The state of the art in text quality assessment and online text filtering is described to illustrate current interdisciplinary research trends in online texts. The chapter begins with "web science" concepts such as the definition of web crawling and an overview of its limitations.
Prologue: “A model of Universal Nature made private" – Garden design and text collections
Chinese gardens are designed to be seen from within, from the buildings, galleries and pavilions at the center of the garden. According to Chevalier (1997), the image of the herbarium exemplifies the French theoretical, abstract view of linguistics.
Introductory definitions and typology: corpus, corpus design and textdesign and text
What “computational" is to linguistics
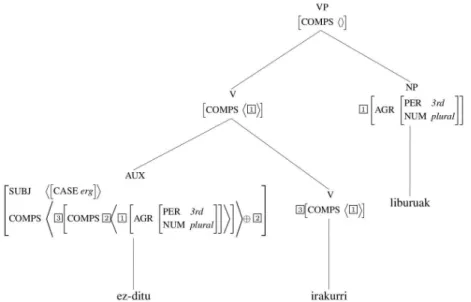
Since my thesis touches on this equation in two places, I will come back to this image in the course of the work. However, one of the points I want to emphasize in this thesis is that these issues are actually crucial, as they influence further linguistic research on corpora.
What theory and field are to linguistics
From the perspective of the philosopher of technology Gilbert Hottois, one can add a sub-tendency on the theory side, the notion of operability. The above distinctions may seem too clear, and the description by Hottois is somewhat far-fetched, since generative grammar can be seen as an heir to the linguistics of the 1930s, which pays attention to field observation.
Why use a corpus? How is it defined? How is it built?
In fact, the traditional way of looking at a corpus is that it is "not just a collection of texts". Although the word "category" may seem obvious in some cases, such as in the difference between a newspaper article and an instruction manual, linguistic variation "in the real world".

Corpus design history: From copy typists to web data (1959-today)(1959-today)
Possible periodizations
Dependent topic information could be useful for all purposes, but it is difficult to piece together based on so many unknowns. Furthermore, it is certainly a fact that the amount of text available for linguistic analysis is ever-increasing, so that Leech (2006) refers to linguists as “inhabiting an expanding universe”.
Copy typists, first electronic corpora and establishment of a scientific methodology (1959-1980s)scientific methodology (1959-1980s)
Consequently, the fact that examples or statistics extracted from the corpus are scientifically valid must be beyond doubt. A corpus is a collection of pieces of language selected and ordered according to explicit linguistic criteria to be used as a sample of the language."
Digitized text and emergence of corpus linguistics, between technological evolutions and cross-breeding with NLP (from thetechnological evolutions and cross-breeding with NLP (from the
Corpus is often said to be the equivalent of the telescope in the history of astronomy. There is an oppositional aspect in the definition of the discipline, based on a legitimizing discourse that has proven to be productive.
Enter web data: porosity of the notion of corpus, and opportunism (from the late 1990s onwards)(from the late 1990s onwards)
According to (boyd & Crawford, 2012), the real nature of the big data paradigm is counter-intuitive, as it is not about size itself, but about a whole dispositive around the data:. The proponents of larger corpora can argue, for example, that "size will automatically sort out all questions of 'balance' in the structure of the data.".
Web native corpora – Continuities and changes
Corpus linguistics methodology
Depending on the composition of the corpus, but also because of the existing different definitions of corpus, a very large corpus of the web can be considered an opportunistic and thus specialized corpus or a general purpose corpus. Importance of Web data for languages with fewer resources There is broad consensus among researchers that the Web corpora is a relevant way to build new resources, in a context where “the first half century of research in computational linguistics – from c. 1960 to present - covers less than 1% of the world's languages".

From content oversight to suitable processing: Known problems
In other words, this is what Bergh and Zanchetta (2008) called “the heterogeneous and somewhat intractable character of the web” (p. 310). Lack of metadata is also a potential problem with BNC (see page 27).
Intermediate conclusions
Changes in corpus design and construction
Usually, web corpus construction is concerned with retrieving full texts, but due to the nature of HTML documents and the necessary post-processing (see next chapter), they may be built from fragments that are artifacts of the text type and processing tools, and thus differ from the traditional meaning of "excerpt". A given corpus can be expanded regularly and thus corresponds to the concept of a monitor corpus.
Challenges addressed in the following sections
Software limitations can now be considered secondary, as well as text availability, as it is the very condition of text inclusion. In most cases, despite or because of convenience, it is not the proper construction of the body, ie.
Introduction
Text quality assessment, an example of interdisciplinary research on web textsresearch on web texts
Underestimated flaws and recent advances in discovering them
Machine-translated content The amount of machine-translated content on the web varies by language. Still according to Rarrick et al. 2011), the amount of machine-translated content on the web increases significantly for languages with lower density such as Latvian, Lithuanian and Romanian.
Tackling the problems: General state of the art
Criteria usually include measurements at or below token level, such as number of characters and tokens (with subsequent ratios between both sides of aligned texts), tokens beyond vocabulary, font features (e.g. ratio of Latin or Cyrillic script). , and the number of tokens that have a direct match on the other (Rarrick et al., 2011). Extreme values for certain metrics are potential indicators of problematic/noisy objects that require closer inspection" (Biemann et al., 2013, p. 36).
From text quality to readability and back
Extent of the research field: readability, complexity, comprehensibility
In readability research, only the last meaning of the word is considered [...] Difficulty of the text can be understood as a synonym for readability. For example, one of the requirements is to go deeper into the simulation of reading mode, for example by integrating features at the discourse level.
State of the art of different widespread approaches
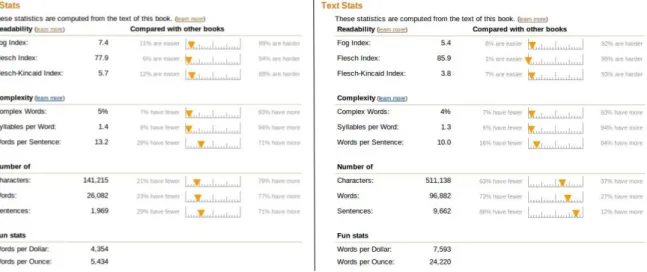
Approach and Indicators Used by Amazon.com to Classify Books Readability formulas such as the Fog Index, the Flesch Index, and the Flesch-Kincaid Index, are apparently used by Amazon: they are listed and explained in their help with text readability.6 The formulas focus on word length and sentence length, which is useful but not always appropriate. In a further example, the user-tracking machine can distinguish a certain specialty of the user, for example the user is a marine biologist or an avid cyclist.
Common denominator of current methods
Despite the apparent variety of readability formulas, all of these measures are based on, or highly correlated with, two variables: word frequency or familiarity, and sentence length.” (McNamara, Louwerse, McCarthy,. Despite the apparent variety of readability formulas, all of these measures are based on two variables or are highly correlated with: word frequency or familiarity and sentence length.” (McNamara et al., 2010, p. 3).
Lessons to learn and possible application scenarios
Their feature selection process divides the number of features used for the calculation by a factor of 10. The authors give no hint about a possible different nature of web texts.
Text visualization, an example of corpus processing for digital humanistsdigital humanists
Advantages of visualization techniques and examples of global and local visualizationslocal visualizations
It uses some of the traits collected in readability studies, from character to discourse level, and also uses a similar method of selecting traits based on statistical significance. The horizontal bars on this graph represent the sentences of the article, so that a relevant criterion immediately stands out: the evolution of the sentence length in the text becomes clear.
Visualization of corpora
A great many of the visualization methods applied to text are derived from analytical quantitative methods originally borrowed from the sciences. Faced with a lot of features, it can be difficult to catch a glimpse of the big picture without a proper visualization of the processes at play.
Conclusions on current research trends
Summary
Using appropriate annotation levels or indicators, a tool can provide insight into the nature, structure, and texture of texts. This may allow for a retraining that would suit other purposes, even if the opposite, such as an analysis of Internet spam, or more precisely, such as building a subcorpus for a specialized issue.
A gap to bridge between quantitative analysis and (corpus) linguisticslinguistics
The methodological insights from other disciplines show that there are decisions during web corpus building that are not made by humans, in contrast to the careful selection of texts in traditional reference corpora. Achievements used in the following chapters Some of the methodological insights and achievements described in this chapter are applied in chapter 4, with work on web corpus construction and evaluation of the collected material.
Introduction
Structure of the Web and definition of web crawling
In other words, the global shape of the web graph is probably not random, there are sites that benefit from interconnection far more than others, and many examples where connections only go in one direction. It includes a conceptual effort, a theoretical framework, and massive datasets of measurements to give scientists an indirect idea of the characteristics of their universe.
Data collection: how is web document retrieval done and which challenges arise?
- Introduction
- Finding URL sources: Known advantages and difficulties
- In the civilized world: “Restricted retrieval"
- Into the wild: Web crawling
- Finding a vaguely defined needle in a haystack: targeting small, partly unknown fractions of the webpartly unknown fractions of the web
The practical drawbacks of the evolution towards "Web 2.0" (a term commonly applied to increasingly dynamic websites) are twofold. This strategy leads to a comprehensive collection of local connected subcomponents of the web graph.
An underestimated step: Preprocessing
Introduction
Finally, is it possible to get a reasonable picture of the output in terms of text quality and variety. It also involves dealing with the potentially extreme variability of content and consequently requires the adaptation of crawling strategies.
Description and discussion of salient preprocessing steps
These issues are not trivial, as they contribute to the reign of the unpredictable in the corpus construction process. Several approaches have been developed to deal with the exponentially growing difficulty of the task as web document collections grow.
Impact on research results
Even from a statistical point of view, access to the corpus is far from immediate, due to the mix of research objectives and processing issues described above. There are diverse notions of 'corpus quality' (and consequently 'noise'), depending on the intended use of the corpus.
Conclusive remarks and open questions
Remarks on current research practice
Given the breadth of the web and its inherent multi-user (social) nature, its science is necessarily interdisciplinary, involving at least mathematics, CS [computer science], artificial intelligence, sociology, psychology, biology, and economics. These changes are combined with an evolving web document structure and a slow but inexorable shift from "web as corpus" to.
Existing problems and solutions
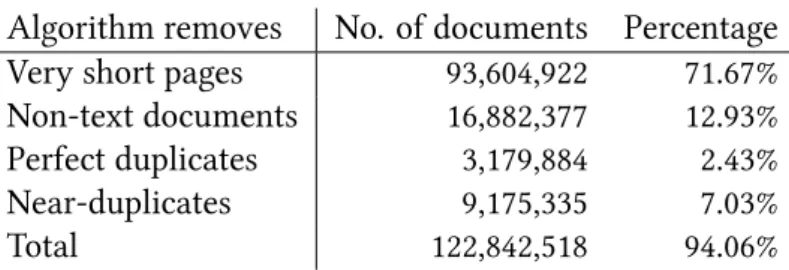
Once the web documents are saved, up to 94% of the downloaded and saved web documents are deleted during pre-processing (Schäfer & Bildhauer, 2013). They are known to be interesting, but are beyond the scope of this work.
Introduction: qualification steps and challenges
Hypotheses
These results can be used to qualify texts collected on the web, which are marked on this basis. Corpora collected on the web can be compared with existing reference corpora, as well as with each other, for quality assessment as well as for typological purposes.
Concrete issues
As Loiseau (2008) explains, automatic classification is not a goal in itself, the most important thing is to take a stand on textual typology in order to arrive at an adequate description.3 4.1.1.2 The usefulness of the results of readability studies for filtering and qualification. In fact, due to the size of corpora, a significant portion of their content is usually unreadable or even skimmed over.
Prequalification of web documents
Prequalification: Finding viable seed URLs for web corpora
Since this is a breadth-first approach, its applicability largely depends on the size of the network. The metadata collected in the studies can be used to draw a partial view of the observed network.

Impact of prequalification on (focused) web crawling and web corpus samplingcorpus sampling
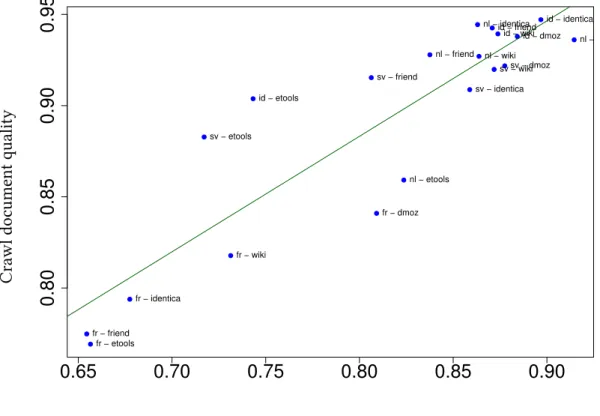
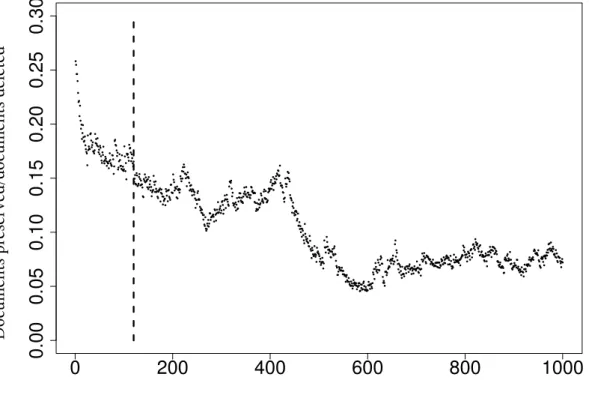
We randomly sampled 1,000 seed URLs for each of 20 permutations of seed sources and languages/TLDs, downloaded them, and used texrex to determine the document-to-document return ratio for the 1,000 seeds. Results Figure 4.3 illustrates that there is a strong correlation (adjusted R) between the yield ratio of documents for seed URLs and the yield ratio of documents found using BFS crawling seeds.
Restricted retrieval
It is then impossible to return to a "raw" version of the acquired web pages The duplication of the articles (see below) as well as the existence of almost duplicate documents are symptomatic of the erratic decisions made by the editors, leading for example to the parallel existence of online and printed versions on the website of Die Zeitin 2008.