Modélisation de l'inexactitude et de l'incertitude des données dans les plateformes de crowdsourcing. Nous commençons ce rapport par la présentation de l’IRISA et de l’équipe Druid dans la section 2.
L’IRISA
Dans cette section, d'une part l'IRISA est présentée, puis d'autre part l'équipe de recherche DRUID, enfin la dernière partie de cette section est consacrée à la responsabilité sociétale, aux normes d'entreprise (RSE).
L’´ equipe DRUID
De plus, les tâches évolueraient en fonction des réponses des utilisateurs, par exemple si une tâche consiste à fournir des informations sur la biographie de l'actrice Natalie Portman, le nombre de films dans lesquels elle a joué. Si le contributeur répond avec un nombre de films différent, la plateforme lui demandera d'en savoir plus sur la filmographie de l'actrice.
RSE de l’IRISA et implication de l’´ equipe
Les droits de propriété intellectuelle (brevet, droit d'auteur, etc.) sont respectés par tous les membres de l'IRISA dans le cadre des activités de recherche. De plus, le contributeur se voit offrir un bonus pour susciter de l'intérêt pour la tâche.
Principales probl´ ematiques associ´ ees au domaine
- La motivation de la foule
- La qualit´ e des r´ eponses
- La carcat´ erisation de la foule
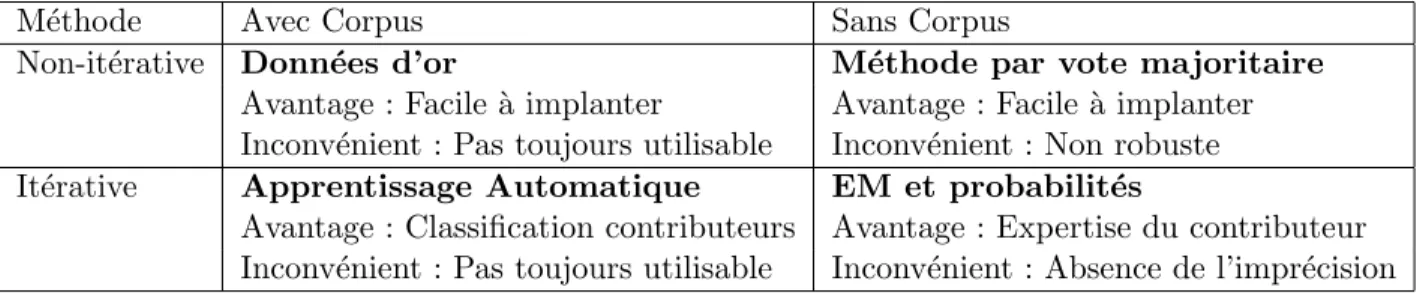
- Donn´ ees d’or
- Apprentissage automatique
- M´ ethode par vote majoritaire
- Probabilit´ e et algorithme EM
C'est pourquoi nous nous concentrons sur deux autres problématiques principales qui sont l'identification des données pertinentes et la caractérisation de la foule dans les plateformes d'activités courantes. Les articles [2, 3] développent l'apport du machine learning dans le contexte du crowdsourcing afin de distinguer les contributeurs « inconscients » du reste de la foule.
La th´ eorie des fonctions de croyance
L'opérateur de combinaison conjonctive de Yager [21] donné par l'équation (6) est intéressant car il permet de rester dans un monde fermé en interprétant la mesure de l'ensemble vide comme « ignorant ». Lorsque l'information provient de plusieurs trames distinctes Ω et Θ que l'on souhaite combiner, on effectue un développement à vide sur ces trames avant de combiner. De même, en considérant le produit cartésien Ω×Θ, on peut se projeter dans le référentiel différence Θ (respectivement Ω) en effectuant une marginalisation de la fonction de masse issue de la combinaison.
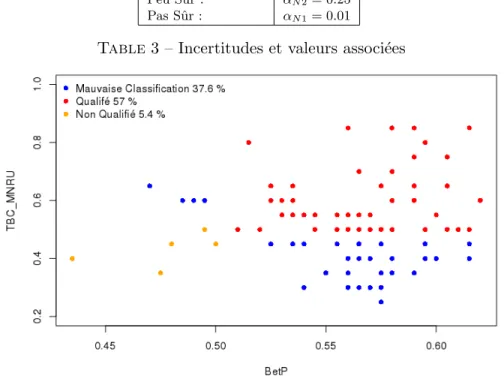
Pour prendre une décision sur les éléments du cadre de discrimination Ω, nous considérons l'élément focal ωi∈Ω pour lequel nous obtenons la probabilité pignistique maximale betP. L'utilisation de cette théorie dans le cadre du crowdsourcing est intéressante car elle permet de modéliser l'incertitude et l'imprécision des réponses d'un contributeur ainsi que la fusion des données résultantes de tous les contributeurs considérés comme sources d'information. Après avoir introduit les fonctions de croyance, nous discutons dans la section suivante de leur utilisation dans le contexte du crowdsourcing.
Fonctions de croyance et crowdsourcing
- Apport de la th´ eorie des fonctions de croyance
- Fonctions de croyance en pr´ esence de donn´ ees d’or
- L’impr´ ecision du contributeur
- Un degr´ e d’expertise pour caract´ eriser le contributeur
D’où l’intérêt d’utiliser des fonctions de croyance pour traduire certaines expertises en crowdsourcing. Ces fonctions permettent une bonne modélisation de l'incertitude et de l'imprécision des données. L’absence de réponse à une question ne pose pas de problème dans le cadre de l’utilisation de la théorie des fonctions de croyance du fait de la modélisation de l’ignorance, contrairement à l’utilisation du mode de vote ou l’absence de réponse est pénalisante.
Cependant, il n'est pas toujours possible de disposer de ces corpus, nous nous intéressons donc à modéliser la qualité des contributions et l'expertise des contributeurs en l'absence de corpus de référence. Il a été observé dans l'état de l'art qu'en l'absence de corpus de référence il est bon de laisser au contributeur la possibilité de se tromper dans ses réponses, aussi cette imprécision a été prise en compte dans notre modélisation. Puis, dans un deuxième temps, la modélisation de l'expertise du contributeur est abordée, en prenant en compte les connaissances et le comportement de ce dernier.
![Figure 1 – Graphique extrait de l’article [1] : Nombre moyen de r´ eponse correct en fonction du nombre d’´ el´ ements focaux](https://thumb-eu.123doks.com/thumbv2/1bibliocom/467154.71725/21.918.158.744.121.401/figure-graphique-extrait-article-nombre-eponse-correct-fonction.webp)
Mod´ elisation du profile du contributeur
Connaissance
Comportement
Supposons qu'un élément g dans l'annexe à la page 36 soit défini par le pseudocode de l'algorithme 1, alors Tcq est le temps de réponse du contributeur à l'interrogation q et Tthq est le temps de réponse théorique attendu. Considérant que l’on peut combiner un grand nombre de sources, nous n’utilisons pas l’opérateur Yager. Car chez cet opérateur, un grand nombre de sources peut provoquer davantage de conflits et cela peut entraîner une trop grande ignorance.
Mais ici, pour obtenir la réflexion du contributeur c, on combine toutes ses réponses aux questions q. Pour un petit nombre de questions (entre 1 et 5) il serait possible d'utiliser l'opérateur Yager. Mais pour les besoins de notre modélisation nous considérons qu'elle peut s'appliquer à toutes les plateformes de crowdsourcing, quel que soit le nombre de questions posées, nous considérons également la moyenne des masses (20) sur toutes les questions : mΩc3.
Expertise
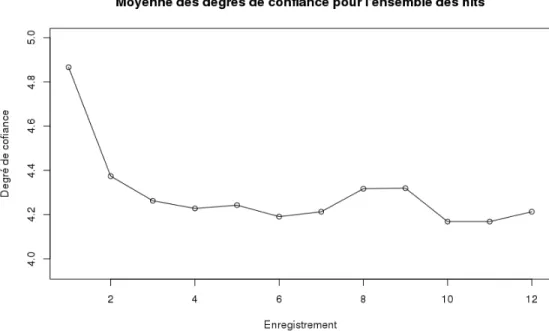
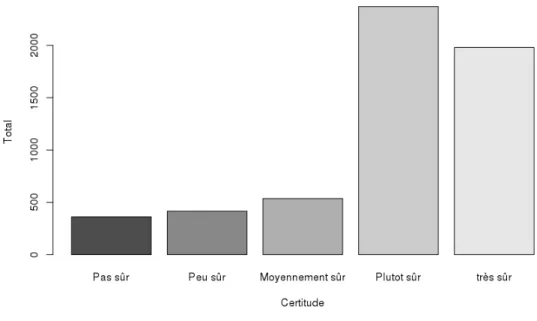
Les tests du modèle proposé sont effectués sur les données d'une campagne de crowdsourcing. Une analyse préliminaire des données est réalisée avant que la modélisation et son expérimentation ne soient établies. Ces échelles de confiance sont évaluées de telle sorte que « Très confiant » correspond à une confiance de 5 et « Pas sûr » à une confiance de 1 afin de mesurer la confiance moyenne des utilisateurs pour chaque question de chaque tir (figure 11 en annexe ).
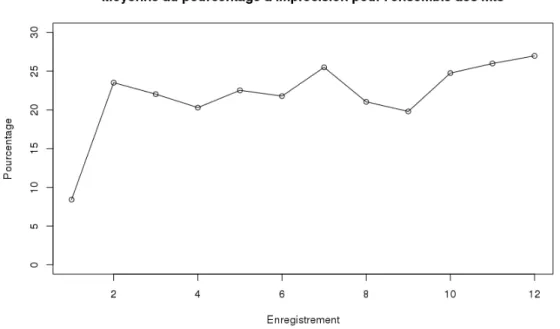
L'un des avantages de cette campagne était que l'utilisateur avait la possibilité de se tromper dans ses réponses. On voit sur ce graphique qu'en plus de l'enregistrement n◦1, entre 20 et 30% des contributeurs ont utilisé la possibilité de se tromper. Cependant, la possibilité de se tromper doit renforcer la confiance de l'utilisateur dans sa réponse, car il est préférable d'avoir une réponse incorrecte et certaine plutôt qu'une réponse correcte mais incertaine.
Biblioth` eques et ressources
Pour l'enregistrement n◦1 le pourcentage d'utilisateurs incorrects est très faible (inférieur à 10%), ce qui s'explique par le fait que le MNRU est de 1 et est en accord avec la confiance importante de l'utilisateur dans sa réponse (figure 3). La confiance avérée des utilisateurs dans leurs réponses est positive pour l’utilisation des données. De plus, lors de la campagne précédente, les contributeurs avaient également la possibilité d'être inexacts, mais n'utilisaient pas cette inexactitude la plupart du temps, ou lorsqu'ils le faisaient. - Sachez qu'ils se considéraient moins confiants dans leurs réponses.
Dans cette campagne, ce lien entre imprécision et certitude est mieux assimilé par l'utilisateur. La section suivante contient des informations sur la bibliothèque et les ressources utilisées pour implémenter la modélisation. Après cette présentation des moyens utilisés pour mettre en œuvre la modélisation, nous allons maintenant discuter de ses résultats.
R´ esultats de la mod´ elisation
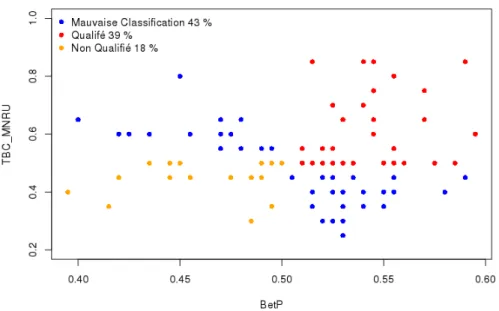
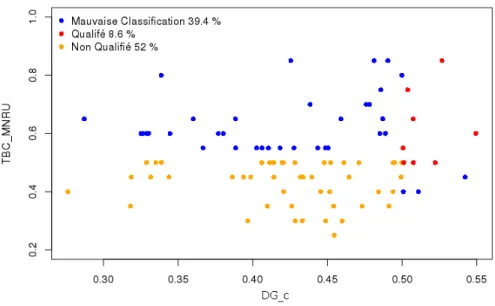
Mesure proposée de la qualification des contributeurs (mΩc2) basée sur les échelles DEc. On obtient pour le rang DGc un bon taux de classement pour l'évaluation de la qualification des contributeurs de 60,6% pour les MNRU et de 58,0% pour les données d'essai. Un bon taux de classification pour qualifier le contributeur mΩc2 est plus important pour les MNRU que pour les données de tests.
Le comportement du contributeur dépend de sa motivation à accomplir la tâche. La modélisation du comportement s'appuie sur la réflexion du contributeur sur la tâche. De même, pour valider la modélisation sur la réponse du contributeur, l'agrégation de toutes les réponses est réalisée quelle que soit la classe du contributeur.

Perspectives
Les expérimentations sur la modélisation de l'expertise correspondent en partie à nos attentes et celles sur la modélisation de la notation sont très positives. Si nous pouvions connaître ces niveaux, nous pourrions les utiliser comme valeurs théoriques des connaissances du contributeur. Ces questions d'attention permettront alors de considérer si le contributeur est attentif « A » ou non « NA » dans l'exécution de la tâche.
Commençons par expliquer ce schéma de modélisation des connaissances des contributeurs. Pour modéliser le comportement, d'une manière analogue aux connaissances en modélisation, une fois l'ensemble des fonctions de masse : mΩcA, mΩc3 et mΩuI serait établi, une expansion vide serait effectuée sur ces fonctions avant d'effectuer une combinaison Yager conjonctive. Les fonctions de masse respectivement ΩY1 et ΩY2 seront le résultat de la modélisation des connaissances et du comportement du contributeur.
Bilan personnel
Pour déterminer ce produit cartésien, une expansion vide serait effectuée sur les trames ΩY1 et ΩY2 puis combinées à l'aide de l'opérateur conjonctif de Yager. Conseil de Laboratoire Comité d'Orientation Scientifique Direction Scientifique RECHERCHE Service Assistante des Equipes de Recherche (SAER) Marie-Noëlle GEORGEAULT - Inria, Resp. Equipes EXPRESSION, HYBRID, INTUIDOC, LINKMEDIA, MIMETIC, PERCEPT D7 - Gestion des données et des connaissances (DKM) Olivier RIDOUX –UR1, Resp.
Ressources et expertise EIT Digital Rennes Jean-Marc JEZEQUEL -UR1, Resp Frédéric RENOUARD -UR1 Yvonnick DAVID -UR1 François MORIN -UR1 Martine LEMERCIER - UR1 Cyber Centre d'Excellence Jean-Marc JEZECHELQEL -UR1, Resp. Modélisation de la réponse du contributeur Moyenne pour les questions q Attention du contributeur c à la question qA. Attention du contributeur c à la tâche. Réflexions générales du contributeur c. Intérêt du contributeur c pour la tâche.