Sérgio Gomes Gonçalves
Uma Plataforma para Revisão Automática
de Literatura via Técnicas de
Sér
gio Gomes Gonçalv
es 18 U ma Plat af or ma par a R evisão A utomática de Lit er atur a via Técncias de
Universidade do Minho
Escola de Engenharia
Text Mining
Te xt MiningDissertação de Mestrado
Mestrado Integrado em Engenharia e Gestão de Sistemas de
Informação
Trabalho efetuado sob a orientação do
Professor Doutor Paulo Alexandre Ribeiro Cortez
e coorientação do
Professor Doutor Sérgio Miguel Carneiro Moro
Sérgio Gomes Gonçalves
Uma Plataforma para Revisão Automática
de Literatura via Técnicas de
Universidade do Minho
Escola de Engenharia
DECLARAÇÃO Nome: Sérgio Gomes Gonçalves
Endereço eletrónico: [email protected] Telefone: 917236569 Número do Bilhete de Identidade: 13117683
Título da dissertação: Uma Plataforma para Revisão Automática de Literatura via Técnicas de Text Mining
Orientador(es): Professor Doutor Paulo Alexandre Ribeiro Cortez Professor Doutor Sérgio Miguel Carneiro Moro
Ano de conclusão: 2018
Designação do Mestrado: Mestrado Integrado em Engenharia e Gestão de Sistemas de Informação É AUTORIZADA A REPRODUÇÃO INTEGRAL DESTA DISSERTAÇÃO APENAS PARA EFEITOS DE INVESTIGAÇÃO, MEDIANTE DECLARAÇÃO ESCRITA DO INTERESSADO, QUE A TAL SE COMPROMETE;
Universidade do Minho, 22/10/2018 Assinatura:
Agradecimentos
Gostaria de agradecer à minha mãe, pai e irmã por todo o apoio que me têm dado ao longo da vida, estando sempre presentes em todas as fases da minha vida, sendo que esta não é exceção, tendo-me dado todo o apoio necessário. São incansáveis no apoio e procuram sempre ajudar-me o máximo que podem, e por isso merecem um grande obrigado, mais que merecido.
Agradeço aos meus orientadores, Professor Doutor Paulo Alexandre Ribeiro Cortez e Professor Doutor Sérgio Miguel Carneiro Moro, pelo apoio dado durante o desenvolvimento da dissertação, estando sempre presentes para o que fosse preciso.
Gostaria também de destacar o Francisco Ferreira, José Pinto e Rafael Morais, visto que a amizade e bons momentos vividos durante o percurso académico merecem ser destacados.
Agradeço também ao Tiago, que tem sido um verdadeiro amigo, sempre disponível para ajudar no que for necessário.
Resumo
A revisão de literatura é parte integrante do trabalho científico, possibilitando a compreensão dos con-ceitos abordados numa determinada área de investigação e servindo de fundação para o trabalho a ser desenvolvido pelos investigadores. Hoje em dia, é relativamente fácil encontrar uma quantidade conside-rável de artigos científicos para incluir no processo de revisão de literatura, visto que awebtem sido um potenciador da divulgação deste tipo de publicações em formato digital, promovendo o acesso a conteúdo de caráter científico. No entanto, e independentemente desses fatores, efetuar uma revisão de literatura é um processo maioritariamente manual e, por isso, demorado. A quantidade de artigos científicos publica-dos, nomeadamenteonline, também tem aumentando, dificultando a realização de revisões de literatura abrangentes, em determinadas áreas científicas.
No caso da revisão sistemática, os fatores enunciados contribuem para um acréscimo da complexidade inerente ao próprio processo de revisão, que engloba um conjunto de etapas metódicas. A etapa de seleção de estudos é uma das várias etapas da revisão sistemática, e envolve uma fase preliminar em que são analisados abstracts das várias publicações. Neste trabalho, através da aplicação de técnicas de Text Mining, bem como o recurso a arquiteturas baseadas em Deep Learning, desenvolveu-se um modelo para classificação de frases de abstracts, em que as frases são categorizadas nas seguintes classes: Background,Objective,Methods,ResultseConclusions. Para o desenvolvimento do modelo de classificação foi adotada a metodologia CRISP-DM, pelo facto de contemplar as várias fases necessárias para tal.
Visto que a maioria dosdatasetsdeste tipo contêm apenasabstractsda área de medicina, decidiu-se criar umdatasetde uma área científica distinta, sendo constituído apenas porabstractsda área de ciências da computação. Para tal, recorreu-se a inteligência coletiva ecrowdsourcing, tendo sido desenvolvida uma plataformawebpara suportar o processo de anotação de dados. Deste modo, o modelo de classificação foi treinado e avaliado em dois datasetsdistintos. Visto que o número deabstractsnodatasetrecolhido através decrowdsourcingé reduzido, decidiu-se também testar técnicas de aumento artificial de dados, de forma a determinar o seu impacto nos resultados.
No caso da plataforma de crowdsourcing, foram introduzidos componentes de gamification, como pontos e badges, para incentivar a participação no processo decrowdsourcing. Além disso, o modelo desenvolvido para classificação de frases deabstracts foi integrado na plataformaweb, possibilitando a utilização do modelo por parte de qualquer utilizador, independentemente do seu conhecimento técnico.
Abstract
The literature review is an integral part of scientific work, allowing the understanding of concepts addres-sed in a given research area and serving as a foundation for the work to be developed by the researchers. Nowadays, it is relatively easy to find a considerable number of scientific articles to include in the litera-ture review process, since the web has been an enabler of the dissemination of scientific publications in digital format, promoting access to scientific content. However, regardless of these factors, the process of conducting a litearture is mostly manual and, therefore, time-consuming. The number of published scien-tific papers, especially online, has also increased, making it difficult to carry out comprehensive literature reviews in certain scientific areas.
In the case of the systematic review, the stated factors contribute to an increase in the complexity inherent to the revision process, which encompasses a set of methodical steps. The study selection stage is one of several steps of the systematic review and involves a preliminary phase in which abstracts from various publications are analyzed for the purpose of study selection. In this work, through the application of Text Mining techniques, as well as the use of architectures based on Deep Learning, we have developed a model for classifying sentences of scientific abstracts, in which the sentences are categorized in the following classes: Background, Objective, Methods, Results and Conclusions. For the development of the classification model, the CRISP-DM methodology was adopted, since it contemplates the various phases necessary for the development of a classification model.
Since most of the datasets of this type contain only abstracts from the medical field, it was decided to create a dataset of a distinct scientific area, being composed only of abstracts of the area of computer science. For this, we used collective intelligence and crowdsourcing, developing a web plataform to support the data annotation process. Thus, the classification model was trained and evaluated on two different datasets. Since the number of abstracts in the dataset that we collected through crowdsourcing is low, it was also decided to test artificial data augmentation techniques, in order to determine their impact on results.
In the case of the crowdsourcing platform, gamification components like points and badges were in-troduced to encourage participation in the crowdsourcing process. Futhermore, the developed model for sentence classification of scientific abstracts was integrated on the web platform, allowing the use of the model by any user, regardless of their level of technical knowledge.
Índice
Agradecimentos . . . . iii
Resumo . . . . v
Abstract . . . vii
Lista de Figuras . . . xiii
Lista de Tabelas . . . . xv
Lista de abreviaturas, siglas e acrónimos . . . xvii
1 Introdução . . . . 1
1.1 Enquadramento e motivação . . . 1
1.2 Objetivos . . . 2
1.3 Abordagem metodológica . . . 3
1.3.1 Estratégia de pesquisa bibliográfica . . . 3
1.3.2 CRISP-DM . . . 3 1.4 Contributos do trabalho . . . 5 1.5 Organização do documento . . . 6 2 Enquadramento conceptual . . . . 9 2.1 Text mining . . . 9 2.1.1 Pré-processamento de texto . . . 10 2.1.2 Representação de texto . . . 11 2.1.3 Similaridade de documentos . . . 13
2.1.4 Named entity recognition . . . 14
2.1.5 Extração de tópicos . . . 15
2.2 Deep learningaplicado a dados textuais . . . 17
2.2.1 Redes neuronais convolucionais . . . 18
2.2.2 Redes neuronais recorrentes . . . 21
2.2.3 Long short-term memory . . . 22
2.3 Representações distribuídas de palavras . . . 24
2.3.1 Word2vec . . . 27
2.3.2 Global vectors for word representation . . . 30
2.4 Tipos de revisão de literatura . . . 31
2.4.1 Revisão narrativa . . . 31
2.4.2 Revisão sistemática . . . 32
2.5 Domínio de aplicação . . . 36
2.5.1 Oportunidades existentes no domínio de aplicação . . . 37
2.5.2 Aplicação detext miningna etapa de seleção de estudos da revisão sistemática 39 2.5.3 Aplicação detext miningpara avaliar a qualidade dos estudos da revisão siste-mática . . . 41
2.5.4 Aplicação detext miningna etapa de extração de dados da revisão sistemática 42 2.5.5 Desafios do domínio de aplicação . . . 43
2.5.6 Mapa de literatura . . . 44
3 Text miningaplicado a revisões de literatura . . . 47
3.1 Datasets . . . 48
3.2 Criação de umdatasetaplicando inteligência coletiva ecrowdsourcing . . . 49
3.2.1 Recolha deabstracts . . . 51
3.2.2 Plataforma para anotação dos dados . . . 52
3.3 Caraterização dosdatasetsa utilizar . . . 65
3.4 Modelação das arquiteturas . . . 67
3.4.1 Ferramentas tecnológicas . . . 67
3.4.2 Hardware . . . 68
3.4.3 Arquitetura proposta para classificação deabstracts . . . 68
3.4.4 CNN . . . 72
3.5 Integração dos modelos na plataforma . . . 73
4 Resultados . . . 77
4.1 Métricas de avaliação . . . 77
4.2 Desempenho dos modelos . . . 79
4.2.1 Desempenho nodataset PubMed 20k . . . 79
4.3 Hiperparâmetros . . . 82
4.4 Aumento artificial de dados e o seu impacto nos resultados . . . 85
4.5 Análise dos modelos . . . 89
5 Conclusões . . . 95
5.1 Síntese . . . 95
5.2 Discussão . . . 96
Lista de Figuras
1 Ciclo de vida e fases da metodologia CRISP-DM. . . 4
2 Identificação e classificação de entidades de uma frase. . . 14
3 Resultados obtidos para distribuições de Dirichlet com diferentes valores do parâmetro α 17 4 Evolução da percentagem de artigos, publicados nas principais conferências deNatural Language Processing, que abordam a utilização deDeep Learning . . . 18
5 Exemplo de operação de convolução sobre uma matriz deinput, para um determinado filtro, e respetivofeature mapresultante. . . 20
6 Diagrama representativo de uma LSTM. . . 23
7 Diagrama representativo da GRU. . . 24
8 Representação vetorial de cada termo, obtida porone hot encoding. . . 25
9 Representação distribuída dos termos. . . 26
10 Exemplo de projeção das posições no espaço para as representações vetoriais de pala-vras, obtidas pelo métodoWord2vec. . . 27
11 Arquitetura do modeloSkip-gram. . . 28
12 Arquitetura do modeloContinuous Bag of Words. . . 29
13 Fases e etapas do processo de revisão sistemática. . . 34
14 Mapa de literatura . . . 45
15 Página de entrada da plataforma. . . 56
16 Página de entrada vista numsmartphone. . . 57
17 Primeira etapa do tutorial de iniciação. . . 58
18 Segunda e última etapa do tutorial de iniciação. . . 59
19 Aviso de respostas erradas na última etapa do tutorial. . . 60
20 Página onde se procede à classificação das frases doabstract. . . 61
21 Aspeto da páginas após classificação de umabstract. . . 62
22 Página deachievements. . . 63
23 Gráfico que demonstra o número de utilizadores consoante o intervalo deabstracts clas-sificados. . . 64
24 Comparação entre o número de utilizadores que têm acesso total à plataforma, pois completaram o tutorial de iniciação, e o número de utilizadores com acesso restrito. . . 65
26 Frequências relativas para odataset PubMed 20k. . . 67
27 Arquitetura do modelo proposto (Word-BiGRU). . . 70
28 Arquitetura do modelo CNN. . . 73
29 Trocas de informação entreLaravelePython. . . 74
30 Página de classificação deabstracts. . . 75
31 Página de apresentação dosabstractsclassificados, com as respetivas classes de cada uma das frases identificadas numa tabela. . . 76
32 Curvas ROC e respetivas áreas abaixo da curva para o modelo Word-BiGRU nodataset PubMed 20k. . . 81
33 Curvas ROC e respetivas áreas abaixo da curva para o modelo Word-BiGRU nodataset CS Abstracts. . . 82
34 Curva ROC e respetivas áreas abaixo da curva para o modelo Word-BiGRU treinados no dataset CS Abstractscom dados aumentados artificialmente. . . 88
35 Termos mais preponderantes na classificação atribuída pelo modelo CNN para a pri-meira frase doabstract. . . 91
36 Termos mais preponderantes na classificação atribuída pelo modelo Word-BiGRU para a primeira frase doabstract. . . 92
37 Termos mais preponderantes na classificação atribuída pelo modelo CNN para a se-gunda frase doabstract. . . 92
38 Termos mais preponderantes na classificação atribuída pelo modelo Word-BiGRU para a segunda frase doabstract. . . 93
Lista de Tabelas
1 Document-term matrix. . . 12 2 Palavras de contexto para cada uma das palavras centrais, utilizando uma janela de
tamanho 3. . . 28 3 Principais distinções entre revisão narrativa e revisão sistemática. . . 33 4 Resumo de alguns dos trabalhos científicos que abordaram a aplicação de técnicas de
Text Mining para revisões de literatura. . . 36 5 Várias ferramentas que suportam a plataforma de anotação de dados, bem como a
função de cada uma delas. . . 53 6 Caraterísticas dehardware, tendo por base a instânciat2.micro. . . 54 7 Pontos necessário para alcançar cada um dos níveis . . . 62 8 Número de abstracts e frases para cada um dos datasets, separados por dados de
treino, validação e teste. . . 66 9 Resultados obtidos nodataset PubMed 20k. (melhores resultados destacados a negrito) 80 10 Resultados obtidos nodataset CS Abstracts. (melhores resultados destacados a negrito) 82 11 Hiperparâmetros do modelo CNN (melhores resultados destacados a negrito). . . 84 12 Hiperparâmetros do modelo Word-BiGRU (melhores resultados destacados a negrito). . . 85 13 Comparação das frases originais com as respetivas frases resultantes do processo de
data augmentation. . . 87 14 Resultados comparativos do aumento artificial de dados do dataset CS Abstracts, para
Lista de abreviaturas, siglas e acrónimos
API Application Programming InterfaceCNN Convolutional Neural Network
CPU Central Processing Unit
CRISP-DM CRoss Industry Standard Process for Data Mining
GRU Gated Recurrent Unit
GPU Graphical Processing Unit
LDA Latent Dirichlet Allocation
LSTM Long Short-Term Memory
ReLU Rectified Linear Unit
1
Introdução
Neste capítulo é feito um enquadramento do trabalho a desenvolver na dissertação, evidenciando as razões que motivam o desenvolvimento de uma dissertação nesta área, objetivos a alcançar, resultados que se esperam obter, bem como os contributos (artigos publicados) no âmbito da presente dissertação. Além do mais, é descrita a abordagem metodológica adotada e qual a estratégia de pesquisa bibliográfica utilizada. Este capítulo é finalizado com uma descrição da organização do documento.
1.1 Enquadramento e motivação
Através de texto o ser humano consegue expressar e transmitir os seu conhecimentos, ideias e opiniões, seja num contexto formal ou informal, desempenhado uma função de destaque no processo de comunica-ção, possibilitando a aquisição de novos conhecimentos (McNamara, Kintsch, Songer, & Kintsch, 1996). No sistema educativo, aprender a ler e escrever são das primeiras etapas no processo de ensino, sendo fundamental para a vida social e para o restante processo de aprendizagem. Nas mais diversas áreas de investigação, o conteúdo escrito, sobre a forma de publicações científicas, tem um papel de relevo no desenvolvimento das mesmas, bem como na transmissão de conhecimento sobre essas áreas. Tal indica que, se analisarmos o conteúdo presente nessas publicações, existirá a possibilidade de extrair padrões e informação de relevo.
No entanto, a quantidade de conteúdo de caráter científico disponibilizado tem vindo a aumentar, dificultando um processo de análise e revisão de modo exclusivamente manual. NoarXiv, um repositório de artigos científicos, no qual o número de publicações submetidas por mês tem subido consideravelmente ao longo dos anos, de acordo com os dados disponibilizados pela plataforma1. O número de publicações
submetidas num dado mês na plataformaarXivno ano de 2017 é aproximadamente o dobro do número de publicações submetidas para esse mês no ano de 2008. Deste modo, constata-se que existe um crescimento do conteúdo científico disponibilizado sobre a forma de publicações científicas, existindo uma necessidade de analisar esse conteúdo computacionalmente, com o objetivo de extrair conhecimento e identificar padrões presentes nas publicações.
Para esse fim, é possível recorrer a técnicas deText Mining que, segundo Tan (1999), possibilitam a extração de padrões e conhecimento de dados textuais, como publicações científicas disponibilizadas em formato digital.
O caso de Moro, Cortez, e Rita (2015) é um exemplo disso mesmo, pois desenvolveram uma metodo-logia na qual, através da utilização de técnicas deText Mining, é possível extrair as tendências existentes
numa determinada área, comoBusiness Intelligence. Os tópicos abordados nas publicações, a evolução desses tópicos ao longo do tempo, bem como os termos mais relevantes, são informações que com re-curso a esta metodologia, podem ser obtidas de forma automática. Assim sendo, a metodologia de Moro et al. (2015) insere-se maioritariamente na perspetiva de analisar as várias tendências presentes numa área de estudo, não existindo um foco no caso particular da revisão sistemática. Por esse motivo, na pre-sente dissertação, pretende-se desenvolver um componente maioritariamente focado no desenvolvimento de modelos para classificação das frases presentes emabstractscientíficos, sendo o principal propósito permitir que estes modelos possam ser aplicados para facilitar o processo de revisão de literatura.
No caso da revisão sistemática, mais particularmente focada na área da medicina, Dernoncourt (2017) na sua tese de Doutoramento propôs a utilização de uma rede neuronal baseada em técnicas de Deep Learning, com o propósito de classificação de frases deabstracts, para facilitar a revisão sistemática na área da medicina, tendo inclusivamente publicado umdataset comabstractsda área da medicina para esse efeito.
Na presente dissertação, é proposto um novo modelo para a classificação deabstracts, baseado em técnicas de Deep Learning, com vista a obter um modelo com melhor do desempenho. Além do mais, através de aplicação decrowdsourcingecollective intelligence, tendo sido desenvolvida uma plataforma
webpara esse propósito, é por nós apresentado um novodataset, que contémabstractsda área de ciência da computação, e visa a aplicação do modelo de classificação deabstracts para agilizar a revisão siste-mática na área de ciências da computação. Além do mais, o modelo é implementado numa plataforma
web, para que possa ser utilizado por qualquer pessoa, sem necessitar de um conhecimento aprofundado a nível tecnológico.
1.2 Objetivos
A definição dos objetivos para a dissertação direciona o desenvolvimento da dissertação, visto que esta deverá está alinhada com os objetivos definidos. O principal objetivo é, através da aplicação de técnicas de
Text Mining, auxiliar o processo de revisão de literatura, nomeadamente através da aplicação de modelos para classificação de texto. Para tal existe a necessidade de identificar de que forma uma revisão de literatura poderá ser auxiliada pela aplicação de técnicas deText Mining, sendo esse assunto abordado na fase de levantamento do estado da arte no domínio de aplicação, com principal incidência no processo de revisão sistemática.
No que ao desenvolvido do modelo de Text Mining diz respeito, o objetivo é utilizar uma arquitetura de Deep Learning e comparar com o que já foi feito na área, nomeadamente nos mesmos datasets.
Subsequentemente, tem-se como objetivo integrar os modelos deText Miningdesenvolver uma plataforma
web, que tem dois objetivos estruturantes. O principal objetivo do desenvolvimento desta plataforma é, através decrowdsourcinge inteligência coletiva, nomeadamente através da introdução de componentes de
gamification, conseguir envolver a participação de várias pessoas, de forma a que qualquer se consiga criar um novodataset, através de um processo de anotação de dados. Outro dos grandes objetivos resultantes do desenvolvimenta da plataforma, é conseguir integrar os modelos desenvolvidos na dissertação nesta mesma plataforma web para que qualquer utilizador possa aplicar estes modelos, independentemente dos seus conhecimentos a nível técnico, abstraindo a complexidade do utilizador final.
1.3 Abordagem metodológica
1.3.1 Estratégia de pesquisa bibliográfica
De modo a compreender os conceitos fundamentais para o trabalho de dissertação e identificar os trabalho relevantes na área, bem como efetuar um levantamento daquilo que é o estado da arte, é necessário fazer uma pesquisa e seleção criteriosa desses artigos. Nesse sentido, foi definido que para encontrar as publicações seriam utilizadas as plataformasGoogle Scholar,Web of Science,Scropus,Semantic Scholar,
ScienceDirectearXiv.
Para a pesquisa dos artigos de cada uma das áreas foram utilizados os seguintes termos de pesquisa:
‘text mining’, ‘deep learning’, ‘natural language processing’, ‘text mining’, ‘text classification’, ‘named entity recognition’,‘distributed representation of words’,‘literature review’,‘systematic review’e‘literature analysis’.
Com o intuito de encontrar artigos que englobassem as duas áreas, ou seja, que abordassem a aplica-ção de técnicas deText Miningpara efetuar revisões de literatura, recorreu-se à seguintequery: (‘literature review’ OR‘systematic review’OR‘systematic literature review’OR‘literature analysis’) AND (‘text mining’
OR‘text classification’OR‘machine learning’OR‘text categorization’OR‘natural language processing’OR
‘deep learning’).
Dos artigos obtidos através das pesquisas, nem todos eram relevantes. Através da leitura dos títulos e
abstractsdos mesmos, considerando também o número de citações, foi possível fazer uma triagem dos mesmos, mantendo apenas os artigos relevantes para as áreas abordadas na dissertação.
1.3.2 CRISP-DM
Para o desenvolvimento deste trabalho é aplicada a abordagem metodológica CRISP-DM (Chapman et al., 2000). A decisão em utilizar esta metodologia deve-se ao facto desta englobar as várias tarefas
envolvidas num processoText Mining. Como se pretende desenvolver modelos de classificação de texto, existe a necessidade de aplicar uma metodologia que identifique e caracterize as várias fases inerentes a um trabalho deste caráter.
As várias fases que formam o processo descrito na metodologia CRISP-DM estão representadas na Figura 1, bem como algumas das relações entre as várias fases da metodologia, formando o respetivo ciclo de vida. No entanto, a metodologia CRISP-DM ressalva que não existe uma obrigatoriedade das fases serem desempenhadas pela ordem exemplificada na Figura 1, podendo essa ordem ser adaptada para satisfazer as necessidades específicas de cada projeto. O mesmo princípio é aplicável para as relações existentes entre as fases, podendo existir mais ou menos relações do que as identificadas na Figura 1.
Figura 1: Ciclo de vida e fases da metodologia CRISP-DM. (Chapman et al., 2000)
Na fase de compreensão do negócio deverá ser entendido o negócio para o qual se pretende desen-volver o projeto em causa. Não é necessário que se compreenda de forma exaustiva e extremamente detalhada, mas sim ter uma perceção do propósito pelo qual está a ser desenvolvido o projeto e a razão pela qual é necessário, ou vantajoso, aplicar Data Mining ou Text Mining para esse propósito. Neste caso, a compreensão do negócio corresponderá maioritariamente à revisão de literatura do domínio de aplicação, até pelo facto dos modelos serem desenvolvidos no âmbito do trabalho de dissertação. A com-preensão do negócio possibilita a devida ponderação sobre a forma como serão aplicadas técnicas deText
Mining. Para esta dissertação, a fase de compreensão do negócio foca-se principalmente em perceber de que modo podem ser exploradas e aplicadas as técnicas deText Miningpara revisões de literatura.
De seguida, existe a fase de compreensão dos dados que tem como finalidade efetuar a devida análise dos dados existentes que neste caso, pelo facto de ser um projeto relativo a Text Mining, são dados textuais. Caso estes ainda não tenham sido recolhidos, é também necessário identificar como os dados textuais irão ser recolhidos, definindo e descrevendo a estratégia a utilizar para tal.
Na fase de preparação dos dados,e no caso concreto dos dados textuais, são realizadas várias ativi-dades necessárias para que os dados textuais possam ser empregues em várias ativiativi-dades relacionadas comText Mining, como treinar modelos de classificação de texto e respetiva validação. Deste modo, esta fase envolve a sequência de etapas necessárias para possibilitar que os dados textuais sejam devida-mente estruturados, para permitir a utilização destes em várias atividades relacionadas comText Mining. Por vezes é necessário voltar à fase de preparação de dados, para introduzir modificações ou alterar as técnicas utilizadas para a representação dos mesmos, fruto de novas necessidades identificadas na fase de modelação, por exemplo.
Na fase modelação são treinados os modelos e efetuadas decisões relativas aos modelos, como a definição da arquitetura a utilizar bem como a devida parametrização dos modelos. Os modelos podem ter diferentes propósitos, como a descoberta de tópicos, classificação de texto ou atribuição de classes a frases presentes no texto.
Durante a fase de avaliação, deverá ser analisado o desempenho dos modelos, através da definição de uma estratégia que possibilite aferir, não só o desempenho de um modelo em concreto, mas também possibilitar a comparação dos vários modelos, para que seja possível efetuar uma comparação justa e aferir corretamente qual o modelo com melhor desempenho.
Na fase de implementação, os modelos desenvolvidos são colocados em ambiente produtivo, que neste caso corresponde à integração dos mesmos numa plataformaweb.
1.4 Contributos do trabalho
No âmbito da presente dissertação foi desenvolvido o seguinte artigo, que já se encontra publicado: • Gonçalves S., Cortez P., & Moro S. (2018) A Deep Learning Approach for Sentence Classification of
Scientific Abstracts. In: Kurková V., Manolopoulos Y., Hammer B., Iliadis L., Maglogiannis I (Eds.), Artificial neural networks and machine learning – ICANN 2018 (pp. 479–488). Cham: Springer International Publishing.
para a finalidade de classificação de frases de abstracts, englobando uma comparação de resultados com um outro modelo.
No âmbito da dissertação, foi também desenvolvido um dataset com o propósito de o disponibilizar publicamente. Essedatasetfoi desenvolvido com recurso a crowdsourcinge inteligência coletiva, sendo que odatasetestá disponibilizado no seguinte endereço:
• https://github.com/sergiog95/csabstracts
O dataset contémabstracts de artigos da área de ciências da computação, sendo que cada uma das frases está categorizada nas respetivas classes.
1.5 Organização do documento
O presente documento é constituído por cinco capítulos. O primeiro capítulo corresponde a um capítulo introdutório, no qual é descrito o enquadramento e motivação da dissertação, bem como os objetivos e abordagem metodológica, assim como a estratégia de pesquisa bibliográfica adotada.
O segundo capítulo corresponde ao enquadramento conceptual, em que são explorados e descritos os vários conceitos inerentes à dissertação, mais concretamente, os conceitos relativos às áreas deText Mininge revisão de literatura. Na última secção deste capítulo, é analisado de que modo as duas áreas, e respetivos conceitos, se relacionam, de forma a identificar o estado da arte relativo à aplicação de técnicas
Text Miningpara revisões de literatura.
No terceiro capítulo, mais precisamente na primeira secção, é detalhado o trabalho desenvolvido para auxiliar o processo de revisão sistemática, nomeadamente através do desenvolvimento modelos para clas-sificarabstracts, sendo este capítulo constituído por cinco secções. Na primeira secção, é efetuada uma análise dos datasets já existentes para treinar modelos de classificação deabstracts. Na segunda sec-ção desse mesmo capítulo, é detalhado o processo através do qual se criou um novodataset para este domínio de aplicação, através decrowdsourcinge inteligência coletiva. Para esse propósito foi desenvol-vida uma plataformaweb, pelo que a infraestrutura tecnológica adotada para tal é também descrita. Na terceira secção são caraterizados os doisdatasets aplicados para treinar os modelos. Na quarta secção são detalhados os modelos e arquiteturas adotadas para os modelos de classificação deabstracts, bem como as ferramentas tecnológicas utilizada para tal. Por fim, na última secção do capítulo, é explicado de que forma os modelos desenvolvidos foram integrados na plataformaweb.
O quatro capítulo corresponde à apresentação de resultados, onde são enunciadas as métricas de avaliação aplicadas, bem como os resultados dos modelos e respetiva análise comparativa.
tra-balho desenvolvido, evidenciando e discutindo os resultados obtidos, assim como o tratra-balho a ser desen-volvido futuramente, no seguimento desta dissertação.
2
Enquadramento conceptual
Neste capítulo são abordados os vários conceitos relacionados com a áreas deText Mining e revisões de literatura, possibilitando a compreensão destas duas áreas de relevo para a dissertação, obtendo-se uma perceção sobre os conceitos inerentes às mesmas. Por essa razão, neste capítulo, e numa primeira instân-cia, são identificados os conceitos-chave que existem nas áreas deText Mininge de revisões de literatura, existindo um foco na revisão sistemática de literatura. É também feito um levantamento dos principais conceitos deDeep Learning, principalmente aqueles que possam ser aplicados no desenvolvimento de modelos de classificação de texto, como redes neuronais recorrentes ouword embeddings.
São ainda identificadas as relações existentes entre os conceitos das duas áreas, identificando desafios e oportunidades, permitindo determinar o estado da arte no que diz respeito à aplicação de técnicas de
Text Miningpara revisões de literatura.
2.1
Text mining
Pelo facto da comunicação escrita ser de natureza humana existem certas nuances que, apesar de serem triviais para o ser humano, um algoritmo computacional apresentará algumas dificuldades em interpretá-las corretamente (Gupta & Lehal, 2009), como o facto da mesma palavra poder ter significados diferentes consoante o contexto em que está inserida. Apesar dessas dificuldades, Gupta e Lehal (2009) referem que os computadores têm a vantagem de conseguirem processar grandes volumes de texto, ao contrário dos humanos. Como resultado da necessidade de extrair padrões e conhecimento de dados textuais, surgiu o conceito deText Mining.
Segundo Tan (1999),Text Miningé um processo pelo qual é possível extrair padrões e conhecimento não trivial de documentos de texto, podendo ser visto como uma extensão de Data Mining aplicada ao caso específico de texto. Porém, em Data Mining são utilizados dados estruturados, muitas das vezes armazenados em bases de dados relacionais, ao invés de Text Mining, em que se utilizam dados não estruturados ou semiestruturados (Gupta & Lehal, 2009).
De realçar queText Miningé uma área interdisciplinar que utiliza os contributos de outras áreas, como
Information Retrieval, Information Extraction e Machine Learning. De acordo com Miner et al. (2012) a área de Machine Learning teve um contributo gradual para os progressos feitos em classificação de texto durante a década de 90. O estudo efetuado por Moulinier e Ganascia (1995) é um exemplo de tal, tendo sido demonstrado experimentalmente que os “os algoritmos de Machine Learningpodem ser aplicados com sucesso na categorização de texto”. São várias as alternativas que podem ser utilizadas para categorização de texto, tais como árvores de decisão, redes neuronais ouSupport Vector Machines
(Korde & Mahender, 2012).
Existem várias aplicações possíveis de técnicas de Text Mining, tanto no contexto empresarial como académico. No entanto, o conjunto de técnicas a utilizar nem sempre é o mesmo. Com o desenvolvimento da web e, em concreto, o aparecimento das redes sociais, surgiram também casos específicos para a aplicação de Text Mining. He, Zha, e Li (2013) realçam que com a crescente presença das empresas em plataformas desocial media, existe uma crescente necessidade das empresas recolherem os dados presentes nas suas redes sociais para que, através da aplicação de técnicas de Text Mining, consigam descobrir padrões presentes no texto. Oliveira, Cortez, e Areal (2017) também analisaram dados textuais contidos em redes sociais, propondo uma metodologia capaz de prever vários indicadores financeiros relacionados com o mercado bolsista, utilizando a polaridade dos sentimentos de tweetspara tal. Num outro estudo, os autores utilizam dados extraídos da plataforma StockTwitspara prever as variáveis dos mercados financeiros (Oliveira, Cortez, & Areal, 2013).
Em áreas científicas como biomedicina, por vezes é necessário analisar grandes quantidade de lite-ratura para descobrir relações entre genes ou proteínas. Contudo, o processo da análise de litelite-ratura pode tornar-se demorado, caso este seja feito de forma manual. Podem ser utilizadas várias estratégias para combater esses obstáculos, nomeadamente através da aplicação de técnicasText Mining, como na-med entity recognition, para identificar e extrair entidades relacionadas com a biomedicina, como genes, proteínas ou nomes de medicamentos (Cohen & Hersh, 2005).
2.1.1 Pré-processamento de texto
O pré-processamento de texto envolve um conjunto de técnicas que são utilizadas para uniformizar os dados textuais, como a substituição de letras maiúsculas por minúsculas, redução de palavras à sua forma raiz através destemming, bem como a remoção destop words.
A aplicação de um algoritmo destemmingpermite reduzir palavras à sua forma raiz. O principal objetivo é possibilitar que diferentes variações da mesma palavra (como diferentes conjunções verbais ou formas gramaticais) sejam reduzidas a uma só palavra, que corresponde à raiz dessas palavras. A aplicação de
stemmingpermite, por exemplo, reduzir a palavrastoppedparastop, oustartedparastart. A redução de uma palavra à sua forma raiz pode ser alcançada de diferentes modos, como a remoção de sufixos ou prefixos de palavras ou a utilização de dicionários, onde se define a raiz de várias palavras.
O algoritmo proposto por Porter (1980) utiliza um conjunto de regras que permitem reduzir as palavras através da remoção dos seus sufixos (caso aplicável). O algoritmo abrange principalmente as palavras escritas em inglês. O autor propôs também umaframework, para possibilitar a implementação de novos
algoritmos destemming(Porter, 2001). Geralmente, a aplicação destes algoritmos acaba por se traduzir numa diminuição do número de palavras originalmente presentes no vocabulário. Em alguns casos, o número de palavras reduzidas para a sua forma raiz poderá ser considerável. Num vocabulário composto por 10000 palavras, Ramasubramanian e Ramya (2013) observaram que após a aplicação destemming
a maioria das palavras presentes no vocabulário foram reduzidas à sua forma raiz. Nem sempre as pala-vras que são reduzidas ficam corretamente representadas, sendo que algumas não são compreensíveis do ponto de vista humano, podendo as diferentes abordagens destemmingter níveis distintos de agres-sividade. Uma abordagem pouco agressiva, em casos dúbios, não reduz a palavra, mantendo-a na sua forma original. Por outro lado, uma abordagem agressiva tende a reduzir a palavra, mesmo em casos dúbios (Singh & Gupta, 2017).
Num estudo efetuado por Biba e Gjati (2014), observou-se que a aplicação de técnicas destemming
melhorou os resultados obtidos num caso específico de classificação de texto, quando comparados com os resultados obtidos semstemming. No entanto, nem sempre a aplicação destemmingtem um impacto positivo nos resultados obtidos visto que, num estudo efetuado por Toman, Tesar, e Jezek (2006), a utilização de stemmingtem um impacto negativo nos resultados obtidos na tarefa de classificação de texto.
2.1.2 Representação de texto
Diferentes técnicas podem ser utilizadas para representar o texto numa estrutura que possa ser utilizada em atividades relacionadas comText Mining, como classificação de texto. Existem dois conceitos relevan-tes para a representação de texto: Bag of WordseVector Space Model(Salton, Wong, & Yang, 1975). O conceito debag of wordsdefine que um documento pode ser representado pelo conjunto de palavras que o integram, sendo ignorada a ordem das palavras. O conceito deVector Space Modeldefine que um docu-mento pode ser representado por um vetor, vetor esse que ocupa uma posição no espaço vetorial (Turney & Pantel, 2010). Turney e Pantel (2010) ressalvam que o conceito deVector Space Modelemprega outros conceitos base, tais comoBag of Words, visto que noVector Space Modelcada documento é representado através de um vetor que não contém qualquer informação relativa à ordem dos termos do documento. Uma estrutura que se enquadra neste conceito é a document-term matrix. Umadocument-term matrix
apresenta uma estrutura similar à que é apresentada na Tabela 1, sendo que estadocument-term matirx
contém três documentos, identificados por ‘Documento A’, ‘Documento B’ e ‘Documento C’. Por sua vez, para esses documentos, é apresentado o número de vezes que cada um dos termos aparece.
Tabela 1:Document-term matrix.
contabilista emprego motorista trabalho universidade
Documento A 1 1 1 1 1
Documento B 0 1 0 2 2
Documento C 0 0 0 1 1
Umadocument-term matrixcontém, essencialmente, informação acerca da constituição dos documen-tos, através da quantificação das palavras presentes nos documentos. Nesta matriz, cada linha corres-ponde a um documento. Para esse documento, são atribuídos valores, de acordo com o número de vezes que um determinado termo aparece no documento (as colunas representam termos), ou seja, cada linha da matriz é um vetor representativo do documento.
Em alternativa, a document-term matrixpode só conter informação relativamente há ocorrência (ou não) de um determinado termo num documento, sendo que tal é feito através da atribuição do valor 0 ou 1 para cada termo, de acordo com a respetiva composição do documento. Salton e Buckley (1988) referem que a atribuição de pesos binários tem algumas limitações, como o facto de não permitir distinguir termos pela sua ordem de importância.
Luhn (1957) sugere que um autor, ao utilizar várias vezes o mesmo termo, está a conferir particular importância a esse termo para exprimir as suas ideias, pelo sugere utilizar a frequência dos termos para representar os documentos.
Visto que os termos mais frequentes nem sempre são os mais importantes, Sparck Jones (1972) propõem um conceito denominadoInverse Document Frequency. Este método assume que a importância de um termo é inversamente proporcional ao número de vezes que este ocorre no conjunto de documentos:
idfi = log ( N dfi ) (1)
onde N é o número total de documentos e dfi é o número de documentos que contêm o termo i. Existe ainda a possibilidade de combinar a Inverse Document Frequencye a frequência dos termos para calcular o peso que cada um dos termos tem, através do métodoTerm Frequency Inverse Document Frequency, que se traduz na seguinte equação matemática:
wij = tfij × log ( N dfi ) (2)
de documentos e dfié o número de documentos que contêm o termo i.
Ressalva-se que a escolha do método para cálculo do peso dos termos poderá ter impacto nos resulta-dos obtiresulta-dos em algumas das tarefas deText Mining, nomeadamente na classificação de texto através de
Support Vector Machines(Lan, Sung, Low, & Tan, 2005) e, por esse facto, a escolha do método deverá ser ponderada e, se possível, deverá ser analisado o desempenho do modelo para diferentes métodos de cálculo do peso dos termos.
2.1.3 Similaridade de documentos
Dado um conjunto de documentos, um humano consegue aferir o quão similar ou díspares são os docu-mentos do conjunto, através da leitura dos mesmos. Tendo em conta que, para fins deText Mining, os documentos podem ser representados sobre a forma vetorial, uma solução lógica consiste na manipula-ção desses vetores através de operações, com o objetivo de extrair informamanipula-ção sobre a similaridade dos documentos.
Dada uma document-term matrix que contenha os vetores representativos de vários documentos, a similaridade entre os documentos pode ser calculada através da similaridade do cosseno. Assim, a simi-laridade do cosseno funciona como uma métrica que quantifica o quão similar é um par de documentos, permitindo efetuar o agrupamento automático de documentos (Huang, 2008).
A similaridade do cosseno é obtida através do cálculo do cosseno do ângulo formado entre dois vetores, cada um pertencente a um documento distinto. Derivado das propriedades de uma document-term matrix, assim como as propriedades matemáticas do ângulo do cosseno, este valor poderá compreender valores entre 0 e 1, inclusive. Caso os documentos sejam algo similares, mas não totalmente similares, os valores deverão andar andar abaixo de 1 mas bastante acima de 0. Em casos que os dois documentos sejam muito pouco similares, o valor deverá estar bastante próximo. Inversamente, caso os documentos contenham constituições bastante similares, os valores deverão ser bastante próximos de 1. De realçar que dois documentos podem ser bastante similares em termos dedocument-term matrixque apresentam mas um ser humano pode acabar por ter uma perspetiva diferente, após a leitura e comparação dos mesmos.
Dados dois vetores, a similaridade do cosseno é obtida através da seguinte equação:
cos(x, y) = x y
∥x∥∥y∥ (3)
onde x e y são os vetores dos documentos para os quais se pretende calcular a similaridade do cosseno. Para calcular os valores da similaridade do cosseno, pode-se recorrer às representações vetoriais dos
documentos, contidos nadocument-term matrix.
Outra solução possível para o cálculo da similaridade de dois documentos consiste na utilização do coeficiente de Jaccard. O coeficiente de Jaccard permite obter a similaridade entre conjuntos, e é obtido através da interseção dos elementos presentes em ambos os conjuntos, dividida pela união dos dois conjuntos. Deste modo, o coeficiente de Jaccard é dado por:
J (A, B) = |A ∩ B|
|A ∪ B| (4)
Assim, depreende-se que o coeficiente de Jaccard depende do número de elementos que existem em comum entre A e B. Identicamente ao valor obtido pela similaridade do cosseno, o valor do coeficiente de Jaccard assume valores entre 0 e 1, inclusive.
2.1.4 Named entity recognition
A finalidade denamed entity recognitioné identificar e classificar corretamente, de forma automática, as entidades que estão presentes num determinado texto. O conceito denamed entity recognition, numa primeira instância, foi abordado na área de extração de informação, na sexta edição daMessage Unders-tanding Coference(Grishman & Sundheim, 1996). Contudo, a tarefa denamed entity recognitiontem sido útil na atividade deText Mining, sendo considerada uma parte importante da aplicação deText Miningcom o propósito de analisar literatura, nomeadamente na área da biomedicina (Tanabe, Xie, Thom, Matten, & Wilbur, 2005). As entidades identificadas no texto são classificadas nas categorias apropriadas, tais como pessoas, organizações, locais, datas entre outras. Na Figura 2 é exemplificado, para uma frase, as várias entidades que seriam identificas e classificadas, através denamed entity recognition.
Figura 2: Identificação e classificação de entidades de uma frase.
Um dos desafios de classificar corretamente as entidades, deve-se ao facto da mesma palavra (ou grupo de palavras) poder ter classificações diferentes consoante o contexto em que se insere. No caso
do termo ‘Francisco Sá Carneiro’, este pode ser entendido como um nome pessoal, assim como o nome do aeroporto do Porto, dependendo do contexto. No que diz respeito às abordagens utilizadas na tarefa denamed entity recognition, estas podem ser categorizadas em dois grandes grupos: as que se baseiam em regras pré-definidas e as que utilizamMachine Learning, com recurso a modelos estatísticos.
Um dicionário de entidades pode ser utilizado na abordagem baseada em regras. Geralmente, nesses dicionários, são definidos os mapeamentos entre termos e a respetiva classificação, ou seja, o dicionário poderia conter o mapeamento entre ‘Portugal’ e a classificação ‘Local’. Assim sendo, o princípio base da abordagem baseada em regras, consiste em definir um conjunto de regras que possibilitem capturar de-terminadas caraterísticas presente no texto, de forma a identificar e classificar corretamente as entidades, com as respetivas limitações associadas a uma abordagem deste género. Veja-se que, se existirem casos que não estão contemplados nas regras definidas, possivelmente a entidade classificada erradamente.
São vários os modelos que têm vindo a ser aplicados, tais como Support Vector Machines (Ekbal & Bandyopadhyay, 2010), redes neuronais de diferentes arquiteturas (Lample, Ballesteros, Subramanian, Kawakami, & Dyer, 2016) ou árvores de decisão (Szarvas, Farkas, & Kocsor, 2006). Visto que aWikipedia
contém uma vasta quantidade de conteúdo sobre a forma de texto, escrito em várias línguas, tal facto pode ser explorado para a criação dos dados de treino, de forma a obter modelos capazes de identificar entidades em idiomas distintos, como proposto por Nothman, Ringland, Radford, Murphy, e Curran (2013). Os modelos deMachine Learningpodem ser treinados de forma semi-supervisionada, combinando da-dos previamente classificada-dos com dada-dos sem qualquer tipo de classificação. Esta solução é apropriada para situações nas quais a quantidade de dados previamente classificados é reduzida (Liao & Veerama-chaneni, 2009). Em contrapartida, existem abordagens não supervisionadas, como proposto por Zhang e Elhadad (2013), sendo o modelo treinado exclusivamente com dados sem classificação prévia.
2.1.5 Extração de tópicos
Latent Dirichlet Allocation (Blei, Ng, & Jordan, 2003) é um modelo estatístico generativo que permite extrair tópicos de documentos de texto. O LDA supõe que um autor, antes de escrever um documento, especifica os tópicos sobre os quais quer escrever. Por sua vez, para cada um desses tópicos, existe um conjunto de palavras que o autor utilizará ao longo do texto.
Com base neste princípio, Blei et al. (2003) sugeriram um algoritmo cujo o objetivo é estimar correta-mente como foi feita essa alocação de tópicos, e quais os termos utilizados nessas alocações. Assim, o LDA deverá ser capaz de estimar uma distribuição de tópicos e, consequentemente, uma distribuição de palavras, de tal forma que essa seja a mais correta para o documento sobre análise.
Uma das limitações do LDA deve-se ao fato de não capturar a semântica utilizada por humanos, visto que os documentos são representados através da técnicaBag of Words(Wei & Croft, 2006), pelo que a ordem das palavras é ignorada.
O processo generativo do LDA pode ser sumarizado pela seguinte sequência de etapas: 1. Para cada tópico k∈ {1, ..., K}:
(a) Extrair uma distribuição de palavras φk∼ Dir(β) 2. Para cada documento d∈ {1, ..., D}:
(a) Extrair uma distribuição de tópicos θd∼ Dir(α) 3. Para cada posição n∈ {1, ..., N} no documento d:
(a) Extrair um tópico k ∼ Multionomial(θd) (b) Extrair uma palavra wd,n∼ Multionomial(φk)
Os parâmetros α e β são referentes às respetivas distribuições de Dirichlet sendo que, de um modo geral, são utilizadas distribuições de Dirichlet simétricas no LDA (Cohen, 2016), pelo que esses parâmetros podem ser instanciados por um único número real. Caso a distribuição não seja simétrica, é necessário utilizar um vetor, constituído por vários números reais, como parâmetro. Segundo Cohen (2016), o motivo pelo qual se costuma utilizar uma distribuição de Dirichlet simétrica, deve-se ao facto desta simplificar significativamente a aplicação da distribuição de Dirichlet, além de facilitar o processo de aprendizagem do modelo. O autor refere ainda que, nestes casos, o parâmetro α da distribuição de Dirichlet dá pelo nome de parâmetro de concentração. Tendo em conta que, para cada documento, a distribuição de tópicos é extraída de uma distribuição de Dirichlet parametrizada por α, esse parâmetro influencia o número de tópicos pelos quais um documento é formado.
Para demonstrar de que forma o parâmetro α influencia a distribuição de tópicos alocada a um do-cumento e, tendo por base as experimentações demonstradas na seguinte apresentação2, simulou-se o
processo pelo qual a distribuição de tópicos é obtida, na ferramenta R, para um total de 25000 amostras, parametrizando a distribuição com diferentes valores de α. Os resultados obtidos estão representados na Figura 3, onde se recorreu a umsimplexbidimensional no qual cada um dos vértices corresponde a um tópico. Cada posição possível nosimplexcorresponde a uma distribuição multinominal, e cada amostra é representada por um ponto azul, sendo que a distribuição multinominal de tópicos, para cada amostra,
depende da posição que o ponto correspondente a essa amostra ocupa nosimplex. Se a amostra estiver localizada junto dos vértices, significa que o documento correspondente a essa amostra é bastante sus-cetível de conter apenas um tópico. Por outro lado, se a posição ocupada por essa amostra for próxima do centro, significa que é provável que esse documento seja constituído por vários tópicos. É possível constatar que, para α = 0.2, existem várias amostras concentradas nos vértices, ou seja, formadas por um só tópico. Por outro lado, para α > 1 verifica-se um aumento na concentração de amostras no centro.
Figura 3: Resultados obtidos para distribuições de Dirichlet com diferentes valores do parâmetro α
2.2
Deep learning aplicado a dados textuais
A área de Deep Learning tem apresentado uma evolução considerável durante os últimos anos, tendo o aparecimento de várias frameworks de Deep Learning, sobre a forma de código aberto, contribuído para uma progressiva utilização das técnicas deDeep Learning, tanto para projetos inseridos em contexto académico como empresarial, permitindo treinar redes neuronais com arquiteturas complexas, assim como utilizar esses mesmos modelos em ambientes de produção.
Frameworks como Tensorflow ou MXNet são exemplos deframeworks que têm contribuído para tal. Existem ainda bibliotecas desoftware, como oKeras, que disponibilizam uma API de alto nível para
inte-ragir com as váriasframeworks, incluindo as já mencionadas, proporcionando uma camada de abstração. A área deNatural Language Processingé uma das áreas nas quais as técnicas deDeep Learningtêm vindo a ser aplicadas, durante os últimos anos. Verificou-se uma evolução na percentagem de artigos científicos, publicados em conferências relativas a Natural Language Processing, nos quais é abordada a utilização de técnicas deDeep Learning, nomeadamente nas seguintes conferências (Young, Hazarika, Poria, & Cambria, 2017):
• Annual Meeting of the Association for Computational Linguistics; • Empirical Methods in Natural Language Processing;
• European Chapter of the Association for Computational Linguistics; • North American Chapter of the Association for Computational Linguistics.
Na Figura 4 é possível verificar a evolução dessa percentagem ao longo do tempo, constatando-se que a percentagem de artigos que abordam a utilizaçãoDeep Learning, publicados nestas quatro conferências da área deNatural Language Processing, evoluiu de forma significativa durante o período compreendido entre os anos de 2012 e 2017.
Figura 4: Evolução da percentagem de artigos, publicados nas principais conferências deNatural Language Processing, que abordam a utilização deDeep Learning (Young et al., 2017).
2.2.1 Redes neuronais convolucionais
Um dos principais aspetos estruturantes de uma rede neuronal convolucional é a layer de convolução. Uma layer de convolução de uma rede neural recebe um input, ao qual é aplicado um filtro (também chamado de kernel, em alguma da literatura), sendo que o filtro corresponde a uma matriz com um
tamanho definido pelo utilizador. Um dos elementos estruturantes dalayerconvolucional é o produto de Hadamard. O produto de Hadamard é o elemento presente nalayerconvolucional que permite converter um conjuntoinputsnumafeature. Ao conjunto defeaturesobtidas através dalayerconvolucional dá-se o nome defeature map. É usual utilizar funções de ativação após a convolução, permitindo a introdução de relações não lineares entre oinpute ooutputdalayerconvolucional. Uma dessas funções, é a função denominadaRectified Linear Unit(ReLU), e usualmente é utilizada como função de ativação nalayer de convolução devido ao facto do erro da rede neuronal convergir num menor espaço de tempo quando comparada com outras funções de ativação (Glorot, Bordes, & Bengio, 2011). A função ReLU é dada por:
f (x) = 0 x < 0 x x≥ 0 (5)
A função de ativação é aplicada a todos os elementos do feature map, obtendo-se assim aoutputda
layer de convolução. O processo que existe numalayerde convolução, desde o inputaté à obtenção do devidofeature mapatravés da aplicação das várias operações, está representado na na Figura 5.
Figura 5: Exemplo de operação de convolução sobre uma matriz deinput, para um determinado filtro, e respetivo feature map resultante.
O propósito dalayerde convolução numa rede neuronal é conseguir extrairfeaturesque sejam represen-tativas e úteis para inferir corretamente as classificações. Asfeaturesextraídas pelalayerde convolução são representações do inputintroduzido no modelo e deverão ser uma “representação interna doinput
capaz de preservar informação relevante” (LeCun, Kavukcuoglu, & Farabet, 2010). Os resultados obtidos no estudo efetuado por Razavian, Azizpour, Sullivan, e Carlsson (2014) sugerem que asfeaturesobtidas através dalayerde convolução poderão obedecer ao princípio enunciado, visto que os autores observaram que asfeaturesobtidas através dalayerde convolução podem ser utilizadas para treinar outros modelos, tais comoSupport Vector Machines, tendo os autores obtido resultados satisfatórios com esta abordagem. Redes neuronais que apresentem uma arquitetura baseada emlayersde convolução têm sido aplica-das com sucesso na área de visão computacional, nomeadamente na deteção e classificação de objetos presentes em imagens (Krizhevsky, Sutskever, & Hinton, 2012). No caso específico da visão
computacio-nal, alayerde convolução possibilita a deteção de padrões que permitem a identificação de caraterísticas com poder discriminativo, tais como formas ou arestas presentes nas imagens e, desse modo, atribuir uma classificação correta para a imagem.
Contudo, o âmbito de aplicação das redes neuronais convolucionais não se limita à área de visão computacional. Na área de Natural Language Processing, as redes neuronais são capazes de capturar relações existentes entre palavras e, desse modo, modelar frases (Kalchbrenner, Grefenstette, & Blun-som, 2014). Segundo Kim (2014), osword embeddingsfuncionam como representações universais das palavras, sobre as quais é possível utilizar uma ou maislayersde convolução, com o propósito de extrair
featuresespecíficas para o problema em questão.
2.2.2 Redes neuronais recorrentes
A principal caraterística que distingue as redes neuronais recorrentes de outras tipologias, é o facto de estas serem constituídas por várioshidden statesque apresentam dependências entre si. As redes neuro-nais recorrentes têm sido utilizadas para efetuar previsões em séries temporais, tais como prever o preço futuro de ações bolsistas (Hsieh, Hsiao, & Yeh, 2011) ou condições meteorológicas (Barbounis, Theocha-ris, Alexiadis, & Dokopoulos, 2006). No âmbito de Natural Language Processing, podem ser utilizadas para modelar dependências entre palavras, através da representação da frase como uma sequência de palavras, em que cada uma das palavras ocupa uma posição na sequência. As redes neuronais recorren-tes são treinadas segundo uma abordagem debackpropagation through time, que otimiza os parâmetros do modelo, como a matriz de pesos, através de gradient descent, com o objetivo de minimizar o erro da rede neuronal. Contudo, no caso de redes neuronais recorrentes é suscetível que a otimização de parâmetros numatime stepdistante dooutputdo modelo não tenha um impacto significativo na minimi-zação do erro, sendo que tal deve-se ao fenómeno devanishing gradientque ocorre nas redes neuronais recorrentes (Bengio, Simard, & Frasconi, 1994).
Este problema ocorre devido à forma como o gradiente é calculado. Como demonstrado por Bengio et al. (1994), para um custo Ctnatime stept, esse custo em função do parâmetro W é dado por:
∂Ct ∂W = ∑ τ≤t ∂Ct ∂st ∂st ∂sτ ∂sτ ∂W (6)
A equação implica que consoante a distância entre r e t aumenta, menor será o impacto resultante em
Ctde uma alteração no valor de W , causando o problema devanishing gradient(Bengio et al., 1994). No caso deNatural Language Processing, caso a ordem das palavras seja um fator importante, tal poderá
ser problemático.
2.2.3 Long short-term memory
A Long Short-Term Memory (LSTM) surgiu como uma alternativa às redes recorrentes convencionais, com o propósito de solucionar o problema de vanishing gradient. O principal fator distintivo de uma LSTM é facto de incluir um componente de memória que permita armazenar informação sobre oshidden statesprévios, como o objetivo de modelar eficazmente as dependências existentes entre elementos em diferentes posições de uma dada sequência.
Numa LSTM existem vários fluxos de informação entre a componente de memória e o hidden state, sendo esses fluxos de informação controlados por um conjunto de mecanismos denominadosgates, que assumem valores entre 0 e 1, inclusive. Existem trêsgatesdistintas:input gate,forget gateeoutput gate. Sejam U e W as matrizes de pesos, aforget gate para a time stept, representada por ft, e que é responsável por controlar a informação a ser eliminada da memória, é obtida por:
ft = σ(Wfxt+ Ufht−1+ bf) (7)
onde bf é o valor debias, σ é a função de ativaçãosigmoide xté oinputpara atime stept.
Como referido, para que seja possível manter informação ao longo dos várioshidden statesé utilizado um componente de memória. Para manter a memória atualizada, é necessário calcular a cadatime step
um novo candidato para o valor de memória. Seja jto candidato para valor de memória, este é calculado através de:
jt= tanh(Wjxt+ Ujht−1+ bj) (8)
Contudo, o novo candidato para valor de memória nem sempre tem informação relevante, pelo que a reutilização de determinada informação emhidden statesfuturos deverá ser evitada, o que significa que há informação que poderá ser ignorada. Seja itainput gateque controla esse fluxo de informação, esta é dada por:
it= σ(Wixt+ Uiht−1+ bi) (9)
Assim, utilizando o símbolo⊙ para denotar o produto de Hadamard, o valor de memória Cté calculado por:
ct= ft⊙ ct−1+ it⊙ jt (10)
forma direita, sendo esse fluxo de informação controlado pelaoutput gateotobtida por:
ot= σ(Woxt+ Uoht−1+ bo) (11)
Deste modo, contemplando aoutput gateot, ohidden statehté obtido por:
ht= ot⊙ tanh(ct) (12)
Na Figura 6 é apresentado o diagrama que demonstra os vários elementos que constituem uma LSTM.
Figura 6: Diagrama representativo de uma LSTM (Rußwurm & Körner, 2018).
2.2.4 Gated recurrent unit
A Gated Recurrent Unit foi introduzida por Cho et al. (2014) e, à semelhança da LSTM, são utilizadas
gatespara controlar os fluxos de informação. Comparativamente a uma LSTM, a GRU utiliza um número menor degatespara controlar os fluxos de informação, sendo aupdate gateereset gateos mecanismos utilizados. Dado ohidden stateht−1, a função dareset gateé conseguir controlar qual a informação desse
hidden stateque poderá ser ignorada nohidden stateht, pelo facto de não ser informação relevante para os próximoshidden states. Sejam U e W as matrizes de pesos, areset gatedenotada por rté calculada através de:
rt= σ(Wrxt+ Urht−1+ br) (13)
onde σ é a função de ativaçãosigmoid.
de ht. Tal é controlado pelaupdate gate, representada por ut:
ut= σ(Wuxt+ Uuht−1+ bu) (14)
Antes de ser calculado ht, é calculado umhidden statecandidato ˜htpara oinputxt, que é obtido por: ˜
ht= tanh(Whxt+ Uh(rt⊙ ht−1) + bh) (15)
Assim, utilizando rte utpara controlar os fluxos de informação, hté obtido por:
ht= ut⊙ ˜ht+ (1− ut)⊙ ht−1 (16)
O diagrama representativo daGated Recurrent Unité apresentado na Figura 7.
Figura 7: Diagrama representativo da GRU (Rußwurm & Körner, 2018).
Em termos de desempenho, não é possível concluir objetivamente que a GRU tem um melhor desem-penho que LSTM, ou vice-versa, tendo sido obtidos por Chung, Gulcehre, Cho, e Bengio (2014) resultados díspares, variando em função dodatasetutilizado. No entanto, durante o processo de treino observou-se que tanto a GRU como a LSTM convergem num menor espaço de tempo, quando comparadas a uma rede neuronal recorrente convencional.
2.3
Representações distribuídas de palavras
Num modelo de Machine Learning é necessário treinar o modelo através de um conjunto de inputs. Contudo, não é viável utilizar texto, de forma literal, para treinar o modelo. As redes neuronais necessitam de valores numéricos, até pelo facto do processo de treino consistir em minimizar uma função objetivo. Por esse motivo, é necessário converter as frases (e os seus termos) numa representação numérica.
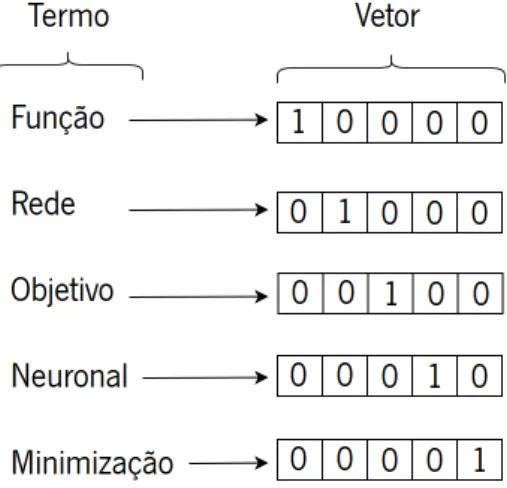
Uma das hipóteses para obter essas representações, consiste em utilizar uma técnica denominada one hot encoding, em que a cada palavra do vocabulário é associada um vetor. Nesse vetor, apenas um dos elementos tem o valor 1, sendo que todos os outros elementos têm o valor 0. Deste modo, o número de dimensões do vetor obtido através de one hot encodingé exatamente igual ao tamanho do vocabulário. As representações distribuídas de palavras não se aplicam apenas a redes neuronais, podendo também ser utilizadas em outros modelos comSupport Vector Machines(Yang, Macdonald, & Ounis, 2017), pelo que as representações distribuídas de palavras tanto podem se utilizadas emText Miningmais tradicional, bem como redes neuronais de arquiteturas complexas baseadas em conceitos deDeep Learning.
Exclusivamente para fins exemplificativos, na Figura 8 considera-se um vocabulário formado por apenas cinco termos, para os quais são obtidas as representações vetoriais porone hot encoding.
Figura 8: Representação vetorial de cada termo, obtida porone hot encoding.
Alternativamente aoone hot encoding, podem ser utilizadas representações distribuídas das palavras como inputda rede neuronal. A principal intenção desta técnica é conseguir atribuir às palavras uma posição no espaço vetorial, de modo a que as suas posições no espaço sejam capazes de capturar certas caraterísticas semânticas das palavras. Assim, palavras similares deverão ter posições bastante próximas no espaço, enquanto palavras pouco similares deverão ocupar posições distantes. Deste modo, uma representação distribuída das palavras poderá ser mais informativa, comparativamente a um vetor obtido através deone hot encoding, pois existe o potencial de conseguir capturar relações de similaridade semântica existentes entre termos. Além do mais, enquanto através dessa técnica o número de dimensões do vetor é igual à do vocabulário, através de uma representação distribuída de palavras o número de dimensões é reduzido (Goldberg, 2016), sendo geralmente utilizadas entre 50 a 300 dimensões. Na Figura 9 estão representados, a título de exemplo, possíveis vetores obtidos através desta técnica.
Figura 9: Representação distribuída dos termos.
Todavia, para obter estas representações vetoriais é necessário utilizar um método que permita capturar as caraterísticas semânticas das palavras, sendo o Word2vec(Mikolov, Chen, Corrado, & Dean, 2013) e
Glovedois dos métodos que podem ser utilizados para o efeito.
Na Figura 10 são apresentadas as posições dos vetores obtidos através do métodoWord2vec, e que demonstra a capacidade deste método em obter representações vetoriais de palavras que aproximam as relações e similaridades existentes entre termos. Neste caso em específico, constata-se que os nomes dos países são colocados numa posição que traduz (de forma aproximada) a distância geográfica existentes entre os países. Países fronteiriços são colocados em posições próximas no espaço vetorial. Por exemplo, Espanha é o termo mais próximo de Portugal, assim como a Alemanha está mais próxima da França do que Portugal. Além do mais, as representações obtidas também traduzem as relações existentes entre cada país e a sua respetiva capital: Madrid está para Espanha como Lisboa está para Portugal.
Figura 10: Exemplo de projeção das posições no espaço para as representações vetoriais de palavras, obtidas pelo métodoWord2vec (Mikolov, Chen, et al., 2013).
Concretamente, mesmo nos casos em que oinputda rede neuronal esteja no formatoone hot encoding, é comum utilizar-se uma embedding layer, responsável por converter esse input numa representação distribuída de palavras (Goldberg, 2016).
2.3.1 Word2vec
OWord2vec(Mikolov, Chen, et al., 2013) foi formulado tendo por base o pressuposto de que palavras com significados idênticos são acompanhadas por contextos idênticos e foi desenvolvido com o propósito de obter representações distribuídas de palavras, na forma de vetores, sendo que esses vetores podem ser obtidos através do métodoSkip-gramouContinous Bag of Words. Estes métodos têm ligeiras diferenças a níveis arquiteturais, mas o conceito chave utilizado é o mesmo. O objetivo do Word2vecé conseguir obter representações vetoriais de palavras que sejam capazes de traduzir a similaridade existente entre diferentes termos, tanto a nível sintático como semântico.
Como foi referido, existem dois métodos (Skip-gram e Continous Bag of Words, sendo que ambos utilizam uma técnica de janela deslizante para determinar as palavras de contexto de cada palavra central. O tamanho da janela é um parâmetro doWord2vecque pode ser definido pelo utilizador. Uma janela de tamanho 5 define que serão selecionadas as 5 palavras imediatamente à esquerda e direita da palavra central. Caso não existam palavras imediatamente à esquerda, apenas serão consideradas as palavras que se encontram à direita, e vice-versa.
Dada a sequência de palavras “o jogador de futebol marcou um golo durante o jogo”, aplicando uma janela de tamanho 3 para as palavras “futebol”, “marcou”, “um” e “golo”, nos casos em que essas palavras ocupam as posições de palavra central são obtidas as palavras de contexto correspondentes, representadas na Tabela 2.
Tabela 2: Palavras de contexto para cada uma das palavras centrais, utilizando uma janela de tamanho 3.
Palavra central Palavras do Contexto
futebol o, jogador, de, marcou, um, golo
marcou jogador, de, futebol, um, golo, durante
um de, futebol, marcou, golo, durante, o
golo futebol, marcou, um, durante, o, jogo
S ip-gram
No modeloSkip-grampretende-se prever as palavras do contexto associadas a uma determinada palavra central. A arquitetura utilizada é relativamente simples, constituída por uma input layer, que tem um tamanho equivalente ao número de palavras diferentes presentes no documento, umaprojection layere, por fim, umaoutput layer. A arquitetura utilizada pelo modeloSkip-gramestá representada na Figura 11.
Figura 11: Arquitetura do modeloSkip-gram (Mikolov, Chen, et al., 2013).
Nainput layer, a palavra é representada através de uma técnica de representação denominadaone hot encoding, no qual cada palavras tem um índice associado, sendo que esse índice apresenta o valor de 1 (casos essa palavra esteja presente) ou 0 (caso essa palavra não esteja presente).