Given a lead sheet as a common foundation, the study of the collaborative process of music improvisation between a human and an artificial agent in a real-time setting is a scenario of great interest in the MIR domain. The artificial agent consists of two subsystems; a model responsible for predicting the human soloist's intentions and a second system that performs the task of accompaniment. To perform data analysis, a summary of the information is required, which is achieved through the process of feature extraction.
Motivation
Research Questions
So far, the approaches developed generate a static accompaniment to solos, compared to the methods discussed here, proposing dynamic changes in the system's responses that depend on human solo improvisation. To what extent does the deployed framework enable the system to respond to dynamic constraints that depend on the human agent?
Thesis Structure
- Illiac
- MUSICOMP
- UPIC
- IBM 7090
Deep Neural Networks have proven to be very effective in capturing the statistical behavior of large data sets, therefore the research objective and questions of this thesis focus on the suitability of such models to be applied to the development of the system proposed in section 4.1 below. The generator-modifier-selector paradigm explained in section 2.1.1 was also applied to MUSICOMP (MUsic SImulator - Interpreter for COMpositional Procedures), one of the first computer software developed with the aim of simulating musical compositional procedures, programmed by Lejaren Hiller and Robert Baker in Fortran and Scatre.
Non - Adaptive Generative Systems
Stochastic Methods
Once the waveforms are saved, the user can use them to create compositions by drawing on the tablet, using the X-axis to represent time and the Y-axis to represent height.
Rule - Based Approaches
- Cellular Automata
- Lindenmayer Systems
- Swarm Intelligence
The central concept of L-systems is rewriting, a technique for defining complex objects by successively replacing parts of a simple initial object using a set of rewriting rules. The typical and simplest form of L-systems belongs to the category of deterministic context-free grammars (DOL systems). Other applications of L-Systems for music-related research cover sound generation [22], the approach of Kaliakatsos-Papakostas et al.
23], where the strings produced were truncated to a fixed length at each subsequent step, producing strings that had quasi-periodic characteristics at different levels, representing a variation on the L-systems, namely the Finite L-Systems (FL -Systems). systems), as well as the exploration of the grammatical evolution of the musical rules of FL-Systems [24, 6]. Swarm intelligence (SI) leads to the emergence of collective spatial behavior through the individual adjustment of the location of unique individuals, based on the application of simple rules that update the velocity of each agent based on its location and speed. This algorithm defines an agent's movement based on three components: shoaling, where each agent moves toward the center of mass of its neighboring agents, collision avoidance, where each agent moves away from the agents that are too close, and training, where the each agent's speed is aligned with the average speed of its neighboring agents [6].
Some of the aforementioned features were incorporated into interactive agents related to music and sound, developing multiple and extensive approaches. Finally, behavioral sonification of SI agents has been integrated into the Swarmlake game [32], which extended social behavior with user-controlled commands and attributed different agents with different sound properties, according to specific game conditions. [6].
Adaptive Generative Systems
- Explicit Learning
- Implicit Learning
- Machine Learning
- Real Time Applications
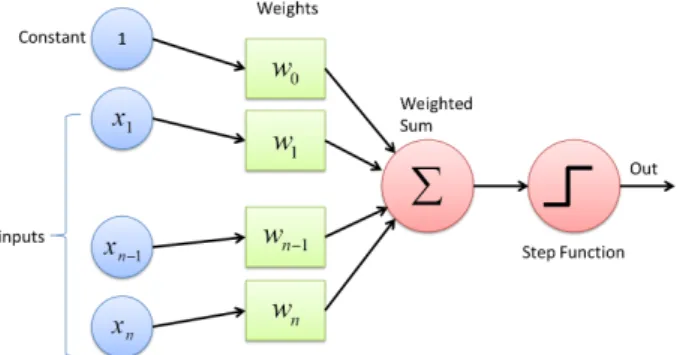
- The Perceptron
- Activation Function
- Loss Function
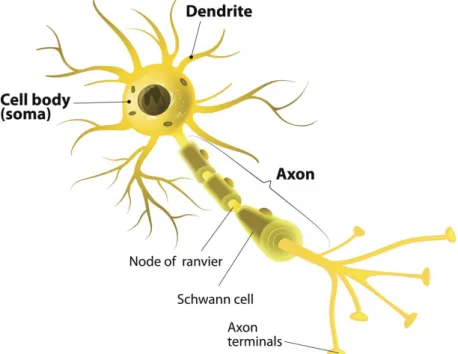
Given a set of one or more composition examples, the ANN is trained to associate a single input configuration with the output temporal sequence of the corresponding composition. Both of the above studies incorporated learning and generation of polyphonic music in the style of Bach chorales, using LSTM units and Gated Recurrent Units (GRUs), respectively. Axon is a long projection that carries information from the soma to other cells in the system, so it is the output part of the cell.
An ANN calculates a function of the inputs by propagating the calculated values from the input nodes to the output node(s). In some cases, usually in unbalanced binary class distributions, part of the prediction is invariant and must be captured, e.g. The tanh function is usually used when the output of the calculations is desired both positive and negative.
The objective of the perceptron algorithm is to minimize the prediction error, so it is heuristically designed to minimize the number of misclassifications. A function whose goal is to minimize the value of the classification error (classification cost) is called a loss function.
Feed - Forward Neural Networks
Backprobagation
In this technique, the values produced as output by the NN are compared with the correct answer to calculate the value of the error function. To properly adjust the weights, a general nonlinear optimization method called gradient descent is used. The network calculates the derivative of the error function with respect to the network weights and changes the weights so that the error decreases (meaning the surface of the error function goes downhill).
Therefore, this phase initializes the intermediate variables that will subsequently be needed in the backward phase. After completing the calculations, the prediction (final output) of the NN is calculated and compared with that of the training instance. The derivative of this posterior loss must be calculated with respect to the weights in all layers in the backward phase.
The main goal of the backward phase is to learn the gradient of the loss function with respect to the various weights using the chain rule of differential calculus. These gradients are used to update the weights in all layers of the NN and are learned in the backward direction, starting from the output unit, where each node is processed exactly once in each pass.
Recurrent Neural Networks (RNNs)
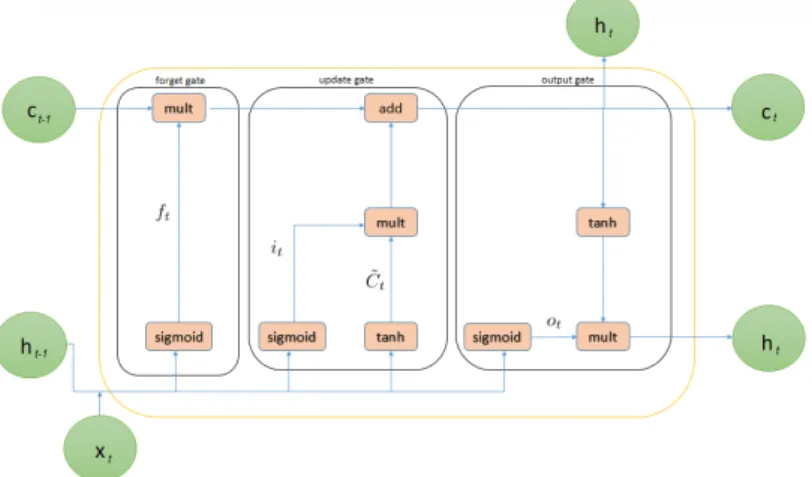
Long Short - Term Memory (LSTM)
The main issues this raises are the vanishing and exploding gradient during weight updating, mainly due to the successive multiplication of that shared weight matrix during backpropagation. The persistence of state values is precisely what eliminates the instability that occurs in the case of vanishing and exploding gradient problems. Specifically, ct-1 represents the input of a memory cell at time stamp t, xt is a data input at step t, ht is the hidden state vector, also known as output vector of the LSTM unit at time t, which goes to both the output layer and the hidden low in the next time step.
The key to LSTMs is the cell state, the line connecting input ct-1 and output ct in Figure 3.5 which runs straight through the entire NN chain, with only a few small linear interactions. The forget gate manages which part of the information from the previous state will be retained in the next state. The output ht is then passed to the next layer of our network as one of the inputs.
The intermediate variables i, f, and o are called input, forget, and output variables, respectively, because of the tasks they perform. The system's job is to interpret the information given from the lead sheet with variability depending on the predicted harmonic variability of the human solo.
Data Preprocessing
- Description of the dataset
- Time Resolution
- Chord Information
- Data Augmentation
- Transposition
- Feature Dimensionality Reduction
- Dictionary Information
The time resolution was reduced, from 24 time steps per beat (quarter) to 2 steps per beat, so that each time stamp represents an eighth note, which is half the duration of the quarter. For the training of the proposed system, chord information needs to be presented in a new, useful and compact way for the purpose of the research, in the form of lead sheets for jazz standards. In particular, instead of keeping the velocity values of the active notes that form the chord at each timestep and their respective midi numbers, only the pitch class of the chord's root is preserved, as well as the chord type, using side and -ready functions from the MIT Music21 Python library2, a toolkit for computer-aided musicology.
First, the accompaniment chords are assigned to the positions of the chord symbols of the leader board. The purpose of data augmentation is to increase the variability in the accompaniment channel depending on the chord symbols of the leader board and the melodic rhythm patterns. To reduce the dependence of chord progressions on the tonality of the piece they are a part of, the parts in the dataset have been transposed to all 12 keys.
The result of this process is greater prediction accuracy of the trained system on new, unseen data, as it learns to recognize the relative separations between chords. Before the harmonic data enrichment process, the accompaniment chord dictionary contained 476 chords, after expansion and before transposition to all 12 pitches there were 847 classes, and finally, after all data preparation (both after augmentation and transposition). ), the number of unique accompaniment chord classes was 2677.
System Architecture
- Overall Structure
- Human Agent (HA)
- Artificial Agent (AA)
- Training
As mentioned above, the system's guidance predictions should be closely related to the expected human solo of the future time steps. The system consists of two subsystems, the Human Agent (HA) and the Artificial Agent (AA), to execute the predictions of the human solo and the accompaniment chords, respectively. This construction allows us to thoroughly investigate the system's response by comparing and analyzing the respective generated chords.
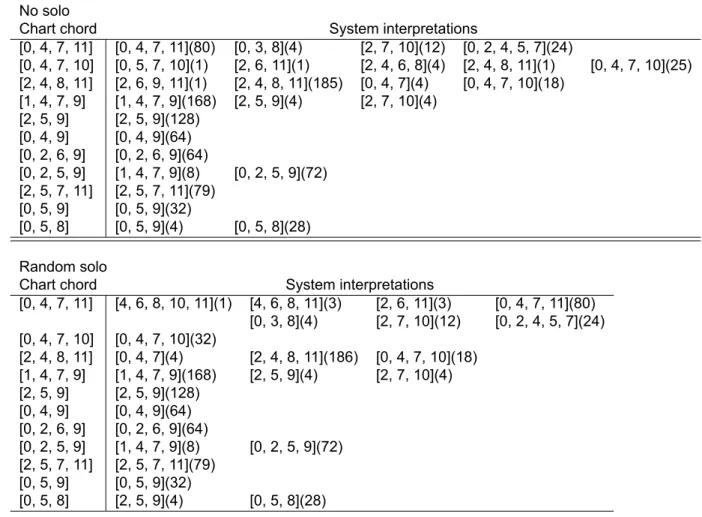
To investigate the impact of the training on the system's harmonic compliance, data from different periods (59 and 1251) were collected and presented below. Tables 5.1 and 5.2 show the chord symbols and the system's responses in the case of the "All of me" jazz standard, when no solo and random solo are provided. For example, regarding "All of Me", as presented in Tables 5.1 and 5.2, in most of the time steps, the system was able to reflect the exact harmonic description in the master sheet map.
In "Au Privave" the same percentage varies from 74% after epoch 59 and reaches 84% at epoch 1251, leading to the conclusion that the presence of the solo has a greater influence on the system generations for this particular piece. In contrast, with respect to "Au Privave", the system generated variations of the main sheet plot for each iteration, even from early epochs (59), and demonstrated more pronounced variability after more epochs (1251) . Additionally, data enhancements have been applied to obtain greater variability of the association of parts in the data set.
Testing of the system was carried out in two simulated cases of real-time scenarios, where the guidance was randomly generated and not solo.
Human Neuron
Perceptron model
Feed-Forward NN structure
RNN unrolled
LSTM architecture
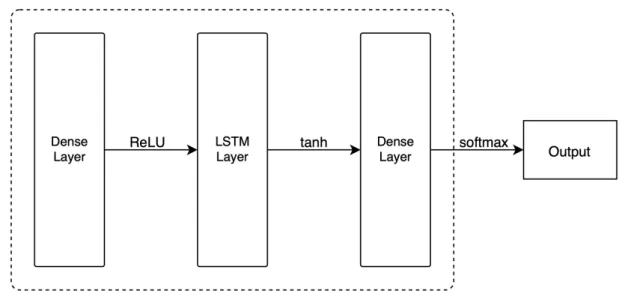
The architecture of both subsystems
The Human Agent Subsystem
The Artificial Agent Subsystem
Validation loss of the objective function over the total number of epochs of
First 8 measures (a) and last 8 measures (b) of system-generated chords