DETECÇÃO DE OUTLIERS MULTIVARIADOS
FABRÍCIO GERALDO VALADARES
DETECÇÃO DE OUTLIERS MULTIVARIADOS
EM REDES DE SENSORES
Dissertação apresentada ao Programa de Pós-Graduação em Ciência da Computação do Instituto de Ciências Exatas e Biológi-cas da Universidade Federal de Ouro Preto como requisito parcial para a obtenção do grau de Mestre em Ciência da Computação.
Orientador: Álvaro Rodrigues Pereira Júnior
Coorientador: André Luiz Lins de Aquino
Ouro Preto
Catalogação: [email protected]
V136d Valadares, Fabrício Geraldo.
Detecção de outliers multivariados em redes de sensores [manuscrito] / Fabrício Geraldo Valadares – 2012.
xx, 53 f.: il. color.; grafs.; tabs.
Orientador: Prof. Dr. Álvaro Rodrigues Pereira Júnior. Coorientador: Prof. Dr. André Luiz Lins de Aquino.
Dissertação (Mestrado) - Universidade Federal de Ouro Preto. Instituto de Ciências Exatas e Biológicas. Departamento de Computação. Programa de Pós-graduação em Ciência da Computação.
Área de concentração:Ciência da Computação
1. Redes de sensores sem fio - Teses. 2. Valores estranhos (Estatística) - Outliers - Teses. 3. Análise multivariada - Teses. 4. Simulação (Computadores) - Teses. I. Universidade Federal de Ouro Preto. II. Título.
Agradecimentos
Primeiramente agradeço a Deus, que tem iluminado a vida da minha família, me per-mitindo alcançar mais este objetivo.
À minha esposa Pollyanna, e ao meu filho Gabriel, pela paciência e diversas discussões para incentivar meu rendimento, pelo apoio nos momentos difíceis, e por não me deixarem desanimar diante dos desafios e dificuldades que surgiram no caminho. Amo muito vocês.
Aos meus pais Cleusa e Anísio, e meus irmãos Cristiano e Luiz Fernando, que sempre me apoiaram e incentivaram. Sem vocês eu não teria chegado até aqui.
Devo agradecer também a meus companheiros de jornada, em especial aos grupos de pesquisa SensorNet-UFOP, SensorNet-UFAL (que calorosamente me receberam em Maceió), ao IMobilis (UFOP) e Idealize (UFOP). Em especial aos alunos do mestrado João Tácio e Jader Lamoia, pelo período de convivência, durante o qual aprendi muito com todos vocês.
Aos professores do programa de pós-graduação em Ciência da Computação da UFOP, que contribuíram muito para meu avanço acadêmico. Em especial aos professo-res Ricardo Rabelo, Joubert Lima, Elizabeth Wanner, Marcone Souza. Devo destacar o professor David Menotti, pelos valiosos conselhos.
Agradeço a meu orientado Álvaro, por me acolher em seu grupo de pesquisa, e me ajudar na revisão dos artigos submetidos, muito obrigado.
À PROPP (Pró-reitoria de pesquisa e pós-gradução), pela bolsa concedida, au-xiliando no financiamento parcial deste trabalho. Também devo agradecer ao projeto Olhos da Cidade, do professor Álvaro (UFOP), pelo auxílio e financiamento parcial deste trabalho.
Por fim, devo agradecer a meu co-orientador, André Aquino (ALLA), que incen-tivou minha vinda ao programa, e foi mais do que um orientador, se tornou um grande amigo. Sua paciência, colaboração e incentivo foram primordiais para alcançar mais este nível em minha formação acadêmica.
“Uma jornada de mil milhas começa com um único passo.” (Lao-Tzu)
Resumo
Esse trabalho apresenta uma análise, via detecção de outliers, sobre os dados mul-tivariados proveniente de uma rede de sensores. Inicialmente, caracterizamos o pro-blema de detecção de outliers nestas redes. Em seguida, realizamos, via simulação, uma comparação entre três métodos gerais para a identificação dos outliers,Minimum Volume Ellipsoid (MVE), Minimum Covariance Determinant (MCD) e Max-Eigen Difference (MED), considerando cenários específicos de uma rede de sensores.
Os dados utilizados na simulação foram gerados a partir de uma base de dados reais proveniente da medição de poluentes no ar. Essa geração nos permitiu represen-tar o cenário de uma rede de sensores. O fenômeno avaliado segue um comportamento Normal, e utilizamos outras duas distribuições, Skew-Normal e T-Student, para repre-sentar a imprecisão inerente do processo de sensoriamento, que nem sempre consegue representar satisfatoriamente o ambiente monitorado. Adicionalmente, representamos a presença de ruídos nos dados (outliers pontuais), inseridos com base em uma dis-tribuição de Bernoulli. Essa disdis-tribuição foi utilizada para selecionar quais amostras seriam substituídas por ruídos.
A avaliação da representatividade dos dados após a remoção dos outliers é re-alizada por intermédio de um ferramental estatístico formado pelos seguintes testes, valor absoluto do erro relativo, ANOVA, medidas de tendência central e a contagem de outliers. Todas as simulações foram realizadas nosoftware estatísticoR. Os resultados das avaliações demonstraram que os erros encontrados podem ser tolerados por grande parte das aplicações em redes de sensores, quando aplicados os métodos MVE e MCD. O método MED não conseguiu identificar todos os outliers, logo, sua aplicação não traz benefícios às aplicações consideradas.
Palavras-chave: Redes de sensores, outliers, dados multivariados.
Abstract
This work presents an analysis based on outliers detection on multivariate dataset of sensor networks. Initially, we characterize the outliers detection problem in these networks. Then, three general methods for outliers detection methods Minimum Vo-lume Ellipsoid (MVE), Minimum Covariance Determinant (MCD) and Max-Eigen Dif-ference (MED) were used and evalueted.
The dataset used in the simulation was generated from an air pollutants data-set. This generation allowed the use of this dataset in sensor networks scenarios. The phenomenon has characterized by a Normal distribution. To represent the sensor per-ception fails, two different distributions was used, the Skew-Normal and T-Student. In addition, the sensor noise was inserted by using a Bernoulli process.
The data representativeness, after the outlier removal, was performed by sta-tistical tools: the absolute relative error, ANOVA, measures of central tendency and the number of outliers. The simulations were performed by software R. The results showed that the MVE and MCD can be used satisfatory in general sensor networks applications. The MED does not remove all outliers, so, its usage is not recommended in these applications.
Keywords: Sensor networks, outliers, multivariate data.
Lista de Figuras
2.1 Tipos de redes sem fio [Aquino, 2008]. . . 8
2.2 Componentes de um nó sensor [Aquino, 2008]. . . 9
2.3 Estrutura básica de uma rede de sensores [Aquino, 2008]. . . 10
3.1 Representação de um sistema de redes de sensores. . . 17
3.2 Densidade das distribuições [Aquino et al., 2012] . . . 20
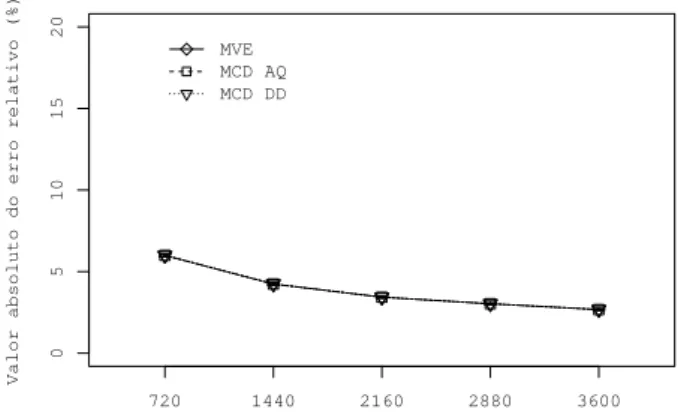
5.1 Valor absoluto do erro relativo . . . 37
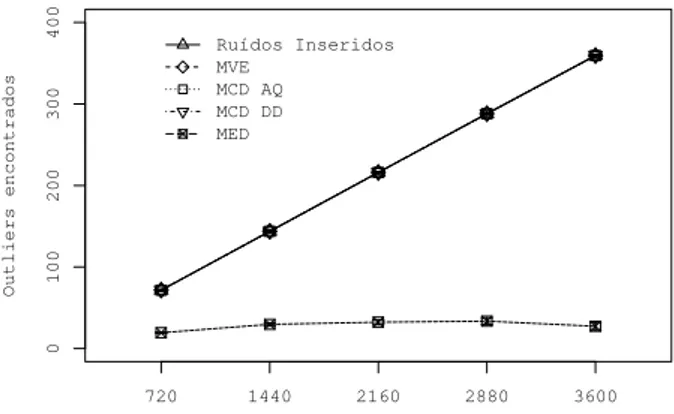
5.2 Contagem de outliers . . . 42
Lista de Tabelas
5.1 Parâmetros da simulação . . . 36
5.2 Rbvar com distribuição Normal . . . 38
5.3 Rbvar com distribuição Skew-Normal . . . 39
5.4 Rbvar com distribuição T-Student . . . 39
5.5 p-valor para Rbanova . . . 40
Sumário
Agradecimentos vii
Resumo xi
Abstract xiii
Lista de Figuras xv
Lista de Tabelas xvii
1 Introdução 1
1.1 Motivação . . . 4
1.2 Objetivo e metodologia . . . 4
1.3 Contribuições . . . 6
1.4 Organização do trabalho . . . 6
2 Fundamentação teórica e trabalhos relacionados 7 2.1 Redes de sensores sem fio . . . 7
2.2 Detecção de outliers . . . 11
2.3 Trabalhos relacionados . . . 14
2.4 Considerações parciais . . . 15
3 Caracterização do problema 17 3.1 Comportamento de uma rede de sensores . . . 17
3.2 Processo de sensoriamento . . . 18
3.3 Processo de contaminação dos dados . . . 20
3.4 Detecção deoutliers . . . 21
3.5 Processo de reconstrução . . . 22
3.6 Definição de regras de decisões . . . 22
3.7 Considerações parciais . . . 23
4 Processo de simulação 25
4.1 Geração dos dados . . . 25
4.2 Contaminação dos dados . . . 27
4.3 Detecção dosoutliers . . . 28
4.4 Representatividade dos dados . . . 32
4.5 Considerações parciais . . . 33
5 Resultados 35 5.1 Metodologia . . . 35
5.2 Valor absoluto do erro relativo . . . 36
5.3 Análise de variância . . . 39
5.4 Medidas de tendência central . . . 40
5.5 Contagem de outliers . . . 41
5.6 Resumo dos resultados . . . 43
6 Conclusão 45
Referências Bibliográficas 49
Capítulo 1
Introdução
O trabalho aqui apresentado, intitulado “Detecção de outliers multivariados em redes de sensores”, assume como premissa a necessidade emergente no tratamento dos dados obtidos pelos sensores e das técnicas utilizadas para esse fim. Sua principal hipótese é:
O processamento a priori dos dados, seja ele para reduzir, filtrar ou pré-processar, de uma forma geral, permite uma maior economia dos recursos da rede mantendo as características do fenômeno monitorado.
Para melhor relacionar as aplicações em redes de sensores, considere um ambiente qualquer que possui uma variedade de fenômenos que podem ser descritos por algumas grandezas, como temperatura, pressão e umidade. Tais fenômenos podem ser monito-rados por dispositivos com poder de sensoriamento, processamento e comunicação. O conjunto desses dispositivos, trabalhando de forma cooperativa, é conhecido na litera-tura como rede de sensores sem fio [Akyildiz et al., 2002; Tilak et al., 2002]. Nessas redes, cada nó sensor tem a capacidade de monitorar um ou mais fenômenos que são reportados, por intermédio de uma comunicação sem fio ad-hoc, para o sorvedouro. Esse elemento possui capacidade superior a dos demais nós, tem a responsabilidade de receber e processar os dados enviados pelos nós sensores e, muitas vezes, repassar as informações sobre o ambiente a um observador.
As redesad-hoc são caracterizadas pela não existência de uma estação base para prover a comunicação entre os elementos das redes. Todos os nós são capazes de se mover e podem se conectar dinamicamente, de maneira arbitrária. Neste cenário a transmissão dos dados é realizada por nós que se encontram entre a origem e o destino dos dados [Royer & Toh, 1999].
Várias aplicações utilizam as redes de sensores para efetuar o monitoramento de diferentes ambientes como, por exemplo, aplicações médicas, agricultura de
2 Capítulo 1. Introdução
são ou monitoramento ambiental [Estrin et al., 1999; Pottie & Kaiser, 2000; Estrin et al., 2001]. Nas aplicações médicas, um paciente pode ser equipado com uma rede de sensores em seu corpo para coletar informações sobre batimentos cardíacos, nível de oxigenação do sangue, temperatura corporal e pressão arterial, favorecendo, assim, o monitoramento e diagnóstico do paciente à distância. Para a agricultura de precisão, uma plantação pode ser equipada com diversos sensores coletando diferentes tipos de dados do ambiente, como temperatura, umidade e acidez do solo, permitindo que o agricultor atue remotamente no ambiente monitorado como, por exemplo, enviando um comando para aplicar uma dosagem de um produto químico (fertilizante ou pes-ticida) ao terreno monitorado. Para o monitoramento ambiental, a área central de uma cidade poderia ser equipada com uma rede de sensores que coleta informações sobre a presença de poluentes no ar, permitindo que os cidadãos, por intermédio de seus telefones celulares, recebam informações sobre a qualidade do ar. Para se projetar cada uma dessas aplicações, existem diferentes estratégias que podem ser seguidas. Em muitos casos, existe uma solução proprietária, restrita e específica para cada problema mencionado na literatura.
No entanto, apesar de seu potencial de utilização nas mais diversas aplicações, as redes de sensores possuem restrições de energia, tempo de resposta e largura de banda. Especificamente no que diz respeito à largura de banda, o envio de grandes quantidades de dados pode ser problemático pela quantidade de nós que terão que acessar o meio, podendo causar atrasos no tempo de resposta e, assim, invalidando os dados. Devido a essas restrições, é necessário adotar alguma estratégia para aumentar o tempo de vida da rede e evitar o atraso na entrega dos dados. Nesse contexto, podemos reduzir o volume de dados que trafegam nessas redes utilizando as seguintes técnicas: agregação, fusão, compressão e amostragem [Chen et al., 2006; Santini & Romer, 2006; Aquino et al., 2007, 2012]. Assim, as soluções para economia de recursos nas redes de sensores tendem a ser específicas e dificilmente podem ser reaproveitadas em diferentes cenários. Os dados coletados pelas redes de sensores podem ser classificados em univariados ou multivariados. São considerados univariados, o conjunto de dados que descrevem um único fenômeno, como por exemplo, um nó com a capacidade para monitorar apenas a temperatura ambiente. Por sua vez, os dados multivariados são representados por um conjunto de dados que descrevem diferentes fenômenos, por exemplo, os dados gerados por um nó com capacidade para monitorar temperatura, pressão e umidade simultaneamente [Aquino, 2008].
3
confiabilidade ou impedem a tomada de decisões provenientes nos dados monitorados por essas redes. Logo, para tornar mais robusta a análise realizada sobre o conjunto de dados, pode ser realizado um pré-processamento que identifica e remove os outliers presentes no conjunto de dados. De forma geral, a identificação de outliers é utilizada em aprendizagem de máquina, mineração de dados, estatística, teoria da informação e no pré processamento de dados para a detecção de intrusão e fraude [Chandola et al., 2009]. Contudo, apenas recentemente, estas técnicas têm atraído a atenção de pesqui-sadores da área de rede de sensores [Zhang et al., 2010].
Considerando a principal hipótese apresentada anteriormente e com o objetivo de delimitar o escopo deste trabalho serão estudadas apenas as abordagens para o processamento dos dados multivariados que utilizam técnicas de detecção de outliers em redes de sensores. Devemos ressaltar que consideramos os outliers como anomalias nos conjuntos de dados, contudo, esses também podem representar eventos ou ataques maliciosos, conforme destacado no trabalho de Zhang et al. [2010]. Deixamos esta diferenciação como trabalhos futuros.
Utilizamos métodos gerais para o reconhecimento de outliers em dados multiva-riados:
• Minimum Volume Ellipsoid (MVE) [Rousseeuw & Zomeren, 1990] – É um método utilizado para tornar a distância de Mahalanobis [Hazewinkel, 1990] robusta. Ele é baseado em um pequeno elipsoide que cobre uma grande parte das observações.
• Minimum Covariance Determinant (MCD) [Filzmoser et al., 2005] – O MCD é também uma forma de tornar a distância de Mahalanobis robusta, porém, este método busca um conjunto observações que torne o determinante da matriz de covariância mínimo. Ele é muito utilizado na prática devido a eficiência do algoritmo.
• Max-Eigen Difference (MED) [Gao et al., 2005] – Diferente das demais métodos, o MED é baseado nos autovetores e autovalores da matriz de covariância, e não utiliza a distância de Mahalanobis para a identificação de outliers.
4 Capítulo 1. Introdução
Para as simulações foram utilizados dados provenientes de fenômenos ambientais reais, porém, esta base de dados não era suficiente para representar os dados coletados por uma rede de sensores e, por este motivo eles foram simulados. Esse processo de simulação é necessário, uma vez que a coleta de dados por precipitação não é con-templada pelos nós sensores, que realizam uma amostragem discretizada do fenômeno monitorado. As simulações utilizam os dados originais como sementes, mantendo sua média e matriz de covariância, porém, assumindo três casos, as distribuições Normal, Skew-Normal e T-Student. Consideramos que o fenômeno monitorado tem comporta-mento Normal, e utilizamos as outras duas distribuições para representar a imprecisão inerente dos dados coletados pelos sensores. Para tornar o processo mais fidedigno, também foram inseridos ruídos nos valores amostrados, aqui chamados de outliers.
A representatividade dos dados é avaliada com o auxílio de quatro métodos, o valor absoluto do erro relativo [Frery et al., 2008], o teste de hipótese ANOVA [Thom-son, 1993], a contagem deoutliers e as medidas de tendência central (média aritmética, média truncada e mediana). Vale ressaltar que as avaliações consideram a detecção dos outliers locais, ou seja, em cada nó sensor.
1.1
Motivação
Como apresentado anteriormente, osoutliers podem comprometer as análises realiza-das sobre o conjunto de dados coletados por uma rede de sensores. Estas anomalias podem levar a tomadas de decisões imprecisas ou incorretas, devido às suas caracte-rísticas. Com isso, a principal motivação desse trabalho é a adequação das principais técnicas para detecção deoutliers em ambientes equipados por redes de sensores e que monitoram dados multivariados. Tal adequação é um importante aspecto que deve ser considerado e estudado de forma mais detalhada pelos projetistas de redes de sensores.
1.2
Objetivo e metodologia
1.2. Objetivo e metodologia 5
Os dados considerados em nossas avaliações são derivados de observações de fenô-menos reais, correspondentes a dezenove variáveis, que incluem a concentração de poluentes n-hexane, methylcyclopentane, toluene, p-xylene e 1,3,5-trimethylbenzene. Utilizamos 72 amostras destes fenômenos que correspondem à média de quatro horas
de observação. Devido ao processo de amostragem via precipitação, que não é con-templado por uma rede de sensores, não é possível obter a discretização completa do fenômeno, por essa razão, o simulamos. As 72amostras utilizadas são provenientes do
trabalho de Albuquerque [2007], onde podem ser encontrados maiores detalhes sobre sua origem.
Uma rede de sensores, gera dados discretizados e não permitem o sensoriamento por precipitação. Por esse motivo, os dados utilizados foram simulados partir dos dados reais. Para isso, mantivemos a média e sua matriz de covariância, porém, considerando três diferentes casos, as distribuições Normal, Skew-Normal e T-Student. Consideramos que o fenômeno monitorado tem o comportamento baseado numa distribuição Normal, assim, as duas outras distribuições são utilizadas para representar a imprecisão dos dados coletados por uma rede de sensores. Também consideramos um segundo processo de contaminação que representa o surgimento de erros nos valores coletados. A primeira forma de contaminação modela anomalias no comportamento global dos dados, por outro lado, a segunda forma modela as anomalias em valores pontuais.
Devemos frisar que, a simulação dos dados reais utilizados é que permite consi-derar a utilização dos métodos de detecção de outliers em dados provenientes de uma rede de sensores. Estes métodos são executados em cada nó sensor, uma vez que esta-mos interessados em outliers locais. As simulações demostraram que o MVE e o MCD mantém significativamente a representatividade dos dados.
6 Capítulo 1. Introdução
1.3
Contribuições
As principais contribuições são:
• Caracterização dos outliers em dados multivariados para redes de sensores.
• Verificação da eficácia da aplicação de técnicas tradicionais em dados oriundos
de sensoriamento.
• Adaptação e caracterização de dados multivariados reais, provenientes do
mo-nitoramento ambiental, para o problema de detecção de outliers em redes de sensores.
• Verificação da robustez de técnicas tradicionais, ou seja, avaliação da resistência
das técnicas à presença deoutliers, aplicadas aos dados reais em redes de sensores.
Durante o desenvolvimento deste trabalho, tivemos como resultado a publicação de um artigo,Detecção de outliers multivariados em redes de sensores [Valadares et al., 2012], publicado nos anaisXLIV Simpósio Brasileiro de Pesquisa Operacional (XLIV SBPO).
1.4
Organização do trabalho
Capítulo 2
Fundamentação teórica e trabalhos
relacionados
Este capítulo discorre sobre os fundamentos teóricos, necessários para o bom enten-dimento do trabalho, e os principais trabalhos relacionados. Para isso, discutimos os conceitos associados às redes de sensores. Essencialmente, é apresentada uma breve introdução sobre redes de sensores e técnicas para a detecção de outliers.
2.1
Redes de sensores sem fio
Para contextualização das redes de sensores no ambiente sem fio, precisamos considerar as redes estruturadas e as redes ad-hoc, que estão ilustradas nas Figuras 2.1a e 2.1b. Conforme descrito nos trabalhos de Loureiro et al. [2003]; Aquino & Silva Filho [2012], nas redes estruturadas, existe uma estação base responsável pela comunicação entre os nós. Porém, nas redes ad-hoc, a comunicação é realizada por intermédio de nós que se encontram entre a origem e o destino e, desta forma, a estação base não é necessária [Royer & Toh, 1999]. As redes de sensores (Figura 2.1c), como as redes ad-hoc, não precisam de estação base para realizar a comunicação entre dois nós com uma característica adicional, a comunicação é centrada nos dados e direcionada ao observador externo e não ponto a ponto.
Conforme Akyildiz et al. [2002], as redes de sensores possuem um número elevado de nós, na ordem de centenas ou milhares, que geralmente se mantém estacionários (imóveis) após sua deposição. Também possui uma frequente mudança na topologia da rede, que pode ser causada por um desligamento do rádio para economia de energia ou danos físicos nos nós. Além destas características, podemos ainda citar a comuni-cação centrada nos dados, podendo os nós não possuírem identificadores únicos, como
8 Capítulo 2. Fundamentação teórica e trabalhos relacionados
(a) Redes estruturadas
(b) Redesad-hoc (c) Redes de sensores
Figura 2.1. Tipos de redes sem fio [Aquino, 2008].
endereço IP, uma vez que estes exigem um espaço adicional, em bits, para identifi-car cada nó, aumentando o tamanho da mensagem e consequentemente o custo de comunicação [Ruiz et al., 2004].
Os nós sensores são dispositivos compactos e autônomos, tem arquitetura simples e são compostos por quatro componentes básicos, que estão ilustrados na figura 2.2. Estes componentes são:
• Unidade perceptiva, com um ou mais tipos de sensores e um conversor de sinais analógico para digital (Analog-to-Digital Converter - ADC);
• Unidade de processamento, com processador e memória;
• Transceptor, responsável por conectar o nó aos outros nós da rede;
• Fonte de energia, geralmente uma bateria não renovável.
Além dos componentes citados, podem existir outros componentes opcionais, depen-dendo da aplicação, como sistema de localização, mecanismo para mobilidade e um gerador de energia [Akyildiz et al., 2002], como destacado em pontilhado.
2.1. Redes de sensores sem fio 9
Figura 2.2. Componentes de um nó sensor [Aquino, 2008].
ambientes hostis e de difícil acesso. As redes de sensores devem, portanto, ser auto-configuráveis, adaptáveis e possuírem gerenciamento escalável [Akyildiz et al., 2002]. Essas características possibilitam sua utilização em uma grande variedade de aplica-ções, como médicas, militares, domésticas, industriais, meio ambiente, agropecuária, robótica, dentre outras [Akyildiz et al., 2002; Arampatzis et al., 2005].
De acordo com Tilak et al. [2002], as redes de sensores podem receber diferentes classificações, a partir da observação de seus elementos básicos, da disposição dos nós na área de sensoriamento e também da maneira como os fenômenos são monitorados. A rede é considerada hierárquica se existirem agrupamentos de nós e um nó líder os representar, caso contrário, será definida como plana. É homogênea se os nós pos-suírem a mesma configuração de hardware, senão, é heterogênea. A rede é simétrica se todos os nós tiverem o mesmo raio de comunicação, caso contrário, é assimétrica. Quando os dados são enviados obedecendo a uma programação pré-estabelecida, a rede é chamada programada, por outro lado, se os dados forem enviados continuamente a rede é contínua. Por último, as redes de sensores podem ser classificadas como dirigida a eventos, se o envio de dados acontecer somente na ocorrência de algum evento, ou sob demanda, quando a rede permite a consulta total ou parcial dos dados a qualquer momento.
Loureiro et al. [2003] reúne as funcionalidades das redes de sensores em cinco grupos de atividades:
1. Estabelecimento, no qual acontecem as configurações iniciais da rede;
10 Capítulo 2. Fundamentação teórica e trabalhos relacionados
3. Sensoriamento, responsável pela coleta de dados do campo monitorado;
4. Processamento dos dados coletados e que serão enviados ao sorvedouro;
5. Comunicação, responsável pela transmissão dos dados processados.
Detalharemos um pouco mais sobre a atividade de processamento, uma vez que ela está diretamente relacionada ao nosso trabalho. O processamento em uma rede de sensores pode ser dividido em duas categorias: processamento de gerenciamento, que permite o processamento funcional de um nó sensor, como comunicação, roteamento e manutenção da rede; eprocessamento dos dados, que efetua o processamento dos dados coletados de acordo com a necessidade da aplicação [Loureiro et al., 2003]. Nosso trabalho se encontra na segunda categoria, onde os dados coletados são sujeitos a um processamento para a identificação e remoção dos outliers. Em seguida, estes dados podem ser enviados diretamente para o sorvedouro, ou passar por um segundo processamento, como redução, fusão ou agregação [Aquino et al., 2012].
Por fim, além dos nós sensores, essas redes possuem outros elementos como: os atuadores, dispositivos com poder para atuar no ambiente monitorado;sorvedouros, que têm a capacidade superior aos demais nós, e a responsabilidade de receber e processar as informações enviadas pelos nós sensores e, muitas vezes, repassar as informações sobre o ambiente a um observador; e os gateways, responsáveis pela comunicação das redes de sensores com outras redes, como a Internet. Vale ressaltar que estes elementos não são necessariamente distintos, podendo osgateways e os sorvedouros serem os mesmos dispositivos, assim como os nós sensores também podem ser atuadores. A figura 2.3 ilustra a estrutura geral de uma rede de sensores.
Gateway
Observador Nó sensor
Nó sorvedouro Dados sensoriados
2.2. Detecção de outliers 11
2.2
Detecção de outliers
Conjuntos de dados, sejam eles grandes ou pequenos, podem conter elementos que não são consistentes com a distribuição do restante dos dados que compõe o conjunto, e.g., pontos que desviam em uma ou mais variáveis, impedindo a modelagem estatística e a correta análise dos dados [Santana Giroldo & Barroso, 2008]. Estas anomalias são chamadas outliers.
Na literatura são encontradas diversas definições para outliers, entre elas, pode-mos citar Hawkins [1980]:
“Outlier é uma observação, que desvia muito de outras observações desper-tando suspeitas de que são geradas por um mecanismo diferente”
e Barnett & Lewis [1994]:
“Outlier é uma observação (ou um subconjunto de observações) que parece ser inconsistente comparado ao restante do conjunto de dados.”
Em redes de sensores, segundo Sheng et al. [2007], podemos citar:
“Outlier é um conjunto de medidas que desviam significativamente do pa-drão normal dos dados sensoriados.
O tratamento de outliers, seja para identificação, remoção ou ambos, tem sido extensivamente pesquisada em várias disciplinas, como a estatística, mineração de da-dos, aprendizagem de máquina e teoria da informação. As aplicações que se beneficiam do tratamento de outliers são a identificação de fraudes ou intrusão de redes, análise de desempenho, previsão do tempo entre outras [Chandola et al., 2009]. Apenas recen-temente o tratamento de outliers tem atraído a atenção em pesquisas relacionadas às redes de sensores [Zhang et al., 2010].
Como estamos interessados em dados multivariados, discutiremos adiante algu-mas técnicas para o tratamento de outliers em dados multivariados. Um método clássico para o reconhecimento de outliers nesse contexto, é a distância de Mahala-nobis [Hazewinkel, 1990],
MDi =
p
(Vi−T(V))C(V)−1
(Vi−T(V))⊤
, (2.1)
calculado para cada ponto em relação à média do conjunto. Na equação 2.1, V
12 Capítulo 2. Fundamentação teórica e trabalhos relacionados
de média aritmética simples, onde existe uma média para cada variável; e C(V) é a
matriz de covariância de dimensõesp×p.
Para uma distribuição Normal Multivariada, a Distância de Mahalanobis ao qua-drado (MD2
i) tem aproximadamente uma distribuição qui-quadrado, com p graus de
liberdade (χ2
p). Então, podemos definir os outliers como aquelas medidas que
ultra-passam um determinado quantil da distribuição qui-quadrado.
Mesmo sendo utilizada para detectar os outliers, a Distância de Mahalanobis é fortemente influenciada por eles. Isso ocorre devido à fragilidade dos estimadores de locação e dispersão utilizados, respectivamente a média aritmética simples e a matriz de covariância amostral [Rousseeuw & Driessen, 1999; Filzmoser et al., 2005]. Logo, são necessários estimadores que sofram menor interferência das anomalias.
Santana Giroldo & Barroso [2008], listam três métodos robustos para a identifi-cação deoutliers em conjuntos de dados multivariados. Estes métodos são o Minimum Ellipsoid Volume(MVE) [Rousseeuw & Zomeren, 1990], oMinimum Covariance Deter-minant (MCD) [Filzmoser et al., 2005] e o Max-Eigen Difference (MED) [Gao et al., 2005]. Com exceção do MED, os outros métodos usam a distância de Mahalanobis para a detecção de outliers, mas, substituindo a média e a matriz de covariância por estimadores robustos.
Minimum Volume Ellipsoid (MVE): Este método utiliza a distância de
Mahala-nobis, porém substituindo os estimadores de locação e dispersão por estimadores que sofrem menor interferência das anomalias. O estimador MVE pode ser de-finido como um par (T, C), que substituem a média e a matriz de covariância
por um vetor T(V)de tamanhop, eC(V), uma matriz positiva semi-definida de
tamanho p×p. O determinante da matriz é mínimo, sujeito a
#{i; (Vi−T(V))C(V)−1(Vi−T(V))t ≤a2} ≥g,
onde # é o número de elementos no conjunto, g = ⌊(n+p+ 1)/2⌋, sendo que, n representa o tamanho da amostra ep a quantidade de variáveis. Considerando que a maior parte dos dados segue uma distribuição Normal, a2 é uma constante, como χ2
p;0,50 [Rousseeuw & Zomeren, 1990]. Desse modo, obtém-se um elipsoide definido por T(V) eC(V), dado um coeficientea2, que cubra ao menos g pontos de dados, onde n/2≤g < n.
2.2. Detecção de outliers 13
será considerado um intervalo de 97,5%. Esses “pontos bons” são utilizados
para os cálculos das estimativas finais dos parâmetros de localização e dispersão, respectivamente a sua média e matriz de covariância [Santana Giroldo & Barroso, 2008]. De acordo com Alameddine et al. [2010], o ponto de ruptura do MVE pode chegar a 50%, quando n aumenta. Esse ponto representa a fração de outliers na amostra que pode tornar o estimador completamente tendencioso.
Minimum Covariance Determinant (MCD): Este método é frequentemente
uti-lizado na prática, particularmente devido à rápida execução de seu algoritmo [Filzmoser et al., 2005]. O objetivo dessa técnica é encontrar g observações que tornem o determinante da matriz de covariância amostral mínimo. O estimador de localização é então a média destesg pontos, enquanto o estimador de dispersão será sua matriz de covariância. Para manter um compromisso entre a eficiência e a robustez do método, o subconjunto é definido como g ≈0,75n, onde n indica o tamanho da amostra [Filzmoser et al., 2005].
O valor aproximado do ponto de ruptura do MCD é dado por (n−g)/n.
Con-siderando g ≈ 0,75n, seu valor será 25%. O cálculo desse estimador torna a
Distância de Mahalanobis robusta.
Os resultados do MCD foram obtidos por intermédio do pacote mvoutlier [Filz-moser & Gschwandtner, 2012], que está disponível no software estatístico R [R Development Core Team, 2012]. Ele realiza o cálculo do MCD com base em duas funções e, seus resultados serão representados por MCD-AQ e MCD-DD. Conforme descrito no trabalho de Santana Giroldo & Barroso [2008], a primeira função realiza um ajuste para evitar que os dados da calda sejam erroneamente classificados como outliers. A segunda função realiza um cálculo baseado na dis-tância de Mahalanobis clássica e na disdis-tância de Mahalanobis robusta (utilizando os estimadores MCD) para a definição dos outliers.
Max-Eigen Difference (MED): Ao contrário das outras técnicas, este método não
14 Capítulo 2. Fundamentação teórica e trabalhos relacionados
serão considerados outliers as amostras com o valor de MED muito diferente dos outros dados.
2.3
Trabalhos relacionados
O trabalho de Zhang et al. [2010], propõe um arcabouço para a detecção de outliers em redes de sensores. Os autores classificam a detecção em métodos baseados em: estatística, classificação, vizinho mais próximo, agrupamento e decomposição espec-tral. A maior parte dos estudos existentes, diferente do nosso trabalho, não leva em consideração os dados multivariados, e fazem a suposição que os dados sensoriados são univariados ou bivariados. Além disso, estes trabalhos consideram a correlação espacial e temporal entre os dados dos nós vizinhos, e desprezam a correlação entre os dados coletados por cada sensor, o que eleva a complexidade computacional.
Considerando a detecção deoutliers em dados univariados e bivariados, o trabalho de Sheng et al. [2007] propõe o uso de métodos baseados em histogramas para remover anomalias em conjuntos de dados gerados por nós sensores. O método apresentado é capaz de filtrar os nãooutliers, e classificar possíveis anomalias em conjuntos de dados. Mas, seu objetivo é a redução do custo de comunicação e, diferente do nosso trabalho, nenhuma consideração sobre a representatividade dos dados é realizada.
O trabalho de Bahrepour et al. [2009] apresenta o uso de métodos baseados no reconhecimento de eventos para a identificação de outliers em redes de sensores. Ele utiliza conjuntos de dados com duas dimensões, e as simulações são executadas consi-derando dados reais e simulados. O método apresentado é capaz de reconhecer eventos e também anomalias. Contudo, diferente do nosso trabalho, análises com mais de duas variáveis não foram realizadas.
O trabalho de Rajasegarar et al. [2010] considera o uso de dados multivariados. Em seu trabalho, são apresentados três métodos elípticos para o reconhecimento de outliersem dados gerados por redes de sensores. De acordo com o autor, estes métodos mantém a mesma precisão de métodos centralizados, mas reduz o consumo de energia, uma vez que os cálculos são executados de maneira distribuída. Neste trabalho, cada nó calcula a média e matriz de covariância de seus dados, em seguida envia estas informações para o sorvedouro, que irá definir estimadores globais para a localização e dispersão. Estes estimadores são enviados de volta aos nós e, baseado neles, serão definidos osoutliers. O autor consideraoutliers globais e locais, ambos calculados com os estimadores locais.
2.4. Considerações parciais 15
de outliers locais, e exploramos a correlação entre os dados do sensor. Um aspecto em destaque no nosso trabalho é a modelagem e a garantia da representatividade do conjunto de dados após a remoção das anomalias, uma vez que os demais trabalhos não se preocupam com tal análise.
2.4
Considerações parciais
Capítulo 3
Caracterização do problema
Este capítulo discorre sobre a caracterização das redes de sensores na presença de outliers. Para isso, primeiro apresentamos um diagrama que representa tal cenário, em seguida, apresentamos o comportamento ideal da rede. Após isso, descrevemos o processo de sensoriamento e o processo de contaminação. Por fim, mostramos os métodos utilizados para avaliar a representatividade dos dados após a aplicação dos métodos para tratamento de outliers.
3.1
Comportamento de uma rede de sensores
O diagrama apresentado na figura 3.1, baseado em Aquino et al. [2012], representa apropriadamente o ambiente de monitoramento de uma rede de sensores com a presença deoutliers, e destaca a utilização de técnicas para a identificação e remoção dos mesmos.
N |E P //V S(h,k)//
R
V′ Ψ //V′′ P ,hb //V
b
R
D Db
Figura 3.1. Representação de um sistema de redes de sensores.
Conforme apresentado por Aquino et al. [2012], o ambiente e o processo a ser me-dido são representados por N, e os estudos apresentados neste trabalho serão restritos
(denotado por "|") a um domínio espaço temporal e às características topológicas da
área monitorada E. P representa o fenômeno multivariado de interesse e V é o seu
domínio, ou seja, é um conjunto de todos os fenômenos possíveis. S(h, k) representa
o conjunto de nós sensores que realiza uma amostragem sobre V, onde cada nó ciente
18 Capítulo 3. Caracterização do problema
de sua posição (h), e capaz de executar algumas funções (k), como o sensoriamento.
Ψ representa os métodos para detecção de outliers e P , hb o processo de reconstrução dos dados. Para exemplificar este modelo, podemos considerar uma floresta (N), onde
concentraremos nossa atenção em uma área crítica (E), local em que a ocorrência de fogo não é aceitável. O fenômeno de interesse pode ser o par "temperatura-umidade", com precisão infinita no tempo, espaço e medidas.
Se considerarmos um cenário ideal, i.e., um conjunto de observações sem ruídos ou perdas de informações, um conjunto de regras ideais R levariam a tomadas de decisões ideaisD. Medidas de temperatura e umidade precisas e totalmente confiáveis poderiam levar a estas regras de decisão, se estas informações pudessem ser enviadas aos guardas florestais. Contudo, devido à complexidade em que as redes de sensores operam, e.g., interferências do ambiente e limitações de hardware, este caso ideal é proibitivo.
3.2
Processo de sensoriamento
Ao invés de uma situação ideal, para monitorar estes ambientes, devemos considerar um conjunto S = (S1
1..p, . . . , S1o..p), onde o é o número de nós sensores e p indica a
quantidade de variáveis que cada nó pode monitorar. Cada nóSié ciente de sua posição
(hi), e as operações que ele pode executar são descritas por uma função característica
ki. Na figura 3.1, h representa a coleção de todas as posições, e k denota o conjunto
de todas as funções características.
Conforme descrito por Aquino et al. [2012], uma destas funções é o sensoriamento. Se considerarmos que o fenômeno de interesse pode ser descrito por uma função f, como umidade (em mg/m3) e temperatura (em graus Celsius) em um instante t, i.e.,
f(t) = (f1, f2)(t), um nó gravará valores instantâneos proporcionais à integral de f(t)
dentro de uma área próxima. O cálculo do índice Ångstrom é outra operação que pode ser realizada localmente por um nó. O índice Ångstrom [Skvarenina et al., 2004] é um sistema simples de classificação do risco de incêndio dado por
f3(t) = f1(t)
20 +
27−f2(t)
10 .
Assim, os dados disponíveis em um nó Si dependem de sua localização hi, e são
deno-tadas por
si(f(t)) =ki(f1, f2)(t) = f1(hi), f2(hi), f3(hi)(t).
tempe-3.2. Processo de sensoriamento 19
ratura (pontual), a umidade e o índice Ångstrom em um instante t gravado em hi.
Segundo Yang & Liu [2012] a localização do nó é uma informação importante para as redes de sensores, contudo, isso foge do escopo deste trabalho. Consideraremos que a melhor solução para a localização do nó foi utilizada, sem comprometer o processo de detecção de outliers. Isso ocorre porque o mesmo algoritmo de localização é utili-zado em todos os nós sensores, então, o consumo energético será o mesmo em todos os elementos.
As operações realizadas por um nósj que monitora a mesma quantidade de dados
podem ser representadas por
sj(f(t)) = kj(f1, f2)(t)
= Z
d1,j
f1,
Z
d2,j
f2,
R
d1,jf1
20 +
27−Rd
2,jf2
10
!
(t),
onde os domínios da integral são d1,j ∈ R e d2,j ∈ R+. Este último sensor, ao
con-trário do sensor anterior, realiza o registro de valores encontrados por intermédio da integração do sinal de uma região próxima da captura. Observe que para cada tem-peratura e umidade são considerados diferentes domínios de integração, ou seja, d1,j
e d2,j. Então, medidas mais realísticas de temperatura, umidade e índice Ångstrom
serão encontradas.
Supondo que todos os nós são capazes de gravar estes três valores, temperatura, umidade e índice Ångstrom, de maneira sincronizada, a coleção das amostras dos o nós sensores sobre o fenômeno f em o posições levam a uma observação multivariada. Cada observação tem um domínio pertencente a R+×R×R. Deste modo, a coleção de todas as observações multivariadas, que tem a forma (s1, . . . ,so)(t), onde sj é dado
pela equação anterior, será gravada a cada instante por uma rede de sensores como um ponto pertencente a (R+×R×R)o.
Se forem gravados n instantes, e.g., t1, . . . , tn, a informação capturada pela rede
assume a forma
(s1, . . . ,so)(t1) (s1, . . . ,so)(t2)
...
(s1, . . . ,so)(tn) ,
que é um vetor de números reais de dimensão 3×o×n. Os procedimentos utilizados
20 Capítulo 3. Caracterização do problema
Podemos então considerar que o conjunto de dados coletados por uma rede de sensores terá o seguinte domínio V′
= (R+×R×R)o
n
. Para generalizar, ao invés de três, consideramos p variáveis reais disponíveis em cada nó, formando assim, um conjunto final dep×o×n.
3.3
Processo de contaminação dos dados
Devemos ressaltar que as redes de sensores não correspondem ao ambiente ideal, e os dados coletados por ela podem conter ruídos, em nosso caso, chamados de outli-ers [Valadares et al., 2012]. Os outliers podem impedir ou invalidar as tomadas de decisões.
Para caracterizarmos a presença de outliers, podemos considerar dois tipos de contaminação sobre os dados V′. Inicialmente, podemos considerar distintos desvios
na distribuição original dos dados (V −→ Vs −→ V′). Supondo que a distribuição
original é Normal, podemos supor que a contaminação (Vs) pode ser modelada por
intermédio das distribuições Skew-Normal e T-Student com média zero. As figuras 3.2a e 3.2b apresentam as densidades características dessas distribuições em escala linear e semilogarítmica. A distribuição Skew-Normal tem um desvio igual a0,5, enquanto a
distribuição T-Student, de cauda mais pesada, tem dois graus de liberdade. Estas dis-tribuições podem ser utilizadas para representar a imprecisão inerente dos dispositivos de sensoriamento, que, por sua vez, nem sempre representam de maneira satisfatória o fenômeno atual. ✲ ✲ ✁ ✵ ✁ ✂ ✄ ✂ ✂ ✄ ☎ ✂ ✄ ✆ ✂ ✄ ✝ ✂ ✄ ✞ ① ❉ ✟ ✠ ✡ ☛ ☞ ☛ ✟ ✡ ●✌✍✎✎✏✌✑ ❙✒❡✓ ●✌✍✎✎✏✌✑ t✲❙t✍✔ ❡✑t
(a) Escala linear
− 4 − 2 0 2 4
1 e − 0 5 1 e − 0 4 1 e − 0 3 1 e − 0 2 1 e − 0 1 x D e n s i t i e s
(b) Escala semilogarítmica
Figura 3.2. Densidade das distribuições [Aquino et al., 2012]
3.4. Detecção de outliers 21
dos dados (V −→ Vs ·Vc −→ V′). Para isso, podemos considerar um conjunto de
dados Vc, similar aVs, gerado com média multiplicado por 210. Com o auxílio de um conjunto de dados gerados a partir de uma Bernoulli com probabilidade igual a 0,1,
as amostras que serão contaminadas são escolhidas em Vs e substituídas por amostras
de Vc gerando, assim, o conjunto de dados V′ contaminado.
3.4
Detecção de
outliers
Como citado na seção 2.2, os outliers podem impedir a modelagem estatística ou a correta análise dos dados. Nas redes de sensores, estas anomalias nos conjuntos de dados podem invalidar ou impedir as tomadas de decisões.
Para garantir a robustez nas técnicas de processamento dos dados coletados por uma rede de sensores, demonstramos o impacto da utilização de métodos gerais na detecção de outliers nessas redes. O objetivo da aplicação destes métodos é a identifi-cação e, se necessário, a remoção dos ruídos que podem estar presentes nas amostras. Como ilustrado na figura 3.1, os métodos de detecção de outliers com remoção são representados por
Ψ :Rp×o×n →Rp×o×n′ | n′
≤n, onde, n indica o número de amostras sobre V′ e
n′ indica a quantidade de amostras
resultantes, ao removermos os outliers. Observe que serão mantidos o número de variáveis (p) e o número de nós sensores (o), mas pode haver uma redução no número de observações, devido ao processo de remoção.
É importante destacar que a detecção de outliers, Ψ, é aplicada em cada nó
sensor, o que resulta nas operações 1 ≤i ≤o : Ψ = (Ψ1, . . . ,Ψo), implicando em Ψi :
Rp×n → Rp×n′ | n′
≤n. A aplicação de Ψ permite uma análise do conjunto de dados
coletados por uma rede de sensores, uma vez que estamos interessados nas tomadas de decisões D, que devem ser tão próximas quanto possível deb D ao considerarmos as regras R.
Em nossa proposta, a detecção de outliers (Ψ) é composta de duas funções, a
classificação de candidatos à outlier (ψC) e um processo de filtro que reduz a taxa de
falsos positivos. Este processo é representado por (ψF):
Ψi =ψF ◦ψC.
22 Capítulo 3. Caracterização do problema
na mediana, medida que sofre menor interferência das anomalias, e o desvio padrão. Assim, todos os dados pré classificados como ruídos serão definitivamente marcados como outliers, sempre que a amostra obtiver valor maior do que a mediana ± desvio
padrão. A utilização deψF reduz significativamente o número de falsos positivos. Após
a aplicação de Ψtemos com resultado os dados sem outliers V′′.
3.5
Processo de reconstrução
Segundo Aquino et al. [2012], é necessário que o sorvedouro realize algum tipo de reconstrução afim de tomar decisões sobre o fenômeno estudado. Na figura 3.1, este processo de reconstrução é representado porPb, que utiliza as informações de localização
da rede, apresentadas sob a formah={hi : 1≤i≤o}, onde,hi é a posição do sensor
Si em R2 ouR3. Desse modo, novas regras Rb sobre V levarão às tomadas de decisões
b
D, que devem ser tão próximas quanto possível deD. No nosso caso, nenhum processo de reconstrução foi aplicado após a remoção deoutliers, deixamos essa atividade como trabalho futuro, logo V′′
−→V.
3.6
Definição de regras de decisões
No contexto da caracterização, considerando a necessidade de realizar a detecção de outliers (Ψ) sobre V′, um aspecto fundamental a ser analisado é o impacto deste
processo na tomada de decisões sobre o fenômeno estudado. A avaliação do impacto da detecção de outliers pode ser realizada em comparação ao conjunto original. Se técnicas de reconstruções ideais estiverem disponíveis, as decisões tomadas serão as mesmas. Estas avaliações serão executadas com as seguintes medidas:
• Valor absoluto do erro relativo [Frery et al., 2008], essa medida realiza uma com-paração entre a média dos dados sem a contaminação nos valores amostradosVs
e a média dos dados após a reconstrução V. O valor absoluto do erro relativo é
b
Rvaer = 100 max
p
|Vs−V|
Vs
,
onde Vs e V são respectivamente a média dos dados antes da contaminação e
3.7. Considerações parciais 23
• Análise de variância(ANOVA) [Thomson, 1993], é usada para verificar se existem diferenças significativas entre as médias dos dados originais Vs e a média dos
dados reconstruídos V. A estatística do teste é calculada por
b
Ranova=λ2B/λ
2
W,
onde λ2
B é a variância entre os conjuntos Vs e V, e λ2W representa a variância
dentro dos conjuntos. Com base neste cálculo, op-valor é usado para determinar a aceitação ou rejeição da hipótese nula H0. A aceitação da hipótese nula indica a inexistência de diferenças significativas entre a dispersão dos dois conjuntos. Assim, um p-valor acima de 0,05 é considerado satisfatório para a aceitação de
H0. O teste F foi utilizado para comparar a variância entre os dois conjuntos.
• Contagem deoutliers(Rbcount), onde podemos verificar se todos os ruídos inseridos
foram encontrados e indicar quando algum dado correto foi classificado como outlier (falsos positivos) e onde o método não consegue identificar um outlier (falsos negativos).
• Medidas de tendência central (Rbcentral), utilizadas como medida de decisão.
Fo-ram aplicadas três medidas de tendência central, a média aritmética que é similar aoRbvaer, a mediana e a média truncada, onde consideramos a porcentagem igual
a 10%. Os cálculos são realizados para cada variável, e apenas a maior diferença
será utilizada. Assim obtemos as diferenças das medidas entre os conjuntos de dados antes da contaminação Vs e o conjunto de dados reconstruídos V.
Por convenção Rbvaer, Rbanova, Rbcount e Rbcentral representarão, respectivamente,
valor absoluto do erro relativo, teste de hipótese ANOVA, contagem de outliers e medidas de tendência central.
3.7
Considerações parciais
24 Capítulo 3. Caracterização do problema
Capítulo 4
Processo de simulação
Esse capítulo apresenta todo o processo de implementação para o tratamento de ou-tliers em redes de sensores. O algoritmo geral que representa todo o processo de simulação pode ser observado no Algoritmo 1. O detalhamento do algoritmo será feito nas próximas seções.
4.1
Geração dos dados
Os dados considerados em nossas avaliações são derivados de observações de fenômenos reais, correspondentes a dezenove variáveis. Utilizamos 72amostras destes fenômenos
que correspondem à média de quatro horas de observação. Devido ao processo de amos-tragem via precipitação, não é possível obter a discretização completa do fenômeno, por essa razão, o simulamos.
No Algoritmo 1, a geração dos dados é representada pelas seguintes linhas:
• Linha 1: Representa o cálculo da matriz de covariância dos dados originais que é obtida por intermédio da funçãocov()pertencente ao pacotestats [Becker et al., 1988; R Development Core Team, 2012] do R.
• Linha 2: Representa o laço onde a condição de parada corresponde à quantidade
de fatores utilizados na geração dos dados pseudo-reais {10,20,30,40,50}, ou
seja, este laço será repetido 5 vezes.
• Linha 3: Representa o laço onde o critério de parada é 600. Este número de
replicações é necessário para se alcançar uma boa representatividade no método de Monte Carlo [Bustos & Frery, 1992] considerado em nossas avaliações. A
26 Capítulo 4. Processo de simulação
Algoritmo 1: Processo de simulação
Entrada: V– Conjunto de médias (dados obtidos por precipitação)
1 C←cov(V);
2 parai∈ {10,20,30,40,50}faça 3 paraj←0;j <600;j=j+ 1faça
4 paradist←1;dist <4;dist=dist+ 1 faça
5 sedist= 1então
6 Vs
←mvrnorm(i,V,C);
7 fim
8 senão sedist= 2então
9 Vs←rmvsnorm(i,V,C,0,5);
10 fim
11 senão sedist= 3então
12 Vs←rmvst
(i,V,C,2);
13 fim
14 B←rbern(i,0.1);
15 Vc
←mvrnorm(i,V∗210
,C);
16 parab∈ |Vs
|faça
17 seB[b] = 1então
18 V′b←Vc
b;
19 fim
20 senão seB[b] = 0então
21 V′b←Vs
b;
22 fim
23 fim
24 detectarOutliers( );
25 testarRepresentatividade( );
26 fim
27 fim
28 fim
quantidade de replicações foi calculada de acordo com Jain [1991],
j= 100zσ
pcRb
!2 ,
onde z representa uma constante de valor 1,96, σ é o desvio padrão encontrado nas dez primeiras simulações, Rb é a média dos valores dos erros obtidos e pc
é a porcentagem da média desejada como desvio, em nosso caso, 5%. Após
executar as dez primeiras simulações, considerando os piores resultados entre os métodos para detecção de outliers, identificamos que, para obter uma boa representatividade dos resultados, seria necessário utilizar aproximadamente 600
replicações independentes.
4.2. Contaminação dos dados 27
• Linhas 5 – 13: Representam a geração dos dados Normal, Skew Normal e
T-Student. A criação dos dados Normal foi realizada por intermédio da função
mvrnorm() do pacote MASS [Venables & Ripley, 2002; Ripley, 2009], utilizando o conjunto V como parâmetro para a média e a matriz de covariância C. As
distribuições T-Student e Skew-Normal, foram geradas respectivamente com o uso das funções rmvsnorm() e rmvst(), ambas pertencentes ao pacote fMulti-var [Hothorn et al., 2001; Wuertz et al., 2012].
A função rmvsnorm() recebe como parâmetros a quantidade de amostras que se
deseja gerar para cada variável (p), o conjunto de médias utilizado como semente (V), a covariância das sementes (C) e o nível de desvio desejado 0,5. A
fun-ção rmvst() considera os mesmos parâmetros da função mvsnorm(), contudo,
informa-se o grau de liberdade empregado, e não o desvio da distribuição.
4.2
Contaminação dos dados
Para inserir os ruídos, geramos um segundo conjunto de dados pseudo-reais, similar a Vs, porém, com a média multiplicada por um fator igual a 210. Baseado em uma
distribuição de Bernoulli, com probabilidade igual a 0,1, determinamos quais amostras do conjunto Vs seriam substituídas por dados contaminados do novo conjunto.
No Algoritmo 1, a contaminação dos dados são representadas pelas seguintes linhas:
• Linha 14: Representa a geração da distribuição de Bernoulli. Essa distribuição foi gerada com o uso da função rbern(), que faz parte do pacote Rlab [Boos & Nychka, 2012] do software R. Seus argumentos são: a quantidade de dados que se deseja como retorno e a probabilidade utilizada para gerar a distribuição, em nosso caso, 0,1, ou seja,10%.
• Linha 15: Representa a criação do conjunto de dados totalmente contaminado
(Vc), que é feito com a aplicação da função
mvrnorm(), pertencente ao pacote
MASS. Essa função produz amostras de uma distribuição Normal multivariada e recebe como parâmetros o número de amostras desejado, a média utilizada como semente (V), e a matriz de covariância amostral do conjunto de dados original
(C). Devemos destacar que as sementes foram multiplicadas por um fator igual
a 210 para representar a presença de ruídos no conjunto de dados.
• Linhas 16 – 23 representam a inserção dos ruídos em Vs. Nesse intervalo existe
28 Capítulo 4. Processo de simulação
Devemos ressaltar que os tamanhos considerados nesse trabalho são iguais a
|Vs|={720,1.440,2.160,2.880,3.600}. Estes tamanhos dos conjuntos de dados
são derivados da multiplicação do número de amostras dos dados reais (72), pelos
fatores {10,20,30,40,50}.
Como pode ser observado, a criação do conjunto de dados pseudo-reais conta-minado (V′) é realizado a cada passo do laço. Assim, sempre que a posição b
da distribuição de Bernoulli (B) for igual a 1, a amostra do conjunto de
da-dos contaminado de V′
b receberá uma amostra do conjunto de dados totalmente
contaminado Vc
b. Por outro lado, se Bb for igual a 0, a amostra atual de V
′
b
receberá uma amostra do conjunto de dados limpos, ou seja, sem ruídos (Vs
b).
4.3
Detecção dos
outliers
Após a contaminação dos dados, será executada a função para a detecção dosoutliers, linha 24 do Algoritmo 1. O detalhamento da função pode ser vista no Algoritmo 2 que recebe como entrada o conjunto de dados pseudo-reais contaminados (V′), retornando
como saída o conjunto de dados (V′′) após a aplicação dos métodos para identificação
das anomalias (Ψ).
Algoritmo 2: Detecção de outliers
Entrada: V′ – Dados pseudo-reais comoutliers
Saída: V′′– Dados pseudo-reais após remoção deoutliers
1 início
2 V′′mve←remove(Ψmve(V′,0,975)); 3 V′′
mcd_aq←remove(Ψmcd_aq(V′,0,975));
4 V′′mdc_dd ←remove(Ψmcd_dd(V′,0,975));
5 V′′med←remove(Ψmed(V′));
6 fim
Como é possível observar, no algoritmo 2, todos os métodos para detecção de outliers (Ψ) serão executados para cada conjunto de dados pseudo-reais contaminados
(V′). Este processo foi adotado para facilitar a comparação entre os métodos. Nas
simulações, foram utilizadas matrizes multidimensionais para armazenar o resultado da aplicação de cada método empregado, V′′
mve, V
′′
mcd_aq, V
′′
mcd_dd e V
′′
med. Os
métodos mve, mcd_aq e mcd_dd utilizam, respectivamente, as funções cov.mve(), aq.plot()edd.plot(). A primeira função é pertencente ao pacoteMASS, já as duas últimas são pertencentes ao pacotemvoutlier [Filzmoser & Gschwandtner, 2012]. Essas funções recebem como entrada o conjunto de dados a ser analisado (V′) e o intervalo
4.3. Detecção dos outliers 29
marcadas as amostras contaminadas. Não existe uma função específica para o cálculo do MED, então, esta simulação foi realizada por intermédio de manipulações algébricas, conforme descrito no trabalho de Santana Giroldo & Barroso [2008].
As manipulações algébricas utilizadas no cálculo do MED estão descritas no algo-ritmo 3. O algoalgo-ritmo recebe como entrada o conjunto de dados com outliers (V′) e tem
como saída um conjunto de dados que representa o valor do MED para cada amostra. Antes de iniciar o laço da linha 2, serão calculados a média, a matriz de covariância, os autovalores e os autovetores do conjunto V′
, representados, respectivamente por mean, vardata, autoval, e autovet. Para calcular a média aritmética, utilizamos a função colMean, pertencente ao pacote base [R Development Core Team, 2012]. Esta função recebe uma matriz de dados como entrada, e retorna a média aritmética das colunas.
A covariância foi obtida por intermédio da função var, do pacote stats, e recebe como entrada um conjunto de dados, representando por uma matriz, e retorna sua matriz de covariância. A funçãoeigen do pacotebase foi utilizada para a extração dos autovalores e autovetores da matriz de covariância. O primeiro autovalor de autoval será copiado para a última posição do vetor AU T OV AL, que tem tamanho n + 1,
onde n representa o tamanho da amostra. Na última posição da matriz AU T OV ET, de tamanho p×n+ 1, onde p indica o número de variáveis, serão salvos os primeiros autovetores da matriz de covariância dos dados com outliers.
• Linhas 2 – 11: Representa o cálculo da média aritmética, matriz de covariância, dos autovalores e autovetores, do conjunto de dados pseudo-real com outliers (V′), extraída a amostra atualmente analisada.
• Linha 12: Representa o produto dos autovalores por autovetores do conjunto de dados V′
.
• Linhas 13 – 15: Representa o cálculo do produto dos autovalores por autovetores do conjunto de dados V′, porém, desconsiderando-se cada amostra analisada.
• Linhas 16 – 18: Representa o cálculo da diferença do produto dos autovalores e
autovetores de cada amostra em relação aos autovetores e autovalores do conjunto completo.
• Linhas 19 – 25: Representa o cálculo da norma euclidiana para cada amostra de V′.
30 Capítulo 4. Processo de simulação
Algoritmo 3: Max-eigen difference (MED)
Entrada: V′ – Dados pseudo-reais comoutliers
Saída: outliermed – Vetor indicando o valor de MED para cada amostra
1 início
2 parai←1;i≤n;i←i+ 1 faça 3 M D←V′
−i;
4 mean1←colM eans(M D);
5 vardata1←var(M D);
6 avv.dados1←eigen(vardata1);
7 autoval1←eigen(vardata, only.values=T RU E$values); 8 autovet1←eigen(vardata, only.values=F ALSE$vectors); 9 AU T OV AL[i]←autoval[1];
10 AU T OV ET[, i]←autovet[,1]; 11 fim
12 P ROD←AU T OV AL[n+ 1]∗AU T OV ET[, n+ 1]; 13 parai←1;i≤n;i←i+ 1 faça
14 P ROD←AU T OV AL[i]∗AU T OV ET[, i]; 15 fim
16 parai←1;i≤n;i←i+ 1 faça
17 DIF ←P ROD[, i]−P ROD[, n+ 1]; 18 fim
19 parai←1;i≤n;i←i+ 1 faça
20 somadif←0;
21 paraj←1;i≤p;j←j+ 1 faça
22 somadif←somadif+ (DIF[i, j])2;
23 fim
24 norma[i]←sqrt(somadif); 25 fim
26 parai←1;i≤n;i←i+ 1 faça 27 paraj←1;i≤p;j←j+ 1 faça
28 y[i, j]←(t(V′i−mean)∗autovet[, j])2 ;
29 fim
30 fim
31 parai←1;i≤n;i←i+ 1 faça 32 paraj←1;i≤p;j←j+ 1 faça 33 sey[i, j]< autoval[j]então
34 indicador[i, j]←1;
35 fim
36 senão sey[i, j]≥autoval[j]então
37 indicador[i, j]←0;
38 fim
39 fim
40 fim
41 parai←1;i≤n;i←i+ 1 faça 42 produtorio[i]←1;
43 paraj←1;i≤p;j←j+ 1 faça
44 produtorio←produtorio∗indicador[i, j];
45 fim
46 d[i]←norma[i]∗(1−produtorio[i]); 47 fim
48 parai←1;i≤n;i←i+ 1 faça 49 somad←somad+d[i]; 50 fim
51 parai←1;i≤n;i←i+ 1 faça 52 outlier_med←d[i]/somad; 53 fim
4.3. Detecção dos outliers 31
• Linhas 41 – 47: Representa o cálculo do MED para cada amostra.
• Linhas 48 – 54: Representa o cálculo do MED padronizado para cada amostra.
Esse valor é obtido dividindo-se a distância de cada amostra pelo somatório de todas as distâncias do conjunto.
Assim, as amostras serão definidas comooutlier sempre que, seu valor de MED exceder a média ± desvio padrão do conjunto de valores do MED (outlier_med).
Os métodos empregados estavam reportando um elevado número de falsos po-sitivos, i.e., quando os dados normais são erroneamente classificados como outliers. Para reduzir esse número, convencionou-se que, os dados marcados como outliers pelos métodos utilizados, MVE, MCD e MED, só serão definitivamente classificados como outliers, após a passagem por um filtro. Esse, compara a amostra considerada com a mediana ± desvio padrão e, sempre que este valor for excedido, dos dados pré clas-sificados serão definitivamente marcados como outliers. A mediana foi escolhida por sofrer menor interferência das anomalias.
Algoritmo 4: Filtro baseado na mediana Entrada: Ψ– Candidatos aoutliers
Saída: V′′– Dados pseudo-reais após a remoção deoutleirs
1 início
2 m←median(V);
3 σ←sd(V);
4 para i←1;i≤n;i←i+ 1faça 5 seΨnfor candidato a outlierentão
6 f lag←0;
7 paraj←1;j ≤p;j←j+ 1faça
8 seV′i,j≥mj+σj então
9 f lag←f lag+ 1;
10 fim
11 senão seV′i,j≤mj−σj então
12 f lag←f lag+ 1;
13 fim
14 fim
15 sef lag >0então
16 remover(V′i,j);
17 fim
18 fim
19 fim
20 fim
32 Capítulo 4. Processo de simulação
• Linhas 2 e 3: Representa, respectivamente, o cálculo da mediana e do desvio
padrão dos dados com outliers. Para isso são utilizadas as funções madian() e sd(), ambas pertencentes ao stats do software R.
• Linha 4: Representa o laço utilizado para percorrer o número de amostras
consi-deradas, ou seja, o número de linhas da matriz de entrada (n).
• Linha 5: Representa o processo de verificação para comprovar se a amostra atual
foi marcada como candidata a outlier.
• Linha 7: Representa o laço utilizado para percorrer o número de variáveis consi-deradas (p), ou seja, o número de colunas da matriz de entrada.
• Linhas 8 – 13: Realiza a comparação da amostra atualmente analisada com o limite definido pelo filtro (mediana ± desvio padrão).
• Linha 15: Representa o processo de exclusão de uma amostra do conjunto ana-lisado. Esta exclusão é realizada sempre que uma ou mais variáveis de uma amostra estiver fora do padrão definido pelo filtro (mediana ± desvio padrão).
4.4
Representatividade dos dados
A representatividade, como discriminado na seção 3.5, é alcançada por intermédio de um ferramental estatístico composto pelo teste de hipótese ANOVA, o valor absoluto do erro relativo, a contagem deoutliers e as medidas de tendência central, representados, respectivamente porRbanova, Rbvaer,Rbcount e Rbcentral. A função chamada na linha 25 do
Algoritmo 1 é apresentada no Algoritmo 5.
Algoritmo 5: Análise de representatividade
Entrada: V′ – Dados pseudo-reais comoutliers
Entrada: V′′ – Dados pseudo-reais após remoção deoutliers Entrada: Vs – Dados pseudo-reais sem
outliers
Saída: Análise de representatividade dos resultados
1 início
2 Danova←Rbanova(Vs
,V′′,V′);
3 Dvaer ←Rbvaer(Vs
,V′′,V′);
4 Dcount←Rbcount(Vs
,V′′,V′);
5 Dcentral←Rbcentral(Vs
,V′′,V′);
6 fim
![Figura 2.1. Tipos de redes sem fio [Aquino, 2008].](https://thumb-eu.123doks.com/thumbv2/123dok_br/15756910.639006/28.892.114.765.141.552/figura-tipos-de-redes-sem-fio-aquino.webp)
![Figura 2.2. Componentes de um nó sensor [Aquino, 2008].](https://thumb-eu.123doks.com/thumbv2/123dok_br/15756910.639006/29.892.275.641.139.394/figura-componentes-de-um-nó-sensor-aquino.webp)
![Figura 2.3. Estrutura básica de uma rede de sensores [Aquino, 2008].](https://thumb-eu.123doks.com/thumbv2/123dok_br/15756910.639006/30.892.192.683.862.1057/figura-estrutura-básica-de-uma-rede-sensores-aquino.webp)