This Master's thesis describes the two-level model, which is one way of doing morphological analysis. The thesis synthesizes the theoretical background in formal languages and equal length relations and uses it to formally describe the two-level model. Key words and phrases: computational morphology, two-level model, same-length ratio, morphological analysis, determination.
Overview
The second stage, called part-of-speech marking, is aimed at identifying word classes. Words are the leaf nodes of the parse tree, while internal nodes represent different syntactic structures. In highly inflected languages like Finnish, morphological analysis also distinguishes parts of speech for most words.
Informal Description of the Two-Level Model
- Language Model in Two-Level Morphology
- The Deep Form and the Surface Form
- Two-Level Rules
- Rules and Transducers
- Lexicon and Feasible Pairs
- Parsing in Action
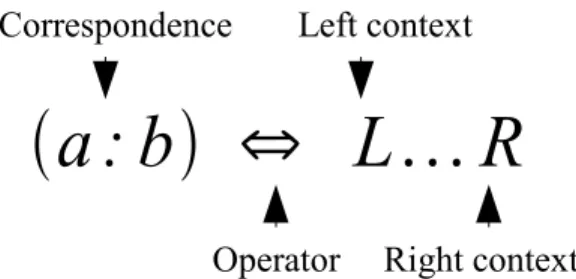
For each character in the surface form, there is a unique counterpart in the deep form. The rules define the correspondence between the characters in the surface form and the deep form. The double circles indicate that both states are final states - the rejection is handled by stopping.

Formal Language Machinery
- Basic Notations
- Regular Expressions and Regular Relations
- Finite State Machines and Transducers
- Same-Length Languages
The only difference between the definitions of regular relations and regular expressions is the alphabet in which we operate: when the state machine definition talks about , the transducer definition talks about. If the root is the concatenation of the subrelations accepted by the transducers T1 and T2, we build a transducer where all paths from the initial state to an end state pass through both T1 and T2. The set of final states for the new transducer is the set of final states for T2.

Two-Level Rules and Their Application
The Rules
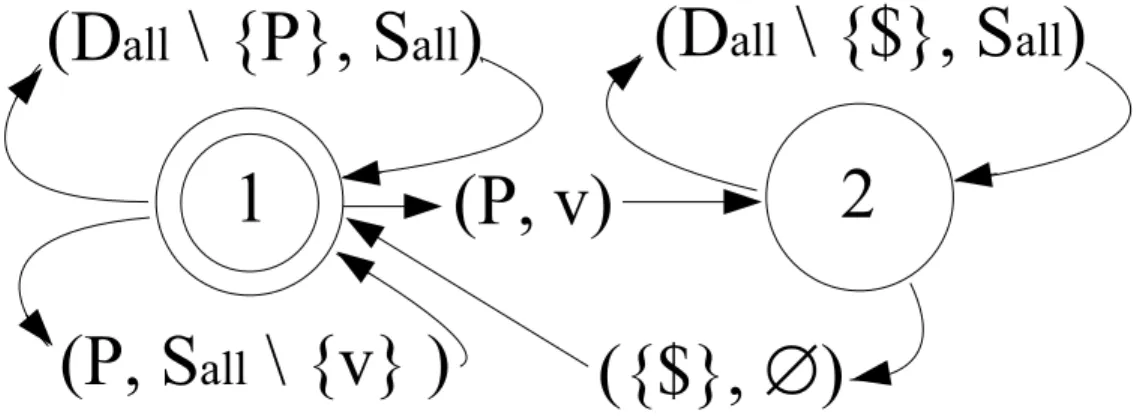
A two-level rule {d}, S,Contexts coercively allows a word w , if the deep form character d always realizes in the surface as some s∈S in the given context. To be formal, for every partitioning P=Left ,d , x, Right matching contexts, it holds that x∈S. The rule trivially allows all words where either d is not present in the deep form or no partitioning matches any context in contexts.
Note that if there are two context constraint rules concerning the same pair, it is enough that one of them w. In mathematical notation, this compound rule would be expressed as a set of 8 rules, enforced both as context constraint rules and as surface constraint rules. Now we see why sets of context restriction rules should be treated with "accept one rule, accept all rules" policy.
A two-level grammar CR, SC consists of a set CR of context constraint rules, and a set SC of surface constraint rules. A two-level grammar CR , SC allows a word w, if w is a concatenation of feasible pairs, CR allows w contextually, and SC allows w imperatively. Ritchie's [1992] definition of feasible pairs also included any pairs mentioned in the context sets of the rules, but there are practical reasons not to do so.
Third, the correspondence part of a two-level rule in his definition was just a pair, rather than a set of pairs, making rules like P : pv⇐ impossible.
Rules as Transducers
Make a list of possible pairs where the surface character is c , or the surface character is empty. A lexicon transition is possible if the transition condition is the deep character of a possible pair listed in 3. Push (1) the lexicon acceptor state, (2) the rule transducer states, and (3) the input pointer onto the stack.
If the input is complete and a new character could not be read, check if all transducers are in a final state. Note that we don't know if the next input character is 'really' a null character or the naive c we read from the string.
Compiling the Rules
- Previous Compilation Algorithms
- Compiling Context Restriction Rules
- Compiling Single Rules
- Compiling Batch Rules
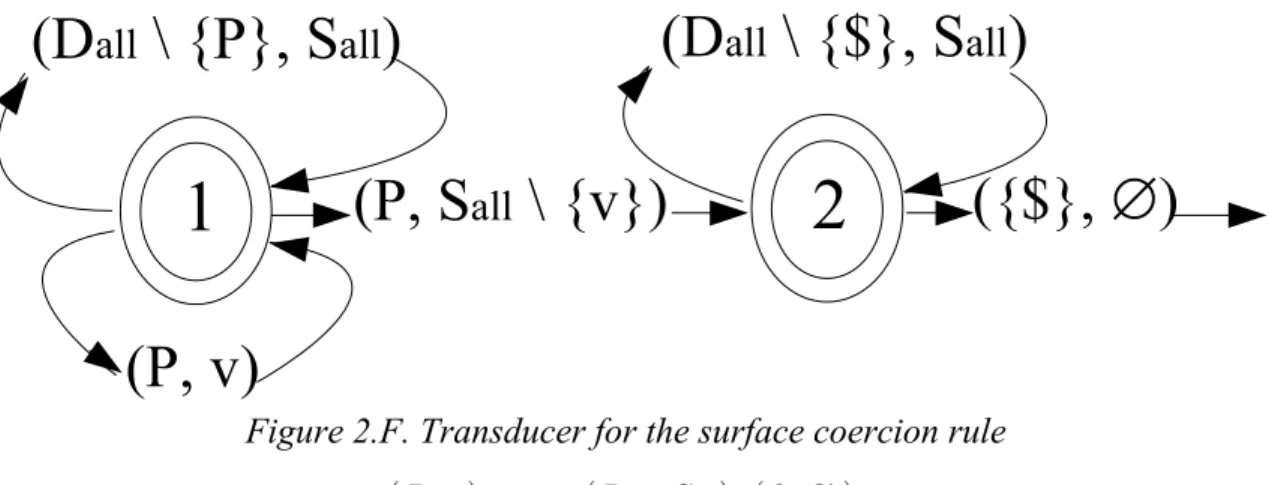
- Compiling Surface Coercion Rules
- Implementing the Algorithms
It accepts the input if the start does not match the left regular ratio, or the start matches the left ratio and the end matches the right ratio. When you notice a 'restricted' correspondence, make sure it has a legal context on the left and right. First, we prove that a single rule with a left and a right context can be split into two simpler rules: One that includes only the left context, and another that includes only the right context.
A context constraint rule d :S⇒LR corresponds to two separate rules, one containing only the left context and the other containing only the right context. We already know how to reduce the IfRightThenLeft operator to basic operations in two languages that we can compute, so this completes the compilation of the left subrule. Splitting the lines into the left subrule and the right requires some preparation, as we don't want to allow Lid , SRj where i≠j.
Our solution is to first split the k original rules into n subrules where the left contexts do not intersect. When the left context of this element ∗L, R is subtracted from itself, the result is an empty language and the rule ∗L, R is removed from the raw. IntersectionLanguage is used as the left context of all new rules, and since it is subtracted from existing rules, they cannot intersect with it.
Since the left contexts do not intersect, only one of them is triggered for each occurrence of c∈d , S in a word.
The Lexicon
Continuation Classes
The lexicon is a 5-tuple ,T, Classes, Root, End, where Classes is a set of continuation classes, where stems belong to ∗, and labels are strings in T∗. The non-alphabetic "+" sign marks the boundary between the root and the lowercase suffix and is required for some rules. It is useful to start and end a word with a special character, as some rules must refer to the beginning or end of the word.

The Deep Form State Machines
The only difference from the deep form acceptor is that the transducer accepts pairs instead of characters. We can modify the algorithm to produce a transducer that maps between the deep shape and tags. The change in algorithm 6.I is limited to the part where we create the transition chain for a stem.
When deep shapes are produced from tags, by the time the transducer reads a tag, it must have gone through a long chain of half-idle transitions that produce the correct deep shape. We have said that rules can be considered as filters that allow or deny certain correspondences between deep form and surface form. The role of the deep surface transducer is to generate raw data that is filtered according to rules.
Output: A same-length converter M=Q ,,,, q0, F that converts between the deep form defined by L and the surface form. In Chapter 2, we ran the rules and the lexicon converter separately for reasons of conceptual clarity. Now we see that both the surface-deep transducer and the rules are the same length transducers.
Running transducers in parallel and rejecting the input when one of the transducers rejects it gives the same result as cutting the separate transducers into one transducer and using it to convert between the deep shape and the surface shape.

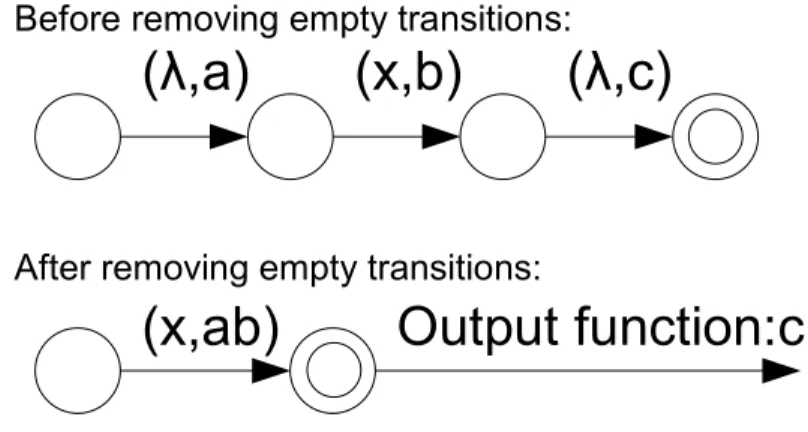
Removing Semiempty Transitions
Q is the set of states, q0 is the initial state and F is the set of final states,. Note that the input condition is always a single character or an empty transition while the output is a string. If the transduction stops at a final state q∈F, the output results of the function output∈q are written to the output bar.
Note that the output function can always be replaced by a set of semi-empty transitions q ,, output , q. A regular array is split into two separate word arrays depending on which alphabet we choose to be the input alphabet. Once an algorithm modifies the transducer word to have some output letters in a transition, it is no longer possible to use the transducer in both directions.
Therefore, the common surface-deep transducer is divided into two word transducers: surface-to-deep and deep-to-surface. The algorithm does not always terminate: for example, if a state q contains an empty input transition to itself. But if Input2 in tnew is empty, the iteration does not change the number of empty input transitions.
Input Determinization
The Determinization Algorithm
Only when the start state is also an end state is it impossible to use a sequential transducer instead. The basic idea is to write the output only when we know what to write. In this algorithm, the states of the resulting transducer are sets of q , String pairs, where q∈Q and String∈O∗ is a possible unwritten output.
Not all transducers can be deterministic, and sometimes deterministic transducers are much larger than non-deterministic ones. Let StateHash be a hash table that maps between superstates and the resulting transducer states: If x is a superstate, then StateHashx∈Q. That is, if there is at least one final substate, then the superstate also becomes final.
Problems with Determinization
Suppose we create a surface-tag converter that includes the word "married" and define it. But if we add a clitic to the word "varattu", the end of the clitic must have two different interpretations, since only final states can handle ambiguity. For this reason, the determiner makes a dedicated copy of the states and transitions representing the clitics, so that both interpretations can be output at the end.
Representing the clitics requires many more states and transitions than representing the core word "varattu". Therefore, determination increases the size of the transducer, because you have to make special copies of bending outputs. There are also other features in Finnish grammar that have the same effect as clitics.
The other problem is caused by the fact that adding a word can add an infinite amount of word-forms due to the mechanism of compound words. This is evident in table 6.B, where strings ending with @ have the continuation class "stem", which refers to the table where new words begin. The consequence is that adding a new word adds an infinite amount of compound word-forms.
The deterministic algorithm is unable to push them to the final states since the number of required final states is infinite.
The Effects of Determinization on Size and Performance
Test Software and Data
Determinization and the Size of the Transducer
Determinization and Parsing Performance
7776 transitions Could not calculate Table 8.B The effect of Brzozowski minimization style transformation on the size of the .
Conclusions
Brodda and Karlsson, 1981] Ben Brodda and Fred Karlsson, An Experiment with Automatic Morphological Analysis of Finland. Koskenniemi, 1983] Kimmo Koskenniemi, Two-level morphology: A general computational model for word form recognition and production. Mohri, 1996] Mehryar Mohri, On some applications of finite state automata theory to natural language processing.
Notation Sheet
Sample of the Lexicon Format