This area of computer vision has increasingly attracted the efforts of the research community due to its wide range of applications, ranging from healthcare to human-computer interaction. First, the classification ability of each of the modalities was tested independently, and as a next step, different fusion approaches were evaluated. The architecture that achieved the best accuracy result was the multimodal approach, i.e., combining RGB, Depth, and Activity images.
The method was evaluated on large-scale datasets and focused on a subset of activities related to common daily living activities from the PKU-MMD dataset and health conditions from the NTU RGB+D dataset.
INTRODUCTION
BACKGROUND
- Pattern Recognition & Machine Learning
- Neural Networks
- Deep Learning
- Convolutional Neural Networks (CNN)
- Convolutional Layer
- Pooling Layer
- Normalization Layer
- Fully Connected Layers
- Rectified Linear Activation Function (ReLU)
- Recurrent Neural Networks
- Long Short Term Memory (LSTM) Networks
A neuron can be connected to all or a subset of the "neurons" in the subsequent layer. In CNNs, the neurons are exposed to a local region of the input (eg, a small grid of the image). Typically, filters are small spatially, but span the full depth of the input volume (e.g.
A major asset of the convolution layer is that each neuron is connected to only a local region of the input volume equal to the filter size. The depth of the output corresponds to the number of filters used, each learning to detect a different feature in the input. Zero-padding fills the input volume with zeros around the boundary, so we can control the spatial size of the output volumes.
The sigmoid produces values between 0 and 1, so a value multiplied by a 0 is forgotten and a value multiplied by 1 contributes to the memory of the network. The first step is to decide which values of the current cell state will be forgotten by multiplying the output of the forget gate by the current cell state. Output gate: The output gate is a filtered version of the new cell state and defines the next hidden state.
Initially, the previously hidden state and the current input are processed through a sigmoid activation that determines which parts of the cell state we will output. The tanh output is multiplied by the output of the sigmoid gate and generates the values for the next hidden state.
RELATED WORK
Visual Skeletal Representations
They created a new transform to turn DMMs into rainbow colormaps, where details corresponding to action motion patterns are encoded into textures and edges. The existence of the fourth JDM improved the robustness of the method in multi-angle testing. Inspired by spatial domain features and time domain features are extracted from skeletal sequence data.
The first ones consist of relative positional distances between joints and distances between joints and lines connecting two joints. The time-domain features are generated using the methods mentioned above to produce a joint distance map (JDM) and a joint trajectory map (JTM). Spatial domain features are given as input to LSTM networks and time domain features are used to train the CNN network.
15] proposed a different spatio-temporal representation for skeletal sequences that also includes the different durations of the different actions performed. Skepxel is constructed by arranging the indices of the skeletal joints in a 2D grid and encoding their coordinate values along the third dimension. Each Skepxel may have a different arrangement of the joints, but to keep the representation of the skeletal sequence compact, only a few highly relevant arrangements have been selected.
A group of skepxels is generated into a single skeleton frame, and the final image is compactly constructed by concatenating the group of skepxels in a column-wise manner into an n-frame sequence. The 5D space consists of the 3D coordinates of each joint and the additional two dimensions of time and common label.
Multimodal Methods
In their method, five subsets of joints are selected to represent the following body parts, arms, legs and trunk. For each body part, the cosine distances and the normalized magnitudes are calculated, creating two feature arrays that are then converted into grayscale images. Although their approach does not focus on human action recognition, both RGB and depth information are taken into account and merged in the following way.
Two coding branches are used for each modality and a fusion block consolidates the feature maps produced.
METHODOLOGY
- Modalities
- Input preprocessing
- Skeletal Information
- Activity Images
- Network Architecture
For each of these joint groups, we construct a series of activity images to be used as an input to our hybrid network. The activity images we use to capture spatiotemporal properties of skeletons are partially inspired by the work of Jiang et al. In this thesis, building on the aforementioned, we propose a quite similar implementation of activity images.
Joint coordinates are also considered as 1D signals and a spectral transformation is used to form the final activity image. However, a key difference in the presented approach is that each action is described by five sequences of activity images corresponding to five body parts, i.e., arms, legs, and head-torso. For this purpose, joint coordinates are conveniently grouped based on the body part to which they belong.
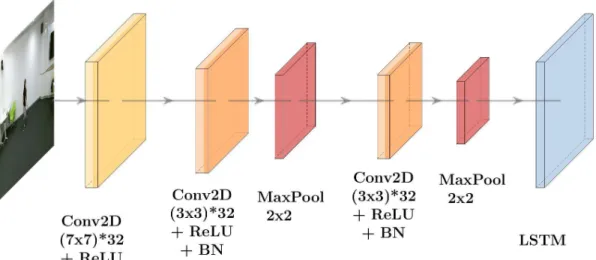
It should also be noted that the common coordinates are arranged in chronological order, ie. the first line corresponds to the first video frame, etc. Finally, activity images are constructed by applying a 2D Discrete Fourier Transform (DFT) to the interpolated signal images, discarding their phase. In particular, various typed data (RGB, depth, body part-based activity images) are filtered by 2D-CNN to learn short-term spatiotemporal features and then fed into LSTM to extract long-term spatiotemporal dependencies.
The output feature maps are concatenated and a final dense layer with a softmax activation is applied for classification. Finally, the output features extracted from the LSTM layer are concatenated for each type of data (i.e., RGB, depth, activity images) and used as inputs to h) a dense layer with softmax activation that produces the final classification results.

EXPERIMENTS
Datasets
- PKU-MMD
Implementation and Network Training Details
Experimental Results and Analysis
- Phase 1
- Experiments with individual modalities
- Fusion of different modalities
- Εxperiments with activity images
- Experiments on 51 classes
- Phase 2
- Experiments on activities of daily living
- Experiments on medical conditions
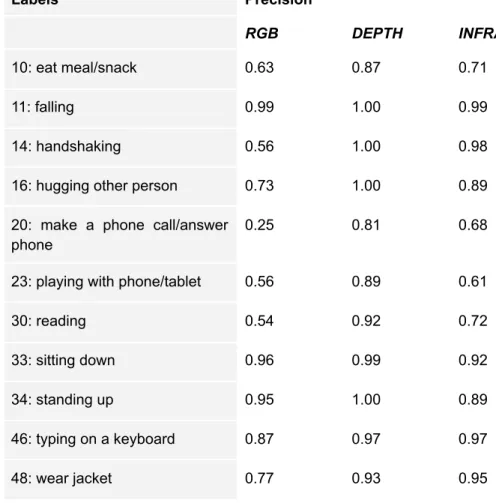
The confusion matrix is illustrated in Figure 11 and the precision results compared to the results for RGB and depth independently are shown in Table 2. The inclusion of the infrared information contributed to a lower precision score for the majority of the classes. Initially, we assessed the contribution of different body parts represented as activity images to the classification accuracy.
It is clear that the majority of the above activities consist mainly of upper body movement. We first analyze the performance of the network trained with different sizes of activity images and different number of frames representing an activity (image sequence length). Suppose we create a sequence of activity images for an activity video of 150 frames which is the average duration of the selected 11 activities.
Such scenarios are explored in the second phase of the experiments (5.3.2), where recording activity images is proven to outperform the RGB depth approximation. As shown in Table 6, adjusting the above parameters improved the classification precision for several activities, while at the same time deteriorating the precision scores of others. In the second phase of the experiments, we aim to thoroughly assess the best configuration of the proposed approach using the hyperparameters extracted from the first phase (resolution of activity image and sequence length).
The authors of the PKU-MMD dataset [34], as well as the authors of the NTU RGB + D dataset [35] propose one set of actor IDs for training and another set for testing. Cross-sectional and within-subject experiments test the robustness of the proposed approach in scenarios that are closer to real-life conditions. Apparently, the addition of activity images outperforms the RGB depth approach, especially in cross-gaze estimation (LR-M: 0.95), indicating its effectiveness for handling view-independent action recognition.
The selected sequence length of the activity images is set to 7 and a fixed height of 45 has been used.
CONCLUSION AND FUTURE WORK
Synopsis
Result conclusions
It should also be noted that several combinations were tried to finally obtain a satisfactory resolution and sequence length for the activity images. We can conclude that these parameters depend on the duration of each activity, and since different classes differ in terms of execution speed, our goal was to find a resolution that is suitable for the average activity duration. The achieved accuracy score was 0.76, which means there is still room for improvement, especially for activities that have similar movement patterns.
Experimental results of phase 2 confirmed the effectiveness of our method for recognizing both ADLs and medical conditions. As expected, medical conditions achieved a lower but satisfactory accuracy score of 0.75 and activities of daily living achieved an accuracy of 0.95. We also point out a clear performance gap in the results of cross-view settings where the training set is derived from the right or left viewpoint and the test set from the left or right viewpoint, respectively.
In such cases, our method achieved the lowest scores, while in scenarios where testing was performed using left and right viewpoint recordings for training and center viewpoint recordings, our approach achieved the best accuracy scores (0.95 on 11 ADLs from the PKU) -MMD, 0.75 on 12 medical conditions from NTU-RGB+D). In particular, with the use of the hybrid CNN-LSTM architecture, we have achieved to produce both short-term spatial features as well as long-term spatial features.
Future work
Velastin, “Spatio-temporal image representation of 3D skeletal motions for view-invariant action recognition with deep convolutional neural networks,” Sensors (Switzerland), vol. Action recognition with spatiotemporal visual attention on skeletal image sequences, IEEE Transactions on Cir-cuits and Systems for Video Technology, vol.
![Figure 2: A deep neural network architecture [2].](https://thumb-eu.123doks.com/thumbv2/pdfplayerco/287834.37445/17.894.137.753.256.571/figure-a-deep-neural-network-architecture.webp)

![Figure 4: A max-pooling example [4].](https://thumb-eu.123doks.com/thumbv2/pdfplayerco/287834.37445/20.894.140.717.93.444/figure-a-max-pooling-example.webp)
![Figure 5: ReLU activation function [3]](https://thumb-eu.123doks.com/thumbv2/pdfplayerco/287834.37445/21.894.215.680.146.395/figure-relu-activation-function.webp)
![Figure 6: An unrolled recurrent neural network [5].](https://thumb-eu.123doks.com/thumbv2/pdfplayerco/287834.37445/21.894.144.754.859.1039/figure-an-unrolled-recurrent-neural-network.webp)
![Figure 7: The LSTM Network [7].](https://thumb-eu.123doks.com/thumbv2/pdfplayerco/287834.37445/23.894.120.780.331.671/figure-the-lstm-network.webp)
![Figure 9: The 25 skeletal joints of the human body [35].](https://thumb-eu.123doks.com/thumbv2/pdfplayerco/287834.37445/30.894.257.636.697.1042/figure-skeletal-joints-human-body.webp)