F
ACULDADE DEE
NGENHARIA DAU
NIVERSIDADE DOP
ORTODissecting Fact-Checking Systems:
The Impact of Evidence Extraction
Methods
Pedro José Lourenço Azevedo
Mestrado Integrado em Engenharia Informática e Computação Supervisor: Doctor Henrique Daniel de Avelar Lopes Cardoso
Second Supervisor: Gil Filipe da Rocha
Third Supervisor: Doctor Diego Nascimento Esteves da Silva
Dissecting Fact-Checking Systems:
The Impact of Evidence Extraction Methods
Pedro José Lourenço Azevedo
Mestrado Integrado em Engenharia Informática e Computação
Approved in oral examination by the committee:
Chair: Doctor João Pedro Carvalho Leal Mendes MoreiraExternal Examiner: Doctor Ricardo Daniel Santos Faro Marques Ribeiro Supervisor: Doctor Henrique Daniel de Avelar Lopes Cardoso
Abstract
In today’s society, with global access to the internet and online posting, we are provided with new information about any subject or topic on a daily basis. With free access on a global scale, it is easy for anyone to share virtually anything, giving raise to what is commonly identified as fake news. Fake news are typically shared with a bad intent, where although some people see them as true, they are actually based on unsustained claims.
Given how pervasive these issues are, automated systems can support users in processing such amounts of information and verify different sets of information. Fact-checking is an example of such systems, based on algorithms and common-sense rules, which aims to determine the truth value of claims.
The topic of fact-checking has captured much attention not only in media coverage, but also in many fields of research, such as natural language processing, knowledge extraction and ag-gregation, and computational journalism. From these initial efforts, several challenges have been proposed, as the Fact Extraction and Verification (FEVER) challenge is one such example. FEVER challenged teams to create a system which could retrieve evidence in order to make an assessment of a given claim based on Wikipedia documents.
This thesis explores the FEVER dataset and contributes to improving the DeFactoNLP system, one of the system participant on the FEVER challenge. This system is divided in three main task: Document Retrieval, Evidence Retrieval, and Label Classification. One ablation study of the system was conducted to evaluate the performance of each component in isolation as well as to assess the propagation of errors in the pipeline of tasks proposed in the DeFactoNLP system.
For the Document Retrieval task, it was found that a NER technique was not retrieving any document for 10% of the claims, and that improving the recall would impact the overall perfor-mance of the system. To address these issues, we used the Open Information Extraction technique with external data sources, and achieved state-of-the-art results. For the Evidence Retrieval task, our analysis show that a better precision and a fixed number of retrieved sentences have the po-tential to improve the overall system. We then propose a Triple-base model and explore two state-of-the-art approaches that leverage recent language models and Transformer-based architectures, using either a pairwise or pointwise methods. The results presented here show that the pointwise architecture performs the best, significantly improving the DeFactoNLP system. Through an error analysis, it was found that the presence of non-solved anaphoric references were negatively im-pacting the models in the Evidence Retrieval task. To tackle this issue, a new Wikipedia dump was created using coreference resolution state-of-the-art models to solve the corresponding anaphoric references. Training the proposed models in this dump had a positive impact, since all the models increased their performance.
Keywords: Fact Extraction, Fact Verification, Open Information Extraction, Natural Language Processing, Deep Learning, Artificial Intelligence, Information Retrieval
Resumo
Na sociedade de hoje, com acesso global à internet e à afixação online, é-nos fornecida diariamente nova informação sobre todos os assuntos ou tópicos. Com acesso gratuito a nível global, qualquer pessoa pode facilmente partilhar algo de forma virtual, aumentando a importância de um problema comummente apelidado de fake news (notícias falsas, em tradução livre). Estas notícias falsas são maioritariamente divulgadas com alegadas más intenções e, embora sejam encaradas por alguns como verdade, não são baseadas em factos reais.
Sendo esta questão muito preocupante, os sistemas automáticos podem ajudar a processar e filtrar informações, verificando e comparando-as com outros conjuntos de informações. Fact-checkingé um exemplo de um dos referidos sistemas, baseado em algoritmos e regras de senso comum, classificando uma afirmação como fidedigna ou não fidedigna.
O termo fact-ckecking tem captado muita atenção não só dos media, mas também de diver-sos campos de pesquisa, como o processamento de linguagem natural, extração e agregação de conhecimentos e jornalismo computacional. Desde o início que foram então propostas várias competições, sendo a mais emblemática a Extração e Verificação de Factos (FEVER). A FEVER desafiou equipas a criar um sistema que fosse capaz de retirar evidências, de forma a avaliar uma determinada afirmação utilizando documentos do Wikipedia.
Esta dissertação explora o conjunto de dados FEVER e contribui para melhorar o sistema DeFactoNLP, sendo este um dos sistemas que participaram na competição FEVER. Este sistema está dividido em três componentes principais: Extração de Documentos, Extração de Evidências e Classificação da Afirmação. Foi conduzido um estudo minucioso do sistema DeFactoNLP, para avaliar o desempenho de cada componente, bem como da propagação de erros pelas mesmas.
Em relação à componente de Extração de Documentos, verificou-se que a técnica NER não estava a extrair nenhum documento para 10% das afirmações e que melhorar o recall iria ter um impacto positivo no desempenho global do sistema. Para abordar estas questões, foi utilizada a téc-nica Open Information Extraction aliada a fontes de dados externas, obtendo resultados estado-de-arte. Na componente Extração de Evidências, a nossa análise demonstra que uma melhor precisão e um número fixo de frases recuperadas possibilitam melhorar o sistema global. Foi proposto um modelo baseado em Triplos e exploradas duas abordagens estados-de-arte que aproveitam mode-los linguísticos recentes e arquiteturas baseadas em Transformers, utilizando operações pairwise ou pointwise. Os resultados comprovam que a arquitetura tem o melhor desempenho, melhorando significativamente o sistema DeFactoNLP. Através de uma análise de erro, verificou-se que a pre-sença de referências anáfóricas não resolvidas estava a ter um impacto negativo nos modelos na tarefa de Extração de Evidências. Por conseguinte, foi criado um novo Wikipedia dump usando resolução de coreferências para resolver as referências anafóricas. Este novo Wikipedia dump teve
iv
um impacto positivo, uma vez que todos os modelos aumentaram o seu desempenho.
Palavras chave: Extração de Factos, Verificação de Factos, Open Information Extraction, Ex-tração da Informação, Processamento da Linguagem Natural, Aprendizagem Profunda, Inteligên-cia ArtifiInteligên-cial
Acknowledgements
Thanks to my family for all the support given.
I also want to thank my supervisors for their constant feedback and availability throughout the development of this entire document.
A big thank you to all the people who have always stood by my side and helped me during this process by actions, words or simply for being there.
Pedro Azevedo
“Every man has his secret sorrows which the world knows not, and often times we call a man cold when he is only sad.”
Henry Wadsworth Longfellow
“The best fights are the ones in which you don’t need to look for your strength. It’s just there”
Pedro José Lourenço Azevedo
Contents
1 Introduction 1 1.1 Motivation . . . 2 1.2 Objectives . . . 3 1.3 Scientific Contributions . . . 4 1.4 Document Structure . . . 5 2 Background 7 2.1 NLP before Data-Driven Models . . . 72.2 Basic Pipeline in NLP . . . 8
2.2.1 Tokenization . . . 9
2.2.2 Lemmatization and Stemming . . . 9
2.2.3 Part of Speech Tagging . . . 10
2.2.4 Parsing Trees . . . 11
2.3 Semantic Models and Word Embeddings . . . 12
2.4 Open Information Extraction . . . 15
2.5 Coreference Resolution . . . 16
3 Related Work on Fact-Checking 19 3.1 Information Retrieval . . . 19
3.2 Question Answering . . . 20
3.3 Challenges . . . 22
3.3.1 FEVER Challenge . . . 22
3.3.2 Other Challenges . . . 24
3.4 Automated Approaches on FEVER . . . 25
3.5 DeFactoNLP . . . 30
4 Ablation Study on DeFactoNLP 33 4.1 Document Retrieval . . . 34
4.2 Evidence Retrieval . . . 36
4.3 Label Classification . . . 36
4.4 Summary . . . 39
5 Improving Document Retrieval 41 5.1 Exploring OIE . . . 41
5.2 Tackling Ambiguity using Word Embeddings . . . 45
5.3 Narrowing Document Retrieval . . . 47
5.4 Exploring External Knowledge Sources . . . 49
5.5 Summary . . . 50
x CONTENTS
6 Improving Evidence Retrieval 51
6.1 OIE model . . . 51
6.2 Pairwise Evidence Retrieval . . . 54
6.3 Pointwise Evidence Retrieval . . . 57
6.4 The Impact of Coreference Resolution . . . 59
6.5 Summary . . . 61
7 Conclusions 63 7.1 Discussion of the Research Questions . . . 64
7.2 Lessons Taken and Future Work . . . 65
List of Figures
2.1 An example of a desired constituency tree [101] . . . 12
2.2 An example of a desired dependency tree [12] . . . 13
2.3 ELMo and BERT architectures [27] . . . 14
3.1 Framework of a QA system, adapted from (Bouziane, Bouchiha, Doumi and Malki, 2015) [1] . . . 21
3.2 FEVER example where it is needed two documents to make a label classification correctly . . . 24
3.3 DeFactoNLP system architecture [88] . . . 31
5.1 Visualization of the first three children in a Constituency Parsing Tree. . . 43
5.2 Constituency Parsing Tree visualization - subject extraction. . . 43
5.3 Constituency Parsing Tree visualization - relation extraction. . . 44
5.4 Constituency Parsing Tree visualization - object extraction. . . 44
5.5 Page views of the disambiguated documents. In the left the document name. In the right the page views. . . 48
6.1 Pairwise Architecture to produce similarity score between a claim and a sentence. 55 6.2 Pointwise Architecture to produce similarity score between a claim and a sentence. 58 6.3 A comparison of the number of page views (y axis) between the document “Ernest Medina” in blue and “Command Responsibility” in green during the period of Jan 2017 and May 2020 (x axis). Source fromhttps://pageviews.toolforge. org . . . 60
List of Tables
2.1 Tags proposed in the Penn Treebank [71] . . . 11
2.2 Comparison between different systems by AUC on OIE20161corpus . . . 16
3.1 Rate of sentences needed to prove a claim . . . 25
3.2 Final results achieved in FEVER 1.0 Shared Task . . . 26
4.1 DeFactoNLP baseline - Document Retrieval . . . 35
4.2 DeFactoNLPbaseline - Evidence Retrieval . . . 36
4.3 DeFactoNLPbaseline - Label Classification . . . 38
4.4 DeFactoNLPbaseline - Label Classification with TF-IDF as input . . . 38
4.5 DeFactoNLP baseline - Label Classification with TF-IDF as input and Random Forest classifier retrained . . . 38
5.1 Results of Document Retrieval using OIE . . . 45
5.2 Results of Document Retrieval Tackling Ambiguations . . . 47
5.3 Results of Narrowing Document Retrieval . . . 49
5.4 Results of Narrowing Document Retrieval with TF-IDF . . . 49
5.5 Results of Mediawiki API for Document Retrieval . . . 50
6.1 Triple-based Extraction Features . . . 52
6.2 Results for Evidence Retrieval based on Triple-Based model (TB) . . . 53
6.3 Results on the Label Classification based on Triple-Based model (TB) . . . 54
6.4 Results on the Evidence Retrieval using Pairwise approach . . . 56
6.5 Results of Label Classification using the Pairwise Model . . . 56
6.6 Results on the Evidence Retrieval using the Pointwise Model. . . 57
6.7 Results of Label Classification using the Pointwise Model. . . 58
6.8 Results of Evidence Retrieval with the Coreference Resolution Wikipedia dump . 60
6.9 Results of Label Classification with the Coreference Resolution Wikipedia dump 61
Abbreviations
FEVER Fact Extraction and VERification
TF-IDF Term Frequency-Inverse Document Frequency NER Name Entity Recognition
OIE Open Information Extraction RF Random Forest
TB Triple-Based
RTE Recognizing Textual Entailment NLP Natural Language Processing API Application Programming Interface AM Argumentation Mining
HMM Hidden Markov Model IR Information Retrieval POS Part-Of-Speech QA Question Answering CR Coreference Resolution CRF Conditional Random Fields
Chapter 1
Introduction
In different research areas, a fact may have distinctive meanings. In philosophy, facts may be perceived as information that one can use to prove a sentence as a true sentence [49]. In law, facts are the information in which lawyers base their arguments, and those facts are, in turn, based on evidence, which has been already proven [105]. In science, a fact is something extracted based on experiments. In all of these areas, there is something in common: there must be something to prove a particular fact, not making any prompt assessment on some perspective or conclusion.
In people’s daily lives, the ability to include facts into their speech is something that cannot be neglected. An important question arises: Are those facts true? This question can only be answered by presenting at least one evidence. Using proven facts can make a speech much stronger, whether in argumentative texts or debates, in a political context or otherwise. Being able to disprove a person’s statement, based upon specific evidence is a powerful weapon to win argumentative situations as the ones illustrated before. In this work, a fact is considered a statement or assertion of verified information about something that exists or has occurred. This must be followed by an evidence that can either prove or disprove the fact.
Internet browsing is becoming a common activity in most people’s every-day life. Web search usage has been increasing more and more throughout time, with keyword-based access to find documents providing information at all levels. The most used website is Google.com with billions of monthly visits, next comes YouTube.com close to 24 billion, and Facebook.com with almost 20 billion [99]. Regarding the use of Facebook and other social networks, a person that writes any kind of information can reach millions of people within hours [2]. In 2016, Google and Facebook employed models preventing a spread of fake news in their advertising services showing only true news and information [120]. Although this was promising news, Google cannot ensure that the information on the documents provided is all true, because of the lack of mechanisms to do so. Also, the information provided for each of Facebook’s users is chosen mainly by the user because the presented information is based on their user friends and Facebook is being used more and more as a source of information [77].
2 Introduction
However, any piece of information may or may not be true, and this can cause a change in people’s attitudes, including voting intentions [40]. Adding to a recent study which finds that false news spread more quickly than true ones [115], the ability to verify the truthfulness of a fact (e.g., by finding evidence from reliable sources) becomes essential in any public website. In the journalistic field, the number of requests to automate this process is very significant [22,4,41].
1.1
Motivation
When a statement is established forward as a fact, there is always the question of its veracity. To aggravate the situation, there is rarely information or sources proving the alleged fact or how it was inferred. Checking a statement manually may take from hours to a few days depending on the complexity of its facts [46]. This process is usually carried out by professionals who, at a first instance, will have to understand the statement and verify its source and what it refers to. Then, they will have to look for previous facts, such as analyzing whole speeches, debates, legislation, among others, in order to extract as much information as possible to form evidence. Only after this process is concluded, it is possible to make an assessment of the statement and turn it into a proven fact.
The manual work of fact-checking is very exhaustive. As for its automation, it is still necessary to overcome several challenges that are explained by Sarr et al. [95]. Some of these challenges intersect with those in some specific aspects of Natural Language Processing (NLP), a field ad-dressing the ability of a machine to read and process text:
• The subjectivity of reliability: Reliability or trust is something that is built over time. Assessing information source over time depends on who assessed the facts before. It also remains a question of whether source consistency of reliability is maintained;
• Unstructured data: All information is presented differently. However, it is known that unstructured data contains more information than structured data. With this, it is necessary to create a robust mechanism for the extraction of information, wherever it is and however it may appear;
• The temporal aspect of the reliability and the lack of sources: When time is considered, checking a fact becomes even more problematic because of having to know when something was, is or will be true. Not knowing the precedent and origin of the source of information, puts a question mark over the reliability of the fact;
• The semantics of sentences: People who write texts never write it in the same way. Often sentences are not written with the right structure. Despite the advances of NLP in this area, it cannot fill and detect all the variations and imperfections that a human may have. Therefore, to check something, since it is necessary to extract information from different sources, the format of the text, the structure of a sentence, and numbers of errors of the information will appear in different ways. This will complicate the whole process of fact-checking;
1.2 Objectives 3
• The identification of factual facts: A factual fact will always be true, therefore timeless. Its use should be a priority, but it is not always of interest. Evaluating a sentence as a factual fact can create an increase in optimization in future iterations as a better identification of important facts, since there is no need for to check the temporal aspect of the fact;
• The real time and speed of information spreading: The information continues to grow exponentially. For a human fact-checker, keeping up with this constant overwhelming flow of information can make a person’s work obsolete and irrelevant [47]. The speed with which news and information are passed between people, for example, due to the use of social networks, there is an increase of interest for users to be able to check, in real time, the information presented;
• The format in Edition: An engaging source of information can be the articles of public opinion. Newspapers publish many argumentative texts, on the Internet a lot of texts are published and presented. However, none of them follow a basic rule of information, also called meta-data. The information presented generally displays only three fields: the author, the title and the text. However, other types of information are also very important, such as the date of publication, information regarding the author, what sources the author used, among others;
• Relation between evidence: For a statement to be verified, just one piece of evidence is often not enough, proving necessary a whole set of evidence to verify the statement. This presents a challenge because it may be necessary to connect several pieces of evidence and determine which may depend on another and how they relate to a statement.
These challenges are all authentic, and the need to overcome them is increasing in interest. One phenomenon that has seen an increase, in social networks, is fake news. This arises from the growth in the amount of information that is passed on. With information also comes mis-information (the creation of rumours) [73], astroturfing (the veiling of a message or movement sponsored by a company or enterprise, but leading people into thinking it was a community ef-fort) [87], spam (referred to as electronic junk) [24] and outright fraud (very similar to phishing by impersonating a trustworthy third party) [52]. In this way, fact extraction and fact verification areas are growing, and more than ever a demand from different business areas and enterprises arises becoming a perspicuous motivation to surpass the main fact-checking challenges.
1.2
Objectives
The main objective addressed in this dissertation is to create an ablation study of a fact-checking system and, by identifying the flaws, to improve the system using different Evidence Extrac-tion methods. The technical goal is to identify at least one evidence, allowing the assessment of a given claim by retrieving information from unstructured data. Therefore, if an evidence is found to support a claim, the claim will become a fact.
4 Introduction
Fact-Checking systems currently consist of three main steps and each step has his own objec-tive:
• Document Retrieval – through a given statement, lies the ability to find documents that are likely to contain information relevant to the fact. Improve this step using a complete semantic and syntactic analysis of the fact and enabling a computing relation with relevant retrieved documents.
• Evidence Retrieval – through an analysis of the documents content, lies the ability to re-trieve possible evidences for the fact. Improve this step by creating a rank system to evaluate how fitting is the evidence to be able to verify a statement.
• Label Classification – through the statement and the extracted evidence, verify the veracity of the fact. Create metrics to evaluate the overall system being able to verify, besides the label given and the evidence retrieved, if the label of the fact is based on the provided evidence.
Each of these three steps are treated independently, allowing a separation. By doing so, the evaluation mechanisms for each of the phases undertaken will be addressed in this dissertation. This stems from the fact that, for the most part, evaluation methods only exist at the end of a system. Yoneda et al. [127] noticed that retrieving evidence that can refute a fact is harder than retrieving a supporting one. This happens due to the lack of similarity between facts and evidence. Therefore, a separate assessment for different types of facts should be considered carefully to always have a balance between refutable and verifiable facts.
A well-known issue of pipeline architectures is the propagation of errors. Reporting scores on the final outcome of the system without studying the performance of underlying components may hide problems in earlier stages, thus potentially degrading the overall performance. Therefore, the fundamental research questions explored in this dissertation are as follows:
• How each fact-checking system component can impact the overall performance?
• Can Open Information Extraction methods be used to help retrieve documents and possible evidence?
• Are transformer-based models, the state-of-the-art in NLP, able to outperform Open Infor-mation extraction methods?
1.3
Scientific Contributions
In this dissertation, one of the proposed systems – DeFactoNLP [88], which achieved the fifth place in Evidence F1 Score at the FEVER 1.0 Shared Task1– is dissected, and an ablation study
1.4 Document Structure 5
is performed to obtain concrete insights on the impact that each component has in the overall per-formance. Based on the ablation study, the Document Retrieval and Evidence Retrieval stages are improved by re-designing them using and applying Evidence Extraction Methods, such as Open Information Extraction and transformer-based models. Therefore, the main scientific contributions of this dissertation are:
• An Ablation Study on the importance of the different metrics in the different stages of the system was assessed.
• In the Document Retrieval task, after a thorough search of the current literature, the state-of-the-art is achieved.
• In the Evidence Retrieval task, is provided how different approaches can help improving evidence retrieval.
• A new dataset dump based on the provided dataset [110], which improves the performance of the models.
1.4
Document Structure
The remainder of this dissertation is structured as follows:
In chapter2 a background of the main topics in Natural Language Processing are presented related to this dissertation.
In chapter3the main stages of a fact checking system are described, making the connection between different research areas and the datasets that can evaluate the developed systems on fact-checking. In the end, the core systems are described in detail.
Chapter4dissects the DeFactoNLP system, evaluating every stage. The chapter is divided into three sections, each one representing a task: Document Retrieval (Section4.1), Evidence Retrieval (Section4.2), and Label Classification (Section4.3).
Chapter 5includes the first system improvement, where the Document Retrieval task is re-designed. This chapter is divided into four sections, representing different approaches, each one motivated by an error analysis or some limitation of the previous approaches.
Chapter6includes the second system improvement, where the Evidence Retrieval task is re-designed. Different models are explored, and the impact on those models in the end-to-end system is shown.
Chapter7points the main conclusions withdrawn from this work and pinpoints some lines of future work.
Chapter 2
Background
Natural Language Processing, also known as NLP, is a branch of Artificial Intelligence that at-tempts to unify, communication, either written or spoken, between the computer and the human through computational linguistic methods. Thus, a machine tries to learn and manipulate a text or speech [18][23] for a given purpose. Many applications are already based on NLP, for example, to make a summary of a text [34], the construction of generic or domain-specific chatbots, structuring of argumentative texts [92], question answering, among many other applications.
In this chapter, the background of the most relevant topics for this dissertation will be pre-sented. Each section will start to give a definition of the topic and a brief history of it and, finally, a brief analysis of the topics strengths and applications. Section2.1starts with a brief historical context focusing on the most significant applications in the Natural Language Processing (NLP) field. All of those applications, including the most recent ones, usually follow several text trans-formations as explained in Section2.2. Section2.3focus on how to represent words in a certain vector space, and how such methods can be combined to represent sentences. Then, this chapter focuses on more specific tasks such as Open Information Retrieval (OIE) and Coreference Resolu-tion (CR). In SecResolu-tion2.4, OIE is presented with an analysis of the relevant literature by explaining each system, comparing their performances, and highlighting the positive aspects. In Section2.5, the theoretical aspect of the Coreference Resolution is explored. A thorough analysis of the rele-vant literature on Fact-Checking systems revealed that, to the best of our knowledge, Coreference Resolution has never been used. However, in this dissertation, this technique is employed as an attempt to improve the performance of fact-checking, more specifically in the Evidence Extraction and Label Classification stages.
2.1
NLP before Data-Driven Models
The first effort for a machine to be able to interpret text began around the 1960s. The two most significant systems were designed to bring about a revolution in the area: ELIZA (1966) [118] and
8 Background
SHRDLU (1971) [121].
ELIZA was developed at MIT Artificial Intelligence Laboratory by Joseph Weizenbaum. The main goal was the creation of a conversation between a machine and a human. The conversation is carried out by the recognition of specific keywords. Through them, a set of questions are formu-lated that were already defined. One of the most positive aspects of this system was the beginning of keyword recognition, context recognition by changing sentences to include keywords or even if keywords are not identified, the ability to change sentences to be relevant in the context of the conversation.
SHRDLU was a system, also developed in MIT, that supported commands obtained from a conversation with the user. Those commands would be executed in a world with objects, making them move, giving names to the objects, and even reporting the state of the world. Through the use of adjectives, the system can identify different objects. Through the use of verbs, the system can recognize actions. Another fundamental aspect was also a memory system for the system to know the last actions and know names given to objects to simplify conversations and identification.
These two programs have created a wave of optimism for the creation of new solutions to retrieve information from text. However, their application in the real-world has not been very suc-cessful due to the ambiguity of natural language. Since then, an area of research called generative grammars has begun to grow. This area focuses on the creation of rules that allow all the possi-bilities of correctly constructing a sentence. Hence, Chomsky proposed a new way of describing natural language called Transformational Grammar, where each sentence can be represented in two aspects: a deep structure representing all the semantic relations, and a surface structure that can be expressed with transformations [16,15].
Natural language began to be represented by rules deeply explored throughout the 1980s. Thus a need was created to find a way to structure information, that is, structured knowledge bases, namely ontologies proposed by Gruber in 1991 [43]. Ontologies contain information about things from a given domain, organized in taxonomies, and linked together through properties [113]. This line of research was explored during the 1990s, enabling the creation of Knowledge Graphs that can be described as large ontologies. However, other contributors have pointed out that knowledge graphs are somehow superior to ontologies and provide additional features [30].
All of this enabled machine learning algorithms to influence Natural Language Processing shifting the focus of NLP tasks to reach data-driven solutions. Collobert et al. [23] presented one of the first works using deep learning, creating an attempt to generalize the four main tasks of NLP: part-of-speech tagging, chunking, named entity recognition, and semantic role labeling. It used a neural network architecture, achieving baselines for those tasks.
2.2
Basic Pipeline in NLP
When analyzing sentences, it is necessary to develop mechanisms that enable a machine to under-stand them. Furthermore, a machine also needs to analyze the different words and the relationships between them. There is no single or general pipeline since it will always be different to fulfill the
2.2 Basic Pipeline in NLP 9
primary goal. However, over time, numerous techniques have been developed to process the texts presented efficiently. The main objective of these techniques, when placed sequentially, is the generation of a text with less noise or, even more important, the ability to create features for the different models of Machine Learning. Thus, this section will present the most common steps in a pipeline to perform a successful text treatment and an analysis of the sentences in a text such as tokenization, lemmatization and stemming, part-of-speech tagging and parsing trees.
2.2.1 Tokenization
The first step that almost all pipelines begin with is a process of tokenization. This process refers to the ability to, given a text, separate it into different words, that have come to be called tokens. If a space is considered as a word boundary, this task may seem trivial. Although several exceptions can occur, these same exceptions can be different and specific for each language. Following, some of those exceptions are stated:
• Some nouns, if separated into different tokens, will have no meaning or will just be redun-dant. For example, the city Los Angeles would be separated into two different tokens, but it is convenient not to do it. The reason is not to lose the meaning of the name of the city. • There are words that are not always separated by space, but by hyphens, being called
com-pound adjectives or nouns. The word off-state can also be written without the hyphen being the separation of sentences by spaces not enough. In Germany, compound nouns are written in the same word without any separation, becoming a challenging task where and when to divide them.
• In a text, a period generally means the end of the sentence. It is the same as a sentence boundary. However, the period can also be used for abbreviations or acronyms, so it should not be separated into different tokens.
In this regard, all the main NLP libraries have their tokenizer module or use specific libraries whose only goal is to tokenize. A set of regular expressions is the primary way that those libraries create tokens. Stanford Penn Treebank Tokenizer, from The Stanford CoreNLP library [70], has a slightly different approach. It uses a finite automaton, with heuristics to decide when and where to split.
2.2.2 Lemmatization and Stemming
While words may have the same meaning, others may belong to the same word family. This hap-pens because one word may contain different forms (work, works, working). In some specific areas, such as Information Retrieval, the probability of finding documents decreases with the in-creasing of vocabulary. In general, by removing the suffixes, keeps the essential information from words. On the other hand, prefixes are not common to be removed because they may represent the denial function. Altering the words in a text can make a crucial step in an NLP pipeline. So,
10 Background
if different words contain the same word, it is necessary to find ways to reduce the vocabulary by modifying words that belong to the same word family or share the same root. This way, there are two main processes to deal with this: lemmatization and stemming.
According to Oxford University Press1(OUP), a lemma is “a heading indicating the subject or argument of a literary composition, an annotation, or a dictionary entry.”. Transforming words to their lemma will induce removal of all suffixes and prefixes and even the complete modification of certain words (better -> good). For this process to be possible, it is necessary to create word pairs that can create these same relationships: (inflicted form, lemma).
Stemming does not always originate valid words, so unlike lemmatization, it does not need a prior language vocabulary, although the rules are different from language to language. Through the creation of rules, the central concept is to be able to transform the suffixes and prefixes of the word into something different. The first known stemming algorithm was created by Lovins [66], having an extensive set of rules. However, this was primarily surpassed by Porters stemmer [84], which is the most commonly used, and Paice’s algorithm [80].
Sometimes, Part of Speech Tagging is used before lemmatization because it can alter the pro-cess by knowing the part of speech of the word.
2.2.3 Part of Speech Tagging
Part of speech (POS) tagging and named entity recognition can be complemented to perform specific tagging for each word [76]. However, the recognition of entities by specifying their type (person, country, date) does not help as much as POS for the steps of different pipelines. Part of speech can be used as a feature by selecting the word senses from WordNet [75]. However, a different tagging may depend on the corpus or language used. The two most commonly used corpora for English are the Brown corpus [36] and the Penn Treebank [71]. The latter is the most common. An overview of the tags used by the Penn Treebank is presented in Table2.1.
Hidden Markov Model (HMM) [6] is a solution for performing POS tagging. This solution is based on a simplification of a Bayesian network where each observed state has a corresponding hidden state depending only on the previous hidden state.
By creating a simple POS tagging model, it is possible to achieve 90% accuracy [10]. This accuracy is possible because most English words have only one possible match. This value is reached only by analyzing a corpus and, for words that contain more than one possible tag, the most common is selected. For unknown words, the proper noun is used. 90% can seem a very high value; however, if only considering words that may have more than one tag, the value would be lower. Using Hidden Markov models as a base, the POS tagging system obtains about 95% ac-curacy [97]. With this result, a Second Order HMM was proposed reaching 96% accuracy making use of more contextual information than standard statistical systems for the approximations used in the second-order [108].
2.2 Basic Pipeline in NLP 11
Table 2.1: Tags proposed in the Penn Treebank [71]
Tag Description Example Tag Description Example
CC coord. conjunction and, or RB adverb extremely
CD cardinal number one, two RBR adverb, comparative never
DT determiner a, the RBS adverb, superlative fastest
EX existential there there RP particle up, o
FW foreign word noire SYM symbol +, %
IN preposition or subconjunction of, in TO “to” to
JJ adjective small UH interjection oops, oh
JJR adject., comparative smaller VB verb, base form fly
JJS adject., superlative smallest VBD verb, past tense flew
LS list item marker 1, one VBG verb, gerund flying
MD modal can, could VBN verb, past participle flown
NN noun, singular or mass dog VBP verb, non-3sg pres fly
NNS noun, plural dogs VBZ verb, 3sg pres flies
NNP proper noun, sing. London WDT wh-determiner which, that
NNPS proper noun, plural Azores WP wh-pronoun who, what
PDT predeterminer both, lot of WP$ possessive wh- whose
POS possessive ending ’s WRB wh-adverb where, how
PRP personal pronoun he, she
With the appearance of deep learning techniques, by using state of the art models, it was pos-sible to achieve 97% accuracy with Conditional Random Fields (CRF) with structure regulariza-tion [107]. By creating an ensemble between CRF and a bidirectional Long Short Term Memory (BI-LSTM) the model achieved the state of the art results in POS Tagging [51].
2.2.4 Parsing Trees
All the steps described so far analyze natural language without worrying about the order in which words appear in a sentence. However, understanding the relationship between words is a task in which syntactic parsing focuses on. This task creates word links through the generation of trees. It is a mediation between linguistic expression and meaning.
Constituency trees subdivide a sentence into several sub-sentences. Similar to a binary tree, a node can be subdivided up to two nodes. Generally, the first nodes of the tree consist of a noun phrase (NP), a verbal phrase (VP), and a prepositional phrase (PP). The leaves will contain the words of the sentence and its part of speech tag. Thus, it is possible to state that this type of tree groups different words that together have a meaning in the sentence. In Fig2.1, an example of a constituency tree is shown, for the phrase He eats spaghetti with meat. It is possible to infer, with a depth first search, that VP eats relates the NP He and the NP spaghetti.
Unlike constituency trees, dependency trees may not relate all the words. However, rela-tionships are created where the nodes are the words, and the edges represent those relations that indicate direct links between words, labeled as syntactic relations. In Fig2.2, an example of a dependency tree is shown, for the phrase He has good control..
12 Background
Figure 2.1: An example of a desired constituency tree [101]
2.3
Semantic Models and Word Embeddings
A machine learning model needs features, and these same features have to be, mainly, in numerical values, and the first need arises: the ability to transform the text into numbers to function as input for the models.
One of the most known transformation methods is Bag-of-Words (BoW). This transformation needs, in a first instance, a vocabulary and, through it, count the frequency of each word. Although it is simple, it can undoubtedly get better results through the lemmatization of words. This hap-pens since BoW generates sparse vectors due to a large vocabulary. Lemmatization reduces the vocabulary size, hence, the BoW model generates more concise vectors. Another way to improve is to reduce vocabulary by removing stop-words or even removing words with almost one or a non-substantial frequency. Another very well known transformation is called Term Frequency-Inverse Document Frequency (TF-IDF). TF-IDF allows normalizing the frequency of words in a whole corpus [69].
Although these are reasonable solutions to relatively simple problems, in the area of Informa-tion ExtracInforma-tion, the need to find similar phrases or words is imperative. For example, the sentence “A student got great grades” can also be written as “A graduate obtained good classifications”. Analyzing the words by their frequency will indicate a nearly zero match due to the lack of com-mon words. In this way, it should be possible to present words in the form of vectors to capture semantic relationships. Representing words or texts as numerical vectors is called word embed-dings. Thus, some unsupervised methods, to represent documents in a certain vector space, are
2.3 Semantic Models and Word Embeddings 13
Figure 2.2: An example of a desired dependency tree [12]
based on word frequency in documents, but especially on their co-occurrence:
• Latent Semantic Analysis (LSA) [59] is a method based on the construction of matrices for each document in a certain corpus. These matrices count the number of occurrences of certain words. A mathematical method called singular value decomposition (SVD) is used to reduce the number of rows. LSA also assumes that if similar pieces of text contain the same words, those words have a close meaning. By performing this matrix construction, it is possible to evaluate how similar the documents are.
• Latent Dirichlet Allocation (LDA) [7] is based on the explanation of the similarity be-tween documents through latent topics. Thus, a generative probabilistic model will observe documents finding relationships between words to create these latent topics to represent the information in the best way.
• Word2vec [74] is based on a feed-forward neural network capable of training word embed-dings. The result of this model is the probabilistic prediction of a word appearing in a given context window. It is one of the most popular models when creating relationships between similar words and, through each word being represented in a multidimensional space, can find similar semantic value. For example, the words king and queen would be at the same distance as men and women.
• GloVe [82] differentiates of the word2vec model by creating a global co-occurrence matrix. GloVe embeddings are achieved by estimating, given a word, the probability if it will co-occur with other words. This presence of global information makes GloVe embeddings ideal for tasks such as word analogy, word similarity, and named entity recognition. However, the best benefit is that the training process is faster than word2vec. In order to compete with GloVe embeddings, a faster word2vec was created named FastText [8] that also can compute vectors for unknown vocabulary. This is possible since FastText word vector is built from subwords of words and also from substrings of characters. If the input contains misspelled words or even unknown words, this will still manage to build vectors.
14 Background
• ELMo (Embeddings from Language Models) [83] generates the vectors for word represen-tation using Recurrent Neural Networks (RNN), more specifically Long Short Term Mem-ory (LSTM) units, rather than a feed-forward neural network such as used in Word2vec. LSTM has the main advantage of being able to solve dependencies efficiently. In Peters et al. [83] it is proposed to use bidirectional LSTM, using two LSTM: a forward one (left to right) and a backward one (right to left). These are concatenated at the end in the architecture generating the final embeddings. This type of architecture allowed us to start representing context-based sentences, thus increasing performance in major NLP tasks such as Question Answering, Co-reference Resolution, and Translation. ESIM model [14], enhanced sequen-tial inference model, is based on LSTMs chains, carefully designed sequensequen-tial inference model.
• BERT (Bidirectional Encoder Representations from Transformers) [27] was trained through the unlabelled data use of Wikipedia, containing about 2,500 million words and in a cor-pus of several books, containing about 800 million words. The BERT model is based on Sequence to Sequence models, consisting of two self-attention units: an Encoder and a De-coder. Unlike ELMo Embeddings, the contexts left to right and right to left are dependent on each other. In Figure2.3, it is possible to notice the difference between BERT and ELMo model architectures, highlighting the contextualization differences. Looking at the GLUE Benchmark [116], BERT achieved state-of-the-art results in over 20 tasks. Several models were created based on BERT’s architecture, such as AlBERT [58] and RoBERTa [65]. The pre-trained model is done by using a special token [MASK], which never occurs in the fine-tuning stage. This leads to one of the big problems of these models: a constant need for a fine-tuning for every specific task to achieve good results.
2.4 Open Information Extraction 15
2.4
Open Information Extraction
Open Information Extraction (OIE), as a research field, was firstly presented in 2007 by Banko et al. [5]. This research area aims to extract relations from a sentences creating tuples of information. Thus, information in natural language text can be represented in a structured way using verbal phrases and their arguments. In its purest form, given a natural language sentence, OIE techniques can extract information forming tuples in the form of a triple, consisting of subject (S), relation (R) and object (O).
Suppose we have the following input sentence:
AMD, which is based in the U.S., is a technology company.
It is possible to extract the two following triples:
("AMD"; "is based in"; "U.S.") ("AMD"; "is"; "technology company")
The formation of Triples can be achieved by specific algorithms using Dependency Parse trees [93, 54]. The general work of these algorithms, with a Dependency Parse Tree, through a depth first search, is to find nouns, verbs, and adjectives obtaining relations between them.
The first Open Information Extraction system using self-supervised learning was presented in 2007, called TextRunner [126]. ReVerb, an OIE software, introduced two new constraints: syn-tactic, that eliminates incoherent and uninformative extractions, and lexical, that separates valid relation phrases from an overly-specific relation [33]. OLLIE [96] was presented in 2012 based on ReVerb, making several improvements. The system’s main features are the extraction of rela-tions mediated by nouns, adjectives, and more by learning extraction patterns. ClaussIE [26], as the name suggests, proposes an approach through clauses. Thus, the sentences are divided into clauses, and the type of clause presented can be identified. OpenIE4 [72] ensembles all the pre-vious techniques into one having as base the work develop in OLLIE. Using ClausIE as the base, MinIE’s [38] main contribution was to mitigate overly-specific relations. This contribution has lead to a noise removal, achieving state-of-the-art scores. RnnOIE [104] used a BiLSTM and IOB (Inside–outside–beginning) tagging. Seq2seq OIE [25] used a sequence to sequence model and a copy mechanism achieves similar scores by using state-of-the-art models in Open IE task.
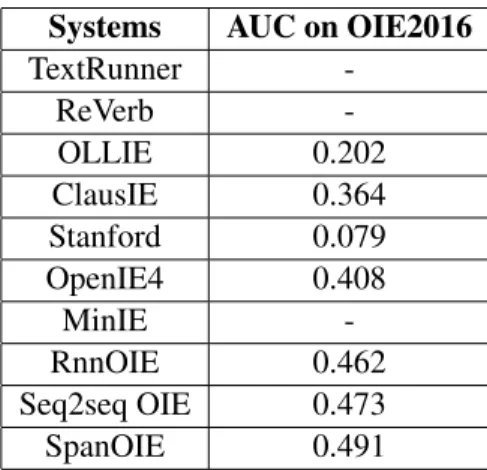
In Table 2.2 comparison values obtained by Zhan et el. [129] on the most recent OpenIE systems are presented. A benchmark was created for Open Information Extraction [103], where the scores are based on area Under the Receiver Operating Characteristic Curve (AUC) on the OIE2016 corpus.
16 Background
Table 2.2: Comparison between different systems by AUC on OIE20162corpus Systems AUC on OIE2016
TextRunner -ReVerb -OLLIE 0.202 ClausIE 0.364 Stanford 0.079 OpenIE4 0.408 MinIE -RnnOIE 0.462 Seq2seq OIE 0.473 SpanOIE 0.491
2.5
Coreference Resolution
A document generally contains more than one sentence. Thus, each sentence can be contained within a given context. As mentioned in Section2.3, allowing models capture a sense of context into the sentence (through models such as ELMo and BERT) brought state-of-the-art improve-ments in almost all NLP tasks. This need for context is relevant because of the many different forms and types of reference outside of a sentence that the model can not handle as input.
There are several types of references in the English language that make Coreference Resolution extremely complex. In Sukthanker et al. [106] 8 types of references are presented:
• Zero Anaphora is a reference that assumes a kind of listing. For example, in the sentence: Pedro always carries 3 things (1):, his laptop (2), his mobile phone (3), his keys(4). It is possible to notice that (1) it refers to 3-anaphors;
• One Anaphora is a type of reference when it is used a similar expression such that one, where the demonstrative varies and the word one is maintained;
• Demonstratives, in general, assumes a comparison with something that appeared before. For example, when demonstratives are used like than, that;
• Presuppositions is a type of reference often used with the pronouns anybody, everyone, amoung others. This kind of reference can be very ambiguous. For example:If someone (1) can do the task, it is him (2);
• Discontinuous Sets assume, similarly to Zero Anaphora, that the pronoun may refer to more than one antecedent. For example, when using the pronoun they, it can refer to Pedro and Gisela;
• Pronominal Anaphora is the most common reference used in everyday life, newspapers, and magazines. It can be divided into three major types: Indefinitive, Definitive and Adjec-tival Pronominals. For example: Pedro is happy. He got a console. the antecedent is Pedro and the anaphoric expression is He.
2.5 Coreference Resolution 17
• Cataphora is also known as the opposite of anaphora. In this kind of reference, the anaphoric reference happens before: He (1) was so generous to bring the dog, although Pedro (2) did not need to do it.
• Inferable or Bridging Anaphora is one of the most ambiguous references because an un-derstanding of context or previous knowledge is not necessary. For example, in the sentence Pedro wanted to buy a pair of jeans (1), but he noticed a defective in the pockets. (2), (2) refers to (1), not directly, but by making background assumptions.
Since early on, the first algorithms, for coreference resolution, were created in 1978 [48] that used parse tree analysis to create rules capable of solving pronouns in the sentence. In 1974 [60], a system was developed a system using logic programming to analyze the sentences presented to discover noun phrase antecedents syntactically. Today, deep learning models are used for corefer-ence resolution [122,20] reaching state-of-the-art in the area.
Chapter 3
Related Work on Fact-Checking
Fact-checking, associated with Natural Language Processing, is a cluster of several NLP research areas allowing to create robust end-to-end systems. Thus, this chapter will start by focusing on the two main components that generally incorporate a pipeline of fact-checking (Information Retrieval and Question Answering), followed by the main challenges of executing such pipelines. The first component, Information Retrieval, is presented in Section3.1and studies on how to find and rank by relevance useful information in a given data store. Hence, it is an important component for Document Retrievaland Evidence Retrieval tasks. The second component is Question Answering, and is presented in Section3.2. This section will explain how to analyse and extract information from a given question (i.e., claim) and corresponding answers (i.e., evidence). Finally, the dataset used in this dissertation will be explained, in SubSection3.3.1, as well as current state-of-the-art approaches that explore it, in Section3.4.
3.1
Information Retrieval
Information Retrieval (IR) is an area that studies mechanisms that can identify and rank infor-mation. This area is evaluated by, through an analysis of a given query, the ability to retrieve unstructured text that is relevant to the query. At the moment, a crucial step is the ability to map words in vectors with algebra models. Thus, this mapping enables the evaluation of the produced vectors with a similarity between a query and text through cosine-similarity [94]. Named En-tity Normalization can resolve many problems in end-to-end information access tasks [56]. This means that the ability to disambiguate names like Bush as a person or Bush as a plant is a cru-cial task and can solve many issues found in Information Retrieval tasks. Also, focusing only on entities automatically neglects stop-words.
New approaches focus mainly on calculating the likelihood of a query being close to a docu-ment and thus presenting a docudocu-ment ranking. However, this ranking is extremely sensitive to a parameter called smoothing [128]. Smoothing adjusts the maximum likelihood estimator in order
20 Related Work on Fact-Checking
to mitigate the data sparseness that provokes inaccuracy. This is very important when working with unknown sources.
There are many metrics to evaluate different IR mechanisms:
• Precision evaluates the capacity if the retrieved documents are correct, being important to assess if the top-ranked documents were retrieved correctly.
precision= relevant_documents ∩ retrieved_documents retrieved_documents
• On the other hand, Recall assesses the ability if the relevant documents are retrieved. This metric is vital for assessing sensitivity, mainly when thresholds are used.
recall= relevant_documents ∩ retrieved_documents relevant_documents
• Fall-out (Noise) is one of the most interesting metrics since evaluates the number of wrong documents that have been retrieved. This metric can be easily fooled if zero documents are retrieved. However, the higher this metric is, the more noise is being retrieved.
noise=
non− relevant_documents ∩ retrieved_documents non− relevant_documents
• Discounted cumulative gain is a metric which, if any document related to the query has not been removed, will penalise it in a more significant way. There is also a greater penalty the less likely the retrieved documents are to be relevant [117].
DCGp= p
∑
i=1 2reli− 1 log2(i + 1) where p stands as a particular rank position.3.2
Question Answering
Question Answering (QA) is a research area that focuses the attention on answering questions presented by humans in natural language. One of the first QA applications was developed in 1961 to be able to answer simple questions about baseball [42]. The LUNAR system is a remarkable step in the history of Question Answering by answering questions related to the geological analysis of rocks during Apollo expeditions [123]. These systems were able to answer 90% of the questions in its domain posed by people that did not know how the machine worked. A more recent mark is the IBM Watson being able to compete against humans [35]. The machine has a 64% win rate against humans in the Jeopardy contest.
QA architectures depend mainly on how the information is presented. From this, two major divisions are made: unstructured data and structured data. Plain text corresponds to unstructured
3.2 Question Answering 21
data, and the first approach to deal with unstructured type of data relies on Information Retrieval. Meanwhile, for structured data, databases, or even graphs, are the intermediate representations of this kind of data. Structuring data allows the use of more specific mechanisms, like Resource Description Framework (RDF), to extract the information and process it.
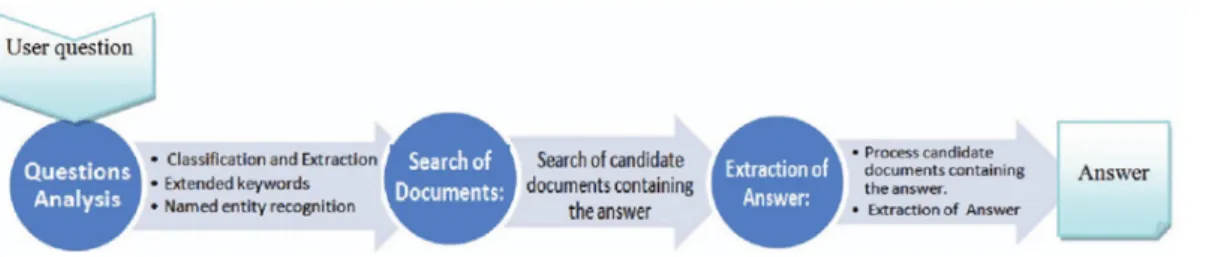
A base structure for QA models is followed, so a generic pipeline is defined with three major modules [85][50][21]:
1. Question Analysis: All questions are different. The input from the user is in Natural Lan-guage, and therefore its processing is required. Information extraction and classification need to be processed, analysed, and subsequently transformed in the best way to be used in the next phase. One of the first approaches, in 2003, performed stop-word removal, conver-sion of the inflected term to its canonical form, query term expanconver-sion, and syntactic query generation was implemented [19]. Phrase level dependency graph was adopted to determine question structure and the domain dataset was used to instantiate created patterns [124]; 2. Passage Retrieval: Passage retrieval focuses primarily on an information search in which
an engine is used that will lead to a retrieve of information significant to the question. This retrieval information is evaluated as passage candidates or sentences that are extracted from a knowledge base. From the question analysis module, this stage will formulate queries and looks up for potential answers using as a base the different information sources that can answer the question. Other unstructured information sources, where the information presented is dynamic, like the web and some online databases can also be used here. Be-ing an IR mainly problem, some implementations can use knowledge graph information sources [98,112];
3. Answer Extraction: Using the appropriate representation of the question and each can-didate passage, cancan-didate answers are extracted from the passages and ranked in terms of probable correctness. The main techniques used for Answer Extraction are the use of n-grams [29], patterns, named entities and syntactic structures. More recently, an Answer Extraction technique was introduced that uses a merging score strategy (MSS) based on hot terms [61].
Figure3.1shows a typical flow of a QA system’s framework.
Figure 3.1: Framework of a QA system, adapted from (Bouziane, Bouchiha, Doumi and Malki, 2015) [1]
22 Related Work on Fact-Checking
3.3
Challenges
Challenges usually have an overall goal. For those who propose the challenge, they need to have the ability to organise and give all the conditions to achieve the main objective; for participants, the ability to develop techniques that are innovative and make them better than others. There will never be a single solution, but the most important thing is the learning obtained from each developed system. Therefore, challenges for the fact-checking area are important in the sense that they foster progress in the development of computer systems to address this type of task.
Thus, in this section, we will reference FEVER, the dataset on which this dissertation will focus to validate its approaches. For this dataset, there were two challenges: FEVER 1.0 and FEVER 2.0. Then will be presented other noticeable datasets and their competitions.
3.3.1 FEVER Challenge
The main objective of the Fact Extraction and VERification (FEVER) Challenge is to create auto-matic systems that can verify pieces of information by extracting evidence from Wikipedia.
There have already been two iterations of the challenges:
• Fever 1.0 Shared Task (August 2018)1 was the first challenge, where it focused only on
creating automatic systems for the creation of fact-checking pipelines capable, above all, of finding the correct evidence [111];
• Fever 2.0 Shared Task (August 2019)2, where adversarial examples were used to fool the
systems developed in order to improve their robustness [109].
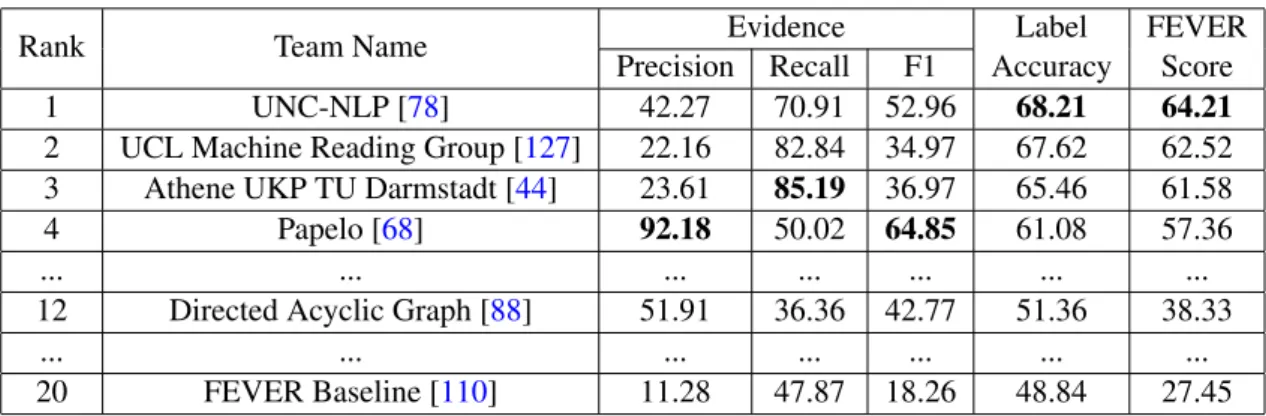
In order to validate the developed systems, a corpus was created with about 5.4 million Wikipedia articles and about 185 thousand claims. The systems would have to go through ev-ery claim and extract relevant evidence. In the end, it was necessary to classify the claim in three possible ways: SUPPORTED, REFUTED or NOT ENOUGH INFORMATION. If the claim were classified as SUPPORTED or REFUTED, in order to verify it, to support the given label is neces-sary to retrieve evidence.
The evaluation of the systems is done through a metric called FEVER Score. It is the accuracy whether the system can correctly classify the claim if, and only if, at least one of the proposed evidence is in the gold standard evidence, created by different annotators. The dataset is divided into two essential parts: Wikipedia Corpus and Claim Dataset.
The wikipedia corpus was extracted from a Wikipedia dump in June 2017. This dump gener-ated 5 396 106 articles where only two pieces of information were kept: title and text. Regarding the text, due to their size, only the introductory text which summarises the entire article was main-tained.
1http://fever.ai/2018/task.html 2http://fever.ai/2019/task.html
3.3 Challenges 23
In order to relate the extracted evidence to the documents and, more specifically, to each sentence, the title was not pre-processed, and the text was divided into sentences and numbered in ascending order. The sentences, of each document, were pre-processed using the Standford CoreNLP [70]. The titles of articles, in Wikipedia, are concise, without containing any special characters. It is necessary to recognise that some of the titles already have the kind of entity they represent, since it gives a quick understanding on what the document is about. For example: ‘Kamal Muara Stadium’, ‘Richard Haddock (1673-1751)’, ‘Turn It Up (Pixie Lott album)’, ‘Ann Richards (singer)’ and ‘Ann Richards (actress)’. Since there are docs with the same name but referring to different entities, to disambiguate them, Wikipedia adds some suffixes in a parenthe-sised way. This disambiguation is very important to take notice; for example, the title named Ann Richards can be referred to the actress or the singer. The titles contain, on average, 2.8 tokens.
The claim dataset [110] contains a total of 185 445 claims with an average size of 9.4 tokens. Each of the claims was manually built from 50 000 most popular articles. In order to have no previous knowledge or some kind of bias in the interpretation of the claims, the annotators who built the claims did not make evidence annotations. A second group of annotators tried to discover possible evidence, not by searching in the 50 000 pages, but the whole corpus, making possible the existence of more than one evidence in the dataset for each claim.
One of the strengths of this dataset is the freedom given to annotators to do cross-reference between documents. Thus, to be able to classify a claim, it may be necessary to relate more than one sentence or even in different documents. In Figure 3.2 it is possible to verify that, for the claim The Rodney King riots took place in the most populous county in the USA, two different documents must be found: LosAngelesRiots and LosAngelesCounty. Within these two documents, it is necessary to discover three relationships: that Los Angeles riots (the title of one of the docu-ments) are also known as the Rodney King riots, that these riots occurred in Los Angeles County and that, in turn, Los Angeles county is is the most populous county in the USA.
The number of supported claims is 93 367, while the number of refuted claims is 43 107; the number of claims with Not Enough Information is 48 971. The dataset is divided into four cate-gories: Training (an unbalanced set that is dedicated to train or fine-tune models), Development (a balanced set with 9 999 claims that are used for validation), Test (a balanced set with 9 999 claims without knowing the annotations) and Reserved (a balanced set with 19 998 claims used for the FEVER shared task challenge). It is very important to notice that claims that need more than one sentence to be verified (includes supported and refuted claims), represents 12% of the whole dataset. In Table3.1it is possible to see that the training set and the development (dev) set were carefully divided in order to preserve a specified rate of hard cases. So, it is possible to get a maximum of 87.5% accuracy in the training set for the supported category retrieving only one sentence, while by retrieving two sentences it is possible to get a maximum accuracy of 0.983. Claims that need more than 3 sentences represent 1% of the whole dataset. For example, the claim Bonnie Hunt was in a movie., with the ID 88173 is annotated as requiring 43 sentences in order to classify it as SUPPORTED.
24 Related Work on Fact-Checking
Figure 3.2: FEVER example where it is needed two documents to make a label classification correctly
3.3.2 Other Challenges
In this subsection, some prevalent challenges that can be related to the FEVER challenge are highlighted. This relationship is possible because, in general, in the Document Retrieval stage, the approaches and techniques are similar to those used in QA and Natural Language Inference (NLI) because of the way classification is done between two phrases – in FEVER, between a claim and evidence.
A vital benchmark to evaluate different NLP systems is the General Language Understanding Evaluation (GLUE) [116]. This platform is centred on nine English sentence understanding tasks, covering a broad range of domains, data quantities and difficulties, consisting of natural language understanding (NLU). Currently, there are 11 tasks evaluated. However, it is possible to evaluate the performance of the systems in 4 different categories: lexical semantics, predicate-argument structure, logic and Knowledge, and Common sense. Each of these categories is subdivided to evaluate them in extra detail.
The leaderboard3 shows the performance of the different proposed systems in the 11 tasks and each category performed in a diagnostic dataset. The current state-of-the-art systems are mainly based on Bidirectional Encode Representations from Transformers (BERT) [28]. The highest ranked model is initialised in RoBERTa [65], a large model developed by Microsoft [53]. RoBERTa is leading most of the GLUE tasks with ensemble models based on it. Google recently submitted a new model named T5, based on transformers as well, reaching the highest score. However, there is no article published at the moment of writing this dissertation. Although it is not clear, this benchmark allows evaluating the strong and weak points of every model. It can also
3.4 Automated Approaches on FEVER 25
Table 3.1: Rate of sentences needed to prove a claim Number of Sentences Number of Sentences from the same document from different documents
1 2 3 2 3
Training Supported 0.875 0.170 0.025 0.152 0.024 Refuted 0.901 0.142 0.019 0.132 0.018 Dev Supported 0.899 0.145 0.017 0.128 0.017 Refuted 0.921 0.116 0.015 0.102 0.014
allow for better real-life implementations, by having previous knowledge of what areas a model is good for.
Another relevant dataset is the well known Stanford Question Answering Dataset (SQuAD) [86]. The dataset is based on more than 100 000 questions posed by crowdworkers on a set of Wikipedia articles. Since the dataset is open, it presents itself as a challenge for research to overcome the human baseline performance of 86.8%. Similar to GLUE, leading research companies such as Google, Facebook, Microsoft, among others, have a high interest in reaching the highest per-formance on these tasks. Transformers such as RoBERTa and AlBERT [58] are reaching the best results merged with ensemble methods. Being a QA task, the models represent similar pre-processing methods in order to achieve the best document retrieval and reading comprehension performance (in a text, select the most meaningful words or sentences).
For the NLI area, the Stanford Natural Language Inference (SNLI)[9] was created. The pur-pose of this dataset is to understand how one sentence relates to another. SNLI contains about 570 000 English pairs of sentences that can be labelled as entailment, contradiction or neutral. A fun-damental note, related to FEVER, is that the average number of tokens in the sentences inside the documents in this corpus is 14, compared to FEVER where this number is, on average, 31 tokens. Since it is possible to create relations between sentences, FEVER approaches took advantage and used models pre-trained on the SNLI dataset, mainly because the labels are similar. An improved dataset is the Multi Genre Natural Language Inference (MultiNLI) [119] that consists of 433 000 sentences, being a more diverse corpus that was designed to be incorporated as a task of the GLUE platform. MultiNLI, when compared to the SNLI dataset, provides a wider and more diversified range of text, alongside an auxiliary test set for cross-genre transfer evaluation
3.4
Automated Approaches on FEVER
In the FEVER 1.0 Shared Task, 24 teams participated, in which Thorne et al. [111] provide a summary of the main approaches that the teams made. It is interesting to note that almost all teams that exceeded the baseline score divided their end-to-end system into three stages: Docu-ment Retrieval, Evidence Extraction and Label Prediction. Since some teams wanted to remain
![Table 2.1: Tags proposed in the Penn Treebank [71]](https://thumb-eu.123doks.com/thumbv2/123dok_br/15795472.1078658/31.892.148.786.178.560/table-tags-proposed-penn-treebank.webp)
![Figure 2.1: An example of a desired constituency tree [101]](https://thumb-eu.123doks.com/thumbv2/123dok_br/15795472.1078658/32.892.235.613.169.522/figure-example-desired-constituency-tree.webp)
![Figure 2.2: An example of a desired dependency tree [12]](https://thumb-eu.123doks.com/thumbv2/123dok_br/15795472.1078658/33.892.260.674.163.297/figure-example-desired-dependency-tree.webp)
![Figure 2.3: ELMo and BERT architectures [27]](https://thumb-eu.123doks.com/thumbv2/123dok_br/15795472.1078658/34.892.128.735.861.1039/figure-elmo-and-bert-architectures.webp)

![Figure 3.3: DeFactoNLP system architecture [88]](https://thumb-eu.123doks.com/thumbv2/123dok_br/15795472.1078658/51.892.257.682.311.901/figure-defactonlp-system-architecture.webp)
