Sistemas de Indexação
automática
Renato Fernandes Corrêa
Os atuais SRIs somente dão aos usuários a possibilidade de recuperar documentos por meio de consultas envolvendo palavras isoladas como ponto de acesso a documentos.
Casamento limitado da linguagem do usuário com
a linguagem do sistema
Trabalha apenas no nível léxico
Utiliza palavras isoladas, que sofrem com fenômenos linguísticos
Baixa precisão e excesso de documentos
retornados
Limitações
Sistemas de Indexação Automática
•
São sistemas que realizam a indexação automática de
documentos.
•
Veremos os sistemas:
• SISA (Sistema de Indexação Semi-Automático) foi desenvolvido na Espanha por Gil Leiva, sendo inicialmente proposto para a área de Biblioteconomia e Documentação, no entanto, a flexibilidade do sistema permite adaptar sua configuração para aplicar a qualquer área, desde que possua uma linguagem documentária.
• Realiza indexação automática por atribuição
• OGMA foi desenvolvido por Luiz Cláudio Gomes Maia na UFMG para
automatizar a extração dos sintagmas nominas e o cálculo do peso de cada termo na indexação dos documentos.
• Realiza indexação automática por extração
•
Diferentemente da abordagem tradicional de indexação
automática por extração de termos como palavras isoladas
do conteúdo dos documentos, estes sistemas trabalham
Ogma
•
Software de análise de texto que
pode ser utilizado para fins de
indexação automática.
•
O nome Ogma foi dado em
homenagem ao deus celta Ogma.
Considerado o deus que criou
mecanismos de linguagem e
engrandeceu a comunicação do povo
celta.
OGMA
•
O OGMA é uma ferramenta para análise automática de
texto, que é capaz de:
• a) extrair os sintagmas nominais.
• b) atribuir pesos aos sintagmas nominais extraídos de acordo com a frequência em que aparecem no texto.
• c) atribuir pesos aos sintagmas nominais extraídos de acordo com a frequência em que aparecem no texto e dentro de outros sintagmas nominais.
• d) Identificar a classe do sintagma nominal (CSN).
• e) Calcular a pontuação de cada sintagma nominal extraído.
• f) Extrair termos e atribuir pesos de acordo com sua frequência no texto.
• g) Extrair termos, exceto os constantes na lista de stopwords, e lhes atribuir pesos de acordo com sua frequência no texto.
• h) Calcular a similaridade entre duas listas de termos (extraídas do documento) utilizando o coseno.
Ogma em Números
Utiliza-se um banco de dados Access com:
Uma tabela contendo
41.978 nomes e adjetivos
.
Utilizando a ferramenta “conjugue”
e uma lista de 5.000
verbos foi construída uma tabela com
292.720 formas
verbais
.
Uma tabela contendo
490 preposições, artigos,
conjunções, etc
.
O banco de dados é utilizado para etiquetar as palavras do
texto com as classes gramaticais.
Sintagma Nominal - Definição
Sintagma
“
conjunto de elementos que constituem uma unidade
significativa dentro da oração e que mantêm entre si
relações de dependência e de ordem. Organizam-se em torno
de um elemento fundamental, denominado núcleo, que
pode, por si só, constituir o sintagma
.
”
Silva e Koch (2007)
“sintagma nominal
é a menor parte do discurso
portadora de informação
”.
SINTAGMAS NOMINAIS
•
O sintagma nominal possui uma estrutura bastante
complexa, pois é possível distinguir em sua composição
várias funções sintáticas.
ES
TRU
TUR
A
DE U
M
SN
SN Núcleo Determinantes Modificadores • Nome• Nome composto • Artigos • Pronomes demonstrativos • Pronomes Possessivos numerais • Pronomes indefinidos • Adjetivos • Locuções adjetivas • SN’s preposicionados • Orações adjetivas SN
... UM RESULTADO EXCELENTE
Nome
Art Adjetivo
Fonte:
Uma maneira para melhorar a eficácia de um SRI é dotá-lo de estruturas de indexação e recuperação baseadas em sintagmas nominais (SNs), que são capazes de descrever com maior exatidão os assuntos tratados nos documentos e permitem uma precisão maior na recuperação da informação.
Si
n
tagmas
Nomi
nai
s
estruturas gramaticais frasais
possuem substantivos como núcleo
são considerados melhores descritores de assunto
sofrem menos dos problemas de sinonímia, polissemia e ambiguidade das palavras isoladas
Documentos
Etiquetagem Morfossintática
Extração de sintagmas nominais
Ranqueamento e seleção de SN’s
Indexação
Construção da Interface
EXTRA
ÇÃ
O DE SN’
S
o texto é inserido no software, que solicita ao usuário qual etiquetador utilizar, obtendo
como saída o texto etiquetado com o padrão de etiquetas específico do
etiquetador.
Devido a diversidade nos padrões de etiquetas utilizadas nos etiquetadores,
adota-se o padrão utilizado por Maia (2008) na construção da ferramenta de extração de sintagmas nominais OGMA.
São aplicadas as regras de extração de sintagmas Nominais descritas por Maia
(2008) para obtenção dos SN's.
Etiquetagem Morfossintática
Conversão de etiquetas para o formato das regras
de extração de SNs
Extração de Sintagmas
Regras utilizadas por Maia (2008)
Etiqu
eta
gem
Mor
foss
intát
Regras utilizadas por Maia (2008)
Extr
ação
de
Sinta
gmas
CL
ASS
IFICA
ÇÃ
O
DOS S
N’
S
Fonte: MAIA(2008)
Categorias Gramaticais
Classificador Substantivos
Sub-Classificador AdjetivosPronomes possessivos Qualificador Adjetivos
A tutela dos direitos da personalidade por meio da aplicabilidade direta do princípio da dignidade da pessoa humana nas relações de direito privado. O presente trabalho faz um
estudo do sistema de proteção dos direitos da personalidade no ordenamento jurídico brasileiro ...
A/AD tutela/NP dos/PR direitos/NP da/PR personalidade/NP por/PR meio/NP da/PR aplicabilidade/NP direta/AJ do/PR princípio/NP da/PR dignidade/NP da/PR pessoa/NP
humana/AJ nas/PR relações/NP de/PR direito/NP privado/AJ ./PN O/AD presente/AJ trabalho/NP faz/VB um/AI estudo/NP do/PR sistema/NP de/PR proteção/NP dos/PR direitos/NP da/PR personalidade/NP no/PR ordenamento/NP jurídico/AJ brasileiro/AJ
Sintagmas Nível 2
Ogma - Interface
Ogma
Ogma
–
Termos Etiquetados
Ogma
–
Sintagmas Nominais Simples
Ogma
–
Termos Pontuados
Ogma
–
Lista de Termos sem "stopwords"
O SISA - INTRODUÇÃO
•
O Sistema de Indización Semi- Automático
desenvolvido na Espanha por Gil Leiva (1999- 2008)
foi inicialmente proposto para a área de
Biblioteconomia e Documentação.
Professor Isidoro Gil Leiva (Professor da Universidade de Murcia-Espanha)
http://webs.um.es/isgil
SISA
•
O SISA analisa as partes do documento que estão
delimitados com marcadores para que o sistema
possa reconhecer as fontes (título, resumo e texto)
e aplicar seus critérios para propor os termos de
indexação.
•
As fontes utilizadas no processamento pelo SISA
são:
•
o texto completo (título, resumo e texto),
•
uma lista de palavras vazias (
stoplist)
•
e
uma linguagem documentária,
•
Todos os arquivos em formato txt.
O SISA é um sistema semi-automático de
indexação
A metodologia aplicada por esse software no processo de
análise do documento é efetuada pela comparação entre o
documento
–
constituído por título, resumo e texto
–
e uma
linguagem documentária, levando em conta critérios
preestabelecidos de frequência e posição no documento
para propor os termos de indexação.
O usuário pode escolher entre os termos sugeridos pelo
sistema para um documento quais ele gostaria de manter,
bem como quais ele gostaria de incluir no vocabulário
SISA
–
Método
• O processo de indexação se desenvolve em três módulos:
No módulo 1 o documento é preparado sinalizando-se as partes com
marcadores, frases e orações compreendidas entre sinais de pontuação são horizontalizadas, ocorre também a eliminação das palavras vazias mediante a comparação com a lista de palavras vazias e então é
computado o total de palavras das fontes título, resumo e texto.
No módulo 2 ocorre a etapa de análise do conteúdo, processamento em
que um algoritmo busca e seleciona termos.
O módulo 3 é a etapa de valoração e ponderação de termos que consiste
na aplicação de critérios de avaliação dos termos para que o sistema possa selecionar os termos de indexação que representarão o conteúdo do documento. Isso é necessário, pois do contrário, o sistema
selecionaria todos os termos da linguagem documentária que coincidem com os das fontes.
Módulo 1 – Fase de Pré-Processamento
•
Preparação do documento com as demarcações de início e fim do
título; do resumo e do corpo do texto.
O documento, no formato TXT,que vai ser indexado, é sinalizado com os marcadores exigidos pelo SISA que são: #CTI# e #FTI# para o Título, #CR# e #FR# para o Resumo e #CTE# e #FTE# para o Texto.
Os marcadores utilizados são:
#CTI# (começo do título), #FTI (fim do título),
#CR# (começo do resumo), #FR# (fim do resumo),
#CTE# (começo do texto) e #FTE# (fim do texto).
• Isso é preparado para que, posteriormente, os cálculos de ponderação sejam realizados a partir da identificação da frequência nessas estruturas denominadas, fontes.
Módulo 1 – Fase de Pré-Processamento
Ne
ste módulo, ainda são realizadas as etapas:
1) a eliminação das palavras vazias por meio do confronto
do documento com a Lista de Palavras Vazias (
stopwords
)
• são eliminadas as palavras vazias através da comparação com uma lista de palavras vazias pré definida pelo usuário.
2)
a
horizontalização,
em
que
frases
e
orações
compreendidas entre os sinais de pontuação (. , ; :) são
dispostas em forma horizontal, isto é, são separadas em
cada linha do texto.
3)
Computação da frequência de palavras nas fontes
título, resumo e texto.
O SISA - MÉTODO
Módulo 2
–
Fase de Processamento
Ocorre a etapa de análise do conteúdo, processamento
O SISA - MÉTODO
O módulo 2:
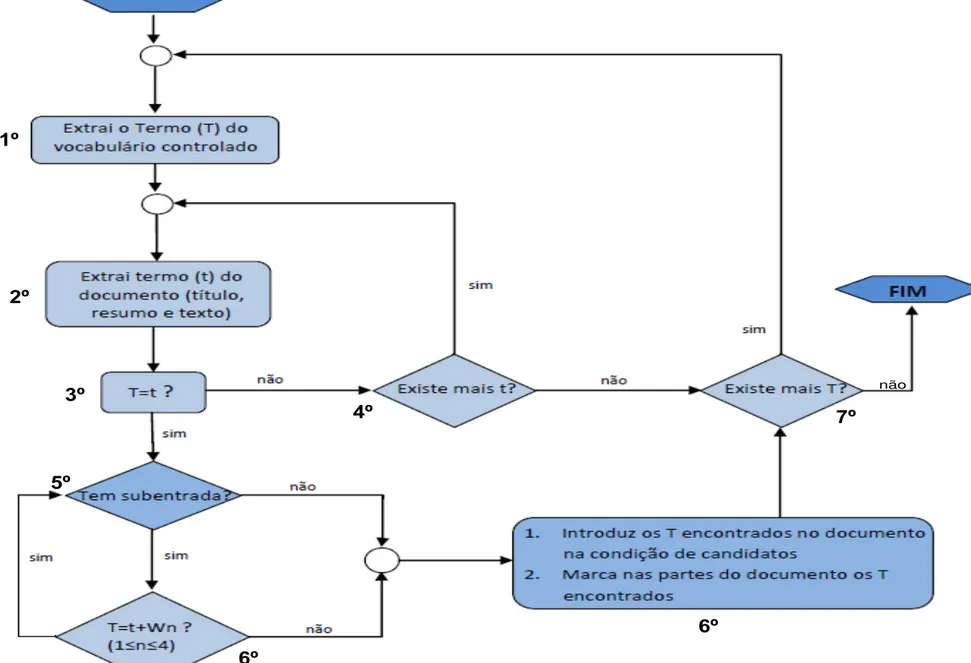
Figura 7. Diagrama de fluxos do algoritmo SISA do módulo II.
1º
2º
3º
4º
5º
6º
6º
7º
não
2.2
Indexação Automática por atribuição
Aplicação do SISA / Uso do Tesauro
1º 2º. 4º. 5º. 3º. 6º. 7º. 6º. não
Módulo 2
Fase de
Processamento
Nesta fase o documento
é analisado e os termos
de
indexação
são
identificados
e
2.2
Indexação Automática por atribuição
Aplicação do SISA / Uso do Tesauro
1º 2º. 4º. 5º. 3º. 6º. 7º. 6º. não
Módulo 2
O Processamento
1º)
Extrai-se o primeiro
termo
do
vocabulário
controlado (tesauro);
2º)
Extrai-se o primeiro
termo
da
fonte
(texto
completo);
3º)
Verifica-se se os termos
2.2
Indexação Automática por atribuição
Aplicação do SISA / Uso do Tesauro
1º 2º. 4º. 5º. 3º. 6º. 7º. 6º. não
Módulo 2
O Processamento
2.2
Indexação Automática por atribuição
Aplicação do SISA / Uso do Tesauro
1º 2º. 4º. 5º. 3º. 6º. 7º. 6º. não
Módulo 2 – O Processamento
5º) Se a palavra da fonte e o termo
2.2
Indexação Automática por atribuição
Aplicação do SISA / Uso do Tesauro
1º 2º. 4º. 5º. 3º. 6º. 7º. 6º. não
Módulo 2 – O Processamento
2.2
Indexação Automática por atribuição
Aplicação do SISA / Uso do Tesauro
1º 2º. 4º. 5º. 3º. 6º. 7º. 6º. não
Módulo 2
–
O Processamento
7º)
Confirma-se se há mais
termos (
T
) no vocabulário
controlado: Se não existem
mais palavras, finaliza-se o
processo. Se houver mais
palavras,
continua-se
o
Indexação Automática por atribuição
Aplicação do SISA / Uso do Tesauro
Módulo 3 – Ponderação dos Termos
-
Nesta fase, os termos que foram analisados pelo
sistema, são ponderados. Aqui é feita a valoração e
ponderação, nesse etapa o sistema classifica termos de
acordo com critérios que indicam relevância na
indexação.
Indexação Automática por atribuição
Aplicação do SISA / Uso do Tesauro
Módulo 3 – Ponderação dos Termos
O sistema considera os seguintes critérios para propor os termos de
indexação:
1
–
Se um termo autorizado aparece na fonte-título e na fonte-resumo,
apresenta-se como termo de indexação.
2
–
Se um termo autorizado aparece na fonte-título e na fonte-texto,
apresenta-se como termo de indexação.
3
–
Se um termo autorizado aparece na fonte-resumo e na fonte-texto,
apresenta-se como termo de indexação.
4
–
Se o termo candidato a descritor aparece no título, no resumo e no
texto, apresenta-se ao indexador para sua possível incorporação como
termo de indexação.
5
–
Se um termo candidato a descritor aparece no texto dez vezes ou
O SISA - MÉTODO
No módulo 3:
É apontado como termo de indexação,
o termo
autorizado que aparece em duas fontes diferentes
:
No título e no resumo;No título e no texto;
No resumo e no texto;
Termos são considerados candidatos quando, as palavras
semi-vazias aparecem:
No título, resumo e texto;No texto dez vezes ou mais;
No texto aparece em oito parágrafos diferentes ou mais.
SISA
–
Configurar indexação
SISA - Configuração
SISA
–
Selecionar Arquivos
SISA - Marcação
44
SISA - Indexar
SISA
–
Termos de Indexação e Termos Candidatos
SISA - Funções
47
Artigo Original
Artigo Horizontalizado
Artigo Sem Palavras Vazias
O padrão de referência (gold standard) de qualidade é a indexação manual ou
intelectual.
Na análise da consistência na indexação, existem dois critérios de comparação: a) “Critério de Consistência Relaxada”:
Ao comparar os termos de indexação propostos pelo sistema de indexação automática com os termos das palavras-chave dos documentos:
- quando há coincidência total entre os termos que estão sendo comparados atribui-se valor 1,
- quando há coincidência parcial, atribui-se valor 0,5 e,
- quando não há coincidência, atribui-se valor 0. (GIL LEIVA, 2008).
b) “Critério de Consistência Rígida”:
Quando os termos de indexação propostos pelo sistema de indexação automática coincidem completamente com os termos das palavras-chave atribui-se valor 1, caso contrário, atribui-se valor 0.
Avaliação da Indexação Automática
𝐶𝑖 =
𝐴 + 𝐵 − 𝑇𝑐𝑜
𝑇𝑐𝑜
Ci = Índice de consistência
Tco = Número de termos comuns nas duas indexações;
As métricas de precisão, revocação e medida F podem
também ser utilizadas para avaliação da qualidade na
indexação automática de um sistema. Neste caso,
existem duas formas de realizar o cálculo destas
métricas:
a)
Na recuperação de documentos
.
b)
Na proposição de termos de indexação
.
a) Na recuperação de documentos:
Nos moldes da avaliação de um sistema de recuperação de informação com o índice construído a partir da saída do sistema de indexação automática, utilizando as palavras-chaves como consultas e julgamentos de relevância com base na presença das palavras-chaves nos documentos:
- quando há coincidência entre os documentos relevantes e os retornados pelo sistema para a consulta, se contabiliza como relevantes retornados.
Avaliação da Indexação Automática
Revocação = Número de documentos relevantes recuperadosNúmero total de documentos relevantes
Precisão = Número de documentos relevantes recuperadosNúmero total de documentos recuperados
b) Na proposição de termos de indexação:
Quando os termos de indexação propostos pelo sistema de indexação automática coincidem completamente com os termos das palavras-chave (termos relevantes) contabiliza-se como termo relevante recuperado, caso contrário, como termo irrelevante recuperado.
Avaliação da Indexação Automática
Revocação = Número de termos relevantes recuperadosNúmero total de termos relevantes
Precisão = Número de termos relevantes recuperadosNúmero total de termos recuperados
Exercícios
•
Indexe o seguinte artigo utilizando o software
OGMA:
• http://revistas.ufpr.br/atoz/article/view/41280/25197
•
Dadas as seguintes palavras-chaves para o artigo acima:
Sintagmas nominais; Recuperação de informação; Indexação
automática; Teses e dissertações. Avalie a qualidade na
indexação automática do sistema OGMA.
•
Para realizar a indexação do artigo acima utilizando o
software SISA, quais arquivos são necessários?
•
Indexe o seguinte artigo utilizando o software
SOBEK:
Links para sistemas de indexação
automática para o português
•
Ogma
•
Ogma Web:
https://sourceforge.net/projects/ogmaweb/
•
Ogma Desktop:
http://www.luizmaia.com.br/ogma/
•
SISA
•
Homepage do desenvolvedor:
http://webs.um.es/isgil/
•
SOBEK (sumarizador automático para textos em
português)
•
http://sobek.ufrgs.br/
Links para sistemas de indexação
automática online multilíngue
• Yake
• https://boiling-castle-88317.herokuapp.com/demo/user
• TextRazor
• https://www.textrazor.com/demo
• TagMe
• https://tagme.d4science.org/tagme/
• AlchemyAPI (IBM Watson Project)
• https://alchemy-language-demo.mybluemix.net/
• Dbpedia Spotlight
• http://dbpedia-spotlight.github.io/demo/
Links para sistemas de indexação
automática online para o inglês
• Open Calais
• http://www.opencalais.com/opencalais-demo/
• Medical Text Indexer (MTI)
• https://ii.nlm.nih.gov/Interactive/mti.shtml
• HIVE indexing - HIVE Automatic Concepts Extractor
• http://hive.cci.drexel.edu:8080/indexing.html
Links para sistemas de indexação
automática off-line multilíngue
•
Maui
•
https://github.com/zelandiya/maui
•
KEA
•
http://www.nzdl.org/Kea/
• BAEZA-YATES, Ricardo.; RIBEIRO-NETO, Bertier. Recuperação de informação: conceitos e tecnologia das máquinas de busca. 2. ed. Porto Alegre: Bookman, 2013.
• CORRÊA, R.; MIRANDA, D.; LIMA, C.; SILVA, T. Indexação e recuperação de teses e dissertações por meio de sintagmas nominais. AtoZ, Curitiba, v. 1, n. 1, ago. 2011. • KURAMOTO, H. Sintagmas nominais: uma nova proposta para a recuperação de
informação. DataGramaZero: revista de Ciência da Informação, v. 3, n. 1, 2002. • MAIA, Luiz Cláudio Gomes. Uso de sintagmas nominais na classificação
automática de documentos eletrônicos. Tese (Doutorado em Ciência da Informação) - Universidade Federal de Minas Gerais, Belo Horizonte, 2008.
• MORELLATO, L. V. Metodologia Computacional para Identificação de Sintagmas Nominais da Língua Portuguesa. Dissertação (Mestrado em Ciência da
Computação) — Universidade Federal do Espírito Santo, Vitória, 2010.
• Golub, K., Soergel, D., Buchanan, G., Tudhope, D., Lykke, M. and Hiom, D. A framework for evaluating automatic indexing or classification in the context of retrieval. J Assn Inf Sci Tec, 67: 3–16. 2016. doi:10.1002/asi.23600
• Su Nam Kim, Olena Medelyan, Min-Yen Kan, Timothy Baldwin. Automatic
keyphrase extraction from scientific articles. Language resources and evaluation, v.47,n.3, 2013. pp.723-742. Disponível em:
NARUKAWA, Cristina Miyuki; GIL LEIVA, Isidoro; FUJITA, Mariângela Spotti Lopes. Indexação automatizada de artigos de periódicos científicos: análise da aplicação do software SISA com uso da terminologia DeCS na área de Odontologia.
Informação & Sociedade: Estudos, João Pessoa, v. 19, n. 2, p. 99-118, maio/ago. 2009.
GIL-LEIVA, Isidoro. Sistema para la Indización Semi-Automática (SISA) de Artículos de Revista de Biblioteconomía y Documentación. In: II Jornadas de Tratamiento y Recuperación de Información, septiembre 2003, Leganés (Madrid), p. 228-232.
GIL-LEIVA, Isidoro. Manual de indización. Teoría y práctica. Gijón: Trea, 2008. pp. 429. ISBN:978-84-9704-367-0.
SPOTTI LOPES FUJITA, Mariângela and GIL-LEIVA, Isidoro. Avaliação da indexação por meio da recuperação da informação. Ciência da Informação, vol. 41, nº 1, 2014. p. 50-66. Disponível em:
http://webs.um.es/isgil/resources/Indexing%20&%20retrieval%20Fujita%20Gil-Leiva2014.pdf
GIL-LEIVA, Isidoro. SISA: Automatic indexing system for scientific articles. Experiments with location heuristics rules versus TF-IDF rules. Knowledge Organization, vol. 43, nº 3, 2017. p. 139-162.