Spin One’s Wheels? Byzantine Fault Tolerance with a Spinning Primary
16
0
0
Texto
Imagem
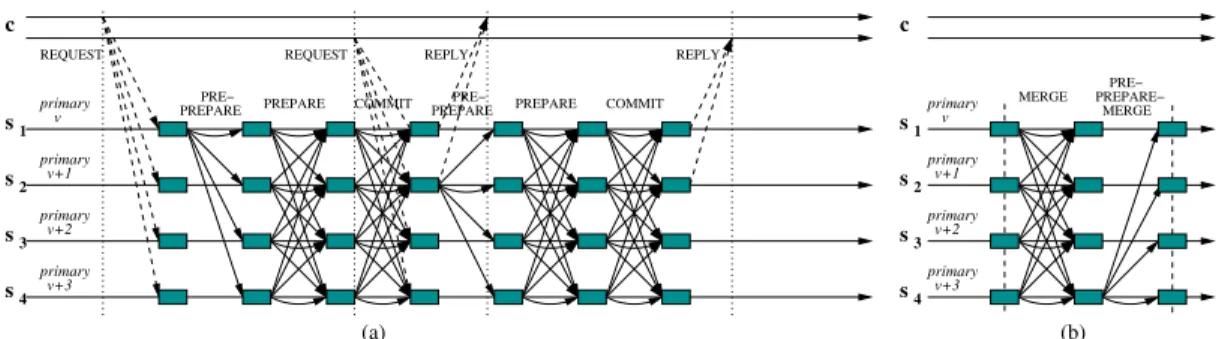
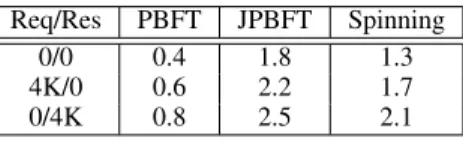
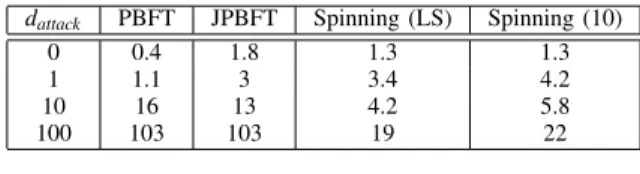
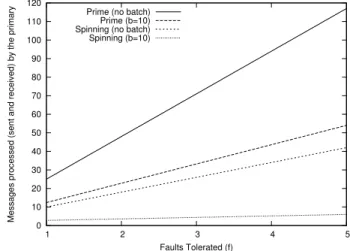
+2
Documentos relacionados