Braz. J. of Develop., Curitiba, v. 5, n. 12, p. 29226-29242 dec 2019 . ISSN 2525-8761
PBIL AutoEns: uma Ferramenta de Aprendizado de Máquina
Automatizado Integrada à Plataforma Weka
PBIL AutoEns: an Automated Machine Learning Tool integrated to the
Weka ML Platform
DOI:10.34117/bjdv5n12-082
Recebimento dos originais: 15/11/2019 Aceitação para publicação: 06/12/2019
Cephas Alves da Silveira Barreto
Doutorando em Ciências da Computação pela Universidade Federal do Rio Grande do Norte (UFRN)
Instituição: Universidade Federal do Rio Grande do Norte Endereço: Av. Senador Salgado Filho, 3000, Natal-RN
E-mail: cephasax@gmail.com
Anne Magaly de Paula Canuto
Doutora em Engenharia Eletrônica pela Universidade de Kent, Inglaterra Instituição: Universidade Federal do Rio Grande do Norte (UFRN)
Endereço: Av. Senador Salgado Filho, 3000, Natal-RN E-mail: anne@dimap.ufrn.br
João Carlos Xavier-Júnior
Doutor em Engenharia Elétrica pela Universidade Federal do Rio Grande do Norte (UFRN) Instituição: Universidade Federal do Rio Grande do Norte
Endereço: Av. Senador Salgado Filho, 3000, Natal-RN E-mail: jcxavier@imd.ufrn.br
Antonino Feitosa-Neto
Doutor em Sistemas e Computação pela Universidade Federal do Rio Grande do Norte (UFRN)
Instituição: Universidade Federal do Rio Grande do Norte Endereço: Av. Senador Salgado Filho, 3000, Natal-RN
E-mail: antonino_feitosa@yahoo.com.br
Douglas Felipe Alves Lima
Graduando em Tecnologia da Informação pela Universidade Federal do Rio Grande do Norte (UFRN)
Instituição: Universidade Federal do Rio Grande do Norte Endereço: Av. Senador Salgado Filho, 3000, Natal-RN
E-mail: douglas.felipelima18@gmail.com
Ranna Raabe Fernandes da Costa
Graduanda em Tecnologia da Informação pela Universidade Federal do Rio Grande do Norte (UFRN)
Braz. J. of Develop., Curitiba, v. 5, n. 12, p. 29226-29242 dec 2019 . ISSN 2525-8761 Endereço: Av. Senador Salgado Filho, 3000, Natal-RN
E-mail: ranna.raabe@gmail.com
RESUMO
O Aprendizado de Máquina (AM) tem se popularizado nos últimos anos como uma abordagem eficiente para resolução de problemas. Existem na atualidade centenas de métodos de classificação, por exemplo, o que torna praticamente impossível analisar todos os possíveis resultados, dado que além de existirem muitos métodos, são muitas as configurações para cada um desses métodos. A partir desse problema, surgiu o conceito de Aprendizado de Máquina Automatizado (AutoML), uma técnica que busca entre diversas soluções, a melhor possível para um determinado problema, sem a necessidade de interferência humana. Este trabalho apresenta o PBIL AutoEns, uma ferramenta de AutoML que utiliza a API da plataforma WEKA para buscar soluções (modelos) dentre um grande conjunto de possibilidades. O PBIL AutoEns foi comparado com o Random Forest e XGBoost (métodos de comitês) e o MLP (classificador base). Nessa comparação, usamos uma medida de precisão preditiva muito forte (F-measure) para analisar o desempenho de classificação de todos os quatro métodos em 21 base de dados.
Palavras-chave: Aprendizado de Máquina Automatizado; Algoritmos Evolutivos;
Comitês de Classificadores.
ABSTRACT
Machine Learning (ML) has become very popular recently as a robust approach to solve problems. There are hundreds of methods for classification tasks, for instance which makes almost impossible to analyze every possible result of each one of them. On top of that, there are many hyper-parameter settings for each one of these methods. Aiming to tackle this search problem, the concept of Automated Machine Learning (AutoML) has been proposed as a technique that searches for a good model (base classifier or ensemble) among many possible methods for a given problem without human interaction. This work presents the PBIL AutoEns, an AutoML tool designed to be used over the WEKA’s machine learning platform. The PBIL AutoEns was compared against Random Forest and XGBoost (strong ensemble methods), and MLP (robust base classifier). We used a very strong predictive accuracy measure (F-measure) to analyse the classification performance of all four methods over 21 datasets.
Keywords: Automated Machine Learning; Evolutionary Algorithms; Classifier
Ensembles.
1. INTRODUÇÃO
A classificação é uma tarefa de Aprendizado de Máquina muito popular, em que cada instância (objeto sendo classificado) consiste em um conjunto de recursos preditivos e uma variável de classe nominal ou discreta. Em geral, o objetivo de um algoritmo de classificação é aprender um modelo de classificação que pode ser usado para prever o valor
Braz. J. of Develop., Curitiba, v. 5, n. 12, p. 29226-29242 dec 2019 . ISSN 2525-8761 da classe (rótulo) de uma nova instância, com base nos valores dos recursos dessa instância [Faceli et al. 2015].
Várias décadas de pesquisa na área de classificação de dados produziram um grande número de algoritmos [Kotsiantis et al. 2007]. Porém, na prática nenhum desses algoritmos é o melhor para todos as bases de dados possíveis, pois o desempenho preditivo de um algoritmo é fortemente dependente das características da base de dados de entrada [Brazdil et al. 2009], bem como das configurações de hiper-parâmetros do algoritmo. Isso cria um problema muito difícil de como escolher o melhor algoritmo de classificação para a base de dados disponível. Além disso, a busca do melhor algoritmo e sua configuração pode se tornar muito demorada [Ho and Pepyne 2002].
Surgiu nos últimos anos uma abordagem promissora para lidar com a questão da escolha automática dos melhores classificadores e seus parâmetros de configuração [Feurer et al. 2015; Olson et al. 2016; Thornton et al. 2013] chamada de Aprendizado de Máquina Automatizado (do inglês Automated Machine Learning - AutoML). A grande maioria das abordagens utilizadas em AutoML fazem uso de técnicas de otimização na busca das melhores soluções.
Além de classificadores "simples'', os métodos de AutoML também podem utilizar classificadores do tipo comitê (Ensemble). Nesse tipo de método, dois ou mais classificadores simples são usados de forma conjunta para obtenção de um modelo que classifique os dados de forma mais precisa. O fato de utilizar comitês na classificação de problemas, em geral, melhora a acurácia de classificação dos sistemas, mas por outro lado, aumenta substancialmente o espaço de busca [Mitchell 1997].
Tendo como base esse contexto, foi proposto em 2018 um método de AutoML chamado PBIL AutoEns [Xavier-Júnior et al. 2018]. Esse método foi apresentado como sendo uma ferramenta integrada à plataforma de Aprendizado de Máquina WEKA [Hall et al. 2009], e também mostrou uma análise comparativa (acurácia) com outro método de AutoML (Auto-WEKA [Thornton et al. 2013]). Contudo, não houve uma análise mais profunda com relação a utilização de classificadores robustos (e.g. MLP e SVM) ou métodos de comitês (e.g. Random Forest e XGBoost).
A partir dessa lacuna deixada pelo trabalho supracitado, este trabalho visa fazer uma análise comparativa entre quatro métodos, sendo um classificador base (MLP), dois métodos de comitê (Random Forest e XGBoost) e um método de AutoML (PBIL AutoEns). Para tal, utilizaremos todas as bases reportadas no trabalho anterior e mais seis também
Braz. J. of Develop., Curitiba, v. 5, n. 12, p. 29226-29242 dec 2019 . ISSN 2525-8761 retiradas de repositórios abertos. Além disso, este trabalho também abordará o funcionamento do PBIL AutoEns seus parâmetros de configuração dentro da plataforma WEKA.
Nas próximas seções serão apresentados conceitos fundamentais para o entendimento deste trabalho (seção Conceitos Relacionados), serão apresentados e discutidos os trabalhos relacionados à esta pesquisa (seção Trabalhos Relacionados), a plataforma e os experimentos realizados serão detalhados nas seções Funcionamento do Método e Metodologia, respectivamente. Logo após, os resultados obtidos serão apresentados na seção Resultados Experimentais e, por fim, as considerações finais na seção Conclusão.
2. CONCEITOS RELACIONADOS
2.1 CLASSIFICAÇÃO
Em Aprendizado de Máquina, classificação é uma tarefa onde cada instância (objeto a ser classificado) é formada por um grupo de características preditivas e de uma classe. Como dito anteriormente, o objetivo de um algoritmo de classificação é aprender um modelo de classificação que seja capaz de determinar o valor de classe de uma nova instância, baseado nos valores de suas características [Faceli et al. 2015].
2.2 COMITÊS DE CLASSIFICAÇÃO
Comitês de Classificadores produzem um modelo de classificação utilizando um conjunto de classificadores, nesse contexto chamados de classificadores base. Os comitês, mais especificamente os de arquitetura paralela, realizam uma classificação em duas etapas: na primeira, o conjunto de classificadores utilizados pelo comitê recebe a base de dados e cada classificador base retorna a sua predição; na segunda, o comitê recebe as predições dos classificadores e as combina de forma a gerar uma predição única [Kuncheva 2004].
Os comitês de classificação podem combinar diferentes técnicas de classificação de modo que os acertos da maioria possam compensar os erros dos demais, gerando um ganho de desempenho na acurácia quando comparado com os membros individuais do comitê. Tal característica é denominada diversidade, sendo ela uma fator importante no desenvolvimento de comitês de classificação [Zhou 2012].
Braz. J. of Develop., Curitiba, v. 5, n. 12, p. 29226-29242 dec 2019 . ISSN 2525-8761 2.3 AUTO-ML
Métodos de Aprendizado de Máquina Automatizado (AutoML) são métodos que buscam e selecionam algoritmos de classificação e seus hiper-parâmetros de maneira automática, com o intuito de aumentar o desempenho sobre uma base de dados. Devido ao fato da existência de diversos algoritmos de classificação e cada um desses algoritmos possuírem limitações, é preferível o uso do melhor algoritmo de classificação existente. Entretanto, como não existe um classificador que abranja todo o domínio de problemas existentes [Ho and Pepyne 2002], e como existem diversos algoritmos com aplicações e configurações diferentes, utilizar Auto-ML como ferramenta pode simplificar o trabalho e auxiliar na resolução desse problema [Hutter et al. 2019].
2.4 ALGORITMOS DE ESTIMATIVA DE DISTRIBUIÇÃO (EDA)
Os Algoritmos Evolutivos (EAs) são um tipo de técnica de busca e otimização inspirada no princípio da seleção natural. Como técnicas de otimização, os EAs têm as vantagens de realizar uma pesquisa global no espaço de soluções candidatas (menos propensos a ficar preso em ótimo local do que uma busca gananciosa) e ser robusto ao ruído [Eiben et al. 2003; Freitas 2002].
Algoritmos de Estimativa de Distribuição (EDA) são um tipo de EA que explora o espaço de possíveis soluções, construindo e amostrando modelos probabilísticos explícitos de soluções candidatas promissoras [Larrañaga and Lozano 2001]. Os EDAs foram aplicados a vários tipos de tarefas de Aprendizado de Máquina, incluindo a seleção de atributos [Inza et al. 2002; Shelke et al. 2013] e classificação [Saeys et al. 2004; Yang et al. 2009].
Os EDAs geram e avaliam iterativamente uma população de soluções candidatas (indivíduos) para um problema. A população inicial é gerada com base na distribuição uniforme de todas as soluções possíveis. Uma vez computada a adequação de cada indivíduo, os indivíduos são classificados com base em seus valores de aptidão e um subconjunto das soluções mais promissoras (geralmente, 50% das melhores soluções) é selecionado. Então, um modelo probabilístico é construído com o objetivo de estimar a distribuição de probabilidade das soluções selecionadas. Uma vez que o modelo é construído, novas soluções são geradas por amostragem da distribuição codificada por este modelo. A adequação de cada novo indivíduo é avaliada e assim por diante. Esse processo
Braz. J. of Develop., Curitiba, v. 5, n. 12, p. 29226-29242 dec 2019 . ISSN 2525-8761 é repetido até que alguns critérios de encerramento sejam atendidos, como em outros tipos de EAs.
O algoritmo de Aprendizagem Incremental Baseada na População (Population Based Incremental Learning - PBIL) proposto por [Baluja and Caruana 1995] e revisado por [Zangari et al. 2017] é um tipo de EDA que desenvolve um vetor de probabilidade, onde cada componente vetorial representa a probabilidade desse componente ser selecionado para inclusão na criação de uma solução candidata. Os valores dos componentes do vetor são geralmente inicializados com uma probabilidade de 0,5. Então, a cada geração (iteração), uma população de indivíduos (soluções candidatas) é amostrada a partir do vetor de probabilidade com base em seus valores de probabilidade, e cada indivíduo é avaliado usando uma função de adequação (fitness). Assim, o vetor de probabilidade evolui gradualmente para componentes com valores de probabilidade mais próximos de 1 ou 0, dependendo se o componente foi ou não utilizado nas melhores soluções candidatas avaliadas ao longo das gerações.
3. TRABALHOS RELACIONADOS
3.1 SELEÇÃO AUTOMATIZADA DE MODELOS DE CLASSIFICAÇÃO
Alguns estudos apresentam abordagens interessantes para a automatização da criação de comitê de classificadores, tais como: [Wistuba et al. 2017], [Lacoste et al. 2014], [Lévesque et al. 2016]. É de suma importância frisar que, todas as três abordagens descritas pelos autores utilizam a otimização Bayesiana, muito comum nesse tipo de problema.
Das três abordagens, [Wistuba et al. 2017] propõe uma abordagem automática que gera comitês com várias camadas, onde a otimização Bayesiana seleciona classificadores e suas devidas configurações. Enquanto isso, [Lacoste et al. 2014] propõe uma extensão do Modelo Baseado em Otimização Sequencial (SMBO), onde o SMBO otimiza os comitês com base no método bootstrap, que seleciona subconjuntos, de modo aleatório, e assim realiza a validação dos dados de entrada. Por fim, [Lévesque et al. 2016] propõe construir comitês de tamanho fixo utilizando um algoritmo de hiperparâmetros que, de maneira resumida, a cada iteração otimiza a configuração de um classificador.
Braz. J. of Develop., Curitiba, v. 5, n. 12, p. 29226-29242 dec 2019 . ISSN 2525-8761 Os Algoritmos Evolutivos (EAs) têm sido escolhidos para uso em diversas áreas da computação por suas vantagens, como mostrar um desempenho devido à correção/aperfeiçoamento que é feita a cada execução. Ademais, outras vantagens dos EAs são consideradas nas pesquisas de [De Sá et al. 2017] e [Kordík et al. 2018].
No trabalho de [Kordík et al. 2018], os autores utilizam um algoritmo genético (GA) para procurar possíveis arquiteturas de comitês hierárquicos e otimizar seus hiper-parâmetros. Esse trabalho possui um foco maior na transferência de aprendizagem (meta-aprendizagem retirada dos classificadores). Enquanto isso, de modo simples, [De Sá et al. 2017] propõe um EA para buscar algoritmos diferentes de Classificação Multi-Label (MLC) e seus hiperparâmetros; e [De Sá et al. 2017] propõe um método para automatizar a seleção de algoritmos e métodos de pré-processamento de dados.
4. FUNCIONAMENTO DO MÉTODO
O método de AutoML é baseado no Algoritmo Population-Based Incremental Learning (PBIL) proposto por [Baluja and Caruana 1995] e revisado por [Zangari et al. 2017]. O utiliza tanto classificadores base como comitês de classificadores na busca por soluções de classificação para determinada base de dados, e se baseia em uma abordagem probabilística para encontrar o melhor classificador de forma automatizada. Para fins deste trabalho, uma solução é a representação de um classificador (e seus parâmetros de configuração) ou de um comitê de classificadores (e seus parâmetros de configuração - e.g. classificadores base e respectivas configurações).
O funciona como o descrito em [Xavier-Júnior et al. 2018] e segue a seguinte lógica:
1. Cada um dos n indivíduos (soluções candidatas) da população do pode representar
um comitê ou um classificador base. Todos os métodos são oferecidos pela plataforma WEKA. As possíveis opções são divididas em dois tipos: (a) métodos de comitê: Random Forest (RF), AdaBoost (ADA), Bagging (BAG), Random Committee (RC), Stacking (STA), Vote (VT); e (b) classificadores base: BayesNet (NET), Naive Bayes (NB), Multilayer Perceptron (MLP), Support Vector Machine (SMO), k-Nearest Neighbor (IBK), KStar (KST), Decision Tree (J48), Decision Table (DT), and Random Tree (RT). Todas as n soluções são avaliadas através de uma função de fitness calculada sobre o conjunto de validação.
Braz. J. of Develop., Curitiba, v. 5, n. 12, p. 29226-29242 dec 2019 . ISSN 2525-8761
2. Após o fim da primeira geração, as p% melhores soluções são utilizadas para
atualizar os vetores de probabilidade, favorecendo, dessa forma, a criação de novas soluções similares as melhores da primeira geração. Além disso, a taxa de aprendizado (t) também é utilizada na atualização dos vetores.
3. A melhor solução de cada geração é armazenada, para que ao final da execução do
PBIL AutoEns, determinada por um critério de tempo, seja escolhida a melhor solução entre todas as armazenadas.
É importante enfatizar que, a cada geração, a seleção das melhores p% soluções e a atualização dos vetores de probabilidade realizam uma espécie de direcionamento para que as próximas soluções geradas possam ter características mais semelhantes as soluções que obtiveram bons resultados. Neste sentido, a taxa de aprendizado (t) também é muito importante, pois: se for alta, pode tornar a convergência muito rápida e fazer o método ficar preso em um mínimo local; se for baixa, tornará a convergência uma questão mais demorada, o que pode inviabilizar convergência em termos de tempo, dado que o método também possui configurações relacionadas ao tempo de execução geral.
4.1 UTILIZAÇÃO DO NO WEKA
O foi integrado a plataforma WEKA e pode ser localizado na pasta dos Meta classificadores, que reúne todos os algoritmos de comitês de classificadores. Dessa forma, para acessá-lo basta escolher a aba Classify da Interface Gráfica do Usuário (do inglês - Graphic User Interface - GUI) do Weka. Depois, como pode ser visualizado na Figura 1, basta escolher a pasta meta, e dentro dela escolher o PBIL AutoEns.
Após ser selecionado, conforme pode ser visualizado na Figura 2, é importante que a opção de utilizar um conjunto de treinamento seja selecionada, pois o próprio algoritmo se encarregará de criar os três os conjuntos necessários (e.g. treinamento, validação e teste). Ainda nesta mesma (Figura 2) é possível ver a configuração padrão para o PBIL AutoEns, mostrada na parte superior da figura, ao lado do nome do algoritmo.
Braz. J. of Develop., Curitiba, v. 5, n. 12, p. 29226-29242 dec 2019 . ISSN 2525-8761
Figura 1 - Tela para a seleção de Meta Classificadores PBIL AutoEns
Fonte: o autor
Figura 2 - Tela de configurações do PBIL AutoEns
Braz. J. of Develop., Curitiba, v. 5, n. 12, p. 29226-29242 dec 2019 . ISSN 2525-8761
Figura 3 - Configuração padrão do PBIL AutoEns
Fonte: o autor
Para ter acesso a tais configurações, basta dar dois cliques no referido campo, que uma nova janela (Figura 3) se abrirá, possibilitando, dessa forma, alterar os valores para cada parâmetro. A listagem a seguir mostra os parâmetros que podem ser configurados através da interface gráfica, significados e valores possíveis para cada um deles.
● generations: trata-se do número de iterações do processo evolutivo. Seu valor padrão é 20. Quanto maior for a quantidade de iterações, mais tempo o algoritmo precisará para escolher uma solução, entretanto, se esse valor for muito pequeno, o pode não encontrar uma boa solução;
● learnigRate: trata-se do valor a ser utilizado na atualização dos vetores de probabilidade, e que aumenta assim a chance de um hiperparâmetro de um classificador base ou de um comitê ser selecionado na próxima geração. Esse parâmetro está diretamente relacionada à convergência do algoritmo;
● numBestSolves: é o número de soluções geradas pelo algoritmo. Seu valor padrão é 1, i.e. o retornará apenas uma solução ao final de sua execução, ou seja, a melhor solução gerada pelo processo evolutivo;
● numFolds: número de folds internos usados para avaliar (e.g. conjuntos de treinamento e validação) cada solução gerada pelo PBIL AutoEns. A base de dados (dataset) é inicialmente dividida em duas partes (90\% e 10\%), sendo a primeira parte
Braz. J. of Develop., Curitiba, v. 5, n. 12, p. 29226-29242 dec 2019 . ISSN 2525-8761 usada internamente (numFolds), enquanto que a segunda é guardada para testar a melhor solução encontrada. O valor padrão para numFolds é 10;
● population: a quantidade de soluções geradas por geração. Seu valor padrão é 30. Aumentar esse valor faz com que o demore mais tempo para gerar todas as soluções por geração, entretanto, um valor muito pequeno pode não fornecer toda a diversidade de soluções que um algoritmo evolutivo necessita;
● numSamplesUpdate: número de soluções que serão utilizadas para atualizar os vetores de probabilidade. Seu valor padrão é 15, metade do valor padrão para o tamanho da população. Aumentar esse valor fará com que a probabilidade de soluções mais fracas (acurácia) seja incrementada;
● seed: é a semente utilizada para gerar números randômicos necessários para que o gere as soluções em cada interação. Alterar somente esse parâmetro pode mudar completamente o resultado da execução do PBIL AutoEns, já que ele é um classificador não determinístico;
● stratify: configuração que indica se os folds gerados pelo manterão a proporção de classes da base de dados ao serem criados. Seu valor padrão é false;
● timeLimit: tempo limite em minutos para a execução do PBIL AutoEns. Seu valor padrão é de 15 minutos. Se esse tempo for excedido, então o resultado da execução será a melhor solução gerada até que o limite de tempo tenha sido atingido;
● timeLimitBySolveInSeconds: tempo limite, em segundos, de teste para cada solução gerada pelo PBIL AutoEns. Seu valor padrão é de 15 segundos. Se uma solução exceder o tempo limite, outra solução previamente gerada tomará o seu lugar;
● batchSize, configuration, debug, doNotCheckCapabilities: essas configurações referem-se apenas à opções internas do WEKA que se relacionam à forma de exposição dos resultados.
Figura 4 - Solução formada pelo PBIL AutoEns em formato CLI
Fonte : o autor
Ao fim da execução, o WEKA apresentará a solução escolhida, como mostrado na Figura 4. Além disso, ele também mostrará a matriz de confusão da solução e algumas
Braz. J. of Develop., Curitiba, v. 5, n. 12, p. 29226-29242 dec 2019 . ISSN 2525-8761 métricas utilizadas para avaliá-la, tais como: TP Rate, FP Rate, Precision, Recall,
F-Measure, MCC, ROC Area e PRC Area.
5. METODOLOGIA
5.1 BASES DE DADOS
Para avaliar o desempenho dos métodos aqui investigados, foram utilizados 21 bases de dados que retratam problemas de classificação, e que estão disponíveis para download no conhecido repositório de Aprendizado de Máquinas da UCI. A maioria dessas bases também foram utilizados em estudos recentes de Auto-ML [Feurer et al. 2015; Thornton et al. 2013; Wistuba et al. 2017]. A Tabela 1 mostra o número de instâncias, atributos (separadamente para atributos contínuos e discretos) e classes em cada uma das bases de dados usados.
Braz. J. of Develop., Curitiba, v. 5, n. 12, p. 29226-29242 dec 2019 . ISSN 2525-8761 5.2 EXPERIMENTOS
Visando realizar uma análise comparativa mais abrangente, comparamos o com dois algoritmos de comitê de classificadores (Random Forest e XGBoost), e com um classificador base robusto (Multilayer Perceptron - MLP). O algoritmo Random Forest (RF) tem obtido bons resultados em tarefas de classificação [Fernandez-Delgado et al. [S.d.]] . Já o XGBoost é um algoritmo que tem dominado recentemente a área de Aprendizagem de Máquina aplicada e as competições de Kaggle para dados estruturados ou tabulares [Chen and Guestrin 2016]. Por último, o MLP foi escolhido por ser um classificador base, que tradicionalmente apresenta resultados robustos em problemas de classificação. Desta forma, o conjunto de métodos para a realização dos experimentos é composto por: XGBoost; MLP; RF e PBIL AutoEns.
Como todos os métodos são probabilísticos, foram escolhidas 5 seeds que determinam a execução de cada método sob uma semente numérica. Logo, para cada base de dados, há 5 resultados por método, sendo considerado o valor médio desses resultados. Além disto, também foi usada como configuração de execução a abordagem de validação cruzada (cv). Para esta configuração, foram utilizados 5 fold cv (externo). Isto significa que, para cada seed, o método realizará 5 execuções, utilizando diferentes porções da base (4/5 e 1/5), onde a primeira porção é passada para o processo interno (10 fold cv) de treinamento e validação, enquanto que a segunda porção é reservada para testar a melhor solução. Ao final disso (5 fold cv - externo), o método executado retorna o valor médio de todo o processo.
Os experimentos foram executados em uma máquina virtual sobre o sistema operacional Ubuntu na versão 16.04 com as seguintes configurações : Intel(R) Xeon(R) CPU E5-4610 v4 @ 1.80GHz, 6 núcleos, e memória RAM com 6 Gb. Após a execução de cada método os resultados médios foram coletados e planilhados.
5.3 RESULTADOS EXPERIMENTAIS
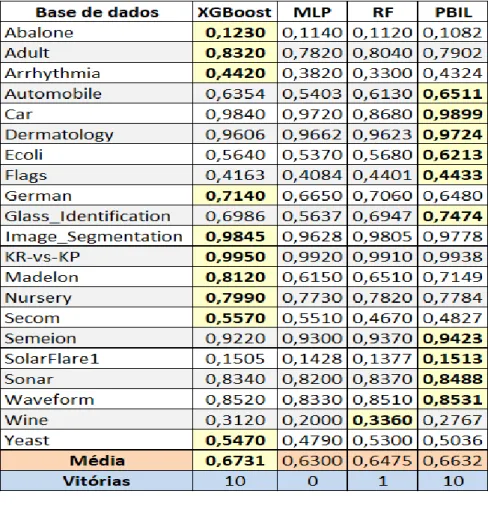
A Tabela 2 apresenta os valores médios da métrica F-measure para XGBoost (2ª coluna), MLP (3ª coluna), RF (4ª coluna) e (5ª coluna). Como mostrado na última linha da mesma tabela, o conseguiu o mesmo número de vitórias que o XGBoost (maior valor de F-measure), enquanto que o Random Forest conseguiu uma vitória, restando ao MLP zero (0) vitória.
Para realizar uma análise estatística dos resultados, os testes de Friedman e Nemenyi (post-hoc) foram usados para determinar se existe ou não uma diferença estatisticamente
Braz. J. of Develop., Curitiba, v. 5, n. 12, p. 29226-29242 dec 2019 . ISSN 2525-8761 significativa entre as precisões preditivas dos métodos. Ambos os testes são aplicados no nível de significância convencional de 5%. O teste de Friedman foi escolhido porque é não-paramétrico (evitando a suposição de normalidade), sendo baseado na classificação média dos quatro métodos em todos as bases de dados. Em caso de rejeição da hipótese nula, aplicamos o teste post-hoc Nemenyi para avaliar se existe uma diferença significativa entre cada par de métodos. Isso é necessário porque o teste de Friedman compara os quatro métodos como um todo, sem indicar quais pares de métodos têm um desempenho significativamente diferente.
O teste de Friedman produziu o valor de p = 0,000187, portanto a diferença entre as acurácias dos quatro métodos é estatisticamente significativa. As comparações entre pares usando o teste Nemenyi produziram apenas dois resultados estatisticamente significativos: XGBoost x MLP (0,000465) e x MLP (0,001908). Ou seja, não houve diferença significativa entre as acurácias de outros pares de métodos (XGBoost x PBIL AutoEns, XGBoost x RF e x RF).
Braz. J. of Develop., Curitiba, v. 5, n. 12, p. 29226-29242 dec 2019 . ISSN 2525-8761
6. CONCLUSÃO
Neste trabalho foi proposto uma análise comparativa entre um método de AutoML (PBIL AutoEns), dois métodos de comitê de classificadores (Random Forest e XGBoost) e um classificador tradicional (MLP). Além disso, foi mostrada a integração do referido método (AutoML) dentro da plataforma WEKA, dando ênfase aos parâmetros de configuração.
Em experimentos utilizando 21 bases de dados de classificação, no geral, os métodos e XGBoost obtiveram os melhores desempenhos preditivos comparados com os outros dois métodos (RF e MLP). Sendo que cada método foi superior em 10 bases das 21. Contudo, o teste Nemenyi apontou que não houve diferença significativa entre os dois melhores métodos.
Mesmo não havendo superioridade estatística, o PBIL AutoEns, como método de AutoML, provou ser eficiente na resolução do problema de seleção automática de métodos de classificação e seus hiperparâmetros. Como uma direção para trabalhos futuros, seria interessante estender os experimentos para considerar outros métodos de AutoML. Outra direção de trabalho futura seria realizar experimentos com bases de dados muito maiores, usando recursos computacionais mais poderosos.
AGRADECIMENTOS
Este trabalho foi financiado pelo Conselho Brasileiro de Pesquisa (CNPq) sob os processos de nº 150748/2017-5 e nº 407518/2018-5.
REFERÊNCIAS
Baluja, S. and Caruana, R. (1995). Removing the genetics from the standard genetic algorithm. Machine Learning Proceedings 1995. Elsevier. p. 38–46.
Brazdil, P., Carrier, C. G., Soares, C. and Vilalta, R. (2009). Metalearning: Applications to Data Mining. Berlin Heidelberg: Springer-Verlag.
Chen, T. and Guestrin, C. (2016). XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22Nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. , KDD ’16. ACM.
Braz. J. of Develop., Curitiba, v. 5, n. 12, p. 29226-29242 dec 2019 . ISSN 2525-8761 selecting and configuring multi-label classification algorithms. In Proceedings of the Genetic and Evolutionary Computation Conference Companion. . ACM.
De Sá, A. G., Pinto, W. J. G., Oliveira, L. O. V. and Pappa, G. L. (2017). RECIPE: a grammar-based framework for automatically evolving classification pipelines. In European Conference on Genetic Programming. . Springer.
Eiben, A. E., Smith, J. E. and Others (2003). Introduction to evolutionary computing. Springer. v. 53
Faceli, K., Lorena, A. C., Gama, J. and Carvalho, A. (2015). Inteligência Artificial: Uma abordagem de aprendizado de máquina. Rio de Janeiro: Livros Técnicos e Científicos Editora Ltda. v. 2
Fernandez-Delgado, M., Cernadas, E., Barro, S. and Amorim, D. ([S.d.]). Do we Need Hundreds of Classifiers to Solve Real World Classification Problems? p. 49.
Feurer, M., Klein, A., Eggensperger, K., et al. (2015). Efficient and Robust Automated Machine Learning. In: Cortes, C.; Lawrence, N. D.; Lee, D. D.; Sugiyama, M.; Garnett, R.[Eds.]. . Advances in Neural Information Processing Systems 28. Curran Associates, Inc. p. 2962–2970.
Freitas, A. A. (2002). Data mining and knowledge discovery with evolutionary algorithms. Springer Science & Business Media.
Hall, M., Frank, E., Holmes, G., et al. (16 nov 2009). The WEKA data mining software: an update. ACM SIGKDD Explorations Newsletter, v. 11, n. 1, p. 10.
Ho, Y.-C. and Pepyne, D. L. (2002). Simple explanation of the no-free-lunch theorem and its implications. Journal of optimization theory and applications, v. 115, n. 3, p. 549–570. Hutter, F., Kotthoff, L. and Vanschoren, J. (2019). Automated Machine Learning-Methods, Systems, Challenges. Springer.
Inza, I., Larrañaga, P. and Sierra, B. (2002). Feature subset selection by estimation of distribution algorithms. Estimation of Distribution Algorithms. Springer. p. 269–293.
Kordík, P., Černý, J. and Frýda, T. (jan 2018). Discovering predictive ensembles for transfer learning and meta-learning. Machine Learning, v. 107, n. 1, p. 177–207.
Kotsiantis, S. B., Zaharakis, I. and Pintelas, P. (2007). Supervised machine learning: A review of classification techniques. Emerging artificial intelligence applications in computer engineering, v. 160, p. 3–24.
Kuncheva, L. I. (2004). Combining pattern classifiers: methods and algorithms. John Wiley & Sons.
Braz. J. of Develop., Curitiba, v. 5, n. 12, p. 29226-29242 dec 2019 . ISSN 2525-8761 Lacoste, A., Larochelle, H., Laviolette, F. and Marchand, M. (2014). Sequential model-based ensemble optimization. arXiv preprint arXiv:1402.0796,
Larrañaga, P. and Lozano, J. A. (2001). Estimation of distribution algorithms: A new tool for evolutionary computation. Springer Science & Business Media. v. 2
Lévesque, J.-C., Gagné, C. and Sabourin, R. (2016). Bayesian hyperparameter optimization for ensemble learning. arXiv preprint arXiv:1605.06394,
Mitchell, T. M. (1997). Machine learning. 1997. Burr Ridge, IL: McGraw Hill, v. 45, n. 37, p. 870–877.
Olson, R. S., Urbanowicz, R. J., Andrews, P. C., et al. (28 jan 2016). Automating biomedical data science through tree-based pipeline optimization. arXiv:1601.07925 [cs],
Saeys, Y., Degroeve, S., Aeyels, D., Rouzé, P. and Van de Peer, Y. (2004). Feature selection for splice site prediction: a new method using EDA-based feature ranking. BMC bioinformatics, v. 5, n. 1, p. 64.
Shelke, K., Jayaraman, S., Ghosh, S. and Valadi, J. (2013). Hybrid feature selection and peptide binding affinity prediction using an EDA based algorithm. In 2013 IEEE Congress on Evolutionary Computation. . IEEE.
Thornton, C., Hutter, F., Hoos, H. H. and Leyton-Brown, K. (2013). Auto-WEKA: combined selection and hyperparameter optimization of classification algorithms. . ACM Press. http://dl.acm.org/citation.cfm?doid=2487575.2487629, [accessed on Aug 7].
Wistuba, M., Schilling, N. and Schmidt-Thieme, L. (2017). Automatic Frankensteining: Creating complex ensembles autonomously. In Proceedings of the 2017 SIAM International Conference on Data Mining. . SIAM.
Xavier-Júnior, J. C., Freitas, A. A., Feitosa-Neto, A. and Ludermir, T. B. (2018). A Novel Evolutionary Algorithm for Automated Machine Learning Focusing on Classifier Ensembles. In 2018 7th Brazilian Conference on Intelligent Systems (BRACIS). . IEEE.
Yang, X., Dong, H. and Zhang, H. (2009). Naive bayes based on estimation of distribution algorithms for classification. In 2009 First International Conference on Information Science and Engineering. . IEEE.
Zangari, M., Santana, R., Mendiburu, A. and Pozo, A. T. R. (2017). Not all PBILs are the same: Unveiling the different learning mechanisms of variants. Applied Soft Computing, v. 53, p. 88–96.