Distribuição de Tarefas ETL em Ambientes GRID
Vasco Santos 1, Bruno Oliveira 1, Rui Silva 1 e Orlando Belo 2
1) CIICESI, Escola Superior de Tecnologia e Gestão de Felgueiras, Instituto Politécnico do Porto, Portugal
{vsantos, 8060171, 8060077}@estgf.ipp.pt
2) Algoritmi R&D Centre, Universidade do Minho, Portugal
obelo@di.uminho.pt
Resumo
Um Data Warehouse (DW) armazena dados de forma integrada, orientada por assunto e consistente, o que o torna, assim, num repositório de dados ideal para suporte a processos de tomada de decisões. No entanto, para manter este repositório devidamente actualizado é necessário aceder a um conjunto variado de sistemas fonte, transformar a informação que neles é colectada, de acordo com os requisitos do negócio, com vista a uma alimentação adequada do DW. Estas tarefas, geralmente designadas por Extracção, Transformação e Carregamento, são normalmente complexas, requerem grandes recursos computacionais e operam numa janela temporal limitada. Neste artigo será exposta uma abordagem não convencional para a execução destas tarefas, tirando partido do poder computacional existente numa organização, através da utilização de uma GRID, e apelando à abstracção que uma linguagem de manipulação de dados como a Álgebra Relacional nos providencia, tendo como suporte o standard de representação de dados presente na linguagem XML.
Palavras chave: Sistemas de Data Warehousing, Processos ETL, Processamento Distribuído,
Computação em GRID, Álgebra Relacional, JAVA, XML.
1. Introdução
Um Sistema de Data Warehousing (SDW) tem como principal objectivo providenciar um repositório de dados centralizado, uniforme e consistente, capaz de reflectir, correctamente, o histórico transaccional de uma organização. Hoje, um SDW é reconhecido como um dos componentes críticos de qualquer Sistema de Informação Empresarial (EIS) uma vez que interage com os seus demais componentes, em particular com os sistemas transaccionais que suportam as actividades do dia-a-dia da organização e que armazenam, como tal, informação vital para o DW [Inmon 2002, Kimball et al. 2008]. Esta interacção com os mais variados tipos de sistemas assume grande importância no decorrer de qualquer processo de Extracção,
Transformação e Carregamento (ETL). Este tem como principal objectivo alimentar o DW com
informação, acedendo a dados relevantes, dispersos pelos sistemas fonte, transformando-os, recorrendo a técnicas de limpeza e uniformização, e posteriormente armazenando-os no DW [Kimball e Caserta 2004].
O ciclo de vida natural de um SDW, assumindo a abordagem de desenvolvimento preconizada por [Kimball et al. 2008], tende a abranger cada vez mais áreas de negócio de uma organização e, consequentemente, a aumentar o volume de dados a tratar com vista à sua integração no DW. Isto faz com que um DW seja um repositório em contínuo crescimento. Como consequência, dia após dia, a componente de ETL de um SDW tem cada vez mais dados para tratar, mas tendo que
o fazer, provavelmente, com a mesma janela temporal. Esta particularidade torna-se um desafio para a equipa de desenvolvimento do SDW pois é necessário desenhar estratégias que permitam que estas operações concluam com sucesso, no tempo designado, por forma a que seja possível tirar partido do DW no quotidiano da organização.
A definição da arquitectura de suporte a estes processos é de particular importância, pois deve ser desenhada e planeada de forma a suportar o desenvolvimento do SDW e o consequente acréscimo do volume de dados a ser processado. As ferramentas utilizadas para o desenho e implementação da componente de ETL condicionam também a escolha da arquitectura. O contrário também se verifica. Assim, é necessário desenhar uma arquitectura e utilizar ferramentas que potenciem o desenvolvimento do SDW e o acompanhem, sem que para tal seja necessário redesenhar periodicamente a componente de ETL ou readaptar a arquitectura de suporte – tudo isto implicaria um grande esforço em termos de trabalho e, obviamente, custos bastante avultados.
Neste contexto, a utilização de recursos computacionais já existentes nas organizações permitirá reduzir custos de hardware e obter um acréscimo significativo do poder computacional disponível, uma vez que grande parte destes recursos se encontram subaproveitados ou mesmo inactivos. A utilização destes recursos, naturalmente heterogéneos, é possível, com recurso à utilização de linguagens multi-plataforma, como por exemplo JAVA, e tendo como suporte de armazenamento de dados o standard XML, que cada vez mais se afirma como uma alternativa viável ao armazenamento de informação. Tudo isto são os “ingredientes” necessários para a implementação e gestão de um ambiente GRID. Como tal, parece-nos exequível uma abordagem descentralizada de processamento de dados que satisfaça os requisitos e condicionantes de um sistema ETL, utilizando como suporte a infra-estrutura já existente na organização e a sua execução através de tarefas distribuídas suportadas por um ambiente GRID. Nas secções seguintes deste artigo serão detalhadas as abordagens comuns para desenvolvimento de sistemas ETL, nomeadamente através da modelação conceptual e lógica dos seus processos, bem como a sua implementação física num ambiente heterogéneo e distribuído como uma GRID.
2. Especificidades e Requisitos de Sistemas de ETL
O sistema de ETL é uma componente crítica no sucesso da implementação de um qualquer SDW. O desenho e implementação desta componente envolve o desenvolvimento de processos complexos, que interagem com a grande maioria das restantes componentes do SDW e baseiam grande parte das suas operações no processamento dos dados que estão armazenados em sistemas transaccionais cuja disponibilidade de acesso é condicionada e limitada. Adicionalmente, este sistema deverá ter a capacidade de evoluir, acompanhando o normal desenvolvimento de um SDW à medida que mais áreas de negócio vão sendo incorporadas no DW ao longo do tempo [Mannino e Walter 2006]. Esta capacidade de evolução, incorporando operações mais complexas e morosas, condiciona a escolha da infra-estrutura de suporte à execução dessas mesmas operações. Isto significa que o planeamento da infra-estrutura deverá ter em linha de conta que a quantidade de dados a processar, bem como o poder computacional exigido para que estas operações terminem dentro do tempo disponível tende a aumentar, o que faz com que tal sistema se torne mais dispendioso.
2.1. Modelação Conceptual
Ao mesmo tempo que fazemos o planeamento da infra-estrutura de suporte ao sistema ETL, temos que fazer também o desenho das operações de ETL. Esta etapa do processo pode ser realizada seguindo a filosofia utilizada no desenho de bases de dados por [Vassiliadis et al. 2002a] e [Trujillo e Luján-Mora 2003]. Ambos os trabalhos apresentam notações específicas para a representação do modelo conceptual do processo ETL tornando-o mais fácil de ler,
interpretar, e actualizar (se necessário) de forma bastante metódica – as duas notações permitem identificar as fontes, os atributos e as transformações necessárias para extracção, transformação e alimentação de informação no DW. Ícone Significado Conceito Atributo Transformação Nota 1 Parte de Providencia
Tabela 1 - Notação gráfica usada na modelação conceptual proposta por [Vassiliadis et al. 2002a]
A notação proposta por Vassiliadis et al. assenta num conjunto de elementos gráficos (Tabela 1) que permitem construir o modelo conceptual com as devidas restrições e anotações, possibilitando assim a formalização de um processo que é, como sabemos, documentado frequentemente de forma muito ad-hoc. No entanto, na prática, a utilização desta notação torna-se bastante confusa uma vez que as dimensões e as tabelas de factos de um DW podem torna-ser constituídas por um conjunto elevado de atributos, distribuídos por várias fontes. Esta circunstância eleva, naturalmente, à complexidade do diagrama e prejudica a sua leitura e interpretação. Sugere-se, então, que esta abordagem seja apenas utilizada de forma parcial, separando cada uma das tabelas de factos e dimensões relacionadas em diagramas específicos.
Figura 1 - Exemplo da utilização da notação proposta por [Vassiliadis et al. 2002a] para a modelação conceptual sem atributos
Na Figura 1 apresenta-se um pequeno exemplo no qual utilizamos a notação de Vassiliadis, descrevendo uma operação de alimentação de uma dimensão (dim_Pessoa) que utiliza dados provenientes de três fontes diferentes - este exemplo é baseado num extracto simplificado e modificado do ETL de uma base de dados exemplo da Microsoft (AdventureWorksDW)1 – neste
exemplo optou-se por simplificar a estrutura das entidades e traduzir para português as designações de todas as entidades e objectos envolvidos.
Ao se detalhar o esquema da Figura 1, ao ponto de incluirmos os atributos presentes em cada fonte, é possível obter as correspondências de atributos utilizados na alimentação da dimensão em causa (dim_Pessoa) (Figura 2).
Figura 2 - Detalhe do modelo conceptual com inclusão dos atributos
Trujillo, por sua vez, propõe uma abordagem baseada na notação UML, estendendo-a com conceitos inerentes aos processos de ETL (Tabela 2). Esta notação, embora mais fácil de interpretar dado o sucesso do UML, recorre em demasia à anotação do diagrama para a explicitação das operações típicas de um processo ETL. Para processos simples é de fácil utilização e compreensão, no entanto, quando o processo de ETL contém muitas transformações, com vista à uniformização dos dados envolvidos, torna-se necessário complementar os diagramas desenvolvidos com anotações uma vez que as tarefas não são discriminadas na notação proposta.
Ícone Mecanismo ETL (Estereótipo)
Descrição
Conversão Altera o tipo de dados de atributos
Junção Efectua a junção de duas fontes relacionadas entre si em determinados atributos
Tabela 2 - Excerto da notação gráfica usada na modelação conceptual proposta em [Trujillo e Luján-Mora 2003]
Na Figura 3 apresentamos o exemplo de demonstração utilizado anteriormente na notação proposta por Trujillo. Neste caso, utiliza-se o estereótipo Conversão, de forma a representar uma alteração do tipo de dados de um atributo de uma das fontes, e o estereótipo Junção, para
identificar as junções entre pares de fontes com vista à obtenção dos atributos necessários à alimentação da dimensão dim_Pessoa.
Figura 3 - Exemplo da utilização da notação proposta por [Trujillo e Luján-Mora 2003] para a modelação conceptual
2.2. Modelação Lógica
Uma vez construído o modelo conceptual para o sistema de ETL é necessário elaborar o respectivo modelo lógico, no qual serão discriminadas cada uma das operações em conjunto com o fluxo de execução de cada uma delas. Neste sentido, [Vassiliadis et al. 2002b] propõe, na sequência do trabalho anteriormente referido, uma notação gráfica que permite construir um grafo de operações para especificar o fluxo da execução de todas as operações envolvidas com o processo de alimentação do DW. De salientar a diferença deste tipo modelo relativamente ao modelo conceptual previamente desenvolvido: em síntese, no primeiro identificam-se quais os dados existentes e as transformações a implementar, enquanto que no segundo se esquematiza a sequência das operações necessárias à execução do modelo conceptual.
Na Figura 4 apresenta-se um diagrama com a aplicação prática da notação proposta, tendo por base o modelo conceptual presente na Figura 2. As operações estão sequenciadas e podem, por questões de optimização, ser reposicionadas no decorrer dos fluxos que compõem as transformações efectuadas às três fontes de dados.
3. Modelação Lógica de Processos ETL para GRIDs
A execução de um processo de ETL está necessariamente relacionada com a infra-estrutura em que é executado. Com uma abordagem descentralizada, tendo como base de trabalho um ambiente GRID, a estrutura de execução terá de ser diferente. A Figura 4 apresenta uma possível modelação lógica para um processo centralizado e executado num SDW. No entanto, a abordagem apresentada neste artigo segue uma metodologia descentralizada, na qual os dados (ou sistemas fonte) se encontram representados em documentos estruturados em XML, com as transformações a serem realizadas por aplicações cuja execução poderá ser realizada em diferentes nodos da GRID. Como tal, será necessário definir um modelo lógico no qual as
actividades integradas num processo de ETL sejam decompostas em operações base da Álgebra Relacional.
Figura 4 - Exemplo da utilização da notação proposta em [Vassiliadis et al. 2002a] para a modelação
lógica
3.1. Modelo Lógico de Representação para uma GRID
De forma a simplificar o modelo lógico já apresentado (Figura 4) e adaptá-lo para a realidade de uma GRID computacional, apresentamos na Figura 5 uma proposta de modelação lógica de um processo de ETL para a execução nesse tipo de ambiente. O modelo desenvolvido segue a estrutura do exemplo apresentado anteriormente, em que podemos ver a descrição de um fluxo de tarefas, sinalizado pelo nodo Start, que indica o início do processo, desencadeando a execução de três projecções que podem ser executadas em paralelo. De notar que, a operação de conversão do atributo Sexo foi decomposta em operações de Álgebra Relacional, dando origem a duas selecções, duas novas projecções e a uma operação de união. Segundo este modelo cada operação, depois de executada, dá origem a um documento resultado que reflecte a transformação realizada sobre o documento original – o documento resultado de uma operação representa a entrada de dados da operação seguinte. No exemplo apresentado é possível observar que as duas operações de junção necessitam de resultados de operações que as precedem. O fim da execução do processo de ETL é devidamente sinalizado pelo nodo End. Na Tabela 3 encontram-se descritas, em Álgebra Relacional, cada uma das operações utilizadas na proposta de modelação lógica do ETL da Figura 5. De notar que as operações de junção operam sobre dados resultantes das operações que as precedem.
Operação Representação em Álgebra Relacional
π1 π(IDMorada) (P.Morada)
π2 π(IDEmpregado, IDMorada) (RH.EmpregadoMorada)
π3
π(IDEmpregado, BI, Titulo, DataContrato, DataNasc, LoginID, EstadoCivil, (RH.Empregado) Sexo, IDGestor, IDContacto)
⋈1
R π1⋈ π2σ
1 σ(Sexo=’M’) (RH.Empregado)π
4 π(IDEmpregado, BI, Titulo, DataContrato, DataNasc, LoginID, EstadoCivil, (σ1) 1->Sexo, IDGestor, IDContacto)σ
2 σ(Sexo=’F’) (RH.Empregado)π
5 π(IDEmpregado, BI, Titulo, DataContrato, DataNasc, LoginID, EstadoCivil, (σ2)0->Sexo, IDGestor, IDContacto)
U S π4 U π5
⋈2
R ⋈ STabela 3 - Representação das operações utilizando Álgebra Relacional
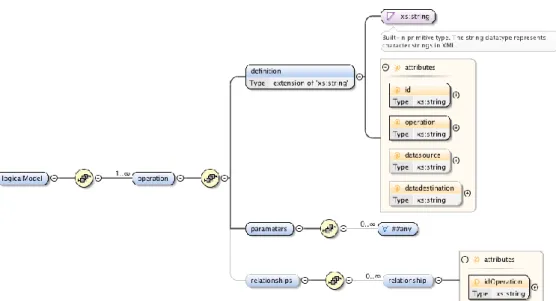
Uma questão fundamental a ter em consideração é a representação do modelo num formato que o escalonador da GRID possa interpretar, de modo a identificar quais as operações que terá de realizar, como as irá executar e qual a ordem da sua execução. Para tal, a representação deste modelo, utilizando o formato XML torna-se um ponto essencial nesta abordagem. Na Figura 6 é apresentado o esquema XSD de suporte a este modelo lógico.
O modelo apresentado, cuja construção é baseada no formato XPDL [van der Aalst 2003, "Workflow Management Coalition"] (XML Process Definition Language), tem como objectivo representar em XML o fluxo de dados associado com o modelo em Álgebra Relacional apresentado anteriormente. Este modelo identifica todas as actividades (tarefas) a serem realizadas, bem como o respectivo fluxo de dados e a estrutura de execução das operações de transformação. Cada operação é, obrigatoriamente, identificada pelos atributos: id, que representa um identificador para a operação; operation, a descrição da operação a ser utilizada;
datasource, a fonte relativa a um documento XML original; datadestination, que indica se se
pretende armazenar o resultado de uma determinada operação num documento, para posterior consulta; relationships, que define as operações que a operação possui como precedentes, identificadas devidamente pelo seu id.
Uma questão essencial na representação do documento XML é o elemento parameters. Este elemento indica os parâmetros que devem ser enviados para a respectiva operação de transformação. No entanto, em Álgebra Relacional existem diversas operações unárias e binárias que possuem especificações diferentes em termos da sua configuração, por exemplo, uma junção necessita de receber como parâmetro as relações para realizar a junção, enquanto que a operação de projecção necessita de receber como parâmetros os atributos a projectar. O elemento parameters reflecte isso mesmo, isto é, indica ao escalonador de tarefas da GRID como gerar o respectivo documento de definição para a operação a realizar no processo de ETL.
Figura 6 - Proposta de esquema XSD para a representação do fluxo de operações de Álgebra Relacional
4. Distribuição e Escalonamento do Sistema de ETL
Uma vez gerado o documento XML, que determina o fluxo de operações de Álgebra Relacional necessário à execução do ETL, e tendo em vista o objectivo inicial de distribuição destas operações num ambiente GRID, é necessário analisar a sequência de operações a realizar e, mediante a disponibilidade corrente da GRID, submeter essas operações como tarefas a serem executadas nos nodos disponíveis num dado momento.
No presente trabalho, a construção da GRID de testes foi conseguida através da utilização do Middleware Globus Toolkit 4.2.1 [Foster 2006]. Para a realização do escalonamento de tarefas num ambiente GRID é necessário conhecer as características dos recursos existentes, de forma a optimizar a distribuição de tarefas. Para tal, o Globus disponibiliza o serviço MDS [Xuehai e Schopf 2004] (Serviço de Monitorização e Descoberta de Recursos), que em conjunto com o software de monitorização Ganglia [Massie et al. 2004] torna possível a obtenção de dados dos recursos computacionais existentes. Posteriormente, a consulta desta informação é conseguida através da utilização de um Web Service disponibilizado pelo Globus. A Figura 7 apresenta um excerto da informação recolhida através de consulta ao servidor MDS.
Figura 7 - Excerto da informação recolhida pelo MDS relativa a um nodo da GRID
Para desenvolver um módulo de escalonamento do processo de ETL e monitorizar o estado da GRID foi utilizado o JAVA CoG Kit JGlobus [von Laszewski et al. 2002]. Este permite aceder a todas as funcionalidades da GRID (p. ex.: lançamento de trabalhos, monitorização de trabalhos, controlo de credenciais, etc.) através da Framework JAVA.
De seguida, e tendo em vista a optimização da distribuição do processo de ETL na GRID, é necessário avaliar os recursos existentes quanto à sua performance e disponibilidade num determinado instante. Para isso foi considerado o trabalho desenvolvido em [Guerreiro e Belo 2009], especialmente os aspectos relacionadas com a previsão de disponibilidade de uma GRID. A disponibilidade computacional mede a máxima capacidade de poder de processamento que uma máquina é capaz de disponibilizar num determinado momento, considerando a sua carga computacional em utilização. Em [Guerreiro e Belo 2009] a disponibilidade computacional é o factor de decisão que mais influencia o tempo de execução de tarefas e a sua taxa de sucesso. A fórmula (1) permite quantificar a disponibilidade computacional de cada nodo num dado momento.
PerfAVAILABILITY = (kCPU x kCPUARCH x CPUFREQ x FreeCPUs+ kMEM x AvailRAM ) x AvailCOEF . (1)
Esta disponibilidade assenta na avaliação de factores como o tipo, velocidade e importância relativa do processador em conjunção com a disponibilidade e importância da memória local para a execução do trabalho. Este cálculo ainda é afectado por um factor que é inversamente proporcional à carga de cada nodo da GRID. No nosso exemplo propõe-se a utilização da carga computacional média dos últimos cinco minutos (2).
AvailCOEF = 1 - CPULoad 5 Min . (2)
Para melhorar a qualidade do escalonamento foi implementado um sistema de previsão de performance e disponibilidade do ambiente GRID. Tendo em vista a utilização do algoritmo de árvores de decisão proposto em [Guerreiro e Belo 2009] é necessário subdividir os nodos em seis classes de performance (C0 – C5) calculadas em (3) :
(Perf AVAILABILITY x 5) / (max(Perf AVAILABILITY )) . (3)
Adicionalmente, foi introduzido um factor de probabilidade de execução a cada uma destas classes de forma a introduzir diversidade no escalonamento de tarefas (4)(5).
ProbCi < ProbCi+1 . (4)
∑i=0..5 ProbCi=1. (5)
A modelação lógica do processo ETL é submetida na GRID, através da sua codificação em RSL (Resource Specification Language). A RSL é uma linguagem que providencia uma sintaxe constituída por pares atributo/valor para descrever os recursos requeridos para uma tarefa e a sua definição - em Apêndice a este artigo apresenta-se um pequeno exemplo do ficheiro RSL para um caso específico de uma operação de projecção.
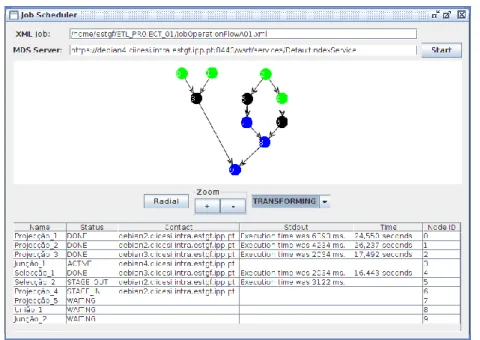
Através da sintaxe disponibilizada pela RSL é possível definir qual a operação ETL a realizar e quais os seus argumentos. Adicionalmente, podemos também definir a localização dos ficheiros necessários à execução de uma tarefa, bem como identificar o local onde será colocado o resultado (eventualmente um outro nodo da GRID). Após a definição do ficheiro RSL a operação é submetida ao nodo que foi seleccionado pelo escalonador. Ao longo do processo de ETL é monitorizado o estado de execução de cada uma das operações (Figura 8), tornando-se
possível lançar operações quando a execução das suas precedentes estiverem concluídas ou relançar operações quando for observado em erro durante a execução.
Figura 8 - Monitorização do estado da execução das operações ETL em curso
5. Conclusões e Trabalho Futuro
O processo de alimentação de um DW é necessariamente um processo complexo, tendo em conta a elevada quantidade de dados a processar, especialmente quando a janela de oportunidade é limitada. O estudo de alternativas que possam tornar viável a execução destas tarefas em ambientes distribuídos é uma abordagem que visa não só rentabilizar os recursos já existentes e subaproveitados, mas também um contributo válido para o controlo de custos associados com os SDW.
Neste artigo apresentamos uma abordagem que tira partido de um ambiente GRID configurado como infra-estrutura base para o suporte a um sistema ETL através da distribuição das suas operações em Álgebra Relacional. Baseando-nos na abordagem de desenho conceptual/lógico de processos de ETL, propusemos a sua adaptação para um modelo lógico de Álgebra Relacional que, após avaliação da GRID, será instanciado através da estratégia de distribuição adoptada no momento - a cada operação será atribuída um nodo da GRID para a sua execução. De modo a validar o modelo ETL proposto, foi construído um protótipo de um ambiente GRID, utilizando quatro nodos computacionais. A comunicação entre as máquinas foi realizada numa rede de 100 Mbit. O protótipo do ambiente GRID implementado foi testado recorrendo a execução de várias tarefas de ETL, presentes na base de dados exemplo da Microsoft (AdventureWorksDW). Os resultados obtidos permitem observar que o processo mais crítico na fase de escalonamento está na transferência de ficheiros entre nodos da GRID.
Como trabalho futuro propomo-nos a aprofundar o estudo de previsão do tempo de execução das operações ETL com base na capacidade computacional dos nodos existentes numa GRID, com o objectivo de melhorar o processo de alocação de tarefas e do controlo do tempo necessário à execução total do sistema de ETL. O estudo da reserva antecipada de recursos poderá contribuir para uma mais rápida tomada de decisão do nodo computacional a utilizar. Tendo sido detectado que a transferência de ficheiros entre nodos é um dos processos mais morosos, propõem-se também estudar um novo tipo de escalonamento que considere a
distribuição de ramos de operações de Álgebra Relacional ao invés de operações individuais com vista à redução da transmissão de dados entre nodos.
Referências
Foster, I., "Globus Toolkit Version 4: Software for Service-Oriented Systems". Paper presented at the IFIP International Conference on Network and Parallel Computing, (2006).
Guerreiro, N. e Belo, O., Predicting the Performance of a GRID Environment: An Initial Effort
to Increase Scheduling Efficiency. In Y.-h. Lee, T.-h. Kim, W.-c. Fang e D. Slezak (Eds.), Future Generation Information Technology (Vol. 5899, pp. 112-119): Springer Berlin /
Heidelberg, 2009.
Inmon, W. H., Building the Data Warehouse (3rd ed.): John Wiley & Sons, 2002.
Kimball, R. e Caserta, J., The Data Warehouse ETL Toolkit - Pratical Techniques for
Extracting, Cleaning, Conforming, and Delivering Data. : Wiley Publishing, Inc., 2004.
Kimball, R., Ross, M., Thornthwaite, W., Mundy, J. e Becker, B., The Data Warehouse
Lifecycle Toolkit - Practical Techniques for Building Data Warehouse and Business Intelligence Systems (Second Edition ed.). : Wiley Publishing, Inc., 2008.
Mannino, M. V. e Walter, Z. "A framework for data warehouse refresh policies". Decision
Support Systems, 42, 1 (2006), 121-143.
Massie, M. L., Chun, B. N. e Culler, D. E. "The ganglia distributed monitoring system: design, implementation, and experience". Parallel Computing, 30, 7 (2004), 817-840.
Trujillo, J. e Luján-Mora, S., A UML Based Approach for Modeling ETL Processes in Data
Warehouses Conceptual Modeling - ER 2003 (Vol. 2813/2003, pp. 307-320). Berlin
Heidelberg: Springer -Verlag, 2003.
van der Aalst, W. M. P. Patterns and XPDL: A Critical Evaluation of the XML Process Definition Language, (2003).
Vassiliadis, P., Simitsis, A. e Skiadopoulos, S., "Conceptual modeling for ETL processes". Paper presented at the Proceedings of the 5th ACM international workshop on Data Warehousing and OLAP, McLean, Virginia, USA, (2002a).
Vassiliadis, P., Simitsis, A. e Skiadopoulos, S., "On the Logical Modeling of ETL Processes". Paper presented at the Proceedings of the 14th International Conference on Advanced Information Systems Engineering, (2002b).
von Laszewski, G., Gawor, J., Lane, P., Rehn, N. e Russell, M. "Features of the Java Commodity Grid Kit". Concurrency and Computation: Practice and Experience, 14, 13-15 (2002), 1045-1055.
Workflow Management Coalition Retrieved in July 9, 2011, from
http://www.wfmc.org/xpdl.html
Xuehai, Z. e Schopf, J. M., "Performance analysis of the Globus Toolkit Monitoring and Discovery Service, MDS2". Paper presented at the IEEE International Conference on Performance, Computing, and Communications, (2004).
Apêndice
Exemplo da definição RSL de um trabalho a submeter à GRID <job> <executable>/usr/lib/jdk1.6.0_23/bin/java </executable> <directory>${GLOBUS_USER_HOME}</directory> <argument>-jar</argument> <argument>Projection.jar</argument> <argument>Query.xml</argument> <argument>TableIn.xml</argument> <argument>TableOut.xml</argument> <stdout>${GLOBUS_USER_HOME}/stdout</stdout> <stderr>${GLOBUS_USER_HOME}/stderr</stderr> <fileStageIn> <transfer> <sourceUrl> gsiftp://debian1.ciicesi.intra.estgf.ipp.pt:2811/home/estgf/Projection.jar </sourceUrl> <destinationUrl> file:///${GLOBUS_USER_HOME}/Projection.jar </destinationUrl> </transfer> <transfer> <sourceUrl> gsiftp://debian1.ciicesi.intra.estgf.ipp.pt:2811/home/estgf/Query.xml </sourceUrl> <destinationUrl> file:///${GLOBUS_USER_HOME}/Query.xml </destinationUrl> </transfer> <transfer> <sourceUrl> gsiftp://debian1.ciicesi.intra.estgf.ipp.pt:2811/home/estgf/TableIn.xml </sourceUrl> <destinationUrl> file:///${GLOBUS_USER_HOME}/TableIn.xml </destinationUrl> </transfer> </fileStageIn> <fileStageOut> <transfer> <sourceUrl> file:///${GLOBUS_USER_HOME}/TableOut.xml </sourceUrl> <destinationUrl> gsiftp://debian1.ciicesi.intra.estgf.ipp.pt:2811/home/estgf/ProjectionTableOut.xml </destinationUrl> </transfer> </fileStageOut> </job>
![Figura 1 - Exemplo da utilização da notação proposta por [Vassiliadis et al. 2002a] para a modelação conceptual sem atributos](https://thumb-eu.123doks.com/thumbv2/123dok_br/17031033.766706/3.892.223.673.684.850/exemplo-utilização-notação-proposta-vassiliadis-modelação-conceptual-atributos.webp)
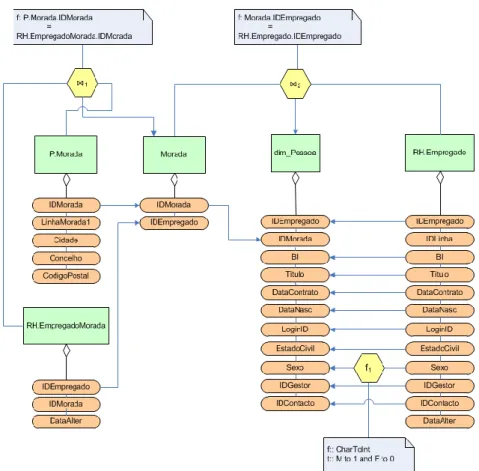
![Figura 3 - Exemplo da utilização da notação proposta por [Trujillo e Luján-Mora 2003] para a modelação conceptual](https://thumb-eu.123doks.com/thumbv2/123dok_br/17031033.766706/5.892.232.662.180.543/figura-exemplo-utilização-notação-proposta-trujillo-modelação-conceptual.webp)
![Figura 4 - Exemplo da utilização da notação proposta em [Vassiliadis et al. 2002a] para a modelação lógica](https://thumb-eu.123doks.com/thumbv2/123dok_br/17031033.766706/6.892.191.708.179.395/figura-exemplo-utilização-notação-proposta-vassiliadis-modelação-lógica.webp)