Universidade do Minho
Escola de Engenharia
Departamento de Informática
Ricardo Manuel Arantes Silva
Definição e Caracterização de Assinaturas
OLAP
Universidade do Minho
Escola de Engenharia
Departamento de Informática
Ricardo Manuel Arantes Silva
Definição e Caracterização de
Assinaturas OLAP
Dissertação de Mestrado
Mestrado Integrado em Engenharia
Informática
Trabalho efetuado sob a orientação de
Professor Doutor Orlando Manuel Oliveira
Belo
Agradecimentos
Com o final do meu mestrado é agora o momento de agradecer e prestar a minha homenagem a todos aqueles que direta ou indiretamente ajudaram e contribuíram para que este momento se tornasse realidade, facilitando a conclusão deste percurso de aprendizagem académica e pessoal com sucesso.
Durante o desenvolvimento desta dissertação foram muitas as pessoas que me apoiaram, incentivaram e colaboraram na sua realização, que agora merecem um especial agradecimento. Como não podia deixar de ser, começo por toda a minha família, que me apoiou e acarinhou durante toda a minha vida. Em especial aos meus pais que me proporcionam todas as condições para que eu conseguisse terminar esta etapa da minha vida com sucesso e sem qualquer restrição.
Agradecer ao meu orientador, Professor Doutor Orlando Belo, em primeiro lugar por me ter aceite como orientado, e agradecer também todo o acompanhamento, compreensão, paciência e disponibilidade que sempre demonstrou durante toda esta etapa, bem como todas as criticas e correções realizadas ao longo deste trabalho.
Quero também agradecer aos meus amigos e companheiros pelos bons momentos de amizade, ajuda e alegria, que passamos juntos, e facilitaram a conclusão desta etapa. A todos o meu muito obrigado.
Resumo
Definição e Caracterização de Assinaturas OLAP
As assinaturas OLAP podem ser vistas como uma forma de caracterização de um dado perfil de exploração analítica. Porém, ao contrário de um perfil de exploração típico, uma assinatura OLAP não tem uma natureza estática. Uma assinatura OLAP congrega de uma forma única todos os elementos de informação recolhidos ao longo do tempo nas várias sessões de exploração OLAP desenvolvidas por um dado utilizador, caracterizando de uma forma bastante concreta esse utilizador ao longo do tempo. Num sistema OLAP as assinaturas podem ser utilizadas para traçar um perfil de exploração de dados de um dado utilizador, baseado nas queries que este coloca ao longo do tempo sobre um dado sistema de processamento analítico e dos seus hábitos e tendências de exploração. Através da análise das assinaturas OLAP podemos otimizar as estruturas multidimensionais – cubos - de um dado sistema analítico, de forma a reduzir o seu tamanho, guardando apenas informação relevante, e prever quais as operações que podem ser despoletadas a partir da ocorrência de uma dada querie. Desta forma é possível escolher a priori
quais as partes do cubo que devem ser carregadas para memória ou aquelas que podem ser transferidas para a máquina do próprio utilizador. Tudo isto, para que seja possível minimizar a carga do servidor e reduzir o tráfego de dados no sistema de comunicação que suporta os processos de exploração analítica. Neste trabalho de dissertação exploraremos esta temática e definiremos um método sustentado para definição e manutenção de assinaturas OLAP.
Palavras-chave: Sistemas de Data Warehousing, Processamento Analítico de Dados, OLAP, Sessões OLAP, Cadeias de Markov, Classes de Equivalência, Assinaturas OLAP, Identificação e Caracterização de Perfis de Exploração.
Abstract
Definition and Characterization of OLAP Signatures
OLAP signatures can be viewed as a way of characterizing one analytical exploration profile. However, unlike a typical scan profile, an OLAP signature does not have a static nature. An OLAP signature uniquely brings together all the information elements collected over time in the various OLAP exploration sessions developed by one user, characterizing that user in a very concrete way along the time. In an OLAP system the signatures can be used to trace a data exploration profile of a user, based on the queries that this one places along the time on an analytical processing system and its exploration habits and trends. Through the analysis of OLAP signatures we can optimize the multidimensional structures - cubes - of an analytical system, so as to reduce its size, keeping only relevant information, and predict which operations can be triggered from the occurrence of a specific query. In this way it is possible to choose primarily which parts of the cube should be loaded into memory or those that can be transferred to the user's own machine. With this we can minimize server load and reduce data traffic in the communication system that supports analytical scanning processes. In this dissertation we will explore this theme and define a sustained method for defining and maintaining OLAP signatures.
Keywords: Data Warehousing, Data Analytical Processing, OLAP, OLAP Sessions, Markov Chains, Equivalence Classes, OLAP Signatures, Identification and Characterization of Exploration Profiles
.
Índice
1 Introdução ... 1 1.1 Contextualização ... 1 1.2 Motivação ... 3 1.3 Objetivos ... 4 1.4 Estrutura Documento... 4 2 Assinaturas ... 7 2.1 Perfis de Exploração ... 72.2 Cálculo de uma Assinatura OLAP ... 9
2.3 Métodos para a Atualização de Assinaturas ...13
2.4 Preferências de Utilização ...15
2.5 Algoritmos para Seleção de Vistas ...17
2.5.1 O Algoritmo Greedy ...18
2.5.2 O Algoritmo HRU ...18
2.5.3 O Algoritmo PGA ...19
2.5.4 O Algoritmo BPUS ...20
3 Um Modelo Baseado em Assinaturas OLAP... 23
3.1 As Assinatura OLAP ...23
3.2 As Classes de Equivalência ...26
3.3 As Cadeias de Markov ...30
3.5 Evolução de uma Assinatura ...38
4 Aplicação do Modelo de Assinaturas ... 43
4.1 Materializar ou não Materializar ...43
4.2 Ferramentas Utilizadas ...45
4.3 O Ciclo de Vida das Assinaturas ...45
4.4 Análise da Temática ...47
4.5 Tratamento e Integração dos Dados ...49
4.6 Preparação do Processo ...51
4.7 Definição das Assinaturas ...55
4.8 Análise de Resultados ...58
4.8.1 Definição das Assinaturas ...58
4.8.2 Evolução das Assinaturas ...63
5 Conclusões e Trabalho Futuro ... 71
5.1 Conclusões ...71
5.2 Trabalho Futuro ...72
Índice de Figuras
Figura 1: Modelo para análise da variação de uma assinatura (Ferreira et al. 2006). ...11
Figura 2: Cálculo de distâncias entre assinaturas (Belo & Monsanto 2012). ...11
Figura 3: Cálculo de uma assinatura de exploração (Belo & Monsanto 2012). ...11
Figura 4: A fórmula de cálculo de uma assinatura (Belo & Monsanto 2012). ...12
Figura 5: Esquema do processamento de uma assinatura (Edge & Falcone Sampaio 2009). ...13
Figura 6: Ilustração da evolução de uma assinatura ao longo do tempo (Ferreira et al. 2006). ...14
Figura 7: Atualização da assinatura de acordo com (Ferreira et al. 2006). ...15
Figura 8: Pseudo Código Algoritmo Greedy (Harinarayan et al. 1996). ...18
Figura 9: Pseudo Código Algoritmo HRU (Hanusse et al. 2009). ...19
Figura 10: Pseudo Código Algoritmo PGA (Nadeau et al. 2002). ...20
Figura 11: Pseudo Código algoritmo BPUS (Gupta, 1997). ...21
Figura 12: Exemplo de uma assinatura OLAP. ...24
Figura 13: Ilustração da sobreposição do espaço de solução de um conjunto de queries. ...27
Figura 14: Matriz Probabilidades. ...31
Figura 15: Exemplo Cadeia Markov. ...32
Figura 16: Representação de uma sessão de exploração através de uma cadeia de Markov. ...33
Figura 17: Esquema das tarefas do processo de cálculo de uma assinatura. ...34
Figura 18: Seleção dos Nodos. ...36
Figura 19: Expressão de cálculo da variação de uma assinatura. ...38
Figura 20: Pseudocódigo do processo de cálculo de uma assinatura OLAP. ...39
Figura 21: Assinaturas OLAP – Ciclo de aplicação. ...46
Figura 23: Estrutura base da tabela de transição “Log”. ...50
Figura 24: Esquema geral da base de dados de trabalho. ...52
Figura 25: Esquemas base das tabelas “Perfil”, “Query_Perfil” e “Log”. ...54
Figura 26: Conjunto de medidas, dimensões, filtros e subfiltros extraídos. ...56
Figura 27: Fragmento de um scritp de povoamento dos filtros. ...56
Figura 28: Exemplo de uma assinatura OLAP. ...57
Figura 29: Caracterização inicial de uma assinatura. ...58
Figura 30: Definição de uma assinatura inicial através de um gráfico de “calor”. ...59
Figura 31: Medidas definidas para o 1º Utilizador durante o 1º período de análise. ...60
Figura 32: Dimensões do 1º Utilizador no 1º Período de análise. ...61
Figura 33: Filtros do 1º Utilizador no 1º Período de análise. ...61
Figura 34: Uma star-net query com as dimensões de análise mais relevantes. ...62
Figura 35: Uma star-net query com as medidas mais relevantes. ...63
Figura 36: Caracterização da assinatura final. ...63
Figura 37: As queries injetadas para análise da variação de uma assinatura. ...64
Figura 38: Dimensões que foram identificadas como relevantes de uma assinatura. ...64
Figura 39: Medidas que foram identificadas como relevantes de uma assinatura. ...65
Figura 40: Filtros que foram identificados como relevantes de uma assinatura. ...65
Figura 41: Dimensões identificadas como relevantes a par uma assinatura após o 1º ciclo. ...66
Figura 42: Medidas identificadas como relevantes a par uma assinatura após o 1º ciclo. ...66
Figura 43: Dimensões relevantes após realização de todas as atualizações. ...68
Figura 44: Medidas relevantes após realização de todas as atualizações. ...68
Índice de Tabelas
Tabela 1: Tabela de Probabilidades. ...31
Tabela 2: Sessões de exploração. ...31
Tabela 3: Resultado do processo de extração de características. ...37
Tabela 4: Valores Matriz Antiga. ...40
Tabela 5: Matriz de atualização. ...40
Tabela 6: Matriz Atualizada. ...40
Tabela 7: Descrição geral das tabelas que integram a base de dados de trabalho. ...53
Tabela 8: Descrição da tabela “Perfil”. ...54
Tabela 9: Descrição da tabela “Query_Perfil”. ...54
Tabela 10: Descrição da tabela “Log”. ...55
Lista de Siglas e Acrónimos
BD Base Dados
OLAP On-Line Analytical Processing
DW Data Warehouse
MDX Multi-Dimensional Expressions
CSV SD
Comma-separated values Sistema de Suporte à Decisão
Introdução
Capítulo 1
1
Introdução
1.1
Contextualização
Hoje, os ambientes são muito dinâmicos e voláteis. Como tal é essencial que as empresas tenham a possibilidade de fazer a identificação de comportamentos e tendências de negócio, de forma que possam tomar decisões de forma imediata, com elevada frequência, para se manterem fortes e competitivas no mercado. Uma decisão tomada antes de um concorrente pode causar diferença, ser decisiva. Para ajudar nesta tarefa tão complicada, os sistemas de suporte à decisão (SD), e em particular os sistemas de processamento analítico (OLAP), disponibilizam um conjunto de meios e serviços muito úteis e de aplicação bastante rápida. Estes sistemas tiveram o seu aparecimento durante a década de 90 (Codd et al. 1993), como uma resposta à necessidade de interação dos analistas com os sistemas de informação, de uma forma muito dinâmica e flexível. As consultas em sistemas OLAP são respondidas a partir de operações de seleção, junção e agregação, segundo um dado conjunto de perspetivas de análise – diferentes visões sobre o domínio de aplicação. Para suportar estes novos sistemas, foram concebidas e implementadas estruturas de dados bastante específicas: as estruturas multidimensionais de dados, vulgarmente designados por cubos, que têm uma grande capacidade de acolher e organizar dados provenientes de sistemas operacionais comuns, de forma a que estes possam ser explorados de acordo com as várias perspetivas de análise de negócio, garantindo uma qualidade de serviço muito elevada, respondendo às
Introdução interrogações sobre elas lançadas de forma muito expedida e sem grande variação temporal, mesmo em casos de interrogações de elevada complexidade. Porém, para povoar estas estruturas e dados de uma forma eficaz é necessário recorrer-se a algumas técnicas e mecanismos que sejam capazes de algum aplicar algum tipo de seleção sobre a informação adquirida, de forma a não se considerarem dados que nunca ou raramente são utilizados. Numa análise rápida à forma como um sistema OLAP usualmente é utilizado, facilmente verificamos que utilizadores distintos têm necessidades distintas, mesmo quando exploram um mesmo cubo de dados. Por outro lado, também sabemos que, algumas das zonas de um cubo, apesar de estarem materializadas e acessíveis, não são nunca alvo de qualquer interrogação, o que provoca consumos excessivos e desnecessários em termos de processamento e de armazenamento de dados, especialmente quando estão em causa o tratamento de grandes volumes de dados. Isto, obviamente, contraria um pouco o desempenho das consultas OLAP, as quais, em condições normais de operação, como sabemos são satisfeitas de forma bastante rápida. Tendo todos estes aspetos em consideração, não é difícil concluir que muita da informação que é colocada num cubo poderia ser evitada ou pelo menos endereçada para outras estruturas nas quais fosse realmente utilizada.
A seleção de vistas de um cubo a materializar é algo que há muito tem vindo a ser estudado por diversos autores. A ideia base é sempre a mesma: materializar num cubo apenas a informação que realmente é necessária. Muitas abordagens tentam gerar a partir de uma estrutura base uma estrutura alternativa que de alguma maneira corresponda à anterior. Porém, esta estrutura alternativa deverá exigir menores recursos computacionais, descartando, quando possível, informação pouco relevante, permitindo assim um acesso mais rápido e eficaz à informação que, de facto, é necessária. Porém, este processo não é simples. O problema da seleção de vistas ou subcubos foi trabalhado por (Harinarayan et al. 1996) que o consideraram NP-Hard.
Mais recentemente, outros modelos e técnicas foram introduzidas em novos processos de seleção de vistas multidimensionais de dados. Uma dessas técnicas é o cálculo de assinaturas de exploração, que é algo muito semelhante à definição de um perfil de utilização, mas com a propriedade de acompanhar (caracterizar) ao longo do tempo o comportamento do utilizador. Uma assinatura, como o próprio nome indica, é algo que define e caracteriza um utilizador, dá-lhe uma identidade de acordo com o tipo de aplicação em causa. Uma assinatura OLAP tem exatamente a mesma função. Todavia, é identificada e mantida através de informação proveniente de consultas executadas ao longo das diversas sessões de exploração OLAP de um utilizador. Assim, neste
Introdução trabalho de dissertação, pretendemos ver em que medida esta técnica pode ser aplicada num processo de otimização de uma estrutura de dados multidimensional, utilizando-a como um método alternativo para a realização da seleção de vistas de uma estrutura multidimensional de dados.
1.2
Motivação
O tempo de resposta das consultas OLAP é algo bastante crítico. Respostas rápidas são claramente um fator de diferenciação no desempenho dos sistemas. Nos processos de tomada de decisão empresariais, este tempo pode ser influenciado por muitos fatores. A disponibilidade dos dados é um deles. A necessidade de redução no tempo da resposta bem como da redução do espaço de armazenamento dos dados são cada vez mais fatores a ter em conta, uma vez que influenciam diretamente a qualidade do serviço prestado como da atualidade da informação. É importante, pois, que se estudem e se reavalie as técnicas e os modelos de armazenamento de dados utilizados, de forma a agilizar os processos de exploração de dados.
A aplicação de técnicas de descoberta de padrões de utilização, para diferentes utilizadores de um sistema OLAP, é algo que cada vez mais se toma em consideração em processos de otimização do serviço prestado por um servidor analítico. Usualmente, na maioria deste tipo de servidores, os processos de exploração de dados são registados em ficheiros de log específicos, que guardam informação bastante pertinente sobre aquilo que um ou mais utilizadores vai realizando, quando e como o fez. Esses dados são bastante preciosos para qualquer administrador de um sistema OLAP que se preocupe com a rentabilização e a otimização do seu sistema. A partir desses dados é possível estabelecer padrões de utilização, neste caso, padrões de exploração analítica de dados, e com base neles estudar o comportamento de cada um dos utilizadores com vista a uma melhor adequação dos serviços de prestação de dados. Esse estudo pode conduzir a uma caracterização bastante efetiva dos recursos que um utilizador OLAP utiliza ao longo do tempo. Esses perfis podem ser materializados em assinaturas, um mecanismo que permite caracterizar um determinado utilizador (todo o seu comportamento) ao longo do tempo com base no seu comportamento passado.
Introdução O conhecimento associado a uma assinatura é suficiente para se poder reconhecer de forma automática um dado utilizador, mesmo quando ele não se identifica.
1.3
Objetivos
Tentar superar as expectativas de um cliente é sempre algo bastante positivo. Conseguir prever o seu comportamento, conseguindo reduzir eventuais erros num processo de tomada de decisão é estar sempre um passo à frente no enredo da concorrência dos mercados. Assim, basicamente, o objetivo é saber identificar e caracterizar as assinaturas de utilizadores e desenvolver uma ferramenta que faça a sua descoberta de acordo com os processos de exploração de um dado cubo levados a cabo, e que mostre qual a estrutura do cubo a materializar para um dado utilizador com base nas suas sessões de exploração OLAP. Pretende-se, assim, fazer a criação de um sistema baseado em assinaturas de exploração analítica, que seja capaz de propor um método de seleção e de materialização de vistas de utilização e que permita reduzir a utilização de recursos computacionais. Em suma, pretende-se maximizar o desempenho das consultas OLAP, otimizar e selecionar a informação mais relevante através da análise das secções OLAP e implementar cubos com informação focada e detalhada. Tudo isto permitirá reduzir o espaço de armazenamento através da “eliminação” de informação não utilizada (inativa) e da libertação do seu espaço de armazenamento, e aumentar a performance nas respostas aos utilizadores. Na realidade, aquilo que nos motiva para realização deste trabalho de dissertação é conhecer bem as necessidades de cada utilizador OLAP, com base nos seus comportamentos, e preparar as estruturas de exploração especificamente para cada um deles, com vista à rentabilização dos recursos computacionais envolvidos.
1.4
Estrutura Documento
Para além deste primeiro capítulo introdutório, esta dissertação integra mais quatro outros capítulos, nomeadamente:
• Capitulo 2 – Assinaturas OLAP. Neste capitulo é feita uma breve abordagem aos conceitos relacionados com as assinaturas OLAP, apresentando-se algumas das definições
Introdução e conceitos associados, expostos por diversos autores, a sua utilidade e aplicação, e as áreas onde já foram aplicadas.
• Capitulo 3 – Um Modelo Baseado em Assinaturas OLAP. Neste terceiro capítulo apresentamos o método que propomos para fazer a identificação dos dados de um cubo que realmente são consultados nas sessões. De forma detalhada, apresentamos e explicamos os principais conceitos e tecnologias - assinaturas OLAP, classes de equivalência, cadeias de Markov, entre outros - envolvidas no desenvolvimento deste trabalho de dissertação, estabelecendo sempre que necessário uma “ponte” entre a sua exposição e demonstração, como em conjunto podem facilitar o processo de seleção. Além disso, também expomos a forma como o método foi implementado.
• Capitulo 4 – Aplicação do Modelo de Assinaturas. Aqui apresentamos o processo de trabalho desenvolvido com a implementação do modelo de assinaturas que desenvolvemos, dando particular ênfase à recolha e preparação dos dados e às técnicas que utilizámos para avaliar o método e analisar a sua aplicação.
• Capitulo 5 – Conclusões e Trabalho Futuro. Neste último capítulo tecemos alguns comentários e expomos algumas conclusões sobre o trabalho realizado, bem como apresentamos algumas ideias e sugestões para a evolução do trabalho presente nesta dissertação.
Capítulo 2
2
Assinaturas
2.1
Perfis de Exploração
Hoje em dia, o número de serviços disponíveis para utilizadores de dispositivos eletrónicos – e.g. exemplo, smartphone, tablet, computadores - é enorme. A forma como estes serviços são explorados pelos utilizadores é muito interessante para uma qualquer empresa que use essa informação para rentabilizar os seus negócios com base no comportamento dos utilizadores. Nos dias de hoje, com os níveis de competitividade existentes, as análises dos perfis de utilizadores de serviços tornam-se essenciais para os seus prestadores conhecerem bem os seus clientes, o que lhes permite implementar processos de personalização e consequentemente adaptar a sua oferta às necessidades concretas dos seus clientes. Os serviços personalizados visam, pois, combinar os requisitos, preferências e necessidades dos utilizadores de forma a propiciar um fornecimento de serviço o mais adequado possível. O sucesso desses serviços depende do quão bem o prestador conhece o utilizador e o quanto isso se reflete no serviço.
Os perfis de utilização criados a partir de dados recolhidos de processo de exploração de equipamento tecnológico são a representação virtual daquilo que cada utilizador realiza. Tais perfis incluem uma grande variedade de informação, como dados pessoais, dados de interesse sobre produtos e serviços, tendências e preferências de exploração. A criação desses perfis resulta das análises dos processos de utilização e são essenciais para a personalização dos serviços. A
natureza do crescimento dos dados, e a evolução das tecnologias, mudaram a forma como os resultados devem ser armazenados nos sistemas. Além disso, as metodologias de seleção de informação, frequentemente não captam a informação mais adequada e o tempo de captação muitas vezes excede o tempo ideal.
Existem dois desafios principais no processo de criação de perfis de utilizadores. Estes desafios são a geração de um perfil de utilizador inicial para um novo utilizador e a atualização contínua (manutenção) da informação do perfil, para adaptar as preferências, interesses e necessidades do utilizador o longo do tempo. Na literatura, foram propostos dois métodos fundamentais de criação de perfis para enfrentar esses desafios (Cufoglu 2014): um baseado no conteúdo e outro baseado na colaboração. Ambos os métodos têm limitações. Isso motivou a criação de um perfil de utilizador híbrido que, basicamente, resulta de uma combinação dos dois métodos já definidos, rendo sido proposto para superar as limitações dos dois métodos referidos.
Um método baseado em conteúdo assume que o utilizador realiza sempre o mesmo comportamento, específico, sob as mesmas circunstâncias (Araniti et al. 2003; Godoy & Amandi 2005; Kuflik & Shoval 2000). Por isso, neste tipo de método, o comportamento do utilizador atual é previsto com base no seu comportamento passado. Além disso, os perfis dos utilizadores são representados de forma semelhante aos das consultas do sistema, nos quais se faz a seleção dos itens que possuem uma alta correlação de conteúdo com o perfil do utilizador.
Quanto ao método colaborativo, este baseia-se na premissa de que os utilizadores que pertencem ao mesmo grupo (ex: a mesma idade, sexo ou classe social) comportam-se de forma semelhante e, portanto, têm perfis semelhantes (Araniti et al. 2003; Godoy & Amandi 2005; Kuflik & Shoval 2000). O método colaborativo é baseado em padrões de classificação de utilizadores semelhantes (Kuflik & Shoval 2000). Neste método, as pessoas com padrões de classificação semelhantes são referidas como "pessoas de mentalidade semelhante" (Kuflik & Shoval 2000). O método, colaborativo ignora o conteúdo de um dado item, fazendo a recomendação dos itens apenas com base em semelhanças.
O método hibrido conjuga o melhor dos dois métodos apresentados. Um sistema que empregue um método híbrido fornece uma descrição mais precisa dos interesses e preferências do utilizador. Geralmente, um método híbrido atribui a um novo utilizador um perfil padrão, recorrendo ao uso
de um método colaborativo, melhorando o perfil de um utilizador através de um método baseado em conteúdo.
Se nos situarmos na área de profiling, pensamos genericamente a captar comportamentos passados de utilizadores e a partir da sua caracterização fazer a construção de um "dicionário de utilizadores", no qual se armazena a informação sobre as sessões com uso mais comum ou típico. Este dicionário contém resumos de valores que reportam a aparência de um comportamento ou um padrão de comportamento multivariável. O comportamento futuro dos utilizadores pode, assim, ser previsto, de alguma forma, com base no seu passado. No entanto, devemos ter sempre em consideração que nunca podemos ter a certeza de que o dicionário indica a informação correta para o utilizador a que corresponde, devendo-se fazer sempre uma investigação cuidadosa sobre tudo aquilo que é observado (Cortes et al. 2000). Neste trabalho, aplicamos algumas técnicas de
profiling na construção da assinatura baseada num método hibrido, no qual teremos um conjunto de variáveis que caracterizam o utilizador, povoadas através de dados antigos, mas que sofrerão atualizações ao longo do tempo, à medida que nova informação vá surgindo.
2.2
Cálculo de uma Assinatura OLAP
Basicamente, uma assinatura sustenta um processo que facilita a análise de comportamentos. Como tal, uma assinatura OLAP é o reflexo de um comportamento normal de consultas sobre estruturas multidimensionais construído através de perfis de utilizadores. Estes podem ser vistos como conjuntos de dados que armazenam a descrição das suas características utilização. Um perfil corresponde, pois, à assinatura de um dado indivíduo, consistindo na representação digital e explícita da identidade de uma dada pessoa. As assinaturas são utilizadas para identificar ou representar indivíduos. Exemplos de sistemas computacionais que fazem uso de assinaturas são, por exemplo: as redes sociais (Facebook ou LinkedIn); os sistemas operacionais (Microsoft Windows Profile); os setores comerciais para estratégias de marketing sobre clientes; e os setores financeiros para concessão de créditos e prevenção de fraudes. Existem diversas metodologias para a geração de perfis de utilizadores. A sua aplicação inclui a definição e a manutenção de assinaturas como uma forma prática de caracterizar o comportamento de um dado indivíduo, num dado ramo de atividade, ao longo do tempo.
Um utilizador OLAP realiza uma série de consultas analíticas com o intuito de responder a um dado estudo que tem em mente, por exemplo, um analista que deseja perceber a evolução das vendas de carros em várias lojas espalhadas pelo país. Para chegar a esse resultado o utilizador pode começar com um pequeno conjunto de consultas parciais, por exemplo, “Quais as lojas mais rentáveis do último trimestre?”. Em seguida, e já com base nos resultados da pergunta anterior, ele pode querer saber: “Quais os carros mais vendidos nessas lojas?”. Este processo continuará até ele obter quilo que lhe interessa.
As consultas OLAP realizadas por um dado utilizador são um indicativo do que realmente é relevante para esse utilizador, num dado momento. A distribuição da frequência de repetição de cada consulta efetuada corresponde a um histórico de execução de consultas do utilizador. Ter esse histórico em consideração na hora da decisão sobre a escolha de qual a vista que deve ser materializada é muito importante, pois a escolha é feita de acordo com o que é realmente importante para o utilizador. Assim, as assinaturas OLAP (A-OLAP) são um conjunto de informações extraídas a partir do registo histórico de consultas OLAP, feitas por utilizadores, com vista a um dado fim. As A-OLAP são utilizadas para melhorar o desempenho do processamento de consultas (Lopes et al. 2011; Mota et al. 2014; Cortes & Pregibon 2001; Edge & Falcone Sampaio 2009; Ferreira et al. 2006; Belo & Monsanto 2012). O primeiro passo na definição de uma assinatura concreta é a correta seleção do conjunto de variáveis que a vão definir e sustentar. Para essa seleção ser realizada de forma adequada, é necessário fazer uma investigação sobre a instituição em causa e a utilização que se pretende ter com esta tecnologia.
Desde a origem do termo assinatura, vários autores têm realizado trabalhos recorrendo a diferentes definições e implementações de assinaturas. Por exemplo Cortes & Pregibon (2001) definiram uma assinatura como sendo um modelo e um vetor de parâmetros no qual o modelo consiste na forma como as distribuições de probabilidade descritas são combinadas. Assim, uma assinatura em si é uma estimativa da distribuição de probabilidades conjuntas de todas as variáveis ou características de um dado componente e partem de uma suposição padrão, que é: todos os componentes de uma assinatura devem ser tratados como se fossem independentes. Desta forma, o modelo de independência é simplesmente o produto marginal, podendo-se pressupor que existe uma assinatura para todas as entidades da rede. Por seu lado, Ferreira et al. (2006) definiram que uma assinatura de um utilizador corresponde a um vetor de variáveis de características cujos valores são determinados durante um determinado período de tempo, o que
propuseram, uma assinatura pode conter variáveis simples, se acolherem um valor atômico único (ex: inteiro ou real) ou complexas, se acolherem valores estatísticos co dependentes, tipicamente a média e o desvio padrão de uma determinada característica. Segundo Ferreira et al. (2006) uma assinatura S é obtida a partir de uma função ƒ, para uma determinada janela temporal w, em que S = ƒ (w) ( Figura 1).
Figura 1: Modelo para análise da variação de uma assinatura (Ferreira et al. 2006).
Nestes casos a assinatura é contruída através de um conjunto de variáveis. Depois, á medida que vão surgindo novos dados, é determinado um desvio considerado como anormal, com valores fornecidos pela assinatura. Complementarmente, definiu-se nesse trabalho uma função distância que pode ser calculada como a Figura 2 apresenta.
Figura 2: Cálculo de distâncias entre assinaturas (Belo & Monsanto 2012).
Depois de calculada a distancia verifica-se que, se os valores excedem um determinado limite definido, Dist (S; C) > 0, é lançado um alarme, caso contrário o utilizador é considerado dentro do seu comportamento normal. Mais tarde, Belo & Monsanto (2012) demostraram uma outra aplicação do conceito de assinatura, calculando-a através de um outro conjunto de valores (Figura 3).
Neste último caso, para o cálculo da assinatura, foram definidos pesos para os seus atribuídos que, neste caso, são diretamente proporcionais à sua importância no processo - todos os pesos foram definidos com base na experiência dos analistas envolvidos. Assim, generalizando o processo de assinatura, podemos dizer que o valor de uma assinatura pode ser calculado a partir da soma da média dos valores variáveis representativas das características da assinatura, multiplicados pelo seu coeficiente de importância (Figura 4).
Figura 4: A fórmula de cálculo de uma assinatura (Belo & Monsanto 2012).
Associados á deteção de fraudes, existem outros trabalhos que aplicam e utilizam o termo assinatura com outros objetivos. As assinaturas, como já foi mencionado anteriormente, são essencialmente representações matemáticas de atividades ou de comportamentos. Estas podem ser usadas para detetar fraudes através de técnicas de proffiling, nas quais as transações realizadas pelos sistemas em causa são comparadas com perfis fraudulentos já estabelecidos (Lopes et al. 2011; Mota et al. 2014; Edge & Falcone Sampaio 2009; Ferreira et al. 2006). Por exemplo (Edge & Falcone Sampaio 2009), tal como podemos ver na Figura 5, neste trabalho existe um conjunto de dados treinado com exemplos de fraude que é comparado com as assinaturas dos utilizadores, que vão sofrendo alterações á medida que vão crescendo. Este processo tem dois desfechos possíveis, ou a assinatura é atualizada, caso esta seja considerada dentro dos valores normais, ou então, lança-se um alerta que identifica uma potencial situação de fraude.
Figura 5: Esquema do processamento de uma assinatura (Edge & Falcone Sampaio 2009).
Embora neste exemplo seja representado um caso no qual a assinatura vai sofrendo atualizações, existem porém outros autores que defendem que a assinatura não deve ser atualizada, porque a atualização pode lentamente alterar a assinatura e fazer com que ações fraudulentas sejam consideradas normais (Cortes & Pregibon 2001; Cortes et al. 2000). Uma das principais ideias por trás do conceito de assinatura é dar a noção de que os dados variam consoante o utilizador e a plataforma, sendo personalizados de visitante a visitante, o que faz lentamente a mudança da lentamente ao longo do tempo.
2.3
Métodos para a Atualização de Assinaturas
Um dos grandes problemas da informação armazenada é a forma como esta é atualizada. Existem dois modelos de processamento comuns: um, orientado por eventos e outro em função da duração de tempo (event-driven e time-driven). Na atualização por eventos, cada novo resultado advém da atualização da assinatura associada a um dado registo. Na atualização por tempo, os registos são temporariamente armazenados e após terminar o seu período de tempo de armazenamento os registos são resumidos e as assinaturas atualizadas. Cada método tem o seu próprio conjunto de limitações, as quais se tornam visíveis quando vemos o que a atualização realmente significa (Edge & Falcone Sampaio 2009). A atualização de uma assinatura pode ser desenvolvida em três etapas: leitura da assinatura, alteração dos valores da assinatura de acordo com algum algoritmo e escrita da assinatura atualizada (Cortes & Pregibon 2001)
Uma das primeiras ideias que causou divergência no domínio das assinaturas foi o método de atualização. Como já referimos, nem todos os autores partilhavam a ideia que as assinaturas precisam de ser atualizadas para refletir o comportamento mais recente. Porém, um dos desafios estatísticos de um perfil é a necessidade de adaptar as assinaturas às mudanças nos padrões de utilização para combater a existência de outliers. (Cortes & Pregibon 2001; Cahill et al. 2002) propõe não atualizar as assinaturas com um determinado registo se o registo for demasiado desviado da assinatura, (Ferreira et al. 2006) propõe atualizar sempre a assinatura. Mas, o trabalho (Ferreira et al. 2006) demonstra como as assinaturas podem ser atualizadas para incorporarem as transações de contas mais recentes no histórico de um comportamento mantido e para uso em futuras operações de avaliação de assinaturas. Segundo este trabalho a revisão do valor da assinatura em relação aos novos dados de utilização deve, portanto, refletir com precisão as transações recentes, no caso tratado, da conta de telefone associada, sem perda total do histórico transacional anterior. Isto é alcançado através da implementação de uma nova função de ponderação linear, que determina a taxa em que os dados antigos são "envelhecidos" em cada reavaliação do valor da assinatura. Na Figura 6 está ilustrado o esquema da evolução de uma assinatura ao longo do tempo. Nesse esquema S corresponde ao valor inicial da assinatura do utilizador. Após uma mudança de unidade de tempo, a assinatura S é então atualizada para S’ com as novas informações de uso e onde o delta t é a unidade de tempo que verifica se a assinatura está dentro dos limites considerados.
Figura 6: Ilustração da evolução de uma assinatura ao longo do tempo (Ferreira et al. 2006).
Na Figura 7 está a expresso de cálculo que utilizada por (Ferreira et al. 2006) para fazer a atualização de uma assinatura. Nessa expressão a constante β é regulada pelo analista de fraude para determinar o efeito das novas ações sobre o valor de assinatura mantido e para a adaptação da atualização de assinatura, dependendo do modelo de processamento adotado.
Em implementações orientadas a tempo, o fator de ponderação usado é normalmente um valor constante que determina uma taxa para a qual os dados antigos tornam-se irrelevantes. Por exemplo, em (Cortes e Pregibon 2001), é demonstrado como um valor de β = 0,85 pode ser usado
para eliminar todos os dados maiores que 30 dias antes, e β = 0,5 todos os dados maiores que 7 dias. Em aplicações orientadas à ação, β é definida como uma função do registo do tempo entre as chegadas. Embora a assinatura da conta seja atualizada por transação, o valor da assinatura é mantido durante um período de tempo fixo (por exemplo, semana ou mês) para minimizar a falsa rotulagem de anomalias de transações e suportar variações comportamentais entre a conta, garantindo o efeito de uma nova atividade na assinatura proporcional à taxa de chegada da transação. Atribuir β = β (taxa de transação), garante que novas transações tenham maior influência em contas de utilizadores infrequentes que demonstram padrões de uso estáveis e relativamente menos peso em contas altamente ativas que tendem a ilustrar comportamentos de gastos mais voláteis.
Figura 7: Atualização da assinatura de acordo com (Ferreira et al. 2006).
A atualização de uma assinatura torna-se cada vez mais complexa ao lidar com transações ambíguas, como é o caso quando os dados sinalizados são usados para atualizar a assinatura da conta mantida. As propostas de (Cortes & Pregibon 2001) e (Cahill et al. 2002) revelam que as assinaturas só devem ser revisadas em relação a instâncias de dados legítimas, com atividade sinalizada, sendo a revisão alertada para o analista de fraude para uma investigação mais aprofundada. Em contraste, (Ferreira et al. 2006) argumenta que todas as instâncias recebidas, incluindo possíveis fraudes, devem ser usadas para atualizar a assinatura da conta devido à possibilidade de transações alertarem falsos alarmes, após uma análise mais aprofundada. Isso garante que os dados não sejam perdidos no caso de instâncias falsas. No entanto, esses autores requerem a implementação da funcionalidade de reversão apropriada para remover quaisquer instâncias da assinatura que, posteriormente, sejam confirmadas como empresas fraudulentas.
2.4
Preferências de Utilização
Cada vez mais enfrentamos questões relacionadas com aspetos de otimização, redução de espaço e de custos, rapidez de resposta e de segurança. Todos estes aspetos são fundamentais. Muitos trabalhos de investigação foram desenvolvidos em áreas nos quais tais aspetos se revelam frequentemente. Assinaturas e preferências são dois conceitos que em conjunto ainda não foram
alvo de grandes investigações, no entanto são áreas que podem facilmente ser associadas, sendo capazes de propiciar resultados muito interessantes na análise de aspetos como os referidos. Além disso, uma das grandes vantagens das assinaturas é a indicação de preferências através da análise de comportamentos. No entanto, as preferências não exprimem nem compõem uma assinatura.
As preferências são um termo com origem bastante mais recente, dinamizado por Golfarelli e Rizzi
(Golfarelli & Rizzi 2009). Nos últimos anos têm sido um tópico de investigação e desenvolvimento, cada vez mais estudado, não só em ambientes académicos e de investigação, mas também no setor empresarial. Veja-se, por exemplo, o caso da personalização de um data warehouse. Um DW
pode ser personalizado por um utilizador quando este expressa preferências em queries OLAP (Golfarelli & Rizzi 2009). Um dos métodos para melhorar esse processo, consiste na recomendação de queries no data warehouse por utilizador. As recomendações OLAP forma propostas em (Giacometti et al. 2009) e (Jerbi et al. 2009). Giacometti et al. (2009) utilizaram a informação de antigas sessões de trabalha de um mesmo utilizador num data warehouse para analisar e extrair informação pertinente para a caracterização do seu comportamento. Em (Jerbi et al. 2009) estudou-se perfis de utilização contendo preferências de um utilizador para gerarem recomendações para consultas. Posteriormente, em (Kozmina & Niedrite 2010) - OLAP Personalizaton with User-describing Profiles - foram apresentados vários tipos de personalizações OLAP. Outros exemplos de abordagens baseadas em preferências são:
a preferência em construtores, que basicamente consiste numa álgebra que permite a formulação de preferências sobre atributos, medidas e hierarquias;
a personalização dinâmica que permite de uma forma dinâmica, para diferentes utilizadores, fazer a definição e posterior criação de cubos OLAP, isto significa que um cubo OLAP é adaptado durante o tempo de execução de acordo com as necessidades e ações que um utilizador vai apresentando e realizando;
a análise de sessão do utilizador, na qual se utiliza os padrões de análise criados a partir de dados anteriores sobre os utilizadores registados no ficheiro log de consulta de um servidor OLAP durante as sessões que por ele são levados a cabo;
a análise de preferências do utilizador, que propõe um método baseado num dado contexto de análise para fornecer aos utilizadores recomendações que lhes permitam fazer uma exploração mais efetiva; um contexto de análise pode incluir diversos conjuntos de cubos, medidas, dimensões, atributos, etc…
É de referir que, apesar das inúmeras fontes de informação que abordam a temática das expressões de preferências em OLAP, existem inúmeros problemas que dificultam a criação de um método standard capaz de expressar preferências em sistemas analíticos. Não é, pois, uma abordagem de simples aplicação. Porém, em contextos de aplicação específicos, tem revelado um grau de efetividade muito interessante.
2.5
Algoritmos para Seleção de Vistas
Os sistemas de suporte á decisão têm o papel de conciliar e integrar informação interna e externa subjacente às atividades e modelos de negócio de uma empresa numa única plataforma de dados. O objetivo principal é disponibilizar a informação necessária aos seus agentes de decisão durante um processo de tomada de decisão, nas diversas vertentes do negócio. Recentemente tem-se assistido a um aumento do investimento em investigação e desenvolvimento de técnicas de otimização. Estas técnicas são utilizadas no melhoramento do desemprenho de sistemas de suporte á decisão.
A materialização de vistas é outra das técnicas mais utilizadas na otimização do processamento de interrogações. Basicamente, esta técnica assenta no conceito de antecipação do cálculo (total ou parcial) das interrogações, de forma a minimizar o impacto que os seus tempos de resposta teriam no desempenho global do sistema, bem como das necessidades de armazenamento associadas. Hoje, já existem disponíveis alguns algoritmos que tentam resolver com alguma efetividade o problema da seleção de vistas materializadas. No entanto nenhum deles recorre ao conceito de assinatura para resolver o problema do processamento e materialização da “melhor” vista de dados. Alguns dos algoritmos mais referidos na literatura são, nomeadamente, o Greedy
(Harinarayan et al. 1996), o HRU (Vijay Kumar & Ghoshal 2009), o PGA (Nadeau & Teorey 2002) e o BPUS (Shukla et al. 1998). Todos estes algoritmos apresentam soluções bastante idênticas. De seguida, apresentamos uma pequena caracterização de cada um deles. Para um conhecimento mais alargado de cada um deles, sugerimos a leitura das várias referências apresentadas.
2.5.1 O Algoritmo Greedy
O algoritmo Greedy (Harinarayan, 1996) baseia-se em métodos greedy (gananciosos), tendo como é minimizar o tempo necessário para efetuar uma avaliação sobre a lattice, arvore de agregação do cubo e, como tal, reduzir o seu tempo de processamento. O algoritmo básico pode ser observado na (Figura 8). Este algoritmo apresenta as seguintes propriedades: o número de vistas a materializar é previamente estipulado; os cuboides que constituem a lattice possuem um custo associado, que são passados como parâmetro – e.g. o espaço que ocupariam depois de materializados ou a frequência com que são consultados no servidor OLAP; o nodo que contém informação sobre todos os atributos é sempre materializado (root).
Figura 8: Pseudo Código Algoritmo Greedy(Harinarayan et al. 1996).
2.5.2 O Algoritmo HRU
O algoritmo HRU (Hanusse et al. 2009) (Figura 9) é um algoritmo de seleção que tem como objetivo tratar a presença e a conciliação de três medidas de performance, que permitem avaliar a execução de um algoritmo de seleção. Essas medidas são a quantidade de memória que se utiliza para materializar um cubo, a complexidade do próprio algoritmo e os custos de processamento de uma querie sobre um conjunto de cuboides. Este algoritmo considera a existência de estruturas de índices, custos de atualização e frequência das atualizações. Com isso consegue determinar um
uma forma muito simples, aquilo que o algoritmo HRU faz é avaliar cada nó não selecionado durante cada iteração, considerando em cada avaliação o efeito sobre cada nó descendente.
Figura 9: Pseudo Código Algoritmo HRU (Hanusse et al. 2009).
2.5.3 O Algoritmo PGA
Tal como o algoritmo HRU, o algoritmo PGA (Nadeau et al. 2002) (Figura 10) seleciona uma vista para materializar em cada uma das suas iterações. Contudo, este algoritmo divide cada iteração em duas fases: nomeação e seleção. A primeira fase é responsável por nomear as vistas promissoras, com base num conjunto de vistas candidatas e depois escolher um caminho válido desde a raiz até ao topo da lattice do cubo em questão. Já na segunda fase, o algoritmo faz a previsão dos benefícios da materialização de cada uma das vistas candidatas e seleciona a vista com a avaliação mais alta para proceder à sua materialização. O benefício da seleção é calculado de uma forma bastante simples, o algoritmo subtrai o peso estimado do nó em causa, com o seu nó antecessor materializado de menor custo, multiplicando-o depois pelo número de nós dependentes.
Desta forma, o algoritmo PGA evita as duas fontes de complexidade exponencial no que diz respeito ao número de dimensões, dado que durante as iterações não considera todos os cuboides que ainda não foram analisados e que constam na lattice do cubo, mas também não efetua os
cálculos associados a todos os cuboides descendentes de um dado cuboide previamente selecionado.
Figura 10: Pseudo Código Algoritmo PGA (Nadeau et al. 2002).
2.5.4 O Algoritmo BPUS
O algoritmo BPUS (Gupta, 1997) (Figura 11) é um dos algoritmos de processamento mais discutidos e estudados. Este utiliza grafos acíclicos orientados para representar as vistas e as interrogações realizadas sobre um cubo. O algoritmo BPUS utiliza um grafo como base de trabalho, no qual cada nó representa uma operação de agregação, seleção, projeção ou junção. A cada nó desse grafo está associado um tamanho (número de tuplos) e uma frequência de interrogação (número de vezes que o nó foi acedido). Em cada uma das iterações que realiza, o algoritmo BPUS seleciona a vista com o maior benefício por unidade de espaço. O cálculo do benefício de uma vista é realizado com base na diferença dos custos de processamento do conjunto de vistas materializadas com e sem a vista em questão.
Capítulo 3
3
Um Modelo Baseado em Assinaturas OLAP
3.1
As Assinatura OLAP
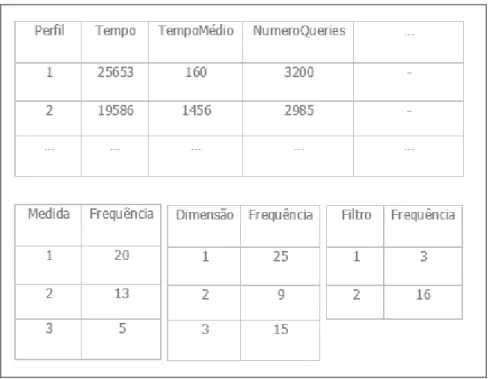
Em termos gerais, as assinaturas podem ser aplicadas com sucesso num enorme conjunto de áreas de aplicação – e.g. deteção de fraude, materialização de vistas, validação de credenciais. Para que isso possa acontecer, nestas áreas, são utilizadas várias técnicas de profiling através das quais são traçados perfis dos diversos utilizadores envolvidos nos processos em tratamento. Para além destas áreas existem muitos outros negócios que cada vez mais recorrem ao conceito de assinaturas para aumentar a performance dos seus negócios. Como o próprio nome indica, uma assinatura é uma “marca” que foi colocada em algum documento, com vista a atribuir-lhe uma identificação ou referir algum tipo de validação. Uma assinatura OLAP possui o mesmo significado de uma assinatura comum. A diferença está na forma como é aplicada e nos resultados que pretendemos obter para além da identificação regular do utilizador. Neste caso, uma assinatura OLAP pode ser usada para selecionar um conjunto mais especifico de informação (Figura 12). Ao utilizarmos assinaturas OLAP, estamos a dar enfase à variação temporal do comportamento de um dado perfil de exploração analítico, isto é, através das consultas realizadas podemos conhecer a forma como um dado utilizador atua e os dados a que normalmente acede.
Figura 12: Exemplo de uma assinatura OLAP.
Neste exemplo (Figura 12) é apresentada uma tabela com as variáveis estatísticas sobre o comportamento geral dos utilizadores e a forma como eles atuam, e temos os dados a que normalmente acedem (Medidas, Dimensões e Filtros) e as suas respetivas frequências para facilitar a seleção.
No âmbito deste trabalho, adotámos o conceito de personalização dinâmica definido por Kozmina e Niedrite (2010) em que defendem que uma dada variação da assinatura de um perfil de utilização sugere uma reestruturação de um cubo OLAP, o que na prática significa uma adaptação gradual àquilo que o utilizador vai fazendo. No entanto a variação de uma assinatura e a sua atualização têm de ser um processo lento, gradual, que vai ocorrendo durante os períodos de exploração das estruturas analíticas. A definição de uma assinatura tende a estabilizar num dado conjunto de valores que identificam e definem o perfil de utilização à qual corresponde. Além disso, temos que assegurar também que os dados novos, provenientes de novos comportamentos do utilizador, que sejam em quantidade inferior aos dados já analisados, não alteram drasticamente a assinatura. Como tal, é importante que se definam pesos a cada um dos aspetos (características) de uma assinatura. Ao fazermos a definição dos pesos desses aspetos pretendemos definir qual o impacto de cada um deles na definição final do valor da assinatura, bem como controlar a forma como os
longo dos tempos das sessões realizadas pelos utilizadores nos sistemas OLAP. Estas variações, além de poderem ser identificadas através da assinatura, por exemplo através de comparações homologas dos dados, não refletem o problema em concreto, pois á medida que vão sucedendo impõem o reajustamento dos dados, o que faz com que estes sejam sempre o reflexo do comportamento dos utilizadores.
Estatisticamente, uma assinatura pode ser descrita como uma estimativa da distribuição de probabilidades de um conjunto de um grupo de componentes selecionados. De acordo com Cortes e Pregibon (2001) tal conjunto de componentes pode ser visto como o conjunto de variáveis cujos valores são determinados através de uma dada janela temporal, que delimita as fronteiras da definição do comportamento de exploração dos utilizadores e, consequentemente, da posterior definição da assinatura. Os componentes de uma assinatura devem ser tratados de forma independente, de modo a que o modelo de assinatura possa ser simplesmente um produto de distribuições marginais. Além disso, devemos ter em conta o período de tempo que consideramos relevante para a definição e manutenção de uma assinatura. Tudo isto aplica-se também ao caso das assinaturas OLAP.
No nosso caso, definimos que uma assinatura teria OLAP um dado ciclo C e um dado período P,
que regulariam a definição e a manutenção da assinatura. Basicamente, o ciclo compreende o período total de avaliação da assinatura, enquanto que o período compreende uma secção do ciclo claramente distinta dos restantes períodos dentro do mesmo ciclo. Este controlo e validação temporal são necessários porque um perfil de utilização pode ter diferentes comportamentos em diferentes períodos de tempo. De acordo com os requisitos do nosso processo de demonstração, definimos que o ciclo (C) seria trimestral e o período (P) mensal. Por exemplo, no caso, para a demonstração da utilização do nosso modelo de assinaturas, iremos utilizar dados referentes ao período de 01-01-2009 a 07-03-2010. Como tal, um ciclo de análise trimestral, com um período de avaliação distinta mensal, é a melhor opção, uma vez que permite definir um melhor equilíbrio entre os dados passados e as sus consequentes atualizações, suportando posteriormente as demostrações que forem necessárias realizar par análise das variações da assinatura ao longo dos ciclos considerados. A definição de um período mensal permite, pois, mostrar 3 comportamentos distintos da assinatura, e caracterizar os perfis dos utilizadores de acordo com essa definição. Os conceitos de período e ciclo nas assinaturas apareceram, assim, para possibilitar a caracterização de perfis de utilização, com características e necessidades de utilização diferentes em diferentes períodos de tempo. No nosso caso, como referido, adotaremos um período mensal, uma vez que
queremos caracterizar os utilizadores com base nas suas consultas mensais. Todavia, para o caso de pretendermos fazer esse trabalho em termos diários ou semanais, teríamos de mudar o período, respetivamente, para diário ou semanal, obviamente.
Uma assinatura OLAP pode ser usada para fazer a seleção de vistas OLAP necessárias aos perfis de utilização estudados, de forma a caracterizar potenciais padrões de utilização e estabelecer, por exemplo, um novo sistema de meta dados mais adequado e menos consumidor de recursos relativo às estruturas multidimensionais envolvidas nas sessões de exploração estudadas, ou então um sistema de caching baseado na informação disponibilizada pela assinatura. A aplicação de assinaturas oferece a um administrador de um sistema OLAP a possibilidade de reconfigurar o sistema de materialização a partir dos perfis de utilização estabelecidos. Este processo permitirá, mediante identificação do perfil de utilização a aceder, prever a próxima vista a ser consultada e proceder, por exemplo, à sua colocação em cache antes dessa consulta ser efetuada. Além disso, podemos também saber quando uma dada vista deixará de ser necessária, o que permite otimizar o espaço da cache fazendo a sua remoção quando deixar de ser precisa. Desta forma, poderemos ter acessos mais rápidos e mais eficientes aos dados realmente utilizados pelos utilizadores e uma gestão mais eficiente dos recursos envolvidos.
Como vimos, a definição e a caracterização de uma assinatura OLAP dependem de inúmeros elementos, que podem incluir a simples análise das queries executadas numa dada sessão de exploração ou consideração de aspetos temporais que cracterizem a forma como um dado utilizador explor os seus dados ao longo do tempo. De facto, o estabelecimento de um perfil de exploração não é algo de fácil obtenção e de caracterização. Porém, sabemos que quanto mais rico for esse perfil, mais conhecimento teremos sobre a forma como os nossos sistemas de dados são explorados e, com base nesse comhecimento, optimizar todos os processos relacionados com o seu processamento e armazenmento. De seguida, vamos analisar duas técnicas de análise que nos podem ajudar a fazer o referido enriquecimento.
3.2
As Classes de Equivalência
As técnicas que temos vindo a apresentar permitem-nos fazer a análise de processos de exploração de utilizadores através da identificação dos vários elementos de dados que são mais ou
são mais uma técnica que nos permite fazer também esse trabalho. O principal objetivo desta técnica é fazer a identificação da sobreposição dos domínios de consultas em estruturas multidimensionais de dados. Basicamente, as classes de equivalência permitem-nos ter uma ideia bastante concreta dos elementos de dados que são mais utilizados, bem como os seus diversos elementos constituintes. A classe de equivalência é um conceito proveniente da matemática, que foi exportado para outros domínios por diversos autores. Niemi, Numenmaa e Thanisch, em 2001, propuseram o uso desta técnica para encontrar similaridades entre queries multidimensionais, com a finalidade de identificar e caracterizar um novo cubo mais simples, que exigisse menos recursos, e que refletisse de forma bastante linear as necessidades de exploração dos seus utilizadores. De acordo com estes autores, duas queries são similares se ambas partilharem uma ou mais dimensões de forma direta ou transitiva (Niemi et al., 2001).
As classes de equivalência fornecem-nos elementos que nos permitem agrupar as queries lançadas sobre um determinado cubo OLAP, bem como informação por elas disponibilizada. Na Figura 13 podemos ver ilustrada, de uma forma bastante simplista, a forma como são identificadas as sobreposições de resultados das queries, que por si só definem um espaço de soluções que nos revela as áreas mais utilizadas pelos utilizadores e consequentemente as vistas de utilização.
Figura 13: Ilustração da sobreposição do espaço de solução de um conjunto de queries.
Colorindo cada uma das vistas geradas, a sua eventual sobreposição será representada por uma cor mais escura quanto maior for o número de sobreposições das vistas. No limite, a zona mais escura representará o bloco de dados mais solicitado, possivelmente identificando uma classe de equivalência. No entanto, esta observação de carácter empírico, não é o suficiente para a reestruturação efetiva do cubo, mas sim um princípio de avaliação.
No seguimento desta ideia em (Niemi et al., 2001) é proposto um algoritmo que divide queries MDX em classes de equivalência. O Algoritmo é executado da seguinte forma. Considere-se, um conjunto Q de queries MDX que foram lançadas sobre um determinado hipercubo. As queries consideradas nesse conjunto foram as seguintes:
1. Q1: SELECT dia, grupo_produto WHERE lucro, ano.[2010] 2. Q2: SELECT ano, id_loja WHERE quantidade
3. Q3: SELECT ano, id_produto, loja WHERE quantidade 4. Q4: SELECT dia, id_produto, id_cliente WHERE quantidade
O algoritmo de Niemi et al. (2001) desenvolve-se em quatro etapas distintas, são elas nomeadamente:
1) No primeiro passo, para cada querie, extrai-se os atributos da cláusula SELECT. Desta forma obtemos os seguintes conjuntos:
X1 = {dia, grupo_produto} X2 = {ano, loja}
X3 = {ano, id_produto, loja} X4 = {dia, id_produto, id_cliente}
2) No segundo passo, com base nas dependências funcionais de cada um dos conjuntos X estabelecidos, constrói-se o conjunto Y que contem as chaves.
Y1 = {dia, id_produto} Y2 = {dia, id_loja}
Y3 ={dia, id_produto, id_loja} Y4 = {dia, id_produto, id_cliente}
3) No terceiro passo, faz-se a construção das classes de equivalência da seguinte forma: duas queries Q e Q’ pertencem à mesma classe de equivalência E se for possível formar uma sequência de queries <Q0 = Q, Q1, ..., Qn, Q’ = Qn+1> tal que Yi ⋂ Yi+1 ≠ ∅ e 0 ≤ i ≤ n, em que Yi representa o conjunto de chaves de dimensão de Qi. O resultado produzido
E1 (tempo, produto) = {Q1, Q3, Q4} E2 (loja, produto) = {Q3}
E3 (tempo, produto, loja) = {Q3} E4 (produto cliente, tempo) = {Q4}
4) Além destes três passos, podemos realizar um outro passo adicional, que consiste em construir uma nova classe de equivalência E’ = {Q’}, para cada classe de equivalência Ei, para cada Q em Ei, se existir uma querie Qi em Ei, com as mesmas dimensões que Q, mas num nível de detalhe diferente de Q. De acordo com este, a classe de equivalência E1 pode ainda ser dividido em duas,
E1’(dia, produto) = {Q1, Q4}
Como visto e explicado acima, as classes de equivalência realizam divisões das queries com o objetivo de as agrupar através da informação que estas contêm. Neste trabalho a ideia de divisão e seleção foi desenvolvida segundo este conceito. No primeiro contacto que temos com as queries e com a sua respetiva informação, fazemos a divisão das queries, dividimos o corpo destas de forma a conseguir retirar a informação que consultam, a divisão é feita individualmente por dimensão e medida divididaspela cláusula Where. Esta divisão, da cláusula Where é feita para que consigamos saber qual a informação presente nos filtros, numa tentativa de conseguir uma informação mais detalhada.
No entanto, neste trabalho a principal divisão está na extração das medidas e nas dimensões de todas as queries. Esta extração de informação é feita, para que depois, quando possuirmos todas as queries executadas pelos utilizadores, seja mais fácil extrair toda a informação que eles consultaram. Depois de termos toda a informação consultada e analisada fazemos então a agrupação da mesma, no nosso caso não temos uma classe de equivalência sombreada como mostra a figura, mas temos uma “tabela” com a informação e a sua respetiva frequência, que nos permite criar grupos de informação. Ao criarmos os grupos conseguimos sinalizar qual a informação mais consultada e assim definir as dimensões e medidas que mais são consultadas por cada utilizador.
3.3
As Cadeias de Markov
Partindo do principio que um dado utilizador OLAP segue vária linhas de exploração e de análise de dados e que, normalmente, o seu comportamento pode ser conhecido através da correlação das várias interrogações que vai fazendo ao longo das sessões de exploração, então através da extração dos padrões de consultas conseguimos descobrir qual a informação que o utilizador mais consulta, em que períodos e com que frequência. Para podermos estabelecer tais padrões de exploração adotámos uma técnica híbrida, que combina vários dos conceitos das classes de equivalência anteriormente apresentados. Tal técnica pode ser aplicada de uma forma bastante simples. A forma como a aplicamos pode ser descrita da seguinte maneira: para cada um das queries que foi lançada numa dada sessão de exploração obtemos todas as queries que foram lançadas de seguida. Como cada querie transporta sempre as respetivas dimensões, medidas e respetivos filtros, apresentados usualmente nas suas cláusulas where,não é complicado retirar a informação transportada por cada uma das queries, bem como guardar a sua sequência de execução – o “caminho” da exploração de dados. Depois, após as queries serem identificadas e guardadas, tratamos de arranjar uma maneira para relacionar a informação obtida com as classes de equivalência com as sequências de queries identificadas. É, nesta altura, que utilizamos as cadeias de Markov.
Uma cadeia de Markov é um caso particular de processo estocástico com estados discretos que permitem analisar processos estocásticos e visualizá-los sob a forma de um grafo, e permitem ver as probabilidades de qualquer comportamento futuro, quando o seu estado atual é conhecida. Este conceito estabelece que em um conjunto de estados discretos, o futuro só depende do estado presente.As cadeias de Markov são matrizes de probabilidades que representam, nas suas células, as probabilidades de um estado suceder outro, ou seja representam a probabilidade de um estado i no tempo (n+1) dado que está no estado j no tempo n.
Considerando uma cadeia de Markov, matriz de probabilidades (Figura 14), que representa as sequências das consultas realizadas por um utilizador, com espaço de estados S = {1,2,3} com a matriz de transição estabelecida.
Figura 14: Matriz Probabilidades.
Assumindo que as probabilidades de transição são dadas pela seguinte tabela (Tabela 1):
Para 1 Para 2 Para 3
De 1 0 0.5 0.5
De 2 0.33 0 0.66
De 3 0.33 0.66 0
Tabela 1: Tabela de Probabilidades.
Considerando o seguinte exemplo das sessões (Tabela 2):
Sessão Estrutura da Sessão 1 Q1 -> Q3 -> Q2 2 Q1 -> Q2 -> Q3 3 Q3 -> Q1 -> Q2
Tabela 2: Sessões de exploração.
No seguimento deste exemplo, matriz de probabilidades (Figura 14) e sessões de exploração (Tabela 2), a cadeia de Markov seria a seguinte (Figura 15). Neste exemplo identificamos o estado inicial com sendo a querie 1 e o final como sendo a querie 3.
Figura 15: Exemplo Cadeia Markov.
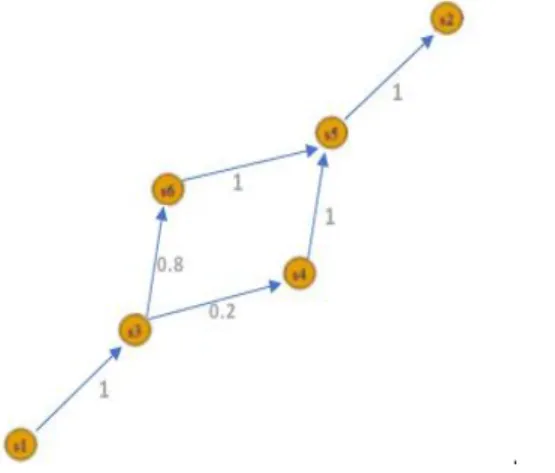
As cadeias de Markov são uma forma simples e eficaz de resolver problemas, pois permitem analisar e visualizar os comportamentos e as relações de elementos, sob a forma de grafos (Weber 2011). Assim, ao integrarmos as cadeias de Markov no nosso processo de categorização de exploração, asseguramos a relação entre uma dada querie e todas as outras que a sucederam ao longo das várias sessões de exploração, guardando ao mesmo tempo a sua probabilidade de ocorrência. Com a utilização das cadeias de Markov é possível estudar e traçar os comportamentos dos utilizadores, bem como estabelecer as relações que existam entre os diversos itens de informação consultados. A cadeia de Markov será assim alimentada com as diversas queries dos utilizadores, de forma incremental, permitindo acrescentar nova informação sem que afete as estruturas já estabelecidas. Outra das grandes vantagens das cadeias de Markov é a sua representação através de grafos, nos quais os vários nodos podem apresentar a probabilidade de um estado preceder ou anteceder um outro estado. O cálculo dessas probabilidades (P(A,B)) pode ser realizado através do número de vezes que um dado estado sucede um outro, cujo resultado pode ser obtido através da seguinte expressão:
A ( ).
Na Figura 16 podemos ver um exemplo de uma cadeia de Markov, na qual se representa uma sessão de consultas realizadas por um utilizador. A cadeia de Markov em questão inclui as probabilidades relativas às diversas passagens de estado, no qual cada querie é identificada por um nodo. Os estados s1 e s2. representam o início e o fim da cadeia, sendo, obviamente, nodos