ao sinal medido, e é contínuo em magnitude e no tempo. A maioria das variáveis físicas como temperatura, pressão, e aceleração são contínuas por natureza e são prontamente medidas com um sensor analógico.
Para escolher o melhor sensor analógico, deve-se verificar as características da variável física que se deseja medir com as características do sensor.
A saída de um sensor pode ser um sinal analógico ou um sinal digital, e a variável de saída normalmente é uma tensão, embora existam alguns sensores com saídas de corrente.
A corrente é usada freqüentemente para transmitir sinais em ambientes ruidosos porque o sinal de corrente é muito menos afetado por ruídos do meio ambiente.
No entanto, o sinal mais comumente conectado é um sinal de tensão. Por exemplo, termopares, acelerômetros, microfones, todos produzem sinais de tensão. Há três aspectos principais de um sinal de tensão que precisam ser considerados:
- A Amplitude - A Freqüência
- A Duração da Aquisição.
- Amplitude: Se o sinal for menor que alguns milivolts, deve-se amplificar este sinal. Se o valor máximo do sinal é maior que o suportado pelo “hardware” analógico (tipicamente ±10 V), deve-se dividir o sinal usando uma rede de resistores.
- Freqüência: Sempre que se adquire dados, deve-se decidir a freqüência mais alta a ser medida. O componente de freqüência mais alta do sinal determina com que freqüência deve-se amostrar o sinal de entrada. Em freqüências mais altas podem estar presentes ruídos que são removidos filtrando o sinal antes de ser digitalizado.
2&21',&,21$0(172'(6,1$/
Como citado anteriormente, os sinais de um sensor são freqüentemente incompatíveis com hardware de aquisição de dados, e para superar esta incompatibilidade, deve-se condicionar o sinal do sensor. O tipo de condicionamento de sinal requerido depende do sensor que se está usando. Por exemplo, um sinal pode ter uma amplitude pequena e requer amplificação, ou pode conter componentes de freqüência não desejados e pode requerer filtragem. Os modos comuns para condicionar sinais incluem:
- Amplificação - Filtragem
- Isolamento elétrico - Multiplexagem - Fonte de excitação
- Amplificação: Sinais de baixa amplitude (menos que ou ao redor de 100 milivolts) normalmente precisam ser amplificados.
Por exemplo, o sinal de saída de um termopar é pequeno e deve ser amplificado antes de ser digitalizado.
- Filtragem: Remove os sinais indesejáveis que estão fora da banda de freqüência de interesse.
- Isolamento elétrico: Se o sinal de interesse contiver transientes de alta-voltagem que podem danificar o computador, então os sinais do sensor devem ser eletricamente isolados do computador para propósitos de segurança.
- Multiplexagem: Esta técnica consiste em medir vários sinais com apenas um dispositivo de medida.
- Fonte de excitação: Alguns sensores exigem uma fonte de excitação para operar.
2&20387$'25
Saber que foi registrado o que um sensor está lendo não é bastante, geralmente precisa-se saber também quando esta medida aconteceu. Os dados são transferidos do hardware à memória do sistema por acesso de memória dinâmico (DMA), por interrupções (IRQ), ou diretamente pelo software. O DMA é um controlador de hardware extremamente rápido. As interrupções podem ser lentas devido ao tempo de espera entre os pedidos de interrupção e a resposta do computador. A máxima taxa de aquisição também é determinada pela arquitetura do barramento de dados (bus) do computador.
262)7:$5(
Independente do hardware que se use, deve-se enviar e receber informações deste hardware. Também é preciso fornecer ao “hardware” informações de como se integrar com outro hardware e dos recursos de computador. Esta troca de informação é realizada com o software.
Existem dois tipos de software:
- Software chamado de “driver” (gerencia o hardware) - Software de aplicação
Software de “driver”:. Permite o acesso e controle das capacidades do hardware. Entre outras coisas, o software de driver básico permite:
- Receber e enviar dados à placa do “hardware”; - Controlar a taxa à qual os dados são adquiridos;
- Integrar o “hardware” de aquisição de dados com recursos de computador, como interrupções do processador, DMA e memória;
-Integrar o “hardware” de aquisição de dados com “hardware” de condicionamento;
- Acessar múltiplos subsistemas em uma determinada placa de aquisição de dados; - Acessar placas de aquisição de dados múltiplas.
Software de aplicação: Fornece uma interface conveniente ao software de driver. Um software de aplicação básico permite:

![Figura 3.8: Modelo do ouvido humano (Modificada de Lawrence Rabiner, pg 132. [17])](https://thumb-eu.123doks.com/thumbv2/123dok_br/16990291.763631/39.892.155.768.468.906/figura-modelo-do-ouvido-humano-modificada-lawrence-rabiner.webp)