Pour le contrôle d'admission sur les paramètres (dans les réseaux ATM en particulier), nous proposons une collaboration sur des réseaux de neurones distribués pour évaluer la qualité de service le long d'un chemin. La dernière section s’intéresse plus précisément à l’utilisation de modèles neuro-mimétiques de qualité de service dans cette démarche.
La qualité de service (QoS)
La notion de qualité de service (QoS) a été définie pour formaliser ces nouvelles restrictions de trafic. La qualité de service est aujourd'hui au cœur des problématiques de recherche dans le domaine des réseaux.
Réseaux multiservices
Les réseaux ATM
La bande passante initialement réservée à la classe VBR et qui n'est pas réellement utilisée est réaffectée au trafic ABR (zone ombrée sur la figure 1.1). La zone grisée correspond à la bande passante réservée au trafic VBR mais utilisée par le trafic ABR.
QoS dans les réseaux IP
DiffServ distingue deux types de routeurs : les routeurs de périphérie qui sont chargés de classer les flux et de conditionner le trafic, et les routeurs centraux qui sont chargés de gérer les paquets en fonction de la classe de trafic et de leur politique interne appelée PHB (Per-Hop Behaviour). . Étant donné que les routeurs de périphérie sont traversés par un nombre relativement faible de flux par rapport au nombre total de flux circulant dans le réseau, ils peuvent effectuer des traitements complexes tels que la classification des paquets et le conditionnement du trafic.
Les réseaux MPLS
Le routage au sein d'un domaine MPLS ne repose plus sur l'analyse de l'adresse de destination, mais sur une étiquette. Dans un L-LSP, l'étiquette sert à la fois à déterminer la destination du FEC, mais également la classe de service.
Problématiques liées au support de la qualité de service
- Evaluation de performance
- Contrôle d’admission et allocations de ressources
- Routage
- Conception de réseaux
Enjeux liés à la qualité de service 21 1.3.2 Contrôle d'accès et allocation des ressources. L’introduction de la QoS de bout en bout rend ces problèmes de routage plus complexes.
De l’«intelligence» dans les réseaux multiservices
- Modèles connexionnistes pour le contrôle d’admission
- Modèles dynamiques de trafic
- Modèles de classification de trafic
- Apprentissage par renforcement pour le routage et le contrôle de trafic
« L'intelligence » dans les réseaux multiservices 27 1.4.4 Apprentissage par renforcement pour le routage et le contrôle dynamiques. La prédiction de mouvement dans un réseau mobile [Hadjiefthymiades et al., 2002] proposent une autre application de l'apprentissage par renforcement pour améliorer les performances du protocole TCP dans les réseaux mobiles.
Conclusion
Dans ce chapitre, nous nous concentrons sur les méthodes d'apprentissage supervisé pour résoudre les problèmes d'estimation (par opposition aux problèmes de classification) et nous nous concentrons principalement sur l'utilisation de réseaux de neurones à action directe dans ce contexte. Nous présentons les réseaux de neurones à action directe qui constituent une classe relativement efficace de fonctions paramétriques pour la régression non linéaire et dans la troisième section, nous nous concentrons sur les méthodes d'apprentissage des réseaux de neurones à action directe qui sont basées sur la rétro-propagation des erreurs.
Régression paramétrique
Moindres carrés
Maximum de vraisemblance
Cette relation permet d'associer le critère de risque local à des hypothèses sur la loi de propagation des erreurs. Ainsi, les estimateurs des moindres carrés et du maximum de vraisemblance coïncident lorsque les erreurs suivent une distribution normale de moyenne nulle (bruit blanc).
Réseaux de neurones feed-forward
- Le neurone formel
- Le Perceptron multicouche
- Propriétés d’approximations du MLP
- Le modèle feed-forward
En général, les neurones de la couche d’entrée ne sont pas actifs, c’est-à-dire que leur activité est égale au signal d’entrée. On désignera par N, l'ensemble des neurones d'un FFNN et la sortie (couche de sortie) du FFNN.
Apprentissage
Calcul du gradient par rétropropagation de l’erreur
Le but est de calculer le gradient Eq(w) de l'équation (2.11) par rapport aux paramètres du modèle, c'est-à-dire par rapport aux poids w du réseau de neurones. Le calcul du gradient est linéairement complexe par rapport au nombre d'arêtes du réseau neuronal, ce qui en fait un algorithme très efficace pour les méthodes d'optimisation basées sur le gradient.
Méthodes d’apprentissage par lot
La méthode du gradient conjugué consiste à choisir une direction qui correspond à la direction de l’étape précédente. La méthode de Levenberg-Marquardt est une adaptation de l'algorithme de Gauss-Newton, similaire aux méthodes des régions de confiance.
Méthodes d’apprentissage incrémentales
La différence entre les deux algorithmes sera plus grande, puisque les exemples sont dans la base d’apprentissage. Un apprentissage progressif est donc recommandé lorsque la base d’apprentissage est importante et/ou redondante.
La généralisation
Élements de la théorie de l’apprentissage statistique
Le principe de minimisation empirique du risque (ERM) est non trivialement cohérent si et seulement si le risque empirique E(w) vérifie la convergence uniforme vers le risque théorique R(w) sur l'ensemble de fonctions Q suivant. Le principe de minimisation du risque structurel (SRM) propose de minimiser conjointement l'erreur empirique et l'intervalle de confiance.

La régularisation
Cela revient à trouver un compromis entre la qualité de l’approche par apprentissage et la complexité de la fonction qu’elle remplit. 2.37) L'idée derrière ce terme de régularisation est de contrôler directement les courbures excessives de la fonction lors de l'apprentissage.
La validation croisée
La validation croisée limite la dépendance de la méthode de validation simple au choix de la base de validation en faisant la moyenne sur K bases différentes. A l’inverse, si K est petit, v devient grand, ce qui peut être d’un coût prohibitif si l’on dispose de peu d’exemples (en fait, l’apprentissage est dépourvu de v exemples issus de la base de validation).
Critères d’erreur asymétriques
Erreur de Minkowsky asymétrique
Cependant, la méthode nécessite que K apprenne plusieurs modèles, ce qui peut être relativement coûteux si K est trop grand. Dans [DeCoste, 1997], l'auteur utilise une version asymétrique de l'erreur de Minkowski pour estimer les enveloppes supérieure et inférieure d'un nuage de points.
Erreur de Gumbel
Le paramètre de forme β de la loi de Gumbel permet de moduler l'asymétrie de notre fonction d'erreur : plus elle est petite, plus les sous-estimations seront pénalisées lors de l'apprentissage. Le paramètre de forme β de la loi de Gumbel correspond à un facteur d'échelle dans le critère d'erreur.
Prévision d’une série temporelle avec un critère asymétrique
Apprendre avec des « données » [Abu-Mostafa, 1990, Abu-Mostafa, 1995] permet de prendre en compte lors de l'apprentissage les propriétés de la relation que l'on souhaite apprendre. ExpectationEx[em(x)] fournit une mesure théorique de l'erreur de monotonie globale de la fonction qui peut être prise en compte lors de l'apprentissage.
Formalisation du problème
Lorsque nous voulons considérer les contraintes de croissance, l’apprentissage basé sur les réseaux de neurones devient un problème d’optimisation non linéaire sous contraintes. La fonction objectif E(x) détermine l'erreur empirique du réseau neuronal sur l'ensemble de la base d'apprentissage associée au critère de risque local (·, ·) (voir section 2.1).
Apprentissage de la monotonie
Méthodes de pénalité pour l’optimisation non-linéaire sous contraintes
Plus la solution est proche de la limite de la région réalisable, plus le terme de pénalité est élevé. La méthode du multiplicateur permet d'éliminer le problème de mauvais conditionnement qui peut apparaître dans les méthodes de pénalité à l'approche de la solution optimale.
Application au problème d’apprentissage de la monotonie
Algorithme avant-arrière pour le calcul du gradient
- Calcul de la matrice jacobienne
- Différentiation de la matrice jacobienne
- Différentiation du terme de pénalité
- Algorithme
Pour simplifier les notations, nous omettrons par la suite de spécifier le vecteur d'entrée x et le vecteur paramètre w. La dérivée partielle d'un élément Jij dans la matrice jacobienne par rapport à un poids wklest (i∈ Nout,j∈ Ninet(k, l)∈ A).
Construction heuristique d’une solution initiale réalisable
Étude d’un cas unidimensionnel
- Apprentissage sans contraintes
- Apprentissage avec une fonction de pénalité ou le lagrangien augmenté
- Apprentissage avec une fonction barrière
- Conclusion
- Définition
- Evaluation de performance
- Files markoviennes
- Files non markoviennes
Les résultats d'apprentissage des 30 itérations d'apprentissage sont résumés dans le tableau récapitulatif 3.1 à la fin de la section. L'utilisation d'une fonction barrière permet de s'assurer de la validité des contraintes (sur une base d'apprentissage) tout au long du processus d'apprentissage.
Modélisation par réseaux de neurones
Généralités
En fait, les estimations du réseau de neurones se rapprocheront de l’enveloppe supérieure du nuage de points de base d’apprentissage. L'utilisation de contraintes de monotonie dans l'apprentissage permet de garantir la croissance de la fonction de régression sur la base de l'apprentissage.
Caractérisation des trafics
Le coefficient de variation est une mesure importante, quoique incomplète, de la variabilité du trafic. Les indices de dispersion sont des outils de caractérisation de la variabilité d'un processus stochastique, plus généraux que le simple coefficient de variation.
Schéma général
De plus, l'équation (4.13) n'est valable que lorsque le trafic incident est généré par des processus de renouvellement.
Files d’attente de type FIFO
Le modèle de trafic sporadique le plus simple et le plus populaire est le modèle source ON-OFF. Cela correspond généralement au trafic vocal sur un réseau de données. a) Modèle source ON-OFF.
Ces NMSE correspondent à l'erreur quadratique normalisée de l'estimation du log-lag des modèles sur leur base de validation (on note ici N(x) la valeur donnée par le réseau de neurones pour le vecteur d'entrée x). Les intervalles de confiance pour l'erreur de généralisation (respectivement [4,17,6,61] et [3,15,5,97] pour un niveau de confiance de 95 %) sont très proches.
Superposition de trafics sporadiques
Nous ne considérons que deux sources car l’impact des corrélations est plus important sur le comportement de la file d’attente. La différence que l'on mesure entre la valeur théorique de I(∞) et le Cv2a que l'on mesure sur le trafic total correspond à des phénomènes de corrélation.
Files d’attente à serveur partagé
Introduction
Trafics poissonniens
Les valeurs du tableau sont les moyennes et écarts types sur 10 répétitions de la formation NMSE (×10−3) mesurées dans les bases de validation MLP (3×15×3). Quant à l'estimation du nombre moyen de clients, les estimations sont plus difficiles et s'expliquent par une répartition des valeurs très hétérogène dans notre base d'échantillon : il existe de nombreuses valeurs très basses et peu de valeurs élevées.
Surtout, on constate que l'apprentissage du délai semble plus difficile que le taux de perte dans les scénarios 2 et 3. Les valeurs du tableau sont des moyennes et des écarts types sur 10 répétitions de l'apprentissage NMSE (×10− 3 ) mesurés sur le Base de validation MLP.
Conclusion
Contrôle d’admission
La décision d'admission peut être centralisée, et dans ce cas un seul agent décide de l'admission (qui peut se situer par exemple au point d'entrée du nouveau flux), ou est répartie sur le réseau. La décision d'admission peut donc être prise par un agent à partir de ces estimations, en tenant compte des contrats de chaque connexion (la QoS négociée est-elle garantie pour tous ?) et éventuellement à partir de règles définissant une politique de contrôle d'admission.
Principe
Pour cela, en plus des critères de QoS, les réseaux de neurones doivent également évaluer les caractéristiques du trafic sortant. Ainsi, à partir de la description du trafic à l’entrée du réseau, des prédictions seront propagées de réseau de neurones en réseau de neurones pour estimer la QoS tout au long du trajet.
Expérimentations et objectifs
Apprentissage de la QoS dans des files d’attente en série
- Une seule source O N -O FF
- N sources O N -O FF homogènes
- Deux sources O N -O FF hétérogènes
- Conclusion
Les trois files d'attente sont alimentées à partir de N sources ON-OFF identiques (partageant les mêmes paramètres) et indépendantes (voir Fig. Enfin, on constate que les erreurs d'estimation sont faibles pour l'estimation du trafic en sortie Cv2 des trois files d'attente.
Apprentissage de la QoS dans des files d’attente en parallèle
Durée moyenne d’une rafale
La durée moyenne d'un burst provenant d'une superposition de sources modulées par des chaînes de Markov est donc de . L’avantage d’utiliser tB au lieu du courant de crête est qu’il n’est pas constant en sortie d’une file d’attente avec un serveur déterministe.
Construction de la base d’exemples
Ainsi, le taux de départ d'un tel mode est la somme des taux de départ des modes à débit maximal de ce trafic incident. Il peut donc être estimé par les réseaux de neurones pour le propager aux réseaux de neurones suivants.
Estimations du taux de perte par réseaux de neurones distribués
D'une part, les valeurs de sortie de la base d'apprentissage n'ont été soumises à aucun prétraitement particulier (outre la normalisation), ce qui peut expliquer pourquoi les erreurs sont plus importantes pour les petites valeurs (on peut peut-être résoudre ce problème avec une transformation logarithmique ). Valeur cible pour la durée moyenne de burstittBout. a) Erreurs relatives dans la durée moyenne d'une rafale.
Conclusion
- Introduction
- Flots et multiflots dans les réseaux
- Critère de minimisation
- La méthode de déviation de flot
Nous proposons ici d'utiliser les réseaux de neurones comme modèles pour estimer la qualité de service dans le processus d'optimisation. Cette méthode est une application de la méthode de Frank-Wolfe au problème de routage.
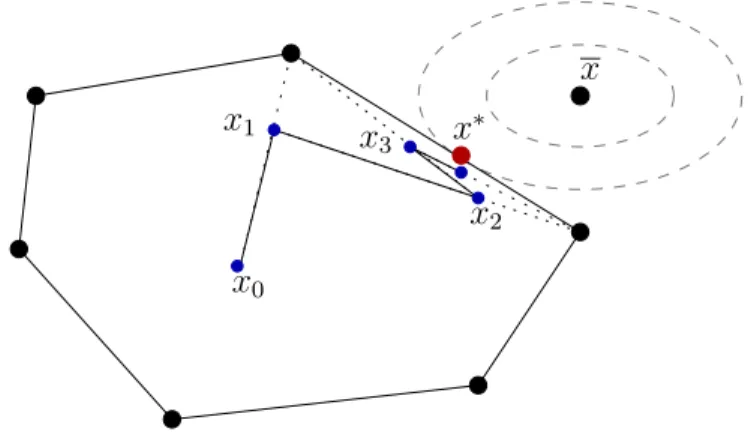
Formalisation du problème de routage sous garantie de QoS
Généralités
Si l’on préserve les contraintes de capacité dans le programme non linéaire, les sous-problèmes par commodité ne sont plus réduits à de simples problèmes de chemin le plus court, mais à des problèmes de flux à coût minimum, et la direction de descente n n’est plus déterminée par un seul chemin. mais d'un flux, accessible par rapport aux capacités : le flux n'est plus détourné vers un seul chemin. L’avantage de cette solution est que la quantité de flux détourné à chaque itération est plus importante.
Contraintes de QoS
Malheureusement, ces variables entières rendent le problème difficile, d'autant plus que les contraintes de QoS restent fondamentalement non linéaires par rapport aux variables de flux. Par conséquent, cette famille de contraintes modélise bien les contraintes de QoS (6.15) sans introduire de variables entières supplémentaires.
Routage dans un réseau à différentiation de service
Malheureusement, la convexité de ces contraintes n’est pas garantie quelle que soit la famille de fonctions d’évaluation{ψe}.
Stratégie de résolution : lagrangien augmenté et déviation de flot
- Relaxation lagrangienne et lagrangien augmenté
- Relaxation lagrangienne des contraintes de QoS
- Méthode de Frank-Wolfe pour la résolution du problème relâché
- Recherche du chemin optimal
- Algorithme récapitulatif
Pour tout vecteur de multiplicateurs λ≥0, la fonction dual est une borne inférieure du problème initial. Dans la section suivante, nous proposons d'utiliser la méthode de Frank-Wolfe pour résoudre le problème détendu.
Couplage avec des réseaux de neurones et résultats numériques
Modèles de la QoS
Nous proposons également d'utiliser un critère d'erreur asymétrique de type erreur de Gumbel (voir Section 2.5) pour obtenir des estimations pessimistes de la QoS. Nous mesurons ensuite l'erreur de mise à l'échelle globale (« msme ») et le pourcentage d'exemples dans la référence de validation pour lesquels la mise à l'échelle n'est pas observée.
Résultats numériques
Ainsi on augmente le facteur de pénalité d’un facteur 10 seulement lorsque l’on ne réduit pas suffisamment la violation de contrainte. On note également que l’on obtient la même solution pour les trois fonctions d’estimation du retard.
Conclusion
Nous proposons ensuite de généraliser cette modélisation à l'estimation de la qualité de service le long d'un itinéraire. Enfin, nous avons proposé d'utiliser la modélisation neuro-mimétique de la qualité de service dans le contexte de l'ingénierie du trafic.
Introduction
Cette annexe est la synthèse d'une réflexion que nous avons eue avec Bruno Bachelet et Loic Yon lors de nos thèses sur l'application des concepts du génie logiciel au domaine spécifique de la recherche opérationnelle. Nous proposons une comparaison de leur efficacité dans la mise en œuvre d’une structure de graphes en recherche opérationnelle.
Structures de données génériques
Généricité et héritage
Toujours en utilisant l'approche d'héritage, il est possible de forcer un cast sans garantie (pas de vérification dynamique), en utilisant le mot-clé C++static_cast:. Arc
Indépendance des structures de données
Certaines conceptions (notamment STL) suggèrent que l'algorithme reçoit directement les itérateurs au lieu de la structure de données. L'exemple suivant illustre comment utiliser la structure de données issue de la modélisation de la Figure B.4.
Vers des algorithmes génériques
Abstraction des algorithmes
L'exemple précédent, basé sur la modélisation de la Figure B.5, montre qu'il est possible de choisir quel algorithme de chemin le plus court utiliser dans l'algorithme de flux à coût minimum au moment de l'exécution. L'algorithme doit être créé et paramétré avant d'être utilisé dans la méthode run() de l'algorithme de flux à coût minimum.
Extension des algorithmes
Le visiteur peut être transmis à l'algorithme lors de sa construction, ou ultérieurement mais avant l'appel à la méthode run(), ou encore à la fin en tant qu'argument à la méthode run(). Comme avec l'approche précédente, le visiteur peut être transmis directement comme argument au constructeur de l'algorithme, plutôt que d'être automatiquement généré par l'algorithme.
Obtenir une bonne généricité
Ainsi, si l'on considère une classe Route avec deux attributs distance et vitesse, il est possible, en proposant deux visiteurs différents (ou deux sous-classes différentes pour la première approche), de calculer un itinéraire plus court tant en termes de temps que même de distance, sans modifier une seule ligne de l'algorithme.Nous comparons les différentes approches de la solution classique qui consiste à écrire deux versions distinctes de l'algorithme : l'une dédiée au temps, l'autre à la distance.
Gestion d’extensions pour les structures de données
Premièrement, la classe Node peut déléguer la gestion de la liste d'extensions à une autre classe (c'est le rôle de ExtensionSet dans la Figure B.11). Dans la deuxième conception, la partie implémentation de la classe est héritée de la classe Extendable.
Maintenir plusieurs modèles d’un même problème
Le graphe observé décide de communiquer les changements pertinents à un ou plusieurs managers, qui à leur tour informent les observateurs. Ce dernier, après avoir reçu une notification, peut choisir de modifier ou non la matrice pour conserver une cohérence avec le graphique.
Conclusion
Répartitions des classes de services ATM
Réservation de ressources dans les réseaux IntServ
Fonctionnement des routeurs edge et core dans une architecture DiffServ
Exemples de fonctions d’activation
Le Perceptron multicouche
Un exemple de réseau feed-forward
Illustration du surapprentissage d’un modèle paramétrique
Illustration de la consistance du principe de minimisation du risque empirique
Illustration du principe de minimisation du risque structurel
Principe de la validation croisée
Densité de probabilité et critère d’erreur pour la loi de Gumbel
Série temporelle de Mackey-Glass
Heuristique d’initialisation d’un FFNN sous contraintes de croissance
Une file d’attente simple
Evolution du nombre moyen de clients en fonction de l’intensité du trafic
Combinaisons de lois exponentielles
Distributions des critères de QoS, cas DiffServ et trafics de Poisson
Erreurs d’estimation sur le délai pour la classe AF1 (cas DiffServ)
Estimation du taux de perte dans les scénarios 2 & 3
Modélisation neuronale d’un réseau de files d’attente
Réseaux de neurones pour l’estimation de la QoS dans 3 files d’attente en série
Modèles de réseaux de neurones avec la durée moyenne d’une rafale
Erreurs relatives pour deux files s’agrégeant dans une troisième
Illustration de la méthode de Frank-Wolfe (cas convexe)
Graphe modélisé par héritage
Nous proposons de comparer ces deux structures en mesurant, dans une implémentation, le temps d'accès aux données d'écoulement portées par un arc. Lorsque les données d'arc sont récupérées, elles seront de typeArcData et devront ensuite être converties en données de typeFlow.
Graphe modélisé par généricité
Algorithme paramétré sur le type de l’itérateur
Algorithme paramétré sur le type de la structure de données
De cette manière, l'algorithme est complètement indépendant de la structure des données, comme dans l'exemple d'assemblage de la Figure B.3. Une meilleure conception serait de proposer une version paramétrable de l'algorithme, où le paramètre est le type de structure de données que l'algorithme manipule (voir Figure B.4).
Abstraction des algorithmes
Il est également important de fournir une méthode dans la classe abstraite ShortestPathAlgo pour renvoyer à l'utilisateur final un objet algorithme par défaut, appartenant à l'une de ses classes concrètes. En général, ce sera la classe reconnue comme la plus efficace, mais on peut proposer une approche plus sophistiquée où, par exemple, une analyse de la structure du graphe permet de trouver l'algorithme le plus efficace ou le mieux adapté pour résoudre un problème spécifique sur ce graphique.
Extension d’un algorithme, approche par méthode virtuelle
Extension d’un algorithme, approche par visiteur abstrait
Enfin, pour éviter les liens dynamiques, le visiteur doit être un paramètre, non pas de la méthode run(), mais de la classe d'algorithme elle-même.
Extension d’un algorithme, approche par interface de visiteur
Sur un graphe de 100 000 arcs, nous proposons de trouver le chemin le plus court entre deux points tirés aléatoirement, d'abord en temps puis en distance, en faisant deux appels consécutifs à l'algorithme (c'est à dire avec des visiteurs différents, ou avec des versions différentes). de l’algorithme, selon l’approche). Le faible écart entre les méthodes, seulement deux secondes, s'explique ici par le fait que l'appel à la méthode getLength() n'est pas très fréquent par rapport à la masse d'opérations dans l'algorithme.
Classe Extension
Par exemple, dans l'apprentissage d'élagage d'un réseau de neurones, il existe deux algorithmes itératifs indépendants : l'algorithme d'apprentissage qui modifie, à chaque itération, les poids du réseau de neurones, et l'algorithme d'élagage qui peut supprimer, à chaque itération, les arcs qui s'avèrent inutiles. La formation et l'élagage nécessitent tous deux l'ajout de données supplémentaires aux nœuds du graphique qui doivent résider entre deux itérations de chaque algorithme.
Modélisation de la gestion de données additionnelles
Le rôle d'un objet ExtensionManager est de gérer l'ajout ou la suppression d'un objet Extension de chaque nœud de l'ensemble qu'il encapsule. Un index est renvoyé indiquant la position de l'extension dans les listes indexées appartenant aux nœuds.
Interface Extendable implémentée avec la délégation
Ainsi, un algorithme qui souhaite ajouter une extension appelle sa méthode Attach() avec un modèle de l'extension à cloner et à placer sur chaque nœud. Cela permet à l'algorithme de demander directement à un nœud une extension spécifique, en utilisant l'index.
Interface Extendable implémentée avec la spécialisation
Classe de service dans un réseau ATM
Résultats d’apprentissage avec des critères d’erreur asymétriques
Synthèse des résultats d’apprentissage sous contraintes de monotonie
Résultats d’apprentissage dans une file DiffServ avec des trafics de Poisson
Paramètres de simulations d’une file d’attente DiffServ
Paramètres de simulation de 2 files s’agrégeant dans une troisième
Erreurs d’estimation pour deux files s’agrégeant dans une troisième
Résultats de l’apprentissage pessimiste sous contraintes de croissance de la QoS
Besoins de qualité de service de chaque classe de service
Résolution de problèmes de routage sous contraintes de délai de bout en bout
Résolution du problème de routage sous contraintes de pertes de bout en bout
Comparaison d’un graphe par héritage avec un graphe par généricité
La collection est fournie directement à l'algorithme, tandis que le modèle d'algorithme est indépendant du type de collection. Pour ce faire, nous avons répété la procédure de la section 2.1 et nous avons mesuré, dans les mêmes conditions, son temps d'exécution (test n°4).
Impact de l’utilisation des itérateurs
Cela signifie qu'un assemblage complètement indépendant a besoin d'un adaptateur pour que l'algorithme puisse l'utiliser. Ainsi, comme le montre la figure B.8, l'algorithme possède un attribut qui représente un visiteur, qui doit remplir un conceptVisitor.
Comparaison des approches pour étendre un algorithme
Nous avons choisi d'implémenter un algorithme de plus court chemin avec un visiteur dont le rôle est de fournir la longueur d'un arc. L'ensemble du processus implique d'effectuer plusieurs itérations de formation, puis une itération d'élagage, et de répéter cette opération jusqu'à ce que certaines conditions soient remplies.
Impact du mécanisme d’extension
InProceedings of the IMCS Multiconference in Computational Engineering in Systems Applications (IMACS-CESA'96), Lille, France. InProceedings of the 6th IFIP Workshop on Performance Modeling and Evaluation of ATM Networks (IFIP ATM'98).


