15ª Conferência da Associação Portuguesa de Sistemas de Informação (CAPSI 2015) 02 e 03 de Outubro de 2015, Lisboa, Portugal
ISSN 2183-489X
DOI http://dx.doi.org/10.18803/capsi.v15.460-474
460
Energy Consumption Categorization in Data Warehouses Populating Systems
Miguel Guimarães, Centro de I&D ALGORITMI, Universidade do Minho, Portugal, [email protected]
João Saraiva, HasLab - Laboratório de Investigação em Software Confiável, Universidade do Minho, Portugal, [email protected]
Orlando Belo, Centro de I&D ALGORITMI, Universidade do Minho, Portugal, [email protected]
Resumo
Os recursos computacionais exigidos durante o processamento de grandes volumes de dados durante um processo de povoamento de um data warehouse faz com que a necessidade da procura de novas implementações tenha também em atenção a eficiência energética dos diversos componentes processuais que integram um qualquer sistema de povoamento. A lacuna de técnicas ou metodologias para categorizar e avaliar o consumo de energia em sistemas de povoamento de data warehouses é claramente notória. O acesso a esse tipo de informação possibilitaria a construção de sistemas de povoamento de data warehouses com níveis de consumo de energia mais baixos e, portanto, mais eficientes. Partindo da adaptação de técnicas aplicadas a sistemas de gestão de base de dados para a obtenção dos consumos energéticos da execução de interrogações, desenhámos e implementámos uma nova técnica que nos permite obter os consumos de energia para um qualquer processo de povoamento de um data warehouse, através da avaliação do consumo de cada um dos componentes utilizados na sua implementação utilizando uma ferramenta convencional. Neste artigo apresentamos a forma como fazemos tal avaliação, utilizando na demonstração da viabilidade da nossa proposta um processo de povoamento bastante típico em data warehouses – substituição encadeada de chaves operacionais -, que foi implementado através da ferramenta Kettle.
Palavras chave: Povoamento de Data Warehouses, Avaliação do Consumo de Energia em
Componentes de Sistemas de ETL, Categorização de Consumos de Energia, Substituição Encadeada de Chaves Operacionais, Kettle.
Abstract
The amount of computational resources required for processing large volumes of data during a populating process of a data warehouse imposes new systems implementations having in attention the energetic efficiency of all the components integrating the populating system. It is notorious the lack of techniques and methodologies to categorize and evaluate the energy consumption for data warehousing systems populating processes. The access to such kind of information allows for the implementation of a data warehousing populating system with a low level of energy consumption and, therefore, more efficient. Adapting some of the techniques used on database management systems to reduce the energy consumption of query executions, we designed and implemented a new technique that allows for gathering the energy consumption of any data warehousing populating process through the evaluation of the energy consumption of each component used in its implementation. In this paper we present and discuss the way we did it, using a typical populating process for a data warehouse – a surrogate key pipelining -, implemented in Kettle, for demonstrating the viability of our proposal.
15ª Conferência da Associação Portuguesa de Sistemas de Informação (CAPSI 2015) 461 Keywords: Populating Data Warehouses, Energy Consumption Assessment ETL Systems
Components, Categorization Energy Consumption , Replacement Chained Operating Keys , Kettle
1.
I
NTRODUÇÃOCorrentemente, e em grande parte devido à mudança de paradigmas, a preocupação por questões energéticas tem vindo a acentuar-se. O aumento do preço da eletricidade bem como as questões relacionadas com o ambiente e a sua preservação, criaram a necessidade de se conceber componentes de software e de hardware energeticamente eficientes. Hoje, por exemplo, o fator de desempenho ou a eficiência de execução deixaram de ser, em exclusivo, as maiores preocupações dos gestores e administradores de centros de dados, sendo notório o peso que a eficiência energética tem vindo a ter na escolha final do software ou do hardware a utilizar. A preocupação pela produção de componentes de menor consumo energético e, consequentemente, que permitem uma maior poupança nos custos de manutenção de um qualquer centro de dados, incentivou a um claro aumento e aprofundamento do estudo de técnicas e métodos para criar sistemas economicamente mais rentáveis em termos energéticos.
Técnicas como o uso de diferentes esquemas de gestão de energia, como, por exemplo, a apresentada em (Kliazovich et al., 2010), demonstraram já a sua aplicação e utilidade na gestão do consumo de energia em centros de dados. Também, os trabalhos apresentados em (Beloglazov et al., 2011) e em (Sitaram et al., 2015) são provas muito claras daquilo que tem vindo a ser desenvolvido para a gestão da eficiência do consumo de energia em centros de dados, sendo mais uma confirmação acerca da mudança de paradigma em relação à questão da preocupação energética e da redução do consumo de energia. Do grande volume de dados que é armazenado diariamente em qualquer centro de dados, uma parte bastante significativa está relacionada com o sustento de sistemas de suporte à decisão e, em particular, com o povoamento de data warehouses. Não é recente a preocupação energética neste tipo de sistemas, sendo, hoje, claramente notória ao nível dos administradores de centros de dados. Tal conduziu ao incentivo do estudo e do desenvolvimento de soluções que tornassem os sistemas operacionais mais eficientes, menos consumidores de energia. Veja-se, por exemplo, o caso do trabalho apresentado em (Poess et al., 2010).
Usualmente, o povoamento de sistemas de data warehousing é realizado por peças de software bastante complexas, que, basicamente, tratam de recolher a informação que este tipo de sistema de dados precisa em diversos sistemas operacionais, conciliando-a, preparando-a e integrando posteriormente no data warehouse em questão. Este tipo de sistema é vulgarmente conhecidos por sistema ETL (Extract – Transform – Load). Porém, muito embora exista a preocupação de reduzir a despesa mensal que a manutenção de um centro de dados acarreta - um terço da despesa de manutenção recai no consumo energético dos servidores e dos sistemas de refrigeração (Rasmussen, 2011) -, nada de grande
15ª Conferência da Associação Portuguesa de Sistemas de Informação (CAPSI 2015) 462 relevância ainda foi feito no sentido de minimizar o consumo energético dos sistemas responsáveis pelo povoamento de data warehouses. Com base nas pesquisas que efetuámos, até à data, não existe nenhuma técnica ou investigação especialmente orientada para avaliar os consumos energéticos de um sistema ETL, especialmente no que diz respeito à avaliação de diferentes configurações para o sistema e dos seus correspondentes consumos energéticos. Apesar de existir desde 2007 um consórcio industrial denominado “The Green Grid” (Green Grid, 2015), formado por profissionais de todo o mundo, que lida com aspetos relevantes no que diz respeito à eficiência da utilização dos recursos envolvidos nos centros de dados, esse trabalho ainda não foi realizado.
Neste artigo, pretendemos apresentar e discutir o trabalho que temos vindo a realizar em prol da avaliação do consumo de energia que os diversos tipos de tarefas e processos apresentam quando integrados num sistemas de povoamento de um data warehouse. Com este trabalho pretendemos determinar a forma como conceber e desenvolver processos ETL mais eficientes em termos energéticos, com base na análise dos diversos componentes utilizados na sua implementação. A partir dessa análise será possível estabelecer uma tabela de eficiência energética para componentes ETL, permitindo, assim, aos arquitetos de sistemas ETL projetar e configurar sistemas de povoamento mais eficientes do ponto de vista energético. Nas próximas secções apresentaremos uma breve exposição de trabalhos relacionados com o processo de investigação que desenvolvemos (secção 2), bem como apresentaremos e discutiremos o caso de estudo selecionado, os dois cenários de implementação prática que levámos a cabo e os resultados alcançados, dando particular relevância, obviamente, à análise dos consumos de energia realizados pelos diversos componentes ETL integrados no sistema que implementámos (secção 3). Por último (secção 4) apresentamos algumas breves conclusões e apontamos algumas linhas de orientação para a realização de novos trabalhos no futuro.
2.
T
RABALHOR
ELACIONADOO tema da eficiência energética tem vindo a ser discutido e investigado por diferentes entidades nas mais diversas áreas do conhecimento. O domínio das tecnologias da informação e da comunicação também tem sido alvo deste tipo de trabalhos. Tanto ao nível do hardware como do software, tem-se vindo a verificar um aumento significativo do número de processos de investigação e da procura de técnicas e métodos que contribuam para a redução do consumo energético dos diversos tipos de componentes que integram os sistemas computacionais e, com isso, contribuir também para poupar recursos económicos e ambientais. Ao nível dos sistemas de software, por exemplo, o trabalho apresentado em (Carção et al., 2014) permitiu adaptar a técnica de localização de falhas para identificar quais as porções de código responsáveis por um maior consumo energético, tornando possível a partir dessa informação reformular o código de forma a se tornar energeticamente mais eficiente. Outro exemplo relevante de trabalhos nesta área é aquele que foi apresentado em (Couto et al., 2014) no qual se descreveu o desenvolvimento de
15ª Conferência da Associação Portuguesa de Sistemas de Informação (CAPSI 2015) 463
uma técnica para detetar consumos anómalos de energia em aplicações Android. Estes dois trabalhos, em particular, estão relacionados com a instrumentação de código em sistemas de software e indiciam claramente que a problemática do consumo energético está cada vez mais presente nos diferentes domínios das tecnologias de informação e comunicação. Outra das áreas em que encontramos alguns trabalhos de relevo neste domínio foi a dos centros de dados. Vejamos, por exemplo, o trabalho apresentado em (Sitaram et al., 2015), no qual se relevou a poupança de recursos energéticos através da criação de um algoritmo de alocação, que toma em consideração a eficiência energética bem como a disponibilidade dos diversos recursos do sistema, não criando pontos de falha, e, como tal, contribuindo para um menor consumo energético.
Também existem alguns trabalhos relacionados com a investigação e o desenvolvimento de metodologias específicas para o cálculo do consumo energético de queries em sistemas de gestão de bases de dados. O relatório Claremont (Agrawal et al., 2008) é um desses casos, tendo sido uma das primeiras abordagens ao consumo de energia no domínio das bases de dados. Segundo este relatório, na idealização e concepção de um sistema de gestão de bases de dados, é importante ter em consideração o consumo de energia efetuado nas suas diversas tarefas. Mais tarde, a seguir a este relatório, surgiram outros processos de trabalho que tomaram em consideração também essas mesmas preocupações (Lang et al., 2009) (Xu et al., 2010) (Lang et al., 2011). Contudo, todos estes trabalhos apenas se focaram em questões de hardware. Em termos de software, só em (Xu et al., 2010) é que encontrámos uma solução para redesenhar o kernel de um SGBD de forma a que este consumisse menos energia. Mais tarde, em (Kunjir et al., 2012) encontramos algumas outras alternativas para reduzir o pico do consumo de energia em sistemas de gestão de bases de dados. Mais recentemente, em (Gonçalves et al., 2014) foi apresentado um trabalho de avaliação sobre o consumo de energia de queries num ambiente convencional de um sistema de gestão de bases de dados. Nesse trabalho, os autores redesenharam o plano de execução de uma query produzido por um motor de bases de dados de forma a que nele pudesse ser incluído informação pertinente sobre o consumo de energia da query, dando particular relevância ao consumo efetuado em cada um das operações mais elementares que foram realizadas na satisfação da query e, consequentemente, determinar o seu consumo total de energia – a esses novos planos foi atribuída a designação de planos de consumo energético.
3.
A
VALIAÇÃO DO CONSUMO DE UMS
ISTEMAETL
3.1. O Consumo de Energia em Sistemas ETL
A crescente preocupação que atualmente se verifica relativamente aos consumos energéticos em ambientes de centros de dados tem conduzido, também, a um aumento dos processos de investigação e desenvolvimento nesse domínio. Tanto em termos de hardware como de software, várias são as iniciativas que têm vindo a ser promovidas e concretizadas. Porém, naquilo que se relaciona com o
15ª Conferência da Associação Portuguesa de Sistemas de Informação (CAPSI 2015) 464 projeto e desenvolvimento de sistemas ETL, até à data, e com base naquilo que até hoje conseguimos apurar, a investigação de técnicas e métodos para avaliar o consumo energético de um sistema ETL são inexistentes. Tal circunstância incentivou-nos a desenvolver um processo de investigação e desenvolvimento que abordasse, em particular, o consumo de energia de um sistema ETL, tomando em consideração cada um dos elementos operacionais (componentes ETL) que são utilizados na sua implementação. A experiência adquirida em trabalhos anteriores no domínio da eficiência energética em sistemas de software (Gonçalves et al., 2014) (Couto et al., 2014), garantiu-nos as bases mais essenciais para iniciar e desenvolver esse trabalho, investigando a forma como poderíamos definir uma forma de avaliar efetivamente o consumo de um sistema ETL. Com isto complementaríamos os atuais métodos e técnicas para a garantia de desempenho de um sistema, que durante muito tempo foi a principal preocupação dos arquitetos e engenheiros de sistemas de ETL, com mais valor, assegurando assim implementações mais eficientes, tanto em desempenho como em consumo de energia.
Os sistemas ETL são os maiores responsáveis pelo consumo de recursos computacionais num sistema de data warehousing. Tais recursos computacionais têm, obviamente, uma tradução direta para recursos energéticos. Assim, a possibilidade de medir o consumo energético de um sistema ETL permitir-nos-á comparar e analisar diferentes implementações para um mesmo sistema, tendo em conta a sua eficiência energética, avaliada a partir dos consumos de energia dos seus diversos componentes. Dessa forma poderemos, também, decidir por esta ou por aquela implementação de acordo com o seu consumo energético. Por exemplo, existem processos ETL específico que são vulgarmente utilizados na implementação de sistemas de povoamento de data warehouses. Referimo-nos a processos relacionados com a captura de dados modificados em fontes de informação, a verificação e garantia da qualidade de dados, a substituição encadeada de chaves operacionais, a atualização de tabelas de dimensão com variação ou o carregamento intensivo de dados. Se para um dado processo ETL puder ser realizada uma implementação energeticamente mais eficiente que uma outra qualquer, é possível optar por uma implementação com maiores ganhos energéticos (em detrimento, por exemplo, de uma implementação mais eficiente em termos de desempenho), diminuindo o consumo de energia correspondente, bem como os custos de manutenção do próprio sistema de data warehousing.
3.2. A Substituição Encadeada de Chaves Operacionais
Para podermos fazer a avaliação do consumo de energia de um sistema ETL num cenário de aplicação real escolhemos um caso bastante prático relacionado com um dos processos mais vulgares que usualmente podemos encontrar num sistema de povoamento de um data warehouse: a substituição encadeada de chaves operacionais – surrogate key pipelining. Basicamente, este processo tão particular permite fazer a conversão de chaves provenientes dos sistemas operacionais fonte por outras chaves correspondentes. Estas últimas são comummente designadas por chaves de substituição. Estas chaves
15ª Conferência da Associação Portuguesa de Sistemas de Informação (CAPSI 2015) 465 artificiais incorporam os esquemas das tabelas de dimensão, acolhendo valores inteiros, únicos, sequenciais e sem qualquer carga semântica associada, que são utilizados, entre outras coisas, como base para a conciliação de valores referentes a uma mesma entidade, para sustentar a realização de processos de atualização de dimensões com variação, ou para facilitar a realização de processos de junção em data warehouses. Na Figura 1 apresentamos uma versão simplificada do processo de definição e mapeamento de uma chave de substituição.
A importância deste tipo de chaves, ao invés das ditas chaves operacionais (frequentemente referidas também como chaves naturais), reside no facto destas garantirem identificadores inequívocos para registos de uma tabela de um data warehouse. Quando no povoamento de um data warehouse estão envolvidas mais do que uma fonte de informação, mais do que um sistema operacional, é vulgar ocorrerem diversos conflitos entre as chaves operacionais de diferentes sistemas, não só causados por valores repetidos como também por valores antagónicos ou inconsistentes. Como tal, estas chaves têm que ser substituídas aquando da sua “migração” para o data warehouse. Além disso, num data warehouse as chaves das tabelas devem ser desprovidas de inteligência, de significado. As chaves de substituição garantem isso, quando substituem as chaves operacionais em simples sequências de números inteiros (se possível pequenos). Para reforçar um pouco mais a necessidade da utilização de chaves de substituição, está também o facto de que, ocasionalmente, num contexto empresarial, os valores das chaves operacionais realmente mudarem ao longo do tempo, por este ou por aquele motivo. Num data warehouse não é nada “boa” a prática de modificar os valores das chaves numa tabela de dimensão ou numa tabela de factos. Usualmente, em casos como estes, são geradas novas chaves de substituição e estabelecidos os relacionamentos que garantam a ligação entre os diversos valores envolvidos.
Figura 1 – Atribuição de chaves de substituição.
3.3. Um Processo de Substituição Encadeada de Chaves Operacionais
Um processo de substituição encadeada de chaves operacionais pode ser implementado de diferentes formas, com base na natureza do próprio processo e das chaves envolvidas como também dos resultados pretendidos – o tipo de chave de substituição que se pretende aplicar. Na Figura 2 podemos
15ª Conferência da Associação Portuguesa de Sistemas de Informação (CAPSI 2015) 466 ver uma versão bastante simplificada deste processo. No caso de estudo que escolhemos, a implementação do processo de substituição foi realizada recorrendo a uma ferramenta de ETL bastante conhecida - o Kettle (Kettle, 2015) ou Pentaho Data Integration - e envolveu a implementação de duas soluções distintas para o processo de substituição referido.
Figura 2 – A substituição encadeada de chaves operacionais.
A primeira implementação do sistema ETL – versão A – aborda a questão da substituição encadeada de chaves operacionais da forma mais habitual. Nesta versão, o processo de substituição atua registo a registo e, para cada um deles, identifica as chaves operacionais a substituir, a partir de uma configuração base previamente estabelecida, e, chave a chave, vai verificando se existe ou não já uma chave de substituição atribuída. Para isso o processo utiliza, para cada chave operacional envolvida, uma tabela de lookup específica. Estas tabelas são estruturas temporárias para suporte ao mapeamento de chaves (e por vezes de outra informação necessária para a conciliação e garantia da qualidade de dados envolvidos no povoamento). Assim, caso a tabela de lookup em causa contenha um valor de substituição para o valor da chave operacional em questão, o processo faz a sua substituição pelo seu correspondente valor de substituição (surrogate key). Num processo de implementação real, caso não existisse um valor de substituição, o processo faria a geração de uma nova chave de substituição, armazenando-a na tabela de lookup correspondente, substituindo de seguida a chave operacional. De forma a simplificar um pouco o nosso caso de estudo e garantir a regularidade da execução do processo (não tratando exceções ou situações de erro, por exemplo), a parte da geração de chaves de substituição não foi considerada. Assumimos, somente, que todas as chaves de substituição deveriam estar garantidas no momento da execução do sistema ETL. Todavia, aplicámos um processo de tratamento de exceções, comum a todos os casos, que trata de situações nas quais se verifique a não existência de uma chave de substituição, criando um procedimento de quarentena, algo bastante típico em sistemas de povoamento de data warehouses.
15ª Conferência da Associação Portuguesa de Sistemas de Informação (CAPSI 2015) 467 Figura 3 – Implementação do processo de substituição encadeada de chaves operacionais (versão A).
Na Figura 3, podemos observar o package Kettle que foi desenvolvido para acolher a primeira versão do processo que acabámos de descrever. Nela, facilmente identificamos a forma como o processo de substituição encadeada de chaves operacionais acontece. Num primeiro componente (Table Input – ‘PreFactTable’) é realizada a leitura dos registos que temos que processar. São registos típicos de uma tabela de factos, aqueles que contêm as chaves operacionais (três atributos) cujos valores, assumimos, devem ser substituídos. De seguida, o processo inicia as tarefas de substituição de chaves operacionais, realizando sequencialmente três operações de lookup, uma para cada chave operacional, utilizando três componentes DB Lookup encadeados (‘Lookup A’, ‘Lookup B’ e ‘Lookup C’) para fazer, respetivamente, as necessárias conversões dos valores contidos em três atributos: A, B e C. Em qualquer um destes componentes, e seguindo o que expusemos anteriormente, caso não exista um valor de substituição para a chave operacional em tratamento, o registo dessa chave é copiado para uma tabela de quarentena utilizando um componente Table Output. Desta forma assinalamos e guardamos os registos cujos valores das chaves operacionais contêm valores incorretos, possibilitando a sua posterior análise e recuperação, se possível. Os restantes componentes Kettle que figuram na implementação desta primeira versão, nomeadamente Select Values (‘Remove Values B’, ‘Remove Values C’ e ‘Change Values’) e Write to Log (‘QuarantineLog’) foram utilizados respetivamente para fazer a seleção de atributos num dado registo e para escrever um determinado evento num dado ficheiro de log.
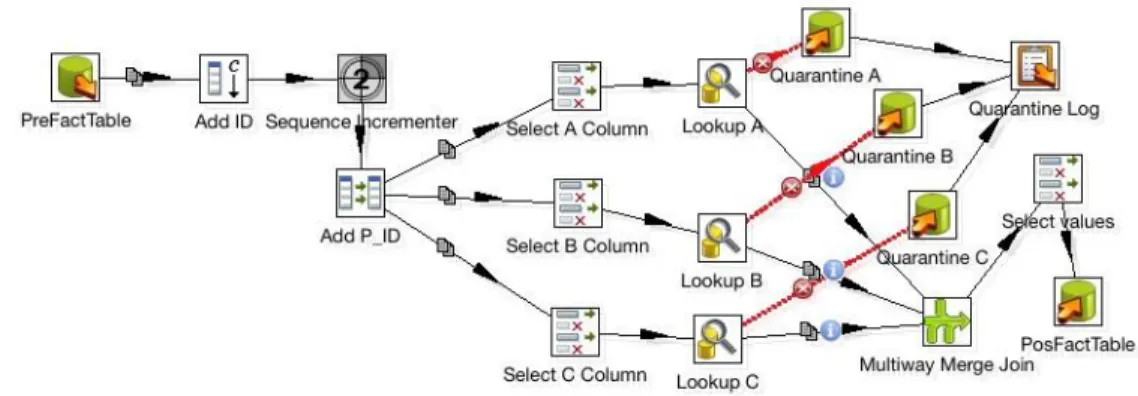
A versão B (Figura 4) da implementação do processo de substituição encadeada de chaves operacionais é, de certa forma, mais elaborada que a versão A. Uma diferença notória é o número de componentes ETL que envolve na sua implementação, que é claramente superior ao da versão A. Isso deveu-se ao tipo de implementação que foi realizado, uma vez que pretendíamos com esta versão alternativa implementar um processo de substituição de chaves paralelo, no qual várias chaves operacionais poderiam ser substituídas simultaneamente, em contraposição à versão A que, como
15ª Conferência da Associação Portuguesa de Sistemas de Informação (CAPSI 2015) 468 referimos anteriormente, processa os registos e a substituição das chaves de forma sequencial, em mode pipelining. Na versão B não temos de facto um pipelining. Mas a forma como o sistema está implementado permite-lhe ter um comportamento perfeitamente equivalente, em termos de resultado refira-se, à da versão A.
Figura 4 – Implementação do processo de substituição encadeada de chaves operacionais (versão B).
Vejamos então como é que a versão B atua. Através da Figura 4 vemos que o processo ETL se inicia da mesma forma que na versão A, com a leitura dos registos a processar. Porém, a partir daqui, o processo desenrola-se de forma bastante distinta. As três tarefas seguintes, envolvendo, respetivamente, componentes ETL Add Constant (‘Add Id’), Add Sequence (‘Sequence Incremeter’) e Set Field Value (‘Add P_Id’), preparam os registos de forma a que os atributos das chaves operacionais sejam separados para serem processados em paralelo nos passos seguintes, de acordo com cada uma das tabelas de lookup envolvidas no processo. Após a separação dos atributos, são despoletados três tarefas de substituição de chaves em paralelo, envolvendo dois tipos de componentes, ETL Select Values e DB Lookup -, uma para cada um dos atributos envolvidos (A, B e C). Nesta tarefas o processo ocorre de forma similar ao seu equivalente na versão A, o mesmo acontecendo para os casos dos valores de atributos que vão para quarentena. Depois disso, os atributos que foram anteriormente separados voltam a ser reunidos por um componente ETL Multiway Merge Join, sendo o registo agora restaurado com as chaves de substituição já atribuídas. Por fim, os registos processados são colocados numa tabela de factos no data warehouse. Os restantes componentes Kettle que figuram na implementação desta segunda versão, nomeadamente Select Values (‘Select Values’) e Write to Log (‘QuarantineLog’) fazem a seleção de atributos num dado registo e a escrita de um determinado evento num ficheiro de log. Estes componentes desempenham um papel muito semelhante àquele que realizaram na versão A.
15ª Conferência da Associação Portuguesa de Sistemas de Informação (CAPSI 2015) 469 Tabela 1 – Relação dos componentes ETL usados nas diferentes versões do processo ETL implementado.
Na tabela 1 podemos observar os diferentes componentes ETL que foram utilizados nas implementações das duas versões do de ETL. A designação de cada um desses componentes está apresentada de acordo com a nomenclatura seguida pela ferramenta de ETL que utilizámos. As diferenças que se verificam entre as duas implementações realizadas podem ser facilmente identificadas através dos componentes que foram utilizados em cada uma delas.
3.4. Avaliação do Consumo de Energia
De forma a garantir que a avaliação do consumo de energia do processo de povoamento em causa fosse mais correta, não se resumindo simplesmente a uma comparação de implementações, projetámos e desenvolvemos seis cenários de teste distintos, com objetivos diferentes, de forma a obter várias medições do consumo e do desempenho das duas versões implementadas para o processo ETL em causa. Para cada cenário de teste considerámos diferentes volumes de dados. De teste para teste, aumentámos significativamente o número de registos com chaves operacionais para substituir. Além disso, criámos tabelas de lookup com diferentes tamanhos e disposições de armazenamento, garantindo tais características no momento do seu povoamento inserindo os seus registos de uma forma ordenada ou de uma forma aleatória conforme as características de pesquisa que queríamos atribuir às tabelas. Assim, as tabelas de lookup, para o processamento dos valores dos atributos A, B e C, foram povoadas, respetivamente, com 10, 100 e 10 000 registos, inseridos com base nas modalidades anteriormente referidas, criando os correspondentes dados para suporte aos cenários de teste t1, t2 e t3.
O volume de dados a processar pelo sistema ETL implementados foi constante para todos esses cenários de teste, tendo sido fixado em 243 000 registos. De salientar que, nem todas as chaves operacionais integradas nesses registos tinham uma chave de substituição na tabela de lookup
15ª Conferência da Associação Portuguesa de Sistemas de Informação (CAPSI 2015) 470 correspondente. Como tal, o número de registos que de facto chegarão ao data warehouse será inferior aos 243 000 registos iniciais. Cada cenário de teste foi executado cinquenta vezes para cada uma das implementações realizadas (versão A e versão B). Na prática isso correspondeu à repetição dos testes cinco vezes, tendo sido realizadas em cada uma das realizações dos testes dez execuções da implementação do sistema ETL em questão. Como planeado, durante a realização dos diversos cenários de teste foram coletados os valores dos consumos de energia realizados por cada um dos
componentes ETL integrados nas duas versões do sistema.
Tabela 2 – Energia consumida (em Joules) por cada componente integrado na versão A do processo ETL.
Após a execução dos vários cenários de testes, para ambas as implementações do sistema ETL, procedemos à análise dos dados de consumo recolhidos. Nas Tabelas 2 e 3 podemos observar uma relação dos consumos realizados pelos diversos componentes ETL utilizados, respetivamente, na versão A e na versão B do sistema ETL. Nessas tabelas, os valores de consumo estão organizados segundo cada um dos componentes ETL utilizados – Table Input, Table Output, DB Lookup, Select Values, etc. – e de acordo com o modo como os dados estavam organizados nas tabelas de lookup – em modo aleatório ou ordenado. De seguida, nas Figuras 5 e 6, podemos ver, em gráfico, respetivamente, o resultado da análise do consumo energético e o resultado da análise de desempenho do sistema, com base nos valores coletados durante os testes realizados.
Tabela 3 – Energia consumida (em Joules) por cada componente integrado na versão B do processo ETL.
Uma das conclusões que podemos retirar, de imediato, através da análise da Tabela 2 e da Tabela 3, é que, em termos comparativos, a versão A do processo de substituição encadeada de chaves operacionais é energeticamente mais eficiente do que a versão B. Para qualquer um dos cenários de
15ª Conferência da Associação Portuguesa de Sistemas de Informação (CAPSI 2015) 471 teste - t1, t2 e t3 - a versão B é claramente mais consumidora que a versão A. Quanto à questão do
consumo energético de ambas as versões é de notar que, para o cenário de teste t3, que acolheu uma
tabela de lookup com 10 000 registos, com os registos ordenados, há um consumo de energia excessivo quando comparado com aquilo que foi consumido com a configuração aleatória dos registos. Em termos de desempenho é possível observar que a versão A tem um melhor desempenho do que a versão B, demorando menos tempo a executar o processo ETL.
Figura 5 – Consumo energético geral do processo ETL.
O consumo excessivo de energia no cenário de teste t3 sequencial, para ambas as versões, é
explicado pelo tempo global que o processo demora a executar. O cálculo da energia é efetuado recorrendo à multiplicação da potência elétrica pela quantidade de tempo em segundos. Assim, se, neste caso, o tempo de execução aumentar, a energia consumida durante o processo de substituição encadeada de chaves naturais também aumenta. De uma forma geral, a versão A do processo ETL é, sem dúvida, muito mais eficiente do que a versão B, quer em termos de consumo energético, quer em termos de desempenho. Apesar destes resultados, é necessário avaliar um maior número de processos ETL para que seja possível criar sistemas energeticamente mais eficientes e definir, por fim, uma tabela de categorização de consumos de energia para componentes ETL. Porém, o facto de podermos medir e avaliar quantitativamente o consumo energético de um determinado processo ETL é claramente uma mais valia para qualquer projeto de implementação de um sistema de povoamento de um data warehouse, uma vez que torna possível a opção por diferentes alternativas de implementação, nas quais se ponderará o peso de uma solução mais eficiente em termos de desempenho e uma solução mais eficiente em termos de consumo de energia.
15ª Conferência da Associação Portuguesa de Sistemas de Informação (CAPSI 2015) 472 Figura 6 – Desempenho geral em segundos do processo ETL.
4.
C
ONCLUSÕES ET
RABALHOF
UTURONeste artigo apresentámos uma avaliação energética para componentes ETL, com base na comparação de duas implementações distintas de um processo de povoamento de um data warehouse – a substituição encadeada de chaves operacionais. Este tipo de avaliação permitiu- nos conhecer o consumo de energia de um processo ETL, bem como a dos diversos componentes que realizam as tarefas implementadas. É muito interessante verificar o impacto que diferentes tipos de implementações para um mesmo caso de estudo têm em termos de consumo de energia. Isto é algo que há bem pouco tempo não se pensaria fazer. Avaliar, em particular, o consumo de energia de um sistema de software pensava-se ser irrelevante quando comparado a outro tipo de sistema, em particular os sistemas de hardware. Porém, em grandes sistemas computacionais, como é o caso dos sistemas de data warehousing, mesmo o consumo de pequenos componentes causa alguma diferença quando tais componentes são utilizados em grande escala. As pequenas diferenças, aqui, fazem realmente a diferença.
As preocupações de um qualquer administrador de um sistema de povoamento sempre estiveram direcionadas para a implementação e execução dos sistemas implementados, para análise da sua correção e desempenho. Todavia, hoje, com os sistemáticos alertas sobre os elevados consumos de energia dos sistemas computacionais, em especial os relacionados com a implementação de grandes centros de dados, e com a consequente degradação dos recursos naturais conjugada com a escassez de recursos económicos, tais preocupações chegaram também aos sistemas de povoamento de data warehouses. Não é pois de estranhar a grande cadência com que estão a aparecer estudos neste domínio. Apesar de existirem várias técnicas para obter ou determinar os consumos de energia, por exemplo, de coisas tão pequenas como uma query sobre uma base de dados, a obtenção de dados relativos a consumos energéticos em processos de ETL é praticamente inexistente. Neste trabalho
15ª Conferência da Associação Portuguesa de Sistemas de Informação (CAPSI 2015) 473 fizemos esse estudo. A avaliação do consumo de energia de um processo de substituição de chaves operacionais, permitiu-nos abrir alguns horizontes relativamente à disponibilização de informação referente aos consumos energéticos para componentes ETL.
De facto, verificamos que este tipo de estudos tem grande interesse e viabilidade. A dimensão dos sistemas atuais requer algum cuidado e preocupação na forma como os desenvolvemos e que componentes usamos ou deixamos de usar na sua implementação tendo em conta os seus requisitos em termos de consumo de energia. Tendo em conta alguns aspetos de escala dos sistemas computacionais, uma análise minuciosa sobre o consumo de energia dos seus componentes pode conduzir, de facto, a uma poupança significativa de energia e, como tal, contribuir para a consequente poupança de recursos naturais. Futuramente, pretendemos construir um repositório com toda a informação energética referente a processos comuns de ETL, bem como a relativa aos diversos componentes ETL que utilizam, para diferentes ferramentas comerciais atualmente disponíveis no mercado, alargando o espectro de aplicação do atual estudo para além do contexto de exploração da ferramenta Kettle. Através da informação do consumo dos componentes ETL, pretendemos construir uma tabela de eficiência energética, para que, aquando da fase de implementação de um processo ETL seja possível substituir componentes bastante consumidores, por outros com as mesmas funcionalidades, mas energeticamente mais eficientes.
R
EFERÊNCIASAgrawal,R., Ailamaki,A., Bernstein,P.A., Brewer,E.A., Carey,M.J., Chaudhuri,S., Doan, A., Florescu, D., Franklin, M.J., Garcia-Molina, H., Gehrke, J., Gruenwald, L., Haas, L.M., Halevy, A.Y., Hellerstein, J.M., Ioannidis, Y.E., Korth, H.F., Kossmann, D., Madden, S., Magoulas, R., Ooi, B.C., O’Reilly, T., Ramakrishnan, R., Sarawagi, S., Stonebraker, M., Szalay, A.S., Weikum, G.: The claremont report on database research. SIGMOD Rec. 37(3), 9–19, September, 2008. Beloglazov, A., Abawajy, J., Buyya, R., “Energy-aware resource allocation heuristics for efficient
management of data centers for cloud computing”. Future Generation Computer Systems, Special Section: Energy efficiency in large-scale distributed systems, 28(5), 755– 768, 2012.
Carção, T., “Measuring and visualizing energy consumption within software code”. In: Visual Languages and Human-Centric Computing (VL/HCC), 2014 IEEE Symposium on, 181–182, July, 2014.
Couto, M., Carção, T., Cunha, J., Fernandes, J.P., Saraiva, J., “Detecting anomalous energy consumption in android applications”. In Pereira, F.M.Q., ed.: Programming Languages - 18th Brazilian Symposium, SBLP 2014, Maceio, Brazil, October 2-3, 2014. Proceedings. Volume 8771 of Lecture Notes in Computer Science., Springer, 77–91, 2014.
Gonçalves, R., Saraiva, J., Belo, O., “Defining Energy Consumption Plans for Data Querying Processes”, In Proceedings of 2014 IEEE Fourth International Conference on Big Data and Cloud Computing (BdCloud 2014), pages 641-647, IEEE computer Society, Sidney, Australia, 2014. Green Grid, The Green Grid, 2015. Available at: http://www.thegreengrid.org/ [Accessed June 15,
2015].
Harizopoulos, S., Shah, M.A., Meza, J., Ranganathan, P., “Energy efficiency: The new holy grail of data management systems research”. In: CIDR 2009, Fourth Biennial Conference on Innovative Data
15ª Conferência da Associação Portuguesa de Sistemas de Informação (CAPSI 2015) 474 Systems Research, Asilomar, CA, USA, January 4-7, 2009, Online Proceedings, www.cidrdb.org, 2009.
Kettle, Pentaho, “Pentaho Data Integration”, 2015. Available at: http://www.pentaho.com/product/data-integration [Accessed March 16, 2015].
Kliazovich, D., Bouvry, P., Khan, S.U., “Greencloud: a packet-level simulator of energy-aware cloud computing data centers”. The Journal of Supercomputing, 62(3), 1263–1283, 2012.
Kunjir, M., Birwa, P.K., Haritsa, J.R., “Peak power plays in database engines”. In Rundensteiner, E.A., Markl, V., Manolescu, I., Amer-Yahia, S., Naumann, F., Ari, I., eds.: 15th International Conference on Extending Database Technology, EDBT ’12, Berlin, Germany, March 27-30, 2012, Proceedings, ACM, 444–455, 2012.
Lang, W., Kandhan, R., Patel, J.M., “Rethinking query processing for energy efficiency: Slowing down to win the race”. IEEE Data Eng. Bull. 34(1), 12–23, 2011.
Lang, W., Patel, J.M., “Towards eco-friendly database management systems”. In: CIDR 2009, Fourth Biennial Conference on Innovative Data Systems Research, Asilomar, CA, USA, January 4-7, 2009, Online Proceedings, www.cidrdb.org, 2009.
Poess, M., Nambiar, R., “Tuning servers, storage and database for energy efficient data warehouses”. In Proceedings of 2010 IEEE 26th International Conference on Data Engineering (ICDE), 1006– 1017, March, 2010.
Rasmussen, N., “Determining total cost of ownership for data center and network room infrastructure”. Technical report, Schneider Electric Data Center Science Center, 2011.
Sitaram, D., Phalachandra, H., Gautham S, Swathi, H., Sagar, T., “Energy efficient data center management under availability constraints”. In 9th Annual IEEE International Systems Conference (SysCon), 377–381, April 2015.
Xu, Z., Tu, Y., Wang, X., “Exploring power-performance tradeoffs in database systems”. In Li, F., Moro, M.M., Ghandeharizadeh, S., Haritsa, J.R., Weikum, G., Carey, M.J., Casati, F., Chang, E.Y., Manolescu, I., Mehrotra, S., Dayal, U., Tsotras, V.J., eds.: Proceedings of the 26th International Conference on Data Engineering, ICDE 2010, March 1-6, 2010, Long Beach, California, USA, IEEE, 485–496, 2010.