NILDO NUNES CORNELIO
ESTUDO SOBRE OS IMPACTOS DE VARIÁVEIS DO DESENVOLVIMENTO DE SOFTWARE NA QUALIDADE DO PRODUTO
Dissertação apresentada ao Programa de Pós-Graduação Stricto-Sensu em Gestão do Conhe-cimento e Tecnologia da Informação da Univer-sidade Católica de Brasília, como requisito para obtenção do grau de Mestre em Gestão do Co-nhecimento e Tecnologia da Informação.
Orientador: Prof. Dr. Edilson Ferneda Coorientador: Prof. Dr. Hércules do Prado
Ficha elaborada pela Biblioteca Pós-Graduação da SIBI//UCB C814e Cornelio, Nildo Nunes
Estudo sobre os impactos de variáveis do desenvolvimento de software na qualidade do produto / Nildo Nunes Cornelio – 2012.
94 f. : il. ; 30 cm.
Dissertação (mestrado) – Universidade Católica de Brasília, 2012.
Orientação: Dr. Edilson Ferneda
1. Gestão do conhecimento. 2. Software - Controle de qualidade. 3. Exploração de dados (Computação). 4. Previsão. I. Ferneda, Edilson, orient.
II. Título.
Dissertação de autoria de Nildo Nunes Cornelio, intitulada “ESTUDO SOBRE OS IMPACTOS DE VARIÁVEIS DO DESENVOLVIMENTO DE SOFTWARE NA QUALIDADE DO PRODUTO” , apresentada como requisito parcial para a obtenção do grau de Mestre em Gestão do Conhecimento e Tecnologia da Informação da Uni-versidade Católica de Brasília, em 07-12-2011, defendida e aprovada pela banca examinadora abaixo assinada:
Prof. Dr. Edilson Ferneda - Orientador
Prof. Dr. Fábio Bianchi – Co-orientador
Prof. Dr. Hércules do Prado - Banca Examinadora
Prof. Dr. – Banca Examinadora
AGRADECIMENTOS
Agradeço infinitamente a Deus, pela saúde, inspiração, proteção e permissão para realizar este trabalho.
Agradeço também aos Profs. Edilson Ferneda, Fábio Bianchi e Hércules A. do Prado, pela paciência durante a orientação e sugestões na elaboração desta disser-tação.
Agradeço ao Prof. Aluízio pela participação e sugestões na banca.
Agradeço a minha mãe Abadia e a meu pai Donício (em memória), pelo amor e por acreditar em mim, em todos os momentos da minha vida.
À minha ex-esposa Eliene, pelo amor, compreensão e apoio integral, nesta etapa do mestrado .
Às minhas irmãs, Ieda, Ione, sobrinhos(a) Bernarndo, Giovane, Juliana e Leo-nardo, cunhados Amilton e Rainer, pelo amor e por me apoiarem em qualquer cami-nhada.
À Universidade Católica de Brasília, que me possibilitou a realização deste trabalho.
A todos amigos(as) e aqueles(as) que me ajudaram direta ou indiretamente a concretizar este sonho.
“Deus me conceda a serenidade para aceitar o que não posso mudar, a tenacidade para mudar o que posso e a boa sorte para não estragar tudo com muita frequência”.
RESUMO
O avanço da tecnologia da informação tem viabilizado o acúmulo de grandes e múl-tiplas massas de dados advindas dos sistemas de informação. Tal fato possibilitou o surgimento e desenvolvimento de pesquisas de Descoberta de Conhecimento em Base de Dados (DCBD), que visa, basicamente, a identificação de padrões novos e úteis em bases de dados. Entre suas áreas de aplicação, qualidade de software vem recebendo atenção mais recentemente. A qualidade de software tornou-se um tema importante para a manutenção e conquista de clientes para as empresas, podendo ser considerada uma arma competitiva. Por outro lado, a qualidade da tomada de decisão em gestão de projetos de software está intimamente relacionada às infor-mações disponíveis sobre o processo de desenvolvimento da organização. Estas informações podem ser obtidas diretamente do processo de desenvolvimento e ana-lisadas com técnicas de DCBD. Este trabalho descreve uma aplicação de DCBD em bases de métricas de qualidade de produtos de software na qual se buscou a identi-ficação das variáveis do processo de desenvolvimento que mais afetam a taxa de erro nas fases de teste, homologação e produção. A empresa alvo do estudo possui um elevado nível de padronização dos seus processos. A construção da aplicação foi conduzida com base nas recomendações do modelo CRISP-DM. Os resultados obtidos nos modelos apontaram uma correlação forte ou moderada de algumas vari-áveis do processo com a qualidade do produto, que podem ser alvo da atenção dos gestores de modo a: (i) melhorar a qualidade geral do processo de desenvolvimento, (ii) reduzir a taxa de erro nos sistemas desenvolvidos e (iii) promover maior
satisfa-ção dos clientes.
ABSTRACT
The advance of information technology has made possible the accumulation of large and multiple masses of data arising from information systems. This fact enabled the emergence and growth of research on Knowledge Discovery in Database (DCBD), which aims primarily to identify new and useful patterns in databases. Among its areas of application, software quality has receiving attention more recently. The quality of software has become an important issue for the maintenance and customer attraction for businesses and can be considered a competitive weapon. On the other hand, the quality of decision making in project management software is closely related to information available about the process of organizational development. This information can be acquired directly from the development process and analized using techniques of DCBD. This work describes an application of DCBD bases of quality metrics for software products which aimed to identify the variables of the process of development which would most affect the error rate during the phases of testing, approval, and production. The study of the target company has a high level of standardization of its processes. The development of the application was conducted based on the guidelines of CRISP-DM model. The results obtained in the models indicated a strong or moderate correlation of some variables of the process with product quality, which may be the target of management attention in order to: (i)
improve the overall quality of the development process, (ii) to reduce the error rate in
the systems developed and (iii) promote greater customer satisfaction.
LISTA DE FIGURAS
Figura 1 Processo de descoberta de conhecimento ... 31
Figura 2 Fases do CRISP-DM ... 32
Figura 3 Exemplo de rede RBF ... 37
Figura 4 Histogramas das variáveis de entrada ... 56
Figura 5 Formatação do nome do projeto ... 61
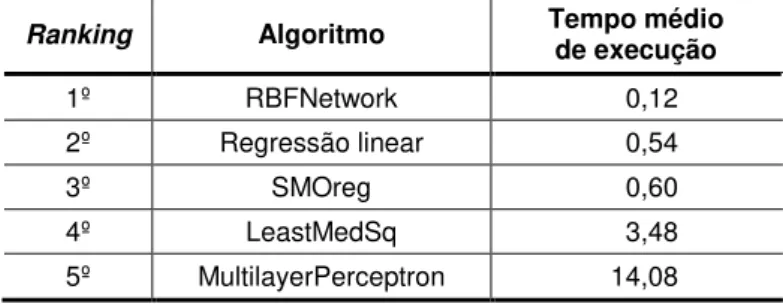
Figura 6 Comparação dos tempos de execução entre as técnicas de mineração consideradas ... 65
Figura 7 Visualização gráfica dos pesos no modelo para densidade de defeitos na fase de testes para desenvolvimento em ordem crescente... 75
Figura 8 Visualização gráfica dos pesos no modelo para densidade de defeitos na fase de testes para manutenção em ordem crescente ... 76
Figura 9 Visualização gráfica dos pesos no modelo para densidade de defeitos na fase de homologação para desenvolvimento ... 77
Figura 10 Visualização gráfica dos pesos no modelo para densidade de defeitos na fase de homologação para manutenção ... 78
Figura 41 Visualização gráfica dos pesos no modelo para quantidade de manutenções corretivas após implantação por PF para desenvolvimento ... 79
Figura 52 Visualização gráfica dos pesos no modelo para quantidade de manutenções corretivas após implantação por PF para manutenção ... 80
QUADROS
Quadro 1 Tipos de métricas ... 26Quadro 2 Detalhamento das variáveis de entrada ... 44
LISTA DE TABELAS
Tabela 1 Quantificação dos projetos considerados ... 43
Tabela 2 Extração parcial dos dados do sistema de garantia de qualidade ... 52
Tabela 3 Extração parcial dos dados do sistema Mantis ... 52
Tabela 4 Extração parcial dos dados do primeiro sistema ... 53
Tabela 5 Quantificação dos atributos por arquivo ... 54
Tabela 6 Estatísticas básicas das variáveis de entrada numéricas ... 54
Tabela 7 Estatísticas básicas das variáveis de saída ... 54
Tabela 8 Quantitativo das variáveis discretas de entrada nominais ... 54
Tabela 9 Comparação dos valores de PF para manutenção e desenvolvimento ... 57
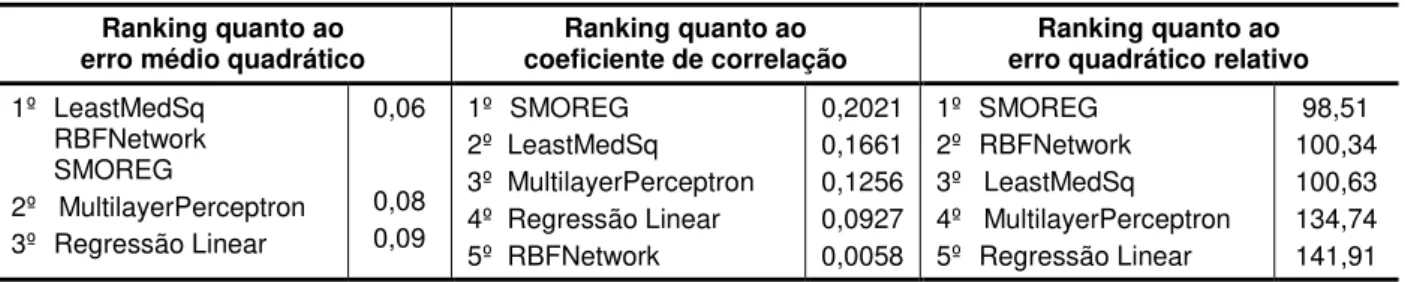
Tabela 10 Resultados de execução de algoritmos de regressão para a densidade de defeitos na fase de testes (3-fold) ... 63
Tabela 11 Resultados de execução de algoritmos de regressão para a densidade de defeitos na fase de homologação (3-fold) ... 63
Tabela 12 Resultados de execução de algoritmos de classificação e regressão para a quantidade de manutenções corretivas após implantação por PF (3-fold) ... 63
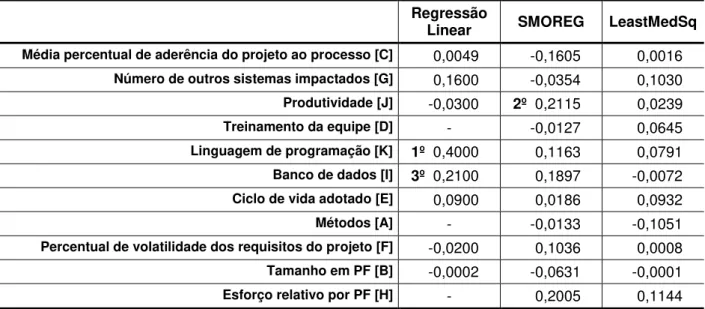
Tabela 13 Ranking dos modelos preditivos em relaçãoà densidade de defeitos na fase de testes ... 64
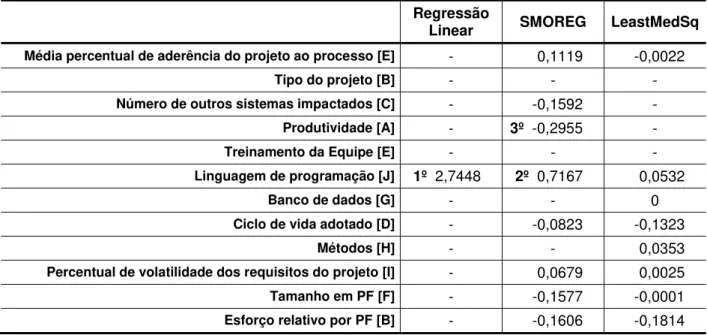
Tabela 14 Ranking dos modelos preditivos em relaçãoà densidade de defeitos na fase de homologação ... 64
Tabela 15 Ranking dos modelos preditivos em relaçãoà quantidade de manutenções corretivas após implantação por PF ... 64
Tabela 16 Ranking relativo ao tempo médio de execução para todas as variáveis de saída ... 65
Tabela 17 Ranking relativo a cada uma das variáveis de saída ... 65
Tabela 18 Densidade de defeitos na fase de testes para desenvolvimento ... 68
Tabela 19 Densidade de defeitos na fase de homologação para desenvolvimento ... 68
Tabela 20 Quantidade de manutenções corretivas após implantação por PF para desenvolvimento ... 68
Tabela 21 Densidade de defeitos na fase de testes para manutenção ... 68
Tabela 22 Densidade de defeitos na fase de homologação para manutenção ... 69
Tabela 23 Quantidade de manutenções corretivas após implantação por PF para manutenção ... 69
Tabela 24 Pesos no modelo para densidade de defeitos na fase de testes para desenvolvimento ... 75
Tabela 25 Pesos no modelo para densidade de defeitos na fase de testes para manutenção ... 76
Tabela 27 Pesos no modelo para densidade de defeitos na fase de homologação para
manutenção ... 78
Tabela 28 Pesos no modelo para quantidade de manutenções corretivas após implantação por PF para desenvolvimento ... 79
Tabela 29 Pesos no modelo para quantidade de manutenções corretivas após implantação por PF para manutenção ... 80
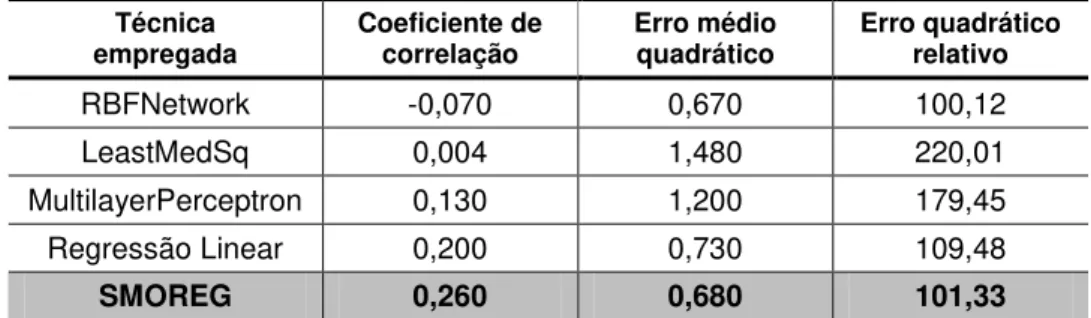
Tabela 30 Coeficientes de correlação para os dados misturados por tipo ... 85
Tabela 31 Projetos de desenvolvimento ... 85
LISTA DE ABREVIATURAS E SIGLAS
CRISP-DM - Cross Industry Standard Processfor Data Mining
ES - Engenharia de Software
GQS - Garantia de Qualidade de Software
ISO - International Organization for Standardization
DCBD - Descoberta de Conhecimento em Bases de Dados MD - Mineração de Dados
PF - Pontos por Função
SGI - Sistema Gerencial de Informações
SUMÁRIO
1 INTRODUÇÃO ... 15
1.1 TEMA ... 15
1.2 RELEVÂNCIA DO ESTUDO ... 15
1.3 FORMULAÇÃO DO PROBLEMA ... 16
1.4 OBJETIVOS ... 18
1.5 ORGANIZAÇÃO DA DISSERTAÇÃO ... 19
2 REFERENCIAL TEÓRICO ... 20
2.1 ENGENHARIA DA QUALIDADE ... 20
2.1.1 Qualidade do processo de software ... 22
2.1.2 Qualidade do produto de software ... 23
2.1 3 Métricas de software ... 25
2.1.4 Teste de software ... 28
2.2 DESCOBERTA DE CONHECIMENTO EM BANCOS DE DADOS ... 30
2.2.1 CRISP-DM ... 32
2.2.2 Técnicas de Data Mining ... 33
2.2.3 Algoritmos de regressão ... 35
3 METODOLOGIA ... 42
3.1 CLASSIFICAÇÃO DA PESQUISA ... 42
3.2 POPULAÇÃO E AMOSTRA ... 42
3.3 COLETA DE DADOS ... 43
3.4 O ESTUDO REALIZADO... 44
3.5 DELIMITAÇÃO DO ESTUDO ... 46
4 ESTUDO DE CASO ... 47
4.1 COMPREENSÃO DO NEGÓCIO ... 47
4.1.1 Objetivos do negócio ... 47
4.1.2 Avaliação da situação ... 48
4.1.3 Objetivos do data mining ... 48
4.1.4 Plano do projeto ... 49
4.2 ENTENDIMENTO DOS DADOS ... 49
4.2.1 Coleta inicial dos dados ... 49
4.2.2 Descrição dos dados ... 51
4.2.3 Exploração dos dados ... 55
4.2.4 Verificação da qualidade dos dados ... 57
4.3 PREPARAÇÃO DOS DADOS ... 58
4.3.1 Seleção dos dados ... 58
4.3.2 Limpeza dos dados ... 59
4.3.3 Engenharia dos dados... 60
4.4 MODELAGEM ... 61
4.4.1 Seleção da técnica de modelagem ... 61
4.4.2 Teste do projeto ... 62
4.4.3 Construção dos modelos ... 62
4.4.4 Avaliação dos modelos... 63
4.4.5 Modelos com a separação por tipo de projeto ... 67
4.5 AVALIAÇÃO DOS RESULTADOS ... 70
4.5.1 Revisão dos processos ... 70
4.5.2 Próximos passos ... 70
4.6 DISTRIBUIÇÃO ... 71
4.6.1 Planejamento da distribuição... 71
4.6.2 Plano de monitoração e manutenção ... 72
4.6.3 Elaboração do relatório final ... 72
4.6.4 Revisão de projeto ... 72
5 RESULTADOS E DISCUSSÕES ... 74
6 CONCLUSÕES E TRABALHOS FUTUROS ... 87
REFERÊNCIAS ... 89
1 INTRODUÇÃO
1.1 TEMA
Um desenvolvimento organizado de software se vale, necessariamente, de uma metodologia de trabalho. Esta metodologia deve ter como base conceitos que visem a construção de um produto de software de forma eficaz e com boa qualidade. Dentro desta metodologia estão definidos os passos necessários para chegar ao produto final esperado. Assim, quando se segue uma metodologia para o desenvol-vimento de um produto de software espera-se um produto final que satisfaça tanto aos clientes quanto ao próprio fornecedor, e isso independentemente da metodolo-gia de trabalho empregada para o desenvolvimento de um software. Assim, para se obter um produto final com certo nível de qualidade, é imprescindível a melhoria dos processos de engenharia de software (ES).
Este trabalho trata da influência de alguns aspectos do desenvolvimento de software na qualidade do produto final. Sabe-se que, segundo Faust (1995), existem duas dimensões no processo de desenvolvimento do software: a dimensão externa, que se refere ao usuário do sistema e a dimensão interna, que envolve o processo de desenvolvimento do software. Este trabalho diz respeito apenas à dimensão in-terna, onde faz-se um estudo sobre a influência de um conjunto definido de variáveis do processo de desenvolvimento sobre as variáveis dependentes que representam a qualidade de um produto.
1.2 RELEVÂNCIA DO ESTUDO
O esforço para o aprimoramento do processo de desenvolvimento de software tem se caracterizado fortemente pela tendência, por parte dos desenvolvedores, de se buscar o atendimento dos padrões definidos pelas certificadoras de desenvolvi-mento de software. No entanto, em que pese a importância do processo, tanto o seu produto quanto a satisfação do cliente não têm sido focalizado na mesma intensida-de.
desem-penho produtivo dos profissionais que trabalham com o sistema.
Diversos fatores influenciam a qualidade de um produto de software. Confor-me McCall e Cavano (1978), tais fatores podem refletir a qualidade de um produto de software em pontos distintos, por meio de métricas tais como transição, revisão e operação do produto. Para a transição do produto, têm-se as métricas referentes a portabilidade, reutilização e interoperabilidade. Para a revisão do produto, as métri-cas utilizadas dizem respeito à manutenção, testabilidade e flexibilidade. Para a ope-ração do produto, utiliza-se de métricas relativas a correção, confiabilidade, usabili-dade, integridade e eficiência.
Conhecer alguns fatores que influenciam a qualidade de um produto de sof-tware torna as empresas mais competitivas, pois empresas que produzem sofsof-tware de alta qualidade podem, em geral, oferecer um melhor serviço a um preço mais competitivo.
Empresas de desenvolvimento de software precisam constantemente aperfei-çoar seus processos. Para isso, a coleta e sistematização de dados geralmente rea-lizadas por essas empresas pode ser uma fonte preciosa de informações úteis. Um dos objetivos pode ser a construção de modelos preditivos de qualidade do produto e de custos, gerando subsídios para a tomada de decisão por parte de gestores de projetos.
1.3 FORMULAÇÃO DO PROBLEMA
Os avanços da tecnologia ocorridos nas últimas décadas têm proporcionado aos gestores de negócios uma grande disponibilidade de ferramentas de apoio à tomada de decisão. Novas tecnologias da informação têm surgido de forma acelera-da, fazendo com que o mercado de desenvolvimento de software seja cada vez mais competitivo. Esse novo cenário de negócios tem obrigado empresas desse setor a buscarem constantemente tecnologias e métodos que lhes permitam garantir a qua-lidade de seus produtos.
sof-tware, em termos de qualidade do produto final e custos, é geralmente consequência da maturidade do processo de desenvolvimento empregado.
A gestão dos projetos de desenvolvimento de software está sujeita a diversos problemas. A natureza desses problemas gira muitas vezes em torno do dimensio-namento dos recursos necessários para o projeto. Normalmente, os desenvolvedo-res trabalham em mais de um projeto ao mesmo tempo, com impacto significativo na qualidade dos produtos resultantes. Outros problemas dizem respeito, por exemplo, a dimensionamento e formação da equipe, dimensionamento do tempo necessário para cada uma de suas fases, customização do projeto ao processo corporativo e abordagem de teste utilizada.
Nos últimos anos, muitos esforços têm sido despendidos na questão de quali-dade de software, alguns deles abordando os aspectos econômicos da qualiquali-dade. COQUALMO (CHULANI, 2002), por exemplo, é um modelo de qualidade de produto de software que reconhece a importância econômica em projetos de desenvolvimen-to, evidenciando as relações entre custos, cronograma e riscos.
Atualmente, já há consciência entre os gestores de projetos de software sobre a necessidade de se considerar as métricas de qualidade não só do produto final, mas também no processo de seu desenvolvimento. Mas a garantia dessa qualidade demanda do gestor do projeto conhecimento técnico sobre os métodos e ferramen-tas disponíveis, além de habilidades relativas a relacionamento interpessoal e lide-rança de equipes.
Como base para qualquer processo de gerência, pressupõe-se que deve exis-tir um sistema de retroalimentação que lhe forneça informações relativas ao proces-so para que eventuais falhas possam vir a ser rapidamente corrigidas. Também é necessário organizar as informações coletadas para que se possa melhor relacionar a qualidade dos produtos com os processos utilizados.
Em relação ao processo de gestão relatado por Boehm (2003), a prática em
ES é feita em um cenário de ‘valor neutro’, onde todos os requisitos, casos de uso,
perspectiva atual, essa influência é cada vez mais perceptível.
De acordo com Buschmann et al.(2000), alguns dos problemas relacionados ao desenvolvimento de sistemas dizem respeito à sua arquitetura, bem como aos requisitos não-funcionais. Assim, a noção de qualidade deve ser considerada desde a fase de concepção do sistema, por meio de atributos como modificabilidade, a por-tabilidade, a reusabilidade, a integrabilidade e a tespor-tabilidade, até a fase de produ-ção, por meio de atributos como desempenho, segurança, disponibilidade, funciona-lidade e usabifunciona-lidade.
Pfleeger (1994) afirma que as métricas são fundamentais para a avaliação de desempenho e de progresso da qualidade de um produto. Elas devem garantir qua-lidade e transparência aos processos. Através da medição, a produção de software pode ser monitorada, proporcionando uma avaliação constante do processo e a possibilidade de ajustes em função de tendências detectadas.
Em um projeto de software, o levantamento e a gestão de requisitos tornam-se parte do processo de gerência da qualidade. É preciso ter claro qual é o universo informacional, o contexto no qual será desenvolvido e operado e as necessidades dos clientes e dos usuários do software em questão.
A quantidade de retrabalho e de manutenções corretivas em sistemas de sof-tware está geralmente relacionada com a qualidade do processo de desenvolvimen-to (Marshall et al., 2006). Observa-se que a falha muitas vezes está no não cumpri-mento de determinadas etapas que poderiam agregar qualidade ao produto ou no desconhecimento dos fatores determinantes para alcançar a qualidade almejada. Poucas iniciativas nesse sentido podem ser percebidas no âmbito das organizações, no sentido de produzir informações úteis para apoiar decisões a nível estratégico, visando aumentar a qualidade do processo de desenvolvimento.
A partir do exposto acima, pode-se considerar a seguinte questão geradora: Como identificar os fatores do desenvolvimento que influenciam na qualidade de um produto de software?
1.4 OBJETIVOS
a gerar subsídios para gestão da qualidade do projeto. Para isso, tem-se por objetivos específicos:
Identificar variáveis do processo de desenvolvimento de software candidatas a preditoras da qualidade do produto final;
Testar modelos de regressão visando identificar os que melhor correlacionam as variáveis do processo de desenvolvimento de software candidatas e a quali-dade do produto final;
Elencar o conjunto de variáveis da metodologia de criação de software utilizada que possam ser foco de atuação do gestor de projetos de software com vistas à melhoria da qualidade do produto final.
1.5 ORGANIZAÇÃO DA DISSERTAÇÃO
Inicialmente, no Capítulo 1, apresenta-se o tema da pesquisa e a problemati-zação que a pesquisa se destina a resolver, contendo também os objetivos gerais e específicos a serem atingidos. O Capítulo 2 refere-se ao referencial teórico para em-basamento do tema, contendo um estudo bibliográfico das principais referências do assunto. A metodologia para a pesquisa é descrita no Capítulo 3, contendo a descri-ção dos dados e como será feita a coleta, análise e interpretadescri-ção dos resultados.
2 REFERENCIAL TEÓRICO
2.1 ENGENHARIA DA QUALIDADE
De acordo com a International Standardization Organization (ISO, 2000),
or-ganização internacional responsável pelas normas de qualidade, em diversos seto-res, qualidade é a adequação ao uso; é a conformidade às exigências.
Qualidade tem a ver, primordialmente, com o processo pelo qual produtos ou serviços são materializados. Segundo Gonçalves (2007), "a qualidade reside no que se faz – aliás – em tudo o que se faz – e não apenas no que se tem como
conse-quência disso.” Em outras palavras, todos os processos de uma determinada ativ i-dade são importantes; se os processos forem estruturados e desenvolvidos com qualidade, o produto final terá qualidade.
A qualidade está ligada a sentimentos subjetivos que refletem as necessida-des internas de cada um. Muitas pessoas avaliam a qualidade pela aparência; ou-tras se voltam à qualidade do material com que é feito o produto. Ouou-tras, ainda, ava-liam a qualidade de alguma coisa pelo preço.
Ainda conforme Gonçalves (2007), existem várias dimensões para qualidade, mas o processo reflete seus aspectos objetivos e mensuráveis. É pelo processo que se pode implantar modelos de qualidade como, por exemplo, as normas ISO-9000 (ISO, 2000). Assim, tanto os processos de fabricação de um Rolls Royce como a preparação de sanduíches McDonald`s seguem etapas de desenvolvimento bem es-tabelecidas. A tinta na coloração exata, as máquinas da linha de produção perfeita-mente reguladas, os parafusos nos lugares corretos, o tempo de fabricação perfei-tamente controlado, um veículo exaperfei-tamente igual ao outro. Da mesma forma, os componentes do sanduíche sempre do mesmo fornecedor, a chapa de fritura aque-cida na mesma temperatura, a forma do manuseio do sanduíche sempre com higie-ne resultando num produto final bastante parecido, independente da lanchohigie-nete que se utilize. É o chamado padrão de qualidade.
se-jam tão somente adequados às crianças e aos adolescentes). Mesmo sem questio-nar a qualidade de um Rolls Royce, o seu preço é passível de crítica.
A partir da preocupação das organizações em estudar a qualidade nas di-mensões não atingidas pelos processos, surgiu o conceito de Qualidade Total, que abrange e se dedica a estudar a satisfação dos clientes. O conceito de cliente deve ser estendido ao ponto de todos – numa organização – serem considerados clientes. Existem, então, clientes externos (todos que entram em contato com a organização e que não são parte integrante da mesma) e clientes internos (todos os funcionários e setores da organização). Dessa forma, avaliam-se as relações dos diversos seto-res de uma organização e desta com a sociedade como um todo. (OAKLAND,1994)
Para Gonçalves (2007), qualidade pode, então, ser definida como o conjunto de atributos que tornam um bem ou serviço plenamente adequado ao uso para o qual foi concebido, atendendo a critérios tais como: operabilidade, segurança, tole-rância a falhas, conforto, durabilidade, facilidade de manutenção e outros. Essa no-ção de qualidade como adequano-ção ao uso, apesar de clara e concisa, não explicita algumas particularidades das atividades de produção, comercialização e atendimen-to pós-venda de um produatendimen-to (ou, guardadas as proporções, de um serviço). De faatendimen-to, são também associadas à qualidade outras características típicas da relação entre o fornecedor e o usuário, tais como a capacidade do fornecedor em se antecipar às necessidades do cliente, o seu tempo de resposta e o suporte oferecido.
Se a qualidade de um produto é, em parte, decorrente da qualidade do pro-cesso de produção, é necessário acompanhar o seu ciclo de vida, desde o projeto até o uso. Para isso, devem ser identificados os atributos que irão determinar essa qualidade, nortear sua produção de acordo com as especificações determinadas e acompanhar o seu uso, verificando se foi adequadamente projetado e corretamente produzido. Nesse contexto, a Engenharia da Qualidade se coloca como o conjunto das técnicas e procedimentos para (i) o estabelecimento de critérios e medidas da
qualidade de um produto, (ii) a identificação dos produtos que não estejam
confor-mes a tais critérios, evitando que cheguem ao mercado, e (iii) o acompanhamento
do processo de produção, identificando e eliminando as causas que levem a não-conformidades. (GONÇALVES, 2007)
organi-zações em geral, qualquer que seja o seu tipo ou dimensão. Esta família de normas estabelece requisitos que auxiliam a melhoria dos processos internos, a maior capa-citação dos colaboradores, o monitoramento do ambiente de trabalho, a verificação da satisfação dos clientes, colaboradores e fornecedores, num processo contínuo de melhoria do sistema de gestão da qualidade. Essas normas são aplicáveis a campos tão distintos quanto materiais, produtos, processos e serviços. (WIKIPÉDIA, 2010).
2.1.1 Qualidade do processo de software
Para Reis (2002), um processo de software pode ser compreendido como o conjunto de todas as atividades necessárias para transformar os requisitos do usuá-rio em software. É formado por um conjunto de passos de processo parcialmente denados, relacionados com conjuntos de artefatos, pessoas, recursos, estruturas or-ganizacionais e restrições, tendo como objetivo produzir e manter os produtos de software finais requeridos. O processo utilizado no desenvolvimento de um projeto tem grande reflexo na produtividade e na qualidade do software desenvolvido.
Apesar dos modelos aplicados na garantia da qualidade de software atuarem principalmente no processo, seu principal objetivo é garantir um produto final que sa-tisfaça às expectativas do cliente, dentro daquilo que foi acordado inicialmente.
O Modelo Integrado de Capacitação e Maturidade (Capability Maturity Model
Integration) (CMMI, 2006) é um modelo de qualidade desenvolvido e mantido pelo
Software Engineering Institute1, da Universidade Carnegie-Mellon, sob o patrocínio
do Departamento de Defesa dos EUA, visando a melhoria dos processos organiza-cionais. Ele baseia-se em uma escala numérica para se avaliar a maturidade de um processo (por exemplo, de desenvolvimento ou manutenção de software) ou de uma equipe.
O CMMI está dividido em cinco níveis de maturidade: Inicial (nível 1); Dirigido (nível 2); Definido (nível 3); Quantitativamente gerenciado (nível 4) e Otimização (ní-vel 5).
No nível 1 de maturidade do CMMI, os processos de desenvolvimento e ma-nutenção de software geralmente se apresentam sem nenhuma organização, e tam-bém são feitos para um propósito específico (SEI, 2011). Neste nível de maturidade, para que a organização tenha êxito, é necessário que cada um se empenhe, pois
não há um processo claro definido, o que pode ocasionar atrasos no orçamento e no cronograma.
No nível 2 de maturidade, busca-se a repetição da gestão para se alcançar a excelência. Há a preocupação em se documentar e executar um projeto de forma padronizada, de modo a controlar variáveis como o custo,o esforço e o prazo.
No nível 3 do CMMI, existe a preocupação em se padronizar o processo de engenharia de software na empresa como um todo. Define-se, neste nível, um pro-cesso a partir de um padrão anteriormente criado, e este é divulgado e internalizado entre os funcionários.
No nível 4 de maturidade, o principal objetivo é coletar métricas de desenvol-vimento e manutenção para controle. Por meio das métricas, o gestor pode modificar comportamentos adversos ajustando o projeto para que o sucesso seja atingido a tempo, ou seja, há o conceito do gerenciamento quantitativo.
Por último, o nível de maturidade 5 busca o aperfeiçoamento contínuo do pro-cesso de desenvolvimento e manutenção, implementando novos conceitos e tecno-logias emergentes, sem causar grandes impactos nos produtos criados.
Outro modelo que também visa o aumento da qualidade pela melhoria do processo é o MPS-BR. O MPS.BR, Melhoria de Processos do Software Brasileiro, é um modelo de qualidade voltado para a realidade das pequenas e médias empresas de desenvolvimento de software do mercado brasileiro (MPS.BR, 2006). Este mode-lo apresenta 7 níveis de maturidade: Em Otimização, Gerenciado quantitativamente (nível B), Definido (nível C), Largamente Definido (nível D), Parcialmente Definido (nível E), Gerenciado (nível F), Parcialmente Gerenciado (nível G).
Neste modelo, existem processos categorizados da seguinte forma: proces-sos fundamentais, procesproces-sos organizacionais e procesproces-sos de apoio. Para cada nível de maturidade anteriormente relatado, há uma avaliação para que a organização atinja um determinado nível de capacitação.
2.1.2 Qualidade do produto de software
de vista do cliente, a qualidade está associada ao valor e à utilidade reconhecidos ao produto, estando em alguns casos ligada ao preço.
A Norma ISO 9126 define a Qualidade de Software como “a totalidade de c a-racterísticas de um produto de software que lhe confere a capacidade de satisfazer necessidades explícitas e implícitas”. A Norma ISO/IEC 9126-1 (ISO, 2003) identifica 6 principais características da qualidade de software e 21 sub-características abran-gendo partes internas e externas de produto de software, permitindo uma avaliação do software pela visão do usuário. Segundo essa norma, as características analisa-das dizem respeito a: (i) funcionalidade (as funções satisfazem as suas
necessida-des?), (ii) confiabilidade (o software é capaz de lidar com erros?), (iii) usabilidade (o
software é de fácil de ser usado?), (iv) eficiência (os recursos e os tempos são
com-patíveis com o desempenho requerido?), (v) manutenibilidade (é fácil fazer
altera-ções, atualizações e correções no software?) e (vi) portabilidade (é possível usar o
software em outras plataformas?). Segundo Barreto (2011), acrescentar proprieda-des em um sistema de software para beneficiar a manutenibilidade requer custos adicionais, onde há necessidade de se planejar adequadamente as propriedades que um produto deve ter para agregar qualidade na fase de manutenção.
De acordo com Chulani (2002), o modelo COQUALMO é um modelo para es-timar a qualidade de um produto de software. Nele, prevê-se a densidade de defeito do software em desenvolvimento onde os defeitos fluem conceitualmente em um
“tanque” através de vários tubos de introdução de defeitos e são removidos através de vários tubos de remoção de defeitos.
Ainda conforme Chulani (2002), o modelo COQUALMO já foi validado contra estudos publicados sobre densidades de defeitos na área de desenvolvimento de software e o mesmo permitiu realizar comparações com outros modelos relativos a qualidade do produto.
2.1.3 Métricas de software
Segundo Machado (2008, p. 2):
Uma métrica é uma medição de um atributo (propriedades ou característi-cas) de uma determinada entidade (produto, processo ou recursos). Exem-plo: Tamanho do produto de software (número de linhas de código). As mé-tricas de software são úteis, pois permitem o alcance da qualidade do pro-duto por meio da melhoria da qualidade do processo. A qualidade do produ-to de software pode ser avaliada pela medição dos atribuprodu-tos internos (tipi-camente medidas estáticas de produtos intermediários), ou pela medição dos atributos externos (tipicamente medidas do comportamento do código quando executado), ou pela medição dos atributos de qualidade em uso
Métricas são necessárias para: (i) analisar qualidade e produtividade do
pro-cesso de desenvolvimento e manutenção bem como do produto de software constru-ído, (ii) qualificar o desempenho técnico dos produtos do ponto de vista do
desen-volvedor, (iii) qualificar o desempenho dos produtos pela perspectiva do usuário ou
(iv) comparar a produtividade de diferentes técnicas e tecnologias.
As métricas possibilitam o planejamento, atividade fundamental do processo de gerenciamento de projetos. A partir do planejamento, identifica-se a quantidade de esforço, o custo e as atividades necessárias para a realização do projeto.
Até há bem pouco tempo, a única base para a realização de estimativas era a experiência da equipe técnica envolvida no projeto. Diversos problemas, no entanto, ocorriam por se considerar apenas esse aspecto: (i) atividades sobrepostas ou não
realizadas, (ii) produtos com deficiência funcional, (iii) custo de realização além do
previsto, ou (iv) atraso na entrega do produto. Para a mitigação de tais falhas,
Go-mes (2001 apud KANTORSKI, 2004) sugere as seguintes métricas para o processo de gerenciamento do software:
Precisão da estimativa de cronograma de todo o projeto, precisão das estimati-vas de cronograma para as fases de análise, projeto, codificação, testes de unidade feitos por analistas, testes do sistema e testes para homologação.
Esforço total de projeto; esforço nas fases de análise, projeto, codificação, tes-tes de unidade, tes-testes-tes do sistema e tes-testes-tes de homologação; esforço em reuni-ões de revisão; esforço em re-revisreuni-ões (novas reunireuni-ões de revisão realizadas devido a não aprovação do produto em reuniões anteriores); esforço em retra-balho.
Precisão da estimativa de esforço para todo o projeto;
Precisão da estimativa de esforço para as fases de análise, projeto, codifica-ção, teste de unidades, teste do sistema e teste para homologação;
Tamanho do sistema em número de linhas de código.
Número de erros na especificação de requisitos e no projeto do sistema encon-trados em reuniões de revisão; erros no código enconencon-trados no teste de unida-de feitos por analistas;
Número de modificações na especificação de requisitos, projeto ou código após a sua aprovação;
Densidade de defeitos, calculado pelo número de erros somado ao número de modificações em relação ao tamanho do sistema;
Rotatividade do pessoal definido como o percentual de pessoas que saíram, entraram ou mudaram de função durante o desenvolvimento do projeto.
Produtividade, correspondente ao número de linhas de código produzidas por unidade de esforço.
Deterioração do software, visto como a relação entre o esforço gasto para cor-rigir falhas encontradas após a liberação do sistema para o usuário comparado ao esforço gasto antes da liberação do software para o usuário.
Experiência da equipe na linguagem de programação, no domínio da aplicação, nas ferramentas, no método e no processo de desenvolvimento, tipo de treina-mento em engenharia de software, tempo total de experiência profissional.
Para Krieser (2010), dentre as métricas de qualidade de software, destacam-se o número de erros (bugs) por release, por caso de uso, por ponto por função e
e o ambiente (por exemplo, produção, testes ou homologação) em que ocorreram. Aumentos significativos de produtividade são obtidos quando se estabelece métricas para o processo e para os resultados do desenvolvimento de software.
Em relação às métricas temporais, Teixeira (2009) considera que o tempo ne-cessário para realizar uma tarefa de manutenção de software pode ser estimado com uma precisão aceitável. Modelos matemáticos preditivos podem auxiliar ao ge-rente na definição de preços competitivos para serviços, sem perda da qualidade dos produtos.
A medição é algo comum no mundo da engenharia. Mas, no caso da ES, não há ainda uma medição padrão amplamente aceita e com resultados isentos de fato-res subjetivos. Não há consenso sobre o que medir e como avaliar o fato-resultado das medições obtidas.
Diversas são as razões para se medir o software: (i) indicar a qualidade do
produto, (ii) avaliar a produtividade dos que desenvolvem o produto, (iii) determinar
os benefícios derivados de novos métodos e ferramentas de ES, (iv) formar uma
ba-se para as estimativas ou (v) ajudar na justificativa de aquisição de novas
ferramen-tas ou de treinamentos adicionais.
De acordo com a norma ISO/IEC 9126-1 (ISO, 2003), métricas de software podem ser categorizadas em métricas diretas e indiretas. O Quadro 1 mostra alguns exemplos de métricas diretas e indiretas.
Quadro 1 – Tipos de métricas
Métricas diretas Métricas indiretas
Custo Esforço Linhas de Código Velocidade de Execução
Memória Nº de Erros
Funcionalidade Qualidade Complexidade
Eficiência Confiabilidade Manutenibilidade
Fonte: ISO, 2003
Para Kaner e Bond (2004), as métricas de software podem ser classificadas como:
Métricas da produtividade, baseadas na saída do processo de desenvolvimento
Métricas da qualidade, que indicam o nível de resposta do software às
exigên-cias explícitas e implícitas do cliente;
Métricas técnicas, que consideram aspectos como funcionalidade,
modularida-de, manutenibilidamodularida-de, etc.
No entanto, a qualidade de um produto de software não depende exclusiva-mente da escolha apropriada de métricas. Por exemplo, a inadequação do produto pode ser fruto de objetivos mal estabelecidos. Além disso, as pessoas são sensíveis a fatores externos. O ambiente em que trabalham, as pressões a que estão sujeitas, ou a situação das relações familiares e pessoais podem influenciar a produtividade de seus componentes.
2.1.4 Teste de software
A qualidade de um produto de software está diretamente relacionada à quali-dade dos testes realizados. Teste de software é um processo que avalia a adequa-ção do produto às especificações previamente estabelecidas. Seu objetivo é revelar possíveis falhas e suas causas de forma que sirvam de subsídio para que a equipe de desenvolvimento faça os devidos ajustes antes da entrega final.
Para Melo (2010), o teste do software é uma das fases do processo de ES que visa atingir um nível de qualidade de produto superior. O objetivo, por paradoxal que pareça, é mesmo o de encontrar defeitos no produto, para que estes possam ser corrigidos pela equipe de analistas/programadores, antes da entrega final.
O conceito de teste de software pode ser compreendido através de uma visão intuitiva ou mesmo de uma maneira formal. Existem atualmente várias definições pa-ra esse conceito.
consiste em confirmar por testes e com provas objetivas que requisitos particulares para um determinado uso foram atendidos.
De uma forma simples, testar um software significa verificar através de uma execução controlada se o seu comportamento se dá de acordo com o especificado. O objetivo principal desta tarefa é encontrar o número máximo de erros dispondo do mínimo de esforço, ou seja, mostrar aos que desenvolvem se os resultados estão ou não de acordo com os padrões estabelecidos.
Atualmente existem muitas maneiras de se testar um software. Entre as técni-cas mais conhecidas estão:
Caixa-Branca, segundo a qual o desenvolvedor tem acesso ao código fonte da
aplicação e pode construir códigos para efetuar a ligação de bibliotecas e com-ponentes. Neste tipo de teste, analisa-se o código fonte e elabora-se casos de teste que cubram todas as possibilidades do programa. Dessa maneira, todas as variações originadas por estruturas de condições são testadas;
Caixa-Preta, na qual o desenvolvedor dos testes não tem acesso ao código
fonte do programa. O objetivo é efetuar operações sobre as diversas funciona-lidades e verificar se o resultado gerado por elas está de acordo com o espera-do. Para esta categoria, são considerados os eventos que podem ser ativados pelo usuário, como por exemplo, cada clique de mouse a ser realizado em uma interface;
Caixa-Cinza, onde o desenvolvedor dos testes não tem acesso ao código fonte
da aplicação, mas tem conhecimento dos algoritmos que foram implementados, como também pode efetuar manipulações em arquivos de entrada e saída ou mesmo acessar o banco de dados da aplicação para simples conferência de dados ou alteração de parâmetros considerados nos casos de teste;
Testes Alpha, Beta e Gama. No seu processo de desenvolvimento, os testes
disponbilizadas a grupos de usuários, na expectativa que eles encontrem defei-tos peculiares. A comunidade de teste de software usa o termo teste gama de forma sarcástica, referindo-se aos produtos que são mal testados e são entre-gues aos usuários finais para que estes encontrem os defeitos já em fase de produção.
Algumas categorias de testes são tidas como importantes para se obter quali-dade de software (MELO, 2010):
Testes de unidade, também conhecido como teste unitário, visam testar
pe-quenas partes ou unidades do sistema. O universo alvo desse tipo de teste são os métodos dos objetos ou mesmo pequenos trechos de código. Assim, o obje-tivo é o de encontrar falhas de funcionamento dentro de uma pequena parte do sistema funcionando independentemente do todo;
Testes de componente atingem o componente como um todo e não apenas as
suas funções ou métodos, ainda sem considerar a iteração com outras partes do sistema;
Testes de integração visam encontrar falhas provenientes da integração dos
componentes do sistema, geralmente relativas à troca de dados.
Testes de sistema visam explorar o sistema em sua plenitude. Dessa maneira,
os testes são executados nos mesmos ambientes, nas mesmas condições e com os mesmos dados que um usuário faria;
Testes de aceitação são realizados, em geral, por um grupo restrito de usuários
finais do sistema. São feitas simulações das operações de rotina do sistema de modo a verificar a conformidade de seu comportamento com as especificações.
2.2 DESCOBERTA DE CONHECIMENTO EM BANCOS DE DADOS
A descoberta de conhecimento em banco de dados - DCBD (KDD -
Knowled-ge Discovery in Database) refere-se ao processo global de busca por padrões úteis
em dados estruturados (bancos de dados) ou não estruturados (textos). A mineração de dados – MD (Data Mining) é uma das fases desse processo, no qual são
(inter-pretação formal dos resultados de mineração) asseguram sua efetividade. A depen-dência entre essas fases vem evoluindo desde a proposta pioneira de Fayyad et al. (1996). Segundo esse autor, o processo de DCBD compreende a seguinte sequên-cia de passos, conforme apresentada na Figura 1:
Figura 1 -Processo de descoberta de conhecimento
Fonte: FAYYAD et al, 1996.
(i) Definição do problema e objetivos: Definição do problema a ser resolvido por
meio do processo de DCBD. Desenvolver a compreensão do domínio da apli-cação, do conhecimento anterior relevante e dos objetivos do usuário final.
(ii) Seleção: Seleção ou segmentação dos dados apropriados para a análise de
acordo com algum critério. Separação de um conjunto-alvo de dados em que a prospecção deverá ser efetuada.
(iii) Pré-processamento: inclui operações básicas como remover ruídos ou
subca-madas, se necessário, coletando informação necessária para modelar, decidin-do estratégias para manusear (tratar) campos onde nota-se facilmente que não influenciam na solução das perguntas que se deseja responder;
(iv) Transformação: inclui encontrar formas práticas para se representar dados,
de-pendendo da meta do processo e o uso de redução dimensionável e métodos de transformação para reduzir o número efetivo de variáveis que deve ser le-vado em consideração; ou encontrar representações invariáveis para os dados.
(v) Mineração de Dados: Aplicação dos algoritmos para descoberta de padrões
(vi) Interpretação e Avaliação: Pode requerer a repetição de vários passos, mas
normalmente é encarada como uma simples visualização dos dados. Os pa-drões identificados pelo sistema são interpretados e consolidados em conheci-mento, que pode então ser utilizado para suportar a tomada de decisão huma-na.
2.2.1 CRISP-DM
Diversas propostas foram feitas visando o aprimoramento do processo de Fayyad para projetos de DCBD. Entre elas está o método CRISP-DM (
Cross-Industry Standard Process for Data Mining), segundo o qual um projeto de DCBD
pode ser realizado em seis fases interdependentes, de acordo com o fluxo mostrado na Figura 2:
Figura 2 –Fases do CRISP-DM
Fonte: CHAPMAN et al., 2000.
O entendimento do negócio tem por objetivo identificar as metas e os
requeri-mentos do projeto a partir de uma perspectiva de negócio;
características estruturais e á qualidade dos dados a serem usados;
Na preparação dos dados, é feita a extração, limpeza e transformação dos
da-dos de forma a adequá-los aos algoritmos de MD a serem utilizada-dos;
Durante a modelagem, o(s) algoritmo(s) de aprendizagem de máquina
selecio-nados são parametrizados e utilizados para a construção de modelos computa-cionais que refletem os padrões encontrados nos dados;
A avaliação verifica a pertinência do(s) modelo(s) gerados em relação às metas
e requerimentos definidos anteriormente;
Finalmente, é efetivada a aplicação do(s) modelo(s) gerado(s), na forma, por
exemplo, de sistemas de apoio à tomada de decisão.
2.2.2 Técnicas de Data Mining
Encontram-se na literatura diversos métodos ou algoritmos para a extração de padrões úteis de conjuntos de dados. Alguns desses métodos são: classificação, modelos de relacionamento entre variáveis, análise de agrupamento, sumarização, modelos de dependência, regras de associação e análise de séries temporais. A maioria desses métodos é oriunda das áreas de aprendizagem de máquina, reco-nhecimento de padrões e estatística. Sferra et al. (2003) descrevem esses métodos:
A classificação associa ou classifica um item a uma ou várias classes
categóri-cas pré-definidas. Uma técnica estatística apropriada para classificação é a análise discriminante. Os objetivos dessa técnica envolvem a descrição gráfica ou algébrica das características diferenciais das observações de várias popula-ções, além da classificação das observações em uma ou mais classes prede-terminadas. A ideia é derivar uma regra que possa ser usada para associar uma nova observação a uma classe previamente estabelecida;
Modelos de relacionamento entre variáveis associam uma variável,
denomina-da dependente, a uma ou mais variáveis consideradas independentes.
A análise de agrupamento (clustering) associa um item a uma ou várias classes
categóricas (ou clusters), em que as classes são determinadas pelos dados,
diversamente da classificação em que as classes são pré-definidas. Os agru-pamentos são definidos por meio do agrupamento de dados baseados em me-didas de similaridade ou modelos probabilísticos. A análise de agrupamento é uma técnica que visa detectar a existência de diferentes grupos dentro de um determinado conjunto de dados e, em caso de sua existência, determinar quais são eles;
A sumarização determina uma descrição compacta para um dado subconjunto.
As medidas de posição e variabilidade são exemplos simples de sumarização. Funções mais sofisticadas envolvem técnicas de visualização e a determinação de relações funcionais entre variáveis. As funções de sumarização são fre-quentemente usadas na análise exploratória de dados com geração automati-zada de relatórios, sendo responsáveis pela descrição compacta de um conjun-to de dados. É utilizada, principalmente, no pré-processamenconjun-to dos dados, quando valores inválidos são determinados por meio do cálculo de medidas es-tatísticas – como mínimo, máximo, média, moda, mediana e desvio padrão amostral –, no caso de variáveis quantitativas, e, no caso de variáveis categóri-cas, por meio da distribuição de frequência dos valores. Técnicas de sumariza-ção mais sofisticadas são chamadas de visualizasumariza-ção, tidas como de extrema importância, e muitas vezes imprescindíveis, para se obter um entendimento, por vezes intuitivo, do conjunto de dados. Exemplos de técnicas de visualiza-ção de dados incluem diagramas baseados em proporções, diagramas de dis-persão, histogramas e box plots;
Um modelo de dependência descreve dependências significativas entre
variá-veis. Modelos de dependência existem em dois níveis: estruturado e quantitati-vo. O nível estruturado especifica, geralmente em forma de gráfico, quais vari-áveis são localmente dependentes. O nível quantitativo especifica o grau de dependência usando alguma escala numérica;
Regras de associação determinam relações entre campos de um banco de
relação entre variáveis orienta análises, conclusões e evidenciação de achados da investigação. Uma regra de associação é assim definida:
SE X ENTÃO Y,
ou X Y, onde X e Y são conjuntos de itens e X ∩ Y = Ø. Diz-se que X é o an-tecedente da regra, enquanto Y é o seu consequente. Medidas estatísticas co-mo correlação e testes de hipóteses apropriadas revelam a frequência de uma regra no universo dos dados minerados;
A análise de séries temporais determina características sequenciais, como
da-dos com dependência no tempo. Seu objetivo é modelar o estado do processo extraindo e registrando desvios e tendências no tempo. Correlações entre dois instantes de tempo, ou seja, as observações de interesse, são obtidas em ins-tantes sucessivos de tempo – por exemplo, a cada hora, durante 24 horas – ou são registradas por algum equipamento de forma contínua, como um traçado eletrocardiográfico. As séries são compostas por quatro padrões: tendência, variações cíclicas, variações sazonais e variações irregulares. Há vários mode-los estatísticos que podem ser aplicados a essas situações, como os de re-gressão linear (simples e múltiplos), os lineares por transformação e regres-sões assintóticas, além de modelos com defasagem, como os auto-regressivos (AR) e outros deles derivados;
Previsão de situações. Além da análise de séries temporais, há situações em
que se quer predizer uma variável em função de outras (p. ex., o valor de um imóvel em função de suas características físicas e ambientais) ou efetuar pre-visões (p. ex., prever as vendas para o próximo mês), com base em modelos ou regras a serem construídos a partir de uma grande massa de dados, podem ser tratadas com a análise de regressão, os algoritmos em árvore de decisão ou as redes neurais com aprendizado supervisionado.
2.2.3 Algoritmos de regressão
de-senvolve uma fórmula matemática que se ajusta aos dados. Quando se têm dados prontos para usar e para prever o comportamento futuro, simplesmente pega-se os dados, aplica-se na fórmula desenvolvida e tem-se uma previsão. A principal limita-ção desta técnica é que ela só funciona bem com dados quantitativos (como veloci-dade, peso ou idade). Se os dados são categóricos, onde a ordem não é significativa (como nome, cor ou sexo), é mais indicada a escolha de outra técnica.
Regressão Linear
Os algoritmos para regressão linear ajustam um conjunto de dados a uma re-ta tendo por parâmetros as variáveis independentes. É claro que eventualmente os dados podem se apresentar de forma linear, mas mesmo nesses casos usamos ou-tras técnicas de regressão linear onde um dos eixos é achatado por meio de
poten-ciação, logaritmização ou exponenpoten-ciação, então temos regressão por potência, re-gressão logarítmica e rere-gressão exponencial.
A regressão linear consiste em representar um conjunto de dados cartesianos (xi, yi) da seguinte forma (FAYYAD et al, 1996):
i i xi
y (1)
onde yi é a ordenada (por ex., percentagem de uso da CPU), xi é a abscissa (por ex.,
data/hora da coleta de percentagem), α é o coeficiente linear calculado, β é o coefi-ciente angular calculado e εi é o erro ou desvio, utilizado como fator de correção.
Es-se desvio é a diferença entre a ordenada estimada e o valor real:
i
i
i y x
(2)
A ideia por traz da regressão linear é bastante simples: encontrar os valores para α e β tais que o somatório dos quadrados dos desvios para os valores conheci-dos seja o menor possível. Isso pode ser calculado usando-se o produto de matri-zes, mais especificamente, um sistema sub-determinado de equações normais. Nesse sistema, criou-se uma matriz normal 2×2, um vetor
de coeficientes de
1 0 1 0 1 0 2 1 0 1 0 ni i i n i i n i i n i i n i i y x y x x x n (4) RBFNetwork
Uma Radial Basis Function Network (RBF) é um outro tipo de rede neural três
camadas: a de entrada, oculta e camada de saída. Uma rede RBF pode construir dois modelos, de regressão e de classificação.
Em uma rede RBF, as entradas são mapeadas para cada uma das unidades escondidas. A rede RBF do WEKA utiliza a função gaussiana para cálculo do valor de ativação dos neurônios, sendo que a ativação h(x) de um neurônio escondido,
para uma dada entrada x, diminui monotonicamente com a distância entre o centro C da gaussiana.
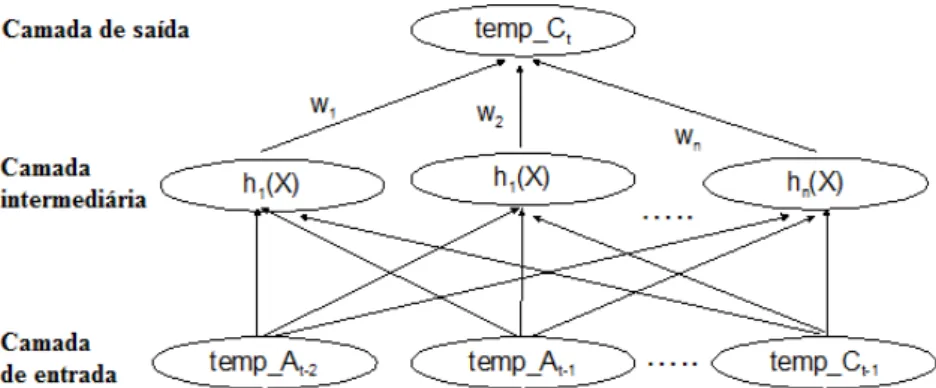
A camada de saída efetua uma combinação linear das saídas das unidades escondidas e é semelhante a um modelo de regressão. Na Figura 3, é apresentado um exemplo de rede RBF para um modelo de previsão de temperatura a partir do histórico de temperaturas.
Figura 3 – Exemplo de rede RBF [Uma rede RBF com n unidades escondidas
para prever temperatura.
Fonte: FAYYAD et al, 1996. X é o vetor de entrada dada à rede e de saída e temp_Ct é a
soma dos produtos das ativações das unidades ocultas e os pesos associados a elas. Cada unidade oculta tem seu próprio centro aprendido.
gaussi-ana. O ponto do espaço para a unidade escondida é obtido a partir do centro da gaussiana para essa unidade oculta. A largura da Gaussiana é um parâmetro de aprendizagem.
Uma rede RBF é treinada para aprender os centros e as larguras das funções Gaussianas para as unidades escondidas e, em seguida, ajustar os pesos no mode-lo de regressão que é usado na unidade de saída. Depois que os parâmetros para a função Gaussiana nas unidades ocultas forem encontrados, os pesos destas unida-des para a unidade de produção são ajustados utilizando Regressão Linear. O pro-cesso pode ser repetido para aprender de uma forma de aprendizado de máquina.
LeastMedSq
O LeastMedSquare WEKA ou algoritmo dos Mínimos Quadrados de Regres-são mediana é um método de regresRegres-são linear que minimiza a mediana dos quadra-dos das diferenças a partir da linha de regressão (WITTEN, 2005). O algoritmo re-quer atributos de entrada e de saída contínuos, e não permite que hajam valores fal-tantes de atributo. Um modelo de regressão linear é aplicada a atributos de entrada para prever a saída. A produção prevista x é obtida como
k j j j kka w a
w a w w 0 ) 1 ( ) 1 ( ) 1 ( 1 1 0 ... (5)
onde aisão atributos de entrada e wi são os pesos associados a eles.
Os pesos podem ser inicialmente definidos para valores aleatórios ou é atribu-ído um valor escalar. O objetivo do processo de atualização de peso é determinar novos pesos para minimizar
k j i j j ii a x w a
median 0 ) ( ) ( (6)
onde i varia de 1 até o número de casos nos dados de treinamento que está sendo
usado e x(i) é a saída real para o i-ésimo exemplo. O resultado previsto para essa
Redes MLP
Uma das redes neurais artificiais mais populares para regressão são as redes
Perceptron Multi-Camadas (MLP), treinadas com o algoritmo backpropagation. Este
é um algoritmo de aprendizado supervisionado, que utiliza pares (entrada, saída de-sejada) para ajustar os pesos da rede, através de um mecanismo de correção de er-ros. O treinamento ocorre em duas fases:
Forward: utilizada para definir a saída da rede para um dado padrão de
entra-da.
Backward: utiliza a saída desejada e a saída fornecida pela rede para atualizar
os pesos de suas conexões.
O algoritmo backpropagation, demonstrado no Quadro 3 é baseado na regra
delta proposta por Widrow e Hoff. As redes que utilizam backpropagation trabalham
com uma variação da regra delta, apropriada para redes multi-camadas: a regra del-ta generalizada. A regra deldel-ta generalizada funciona, quando são utilizadas na rede unidades com uma função de ativação semi-linear, que é uma função diferenciável e não decrescente. Uma função de ativação amplamente utilizada, nestes casos, é a função sigmóide. Essa variação foi a característica que permitiu a este e outros mo-delos fazer representações complexas. Os ajustes dos pesos serão realizados utili-zando o método do gradiente descendente.
O treinamento das redes MLP com backpropagation pode demandar muitos
passos no conjunto de treinamento, resultando um tempo de treinamento considera-velmente longo. Uma forma de amenizar este tipo de problema é considerar efeitos de segunda ordem para o gradiente decrescente. Também não é raro o algoritmo convergir para mínimos locais.
Mínimos locais são pontos na superfície de erro que apresentam uma solução estável, embora não seja a melhor solução. Algumas técnicas são utilizadas tanto para acelerar o algoritmo, como para reduzir a incidência de mínimos locais.
A adição do termo momentum é uma das técnicas mais frequentes para
As redes neurais que utilizam backpropagation (Quadro 3), assim como
mui-tos outros tipos de redes neurais artificiais, podem ser vistas como "caixas pretas", na qual quase não se sabe porque a rede chega a um determinado resultado, uma vez que os modelos não apresentam justificativas para suas respostas.
Quadro 3 – Algoritmo de backpropagation
Algoritmo Backpropagation
1. Iniciar pesos e parâmetros
2. Repetir até o erro ser mínimo ou a realização de um dado número de ciclos 2.1 Para cada padrão de treinamento X.
2.1.1 Definir a saída de rede através da fase foward
2.1.2 Comparar saídas produzidas com as saídas desejadas 2.1.3 Atualizar pesos dos nodos através da fase backward Fase Forward
1. A entrada é apresentada à primeira camada da rede C0 2. Para cada camada (Ci) a partir da camada de entrada
2.1 Após os nodos da camada Ci (i > 0) calcularem seus sinais de saída, estes servirão como entrada para a definição das saídas produzidas pelos nodos da camada (Ci+1)
3. As saídas produzidas pelos nodos da última camada são comparadas às saídas desejadas. Fase Backward
1. A partir da última camada, até chegar na camada de entrada:
1.1 Os nodos da camada atual ajustam seus pesos de forma a reduzir seus erros
1.2 O erro de um nodo das camadas intermediárias é calculado utilizando o erro do nodos da camada seguinte conectados a ele, ponderados pelos pesos das conexões entre eles.
Fonte: WITTEN, 2005.
Estudos vêm sendo realizadas visando a extração de conhecimento de redes neurais artificiais, e na criação de procedimentos explicativos, onde se tenta justificar o comportamento da rede em determinadas situações.
SMOREG
SMOReg é uma implementação do algoritmo de otimização sequencial mí-nima (SMO) para treinamento de um modelo de regressão de vetor de suporte (SVM
– Máquinas de Vetor de Suporte). Esta implementação substitui globalmente todos os valores faltantes e transforma atributos nominais em atributos binários (WITTEN, 2005).
de cada classe a esse hiperplano. A distancia de uma classe a um hiperplano e a menor distancia entre ele e os pontos dessa classe é chamada de margem de sepa-ração. O hiperplano gerado pela SVM é determinado pelo subconjunto dos pontos das duas classes, chamado vetores de suporte.
3 METODOLOGIA
3.1 CLASSIFICAÇÃO DA PESQUISA
Para Silva e Menezes (2005), uma pesquisa científica pode ser classificada quanto à natureza, abordagem, fins e meios. Assim, esta pesquisa é: (i) aplicada,
quanto à natureza, pois gera produtos ou processos com finalidades imediatas na empresa alvo; (ii)quantitativa, quanto à abordagem, por se fundamentar em uma
co-leta e análise de dados que permitem medir, analisar e modelar um fenômeno; (iii) exploratória, quanto aos fins, uma vez que visa proporcionar maior familiaridade com
o problema com vistas a torná-lo explícito ou a construir hipóteses; (iv) quanto aos
meios, é um estudo de caso, visto que envolve o estudo profundo e exaustivo de um
ou poucos objetos de maneira que se permita ampliar e detalhar o conhecimento.
3.2 POPULAÇÃO E AMOSTRA
Para a realização deste trabalho, foram utilizados dados dos projetos de de-senvolvimento e manutenção de software de uma empresa de dede-senvolvimento de soluções em Tecnologia da Informação, para se aferir a qualidade dos produtos de-senvolvidos por esta empresa. O universo considerado para o estudo de caso é constituído de três bases de dados em SQL, uma de cada sistema envolvido: (i) o
Sistema Gerencial de Informações (SGI), (ii) o Sistema de Rastreamento de Defeitos
(Mantis) e (ii) o Sistema de Controle de Revisões de Qualidade (Revisa). Essas
ba-ses vêem sendo atualizadas pelas equipes de desenvolvimento e manutenção de software da empresa alvo desde 2004.
corretiva ou adaptativa ou extrações de relatórios especiais, não estão aí incluídos. Na Tabela 1 é apresentado um resumo dessa quantificação.
Tabela 1 – Quantificação dos projetos considerados
Tipo de projeto Quantidade de projetos %
Desenvolvimento 150 82,1
Manutenções perfectivas 20 10,9
Não identificados 13 7,0
Total 183 100,0
Entre as diversas variáveis coletadas, considerou-se para este trabalho aque-las que supostamente poderiam influenciar a qualidade de um produto.
3.3 COLETA DE DADOS
O sistema SGI é o sistema de gerenciamento de projetos da empresa conce-bido para o gestor de projeto controlar o projeto de software e recursos durante to-das as suas fases. Esse sistema foi desenvolvido em Asp.net, com banco de dados SQL Server.
O Sistema Mantis é um sistema multiplataforma baseado em web, de código aberto e livre (licença GNU), para rastreamento de bugs. Foi desenvolvido em PHP
e funciona com MySQL, MS SQL, e PostgreSQL. Quase todos os navegadores da Web são capazes de funcionar como um cliente desse sistema.
Revisa é um sistema que permite a gestão, registro, formalização e acompa-nhamento de informações das revisões de qualidade referentes aos projetos de sof-tware. Essas atividades são executadas pelos consultores de garantia da qualidade de software (GQS) da Empresa. Foi desenvolvido em plataforma Web, em Asp e com SQL Server, na forma de workflow, enviando mensagens aos envolvidos ao
término de operações ou transações executadas durante o processo de revisão. Desta forma, assegura uma comunicação eficiente entre o consultor de GQS e o lí-der de projeto (gerente do projeto). Esse sistema efetua o controle automático dos prazos estabelecidos para o tratamento de não-conformidades, acionando os níveis superiores de gerência quando expirado o prazo acordado. Possibilita ainda a con-solidação de estatísticas e métricas de GQS em todos os níveis da organização.
de infraestrutura. Foram feitas apurações e extrações sistematizadas em arquivos texto, nos três sistemas de gestão da Empresa citados. Houve negociações com as áreas internas da Empresa no sentido de se obter as permissões de utilização das bases de dados.
Após a extração, foi feita uma análise de dados, de acordo com o CRISP-DM. Os dados foram, então, unificados e tabulados em uma planilha eletrônica, e expor-tados para o formato compatível com o WEKA (http://www.cs.waikato.ac.nz/ml/ weka), ferramenta de mineração de dados utilizada. Com o apoio de seus recursos estatísticos e gráficos e seguindo o CRISP-DM, foram feitas uma analise e uma dis-cussão dos resultados.
3.4 O ESTUDO REALIZADO
O processo de descoberta de conhecimento realizado serviu-se de dados re-lativos à execução do processo de ES nos projetos de desenvolvimento da Empre-sa. Partiu-se do pressuposto de que a qualidade intrínseca de um produto pode ser aferida pela densidade de defeito do software nas suas diversas fases – testes, ho-mologação e pós-implantação (KRIESER, 2010).
Neste estudo, buscou-se construir modelos2 de qualidade com base em
in-formações previamente cadastradas. Para isso, foram estudadas 3 variáveis esco-lhidas previamente como variáveis dependentes, as quais materializam os atributos de alto nível representantes da qualidade do produto: a qualidade intrínseca de um software. Estas variáveis foram: (i) a densidade de defeitos na fase de testes, (ii) a
densidade de defeitos na fase de homologação e (iii) a quantidade de manutenções