Accuracy results of the EfficientNet family of networks on the imagenet dataset compared to some popular neural network architectures. The architecture and number of parameters of the EfficientNet B0 model that will be trained in its entirety.
Introduction
Rationale
For this reason, the performance of machine learning classifiers will be examined in diagnosing dermatoscopic images and in particular the performance of a category of classifiers called neural networks. Targeted architectures of neural networks that process image class predictions (convolutional neural networks) will be presented and tested on the same problem to measure their performance.
Structure of the thesis
After the development of deep learning convolutional neural networks, their results in a minimum viable product application will be examined to see whether or not they are able to be incorporated into a diagnostic center even if it is in a simulation environment. The fifth chapter contains the experimental structure and the results of the selected approaches and the sixth chapter presents the conclusion of these results.
The Problem
Ultraviolet rays damage the DNA of genes that regulate the growth of skin cells and eventually cause skin cancer [2]. Various aspects of the patient's organism also play an important role in the development of melanoma.
Skin Lesions
The presence of multiple moles and fair skin increase the risk of melanoma formation as their tolerance to ultraviolet rays is reduced compared to darker pigmented skin. Most of these types of skin lesions are benign, a setting that corresponds to real-world conditions where benign incidences far outnumber malignant ones.
Dermoscopy Images
Towards that course, new machine learning algorithms are used and tested to analyze images. One category of promising machine learning algorithms that perform well and show significant accuracy results are neural networks.
Machine Learning
The task of a supervised machine learning program is to produce the correct label from the features for each example. This procedure is then repeated until a satisfactory error is displayed. The two applications of supervised learning are classification problems and regression problems.
Neural Networks
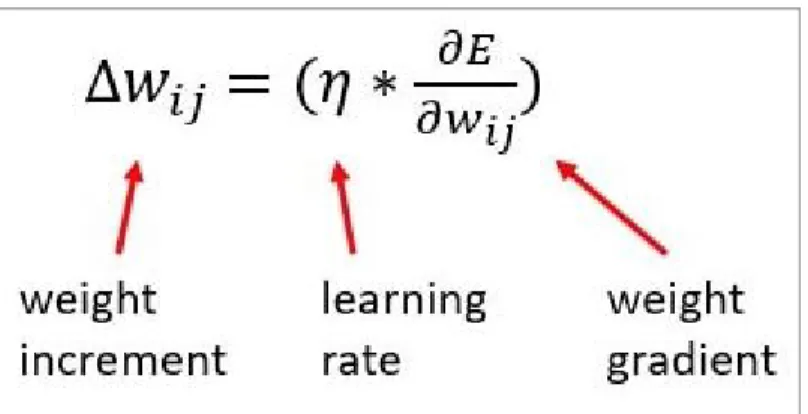
The cost function measures how much the produced output deviates from the correct output (ground truth). One of the most popular techniques for finding all weights and biases that minimize a cost function is gradient descent.
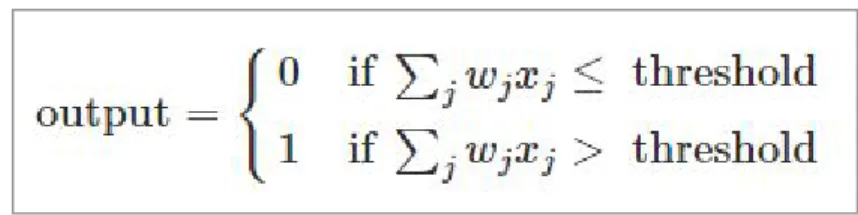
Computer Vision
Another popular technique used in the field of computer vision is the oriented gradient histogram. The histogram feature descriptor of oriented gradients (HOG) is the process of mapping each change in the value of each pixel relative to the regular ones [13]. Each pixel in the cell votes for a gradient orientation bin with a vote proportional to the magnitude of the gradient at that pixel (Figure 13).
By calculating the gradients through a HOG algorithm, the produced feature vector can be considered as a collection of information about the structure of the image (Figure 14). After obtaining the feature vector, then using a classifier such as Support Vector Machines (SVM), for example, the classifier can be trained on those structures and predict the class of an image or perform object detection by checking the existence or absence of theirs.

Convolutional Neural Networks
For a fully connected neural network (FCN) used for image recognition, the input layer will consist of neurons corresponding to the pixels of the image. In CNNs, the input layer again consists of the same number of neurons as the pixel values of the image, but the connections to the first hidden layer are different. The size of the local receptive field can be tuned and is one of the hyperparameters that can be tuned in any CNN architecture.
Finally, all hidden neurons will correspond to a connection to a local receptive field of the input layer. These weights are the same or common for each image scan with that particular local host field.

Hyperparameters of CNNs
When training an ANN, the engineer has the option of using a single example from the data set in each pass or a set of examples. When used with a single sample or a set of samples (mini batch), SGD randomly selects a subset of the data set and trains the network on the isolated data. The main advantage of using a mini-batch technique is the ability of the optimizer to produce noisy process updates and eventually avoid local minima and actually converge [18].
Dropout is a generalization technique used during the training phase in neural networks to help avoid overfitting the model to the data set. The main concept of dropout is to ignore a random subset of the neurons during training and not apply weight adjustment to them.
Related Work
A more thorough examination of the subset of the ISIC dataset that will be used is presented in Section 5.1. Due to the ISIC challenge initiative and the nature of the problem itself, there has been great interest in tackling the task of classifying skin lesions. During their experiments, the research team trained a convolutional neural network called ResNet50 based on image data of skin lesions and compared the network's results with the results of domain-expert diagnostic physicians.
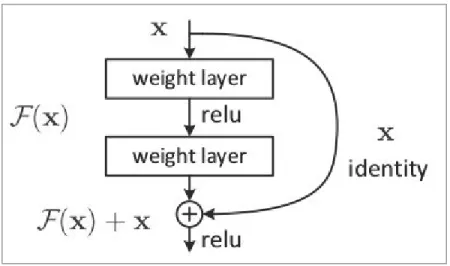
The ResNet family networks were the winners of the 2015 Imagenet challenge and are considered one of the breakthroughs of deep learning in computer vision [21]. That technique is called skip connection (residuals) which connects the output of one layer with the input of the previous one.
EfficientNet
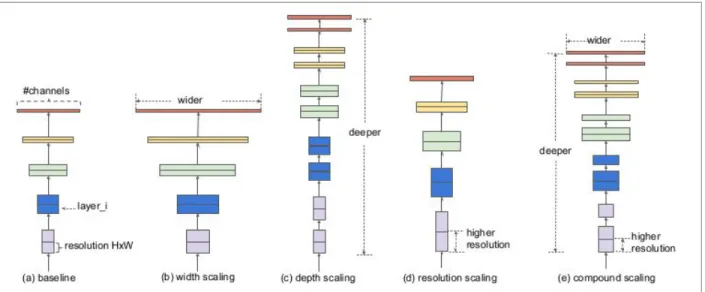
The number of hidden layers can be thought of as its ability to construct complex structures from simple ones. The last architecture parameter that can be scaled up or down is the resolution of the input images, where by feeding the network with increased number of pixels you give the CNN increased information. To do so, 1x1 kernels are used along the depth of the intermediate tensor (point-wise convolution).
To construct deeper architectures and avoid the problem of vanishing gradients, a skip connection is used between the input and the output of the building block (Figure 33). Finally, the resulting architecture of the baseline EfficientNet B0 used to produce the EfficientNet family consists of the layers shown in figure 35.
The Dataset
Among these classes, the number of images belonging to each of them is not constant. All images are in a folder, each with a unique file name ID. As a first step, the images are divided into different folders, each corresponding to one class.
The procedure is performed by scanning the images and then finding by file name the current class and copying that file to the appropriate folder (Figure 37). The resulting structure is a set of 8 folders with the images from that class in each folder.
Transfer Learning
This task is necessary to use the flow_from_directory method of the image generator class that exists in the Keras framework [31].
Training the network
For the next experiment, the neural network to be trained is the EfficientNet B5 network of the same family. The next experiment will check if the unbalanced validation set affects the scores of the model. The final results of the accuracy and loss for the model are shown in figure 55.
The resulting graphs for the accuracy and loss of the training process are shown in Figure 56. The final results on the accuracy and loss of the model are shown in Figure 57.

Skin lesion classification application (Mole Shaman)
As expected, the training accuracy and the loss on the training set are worse than the previous experiments, as the less represented classes hurt the model's performance. After rendering the home page, the user has the option to upload from the local file system an image of the skin lesion he wishes to diagnose (Figure 59). If the check fails, an error page is displayed to the user to try again.
If the checks pass, the application uses a POST HTTP method and executes the predict() function for the server.py file. The predict() function in turn calls the predict_class() function in the efficientnetB0_model.py file, which, using the keras preprocessing method, resizes.
Conclusion
Results
The resulting accuracy and loss of the transfer learning experiments performed show that the EfficientNet B0 model presents increased performance on this particular task when all weights are fine-tuned and not just the back layers of the network. This behavior is expected due to the differences between the ImageNet dataset on which the model was originally trained and the ISIC dataset. At the beginning, each characteristic of the seven-point system was rated 1, so that the final total was 7.
Dataset balancing, performed in several experiments, has been shown to be ineffective in increasing the performance of the EfficientNet B0 model. That fact can be attributed to the relatively small size of the dataset for this particular problem since the classes of the image prediction are large (8) and the differences between them are minimal.

Future Work
Furthermore, another technique used to increase classification accuracy is to form an ensemble of neural networks, either efficientNets alone, or an ensemble of different architectures that all vote together for the most accurate prediction. Examining the rankings of the ISIC challenge, this option appears to be effective as the top scorers use an ensemble of networks. Finally, some data preprocessing can also be performed on the dataset to remove structures that are not necessary for classification, such as hair or skin that does not belong to the skin lesion.
Removing skin that does not belong to the skin lesion can be performed by training a network that predicts the boundaries of the lesion (e.g. Mask-RCNN [37]) and subtracting the excess pixels from the original input image. InProceedings of the 2014 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, August 24 (pp. 661-670).