Alocação de Dados em Bancos de Dados Distribuídos
Matheus Wildemberg, Melise M. V. Paula, Fernanda Baião, Marta Mattoso {mwild, mel, baiao, marta}@cos.ufrj.br
Programa de Engenharia de Sistemas e Computação - COPPE Universidade Federal do Rio de Janeiro, Brasil
Abstract
The problem of data allocation directly impacts on the execution cost of the application over a distributed database in environments that work with data distribution and replication, such as web servers, heterogeneous database integration systems and distributed databases. Allocation algorithms are typically used to find a data distribution among the sites of the network such as to minimize the execution cost of the application. In this work, a heuristic algorithm is proposed for fragment allocation in distributed database systems. The proposed algorithm is based on a heuristic algorithm presented in the literature, and its goal is to find out an allocation schema with a minimal execution cost, maintaining the complexity of the original algorithm. Through simulations performed on top of the TPC-C benchmark, it was possible to identify scenarios where the proposed algorithm found the optimal solution and other scenarios where the proposed algorithm found an allocation schema with a reduced cost when compared to the original algorithm.
1. Introdução
O problema da alocação de dados envolve encontrar a distribuição “ótima” dos dados através de nós da rede de forma a minimizar o custo das aplicações sobre esses dados. A alocação é um aspecto crítico num Sistema de Banco de Dados Distribuídos (SBDD), já que uma alocação ineficiente dos dados pode levar a um aumento considerável do custo de acesso ao SBDD. Em geral, em um projeto de distribuição da base de dados, a fase de alocação é realizada após a fase de fragmentação, a qual determina a distribuição dos dados em fragmentos. Um dos principais objetivos que devem ser alcançados na fase de alocação é aumento da proximidade entre os fragmentos e os nós que os utilizam, minimizando o custo de comunicação.
O principal aspecto que determina a qualidade da solução encontrada para o problema de alocação de dados é a eficiência do projeto de alocação, ou seja, a alocação dos dados nos nós deve minimizar, tanto quanto possível, o custo das consultas executadas.
O processo de tomada de decisão presente no Problema de Alocação de Dados (PAD) em um SBDD, de uma forma geral, pode ser definido como: escolher dentre todos os possíveis modelos de alocação de fragmentos nos nós de uma rede, ou seja, entre todas as possíveis distribuições dos fragmentos, aquela que minimize o custo de acesso aos dados alocados considerando um conjunto de restrições do problema, como por exemplo, a capacidade dos nós onde os dados são alocados. Este problema inclui a decisão de replicação dos fragmentos. Este tipo de problema é classificado na literatura como Problema de Otimização Combinatória.
nós, (2m - 1)n é o número de combinações possíveis para este problema. Esta é mais uma justificativa para o uso de métodos heurísticos na solução do PAD, pois é inviável solucionar esse tipo de problema com um algoritmo exato em função da sua complexidade.
Existem na literatura propostas que buscam solucionar o problema de alocação de fragmentos em SBDD. Alguns destes trabalhos, como [6, 9], não consideram replicação de fragmentos em sua alocação para diminuir a complexidade do problema. Em [5, 6], o algoritmo proposto independe do modelo de dados, ou seja, pode ser executado tanto para fragmentos de tabelas relacionais quanto para fragmentos de classes de objetos enquanto que em [9, 10] são voltados ao modelo relacional e [12] propõe um modelo de alocação de fragmentos de classes em sistemas de base de objetos distribuídos. Em [3] é proposto um algoritmo de alocação dinâmica onde os fragmentos podem ser re-alocados aumentando o desempenho das aplicações sobre a base de dados distribuída que já esteja em produção, enquanto [1] utiliza algoritmos evolucionários para tratar o problema.
O algoritmo proposto neste trabalho, denominado Aloc, visa buscar uma alocação próxima de ótima, e utiliza os mesmos fundamentos apresentados no algoritmo de [5]. No trabalho de [5] são feitas considerações quanto aos algoritmos existentes na literatura, onde ou a complexidade dos algoritmos é muito grande, tornando-os de difícil aplicabilidade, ou o problema é muito simplificado, como é o caso da desconsideração da replicação em [6,9]. A escolha do trabalho de [5] se justifica pela simplicidade dos algoritmos apresentados e principalmente pelos resultados satisfatórios obtidos pelos autores. Além disso, o algoritmo leva em conta a replicação de fragmentos e reflete o comportamento real das transações em um banco de dados distribuído. Outra característica é sua independência do modelo de dados, assim é possível estendê-lo para problemas de alocação de dados em outros ambientes que possuam seus dados distribuídos.
O objetivo deste trabalho é apresentar o Aloc, uma variação do algoritmo apresentando em [5], mantendo algumas características como a independência do modelo de dados adotado e a replicação. De forma simplificada, a heurística de [5] faz uma alocação gulosa privilegiando as operações de leitura, enquanto que em Aloc, essa alocação inicial é estendida contemplando também as operações de atualização. Assim, é mantida a simplicidade do algoritmo, embora o espaço de soluções seja aumentado por considerar na alocação inicial nós com transações apenas de atualização. Este aumento do espaço de soluções acarretou em um aumento do tempo de execução do algoritmo (9.26% na média, 16% no máximo) em relação ao de [5], sem, no entanto alterar a ordem de complexidade, desta forma mantendo a viabilidade de sua utilização em problemas reais. O algoritmo Aloc, em casos que possuem um número maior de transações apenas de atualização, conseguiu alcançar resultados melhores que o algoritmo de [5]. Nos demais casos, ele conseguiu alcançar os mesmos resultados de [5].
O restante deste trabalho está organizado da seguinte forma. Na seção 2 é definido o problema de alocação de fragmentos em SBDD. A seguir, a seção 3 descreve Aloc, o algoritmo heurístico proposto para a alocação. Na seção 4 são mostrados alguns experimentos feitos com o algoritmo apresentado e finalmente na seção 5 são mostradas as conclusões deste trabalho.
2. Aspectos gerais do Problema de Alocação de Fragmentos em SBDD
Assim, seja S = {s1, s2,..., sm} o conjunto de nós, onde m é o número de nós da rede, T = {t1, t2,..., tq} o conjunto de transações que são executadas em S, onde q é o número de transações, e F = {f1, f2,..., fn} o conjunto de fragmentos resultantes da fase de fragmentação do projeto de distribuição, onde n é o número de fragmentos, o custo total para a execução de cada tk disparada de cada sj sobre os diversos fragmentos envolvidos em tk deve ser o menor possível.
A modelagem do problema é baseada em um conjunto de parâmetros que podem ser classificados em:
1. Parâmetros do banco de dados: os tamanhos dos fragmentos, representados por um vetor TAM, onde tam(i) é o tamanho do fragmento fi.
2. Parâmetros das transações: incluem quatro matrizes: (i) a matriz RM representa os pedidos de leitura, onde rmki representa o número de vezes que a transação tk faz acesso de leitura ao fragmento fi, a cada vez que é executada. Este valor é inteiro e positivo podendo ser 0 caso a transação tk não acesse o fragmento fi para leitura; (ii) a matriz UM representa os pedidos de atualização, onde umki representa o número de vezes que a transação tk atualiza o fragmento fi, a cada vez que é executada. Como no caso anterior, umki é um valor inteiro e positivo podendo ser igual a 0; (iii) a matriz SEL representa a seletividade das transações, onde selki representa o percentual do volume de dados de fi que é acessado durante a execução da transação tk; (iv) a matriz FREQ representa a freqüência de execução de cada transação em cada nó, onde freqkj é o número de vezes que o nó sj dispara a transação tk.
3. Parâmetros da rede: incluem o custo de transferir uma unidade de dado entre os nós da rede e o custo de construção do circuito virtual entre dois nós. O primeiro parâmetro é representado por uma matriz CTR, onde ctrjl é o custo de transferir um dado do nó sj para o nó sl. Para simplificar o problema, CTR é uma matriz simétrica onde ctrii é igual a 0 para 1<i<m. O segundo parâmetro, VCini, diz respeito ao circuito virtual que é criado entre o nó que dispara a transação e o nó que possui um fragmento acessado por esta transação. Com o fim da transação este circuito é fechado. Além deste, Cini é um custo constante de iniciar a transmissão de um pacote de dados de tamanho p_size.
De posse de tais parâmetros, define-se uma função de custo a partir da qual pode-se estimar o custo da execução de um conjunto de transações sobre uma base de dados distribuída.
No modelo de custo apresentado em [5], os autores fazem uma simplificação do custo de execução das transações, desprezando o custo de processamento local e concentrando-se apenas no custo de comunicação, já que este último é o custo de maior impacto em um ambiente distribuído. Resultados de testes realizados pelos autores comprovaram a validade desta função de custo na comparação dos seus resultados com os obtidos em um ambiente real. Desta forma, a fórmula de minimização do custo de comunicação definida em [5] possui dois componentes, que são o custo de carga dos fragmentos (CCload), que representa o custo para enviar todos os fragmentos de um nó inicial para os nós definidos no esquema de alocação, e o custo de processamento das transações (CCproc), que representa o custo para execução das transações de T sobre o ambiente distribuído.
Min (CCproc =
∑
=m
j 1
∑
=
q
k 1
freqkj * (TRk + TUk + VCini)) (1)
onde TR é o custo de recuperação relacionado às transações de leitura (consulta) detalhados a seguir. Supondo uma transação tk que realiza um acesso de leitura ao fragmento fi e é disparada a partir do nó sj, TRk (definido na equação 2) representa o custo de executar a transação tk . O nó que será lido durante a execução da transação tk é o que apresenta o menor custo de comunicação (CCcom) para transferir os dados consultados para o nó sj, dentre todos os nós que alocam uma réplica do fragmento fi,
TRk =
∑
=
n
i1
rmki * min(CCcom(ctrjs where fat i,s = 1, selki * tami)) (2)
onde fatij é igual a 1 se o fragmento fi está alocado no nó sj, senão é igual a 0 e CCcom é uma função definida na equação 3.
CCcom(ctrjl, m_size) = Cini*
size p
size m
_
_ +
ctrjl * m_size (3)
onde m_size é o tamanho do fragmento e p_size é a capacidade de transmissão da rede.
Para o cálculo do custo relacionado às transações de atualização (TU), supondo uma transação tk que atualiza o fragmento fi e é disparada a partir do nó sj, TUk, definido na equação 4, indica a soma dos custos de comunicação para transferir os dados atualizados pela transação tk a partir de sj em todos os nós que alocam o fragmento fi de forma a garantir a consistência de todas as réplicas de fi no sistema distribuído.
TUk =
∑
=
n
i 1
umki * (
∑
=m
1 l
fati,l, * CCcom (ctrjl, selki * tami)) (4)
3. Proposta de um algoritmo para o problema de alocação de fragmentos em SBDD
O algoritmo proposto para encontrar uma solução próxima de ótima para o problema de alocação de fragmentos em SBDD foi baseado no algoritmo apresentado em [5], descrito a seguir. Em seguida é apresentado o algoritmo Aloc, contribuição principal do presente trabalho, quando são descritas as extensões feitas a partir do algoritmo original apresentado em [5].
3.1. Algoritmo proposto por Huang e Chen [5]
O algoritmo proposto por Huang e Chen [5] está dividido em três passos. No primeiro passo é feita uma alocação inicial de modo guloso considerando somente os acessos de leitura feitos pelos nós a cada fragmento. Para cada fragmento uma réplica é alocada em cada nó que dispare ao menos uma transação de leitura a este fragmento. Formalmente, dado o fragmento fi∈ F e a transação tk∈ T , então:
fatij= 1 para todo nó sj∈ S onde freqkj > 0 e rmki> 0.
Neste passo não é feita nenhuma análise de custo para a distribuição dos fragmentos, portanto não existe um limite de replicações para estes fragmentos. Ao final desse passo o esquema de alocação está de forma que o custo de execução das transações de leitura é mínimo e o custo de execução das transações de atualização pode não ser o ideal, devido ao grande número de réplicas de cada fragmento.
fragmentos alocadas no primeiro passo. O critério para a retirada da réplica de um fragmento de um determinado nó é analisar o custo adicional gerado pela retirada (causado pelo aumento dos custos de leitura) e o benefício alcançado (com a redução dos custos de atualização). Desta forma, para cada fragmento, é retirada a réplica com a maior diferença entre o benefício alcançado e o custo gerado com a retirada onde este valor seja maior que 0. Isto é repetido até que o número de réplicas do fragmento seja igual a um ou não exista mais réplicas cuja diferença entre o benefício e o custo da retirada seja maior que 0. Portanto, ao final desse passo, fica garantido que existe ao menos uma réplica de cada fragmento já alocados no passo anterior em um dos nós.
Supondo uma réplica do fragmento fr alocada ao nó st, temos que:
• Benefício da retirada da réplica: é definido como a eliminação do custo de execução de todas as transações de atualização de fr em st, e é calculado como na equação 5.
∑
=
m
j1
∑
=
q
k 1
freqkj * umkr * CCcom(ctrjt, selkr * tamr) (5)
• Custo da retirada da réplica: é definido como o custo adicional de execução de todas as transações de consulta de fr, e é calculado somando o custo adicional em relação a todos os nós da rede.
Para cada sj∈S, o custo adicional em relação a sj é calculado da seguinte forma: suponha que sprox1 seja o nó mais próximo de sj, e sprox2 o segundo nó mais próximo de sj. Se sprox1 = st, então o custo adicional em relação a sj é a diferença entre o custo de consultar fr em sprox2 a partir de sj (T2) e o custo de consultar fr em sprox1 a partir de sj (T1). A função é dada por:
∑
=m
j 1
(T2 – T1), (6)
onde
T1 =
∑
=
q
k 1
freqkj *rmkr * CCcom(ctrjprox1, selkr * tamr) (7)
T2 =
∑
=
q
k 1
freqkj *rmkr * CCcom(ctrjprox2, selkr * tamr) (8)
O cálculo de sprox1 e sprox2 é feito da seguinte forma:
Dado o nó sv, sprox1 é o nó que contém fr e que possui o menor custo de transferir fr para sv, assim sprox1 é definido pela equação 9.
Min (ctrjv), (9)
onde sj é todo nó que contém fr. sprox2 é o nó que possui o menor custo depois de sprox1.
O segundo passo do algoritmo é repetido para todo fi ∈F.
Neste passo, são consideradas as matrizes de atualização UM e a de freqüência FREQ. Para cada fragmento ainda não alocado, é encontrado o nó que possui o menor tempo de espera em relação à transação. O cálculo do tempo de espera é dado como: Para cada nó que atualiza o fragmento é calculado o custo de executar todas as transações de atualização sobre o fragmento, estando ele alocado neste nó. Esse custo é o produto da freqüência de execução da transação pelo custo de comunicação entre o nó que dispara a transação e o nó candidato à alocação do fragmento. Assim o nó onde fr será alocado é sv ∈ Su onde:
∑
∈S sj
∑
∈T tkumkr * freqkj * ctrlj, (10)
seja mínimo, onde Su é o conjunto o nós que atualizam fr.
Portanto neste passo os fragmentos são alocados em um e somente um nó.
Em [5] os autores mostram que os resultados obtidos por seu algoritmo são melhores que o algoritmo proposto em [7]. Segundo [5], o problema considerado em ambos os trabalhos possui a mesma configuração.
Segundo [5], a ordem de complexidade do algoritmo proposto no seu trabalho é O(nm2q), onde n é o número de fragmentos distintos, m é o número de nós e q é o número de transações.
A partir daqui o algoritmo proposto em [5] será denominado Huang.
3.2. Algoritmo Aloc
A proposta deste trabalho é o algoritmo Aloc que altera o primeiro passo do algoritmo anterior de maneira que a alocação inicial dos fragmentos considere também as transações de atualização.
Deste modo, o ponto que difere o algoritmo Aloc do algoritmo Huang é a distribuição inicial dos fragmentos. Durante o primeiro passo do algoritmo Aloc, uma réplica de cada fragmento é alocada em cada nó que dispare ao menos uma transação de leitura ou de atualização a este fragmento, ou seja, dado o fragmento fi∈ F e a transação tk∈ T, onde rmki > 0 ou umki > 0, então
fatij = 1 para todo nó sj ∈ S onde freqkj > 0 e (rmki > 0 ou umki > 0).
Como no algoritmo anterior, não é feita nenhuma análise de custo para a distribuição dos fragmentos, portanto não existe um limite de replicações para estes fragmentos. Ao final desse passo cada fragmento que é acessado por alguma transação de leitura ou atualização está alocado em ao menos um nó da rede , fato que não acontecia no algoritmo Huang.
O segundo passo é idêntico ao segundo passo do algoritmo Huang, porém no algoritmo Aloc é criada uma lista LCO (Lista de Candidatas Ordenada) para cada fragmento, contendo todas as réplicas do fragmento onde a diferença entre o benefício e o custo de sua retirada seja maior que zero, ordenada de forma decrescente. Desta forma, para um determinado fragmento, retira-se o primeiro elemento da sua LCO, e isto é repetido até que o número de réplicas deste fragmento seja igual a um ou não existam mais elementos na LCO. Esta análise é feita para todos os fragmentos. As funções para definir o benefício e o custo da retirada de uma determinada cópia de um fragmento seguem as definições apresentadas anteriormente (equações 5 e 6, respectivamente). O algoritmo Huang não define explicitamente a utilização de uma estrutura de lista no segundo passo de sua execução, da mesma forma que não deixa claro se a ordem das réplicas de um determinado fragmento é refeita a cada retirada de uma de suas réplicas.
o conjunto de fragmentos restantes Fr = {fr1, fr2, ..., frm} e o conjunto de nós S = {s1, s2,..., sm}, então a alocação ocorre da seguinte forma: fat r1,1 = 1, fat r2,2 = 1,..., fat rm,m = 1, fat rm+1,1 = 1, .... Esta consideração não é feita no algoritmo Huang e permite garantir a completude da alocação, ou seja, garantir que todo fragmento seja alocado em ao menos um nó.
Analisando-se as modificações propostas pelo algoritmo Aloc em relação ao algoritmo original, pode-se verificar que há um aumento do espaço de soluções do algoritmo Aloc.
3.3. Análise do comportamento dos algoritmos
A inclusão de novas réplicas no passo 1 do algoritmo não altera o benefício da retirada das réplicas dos fragmentos já que, de acordo com a função para o cálculo do benefício da retirada de uma réplica, definido na equação 5, a alocação dos fragmentos nos nós que os atualizam não é considerada neste cálculo.
Quanto ao custo da retirada de uma réplica, definido na equação 6, para cada nó é calculado o custo adicional de executar todas as transações de leitura. Esse custo adicional é definido como o acréscimo no custo das transações de leitura advindo da retirada de uma réplica. Segundo esta função, dado o fragmento fr e o nó st de onde se quer retirar fr, o custo para cada nó sj da rede é calculado como a diferença entre o custo de executar todas as transações de leitura no nó sprox1 (que é o nó que apresenta o menor custo para st) e o custo de executar todas as transações de leitura no nó sprox2 (que é o nó que apresenta o segundo menor custo para st). Esta diferença só é considerada se sprox1 for igual a st. Isto porque, considerando su um nó que não executa nenhuma transação de leitura no fragmento fi, mas executa transações de atualização neste fragmento, conforme a função do cálculo do custo adicional definida na equação 6, sprox1 somente será igual a su no cálculo do custo adicional de retirar fi de su, pois sprox1 deve ser igual a st. Portanto isto não interfere o custo adicional dos demais nós. E se sprox2 for igual a su significa que custo de comunicação de su com sj é o menor possível, portanto o custo adicional final será menor. Com isso conclui-se que a inclusão de novas réplicas somente podem reduzir o custo da retirada de alguma(s) da(s) réplica(s) dos fragmentos.
Conforme descrito, no segundo passo do algoritmo Aloc a eliminação das réplicas dos fragmentos é feita segundo uma lista LCO. Como mostrado acima, a diferença entre os resultados no algoritmo Huang e no algoritmo Aloc se dá pela ordem das réplicas em LCO para os fragmentos onde o número de réplicas, definidas no passo 1, seja diferente para os dois algoritmos. Assim podemos comparar o comportamento dos dois algoritmos com 6 casos diferentes variando a ordem da retirada das réplicas nos dois algoritmos:
Considere, para os casos 1 e 2 descritos a seguir, um esquema de alocação onde o fragmento fj possua, na primeira iteração da eliminação de suas réplicas no passo 2 no algoritmo Aloc, a seguinte LCO:
{si, sj,..., sk, su, sl,..., st, sn} sendo su um nó que executa somente transações de atualização em fj.
Caso 1: No algoritmo Huang, considere a ordem da diferença entre o benefício e o custo da retirada das réplicas de fj como {si, sj,..., sk, sl,..., st, sn} e não sofreu nenhuma alteração na sua ordem em nenhuma iteração do algoritmo;
Para os casos 3 e 4, considere um esquema de alocação onde o fragmento fj possua, na primeira iteração da eliminação de suas réplicas no passo 2 no algoritmo Aloc, a seguinte LCO:
{si,..., sk, sl, su},
sendo su é um nó que executa somente transações de atualização em fj.
Caso 3: No algoritmo Huang, considere a ordem da diferença entre o benefício e o custo da retirada das réplicas de fj como {si,..., sk, sl};
Caso 4: No algoritmo Huang, considere a ordem da diferença entre o benefício e o custo da retirada das réplicas de fj como {si,..., sl, sk};
Finalmente para os casos 5 e 6, considere um esquema de alocação onde o fragmento fj possua, na primeira iteração da eliminação de suas réplicas no passo 2 no algoritmo Aloc, a LCO da forma:
{si,..., su, sk, sl},
sendo su é um nó que executa somente transações de atualização em fj.
Caso 5: No algoritmo Huang, considere a ordem da diferença entre o benefício e o custo da retirada das réplicas de fj como {si,..., sk, sl};
Caso 6: No algoritmo Huang, considere a ordem da diferença entre o benefício e o custo da retirada das réplicas de fj como {si,..., sl, sk};
Para os casos 1, 2 e 5, o resultado dos algoritmos serão idênticos, pois após a retirada de fj de su o comportamento será o mesmo para os dois algoritmos.
Para o caso 3, o resultado do algoritmo Aloc será melhor ou igual ao resultado do algoritmo Huang, pois a alocação final de fj será em sl como no algoritmo Huang, ou em su que será melhor. No caso 4 a possibilidade da alocação final ser no nó su é muito maior, pois se esta alocação alterou a ordem da lista significa que o custo de comunicação de su com outros nós é baixa, conseqüentemente o custo da retirada do fragmento do nó é alto.
Não foi encontrado nenhum caso onde ocorresse a situação 6.
A alocação de fj em su somente acarretará alterações muito grandes em LCO se o custo de comunicação de su com os fragmentos for baixo e se isso ocorrer, a alocação final de fj será em su.
4. Resultados Experimentais
Esta seção apresenta os resultados experimentais que foram realizados executando o algoritmo Aloc, o algoritmo Huang e, em alguns casos, um algoritmo de busca exaustiva que encontra a solução ótima. Foram realizados dois grupos de experimentos.
No primeiro grupo, os algoritmos foram executados para um conjunto de problemas pequenos gerados aleatoriamente, utilizando a mesma metodologia utilizada em [5]. Para um número fixo de nós, transações e fragmentos, são geradas - aleatoriamente - variações nos dados de entrada envolvendo a freqüência de transações, custo de comunicação, fatores de seletividade, entre outros. O objetivo deste primeiro grupo de experimentos é mostrar a utilidade do algoritmo proposto, comprovando o baixo custo das soluções obtidas por ele através de comparações com os resultados obtidos com o algoritmo Huang e com a solução ótima. A importância destes testes se deve à impossibilidade de executar o algoritmo de solução ótima para problemas maiores, com um número de soluções possíveis muito grande. No segundo grupo de experimentos, foram feitas simulações com os algoritmos Aloc e Huang para um caso real baseado no Benchmark TPC-C [11].
O modelo de custo descrito na seção 2 possui três parâmetros constantes: (i) Cini: custo de iniciar a transferência de um pacote de dados; (ii) p_size tamanho do pacote de dados e (iii) VCini custo de construção do circuito virtual. Nos experimentos realizados foram considerados os mesmos valores adotados em [5]: Cini = 0,032 ms/byte, p_size = 6250 bytes e VCini 65,5676 ms.
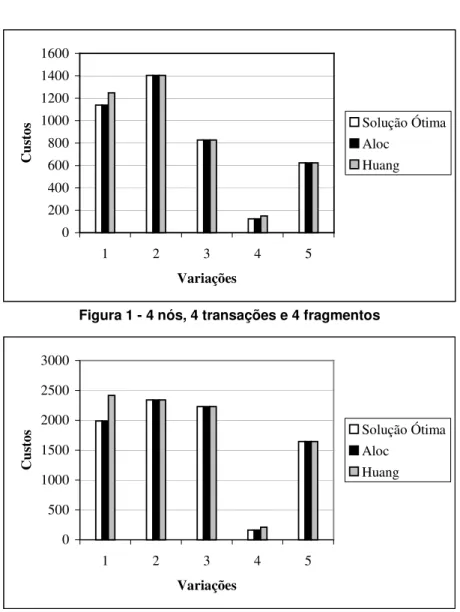
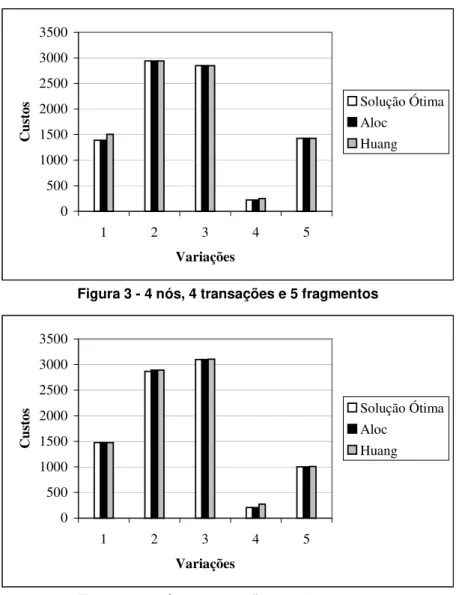
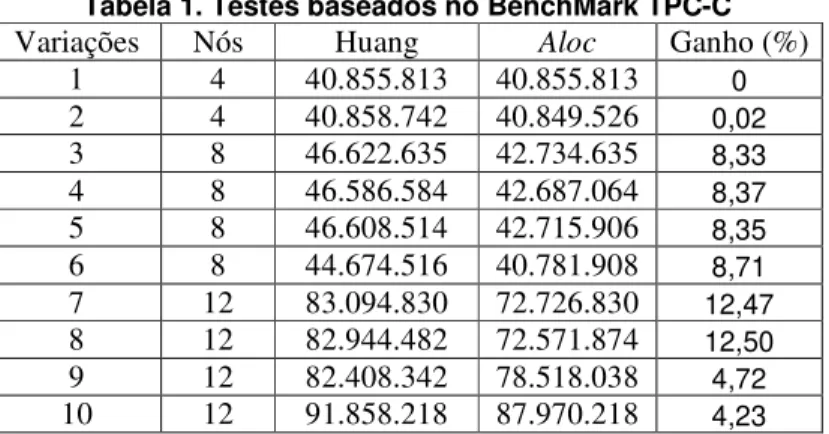
As figuras 1, 2, 3 e 4 mostram a relação entre os resultados obtidos com o algoritmo de busca exaustiva (solução ótima), os algoritmos Aloc e Huang para os casos aleatórios. Os gráficos relacionam as variações geradas com o custo de execução das transações no projeto de alocação.
0 200 400 600 800 1000 1200 1400 1600
1 2 3 4 5
Variações
Cu
st
os Solução Ótima
Aloc Huang
Figura 1 - 4 nós, 4 transações e 4 fragmentos
0 500 1000 1500 2000 2500 3000
1 2 3 4 5
Variações
Cu
st
os Solução Ótima
Aloc Huang
0 500 1000 1500 2000 2500 3000 3500
1 2 3 4 5
Variações
Cust
os Solução Ótima
Aloc Huang
Figura 3 - 4 nós, 4 transações e 5 fragmentos
0 500 1000 1500 2000 2500 3000 3500
1 2 3 4 5
Variações
Cu
st
os Solução Ótima
Aloc Huang
Figura 4 - 5 nós, 4 transações e 4 fragmentos
As figuras de 1 a 4 mostram que os resultados dos algoritmos Aloc e Huang se aproximam da solução ótima e em alguns casos o algoritmo Aloc apresenta uma redução no custo de execução das transações em relação ao resultado apresentado pelo algoritmo Huang. A diferença entre os resultados apresentados pelos algoritmos Aloc e o Huang se acentua nas variações 1 e 4 em todas as figuras acima. Isto se justifica pelo fato de que, nestes casos, na solução final apresentada, existem fragmentos que foram alocados em nós que somente acessam estes fragmentos por transações de atualização. Especificamente para a variação 1 da figura 2, onde esta diferença é ainda maior, verificou-se que ela reflete exatamente o custo de atualização de um fragmento que foi alocado pelo algoritmo Aloc a um nó que dispara somente transações de atualização a este fragmento.
Se um determinado nó que executa um maior número de transações somente de atualização possuir um custo de comunicação relativamente baixo com os demais nós da rede, o projeto de alocação do algoritmo Aloc será mais eficiente que o projeto apresentado pelo algoritmo Huang.
O segundo grupo de testes foi realizado segundo a especificação do TPC-C. Foram utilizadas todas as transações especificadas no Benchmark. A fase de fragmentação do projeto de distribuição foi realizada utilizando-se os algoritmos propostos em [2] para escolha das técnicas de fragmentação aplicadas às tabelas e [4] para definição dos fragmentos de cada tabela, resultando em um total de 17 fragmentos onde a tabela Order_Line sofreu fragmentação vertical gerando dois fragmentos, a tabela Item sofreu fragmentação híbrida gerando cinco fragmentos, a tabela Stock sofreu fragmentação horizontal derivada da tabela Item gerando quatro fragmentos e as tabelas Warehouse, District, History, New_Order, Customer e Order não sofreram fragmentação.
Depois de realizada a fragmentação, alguns casos foram gerados variando a quantidade de nós e o custo de comunicação que não constam na especificação do BenchMark e fazendo uma pequena variação da matriz de freqüência permitida pela especificação. Em função do tamanho do problema, e conseqüentemente do grande número de soluções viáveis, não foram realizados experimentos com o algoritmo de solução ótima (cujo tempo de processamento inviabilizaria a sua execução na prática).
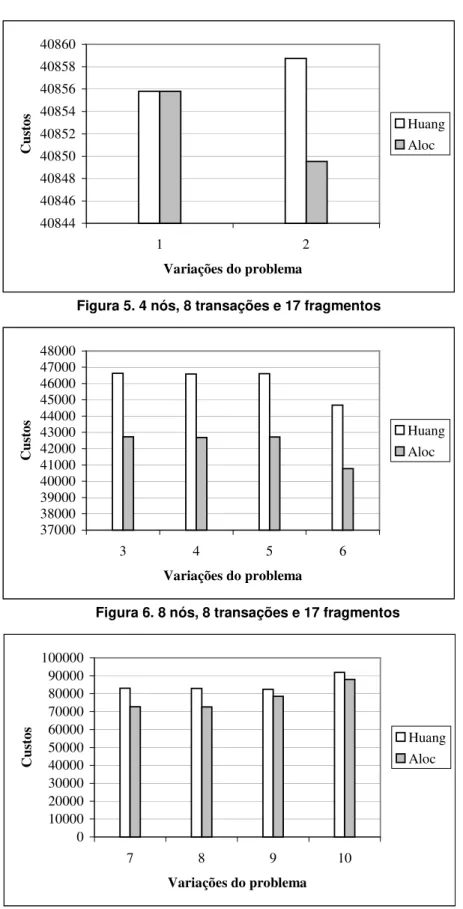
Tabela 1. Testes baseados no BenchMark TPC-C
Variações Nós Huang Aloc Ganho (%) 1 4 40.855.813 40.855.813 0 2 4 40.858.742 40.849.526 0,02 3 8 46.622.635 42.734.635 8,33 4 8 46.586.584 42.687.064 8,37 5 8 46.608.514 42.715.906 8,35 6 8 44.674.516 40.781.908 8,71 7 12 83.094.830 72.726.830 12,47 8 12 82.944.482 72.571.874 12,50 9 12 82.408.342 78.518.038 4,72 10 12 91.858.218 87.970.218 4,23
A tabela 1 mostra a relação entre os custos nos dois algoritmos. A coluna de variação expressa as mudanças realizadas nas matrizes dos dados de entrada, como freqüência de transações (matriz FREQ) nas variações de 1 a 10 e o custo de comunicação (matriz CTR) nas variações 9 e 10, dentro das faixas especificadas no TPC-C. As variações, mostradas na tabela 1, também refletem um número específico de nós. Estes valores são representados na segunda coluna da tabela.
Na última coluna da tabela 1 é mostrada a porcentagem de ganho do algoritmo Aloc em relação ao algoritmo Huang. Verifica-se que em todas as variações realizadas Aloc foi mais eficiente ou idêntico ao algoritmo Huang.
As variações, mostradas na tabela 1, podem ser agrupadas por quantidade de nós em: grupo 1 (4 nós, variações 1 e 2), grupo 2 (8 nós, variações 3 a 6) e grupo 3 (12 nós, variações 7 a 10) onde a diferença entre os elementos de cada grupo é a matriz FREQ, exceto para as variações 9 e 10 onde foram alterados também dados da matriz CTR. As figuras 5, 6 e 7 mostram os custos dos algoritmos para cada variação de cada grupo. Em todas as figuras o eixo de custo está na escala 1:103. Segundo estas figuras e a tabela 1 é possível verificar que a
40844 40846 40848 40850 40852 40854 40856 40858 40860
1 2
Variações do problema
Cust
os Huang
Aloc
Figura 5. 4 nós, 8 transações e 17 fragmentos
37000 38000 39000 40000 41000 42000 43000 44000 45000 46000 47000 48000
3 4 5 6
Variações do problema
Cu
st
os Huang
Aloc
Figura 6. 8 nós, 8 transações e 17 fragmentos
0 10000 20000 30000 40000 50000 60000 70000 80000 90000 100000
7 8 9 10
Variações do problema
Cus
to
s
Huang Aloc
5. Conclusões
Neste trabalho foi apresentada uma solução para o problema de alocação de fragmentos em SBDD. O objetivo foi encontrar um algoritmo simples Aloc que busque se aproximar o quanto possível de um problema real. Baseado em um trabalho previamente definido na literatura [5] que atende a estes quesitos, foi possível encontrar uma solução próxima de ótima com uma pequena variação do seu método de solução, mantendo a complexidade do algoritmo e aumentando o custo de processamento do algoritmo em média em menos de 10%. Com essa variação o algoritmo Aloc conseguiu reduzir o custo da matriz de alocação para todos os casos onde exista ao menos um fragmento onde sua melhor alocação deva ser em um nó que não execute nenhuma transação de leitura e somente atualização deste fragmento.
Além disso, segundo experimentos realizados, é possível verificar que o algoritmo proposto apresenta resultados melhores que o algoritmo original proposto em [5] para problemas com maior número de nós e fragmentos. Estes experimentos foram realizados com um modelo proposto pelo TPC-C para representar o comportamento dos algoritmos em situações reais.
O algoritmo apresentado neste trabalho pode ser estendido também para problemas de alocação de dados em ambientes com distribuição e replicação como servidores web e alguns sistemas de integração de banco de dados heterogêneos. Isto é possível por tratar os fragmentos de forma genérica sem considerar o modelo de dados.
A função de custo utilizada neste trabalho foi baseada na função de custo apresentada em [5]. Em seu trabalho, [5] faz uma comparação entre os custos obtidos com sua função de custo e de experimentos reais realizados comprovando a proximidade entre os valores estimados e reais. Existem na literatura outros modelos de custo que consideram custo de processamento local como o apresentado em [8] que foi desprezado no modelo de [5]. Em trabalhos futuros pretendemos realizar experimentos considerando esses custos no modelo.
Outros trabalhos futuros incluem a otimização do algoritmo de solução ótima, a fim de viabilizar a comparação de seus resultados em problemas maiores. Ainda, como no algoritmo original este trabalho não considera alocação dinâmica, ou seja, não considera a re-alocação de fragmentos, o que também será tratado em trabalhos futuros.
6. Agradecimentos
Este trabalho foi parcialmente financiado pela CAPES, CNPq e FAPERJ.
7. Referências
1. Ahmad, I., Karlapalem, K., Kwok, Yu, So, Siu, 2002, “Evolutionary Algorithms for Allocating Data in Distributed Database Systems”, Distributed and Parallel Databases 11(1), pp. 5-32.
2. Baião, F., Mattoso, M., Zaverucha, G., 1998, "Towards an Inductive Distributed Design of Object Oriented Databases". In: Proceedings of the "Third IFCIS Conference on Cooperative Information Systems" (CoopIS'98), IEEE CS Press, New York, USA, August, pp. 188-197.
4. Cruz, F., Baião, F., Mattoso, M., Zaverucha, G., 2002, “Towards a Theory Revision Approach for the Vertical Fragmentation of Object Oriented Databases”. In: Proceedings of the XVI Brazilian Symposium on Artificial Intelligence (SBIA'02), Lectures Notes in Artificial Intelligence, Springer-Verlag, Recife, Rio de Janeiro, nov, pp. 216-226.
5. Huang, Y e Chen, J., 2001 “Fragment Allocation in Distributed Database Design”. Journal of Information Science and Engineering, 17 (3), pp.491-506.
6. Karlapalem, K., Pun, N., 1997. “Query Driven Data Allocation Algorithms for Distributed Database System”. In Proceedings of the 8th International Conference on Database and Expert Systems Applications (DEXA 1997), pp.347-356.
7. Lin, X., Orlowska, M., Zhang, Y., 1993 “On data allocation with the minimum overall communication costs in distributed database design”. In Proceedings of the Fifth International Conference on Computing and Information, pp 539-544.
8. Özsu, M., Valduriez, P., 1999 “Principles of Distributed Database Systems”. Prentice-Hall, 2nd. Edition.
9. Sacca, D. e Wiederhold, G., 1985. “Database Partitioning in a Cluster of processors”. ACM Transactions on Database System, 10(1), pp. 29-56.
10. Shepherd, J., Harangsri, B., Chen, H. e Ngu, A., 1995. “A Two-Phase Approach to Data Allocation in Distributed Database”. In: Database Systems for Advanced Applications. DASFAA, pp.380-387 .
11. TPC-C, 2003, Transaction Processing Performance Council Benchmark C, version 5. www. tpc.org/tpcc.