Neural Machine Translation is one of the most important tasks in Natural Language Processing. Multimodal machine translation uses additional modalities such as images and speech to ground and enhance the translation task, provided they contain alternative representations of the input data. We focus our work on investigating multiple variations of the same system to integrate visual features into a neural machine translation system.
The results of the mask predictions show that it is more likely that the systems actually use additional modalities when the text is not sufficient, while the text model makes predictions based on the training bias. Being welcomed and included as a new member of the group meant a lot to me.

Introduction
Related Work
Problem Definition
Visualize the quality of results and attention scores at each layer of the transformer.
Delimitations
Ethical Considerations and Gender Aspects
During training, the decoder sequentially takes the beginning of a sentence token and a sentence word in the target language while using the produced context vector as its initial hidden state. At each step, the model generates the probability distribution of the next wordˆi to calculate the loss. Backpropagation is end-to-end, one end is lossy and the other is the start of the encoder, so the gradients flow through the entire system without this total loss.
The problem with the Seq2Seq architecture is that the created encoding of the source sentence by the Encoder RNN represents the entire sentence in a single vector. This problem introduced a technique called Attention Mechanism, which today has replaced conventional encoder-decoder architectures as a baseline in neural machine translation and many other tasks.
Attention Mechanism
A more general definition of attention is the following: Given a set of vector values V and a vector query Q, attention is a technique for computing a weighted sum of the values that depend on the query. In the case of the Seq2Seq model, each hidden state of the decoder is the query and that query concerns all the hidden states of the encoder which are the values. Therefore, attention can be seen as a way to obtain a fixed-size representation of an arbitrary set of representations V by using the query Q, where the calculated weighted sum is a selective summary of the information contained in the values.
Several reasons have focused attention on encoder-decoder architectures as the current baseline rather than the conventional Seq2Seq architecture described in 2.1. As the size of the input sentence increases, simple encoder-decoder architectures miss information by using only the final representation.
Transformer architecture
Transformer Sublayers and Components
- Positional-Encoding
- Attention in the Transformer
- Position-wise Feed-Forward Network
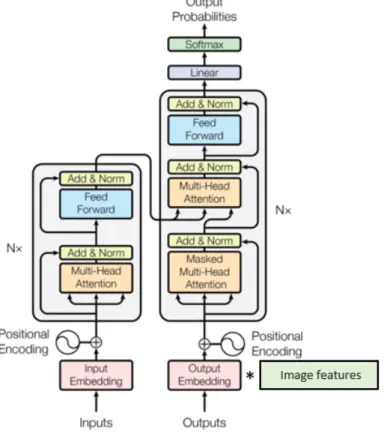
In this subsection, we explain each Transformer component separately to better understand the architecture. Since there is no repetition in the Transformer architecture, there should be a way to determine the position of each word. For this purpose, positional encodings are added to the embeddings of the encoder and decoder inputs, which are essentially vectors that contain positional information and give the network a sense of word order.
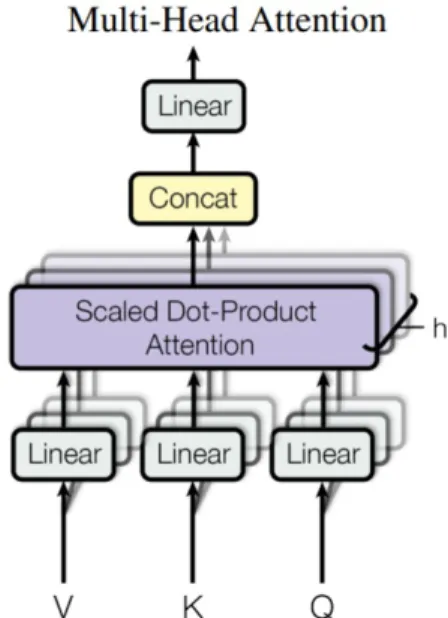
The attention function used in the model is called Scaled Dot-Product Attention (see eq. 2.10) which is a dot-product attention as described in 2.2 except that it uses a scaling factor to avoid small gradients in the softmax function . The dot product between the queries and keys of the same dimension dk is calculated and then divided by√. Both encoder and decoder apply this scaled dot product attention between h different linear projections of their queries, keys and values in different layers or heads in parallel.
The self-attention means that we get a different representational subspace of the same sentence that attends to itself in the different heads. Thus, each position of the encoder or decoder can attend to all positions of the previous head. For the decoder, a masking is used before applying the softmax function to prevent left information flow in the decoder and preserve the auto-regressive property.
In the decoder, apart from the multi-head self-attention layer where the decoder input attends to itself, we have another multi-head attention layer which is the encoder-decoder attention as seen in Seq2Seq models that helps the decoder to focus on source. A fully connected feed-forward network is used in each encoder and decoder layer after the multi-head attention. Visual data: For the multimodal model, we use pre-extracted global average pooled image features of dimension 2048 from a pre-trained ResNet50 [27] on Imagenet [31], provided by the organizers of the competition.
Transformer Architecture Variations
We use the Multi-30k dataset [29] introduced for the WMT16 Shared Task on Multimodal Translation and Image Description [5]. The dataset consists of 29000 training, 1014 validation and 1000 test sentences describing an image for the task with English to French, German and Czech translation. For the multimodal task, the dataset provides images and pre-extracted image features from a 50 layer residual neural network [27].
For English-German, translations were produced by professional translators who were given only the source segment or the source segment and image. For English-French, translations were produced via multiple sources where translators had access to the source segment, the image, and an automatic translation created with a standard phrase-based system as a suggestion to make translation easier. For English-Czech, the translations were crowd-sourced, where the translators had access to the source segment and image.
We use the English sets as our source and the other languages as our targets. To exploit the image features, we linearly project them to dimension 512 to match the model dimension.

Training and Hyperparameters
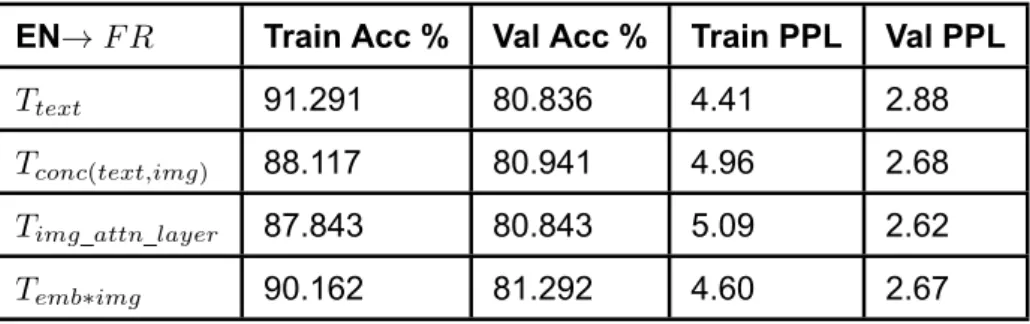
We present the training and validation accuracy and complexity for each system trained in each language. Accuracy is calculated by dividing the number of correct words by the total number of words, while confusion is the exponent of our loss. For English to French presented in Table 1, the latter Temb*img system, where image features are multiplied by target embeddings, achieves the highest verification accuracy, while our baselineTtext has the lowest accuracy and best fit among the models.
For both English-to-German and English-to-Czech, the Tconc(text,img) model performs best in terms of validation. The Timg_attn_layer gives the lowest validation accuracy for German and Czech, but lower confusion compared to the text-only network.

Evaluation Metrics
As a reference to compare our results, we should mention the best scores between the submissions of the shared task.
Example Translations
Attention Visualization
Timg_attn_layer : un petit orchestre jouant du violon ouvert devant deux personnes. TEMB ∗ IMG : UN PETIT ORCHESTRE JOUANT AVEC UN Violon ouvert devant Une
TGT FR : une fille en blanc et une fille en vert passent un lave-auto bleu. Texte : une fille en blanc et une fille en vert passent devant une voiture bleue. Tconc(text,img) : une fille en blanc et une fille en vert passent devant une gare routière bleue.
Timg_attn_layer : une fille en blanc et une fille en vert passent devant une voiture bleue à côté d'une gare bleue. TEMB ∗ IMG: une fille en blanc et un de fille en vert passant Devant une station de voture bleue en train de
Timg_attn_layer: ein mädchen in weiß und ein mädchen in grün gekleidet , gehen an einer blauen vorbei. TEMB ∗ IMG: EIN Mädchen v Weiß und Ein Mädchen v Grün Gehen in Einem Blauen
Temb∗img: the man in the japanese is prepared to be and prepared for an end. The heatmaps show the evolution of the representations passing through the different layers and how each step and step in encoding and decoding affects a different word, creating new representation subspaces.

Color Masking
Tconc(text,img) : une femme en t-shirt rouge levant le bras vers la foule en contrebas. Temb∗img : Une femme en T-shirt bleu lève le bras vers la foule qui marche en contrebas. TGT : Une femme lit un livre assise dans une rangée de fauteuils rouges.
Tconc(text,img) : une femme lit un livre assise sur une rangée de chaises rouges. Timg_attn_layer : une femme lit un livre assise sur une rangée de chaises rouges. Les systèmes de traduction automatique neuronale ne prennent en compte que le texte et ignorent les autres types de modalités.
Elliott, "A shared task on multimodal machine translation and crosslingual image description," i Proceedings of the First Conference on Machine Translation: Volume 2, Shared Task Papers, (Berlin, Tyskland), s. Frank, "DCU-UvA multimodal MT system report ,” i Proceedings of the First Conference on Machine Translation: Volume 2, Shared Task Papers, (Berlin, Tyskland), s. Dyer, “Opmærksomhedsbaseret multimodal neural maskinoversættelse,” i Proceedings of the First Conference on Machine Translation: bind 2, Shared Task Papers, (Berlin, Tyskland), s.
Vázquez, “Delivering MeMAD to the WMT18 multimodal translation task,” in Proceedings of the Third Conference on Machine Translation: Joint Papers, (Belgium, Brussels), p. Third Conference on Machine Translation: Joint Task Papers, (Belgium, Brussels), p.
![Figure 29: Translation results for masking the color [red] that refers to the word ”shirt”.](https://thumb-eu.123doks.com/thumbv2/pdfplayerco/298164.40904/44.892.369.543.111.380/figure-translation-results-masking-color-refers-word-shirt.webp)
![Figure 2: Neural Machine Translation with attention in Seq2Seq architecture [1].](https://thumb-eu.123doks.com/thumbv2/pdfplayerco/298164.40904/17.892.267.644.86.388/figure-2-neural-machine-translation-attention-seq2seq-architecture.webp)
![Figure 3: The original Transformer architecture presented in ”Attention is All You Need” [2].](https://thumb-eu.123doks.com/thumbv2/pdfplayerco/298164.40904/18.892.267.648.88.616/figure-3-original-transformer-architecture-presented-attention-need.webp)
![Figure 6: Multimodal Transformer with additional multi-head attention layer for the image features.(Image retrieved from [2])](https://thumb-eu.123doks.com/thumbv2/pdfplayerco/298164.40904/22.892.216.688.672.1111/figure-multimodal-transformer-additional-attention-features-image-retrieved.webp)