ANÁLISE DE DESEMPENHO DE ALGORITMOS DE BINARIZAÇÃO DE
IMAGENS
Davi H. Neiva¹; Deise M. Borges¹;
Leandro Henrique Espindola V. de Almeida¹; Shayane
de O. Moura¹
¹Mestrando em Ciências da Computação - CIn -UFPE; E-mail: {dhn,dmb3,lheva,som2}@cin.ufpe.br
Justificativa
A binarização é uma técnica de conversão dos tons dos pixels de imagens para dois tons (branco e preto), com o intuito de identificar objetos e separá-los do fundo da imagem, analisar suas formas ou apresentá-la a um dispositivo de saída de um bit de resolução de intensidade. Suas aplicações podem ser vistas em Optical Character Recognition (OCR), armazenamento e transmissão de imagens (ex.
impressoras) e restauração de documentos. Em OCR’s os algoritmos de binarização precisam produzir
resultados rápidos e suficientemente discriminativos entre objeto e fundo da imagem para serem robustos e eficientes em aplicações em tempo real.
Considerando que análises estatísticas são bastante relevantes para determinação da eficiência e robustez de sistemas computacionais, este trabalho apresenta a comparação de desempenho de 17 algoritmos de binarização aplicados a imagens de placas de carro, utilizando testes de hipóteses para avaliar o tempo de execução e a taxa de acerto dos caracteres seguimentados após a binarização.
Fundamentação teórica
Em Processamento Digital de Imagens, uma operação de extrema importância é a Limiarização, que consiste na classificação dos elementos presentes na imagem em grupos, onde cada grupo apresenta características semelhantes. Um caso particular de limiarização ocorre quando se criam apenas dois grupos de classificação. Neste caso, a limiarização recebe o nome particular de Binarização.
Uma binarização se propõe a classificar os pontos presentes na imagem em dois grupos,
frequentemente referenciados como background, ou fundo da imagem, e foreground, ou o objeto
relevante presente. A binarização, por tanto, se propõe a separar os objetos presentes na imagem dos elementos de fundo, dividindo, assim, os pontos da imagem em dois conjuntos disjuntos. No entanto, binarizar com eficiência não é uma tarefa trivial. A maior dificuldade reside em encontrar o limiar ideal para classificar todos os elementos presentes na imagem de maneira correta, mesmo que estes objetos estejam sujeitos a ruídos diversos, como sombra, oclusão, posição e rotação. A busca por um limiar perfeito instiga a criação de vários métodos de binarização que funcionam dentro de seus propósitos, mas ainda não constituem uma técnica definitiva.
A equação abaixo, mostra uma formula básica para a operação de binarização:
Na equação, g(x, y) é o valor de intensidade do pixel na imagem binarizada, f(x, y) é o valor de intensidade do pixel na imagem original e T é o valor do limiar. A saída 1 corresponde aos pixels brancos e a saída 0 aos pixels pretos, respectivamente.
locais, que calculam o valor de cada ponto individualmente. Em geral, os algoritmos globais apresentam um melhor desempenho do ponto de vista computacional, por efetuarem operações mais simples ou de baixo custo. Porém, apresentam resultados inferiores, no plano quantitativo, quando comparados aos algoritmos locais.
Geralmente, os algoritmos globais são mais utilizados em aplicações simples, ou que exijam respostas rápidas, como em aplicações em tempo real. Existem várias formas de se definir um limiar em um algoritmo de binarização global. As principais técnicas de cálculo do limiar envolvem o uso e análise de histogramas, histogramas bidimensionais, limiarização iterativa, lógica fuzzy ou análise de entropia, entre outras tantas.
Ao longo dos anos, vários algoritmos foram sendo desenvolvidos, no intuito de se encontrar um método de binarização que fosse capaz de produzir imagens binarizadas para o maior número de aplicações possíveis. Porém, apesar dos avanços conseguidos, o estado da arte ainda não foi capaz de produzir um algoritmo definitivo de binarização.
Sendo assim, é comum na literatura, ao se pesquisar ou desenvolver um novo algoritmo de binarização, compará-lo com algumas técnicas já consagradas na área de Binarização. A comparação entre algoritmos pode ser feita através de um estudo de segmentação de imagens, como o proposto por
este trabalho, ou através de métricas de Ground Truth, como nos casos das competições de binarização
que ocorrem frequentemente.
Neste trabalho, foram selecionados alguns dos principais algoritmos de binarização existentes na literatura, que servem como parâmetro de comparação para os novos algoritmos que vem sendo desenvolvidos nos últimos anos. Ao todo, foram escolhidos dezesseis técnicas, todas globais, de binarização de imagens. Os algoritmos calculam o limiar de formas diversas: um utiliza lógica fuzzy, quatro utilizam entropia, três são iterativos, cinco utilizam análise de histograma, um utiliza um histograma bidimensional e três utilizam outras técnicas.
Objetivo da pesquisa
O objetivo principal desta pesquisa é avaliar o comportamento dos principais algoritmos de binarização global existentes na literatura, quando deparados com imagens retiradas do cotidiano, em ambientes de iluminação não-controlada, sob influência de sombras, sujeiras, e outros ruídos em geral. Para efetuar essa avaliação, os algoritmos foram comparados quanto a sua eficiência computacional, sendo todos eles executado em um mesmo computador (Intel Core 2 Duo 2.10GHz) e sobre um conjunto de imagens com dimensões padronizadas (1920 pontos de largura por 1080 pontos de altura) e também foram comparados quanto à sua eficiencia quantitativa, avaliada pela quantidade de caracteres segmentados a partir das imagens binarizadas produzidas. Foram considerados caracteres válidos aqueles que foram totalmente segmentados (sem cortes) e que se mostraram legíveis ao leitor.
Especificação da amostra
Dentro do contexto de Processamento de Imagens, a binarização é uma etapa do processo de
OCR’s que, são comumente aplicados para reconhecimento de caracteres de placas de carros em sistemas de segurança e de trânsito. Dessa forma, foram realizados experimentos através da aplicação de dezesseis
algoritmos de binarização sobre um banco de dados contendo 516 imagens de placas de carros, coletadas
na cidade de Recife-PE, utilizando como método de coleta a técnica de amostragem aleatória simples. Algumas imagens que compõem a base de dados podem ser visualizadas na Figura 1. Todas as imagens
Figura 1 - Exemplos da amostra
No primeiro teste, os algoritmos foram analisados em relação ao tempo de execução para binarização de cada imagem, extraindo destes resultados, os parâmetros para execução dos testes de hipóteses. Já no segundo, foi verificada a proporção de acertos na segmentação de todas as imagens binarizadas.
Análise exploratória
Após gerar os histogramas e identificar que, provavelmente, os dados não seguem uma distribuição normal, o teste de aderência Kolmogorov-Smirnov foi realizado. Os resultados do teste comprovaram que os dados não seguem a distribuição.
Metodologia
A realização de todos os experimentos utilizou o software R na versão 3.0.1.
As funções utilizadas, anteriormente, para a geração do histograma e para o teste de Kolmogorov-Smirnov, foram, respectivamente: hist() com inicialização de parâmetros de limites de coordenadas e
nomes dos histogramas e ks.test() parametrizando o teste para a normalidade com “pnorm”.
Foram realizados dois tipos de testes de hipóteses:
● O primeiro, para testar se as médias de tempo de execução dos algoritmos poderiam ser
consideradas iguais, foi utilizado o teste não-paramétrico de Wilcoxon, aplicado a todos os algoritmos, tomados dois a dois.
As hipóteses testadas foram:
H0: µ1 = µ2
H1: µ1≠ µ2
H0, as médias de tempo dos algoritmos são iguais H1, as médias de tempo dos algoritmos são diferentes µ1 e µ2, média de tempo dos algoritmos testados
No R, o teste utiliza a função: wilcox.test(), neste caso, utilizado com o parâmetro paired=TRUE, já que se trata de um teste de dados pareados.
● No segundo, foi realizado o teste de proporção para uma amostra, onde foi verificado se os
algoritmos atingiam uma taxa de acerto mínima de 60% na segmentação de caracteres.
H0: p0≥ 0,6
H1: p0 < 0,6
H0, a proporção de acerto atinge, pelo menos, 60% na segmentação
H1, a proporção de acerto não atinge 60% na segmentação
p0, proporção da amostra
Análise dos resultados
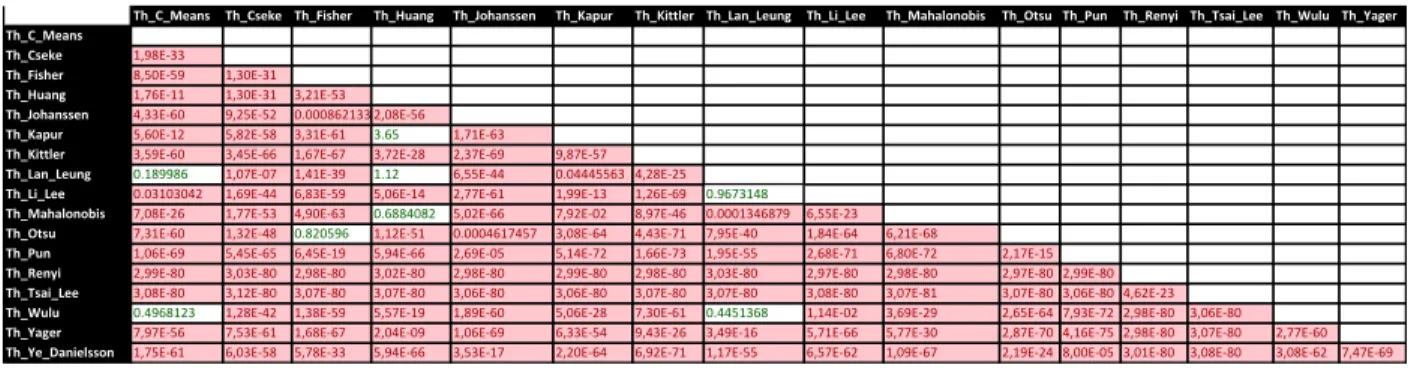
A partir da aplicação do teste de Wilcoxon, foi possivel montar a tabela de resultados a seguir (Tabela 1), que representa os p-values encontrados para o teste de Wilcoxon, quando aplicados aos pares de algoritmos designados pela linha x coluna da tabela:
Tabela 1 – Teste de Wilcoxon
Th_C_Means Th_Cseke Th_Fisher Th_Huang Th_Johanssen Th_Kapur Th_Kittler Th_Lan_Leung Th_Li_Lee Th_Mahalonobis Th_Otsu Th_Pun Th_Renyi Th_Tsai_Lee Th_Wulu Th_Yager Th_C_Means
Th_Cseke 1,98E-33
Th_Fisher 8,50E-59 1,30E-31
Th_Huang 1,76E-11 1,30E-31 3,21E-53
Th_Johanssen 4,33E-60 9,25E-52 0.00086213342,08E-56
Th_Kapur 5,60E-12 5,82E-58 3,31E-61 3.65 1,71E-63
Th_Kittler 3,59E-60 3,45E-66 1,67E-67 3,72E-28 2,37E-69 9,87E-57
Th_Lan_Leung 0.189986 1,07E-07 1,41E-39 1.12 6,55E-44 0.04445563 4,28E-25
Th_Li_Lee 0.03103042 1,69E-44 6,83E-59 5,06E-14 2,77E-61 1,99E-13 1,26E-69 0.9673148 Th_Mahalonobis 7,08E-26 1,77E-53 4,90E-63 0.6884082 5,02E-66 7,92E-02 8,97E-46 0.0001346879 6,55E-23
Th_Otsu 7,31E-60 1,32E-48 0.820596 1,12E-51 0.0004617457 3,08E-64 4,43E-71 7,95E-40 1,84E-64 6,21E-68
Th_Pun 1,06E-69 5,45E-65 6,45E-19 5,94E-66 2,69E-05 5,14E-72 1,66E-73 1,95E-55 2,68E-71 6,80E-72 2,17E-15
Th_Renyi 2,99E-80 3,03E-80 2,98E-80 3,02E-80 2,98E-80 2,99E-80 2,98E-80 3,03E-80 2,97E-80 2,98E-80 2,97E-80 2,99E-80
Th_Tsai_Lee 3,08E-80 3,12E-80 3,07E-80 3,07E-80 3,06E-80 3,06E-80 3,07E-80 3,07E-80 3,08E-80 3,07E-81 3,07E-80 3,06E-80 4,62E-23
Th_Wulu 0.4968123 1,28E-42 1,38E-59 5,57E-19 1,89E-60 5,06E-28 7,30E-61 0.4451368 1,14E-02 3,69E-29 2,65E-64 7,93E-72 2,98E-80 3,06E-80
Th_Yager 7,97E-56 7,53E-61 1,68E-67 2,04E-09 1,06E-69 6,33E-54 9,43E-26 3,49E-16 5,71E-66 5,77E-30 2,87E-70 4,16E-75 2,98E-80 3,07E-80 2,77E-60
Podemos perceber que, para o nível de confiança de 95% (0.05), a hipótese H0 foi rejeitada para
os algoritmos de Ye_Danielsson, Yager, Tsai-Lee, Renyi, Pun, Johanssen, Kittler e Cseke, que sugere que os algoritmos não apresentaram tempo de execução compatíveis com nenhum outro algoritmo testado, um indicativo de que seus tempos de execução seguem distribuições distintas entre si. O teste para o algoritmo C-Means não rejeitou a hipótese nula quando confrontado com os algoritmos de Lan-Leung e Wulu, o que indica que esses três algoritmos podem, com 95% de confiança, ser considerados como tendo a mesma média de performance computacional. O mesmo resultado ocorreu entre os algoritmos de Huang, Kapur, Lan-Leung e Mahalonobis. O algoritmo de Fisher foi semelhante apenas ao de Otsu e o de Li-Lee somente ao de Lan-Leung.
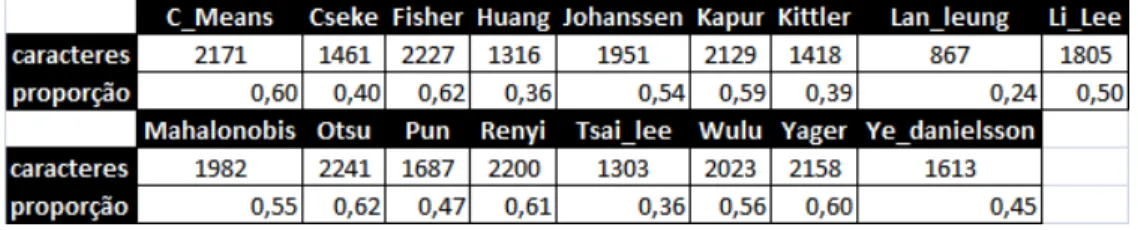
Tabela 2 – Médias dos algoritmos
Comparando as médias dos algoritmos (Tabela 2), podemos observar que, de fato, existe uma
distinção entre os algoritmos, quanto à sua performance computacional. Por exemplo, os algoritmos de Fisher e Otsu apresentaram praticamente a mesma média para as imagens, confirmando o resultado do teste de Wilcoxon. O tempo médio de execução dos algoritmos de Pun, Renyi e Yager, são, de fato, bastante distintas entre si e entre todas as médias dos algoritmos, resultado também previsto pelo teste. Podemos então, agrupar os algoritmos em 4 grupos, como ilustrado na tabela, baseado na semelhança de sua performance e nos resultados obtidos pelo teste de Wilcoxon.
O teste de proporções considera como H0,para cada algoritmo, que sua taxa de acerto seja igual
ou superior a 60% quando segmentados os caracteres das imagens. Assim, as amostras foram segmentadas após a binarização, a fim de verificar a qualidade do procedimento.
A tabela abaixo, mostra os dados iniciais do problema:
Tabela 3 – Proporções dos algoritmos
Após a realização do teste de proporções, os algoritmos foram divididos em dois grupos, onde o primeiro, mostra aqueles que têm desempenho satisfatório e não rejeitam a hipótese nula, atingindo uma proporção maior ou igual a 60%. Já o segundo grupo, mostra os algoritmos que não atingiram a qualidade esperada.
Tabela 4 – Grupo com desempenho satisfatório
Tabela 5 – Grupo com desempenho não-satisfatório
Algoritmo C_Means Fisher Kapur Yager Otsu Renyi
P-Value 0,129 2.031 -1.297 -0,312 2.506 1.114
Teste H_0 H0_não_rejeitado H0_não_rejeitado H0_não_rejeitado H0_não_rejeitado H0_não_rejeitado H0_não_rejeitado
Algoritmo Cseke Huang Tsai_Lee Johanssen Kittler Lan_Leung Mahalonobis Pun Wulu Ye_Danielsson Li_Lee P-Value -23.985 -28.910 -29.351 -7.343 -25.445 -44.160 -6.290 -16.309 -4.897 -18.822 -12.301