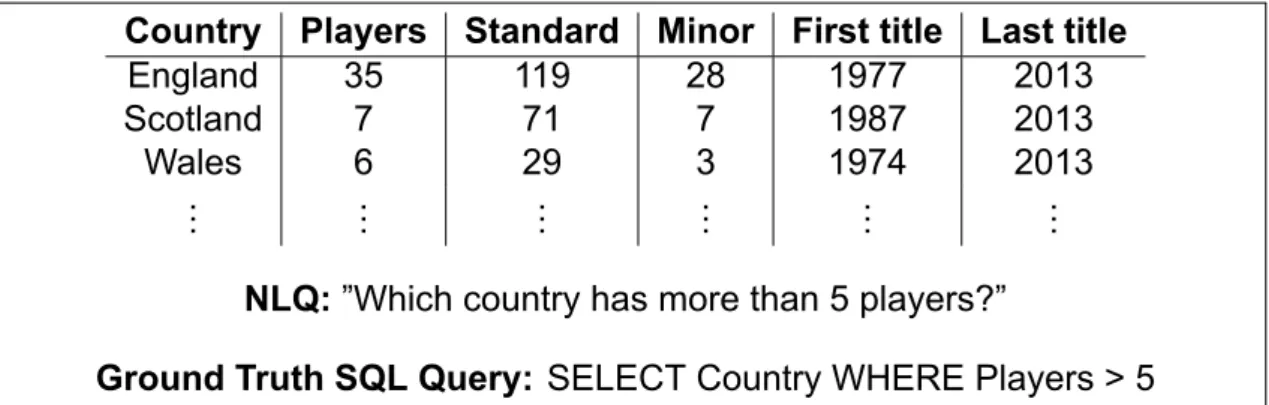
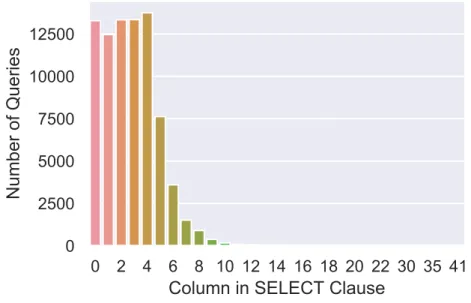
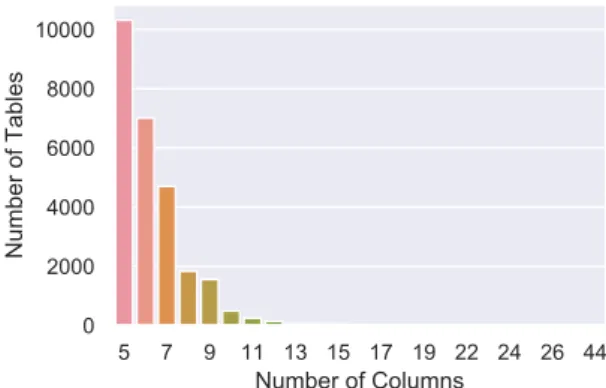
We will compare some systems and see how each of them chooses to tackle the problem. In the main part of this work, we will focus on the SQLNet system that uses deep learning methods to tackle the NL2SQL problem.
INTRODUCTION
The NL2SQL Problem
In such cases, a NL2SQL must be able to understand what the user is referring to, even if the exact word is not in the database. In either case, the system must be able to identify the inability to produce the expected result and inform the user accordingly.
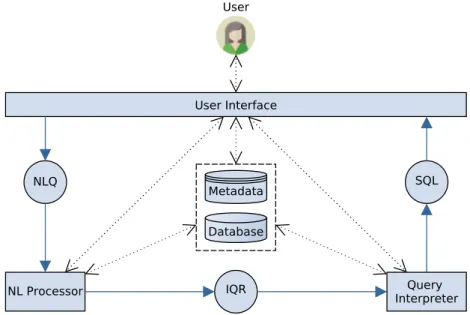
NL2SQL System Workflow
In the second case, the database may not be designed to answer a specific question asked by the user. The same applies to the user interface which can involve the user in the NL Processor or Query Interpreter processes.
BACKGROUND AND RELATED WORK
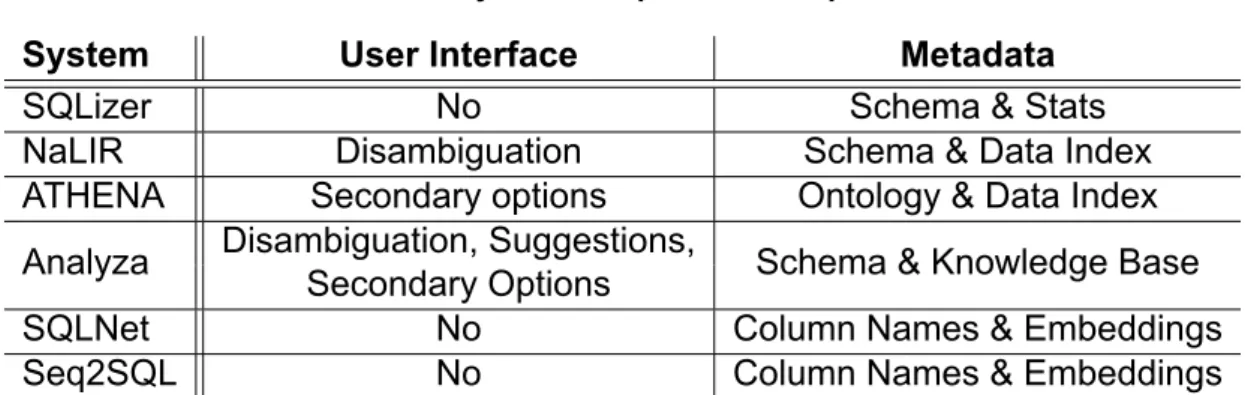
NL2SQL Systems Comparison
- Natural Language Processor NL ParsersNL Parsers
- Intermediate Query Representation
- Query Interpreter
- User Interface
- Metadata
When we receive the NLQ as a string from the user, there is not much we can do about it, but extracting each word in the sentence allows us to use each word separately (eg with word embeddings). Each word is then assigned a word embedding vector so that the final output of the NL processor is a sequence of word embeddings. The intermediate representation of the query is a choice with multiple possibilities and variations even between systems that treat the NLQ in the same or even the same way.
First, based on the schema created by the parser, it tries to find expressions that complement it, which are valid with respect to the database schema, and assigns a confidence score to each of them. The confidence score is an estimate of the probability that the way the schema is completed matches the user's intent and is calculated based on the NL hints provided by the parser, schema element names, foreign and primary keys, and database content. The first generates mappings to the SQL components of each node of the parse tree produced by the parser based on a similarity function.
To give the user an understandable overview or a visualization of the data to eliminate any confusion about what can be achieved by our database and minimize user errors. Analyza has an extensive metadata store and goes far beyond simply using the schema of the database.
Evaluation of Systems
The amount and types of data held by each system can range from the bare essentials (eg database schema) to some very sophisticated architectures that include knowledge that may not even be related to the current database in use. They use only the column names of the table targeted by the NLQ and rely on knowledge of their word embeddings described in Section 2.1.2. SQLizer also takes a relatively simple approach, using the database schema and various statistics about its contents to make sure it's generating valid queries and estimate the likelihood that the query is the one it's looking for.
For example, a query with a WHERE clause of the form WHERE x == c is given a low probability if the value c does not exist in the database. ATHENA also uses an interesting data index for keyword lookup that also supports variant generators that helps group similar names that refer to the same real-world entity (e.g. 'George Katsogiannis', 'G.Katsogiannis' and 'Giorgos Katsogiannis' refer to the same person and should be treated in the same way). What sets it apart from other systems is that it does not depend on the schema of the database, but works with ontologies and mapping functions that relate it to the DB and which must be provided by the designer of the DB.
In addition, it keeps track of every interaction with the user and tries to learn phrases and words classified as unknown on the first encounter, as well as requests to identify data not available in the database and respond accordingly. While this is unavoidable due to the nature of the problem and the varying levels of user inclusion, a common axis that allows NL2SQL systems to be clearly and consistently evaluated would be beneficial to efforts to address the problem.
Available Data Sets/Databases
Because of these functional differences, it is very difficult to make an exact comparison between all the systems we have presented. Another problem with comparing NL2SQL systems is the lack of available databases and NLQs with relevant SQL queries on which to test the systems. In addition to not being a complete relational database, another difference from all the other datasets mentioned is that it is not based on one specific domain, but rather each table contains data from different domains (e.g. sports, geography, etc.).
The FIN data set contains financial data and was created by IBM and used for the ATHENA system[16]. Since ATHENA works on ontologies rather than RDBs, the dataset is described by an ontology containing 75 concepts, 289 attributes and 95 relations, but it is also stored on an RDB with a normalized schema. Besides the datasets used by the systems we've discussed, there are a few more worth mentioning.
WikiTableQuestions is a dataset very similar to WikiSQL, containing questions on individual tables on a variety of domains, just like WikiSQL. The SCHOLAR dataset was released with [6] and contains 816 NLQs accompanied by SQL over an academic relational database.
THE WIKISQL TASK & DATASET
- The WikiSQL Subsets
- SQL Query Complexity
- Bad Questions
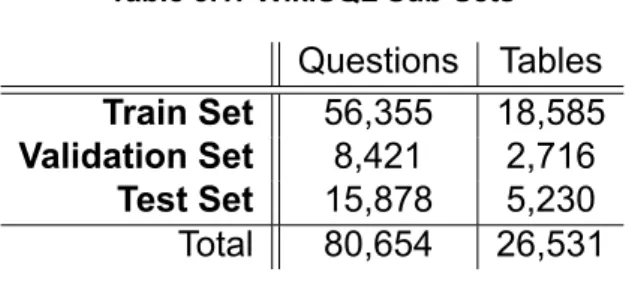
- WikiSQL Statistics
Validation set: To be used to check the performance of the model during training and possibly affect the training of the model, e.g. Each subset has its own unique tables, so the same query or table is never seen by the model in both training and testing. Because all queries target single tables, the resulting SQL queries are not as complex.
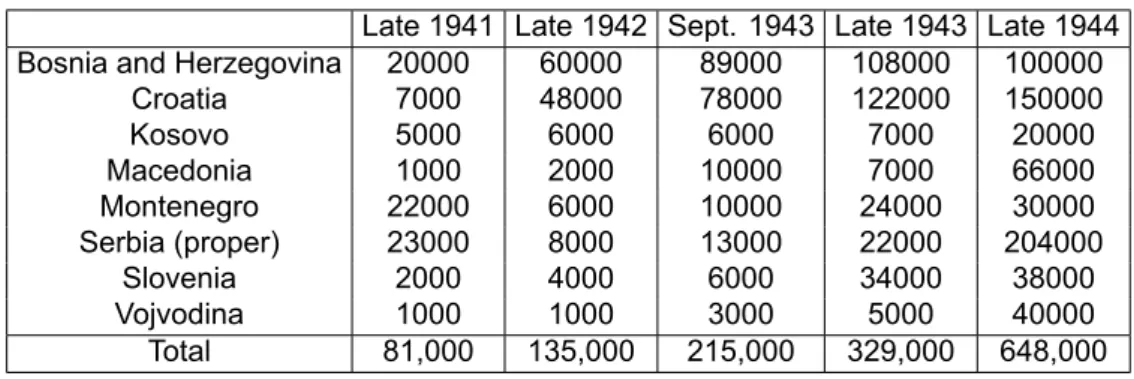
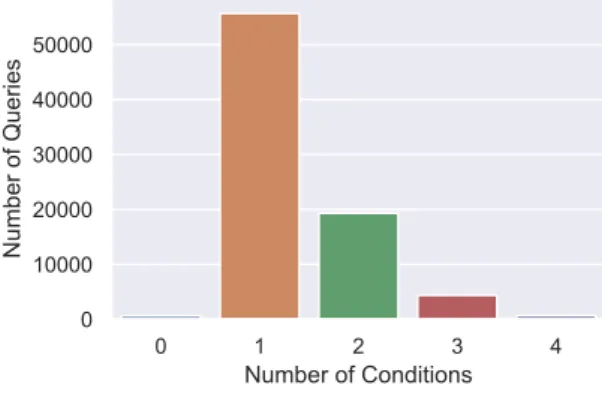
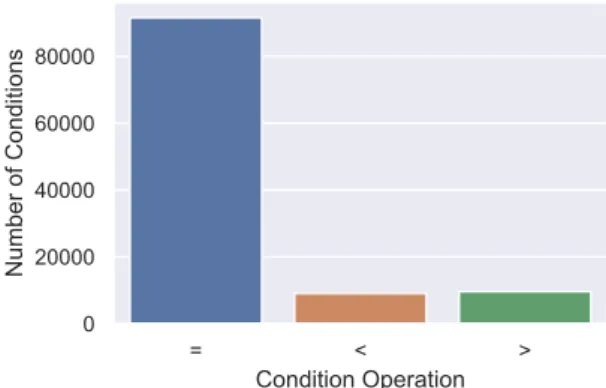
This is evident even by the way the SQL queries are stored in the dataset. A series of conditions (or no conditions) each consisting of: a) The column of the table to which the condition is applied (b). The correct table, seen in Table 3.3, can be found on a Wikipedia and refers to the Yugoslav Partisans of the Second World War.
Besides this table being unintelligible, the WikiSQL dataset actually contains queries asked in this table and even provides the expected SQL queries that should be produced from these queries. Here we see that the vast majority of SQL queries do not use an aggregation function.
Summary
For some SQL queries it is very difficult to understand why they match their equivalent NLQ. It doesn't seem to be very balanced, especially when it comes to the conditions of the SQL queries.
SQLNET
- SQL Sketch
- Dataflow in SQLNet
- Neural Query Translation Components
- Common Procedures
- Aggregation Function Predictor
- Column Selection Predictor
- Condition Number Predictor
- Condition Column Predictor
- Condition Operation Predictor
- Condition Value Predictor
- Programming Details
- Training Details
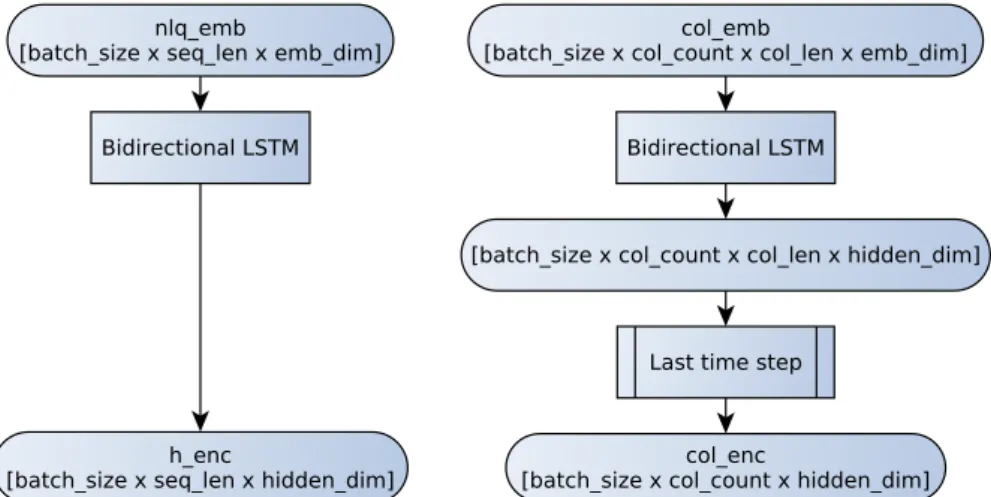
An example of the entire preprocessing procedure can be seen in figure 4.3, for NLQ and table column inputs. WhereEcol, EQ are the encodings of the column names and the NLQ anduc, uq, uaare the trainable matrices of the linear layers. The column selection predictor predicts which column of the table will be in the SELECT slot of the sketch.
The condition column predictor predicts the probability that each column of the table is present in the conditions of the query. The condition value predictor is a Sequence to Sequence (seq2seq) network that predicts the value of the condition (i.e. the value slot in Figure 4.1) for each column. This can be thought of as asking the component “If the first word is x, what will the second word of the condition value be?”.
Note that during this procedure, the entries of the NLQ branch and the column names branch do not change. An illustration of the condition string predictor training process can be seen in Figure 4.14. First, a word index is created, containing all the unique words of the data set to be used by the model.
We will use the same tokenization of the dataset produced using the Stanford CoreNLP Tokenizer [11].

EXPERIMENTS AND RESULTS
- Evaluation
- Trying to Maximize the Embedding Coverage of WikiSQL
- Testing on Database Views
- Interesting Examples of Queries
- Queries that SQLNet can not Answer
Firstly, because the complexity of the queries in the WikiSQL dataset is relatively low, as we mentioned in section 3.2. In Table 5.1 we can observe the query match accuracy (Accqm) of the model's predictions on both the test and validation subsets of WikiSQL, along with the previously mentioned sub-metrics (Accagg, Accsel, Acccond). Each of the categories created was evaluated separately and the results can be seen in Table 5.2.
While processing our model inputs, it can be observed that about 20% of words found in NLQs and WikiSQL column names (i.e. model inputs) have no representation in Stanford's pre-trained GloVe embeddings. -it that we are using. Some foreign words are being corrected to unrelated English words (eg the French word "montagne" meaning mountain was corrected to "montage"). Some Chinese and Arabic symbols and words were corrected in random articles (eg scale symbol was corrected to "a").
The mark +SP indicates a model that uses spell checking on words with ascii characters (line 3 of Table 5.3), the mark +TK indicates a model that uses the enhanced tokenization (line 4 of Table 5.3), and the mark +TK +SP indicates a model using both improvements (line 5 of table 5.3). An example of a table created by these views is shown in Table 5.5 and a complete example of the input SQLNet receives is shown in Figure 5.1. Even if the condition is added to the end of the sentence (for example, "Find all female actors from Austin") the system struggles to use the term correctly.
Another limitation stemming from the design of the system is the inability to include the same attribute (table column) more than once in the condition clause.

CONCLUSION
APPENDIX A. PREDICTIONS ON IMDB DATABASE
NLQ: Find all films in which ”Brad Pitt” acts after 2002 and before 2010 GT: SELECTfilmtitleWHEREactorname = ”Brad Pitt”. PRED: SELECTcast roleWHEREmovie title = ”kate movies movies NLQ: Find all movies featuring “Robin Wright”. PRED: SELECTactor birth yearWHEREmovie title = brad brad NLQ: Find all the women in the cast of “Grumpier Old Men”.
NLQ: Find the decade with the most films produced PRED: SELECTMAX(release year)WHEREbudget = films. NLQ: Find all actors who appeared in the same movie as Tom Hanks. PRED: SELECTActor nameWHEREmovietitle = empty in. NLQ: Find the actors who have not played in the same movie with "Brad Pitt".
NLQ: Find all movies with both Angelina Jolie and Brad Pitt PRED: SELECT cast role WHEREactor name = angelina jolie. NLQ: Find the directors who have not directed more than 10 films PRED: SELECTdirectornameWHEREdirectorname = not directed.

BIBLIOGRAPHY