Universidade do Minho Escola de Engenharia
Raquel Marques Ferreira
Previsão na Área Farmacológica – Modelos Estatísticos
vs Deep Learning
ii
Mestrado Integrado em Engenharia Biomédica
Dissertação de Mestrado em Informática Médica
Trabalho efetuado sob orientação do
Professor Doutor Victor Manuel Rodrigues Alves
Setembro 2017
Raquel Marques Ferreira
Previsão na Área Farmacológica – Modelos Estatísticos
vs Deep Learning
Universidade do Minho Escola de Engenharia
DECLARAÇÃO
Nome: Raquel Marques Ferreira
Título dissertação: Previsão na Área Farmacológica – Modelos Estatísticos VS Deep Learning Orientador: Professor Doutor Victor Manuel Rodrigues Alves
Supervisor na empresa: Engenheiro Martinho Gonçalves Antunes Braga Ano de conclusão: 2017
Designação do Mestrado: Mestrado Integrado em Engenharia Biomédica Área de Especialização: Informática Médica
Escola: de Engenharia
Departamento: de Informática
DE ACORDO COM A LEGISLAÇÃO EM VIGOR, NÃO É PERMITIDA A REPRODUÇÃO DE QUALQUER PARTE DESTA DISSERTAÇÃO
Universidade do Minho, ____/____/________ Assinatura:
A
GRADECIMENTOS
Parece que chegou ao fim mais uma etapa da minha vida e, portanto, gostaria de agradecer a todas as pessoas que, de diversas formas, contribuíram para que eu conseguisse concluir esta jornada.
Em primeiro lugar pretendia agradecer ao meu orientador, Professor Victor Alves, que desde sempre se mostrou prestável e disponível para me ajudar ao longo de todo o processo. Agradeço também a oportunidade que me deu em integrar um estágio curricular na empresa
Tlantic, na qual eu pude adquirir uma vasta gama de conhecimentos novos que foram bastante
úteis quer a nível profissional quer pessoal.
Assim como expressar a minha gratidão ao meu supervisor na empresa, Engenheiro Martinho Braga, pela ajuda e prontidão e por todas as oportunidades que me proporcionou ao longo do meu estágio.
Também um muito obrigada ao Hugo Nogueira, meu colega na empresa, por toda a sua disponibilidade em ajudar-me sempre que precisei e por toda a paciência que teve comigo ao longo destes meses de trabalho.
Um especial agradecimento à minha colega de todas as horas, Daniela Rijo, por todos os momentos, gargalhadas, emoções partilhadas e, acima de tudo, por todo o apoio que sempre me deu e pela amizade que, penso, perdurará entre nós.
A todos os meus restantes amigos deixo o meu especial reconhecimento, pois mantiveram-se a meu lado e fizeram com que toda esta jornada fosmantiveram-se mais agradável e fácil de superar. Destaco as minhas eternas companheiras e amigas: Joana Martins e Márcia Barroso; e todos os que me acompanharam desde a entrada e ao longo do curso: Mafalda Costa, Ana Quintas, Francisca Ribeiro, Joana Ferreira, Isabel Bjørge, Margarida Costa, Cármina Azevedo, Pedro Nuno Fernandes, Andreia Silveira, Eduardo Direito e Paulo Félix.
Por fim, quero realçar o apoio incondicional dos meus pais, irmão e namorado, pois sem eles isto teria sido sem dúvida alguma mais difícil. Aos meus pais e irmão por sempre terem acreditado em mim e me terem dado força para continuar e, ainda, por todo o sacrifício que fizeram para que eu conseguisse alcançar este meu objetivo pessoal. Ao meu namorado, com
vi quem partilhei todas as minhas alegrias e frustrações, por ser quem é e por estar sempre presente nos bons momentos e acima de tudo nos maus, presenteando-me com palavras de motivação, paciência e apoio emocional.
A todos, o meu enternecido obrigada.
R
ESUMO
Hoje em dia, a tomada de decisões de forma rápida e eficaz é essencial nas organizações de saúde. Neste sentido, surgem os Sistemas de Apoio à Decisão, as plataformas de Business
Intelligence e os Sistemas de Tratamento de Dados. De forma a apoiar a decisão no âmbito
farmacêutico surgem plataformas de previsão, as quais pretendem auxiliar ao máximo a tomada de decisão por parte dos prestadores de saúde. No âmbito desta dissertação, foi realizado um projeto com o objetivo de extrair conhecimento de forma automatizada a partir de informações passadas e traduzi-las de forma a desenvolver um sistema de previsão de vendas para a área farmacêutica.
Tradicionalmente, na área da previsão, é comum a utilização de modelos estatísticos, no entanto é interessante perceber se o Deep Learning consegue acompanhar os resultados obtidos através destes modelos. Para o efeito, foi elaborado um estudo comparativo entre modelos de previsibilidade, conseguidos através de modelos estatísticos e conexionistas. Para os primeiros fez-se uso de funções de modelação disponíveis em librarias da linguagem de programação R e no segundo foram aplicadas redes neuronais recorrentes, nomeadamente as
Long Short Term Memory, através de bibliotecas disponíveis em Python para construção de um
modelo deep learning. As metodologias desenvolvidas através dos diferentes modelos de previsibilidade foram aplicadas a três casos de estudo, cada um associado a um conjunto de dados diferente. Assim, tornou-se possível analisar o comportamento dos modelos desenvolvidos quando aplicados a conjuntos de dados distintos.
Por último, foram apresentados os resultados obtidos para os três casos de estudo, referentes à aplicação de ambas as práticas, e feita uma comparação das mesmas. Foi verificado o sucesso da utilização de algoritmos de Deep Learning na área da previsão, obtendo melhores resultados que aqueles conseguidos através dos tradicionais modelos de previsão estatísticos. Este trabalho permitiu perceber o potencial que o deep learning apresenta, sendo no entanto necessário mais trabalho futuro para dar enfâse a esta afirmação.
A
BSTRACT
Nowadays, making decisions quickly and effectively is essential in health organizations. In this sense, Decision Support Systems, Business Intelligence platforms and Data Processing Systems begin to emerge. To support the decision in the pharmaceutical field, there are platforms for forecasting, which are intended to help health decision makers to the maximum extent possible. This dissertation has the objective of extracting knowledge in an automated way from past information, and translating it in order to develop a sales forecasting system for the pharmaceutical area.
Traditionally, in the area of forecasting, it is common to use statistical models, however it is interesting to see if Deep Learning can follow the results obtained through these models. For this purpose, a comparative study was developed for predictability models, achieved through statistical and connectionist models. For the statistical models, it was used functions present in libraries of the programming language R and for the second models, it was applied recurrent neural networks, namely the Long Short Term Memory, through libraries available in Python to construct a Deep Learning model. The methodologies developed through the different predictability models were applied to three case studies, each associated to a different data set. Thus, it became possible to analyze the behavior of models developed when applied to different datasets.
Finally, the results obtained for the three case studies using both practices were presented and it was verified the success of the Deep Learning algorithms in the area of forecasting. They achieved better results than those obtained through the traditional statistical prediction models. This work allowed to realize the potential that Deep Learning presents, being nevertheless necessary more future work to give emphasis to this affirmation.
ÍNDICE
RESUMO ... VII ABSTRACT ... IX ÍNDICE ... XI LISTA DE FIGURAS ... XIII LISTA DE TABELAS ... XV LISTA DE CÓDIGO ... XV NOTAÇÃO, ACRÓNIMOS E GLOSSÁRIO ... XVII
CAPÍTULO 1INTRODUÇÃO ... 1 1.1 Introdução ... 2 1.2 Motivação ... 8 1.3 Objetivos ... 9 1.4 Metodologia de Investigação ... 10 1.5 Estrutura do documento ... 12
CAPÍTULO 2REVISÃO DA LITERATURA ... 17
2.1 Enquadramento ... 18
2.2 Conceitos a reter sobre a tarefa de previsão ... 19
2.3 Tecnologias usadas em modelação ... 26
2.3.1 RapidMiner Studio... 26
2.3.2 Modelos estatísticos... 28
2.3.3 Deep Learning ... 30
CAPÍTULO 3 CASOS DE ESTUDO ... 37
3.1 Introdução ... 38
3.2 Divisão do problema ... 38
3.3 Síntese ... 43
CAPÍTULO 4MODELAÇÃO ... 45
4.1 Introdução ... 46
4.2 Metodologia desenvolvida com o auxílio de modelos estatísticos ... 47
4.3 Metodologia desenvolvida com o auxílio de deep learning ... 54
CAPÍTULO 5RESULTADOS E DISCUSSÃO ... 63
5.1 Introdução ... 64
5.2 Previsão com o auxílio de modelos estatísticos ... 64
5.3 Previsão com Deep Learning ... 81
5.4 Discussão dos resultados ... 87
CAPÍTULO 6CONCLUSÃO ... 91
6.1 Conclusão ... 92
6.2 Contribuições e Perspetivas futuras de investigação ... 94
xii
ANEXOS ... 101
L
ISTA DE
F
IGURAS
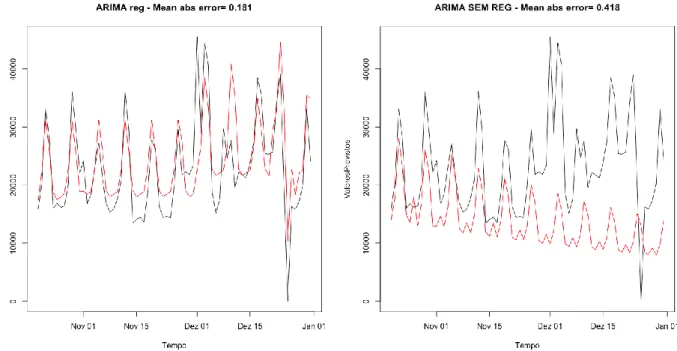
Figura 1.1 - Relacionamento da Informática com outras áreas do saber (adaptado de [3]). ... 3 Figura 1.2 - Áreas de investigação que fazem parte da Informática Médica (adaptado de [7]). . 3 Figura 1.3 - Transformação de dados em bruto em conhecimento (adaptado de [9]) ... 4 Figura 1.4 - Metodologia de Investigação Design Science Research (adaptado de [23]). ... 11 Figura 1.5 - Estratégia adotada para construção dos modelos de previsão. ... 13 Figura 2.1 - Comparação Modelo Aditivo Vs Modelo Multiplicativo séries temporais (retirado de [29])...25 Figura 2.2 - Esquema de uma rede neuronal padrão (retirado de [37]). ... 31 Figura 4.1 - Tipologia de uma rede neuronal recorrente (retirado de [38])...56 Figura 4.2 - Verificação de underfitting e overfitting (retirado de [53]). ... 57 Figura 4.3 - Função de ativação Leaky ReLU e suas variantes (retirado de [60]). ... 58 Figura 5.1 - Valores obtidos para o primeiro caso de estudo através das funções de modelação:
hm() e
tbats()...65
Figura 5.2 - Valores obtidos para o primeiro caso de estudo através das funções de modelação:
nnetar() e tslm(). ... 65
Figura 5.3 - Valores obtidos para o primeiro caso de estudo através da função de modelação
auto.arima() com e sem regressores. ... 66
Figura 5.4 - Valores obtidos para o primeiro caso de estudo através da função de modelação
ets(). ... 66
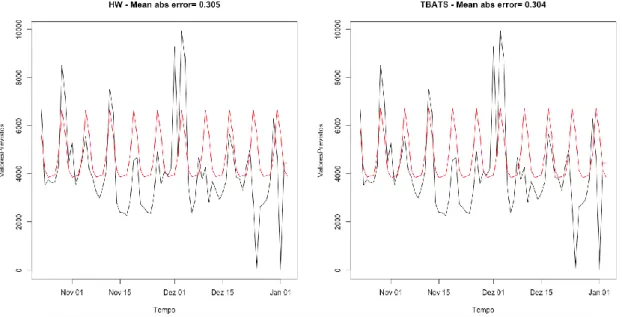
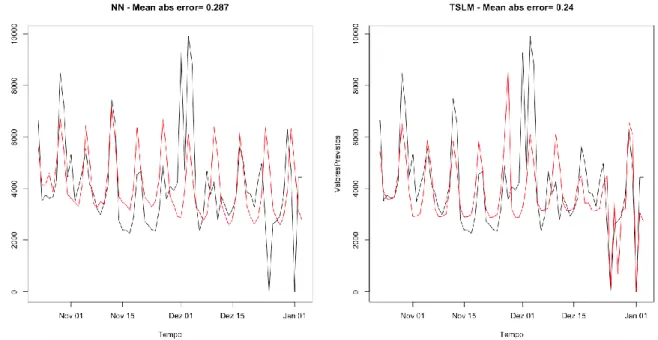
Figura 5.5 - Valores obtidos para o segundo caso de estudo através das funções de modelação:
hw(), tbats(). ... 68
Figura 5.6 - Valores obtidos para o segundo caso de estudo através das funções de modelação:
nnetar(), tslm(). ... 69
Figura 5.7 - Valores obtidos para o segundo caso de estudo através da função de modelação
auto.arima() com e sem regressores. ... 69
Figura 5.8 - Valores obtidos para o segundo caso de estudo através da função de modelação
ets(). ... 70
Figura 5.9 - Valores obtidos para o terceiro caso de estudo através das funções de modelação:
hw(), tbats(). ... 73
Figura 5.10 - Valores obtidos para o segundo caso de estudo através das funções de modelação:
nnetar(), tslm(). ... 73
Figura 5.11 - Valores obtidos para o terceiro caso de estudo através da função de modelação
auto.arima() com e sem regressores. ... 74
Figura 5.12 - Valores obtidos para o terceiro caso de estudo através da função de modelação
ets(). ... 74
Figura 5.13 - Análise dos resíduos para o primeiro caso de estudo através da função tslm(). No cimo: gráfico dos resíduos; em baixo à esquerda: função de autocorrelação dos resíduos; em baixo à direita: histograma dos resíduos. ... 77
xiv Figura 5.14 - Análise dos resíduos para o primeiro caso de estudo através da função
auto.arima(). No cimo: gráfico dos resíduos; canto inferior esquerdo: função de autocorrelação
dos resíduos; canto inferior direito: histograma dos resíduos. ... 78 Figura 5.15 - Análise dos resíduos para o segundo caso de estudo. No cimo: gráfico dos resíduos; canto inferior esquerdo: função de autocorrelação dos resíduos; canto inferior direito: histograma dos resíduos. ... 79 Figura 5.16 - Análise dos resíduos para o terceiro caso de estudo. No cimo: gráfico dos resíduos; canto inferior esquerdo: função de autocorrelação dos resíduos; canto inferior direito: histograma dos resíduos. ... 81 Figura 5.17 - Gráfico de perda final para o primeiro caso de estudo. ... 82 Figura 5.18 - Gráfico de perda para o primeiro caso de estudo, em que os dados de y_test, entraram em overfitting. ... 83 Figura 5.19 - Demonstração de um gráfico de previsão obtido para o primeiro caso de estudo. ... 84 Figura 5.20 - Gráfico de perda final para o segundo caso de estudo. ... 84 Figura 5.21 - Demonstração de um gráfico de previsão obtido para o segundo caso de estudo.85 Figura 5.22 - Gráfico de perda obtido para o terceiro caso de estudo... 86 Figura 5.23 - Gráfico de perda obtido para o terceiro caso de estudo (aproximado). ... 86 Figura 5.24 - Demonstração de um gráfico de previsão obtido para o terceiro caso de estudo. 87 Figura A.1 - Demonstração da interface gráfica da ferramenta
L
ISTA DE
T
ABELAS
Tabela 3.1 - Dataset inicial ... 39 Tabela 3.2 - Dataset com dias da semana e meses ... 40 Tabela 5.1 - Valor médio real para o conjunto de dados de teste referente a cada caso de estudo...6 4
Tabela 5.2 – Interpretação do coeficiente de correlação (adaptado de [58]) ... 67 Tabela 5.3 - Valores obtidos para o RMSE e o coeficiente de correlação para os modelos aplicados ao primeiro caso de estudo ... 68 Tabela 5.4 - Valores obtidos para o RMSE e o coeficiente de correlação para os modelos aplicados ao segundo caso de estudo ... 70 Tabela 5.5 - Valores obtidos para o RMSE e o coeficiente de correlação para os modelos aplicados ao terceiro caso de estudo ... 74 Tabela 5.6 - Valores médios obtidos para o RMSE e para a correlação para o primeiro caso de estudo ... 83 Tabela 5.7 - Valores médios obtidos para o RMSE e para a correlação para o segundo caso de estudo ... 84 Tabela 5.8 - Valores médios obtidos para o RMSE e para a correlação para o terceiro caso de estudo ... 86
L
ISTA DE
C
ÓDIGO
Código 4.1 - Aplicação da função hw() referente ao modelo Holt-Winters, fazendo uso da linguagem de programação R. ... 49 Código 4.2 - Aplicação da função tbats(), fazendo uso da linguagem de programação R. ... 50 Código 4.3 - Aplicação da função NNETAR() referente a redes neuronais, fazendo uso da linguagem de programação R. ... 51 Código 4.4 - Aplicação da função tslm() com regressores (a matriz de eventos), fazendo uso da linguagem de programação R. ... 51 Código 4.5 - Aplicação da função auto.arima() com regressores (a matriz de eventos) fazendo uso da linguagem de programação R. ... 53 Código 4.6 - Aplicação da função auto.arima() sem a matriz de eventos fazendo uso da linguagem de programação R. ... 53 Código 4.7 - Aplicação da função ets()fazendo uso da linguagem de programação R. ... 53
xvi Código 4.8 - Excerto de código desenvolvido em Python para primeira arquitetura do modelo
deep learning. ... 59
Código 4.9 - Excerto de código desenvolvido em Python para construção do modelo final. ... 60 Código 5.1 - Aplicação do teste ADF ao conjunto de dados y_train referente ao segundo caso de estudo, fazendo uso da linguagem de programação R. ... 71 Código 5.2 - Aplicação do teste kpss ao conjunto de dados y_train referente ao segundo caso de estudo, fazendo uso da linguagem de programação R. ... 72 Código 5.3 - Aplicação do teste Box-Pierce e Ljung-Box aos resíduos do primeiro caso de estudo para 1 lag, 12 lags e 24 lags referente à função de modelação tslm(),fazendo uso da linguagem de programação R. ... 77 Código 5.4 - Aplicação do teste Box-Pierce e Ljung-Box aos resíduos do primeiro caso de estudo para 1 lag, 12 lags e 24 lags referente à função de modelação auto.arima(),fazendo uso da linguagem de programação R. ... 78 Código 5.5 - Aplicação do teste Box-Pierce e Ljung-Box aos resíduos do segundo caso de estudo para 1 lag, 12 lags e 24 lags, fazendo uso da linguagem de programação R. Todos os testes demonstram valores de p-value altos refletindo a ausência de correlação... 80 Código 5.6 - Aplicação do teste Box-Pierce e Ljung-Box aos resíduos do terceiro caso de estudo para 1 lag, 12 lags e 24 lags, fazendo uso da linguagem de programação R. Mais uma vez todos os testes demonstram valores de p-value altos refletindo a ausência de correlação. ... 81
N
OTAÇÃO
,
ACRÓNIMOS E GLOSSÁRIO
NOTAÇÃO GERAL
A notação ao longo do documento segue a seguinte convenção:
• Texto em itálico – para palavras em língua estrangeira (ex., Inglês, Latim, Francês), equações e fórmulas matemáticas. Também utilizado para dar ênfase a um determinado termo ou expressão e para destacar nomes próprios.
• Texto em negrito – utilizado para realçar um conceito ou palavra.
• Texto com o tipo de letra Courier New - para enxertos e exemplos de código.
A presente dissertação foi elaborada ao abrigo do novo acordo ortográfico. Ao longo do presente documento são utilizados termos em inglês em situações em que esta língua é universalmente aceite.
A
CRÓNIMOSADF Augmented Dickey-Fuller
ARIMA AutoRegressive Integrated Moving Average ACF AutoCorrelation Function
BI Business Intelligence
CSV Comma-Separated Values
DM Data Mining
DSR Design Science Research
DW Data Warehouse
ELU Exponential Linear Units
ETS ExponenTial Smoothing/Error, Trend and Sasonality
GUI Graphic User Interface
HW Holt-Winters
IGIF Instituto de Gestão Informática e Financeira da Saúde IA Inteligência Artificial
IDE Integrated Development Environment
KPSS Kiatkowski-Phillips-Schmidt-Shin
xviii LSTM Long Short Term Memory
ML Machine Learning
MAE Mean Absolute Error
MSE Mean Squared Error
MI Medical Informatics
NN Neural Net
NNETAR Neural Network AutoRegression
OLAP OnLine Analytical Processing
OMS Organização Mundial de Saúde PCE Processo Clínico Eletrónico PReLU Parametric Rectified Linear Units
RReLU Randomized Leaky Rectified Linear Units
RM RapidMiner
ReLU Rectified Linear Units
RMSE Root Mean Square Error
SADC Sistemas de Apoio à Decisão Clínica
SPMS Sistemas Partilhados do Ministério da Saúde SVM Suport Vector Machine
TI Tecnologias de Informação
TIC Tecnologias de Informação e Comunicação TSLM Time Series Linear Model
TBATS Trigonometric; Box-Cox; AutoRegressive Moving Average; Trend; Seasonal
XML eXtensible Markup Language
G
LOSSÁRIOBatch size - número de casos de treino que são utilizados em cada epoch
Correlação – tem como objetivo medir o grau de relacionamento entre variáveis
Dataset – Conjunto de dados
Dropout layer – coloca aleatoriamente ativações a zero. Corresponde a apagar partes da rede
neuronal
Estacionariedade – uma série temporal é dita estacionária quando se desenvolve aleatoriamente em redor duma média constante, refletindo alguma forma de equilíbrio estável
Epochs – número de passagens para a frente e para trás que são feitas em todos os casos de
treino
Forecasting – tarefa estatística que ajuda na tomada de decisões sobre um planeamento feito à
posteriori, e ainda fornece um “guia” para o planeamento estratégico de longo prazo. Diz respeito à previsão do futuro com a maior precisão possível
Função de ativação – implementa a decisão relativamente aos limites do output, combinando os valores das entradas com os respetivos pesos
Input – dados de entrada
Lag – diferença de atraso -1, entre observações consecutivas
Multicolinearidade – correlação entre duas variáveis Multivariada – série que prevê mais do que uma variável
Normalização – redimensionamento dos dados originais para um intervalo de 0 a 1
Outliers – valores atípicos, observações que apresentam um grande afastamento das demais na
série
Output – dados de saída
Overfitting – quando o número de neurónios seja elevado relativamente ao conjunto de dados
presentes, poderá contribuir para o excesso de treino da rede, resultando na perda da capacidade de previsão
Padronização – redimensionamento do dataset inicial para que a média dos valores observados seja 0 e o desvio padrão 1
Regressores – Matriz de eventos que permite a identificação de eventuais fatores influenciadores de um aumento ou diminuição na quantidade vendida da variável em questão Sazonalidade – padrões repetitivos que ocorrem ao longo do tempo
Série temporal – conjunto de observações feitas sequencialmente ao longo do tempo
xx Tendência – aumento ou diminuição do comportamento da série ao longo do tempo
Underfitting – incapacidade da rede em modelar dados mais complexos O erro é demasiado
grande, tanto nos casos de treino como nos casos de teste Uni variada – série que prevê uma variável
C
APÍTULO
1
2 A presente dissertação descreve o desenvolvimento de dois modelos de previsão direcionados à área médica. O projeto surge no âmbito da dissertação de mestrado do Mestrado Integrado em Engenharia Biomédica da Universidade do Minho. Neste capítulo é apresentada uma contextualização do tema, bem como a motivação para a elaboração do mesmo. São também levantadas algumas questões e traçados objetivos que visam responder a essas questões e, ainda, apresentada a metodologia de investigação adotada na presente dissertação. Por fim, é explicada a estrutura do documento.
1.1 I
NTRODUÇÃOSabe-se que a área da saúde lida diariamente com uma complexa e heterógena quantidade de conceitos, os quais encontram-se em constante transformação. Desta forma, surge a necessidade da informatização de processos, cuja aplicação pretende apoiar a clínica geral, as tomadas de decisão dos profissionais envolvidos e a pesquisa de informação.
A Organização Mundial de Saúde (OMS) reconheceu que o uso de tecnologias de informação e comunicação (TICs) no setor da saúde era uma competência central do século XX, capaz de melhorar as práticas e o desenvolvimento auto sustentável de modelos de prestação de cuidados de saúde, juntamente com o enriquecimento da gestão de sistemas de informação na saúde[1]. No entanto, é necessário ter em consideração um aspeto muito importante: apesar de se verificar um aumento relativo à importância que os sistemas de informação detêm hoje como repositórios de conhecimento, são sobretudo os profissionais de saúde que criam, aprendem, filtram e transmitem o conhecimento essencial contribuindo para o sucesso das organizações. Assim, é expectável que os profissionais de saúde se aliem à informática, no sentido de serem desenvolvidos sistemas de informação cada vez mais adequados a situações reais [2]. A necessidade da medicina socorrer-se de meios digitais para recolha de informação foi um assunto que começou a ser discutido por volta de 1950, sendo que apenas em 1970 tenha surgido o termo Informática Médica, associado a uma nova especialidade.
A Informática Médica (do inglês, Medical Informatics – MI) é considerada uma ciência de gestão da informação na área da saúde, a qual tem sofrido uma evolução exponencial, tendo vindo a ganhar consistência até aos dias de hoje [3]. Antes de se chegar a um consenso do termo que melhor se adequasse, foram inicialmente adotados termos como informática da saúde, computação na medicina, ciências da informação médica, entre outros [4]. Uma das principais alterações que se tem verificado nesta ciência prende-se no facto dos computadores inicialmente serem bastantes limitados, sendo mantidos centralmente, enquanto hoje em dia existem computadores pessoais bastante poderosos e relativamente económicos que estão disponíveis para todos os intervenientes na prestação de cuidados de saúde (médicos, enfermeiros e outros profissionais de saúde). Qualquer profissional de saúde possui deste modo a capacidade de criar ou utilizar informação médica, desde que estes estejam dispostos a tornar as potencialidades dos sistemas e tecnologias de informação em vantagens na execução das suas atividades diárias profissionais [5].
Dada a sua multidisciplinaridade, este conceito apresenta diversas áreas de investigação (Figura 1.2), e.g. Telemedicina, Processo Clínico Eletrónico (PCE), Sistemas de Apoio à Decisão Clínica (SADC), Bioinformática, Imagem Médica [6].
Figura 1.1 - Relacionamento da Informática com outras áreas do saber (adaptado de [3]).
4 Em Portugal, a utilização de tecnologias de informação na saúde tem vindo a ser uma realidade constante nos últimos anos, no entanto, no que diz respeito ao desenvolvimento destes sistemas, é possível afirmar que este tem ainda muito espaço para crescer. Atualmente, um paciente pode estar registado de forma independente, nos mais diversos hospitais e centros de saúde portugueses, sendo visto como um paciente diferente. Esta lacuna diz respeito a uma falta de integração da informação entre as diferentes unidades de saúde existentes, impossibilitando ao paciente o acesso e verificação de todo o seu percurso clínico. No entanto, as tecnologias de informação começam cada vez mais a estar presentes nos hospitais e centros de saúde portugueses. O Ministério da Saúde decidiu criar o IGIF (Instituto de Gestão Informática e Financeira do Ministério da Saúde), atual SPMS (Serviços Partilhados do Ministério da Saúde), a principal entidade dinamizadora da aplicação das tecnologias de informação nos diferentes serviços de saúde pública em Portugal [5].
Um dos principais problemas presentes nas unidades de saúde, e que contribui para a falta de integração da informação ainda hoje presente, é a imensidão de dados existente. Ainda assim, estes dados necessitam de ser previamente tratados para que os mais importantes sejam filtrados e posteriormente organizados segundo padrões, evitando a incontextualização de dados e a existência de outliers. O processo de seleção e tratamento de dados resolve a principal problemática associada à maioria dos sistemas de saúde: ricos em dados, mas pobres em conhecimento. A utilização de tecnologias de informação para apoio à decisão e gestão de dados tem-se tornado cada vez mais uma prioridade, no sentido de assegurar uma maior eficácia na prestação de cuidados de saúde, bem como de garantir o seu próprio futuro a nível financeiro [7].
Como é possível observar através da figura 1.3, os dados são considerados factos isolados que, assentes num determinado contexto e combinados com uma estrutura única, dão origem à informação. Por sua vez, esta ao ser interpretada adquire um significado específico, surgindo o conhecimento.
No ambiente farmacêutico, o termo inventário refere-se a todos os medicamentos e suprimentos médicos, expressos em termos de dados, utilizados nas operações diárias de uma farmácia. A implementação de novas tecnologias de informação e comunicação numa farmácia tem como objetivo melhorar o seu desempenho, sendo um elemento essencial não só para resolver problemas associados com a produtividade, mas também permitir melhorar a eficiência e qualidade na prestação de cuidados. Estas tecnologias têm como finalidade garantir a qualidade da assistência prestada aos pacientes através do uso seguro e racional de medicamentos. A farmácia deve ainda responder às necessidades de medicamentos dos clientes, constituindo stocks destes produtos [8]. Além de evitar a possibilidade de haver ruturas de stock, uma gestão cuidadosa de existências tem como objetivos combater as eventualidades que possam surgir relativamente ao consumo (e.g. picos de consumo), imprevistos com entregas e ainda servir de regulador entre entregas e usos quando estes são feitos a taxas diferentes. Se não houver um controlo efetivo de tudo o que dá entrada e saída nos stocks, pouco se poderá fazer para reduzir custos, daí a importância de investir em
software cada vez mais evoluído que permita uma melhoria nesta área. A gestão de stocks é a
área com maior carência de informatização no âmbito das instituições de saúde e, na maioria das vezes, o controlo e a tomada de decisões são efetuadas sem recorrer a sistemas informáticos específicos de suporte à decisão. Uma vez que esta área da Gestão de Stocks não é considerada uma área produtiva, recebe, por isso, uma forte pressão para reduzir custos em termos de espaço, mão-de obra e de stocks, sem que para isso afete o nível de serviço prestado [9]. Visto o consumo por parte dos clientes não seguir um padrão, deverá existir um gerente que terá como papel principal estudar qual a quantidade de stock que deverá ter disponível, qual a quantidade que deverá encomendar e, ainda, definir prazos para efetuar encomendas. Este responsável deverá assim tomar decisões assentes num propósito: a quantidade de stock deverá ser o mais baixa possível desde que a farmácia não fique sujeita a uma rutura de stock, pondo em causa o cumprimento das necessidades dos clientes; por outro lado, não deve apresentar excesso de stock, o que acabaria por se traduzir em custos extra. Deverá assim
6 existir um equilíbrio no que respeita à quantidade de existências na farmácia, traçando uma estratégia para a gestão de stocks, pois caso esta não seja feita, irá haver consequências negativas tanto ao nível do custo dos produtos, como da satisfação dos clientes [10]. A magnitude presente nestes serviços/ações é outro fator que deve ser tido em consideração, visto que estes produtos são considerados vitais, necessitando de serem acedidos a qualquer altura do dia. Num extremo, uma incorreta distribuição de medicamentos pode pôr em causa todo o processo de tratamento de um doente. Posto isto, um sistema de informação presente num ciclo logístico deve ter como resultado a disponibilidade de produtos de qualidade, adquiridos em tempo oportuno, a custos acessíveis, armazenados e distribuídos de forma a preservar as suas características. Este sistema deverá também ser capaz de auxiliar na previsão de futuros pedidos e lidar com os problemas que possam surgir relativos à quebra. A estes benefícios junta-se uma maior precisão, maior visibilidade e disponibilidade imediata e um aumento da rapidez de processamento [9] [11] [12].
Em 2008 a crise financeira internacional, desencadeada nos Estados Unidos, teve repercussões a nível mundial, afetando sobretudo as economias mais desenvolvidas. Neste ano, o comércio internacional teve uma queda acentuada, e esta, aliada à escassez de crédito, levou a que o país fosse obrigado a pedir um resgate financeiro em 2011 [13]. Assim, em Portugal, as mudanças legislativas e a quebra económica ocorrida nos últimos anos contribuíram para a queda súbita, quer das margens, quer dos preços dos medicamentos, em que muitas empresas dentro do setor farmacêutico foram obrigadas a iniciar uma política de cortes, nomeadamente, a diminuição dos postos de trabalho, também a diminuição dos salários dos trabalhadores, a fusão de algumas empresas para se tornarem mais competitivas. Outras empresas foram vendidas e outras tantas deixaram o mercado português. Muitas, senão a maior parte, foi forçada a reformular o seu plano de negócios, visando uma maior eficácia e ciência dos seus métodos e processos de atuação no mercado português. Não obstante, mantinha-se ainda assim a necessidade de conhecer, controlar e minorar os riscos de negócio associados a cada atividade. Desta forma, tornou-se importante que as decisões tomadas fossem sempre as mais corretas, de forma a que a redução de custos compensasse a queda das margens de lucro e os preços dos medicamentos [14].
É neste seguimento que surge o conceito de Business Intelligence (BI), o qual oferece uma vasta gama de tecnologias para a resolução de problemas de negócio, bem como sistemas de
alerta para possíveis alterações que poderão contribuir para o sucesso da organização. O termo
business concentra-se em lucros e vendas, enquanto BI centra-se em dados. Segundo Howard Dresner em 1989, o termo BI refere-se a “um conjunto de conceitos e métodos para melhorar a
tomada de decisão do negócio através da utilização de sistemas de suporte à decisão” [15]. Enquanto o BI pode ajudar a dar um significado aos dados de maneira facilitada, não é possível obter informações muito ricas com ele. Para isso é necessário soluções mais complexas, capazes de enriquecer a perceção da realidade de negócio, ajudando a encontrar correlações, novos segmentos de mercado e fazer previsões [16]. Forecast respeito ao cálculo de tendências e possibilidades futuras, antecipar resultados e, tendo em conta os mesmos, posteriormente fazer recomendações. Isso vai além das consultas e relatórios disponíveis pelas ferramentas de BI, como o SQL Server Reporting Services, Business Objects ou o Tableau, para métodos mais sofisticados, como a estatística, mineração de dados (do inglês Data Mining - DM), aprendizagem máquina (do inglês Machine Learning - ML), simulação e otimização, os quais procuram tendências e padrões nos dados [17].
A principal e maior diferença entre ML e os modelos estatísticos diz respeito à sua origem. Enquanto o primeiro provém da ciência da computação e da inteligência artificial, o segundo tem como origem a matemática. O ML está relacionado com previsões, aprendizagem supervisionada e não supervisionada, enquanto a estatística tem como foco o conjunto de dados, a população e as hipóteses. Assim, a modelação estatística estuda a relação entre variáveis presentes num conjunto de dados através de equações matemáticas, enquanto o ML representa um conjunto de algoritmos capazes de aprender com a informação que têm presente, sem depender de programação orientada a regras. No entanto, ambos os métodos partilham o mesmo objetivo: aprender a partir dos dados [18].
O DM tem como intuito extrair padrões e tendências a partir de dados em bruto, os quais podem ser utilizados para melhorar o processo de tomada de decisão numa organização. Segundo [19], DM não é mais do que um processo que utiliza um conjunto de técnicas estatísticas, matemáticas, inteligência artificial, processamento analítico online (OLAP), folhas de cálculo e ML para extrair e identificar informações úteis em grandes bases de dados, transformando-as mais tarde em conhecimento. As ferramentas utilizadas pelo ML, a estatística e o DM são praticamente as mesmas, no entanto a sua maior diferença assenta no como e no porquê do seu uso [20]. O DM incorpora um processo designado por “descoberta de
8 conhecimento” (do inglês, knowledge discovery) que descreve as etapas que se devem ultrapassar para obter resultados reveladores e atribuir significado a um conjunto de dados. No entanto, é necessário ter em atenção que o DM não elimina a necessidade de conhecer o meio em questão, o negócio, todos os métodos estatísticos por detrás do negócio e a posterior verificação e validação dos resultados obtidos, pois apesar de permitir aos gestores gerar hipóteses de melhoria para o negócio, não valida essas hipóteses. Em resumo, o DM respeita descoberta de padrões ocultos num vasto conjunto de dados através do uso de estatística, inteligência artificial, ML e gestão de base de dados [21]. Posto isto, os modelos de previsão são assim inicialmente construídos através de métodos estatísticos e/ou de ML e, posteriormente, os padrões dos modelos obtidos são analisados através de DM.
1.2 M
OTIVAÇÃOA saúde é uma das condições básicas para atingir a qualidade de vida tão desejada pelos seres humanos. Mais que o acesso a serviços de qualidade, as instituições de saúde devem garantir a aplicação das novas tecnologias, implementadas com sucesso nas mais diversas áreas, para auxiliar as suas práticas.
Face um mercado em constante mudança, à medida que a quantidade de dados aumenta, surge a necessidade das diferentes empresas do setor farmacêutico (produtoras, distribuidoras e retalhistas) adotarem novas ferramentas que agilizem todo o processo da tomada de decisões. Os sistemas de saúde têm por isso recorrido cada vez mais a tecnologias de informação assentes nestes sistemas, de forma a melhorar a prestação de cuidados de saúde, gestão de custos e ainda assegurar o próprio futuro da organização. Cada vez mais os gestores de topo usufruem consciência de que a informação é essencial para vingar no mundo empresarial, introduzindo novos produtos, ganhando cota de mercado, angariando novos clientes, colmatando falhas de mercado, entre outros. É nesta sequência que se torna imprescindível a obtenção de informação correta, no momento certo, permitindo analisar um conjunto de dados resultantes de meses, anos ou décadas de armazenamento e extrair conhecimento estratificado que permita alcançar o sucesso de uma organização. A aplicação
destes sistemas procura, assim, tornar viável o aproveitamento de informações oriundas dos sistemas de informação operacionais da organização tais como a faturação, quantidades de vendas, stocks, entre outros [7][22][14].
O mercado farmacêutico é composto por enumeras variáveis complexas e não-lineares, as quais não seguem um padrão específico, tornando-se assim mais difícil a correta tomada de decisões e a consequente elaboração de um modelo de previsão. As técnicas de ML e estatística têm revelado sucesso na criação de métodos de previsão eficientes, sendo estas hoje em dia comummente utilizadas de forma a obter mais informações sobre o futuro dos mercados [23].
1.3 O
BJETIVOSA presente dissertação teve como principal objetivo a exploração de soluções estatísticas e de ML para o apoio à decisão e à prática clínica em unidades farmacêuticas, nomeadamente no que respeita à prática de gestão de stocks. Para tal, pretende-se responder às seguintes questões de investigação:
• Que lacunas são encontradas no processo de gestão de stocks?
• Quais as questões que devem ser consideradas na construção de um modelo de previsibilidade?
• De que forma se pode promover a implementação de modelos de previsão na área farmacêutica e qual a viabilidade, utilidade e usabilidade?
• Que informações podem ser alcançadas usando modelos de previsão capazes de auxiliar os profissionais farmacêuticos na gestão de stocks?
• Estes modelos de apoio à decisão possuem capacidade de prender o utilizador através de uma interface intuitiva e de fácil aprendizagem e adaptação da mesma?
10
1.4 M
ETODOLOGIA DEI
NVESTIGAÇÃONa área das Tecnologias de Informação (TIs), o principal objetivo da utilização da metodologia de investigação Design Science Research (DSR) é a construção e avaliação de objetos, também designados “artefactos”, que permitem aos profissionais o processamento de informação organizacional e consequente desenvolvimento de ações face a um problema [21] [22]. Tais artefactos incluem algoritmos (por exemplo, para recuperação de informação), interfaces humanas, interfaces de computação e metodologias de conceção de sistemas ou linguagens [25].
Design significa "inventar e fazer acontecer". Assim, o design lida com a criação de algo
novo (objeto ou artefacto) que não existe. Se o conhecimento necessário para criar tal artefacto já existe, então o desenho é comum; caso contrário, é inovador. Desta forma, distingue-se design inovador de design de rotina/comum, no sentido em que este tem a capacidade de produzir conhecimento novo e verdadeiro que demonstra interesse por parte de toda uma comunidade. O design inovador pode, assim, exigir a utilização da metodologia DSR com o intuito de preencher possíveis lacunas de conhecimento, resultando em artigos de investigação ou patentes. As atividades relacionadas com o design de artefactos são centrais para a maioria das áreas. A pesquisa em design (do inglês, Design Research) é considerada uma metodologia com uma longa história, a qual atinge diferentes áreas de conhecimento, como a arquitetura, engenharia, educação, psicologia e as artes plásticas. O campo da informática e da tecnologia da informação, desde o seu aparecimento no final da década de 1940, apropriou-se de muitas das ideias, conceitos e métodos da ciência do design (do inglês Design Science) que acabaram por contribuir para todas as outras áreas supramencionadas. Simultaneamente, os sistemas de informação (do inglês, Informatic Systems), compostos por hardware altamente mutável, software e interfaces humanas, concebem muitos problemas de design únicos e desafiadores que exigem ideias novas e criativas [26].
Analisando a figura 1.4, numa primeira fase é feita uma identificação do problema e motivação, apresentando-se uma proposta de pesquisa. Visto a definição do problema ser usada para o desenvolvimento do artefacto que irá fornecer a solução, torna-se necessário fragmentar o problema para que a solução consiga capturar claramente toda a sua
complexidade. Os recursos necessários para esta primeira etapa incluem conhecimento do estado do problema e ter ciente a importância da solução a ser elaborada.
Considerando a proposta feita na fase inicial, definem-se os objetivos para o desenvolvimento da mesma. Consiste numa fase criativa, em que para além de elementos já existentes podem também surgir elementos novos. Os objetivos podem ser: quantitativos - por exemplo, quando temos uma solução desejável que seria melhor que as atuais; qualitativos – é a descrição de como se espera que um novo artefacto suporte soluções para problemas não abordados até então. Os objetivos devem ser inferidos racionalmente a partir da especificação do problema. Para esta fase, é necessário conhecimento do estado do problema e, caso exista, o conhecimento da sua eficácia na solução atual.
De seguida é desenhado e desenvolvido o artefacto, direcionado a um problema de negócio importante por resolver, o qual deverá ser relevante para a solução do mesmo. O seu desenvolvimento deve seguir um processo científico rigoroso apoiado no conhecimento e na teoria já explorada. Os artefactos podem ser conceções, modelos, métodos, instanciações (cada uma definida de forma extensa) ou novas propriedades de recursos técnicos, sociais e/ou informativos. Esta fase centra-se na definição da funcionalidade desejada para o artefacto e na sua arquitetura e, assente nessa ideia é, por fim, criado o artefacto.
12 Numa fase seguinte arquiteta-se uma demonstração do artefacto. É demonstrada a sua eficácia como solução para uma ou mais instâncias do problema através de experimentações, simulações, casos de estudos, entre outras técnicas. Urge ter em mente que para efetuar uma correta demonstração do artefacto deverá deter-se amplo conhecimento da forma como este é utilizado.
A avaliação do artefacto consegue-se tendo como base os critérios traçados na primeira fase. Assim, esta fase envolve a comparação dos objetivos atualmente propostos com aqueles alcançados através dos resultados obtidos na fase de demonstração. Neste ponto, caso julguem necessário, os investigadores podem traçar uma delineação de melhorias e iterar de novo a solução de forma a melhorar a eficácia do artefacto, ou seja, recomeçar o ciclo DSR, ou simplesmente, comunicar a solução e deixar melhorias para um plano futuro caso considerem que os resultados obtidos são satisfatórios.
A solução deve ser comunicada e propagada de forma eficiente para o público-alvo. Deve ser ainda comunicado o artefacto, a sua utilidade, inovação, rigor, design e a sua eficácia para os investigadores e outras plateias pertinentes.
Assim sendo, todos os casos de estudo descritos neste documento seguem a metodologia de investigação DSR porque cada solução encontrada para cada problema cumpre as necessidades dos profissionais de saúde em ambiente farmacêutico, isto é, novas informações que com base em modelos de previsão tornam mais eficazes o trabalho efetuado pelos profissionais presentes na indústria farmacêutica. Estas informações propõem ainda apresentar melhores resultados no que toca à gestão de existências em farmácias e ultrapassar os desafios atualmente existentes referentes à não linearidade de vendas [26][27].
1.5 E
STRUTURA DO DOCUMENTOPela leitura do diagrama apresentado na figura 1.5, a construção dos modelos de previsão pode ser dividida essencialmente em duas fases: uma 1ª em que o foco reside sobre o conjunto de dados partilhados para esta prova de conceito; uma 2ª fase em que o foco reside na obtenção e partilha das previsões.
Cada um dos passos da estratégia apresentada no diagrama acima é explicado em detalhe nos seguintes capítulos deste documento. Assim sendo, o presente documento encontra-se dividido em seis capítulos: no primeiro e presente capítulo é apresentada a introdução, seguida de uma breve contextualização e enquadramento do tema, posteriormente é explicada a metodologia de investigação adotada nesta dissertação e ainda apresentada a motivação, objetivos e estrutura do documento. No capítulo seguinte, privilegia-se uma explicação dos conceitos mais importantes relacionados com o tema, bem das técnicas de previsão adotadas para esta dissertação. Por fim, releva-se uma revisão bibliográfica daquilo que já foi conseguido fazendo uso destas técnicas. O terceiro capítulo diz respeito à primeira fase do diagrama: o
dataset disponível é examinado, identificando o seu conteúdo e posteriormente é feita a sua
divisão em diferentes datasets para posteriormente serem estudados individualmente. Seguidamente são apresentados os casos de estudo com descrição do desenvolvimento dos modelos de previsão. É apresentado o desenvolvimento da metodologia, assente nas diferentes técnincas, adotada para este trabalho, explicando todo o processo elaborado até obtenção dos modelo de previsão. Inicialmente é ainda realizada uma introdução teórica de conceitos fundamentais aquando a modelação de séries temporais. O capítulo 5 descreve os resultados obtidos através do desenvolvimento dos diferentes modelos e é também feita uma análise e comparação dos mesmos. Finalmente, o sexto e último capítulo do presente documento pretende resumir e apresentar as principais conclusões e contribuições obtidas através da realização deste estudo, assim como responde às questões levantadas no início da presente
14 dissertação. Para além disso, são igualmente apresentadas propostas que podem ser aplicadas no futuro de forma a continuar o estudo.
C
APÍTULO
2
18 No presente capítulo apresenta-se uma revisão e estado da arte dos conceitos associados ao desenvolvimento desta dissertação. Após uma breve explicação dos temas relacionados com esta dissertação são descritas as técnicas abordadas. Elabora-se uma contextualização sobre quais as tecnologias, metodologias e métodos técnicos escolhidos em cada fase do projeto, bem como o racional da sua escolha.
2.1 E
NQUADRAMENTOPor stock entende-se a existência de qualquer artigo ou recurso usado numa organização.
Nas unidades produtivas, os stocks são classificados em matérias-primas, produtos intermédios, produtos acabados, componentes, abastecimento ou trabalho em curso. Segundo [28], gestão de stocks define-se como o estabelecimento de políticas e de standards de performance para controlar o investimento em existência (em unidade e valor), minimizando o custo provocado pelos seus ciclos e movimentações, e o nível de serviço prestado ao cliente. Com uma política apropriada a organização consegue obter vários benefícios, tais como minimizar os custos associados ao produto, garantir a satisfação dos clientes apresentando sempre matéria-prima (mesmo que ocorram variações no tempo de aprovisionamento) e, ainda, permitem criar uma boa imagem de mercado. Uma boa gestão de stocks é crucial para tornar a empresa competitiva e contribuir para a qualidade dos seus produtos, suportando ainda as variações da procura dos mesmos [28][29].
No entanto, os stocks apresentam inconvenientes. Geralmente, é necessário restringir muito espaço, disponibilizar meios financeiros importantes e aumentar o prazo médio de produção. Os custos de stock podem ser divididos em custos de manutenção, de preparação, de encomenda e de falhas de stock. Os custos de manutenção incluem custos das instalações de armazenamento, de manuseamento e de desgaste do stock. Os custos de preparação correspondem aos custos de mudança de produção, que incluem custos de organização de equipamentos e de atribuição de materiais e de tempo. Os custos de encomenda referem-se aos custos de gestão e administrativos para preparar uma ordem de compra ou de produção. Custos de falhas de stocks correspondem a custos de rotura de stock, os quais são custos
tangíveis, como perda de encomenda ou pagamento de multas, e custos intangíveis, como perda de imagem e de clientes [9][10][29].
O objetivo da análise de stocks no fabrico e nos serviços de armazenação consiste em definir quando devem ser encomendados ou produzidos os artigos e qual a dimensão da encomenda ou produção. Para isso, é necessário prever a procura dos produtos de forma a garantir que estes estão disponíveis no momento exato. A procura pode não ser linear e, portanto, esta deverá tentar ser estimada com o máximo de acuidade, usando métodos de previsão. O fornecimento pode ser instantâneo, caso os artigos estejam em stock, ou linear se for efetuado à medida que os artigos são produzidos [9][10][29].
De referir que uma das práticas adotadas por muitas organizações é a “mass
customisation”, a qual é uma estratégia que concentra na produção em massa, mas orientada
ao cliente. Nesta estratégia as mercadorias são produzidas em massa até determinado nível e posteriormente armazenadas em stock. Assim que se recebe uma encomenda, o produto finaliza-se tendo em conta as especificações do cliente, o que permite suportar melhor os custos associados à produção. Desta forma, o stock tem um papel igualmente importante e impõe-se uma boa gestão com base nas previsões de consumo [9][29].
2.2 C
ONCEITOS A RETER SOBRE A TAREFA DE PREVISÃOTal como já referido, uma particularidade importante e diretamente relacionada com o conceito e função de gestão de stocks é o conceito de previsão de vendas. Este, segundo
Pilinkienė (2008), pode ser definido como um processo cujos objetivos são os de analisar a procura atual e de prever variações da mesma num período futuro [29][28]. Muitas pessoas assumem erroneamente que as previsões não são possíveis num ambiente em mudança. A verdade é que hoje em dia, a mudança é constante em todo o tipo de ambiente, e a base de um bom modelo de previsão assenta na identificação da maneira como as coisas estão a mudar. Normalmente assume-se que a forma como o ambiente está a mudar continuará semelhante no futuro. Ou seja, um ambiente altamente volátil continuará a ser altamente volátil; um negócio com vendas flutuantes continuará a ter vendas flutuantes; uma economia que passou por altos e baixos continuará a atravessar altos e baixos. Um modelo de previsão
20 destina-se a captar a maneira como as coisas mudam, não apenas onde e como as coisas estão [30].
As situações de previsão variam amplamente com os seus horizontes de tempo, fatores que determinam resultados reais, tipos de padrões de dados e muitos outros aspetos. Os métodos de previsão podem ser muito simples ou altamente complexos, dependendo dos dados disponíveis e do fator de previsibilidade sobre estes. A previsão assenta numa tarefa estatística comum nos negócios, a qual ajuda a tomada de decisões sobre o planeamento feito à posteriori, e ainda fornece um “guia” para o planeamento estratégico de longo prazo. No entanto, a previsão de negócios é muitas vezes feita erroneamente, e frequentemente confundido o planeamento com as metas a atingir [14][30]. Posto isto, é possível identificar três conceitos distintos:
1. Previsão – diz respeito à previsão do futuro com a maior precisão possível, dadas todas as informações disponíveis, incluindo dados históricos e conhecimento de eventuais eventos futuros que possam afetar as previsões. Os métodos de previsão adequados dependem sobretudo dos dados disponíveis [30].
2. Objetivos - Representam aquilo que é apetecível de acontecer. As metas devem ser vinculadas a previsões e planos, o que nem sempre acontece. Muitas vezes, os objetivos são definidos sem a elaboração de um plano estratégico para os alcançar, o que contribui para que existam previsões que impossibilitam que estes sejam realistas [30].
3. Planeamento – Trata-se duma resposta às previsões e aos objetivos. O planeamento envolve a determinação das ações apropriadas necessárias para que as previsões correspondam aos seus objetivos [30].
A previsão deve ser parte integrante das atividades de tomada de decisão da administração, uma vez que pode desempenhar um papel importante em muitas áreas da empresa.
Geralmente é possível dividir a tarefa da previsão em cinco etapas: • Definição do problema
Esta etapa acaba por ser, muito frequentemente, a tarefa mais difícil, uma vez que a definição cuidada e concisa do problema requer um conhecimento prévio de como os métodos de previsão serão aplicados e como estes se comportam tendo em conta o ambiente apresentado. Um analista precisa de despender tempo comunicando com todas as partes envolvidas, no sentido de recolher toda a informação útil e ainda considerar a manutenção desses dados numa bases de dados [30][31][32].
• Obter informação
Um problema comum na previsão é a carência de dados “bons”. Por vezes, é possível até obter um histórico de dados de elevada dimensão, no entanto a quantidade poderá não se traduzir em qualidade. Elevada quantidade de dados significaria que o modelo a ser treinado teria, muito provavelmente, melhor hipóteses de obter bons resultados, ainda assim, os dados obtidos podem já não se enquadrarem no ambiente de previsão atual e portanto, precisam de ser descartados, acabando por se obter um volume de dados menor que poderá até já não ser suficiente [30][31][32].
• Análise preliminar
O ponto de partida é sempre a exploração dos dados presentes, a qual pode, e deve, concretizar-se através de gráficos. Também através da análise dos gráficos representativos dos dados há possibilidade de verificar se existe algum padrão entre eles, alguma tendência, sazonalidade, ciclos e ainda a presença de outliers.
• Escolha do modelo
Tal como referido previamente, as situações de previsão variam amplamente com diversos fatores. Cada modelo consiste numa construção artificial sobre uma série de pressupostos (implícitos ou explícitos) que geralmente envolve um ou mais parâmetros que deverão ser ajustados tendo em conta o conhecimento sobre os dados [30][31][32].
22 • Teste e Avaliação do modelo
Assim que se escolhe o modelo, e os parâmetros são devidamente ajustados, o método principal para avaliá-lo consiste em aplicá-lo a um conjunto de dados que apresenta já respostas reais e verificar o grau de similaridade entre os resultados obtidos através do modelo e as respostas reais. Caso se verifique que os resultados são bastantes semelhantes, torna-se provável então concluir que os resultados são favoráveis e que a escolha do modelo foi a correta [30][31][32].
Qualquer observação sequencial ao longo do tempo é uma série temporal. Uma série temporal, por vezes também denominada por sucessão cronológica, pressupõe um conjunto de observações elaboradas sequencialmente ao longo do tempo e apresenta normalmente as seguintes notações:
{𝑋𝑡, 𝑡 ∈ 𝑇}
ou {𝑋(𝑡), 𝑡 ∈ 𝑇}
, em que os valores 𝑋 são chamados de estados e 𝑇 é o conjunto de índices. Uma característica muito importante neste tipo de dados é que as observações vizinhas são dependentes e um dos grandes interesses desta dissertação é analisar e modelar essa dependência [28][30].
Os dados das séries temporais são úteis quando se pretende prever algo que está em mudança ao longo do tempo (e.g., preços das ações, números de vendas, lucros), portanto, o objetivo da previsão aplicada a séries temporais é estimar como a sequência de observações continuará no futuro [28][30]. A previsão de séries temporais extrapolará tendências e padrões sazonais, mas ignora informações tais como atividade de concorrentes, mudanças nas condições económicas, e assim por diante. Todas estas informações auxiliares podem, posteriormente ser identificadas através de uma análise aos dados e é ainda possível treinar já o modelo para que este marque determinados eventos que possam alterar o comportamento dos gráficos, tais como feriados, épocas de saldos, épocas do ano, entre outros. As séries temporais podem ser classificadas em Uni variada e Multivariada [28]:
• Uni variada
{𝑋𝑡, 𝑡 ∈ 𝑇}
Exemplo: Seja 𝑋𝑡 a quantidade diária produzida de um fármaco durante um mês.
• Multivariada
{𝑋1(𝑡), … , 𝑋𝑘(𝑡), 𝑡 ∈ 𝑇}
Exemplo: 𝑋1(𝑡) diz respeito às vendas semanais de um fármaco e 𝑋2(𝑡) os custos
associados à publicidade do mesmo durante um ano.
O conjunto 𝑇 pode ser: • Discreto
𝑇 = {0,1,2, … , 𝑁}
Exemplo: Número de nascimentos mensais ocorridos num certo hospital por determinados anos.
• Contínuo
𝑇 = [0, +∞)
Exemplo: Registo da temperatura de uma arca frigorífica durante uma semana em que 𝑇 = [0,24] é a unidade de tempo em horas.
A variável de interesse, 𝑋, pode também ser considerada discreta ou contínua. Na presente dissertação, o conjunto de dados utilizado diz respeito ao número de vendas de vários produtos por ano/mês/dia/hora, logo a variável de interesse é do tipo discreta [28].
Uma série temporal pode ainda conter duas componentes:
• Determinística: Quando os valores da série podem ser escritos através de uma função matemática. Exemplo: Podemos modelar a tendência através de uma função de senos e cossenos.
24 • Estocástica: Caso a série envolva termos aleatórios. Exemplo: O modelo final de uma
série temporal pode depender dos erros passados da própria série.
Tal como referido uma série temporal diz respeito a qualquer observação sequencial ao longo do tempo e para a sua previsão apenas é utilizado informações sobre a variável a ser prevista. Uma série temporal pode ser decomposta em quatro elementos [28][30]:
1. Ciclos 𝐶𝑡: Reporta-se a variações na série que apesar de periódicas não têm qualquer
periodicidade conhecida.
2. Tendência 𝑇𝑡: O aumento ou diminuição do comportamento da série ao longo do tempo.
3. Sazonalidade 𝑆𝑡: Ciclos ou padrões repetitivos que ocorrem ao longo do tempo.
4. Ruído 𝜀𝑡: Variações que ocorrem ao longo da série temporal sem explicação possível.
Para ser possível analisar eficazmente uma série temporal, é importante compreender a interação entre a sazonalidade geral e a tendência resultante. As interações entre tendência e sazonalidade são geralmente classificadas como aditivas ou multiplicativas [33].
• Modelo Aditivo
1) 𝑋𝑡 = 𝐶𝑡+ 𝑇𝑡 + 𝑆𝑡+ 𝜀𝑡
Através da equação 1) verifica-se que uma série temporal aditiva é originada pela soma dos seus componentes. Caso se verifique um aumento na tendência, este não se irá refletir nos restantes componentes, pois a série mantém a sua amplitude aproximadamente constante.
• Modelo Multiplicativo
2) 𝑋𝑡 = 𝐶𝑡× 𝑇𝑡 × 𝑆𝑡× 𝜀𝑡
Tal como demostrado na equação 2) numa série temporal multiplicativa, os seus componentes multiplicam-se para lhe dar origem. Quando a tendência aumenta, a amplitude da atividade sazonal aumenta também. Tudo se torna mais exagerado.
Figura 2.1 - Comparação Modelo Aditivo Vs Modelo Multiplicativo séries temporais (retirado de [29]).
A figura 2.1 ilustra a diferença entre uma série temporal com estes dois modelos. Na imagem do lado esquerdo, embora a tendência seja crescente, verifica-se que a amplitude dos ciclos sazonais mantem-se mais ou menos constante ao longo do tempo (aditiva). Na segunda imagem, a amplitude dos ciclos vai aumentando ao longo do tempo, ou seja, a amplitude do ciclo sazonal aumenta e por isso a serie possui uma sazonalidade multiplicativa [33].
Na presente dissertação todas as séries temporais estudadas são do tipo aditivo.
Relativamente aos tipos de modelos utilizados no estudo das séries temporais, estes podem classificar-se em dois tipos:
• Modelos Paramétricos
Modelo de aprendizagem que resume os dados com um conjunto de parâmetros de
tamanho fixo (independente do número de exemplos de treino). Ou seja, por mais que se aumente o número de dados que se fornece ao modelo paramétrico, este continuará a escolher os mesmo parâmetros [34].
• Modelos Não-Paramétricos
Permite que sejam passadas mais informações do conjunto atual de dados que está anexado ao modelo, de forma a conseguir prever quaisquer dados futuros. Os parâmetros são
26 geralmente infinitos e, portanto, podem expressar as características dos dados melhor do que os modelos paramétricos. Desta maneira, este tipo de modelos incide mais sobre a análise no domínio da frequência e um dos casos muito utilizados na prática designa-se por análise espectral [34].
2.3 T
ECNOLOGIAS USADAS EM MODELAÇÃOApesar de parecer que o ML e a modelação estatística são dois ramos diferentes no que respeita à técnica de previsão, a diferença entre estes dois métodos tem reduzido significativamente. Todavia, entendendo a associação que existe entre ambos e sabendo as suas diferenças, permite aos utilizadores de ML e da estatística expandir o seu conhecimento e aplicar métodos que estejam foram do seu leque de especialização. Estes métodos estão assim organizados em diferentes categorias, contudo, têm mutuamente o objetivo da previsão ou descrição de conhecimento [18]. Posteriormente, o DM engloba grande variedade de tecnologias que permitem a identificação de padrões em dados biomédicos e clínicos, como a quantidade vendida de um medicamento numa certa altura do ano, qual o medicamento mais vendido e o porquê, entre outras relações que podem auxiliar de forma conveniente o utilizador/profissional de saúde [19]. Uma das aplicabilidades que estas soluções poderão ter é a definição de um modelo de abastecimento de stock de medicamentos, o qual poderá contribuir bastante para a diminuição do desperdício, dos gastos em stock e, mais importante, para a correta distribuição de medicação nos setores da saúde. Seguidamente, são apresentadas as ferramentas/metodologias que foram selecionadas para o desenvolvimento do projeto.
2.3.1 RAPIDMINER STUDIO
O RapidMiner (RM) é uma plataforma de software que fornece um ambiente integrado para Machine Learning, Data Mining, Text Mining, análise preditiva e análise de negócios (BI). Apesar de ser desenvolvido em java, uma das principais razões para a sua popularidade é o facto de permitir a elaboração de diversos modelos/fluxos de trabalho bastantes poderosos, sem a necessidade de escrita de código [35]. O RapidMiner considera-se uma ferramenta de
![Figura 1.4 - Metodologia de Investigação Design Science Research (adaptado de [23]).](https://thumb-eu.123doks.com/thumbv2/123dok_br/17252056.787995/31.892.125.766.240.529/figura-metodologia-de-investigação-design-science-research-adaptado.webp)

![Figura 2.1 - Comparação Modelo Aditivo Vs Modelo Multiplicativo séries temporais (retirado de [29]).](https://thumb-eu.123doks.com/thumbv2/123dok_br/17252056.787995/45.892.147.756.149.416/figura-comparação-modelo-aditivo-modelo-multiplicativo-temporais-retirado.webp)
![Figura 2.2 - Esquema de uma rede neuronal padrão (retirado de [37]).](https://thumb-eu.123doks.com/thumbv2/123dok_br/17252056.787995/51.892.226.656.490.729/figura-esquema-de-uma-rede-neuronal-padrão-retirado.webp)