HAL Id: tel-01127777
https://tel.archives-ouvertes.fr/tel-01127777v2
Submitted on 7 Mar 2015
HAL is a multi-disciplinary open access archive for the deposit and dissemination of sci- entific research documents, whether they are pub- lished or not. The documents may come from teaching and research institutions in France or abroad, or from public or private research centers.
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des établissements d’enseignement et de recherche français ou étrangers, des laboratoires publics ou privés.
survie à risques non proportionnels
Cecile Chauvel
To cite this version:
Cecile Chauvel. Processus empiriques pour l’inférence dans le modèle de survie à risques non pro- portionnels. Mathématiques générales [math.GM]. Université Pierre et Marie Curie - Paris VI, 2014.
Français. �NNT : 2014PA066399�. �tel-01127777v2�
UNIVERSITÉ PIERRE ET MARIE CURIE – PARIS 6 École Doctorale 386
Sciences Mathématiques de Paris Centre
T HÈSE DE DOCTORAT
Présentée en vue de l’obtention du titre de Docteur de l’Université Pierre et Marie Curie - Paris 6
Discipline : Mathématiques Appliquées Spécialité : Statistique
Processus Empiriques pour l’Inférence dans le Modèle de Survie à Risques Non Proportionnels
par
Cécile CHAUVEL
dirigée par John O’QUIGLEY et Philippe SAINT PIERRE
Soutenue le 1er décembre 2014 devant le jury composé de :
M. Antoine Chambaz Professeur, Université Paris 10 Nanterre Examinateur Mme Agathe Guilloux Maître de conférences, Université Paris 6 Examinateur M. Robin Henderson Professeur, University of Newcastle Rapporteur
M. Aurélien Latouche Professeur, CNAM Examinateur
M. John O’Quigley Professeur, Université Paris 6 Directeur M. Philippe Saint Pierre Maître de conférences, Université Paris 6 Co-directeur
Rapporteurs :
Mme. Tianxi Cai Professeur, Harvard Public School of Health M. Robin Henderson Professeur, University of Newcastle
Laboratoire de Statistique Théorique et Appliquée 4, place Jussieu
75252 Paris Cedex 05 Boîte courrier 158
UPMC
Ecole Doctorale 386 de Sciences Mathématiques de Paris Centre 4, place Jussieu
75252 Paris Cedex 05 Boîte courrier 290
Remerciements
Mes premiers remerciements s’adressent à mes directeurs de thèse. John, merci pour la confiance que vous m’avez témoignée en acceptant d’encadrer mon doctorat. Merci d’avoir partagé avec moi vos idées, vos intuitions et votre culture statistique au cours de nos nombreuses discussions.
Philippe, merci de m’avoir fait confiance en me proposant cette aventure alors que j’étais étu- diante à l’ISUP. Merci pour nos discussions (pas toujours statistiques !), les encouragements, le soutien et les conseils que tu m’as prodigués tout au long de ce parcours. Je suis très touchée par l’attention que tu m’as portée.
I would like to thank Tianxi Cai and Robin Henderson for the interest they showed in my work by reviewing this thesis. It is an honour for me that they took time and commented my work.Je remercie également sincèrement Antoine Chambaz, Agathe Guilloux et Aurélien Latouche d’avoir accepté de participer à mon jury de thèse. En particulier, merci à Agathe pour les discussions que l’on a pu avoir au cours de ces trois années. Merci d’avoir pris le temps de me faire des commentaires très pertinents sur mon travail.
Je remercie le directeur du laboratoire, Gérard Biau, et l’ancien directeur, Paul Deheuvels, de m’avoir accueillie au LSTA. Merci à Louise et Corinne pour leur gentillesse et leur disponi- bilité. Merci aux autres membres permanents du laboratoire, toujours à l’écoute, prêts à nous aider en cas de besoin et à discuter autour d’un café !
Ce travail n’aurait pas été le même sans la présence de mes camarades et amis doctorants (docteurs pour certains !) : Agniezska, Alexis, Amadou, Assia, Baptiste, Benjamin, Boris, Er- wan, Layal, Matthieu, Mokhtar, Nedjmeddine, Patricia, Roxane, Sarah L., Sarah O., Soumeya, Svetlana, Tarn et Virgile. Merci pour tous les bons moments passés ensemble. C’était toujours une joie de me rendre au laboratoire pour vous retrouver. Grâce à vous, je garderai un excellent souvenir de ces trois années. Je suis émue d’écrire ces mots qui marquent la fin d’une étape, mais je sais que nos chemins se recroiseront. Je remercie particulièrement Amadou, Benjamin, Erwan et Layal, qui ont partagé mon bureau pendant une grande partie de cette thèse. Merci à Baptiste, Benjamin, Erwan et Svetlana pour notre co-organisation du Groupe de Travail des Thésards. Merci également à toi Salim pour l’aide que tu m’as apportée et ta bonne humeur constante.
D’un point de vue plus personnel, je remercie mes parents de m’avoir toujours soutenue dans mes études et dans mes choix. Merci d’avoir été à l’écoute lorsque j’en avais besoin et d’avoir cru en mes capacités. Je remercie mes sœurs pour leurs encouragements et leur soutien sans faille. Je ne serai pas arrivée là sans vous quatre ! Merci à mes amis, indispensables à la
réussite de cette thèse, et pour lesquels je n’ai pas toujours été disponible ces derniers mois.
Eric, je n’ai pas de mots assez forts pour t’exprimer ma gratitude. Tu m’as toujours soutenue au quotidien et été patient dans les moments difficiles (et on sait que la fin de la thèse n’est pas un long fleuve tranquille). Ces trois années ont été douces à tes côtés. Ainsi s’achève notre année 2014, pleine d’évènements et d’émotions !
Résumé
Nous nous intéressons à des processus empiriques particuliers pour l’inférence dans le modèle à risques non proportionnels. Ce modèle permet au coefficient de régression de varier avec le temps et généralise le modèle à risques proportionnels très utilisé pour modéliser des données de survie. Le processus du score standardisé que nous étudions est une somme séquentielle des résidus standardisés du modèle. Le processus est considéré en présence d’une covariable dans le modèle, avant d’être étendu au cas de multiples covariables pouvant être corrélées.
Le plan du manuscrit se décompose en trois parties. Dans un premier temps, nous établissons les propriétés limites du processus sous le modèle et sous un modèle mal spécifié. Dans une deuxième partie, nous utilisons les résultats de convergence du processus pour dériver des tests de la valeur du paramètre du modèle. Nous montrons qu’un des tests proposés est asympto- tiquement équivalent au test de référence du log-rank pour comparer les fonctions de survie de plusieurs groupes de patients. Nous construisons des tests plus puissants que le test du log-rank sous certaines alternatives. Enfin, dans la dernière partie, nous étudions comment lier prédiction et adéquation dans le modèle à risques non proportionnels. Nous proposons une méthode de construction d’un modèle bien ajusté en maximisant sa capacité prédictive. Aussi, nous introduisons un test d’adéquation du modèle à risques proportionnels. Les performances des méthodes proposées, qu’il s’agisse des tests sur le paramètre ou de l’adéquation du modèle, sont comparées à des méthodes de référence par des simulations. Les méthodes sont illustrées sur des données réelles.
Mots-clés : Survie, Modèle à risques non proportionnels, Processus empirique, Adéquation, Prédiction, Tests d’hypothèse.
Abstract
Empirical Processes for Inference in the Non-Proportional Ha- zards Model
In this thesis, we focus on particular empirical processes on which we can base inference in the non-proportional hazards model. This time-varying coefficient model generalizes the widely used proportional hazards model in the field of survival analysis. Our focus is on the standardi- zed score process that is a sequential sum of standardized model-based residuals. We consider first the process with one covariate in the model, before looking at its extension for multiple and possibly correlated covariates. The outline of the manuscript is composed of three parts. In the first part, we establish the limit properties of the process under the model as well as under a misspecified model. In the second part, we use these convergence results to derive tests for the value of the model parameter. We show that one proposed test is asymptotically equivalent to the log-rank test, which is a benchmark for comparing survival experience of two or more groups. We construct more powerful tests under some alternatives. Finally, in the last part, we propose a methodology linking prediction and goodness of fit in order to construct models.
The resulting models will have a good fit and will optimize predictive ability. We also introduce a goodness-of-fit test of the proportional hazards model. The performances of our methods, either tests for the parameter value or goodness-of-fit tests, are compared to standard methods via simulations. The methods are illustrated on real life datasets.
Keywords : Survival, Non-proportional hazards model, Empirical Process, Goodness of fit, Prediction, Hypotheses testing.
Table des matières
Remerciements 3
Résumé 5
Abstract 6
Plan détaillé de la thèse 11
Liste des notations et abréviations 15
1 Introduction 17
1.1 Introduction à l’analyse de survie . . . 17
1.1.1 Introduction . . . 17
1.1.2 Notation . . . 18
1.1.3 Estimateur de Kaplan–Meier de la survie . . . 19
1.2 Modèle à risques proportionnels et extensions . . . 22
1.2.1 Modèle à risques proportionnels . . . 22
1.2.2 Modèle à risques non proportionnels . . . 26
1.2.3 Alternatives au modèle à risques proportionnels . . . 31
1.3 Test de la présence d’un effet des covariables sur la survie . . . 34
1.4 Evaluation de l’adéquation et de la capacité prédictive du modèle à risques proportionnels . . . 36
1.4.1 Adéquation du modèle . . . 36
1.4.2 Mesures de capacité prédictive du modèle . . . 38
2 Outils mathématiques 41 2.1 Espaces D[0,1]etC[0,1] . . . 41
2.1.1 Topologies des espaces(C[0,1],R)et(D[0,1],R) . . . 41
2.1.2 Topologies de (D[0,1],Rp) . . . 42
2.2 Théorèmes limite . . . 44
2.2.1 Loi faible des grands nombres pour des variables non corrélées . . . 44
2.2.2 Théorèmes de la limite centrale fonctionnels . . . 44
2.3 Inégalité de Taylor-Lagrange multidimensionnelle . . . 47
3 Etude du processus du score standardisé 49
3.1 Introduction . . . 49
3.2 Transformation de l’échelle du temps . . . 51
3.3 Processus du score standardisé univarié . . . 57
3.3.1 Définition du processus . . . 57
3.3.2 Résultats asymptotiques . . . 59
3.4 Processus du score standardisé multivarié . . . 63
3.4.1 Définition du processus . . . 64
3.4.2 Résultats asymptotiques . . . 65
3.5 Preuves . . . 68
3.5.1 Preuves de la Section 3.2 . . . 68
3.5.2 Preuves de la Section 3.3 . . . 69
3.5.3 Preuves de la Section 3.4 . . . 79
4 Tests de comparaison de courbes de survie 87 4.1 Introduction . . . 87
4.1.1 Test du log-rank . . . 88
4.1.2 Tests du log-rank pondéré . . . 89
4.1.3 Combinaison de tests . . . 90
4.2 Tests basés sur le processus du score standardisé . . . 93
4.2.1 Distance depuis l’origine . . . 93
4.2.2 Aire sous la courbe . . . 95
4.2.3 Tests adaptatifs restreints . . . 97
4.2.4 Tests multivariés . . . 99
4.3 Simulations . . . 101
4.4 Applications . . . 105
4.4.1 Données de l’Institut Curie . . . 105
4.4.2 Essai clinique . . . 106
4.5 Discussion . . . 108
5 Construction et évaluation du modèle à risques non proportionnels 115 5.1 Adéquation du modèle à risques proportionnels . . . 116
5.1.1 Méthodes graphiques . . . 116
5.1.2 Tests d’adéquation . . . 119
5.2 Mesure de la capacité de prédiction du modèle à risques non proportionnels . . 121
5.2.1 Variance expliquée . . . 121
5.2.2 CoefficientR2 . . . 125
5.3 Adéquation et construction de modèles . . . 133
5.3.1 Adéquation du modèle à risques proportionnels . . . 133
5.3.2 Construction du modèle à risques non proportionnels . . . 136
5.4 Simulations . . . 139
Table des matières 9
5.4.1 Test d’adéquation . . . 139
5.4.2 Construction du modèle à risques non proportionnels . . . 144
5.5 Applications . . . 150
5.5.1 Données de Freireich . . . 150
5.5.2 Etude clinique . . . 150
5.6 Discussion . . . 153
Annexe - Simulations de données sous le modèle à risques non proportionnels 157 .1 Méthode 1 - Modèle de rupture . . . 157
.1.1 Simulation des données . . . 157
.1.2 Choix des points de rupture . . . 160
.2 Méthode 2 - Modèle à risques non proportionnels . . . 161
Bibliographie 163
Plan détaillé de la thèse
Chapitre 1 - Introduction
Le premier chapitre de cette thèse comporte une revue de littérature de certains aspects de l’analyse de survie. Dans la première partie de ce chapitre, nous définissons les notations qui seront adoptées dans la suite de la thèse et nous rappelons la définition de l’estimateur de Kaplan–Meier de la fonction de survie. Ensuite, nous décrivons le modèle à risques proportion- nels (Cox, 1972) très utilisé en pratique pour représenter les durées de vie. Nous exposons la méthode d’estimation du paramètre du modèle, dont le logarithme représente le risque relatif de décès instantané entre deux individus différents. Ce modèle est un cas particulier du modèle dit "à risques non proportionnels". Ce modèle plus général n’impose aucune restriction sur le risque relatif qui peut varier avec le temps alors que, dans le modèle à risques proportionnels, le risque relatif est constant. Ces modèles vont nous intéresser dans les chapitres suivants. Nous présentons une revue de littérature sur les méthodes d’estimation du paramètre de régression du modèle à risques non proportionnels. Enfin, nous proposons quelques modèles alternatifs au modèle à risques proportionnels pour caractériser les données de survie. La troisième partie de ce chapitre introductif rappelle le test du log–rank pour comparer la survie de groupes de patients (Mantel,1966). Ce test, très utilisé en pratique, est le test de référence pour comparer des courbes de survie. Nous présenterons des tests alternatifs de comparaison de courbes de survie au Chapitre 4. Enfin, la dernière partie du premier chapitre traite l’évaluation du mo- dèle à risques proportionnels. Plus précisément, nous présentons des méthodes d’évaluation de l’adéquation et des mesures de la capacité de prédiction du modèle. Nous reviendrons sur la littérature des méthodes d’adéquation du modèle au Chapitre 5.
Chapitre 2 - Outils mathématiques
Dans le deuxième chapitre, nous énonçons des résultats mathématiques non usuels en analyse de survie qui seront utilisés pour l’obtention des résultats de convergence des chapitres suivants.
Nous rappelons les particularités des espaces de fonctions continues à droite et limite à gauche de [0,1] dans Rp. Nous distinguons les cas p= 1 et p >1. Ceci nous amène à définir des topologies dans ces deux espaces. Ensuite, nous définissons le mouvement Brownien et le pont Brownien sur[0,1]avant d’énoncer des théorèmes de la limite centrale fonctionnels pour des variables indépendantes et centrées, mais dont les variances peuvent être différentes. Ces
résultats sont présentés dans les cas univariés de variables aléatoires réelles et multivariés de vecteurs aléatoires de Rp. Nous introduisons une loi faible des grands nombres pour des variables aléatoires non indépendantes. Enfin, nous présentons une inégalité de Taylor–Lagrange multidimensionnelle.
Chapitre 3 - Etude du processus du score standardisé
Un processus empirique, appelé processus du score standardisé, est défini dans ce3èmechapitre.
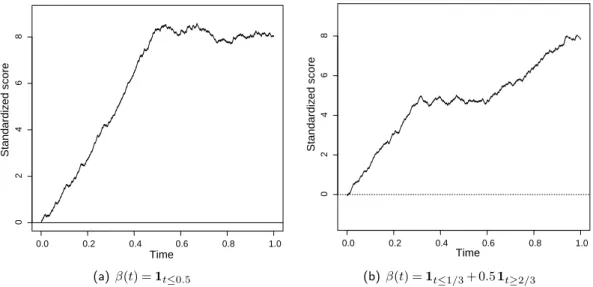
Ce processus est une somme pondérée séquentielle des résidus standardisés du modèle à risques non proportionnels avec un incrément à chaque temps de décès. Le processus est tracé en fonction des rangs des temps d’évènement renormalisés dans l’intervalle [0,1]. Le processus dépend du paramètre du modèle à travers les résidus. En s’inspirant du processus deWei(1984), O’Quigley (2003) a introduit le processus sous le modèle à risques proportionnels avec une unique covariable et un paramètre égal au maximum de vraisemblance partielle. La différence avec le processus de Wei (1984) réside dans une double standardisation. Chaque incrément du processus du score standardisé est standardisé différemment alors que le processus de Wei adopte une standardisation globale. La deuxième standardisation est celle de l’échelle des temps qui n’est pas effectuée avec le processus de Wei. Ceci permet l’obtention d’une loi limite simple et explicite en cas de mauvaise spécification du modèle.
L’originalité du travail présenté dans ce chapitre est d’étudier le processus avec n’importe quel paramètre pouvant éventuellement varier dans le temps. Nous formalisons la transforma- tion à appliquer sur le temps avant d’établir des résultats de convergence pour ce processus.
De plus, nous développons le processus avec plusieurs covariables dans le modèle. La standar- disation des incréments que nous adoptons permet de prendre en compte la covariance entre les covariables. Nous étudions également le comportement limite du processus multivarié. Sous un modèle bien spécifié, la loi limite du processus univarié ou multivarié est un mouvement Brownien. Si le modèle est mal spécifié, le processus n’est plus centré et une dérive propor- tionnelle au coefficient de régression apparaît. Le graphique du processus du score standardisé en fonction du temps permet d’anticiper la forme du coefficient de régression du modèle. Les résultats de ce chapitre sont utilisés dans les Chapitres 4 et 5 pour effectuer des tests d’hypo- thèse ou pour estimer le paramètre du modèle à risques non proportionnels. Les résultats de ce chapitre ont fait l’objet de deux articles (Chauvel et O’Quigley,2014a,b).
Chapitre 4 - Tests de comparaison de courbes de survie
Le processus du score standardisé et les résultats de convergence du Chapitre 3 permettent de dériver des tests asymptotiques de comparaison de courbes de survie. Il s’agit de tester s’il existe une différence entre les survies de différents groupes de patients. Ces tests peuvent également s’appliquer à des covariables continues, auquel cas il s’agit de tester si la covariable est liée à la survie. O’Quigley (2008, chap. 8) propose de s’intéresser à la distance depuis
Plan détaillé de la thèse 13 l’origine ou à l’aire sous la courbe du processus du score standardisé. Sous l’hypothèse nulle du test, le processus limite du score standardisé est un mouvement Brownien standard. Les tests sont alors construits à partir des propriétés du mouvement Brownien.
Dans ce chapitre, nous étudions des propriétés théoriques de ces deux tests. Nous montrons que le test de la distance depuis l’origine est asymptotiquement équivalent au test du log–rank.
Ainsi, comme le test du log–rank, le test de la distance depuis l’origine est le plus puissant lorsque les risques relatifs entre les groupes ne changent pas au cours du temps (Peto et Peto, 1972). En présence de risques relatifs non constants, le test peut perdre de la puissance. Nous montrons que, dans ces situations, le test de l’aire sous la courbe est plus puissant, mais il perd de la puissance par rapport au test du log–rank lorsque le risque relatif ne varie pas au cours du temps. Afin d’obtenir un test puissant sous les deux types d’alternative, nous avons introduit une classe de tests adaptatifs restreints. Les tests sont adaptatifs au sens où la forme de la statistique du test est déterminée en fonction des données. Cependant, les tests de cette classe dépendent d’un paramètre qui peut être délicat à fixer. Nous proposons alors un autre test adaptatif ne dépendant pas d’un paramètre. Nous étudions les comportements des tests sur des simulations et nous les comparons à des tests proposés dans la littérature.
Les simulations montrent que les tests se comportent comme anticipé sous les différentes alternatives. Nous avons également développé les tests dans le cadre multivarié de plusieurs covariables dans le modèle afin de tester plusieurs paramètres du modèle à la fois. La prise en compte de la corrélation entre les covariables dans la construction du processus présente l’avantage de pouvoir appliquer le test sur des variables corrélées. De plus, le graphique du processus en fonction du temps permet de visualiser l’écart à la significativité des différents tests étudiés. Enfin, nous appliquons les tests présentés sur des données réelles. Les résultats de ce chapitre sont publiés dans le journalBiometrika (Chauvel et O’Quigley, 2014a).
Chapitre 5 - Construction et évaluation du modèle à risques non proportionnels
Le dernier chapitre de la thèse traite de la construction du modèle à risques non proportionnels en considérant à la fois l’adéquation et la capacité de prédiction du modèle. Les résultats limites du processus du score standardisé (Chapitre 3) permettent d’utiliser le processus pour estimer le paramètre de régression. Pour ce faire, le processus est évalué avec un paramètre de régression nul. Aucune estimation du paramètre n’est requise, comme c’est le cas en traçant un nuage de points en deux dimensions pour des données non censurées afin d’évaluer le lien entre les deux variables. Dans un premier temps, nous proposons une revue de littérature des méthodes graphiques et des tests d’adéquation du modèle à risques proportionnels. Ensuite, nous présentons la variance expliquée et son estimateur, le coefficientR2d’O’Quigley et Flandre (1994), qui permettent de mesurer la capacité prédictive du modèle à risques proportionnels.
Notre travail a d’abord consisté à étendre le coefficientR2au modèle à risques non propor- tionnels. Nous étudions les propriétés asymptotiques du coefficientR2dans un modèle à risques
non proportionnels mal spécifié. En présence d’une covariable dans le modèle, nous montrons que le maximum du coefficient R2 est atteint lorsqu’il est calculé avec le vrai paramètre du modèle. Ensuite, nous proposons un test d’adéquation du modèle à risques proportionnels, ainsi que des bandes de confiance pour le processus à l’intérieur desquelles le processus évolue si les risques sont proportionnels. Ces bandes de confiance sont construites à partir de la loi limite du processus connue analytiquement. Souvent, à défaut de connaître la loi limite explicitement, les bandes de confiance des processus utilisées pour vérifier l’adéquation du modèle à risques proportionnels sont construites par simulation (Linet al.,1993,Scheike et Martinussen,2004).
Les performances du test d’adéquation développé dans cette thèse sont comparées par simu- lations numériques aux performances de tests de références. Les simulations indiquent que le test d’adéquation ne dépend pas de la corrélation entre les covariables, ce qui n’est pas le cas de tous les autres tests. Ceci permet de valider l’application du test en présence de covariables corrélées. De plus, les simulations permettent de conclure que notre test est plus puissant que les tests concurrents évalués dans les situations considérées.
Enfin, nous proposons une méthode de construction du modèle à risques non proportionnels à l’aide de l’adéquation et de la capacité de prédiction du modèle. L’adéquation est étudiée avec le graphique du processus du score standardisé en fonction du temps et la qualité de la prédiction est estimée par le coefficient R2. Ces outils sont utilisés pour développer une méthode de construction d’un modèle présentant une bonne adéquation et une prédiction optimale sur l’ensemble des modèles candidats. Nous montrons que le coefficient de régression du modèle sélectionné est le plus proche du vrai coefficient de régression au sens de la distance L2. Le coefficient de régression obtenu est un estimateur explicite et simple à interpréter du coefficient de régression. Le choix des modèles candidats est laissé à l’utilisateur afin d’obtenir un coefficient de régression facilement interprétable, même si une estimation non-paramétrique et plus automatique est envisageable. La méthode de construction de modèle est également illustrée par des simulations et des applications sur des données réelles.
Une partie des résultats de ce chapitre a été présentée dansChauvel et O’Quigley(2014b).
Nous avons développé le Package PHeval1 programmé en langage R qui permet d’évaluer et de tracer le processus du score standardisé ainsi que d’estimer le coefficientR2.
Annexe
L’Annexe expose la méthode développée durant la thèse pour simuler numériquement des données sous le modèle à risques non proportionnels. Deux méthodes sont proposées. La première permet de simuler des données sous un modèle de rupture. La deuxième considère un modèle à risques non proportionnels plus général.
1. Disponible à l’adresse :http://cran.r-project.org/web/packages/PHeval/index.html
Liste des notations et abréviations
Notations
W Mouvement Brownien sur[0,1]
B Pont Brownien sur[0,1]
≠æL Convergence en distribution
≠æP Convergence en probabilité
L1
≠æ Convergence en moyenne
p.s. Presque sûrement
1A Fonction indicatrice de l’ensembleA
Mp◊p(R) Ensemble des matrices de dimensionp◊p à coefficients réels ÎaÎ Norme sup du vecteuraœRp
ÎAÎ Norme sup de la matriceAœMp◊p(R)
Abréviations
Fˆ Estimateur de Kaplan–Meier deF
n Taille de l’échantillon
p Nombre de covariables
Ti Temps de décès de l’individui Xi Temps observé de l’individui
”i Indicateur de censure de l’individu i Zi Vecteur de pcovariables de l’individu i Zi(l) lème covariable de l’individui,l= 1, . . . , p
kn Nombre de décès observés sans épuisement des groupes d’individus
— Coefficient de régression du modèle à risques proportionnels
—(t) Coefficient de régression du modèle à risques non proportionnels
Z(t) Covariable de l’individu qui décède au temps t
fii(—(t), t) Probabilité pour que l’individu i décède au temps de décèstsous le modèle à risques non proportionnels de paramètre —(t)
E—(t)(Z|t) Espérance de la covariable de l’individu qui décède au temps tsous le modèle à risques non proportionnels de paramètre —(t)
V—(t)(Z|t) Variance de la covariable de l’individu qui décède au temps tsous le modèle à risques non proportionnels de paramètre —(t)
Unú(—(t), t) Processus du score standardisé évalué au paramètre —(t)et au tempst
Chapitre 1
Introduction
1.1 Introduction à l’analyse de survie
1.1.1 Introduction
L’analyse de survie est une spécialité importante des biostatistiques qui consiste à étudier des durées. L’étude de ces durées peut, par exemple, permettre de comparer les temps jusqu’à la guérison, la rechute ou encore le décès de différents patients. Dans un essai clinique, l’efficacité d’un nouveau traitement peut être déterminée en évaluant si la durée de vie moyenne des patients a été rallongée après la prise du traitement. Dans les études épidémiologiques, l’analyse de survie permet d’évaluer si un ou plusieurs facteurs de risque sont liés à la durée de vie. Ceci peut amener à limiter l’exposition à des facteurs de risque environnementaux, lorsque cela est possible, afin d’allonger la durée de vie. On désigne communément l’évènement auquel on s’intéresse par le terme générique de décès et la durée est appelée durée de vie.
L’analyse de survie peut également permettre d’établir des prédictions sur les temps de survie des patients. Ceci peut se faire de manière non paramétrique, par exemple avec l’esti- mateur de Kaplan–Meier de la survie (Kaplan et Meier, 1958), ou de manière paramétrique ou semi-paramétrique par l’utilisation de modèles pronostiques. Ces prédictions ont une im- portance capitale dans le domaine de la santé. Ils permettent aux patients d’être informés sur leur état de santé futur (pronostic du médecin) à partir de leur état de santé actuel (diagnos- tic établi par le médecin). Parfois, le traitement du patient peut être adapté en fonction de ces prédictions. Par exemple, en oncologie, les effets secondaires de certains traitements sont lourds, amenant à réserver ces thérapies aux patients dont la probabilité de survivre après un temps donné est faible.
La particularité de l’analyse de survie, hormis le fait d’étudier des variables aléatoires posi- tives, réside dans la présence de censure : certaines durées ne sont pas entièrement observées.
Par exemple, lors d’une étude, si un patient ne se rend plus aux rendez-vous fixés avec le mé- decin, il sera désigné comme "perdu de vue". Après la dernière visite à laquelle il s’est rendu, aucune information supplémentaire n’est disponible pour ce patient. Aussi, l’étude peut se terminer alors que des patients n’ont pas encore subi l’évènement d’intérêt. Ces patients sont
appelés les "exclus vivants". Dans ces deux situations, on n’observe pas le temps de survie du patient, la seule information disponible est que le patient a survécu jusqu’à une date connue (la dernière visite ou la date de fin de l’étude). Les estimateurs usuels de la statistique ne peuvent pas être utilisés en présence de censure, comme nous allons le voir dans la Section 1.1.3 avec l’exemple de l’estimateur de la survie empirique qui est remplacé par l’estimateur de Kaplan–Meier. Définissons d’abord les notations qui sont utilisées dans cette thèse.
1.1.2 Notation
L’échantillon est composé den observations. Pour le patient iœ{1, . . . , n}, la durée observée est notéeXi. Nous faisons l’hypothèse de censure à droite et considérons que cette durée est le minimum entre son temps de survieTi et un temps de censureCi : Xi= min(Ti, Ci). On observe également un indicateur de décès”i=1TiÆCi, où 1est la fonction indicatrice :”i= 1 si le décès du patienti a été observé et ”i= 0 si la durée de vie du patient i a été censurée.
On dispose d’un vecteur de covariablesZi pouvant correspondre à l’âge du patient, son sexe, un niveau de biomarqueur mesuré, le stade de sa maladie, etc. Formellement, l’échantillon est noté
{(Xi,”i, Zi), i= 1, . . . , n},
où lesntriplets d’observations sont des réalisations indépendantes et identiquement distribuées du vecteur aléatoire(X,”, Z), avecX= min(T, C)et”=1TÆC. On suppose que les supports des variables aléatoiresC etT sont finis dans R+ et on note [0,T] le support de T etF sa fonction de répartition.
Le vecteur Z=1Z(1), Z(2), . . . , Z(p)2 est un vecteur de p covariables, appelées aussi va- riables explicatives. Lorsque la covariableZ(j)dépend du temps,Z(j)est une fonction de[0,T] dansR, sinonZ(j)œR, pourj= 1, . . . , p. On suppose que le vecteur aléatoireZ(j)est continu à gauche :
Áæ0,Á>0lim Z(j)(t≠Á) =Z(j)(t), ’tœ[0,T], et est de variance non nulle :
V(Z(j)(t))>0, ’tœ[0,T].
Si le vecteur de covariables dépend du temps, on le noteZ=Z(t). Dans cette thèse, pour des raisons de clarté, nous notonsa(t)toute fonctiona de[0,T]dansRp qui n’est pas constante (dans le Chapitre 3 et les suivants, on considèrera les fonctions de[0,1]dansRp). Les fonctions constantes seront dénotéesa de manière à distinguer les deux cas aisément.
Pour tout i= 1, . . . , n, on noteYi(t) =1XiØt l’indicateur que l’individu i soit à risque de décéder au tempst. Il vaut 1 si l’individu i n’a pas subi l’évènement d’intérêt avant tet n’a pas été censuré, et0 sinon. On note
Ni(t) =1TiÆt, TiÆCi,
1.1. Introduction à l’analyse de survie 19 le processus de comptage valant 1 à partir du temps de décès de l’individu i et0 avant. Ce processus est toujours nul si l’individu est censuré. La somme de ces processus de comptage individuels permet de définir le processus de comptage
N(t) =¯ ÿn
i=1
Ni(t),
qui a un saut de taille 1 à chaque temps de décès. Dans notre étude, on suppose qu’il n’y a pas d’ex aequo : chaque temps de décès correspond au décès d’un seul individu.
On note Mp◊p(R) l’ensemble des matrices de dimension p◊p à coefficients réels. Soit AœMp◊p(R). Le produit A¢2 est la matrice dont l’élément (i, j) est A¢2i,j =AiAj pour i, j= 1, . . . , p. De plus,ÎAÎ= max{|Ai,j|, i, j= 1, . . . , p} est la norme sup de la matriceAet ÎaÎ= max{|ai|, i= 1, . . . , p}la norme sup du vecteuraœRp. Dans la suite du manuscrit, sauf mention du contraire, les normes des vecteurs et matrices seront leur norme sup.
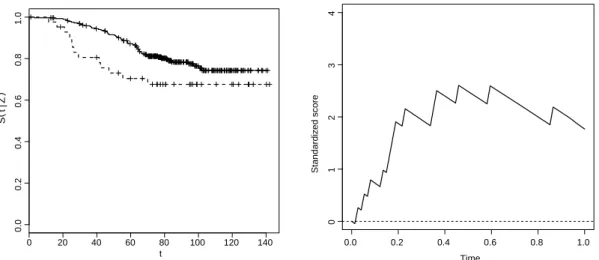
1.1.3 Estimateur de Kaplan–Meier de la survie
En présence de censure, les durées complètes T1, . . . , Tn ne sont pas toutes observées. Ainsi, l’estimateur usuel de la fonction de répartition empirique deT,
Fˆemp(t) = 1 n
ÿn i=1
1TiÆt, 0ÆtÆT,
ne peut pas être évalué. Sans données censurées, cet estimateur sans biais deF(t) =P(T Æt) peut être utilisé. Une solution pour estimer F pourrait être de considérer les temps censurés comme des décès et d’utiliser l’estimateur
1≠1 n
ÿn i=1
Yi(t) = 1 n
ÿn i=1
1XiÆt, 0ÆtÆT.
Cet estimateur de la fonction de répartition de T est biaisé si l’échantillon comporte de la censure. Son espérance au temps t vaut P(T Æt, C Æt), menant à une sous-estimation de P(T Æt). Kaplan et Meier (1958) ont introduit un estimateur convergent de F qui tient compte de la censure.
Définition 1.1.1. L’estimateur de Kaplan–Meier de F, noté Fˆ, est défini par Fˆ(t) = 1≠ Ÿ
i= 1, . . . , n
XiÆt
A
1≠ ”i qn
j=1Yj(Xi) B
, 0ÆtÆT.
Cet estimateur est une fonction constante par morceaux, continue à droite et limite à gauche, avec un saut à chaque temps de décès observé. Les sauts sont croissants ce qui permet de compenser le manque d’observations dans les queues de la distribution, c’est–à–dire pour les grandes valeurs du temps. Si aucune donnée n’est censurée, l’estimateur se réduit à l’estimateur
de la fonction empirique Fˆemp. Notons que l’estimateur de Kaplan–Meier est convergent en faisant l’hypothèse d’indépendance entre la censureC et la durée jusqu’à l’évènement d’intérêt T. L’estimateur de Kaplan–Meier de la fonction de survie deT au tempst,P(T Øt), est défini
par S(t) = 1ˆ ≠Fˆ(t). (1.1)
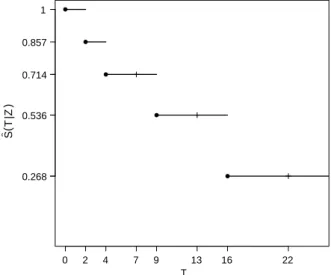
Illustrons le calcul de l’estimateur sur un exemple. Supposons que l’on dispose des 7 ob- servations de la Table 1.1.
X 2 4 7 9 13 16 22
” 1 1 0 1 0 1 0
Table1.1 – Données pour l’exemple du calcul de l’estimateur de Kaplan–Meier Les temps7, 13et22sont des temps de censure et les autres temps correspondent à des temps de décès. La Table 1.2 illustre la construction de l’estimateur de Kaplan–Meier. Dans cette table sont recensées les valeurs de l’estimateur aux temps observés. Sitœ[Xi, Xi+1[alors S(t) = ˆˆ S(Xi). On remarque que la valeur de l’estimateur ne change pas aux temps censurés.
Xi qnj=1Yj(Xi) 1≠”i/qnj=1Yj(Xi) S(Xˆ i)
2 7 1-1/7 1-1/7ƒ0.857
4 6 1-1/6 (1-1/7)(1-1/6)ƒ0.714
7 5 1 0.714
9 4 1-1/4 (1-1/7)(1-1/6)(1-1/4)ƒ 0.536
13 3 1 0.536
16 2 1-1/2 (1-1/7)(1-1/6)(1-1/4)(1-1/2)ƒ0.268
22 1 1 0.268
Table1.2 – Exemple de calcul de l’estimateur de Kaplan–Meier
La Figure 1.1 représente l’estimateur de Kaplan–Meier Sˆ en fonction du temps. Notons que l’estimateur n’atteint pas la valeur,0car le dernier temps observé est un temps censuré.
L’amplitude du saut de l’estimateur de Kaplan–Meier au temps t est notée dS(t). Leˆ résultat suivant permet de quantifier l’amplitude du saut deSˆ à chaque instant de décès.
Proposition 1.1.1. Soittun temps de décès observé. Nous avons la relation
dS(t) = ˆˆ S(t)≠S(tˆ ≠) = S(tˆ ≠) qn
j=1Yj(t), (1.2)
oùS(tˆ ≠) = lim
sæt≠
S(s).ˆ
Preuve de la Proposition 1.1.1. Soitlœ{1, . . . , n}. Supposons que l’individuldécède au temps t: on observe les réalisationsXl=tet”l= 1.
S(t)ˆ ≠S(tˆ ≠) = Ÿ i= 1, . . . , n
XiÆt
A
1≠ ”i
qn
j=1Yj(Xi) B
≠ Ÿ
i= 1, . . . , n
XiÆt≠
A
1≠ ”i
qn
j=1Yj(Xi) B
1.1. Introduction à l’analyse de survie 21
0 2 4 7 9 13 16 22
0.268 0.536 0.714 0.857 1
ˆ S(T
|Z)
T
Figure 1.1 – Exemple d’estimateur de Kaplan–Meier en fonction du temps
= Ÿ
i= 1, . . . , n
XiÆt≠
A
1≠ ”i
qn
j=1Yj(Xi) B A
1≠ ”l
qn
j=1Yj(Xl)≠1 B
= ˆS(t≠) ”l
qn
j=1Yj(t)= S(tˆ ≠) qn
j=1Yj(t).
Les incréments de l’estimateur de Kaplan–Meier peuvent être utilisés pour pondérer des variables dépendantes du temps intégrées par rapport à N. Les intégrales résultantes, dites¯ intégrales de Kaplan-Meier, convergent alors vers l’espérance de fonctions de T et ne sont pas biaisées en présence de censure.Stute(1995) a montré la normalité asymptotique des intégrales de Kaplan–Meier sous de bonnes conditions. Pour ajuster un modèle à risques proportionnels de paramètre—alors que l’effet—(t)inconnu change avec le temps,Xu et O’Quigley(2000) ont pondéré l’équation estimatrice du coefficient de régression du modèle à risques proportionnels par les incrémentsdS. L’estimateur obtenu converge versˆ E(—(T)). Sans les pondérations, les auteurs montrent que l’estimateur de la vraisemblance partielle de Cox ne converge pas vers E(—(T))lorsque l’effet—(t)n’est pas fixe dans le temps.
Il est possible d’exprimer l’estimateur de Kaplan–Meier de la fonction de répartition de T comme une somme pondérée, avec des poids dépendants de l’estimateur de Kaplan–Meier de la fonction de répartition de la censure (Satten et Datta, 2001). On peut montrer que l’estimateur de Kaplan–Meier est uniformément convergent et asymptotiquement normal.
L’analyse de survie consiste à modéliser des durées, c’est-à-dire des variables aléatoires po- sitives. De nombreux modèles ont été développés pour cette modélisation. Dans ce travail, nous considérons le cas d’un modèle semi-paramétrique très fréquemment utilisé en analyse de sur- vie, le modèle à risques proportionnels ainsi que son extension à des risques non proportionnels.
En Section 1.2, nous présentons les deux modèles et nous nous intéressons particulièrement aux
méthodes d’estimation qui ont été proposées dans ces modèles, avant de présenter quelques modèles alternatifs utilisés en analyse de survie. En Section 1.3, nous introduisons le test du log–rank. Ce test, très répandu dans les applications, permet de tester si les temps de survie de plusieurs groupes de patients sont différents. Une bibliographie sur des alternatives à ce test ainsi que ses améliorations seront présentées au Chapitre 4. Enfin, la Section 1.4 abordera les questions de l’adéquation et de la prédiction dans le modèle à risques proportionnels, qui seront approfondies au Chapitre 5.
1.2 Modèle à risques proportionnels et extensions
1.2.1 Modèle à risques proportionnels
Le modèle à risques proportionnels est défini à partir du risque instantané. Introduisons cette quantité avant d’expliquer les particularités du modèle.
Définition 1.2.1. Le risque instantané, ou taux de hasard, de la variable aléatoire positiveX est la fonction⁄ telle que
⁄(t) = lim
h¿0
P(Xœ[t, t+h[ |XØt)
h , tØ0.
SiX représente la durée de vie d’un individu, le risque instantané de X calculé au temps ts’interprète comme la probabilité que l’individu décède juste aprèst, sachant qu’il a survécu jusqu’en t. Ce risque définit de manière unique chaque distribution, au même titre que la densité ou la fonction de répartition. Ceci justifie la définition d’un modèle à partir de cette quantité. On peut montrer que la fonction de survie et le risque instantané sont liés par la relation
S(t) = exp3≠
⁄ t
0 ⁄(s)ds4, tØ0. (1.3) Nous rappelons que Z(t) représente un vecteur de p covariables pouvant dépendre du temps. Par exemple, il peut s’agir du sexe du patient, de son âge lors de l’inclusion dans l’étude, de niveaux de biomarqueurs relevés à différentes dates, du stade de sa maladie, etc. Des modèles paramétriques ont été considérés pour relier les covariables au temps de survie, par exemple les modèles de vie accélérée avec une fonction de survie de base connue. L’avantage de ce modèle réside dans la simplicité d’estimation et d’interprétation des paramètres, mais il est très restrictif. Nous reviendrons plus en détail sur ce modèle dans la Section 1.2.3. Pour assouplir la relation entre Z et T, il est envisageable d’utiliser des méthodes non paramétriques. Par exemple,Stute(1993) a proposé un estimateur de type Kaplan–Meier pour estimer la fonction de répartition P(T Æt, ZÆz). L’interprétation devient alors plus délicate. L’utilisation d’un modèle semi-paramétrique permet à la fois d’interpréter aisément les paramètres liant le temps de survieT aux covariables Z, tout en gardant un lien souple entre les deux. Le modèle semi- paramétrique que nous considérons est le modèle à risques proportionnels avec une fonction de lien exponentielle entre les covariables et le risque instantané.
1.2. Modèle à risques proportionnels et extensions 23
Définition 1.2.2. Le modèle à risques proportionnels est défini par
⁄(t|Z) =⁄0(t)exp{—TZ(t)}, tØ0, (1.4) où⁄0 est un risque instantané de base et —T est le vecteur transposé du vecteur—œRp.
Le vecteur—est le vecteur de coefficients de régression associé àZ(t). Ce modèle a été in- troduit parCox(1972) qui a considéré des covariablesZconstantes au cours du temps. Le mo- dèle (1.4) est couramment appelé "modèle de Cox". L’extension à des covariables dépendantes du temps est immédiate. Avant de discuter des hypothèses du modèle, nous présentons la mé- thode d’estimation du coefficient de régression —. L’intérêt de ce modèle semi-paramétrique réside dans la séparation de la fonction temporelle⁄0 du coefficient de régression—. Ainsi, en maximisant la vraisemblance partielle deCox(1972,1975), l’estimation du paramètre—peut se faire sans spécifier ni estimer la fonction⁄0. L’estimation du risque de base cumulé,s⁄0(s)ds, peut s’effectuer notamment avec l’estimateur de Nelson–Aalen, mais nous ne donnons pas plus de détails ici (Aalen,1978, Nelson, 1972).
En conditionnant sur l’existence d’un décès au tempstet sur la connaissance des individus encore à risque de décéder à ce temps, la probabilité que l’individui décède entest
fii(—, t) =q Yi(t)exp{—TZi(t)}
nj=1Yj(t)exp{—TZj(t)}, i= 1, . . . , n. (1.5) Remarque 1.2.1. En pratique, la covariable de l’individu i, Zi(·), n’est pas observée aux temps supérieurs àXi, ce qui implique que la covariable Zi(t) n’est pas définie pourt > Xi, i= 1, . . . , n. Nous choisissons d’associer la dernière valeur observée de la covariable pour les temps supérieurs au temps de décès. Dans la formule précédente, cela revient à remplacerZi(t) parZi(min(t, Xi)), mais nous ne l’écrivons pas pour des raisons de lisibilité. Cette définition suppose que les valeurs des covariables des individus sont connues à tous les temps de décès jusqu’à ce qu’ils soient censurés ou décèdent à leur tour. Cette hypothèse est courante pour traiter des covariables dépendantes du temps (Andersen et Gill, 1982). Une autre manière de contourner le problème serait d’annuler la valeur de la covariable pour les temps supérieurs au temps observé : Zi(t) = 0 sit > Xi, i= 1, . . . , n (Arjas, 1988). Cette remarque s’applique également aux quantités définies ci–après.
Notons que l’on peut calculer l’espérance et la variance deZ(t)par rapport aux probabilités fii(—, t),i= 1, . . . , n.
Définition 1.2.3. Soit tœ [0,T]. L’espérance et la variance de Z par rapport à la famille de probabilité{fii(—, t), i= 1, . . . , n}sont respectivement un vecteur de Rp et une matrice de Mp◊p(R)tels que
E—(Z|t) =ÿn
i=1
Zi(t)fii(—, t) = (E—(Z|t)1, . . . ,E—(Z|t)p), (1.6)
et
V—(Z|t)a,b=ÿn
i=1
Zi(a)(t)Zi(b)(t)fii(—, t)≠E—(Z|t)aE—(Z|t)b, (1.7) où V—(Z|t)a,b est l’élément en aème ligne et bème colonne de la matrice V—(Z|t), avec a, b= 1, . . . , p.
L’espérance E—(Z|t) correspond à la valeur attendue de la covariable de l’individu qui décède en t sous le modèle à risques proportionnels de paramètre —, où t est un temps de décès. Cette quantité interviendra pour calculer des résidus et elle sera comparée à la valeur observée de la covariable de l’individu qui décède. Nous y reviendrons en Section 1.4.
Chaque contribution à la vraisemblance partielle de Cox sous le modèle à risques propor- tionnels (1.4) de paramètre—, notéeLn(—), est la probabilitéfii(—, Xi)lorsqueXi correspond au temps de décès de l’individui :
Ln(—) =Ÿn
i=1
fii(—, Xi)”i.
L’estimation du paramètre— s’effectue en maximisant la log–vraisemblance partielle notéeln
telle que
ln(—) = log(Ln(—)) =ÿn
i=1
⁄ T
0
Y]
[—TZi(t)≠log Q a
ÿn j=1
Yj(t)exp(—TZj(t)) R b Z^
\dNi(t).
Il s’agit alors de trouver le vecteur — qui annule le score U(—), c’est-à-dire la dérivée de la log–vraisemblance partielle en— :
U(—) = ˆ
ˆ—ln(—) =ÿn
i=1
⁄ T
0 {Zi(t)≠E—(Z|t)}dNi(t). (1.8) La dérivée seconde de la log–vraisemblance partielle par rapport au vecteur — est négative puisqu’il s’agit de l’opposé deI(—), où
ˆ
ˆ—U(—) =≠I(—) =≠ ÿn
i=1V—(Z|Xi)”i<0.
La log–vraisemblance partielle étant strictement concave, le vecteur — qui annule le score réalise le maximum de la vraisemblance partielle. On note ce vecteur—ˆet on aU( ˆ—) = 0. De nombreux ouvrages traitent de l’estimation du paramètre, nous renvoyons à l’un d’entre eux pour plus de détails (Kalbfleisch et Prentice, 2002).
Le modèle à risques proportionnels que nous considérons est particulier, car il repose sur l’hypothèse de log–linéarité entre les covariables et la fonction de risque. En relâchant cette hypothèse, nous obtenons encore un modèle à risques proportionnels défini par
⁄(t|Z) =⁄0(t)r{—TZ(t)},
1.2. Modèle à risques proportionnels et extensions 25 oùrest une fonction positive comme, par exemple,r(x) = 1+xour(x) = 1/(1+x)(Taulbee, 1979). Sous ce modèle, les risques sont toujours proportionnels mais le logarithme du risque instantané, s’il est fini, n’est pas linéaire en les paramètres. Le modèle à risques proportionnels défini équation (1.4), dit modèle à risques proportionnels de Cox, se retrouve en choisissant r(x) = exp(x). Prentice et Self(1983) ont étudié le comportement asymptotique de l’estima- teur du maximum de vraisemblance partielle de ce modèle plus général. Des illustrations du modèle sont présentées dansAndersenet al.(1993).Taulbee(1979) a proposé une extension du modèle à risques proportionnels en considérant un risque instantané polynomial de la forme
⁄(t|Z) =ÿm
k=0
⁄ktkh(—k, Z), mœNú,
oùhest une fonction positive à choisir. Il a notamment considéré le cash(—k, Z) = exp(—kTZ).
Il s’agit alors d’estimer paramétriquement—0,—1, . . . ,—met⁄0,⁄1, . . . ,⁄m, dans un modèle très souple et moins restrictif que le modèle à risques proportionnels (1.4).
En pratique, le modèle à risques proportionnels (1.4) est très utilisé, de par sa simplicité d’interprétation. En effet, si p= 1etZ est une variable de Bernoulli, alors
⁄(t|Z= 1)
⁄(t|Z= 0)= exp(—), tØ0. (1.9)
Ainsi, le risque instantané de décès relatif entre les groupes correspondants àZ= 1etZ= 0 estexp(—). Le risque relatif est une mesure très utilisée en épidémiologie, notamment dans les enquêtes de cohorte visant à trouver des facteurs de risque associés à une certaine maladie.
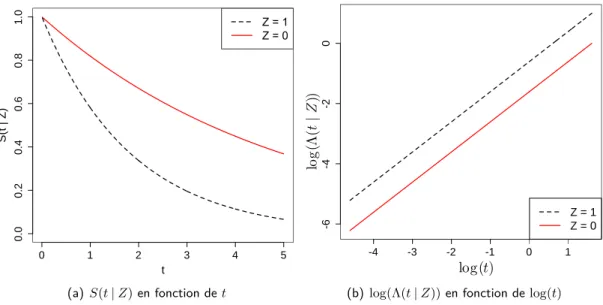
Dans le modèle de Cox, le risque relatif est constant au cours du temps d’après l’équation (1.9), c’est pourquoi le modèle est aussi appelé modèle à risques proportionnels. Cette dernière appellation est plus globale, car elle autorise les covariables à dépendre du temps. L’équation (1.3) permet d’écrire le modèle à risques proportionnels (1.4) à partir de la fonction de survie conditionnelle
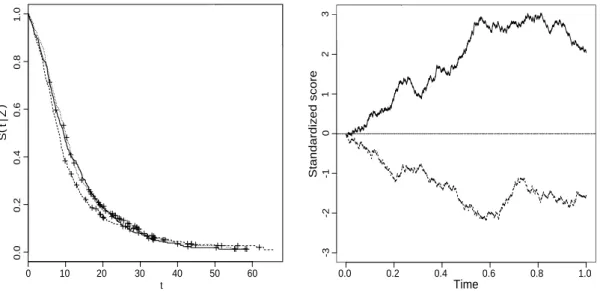
S(t|Z) = exp;≠exp(—TZ)⁄ t
0 ⁄0(s)ds<, tØ0. (1.10) Notons (t|Z) =s0t⁄(s|Z)dsle risque instantané cumulé conditionnel aux covariables au tempst. La Figure 1.2 représente les courbes de survie S(t|Z)et les log risques instantanés cumulés log( (t|Z)) sous le modèle à risques proportionnels en fonction du temps t. Dans cet exemple,Zest une variable catégorielle prenant les modalités0ou1et⁄0 est une fonction constante. L’hypothèse de proportionnalité des risques est visible sur le graphique du logarithme des risques cumulés puisque les deux courbes parallèles. L’écart entre les courbes de survie est croissant en fonction du temps, ce qui traduit graphiquement l’équation (1.10) où les deux fonctions de survie conditionnelles sont liées par une relation puissance.
L’hypothèse des risques proportionnels, appréciable pour l’interprétation, est très forte.
Supposons que les deux groupes de patients représentent deux groupes de traitement : un groupe reçoit le placebo et l’autre un nouveau traitement. Si le modèle est respecté, alors
0 1 2 3 4 5
0.00.20.40.60.81.0
t
S(t | Z)
!"#"$
!"#"%
(a)S(t|Z)en fonction det
-4 -3 -2 -1 0 1
-6-4-20log(⇤(t|Z))
Z = 1 Z = 0
log(t)
(b) log( (t|Z))en fonction delog(t)
Figure1.2 – Exemple de courbes de survie et de risque instantané sous le modèle à risques proportionnels.
l’effet entre les groupes est constant au cours du temps. Or, il a été souvent observé que l’effet d’un médicament peut s’estomper avec le temps à cause de l’accoutumance. A l’inverse, l’effet d’un traitement peut être tardif. Enfin, un cas plus particulier est celui d’un effet qui change de signe. Ce cas peut être illustré par l’exemple d’un traitement chirurgical, dont l’effet est négatif dans un premier temps puisque le risque de décès est élevé lors de l’opération. Par la suite, les patients ont survécu à l’opération et l’effet du traitement devient positif. Utiliser les résultats d’estimation du modèle à risques proportionnels alors que le vrai effet dépend du temps peut mener à des erreurs d’interprétation des données. L’hypothèse des risques proportionnels est très forte et peut être assouplie en considérant un effet qui dépend du temps.
1.2.2 Modèle à risques non proportionnels
Les modèles à risques non proportionnels sont plus souples que le modèle à risques proportion- nels, car ils ne font pas l’hypothèse d’un risque relatif constant au cours du temps. Beaucoup de modèles font partie de la classe de modèles à risques non proportionnels. Dans cette thèse, nous appelons modèle à risques non proportionnels une extension du modèle à risques proportionnels de Cox dans lequel le coefficient de régression peut varier avec le temps.
Définition 1.2.4. Le modèle à risques non proportionnels est défini par
⁄(t|Z) =⁄0(t)exp{—(t)TZ(t)}, (1.11) où⁄0 est un risque instantané de base et —(t) = (—1(t), . . . ,—p(t)) un vecteur de fonctions de [0,T] dansRp.
Le modèle à risques proportionnels est un cas particulier de ce modèle plus général, qui se
1.2. Modèle à risques proportionnels et extensions 27 retrouve lorsque —(t) est constant. Plusieurs méthodes ont été proposées pour estimer —(t).
Nous les classons selon qu’elles consistent en une maximisation simple de la vraisemblance par- tielle, une maximisation d’une transformation de la vraisemblance ou qu’elles soient itératives.
Maximisation de la vraisemblance partielle
La première méthode consiste à transformer la fonction —(t) en un vecteur de paramètres et à maximiser la vraisemblance partielle en ces paramètres. La transformation de —(t) en un vecteur de paramètres peut se faire en considérant des coefficients de régression de la forme
—i(t) =—0,ihi(t), pour i= 1, . . . , p,
avechi une fonction déterministe, par exemple, linéaire (Cox, 1972), constante par morceaux (Brown, 1975) ou polynomiale (Stableinet al., 1981). Le modèle s’écrit alors
⁄(t|Z) =⁄0(t)exp A p
ÿ
i=1
—0,ihi(t)Z(i)(t) B
.
La partie temporelle du coefficient de régression,hi(t), peut être associée à laième covariable Z(i)(t), ce qui se ramène à estimer le vecteur de paramètres —0= (—0,1, . . . ,—0,p) associé au vecteur de covariables dépendantes du temps(h1(t)Z(1)(t), . . . , hp(t)Z(p)(t)).
Anderson et Senthilselvan (1982) ont étudié un effet de la forme—(t) =–1tÆB+“1t>B, en estimant les paramètres –, “ et B par maximisation de la vraisemblance partielle. Plus généralement, les modèles de rupture sont des cas particuliers de modèles à risques non pro- portionnels dans lesquels le coefficient —(t) est constant par morceaux, avec des temps de rupture spécifiés ou non (O’Quigley, 2008, chap. 12).
Moreauet al.(1985) ont considéré l’effet—(t) =—0+G(t)oùGest une fonction constante par morceaux avec des ruptures à des temps prédéfinis. Ils ont développé un test du score de l’hypothèse nulleH0: G= 0. Ce test permet de tester l’adéquation du modèle (1.4) puisque, sousH0, les risques sont proportionnels. Grambsch et Therneau(1994) ont étendu cette idée en considérant un effet de la forme—(t) =—0+◊g(t)et en proposant à la fois une classe de tests pour une fonctiong déterministe ou aléatoire mais prévisible, ainsi qu’un estimateur du paramètre◊.
L’avantage des approches présentées jusqu’ici est d’obtenir un estimateur explicite de—(t) et facile à interpréter, ce qui n’est pas toujours le cas avec les méthodes non paramétriques présentées dans la suite. Une autre possibilité pour transformer la fonction—(t)en un vecteur de paramètres est de la projeter sur une base de fonctions connue avant de maximiser la vraisemblance partielle. Par exemple, Hess (1994) a utilisé une base de splines cubiques et Abrahamowicz et al. (1996) une base de splines quadratiques. Murphy et Sen (1991) ont projeté le coefficient sur une base d’histogrammes, l’estimateur résultant étant constant par morceaux sur des intervalles de temps prédéfinis.Murphy(1993) a développé un test du score basé sur cet estimateur, pour tester l’adéquation du modèle à risques proportionnels (1.4).
Autrement dit, tester l’égalité des différents coefficients projetés sur la base revient à tester si les données respectent bien l’hypothèse de proportionnalité des risques. Marzec et Marzec (1997) ont proposé des tests d’adéquation du modèle à risques non proportionnels basés sur un processus de résidus de martingales avec l’estimateur de —(t) de Murphy et Sen (1991).
Nous reviendrons sur ces deux tests d’adéquation au Chapitre 5.
Maximisation d’une transformation de la vraisemblance partielle
La seconde catégorie de méthodes d’estimation du coefficient —(t) du modèle à risques non proportionnels consiste à maximiser la log–vraisemblance transformée, soit par pénalisation, soit par pondération. Le problème de maximisation en—(t)de la log–vraisemblance pénalisée s’écrit
—(t)œmaxB
)ln(—(t))≠pen(—(t))*. (1.12) L’ensembleB sur lequel est projeté —(t) et la pénalisation pen changent selon les cas. L’uti- lisation d’une pénalisation permet de lisser l’estimateur résultant en imposant une certaine régularité sur sa structure.
Zucker et Karr (1990) ont considéré l’ensemble B des fonctions m–différentiables par morceaux, pourm entier supérieur à 2 et une pénalisation dépendante de lam–différentielle de —(t). Ils ont obtenu des résultats de convergence de l’estimateur résultant pourmØ3et de normalité asy