This thesis presents original research on the subject of Machine Learning and more specifically in the fields of Natural Language Processing and Information Extraction. Finally, we complete a number of case studies for the implementation of natural language processing techniques in the real world and investigate their added value.
Research Areas
Machine Learning
Finally, Knowledge Distillation is a methodology in which a machine learning model (usually referred to as the Student) attempts to predict a desired output, given a set of data points and an already trained model (referred to as the Teacher). Finally, we can summarize that contributions to the field of Machine Learning are usually focused on one of three aspects, i.e.

Natural Language Processing
Therefore, natural language understanding and natural language generation skills are required to provide accurate answers. Natural language generation on the other hand is the task of evaluating the ability of models to generate the coherence of the generated model text.

Biomedical Natural Language Processing
By definition, the contributions of this thesis are also made using Deep Neural Networks as the springboard. Finally, terminology varies greatly even within biomedical texts as the medical field changes (Gu et al., 2020).
Research Problems
Going beyond the specific requirements of the field, the heterogeneity of biomedical texts makes them very challenging (Wang et al., 2018b). Currently, this task is tackled by creating contextualized representations of the identified arguments in an attempt to capture their meaning.
Thesis Contributions and Structure
Linguistic Characteristics
Interestingly, the term “word” as used in language modeling has no linguistic meaning (Manning and Schutze, 1999), but has come to define individual tokens used as input to LM. Furthermore, early approaches to language modeling that used statistical approaches and were commonly called N-gram models because they relied on N preceding words to make predictions about subsequent words suffered from an inability to generalize.
Approaches to Language Modeling
The architecture of transformers, the mechanisms that enable these approaches, and its connection to language models will be further explored in Section 2.5.
Language Model Evaluation
Entity Recognition
Linguistic Characteristics
The first example comes from using the same range of text to describe two different entities of the same semantic type. Another example, usually due to metonymy, is when the same range of text is used to describe two different entities of different semantic types.
Approaches to Entity Recognition
Entity recognition systems rely on a host of linguistic, orthographic, and morphological features derived from the source text, along with the available context, to make a prediction (Nadeau and Sekine, 2007). Modern Entity Recognition models are dominated by Deep Learning approaches, as they require less feature engineering and enable end-to-end training, resulting in higher overall performance (Li et al., 2020a).
Entity Recongition Evaluation
With Deep Learning, Name Entity Recognition systems could work end-to-end, without the need for manual feature engineering or external latent information. While Biomedical Entity Recognition systems have also benefited from Neural Networks, their individual characteristics have led to poor performance compared to their Named Entity counterparts.
Argumentation Mining
Linguistic Characteristics
The structure of inference is the result of identifying the relationship between identifying arguments as either supporting or attacking. Where premises interact sequentially with each other with the last premise on the chain interacting with a claim.
Approaches to Argumentation Mining
Comparable to previous tasks, manually manipulated features were used in early attempts with little success (Palau and Moens, 2009; . Peldszus, 2014; Aker et al., 2017). A hindering factor for biomedical argumentation mining was the lack of high-quality corpora that would enable supervised learning approaches (Mayer et al., 2019).
Argumentation Mining Evaluation
Coreference Resolution
Linguistic Characteristics
Zero Anaphora. This type of anaphora uses a gap in a phrase or clause to point back to the antecedent. Discontinuous Sets (Split Anaphora). This type refers to the anaphora in which the pronoun refers back to more than one antecedent.
Approaches to Coreference Resolution
Deep learning approaches have introduced innovations with latent prior trees (Lee et al., 2018), adversarial training (Subramanian and Roth, 2019), reinforcement learning techniques (Aralikatte et al., 2019), entity matching (Kantor and Globerson, 2019 ) and mention species information (Khosla and Rose, 2020). However, they use domain-specific pre-trained LMs and functions to handle domain requirements (Kilicoglu and Demner-Fushman, 2016; Trieu et al., 2018; Li et al., 2021).
Coreference Resolution Evaluation
Therefore, recording datasets such as the ACE dataset (Doddington et al., 2004), which contain singleton annotations, cannot be trusted. The approximation metrics, both precision and recall, are calculated by checking whether the entities contain the mention, resulting in
The Transformer Architecture
Automatic encoding models are focused on predicting masked information in word sequences (Devlin et al., 2019a). A detailed review of transformer alternatives designed to improve efficiency is available in (Tay et al., 2020).
Knowledge Graphs
These include answering questions, summarizing, searching for information, and constructing a knowledge graph, among others (Li et al., 2020a). Jin and Szolovits, 2018) to answering questions and searching for information (Abacha and Zweigenbaum, 2015; Gulden et al., 2019).
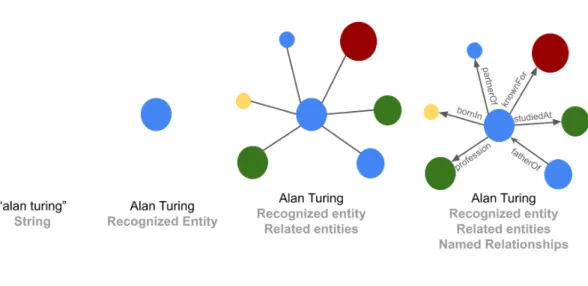
Related Work
The publication of a large, high-quality manually annotated corpus provides the means to further achieve the research objectives with detailed PICO annotations (Nye et al., 2018). Another approach introduces a combinatorial embedding, which uses two character-level architectures and a word-level architecture to create token representations (Cho et al., 2020).
Biomedical Entity Recognition Architectures
Biomedical Entity Recognition with Recurrent Neural Networks
Similar to Kim et al. 2016), we use a nonlinearity function and a max-over-time pooling operation to obtain a fixed-dimensional representation of the word inCxp∈Rdchar×dkernel. The attention mechanism is used to increase the model's ability to extract features from the word representation vector.

Biomedical Entity Recognition with end-to-end Transformers
Longer context modeling with efficient Transformers
The introduced sparsity in the attention mechanism lowers the original quadratic computational complexity to O(n×w)), whereby the window size. Finally, Linformer uses a low-rank projection technique on the length dimension to project the dimension keys and values in the Query, Key, Value attention schema to a lower dimension (k).
Experiments
- Data and Preprocessing
- Experimental setup
- Experimental results
- Ablation study
The detailed results presented in Table 3.1 highlight the performance of each model overall and for each label (population, intervention and outcome) in terms of precision (P), recall (R) and F1 score. We present three typical examples in Table 3.2, and in all of them we notice that the predicted tags are missing some non-medical words or tagging multiple words in the PICO entities.

Conclusion extraction with Evidence-Based Medicine Entities
PICO Statements dataset
More specifically, we identified distinct Populations for each category such as "Graves' Disease" for Endocrinology, "Preterm Birth" for Gynecology, and "Multiple Sclerosis" for Neurology, to be used for document collection. Our annotators consisted of 26 MSc students from the medical department of the Aristotle University of Thessaloniki who already had medical degrees, and the annotation process was evaluated using the Inter Annotator Agreement (IAA) (Roberts et al., 2009) and Cohen's Kappa ( Cohen, 1960).
PICO Statement Classifier
Experimental Results
It becomes clear that the gains in performance, given a better PICO device model, can have a significant boost in performance with different algorithms. These results also suggest that a perfect PICO Entity Recognizer could only boost the performance of the tested classifiers to the scores in Table 3.10 with the used set of features.
Entity-specific Biomedical Entity Recognition
Data and Preprocessing
All the aforementioned corpora are collections of abstracts of publications from PubMed/MEDLINE, assembled using MeSH terms. Due to the similarity of linguistic features between the identification of the surface forms of the selected entity types and the gene and drug type entities, we did not compare the performance of our model architecture with other benchmark corpora.
Entity-specific experimental results
Combined with our model's use of only word and subword features as input, it fails to create meaningful representations for the input tokens. As a result, the majority of models use a combination of multiple word and character embeddings to avoid out-of-vocabulary occurrences.

Conclusions and Future Work
The system uses latent semantic annotation in the form of Evidence-Based Medicine entities from a pre-trained model to increase its performance and expressiveness. In the rest of this chapter, we first review the related works in Argumentation Mining (Section 4.2).
Related Works
The aim of the work is to use the reasoning structure produced by a MAM system (Mayer et al., 2020) as a feature in an argumentative outcome analysis. Handling argument identification as a sequence labeling task with multiple RNNs is investigated (Ajjour et al., 2017; Spliethöver et al., 2019).
TransforMED: A Medical Argumentation Mining system
Factor graphs are constructed in a structure learning approach using SVMs and RNNs in the approach proposed by Niculae et al. Similarly, ResidualAM (Galassi et al., 2018) is a cursor network approach that removes the structure constraints in an attempt to avoid false negatives.
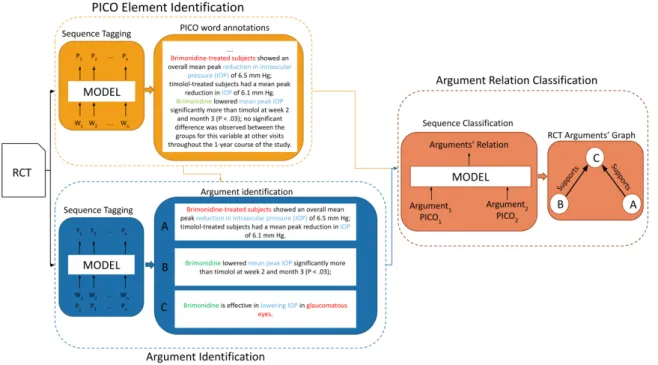
TransforMED Models Architectures
Argument Identification model architecture
Formally, the ArgId model takes as input a sequence of tokensW = (w1, . . . , wl), which is passed through a pre-trained BERT model to produce a sequence of embeddings X = (x1, . The PICO annotations are passed through a embedding layer to produce a sequence of embeddingsP = (p1, . . . , pn), where is the number of tokens in the original sentence and is the maximum number of tokens in a sequence after padding.
Argument Relation Classification model architecture
The resulting vectors Both argument strings are concatenated before padding, with the special token “SEP” inserted between the two strings, before being passed through a BERT model to create a string embeddingX = (X11, . . , . . . , X2m,.
Experiments
- Data and Preprocessing
- Experimental setup
- Experimental results
- Ablation study
These PICO annotations are the same ones generated by the Pre-Trained EBM model in the first stage of the pipeline. As a result, the improvements in ArgId model performance from PICO annotations were minimal but not negligible.

Conclusions and Future Work
However, FFNN-based LMs have limited contextual information available, an issue that was addressed via Recurrent Neural Networks (RNN) (Mikolov et al., 2013a). Until recently, Recurrent Neural Networks (RNNs), and especially Long-Term Memory (LSTM) networks, have been the core of all cutting-edge approaches (McCann et al., 2017b; Peters et al., 2018a). .
Related Works
YangLM (Yang et al., 2017b) first introduced an RNN-based LM with explicit entity decision and learnable entity representations. YangLM (Yang et al., 2017b), also presents a variation of the LM that uses latent representations of a database.
Coreference-aware Language Modeling Training
- The Entity-Transformer block
- Entity representations
- Experimental setting
- Data and Preprocessing
- Experimental results
- Result experiences
The remaining final output is used in the entity attention layer before being forwarded out of the ET block. Entity-Attention is an adaptation of the multi-head attention masking layer used in the original Transformer block.
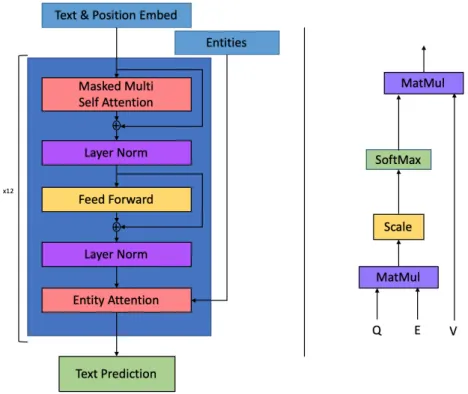
Coreference-aware Language Model Fine-Tuning
- Entity-Gating
- Entity Representations
- Data and Preprocessing
- Experimental Setup
- Experimental results
- Error Analysis
- Result experiences
This design choice is based on the architecture of the Entity-Gating layer (section 5.4.1) and the learning process. Our model has 132M parameters, an increase of 6%, after adding the Entity-Gating layer and the entity representations.

Conclusions and Future work
- Related Works
- The AirSent platform
- Data and Preprocessing
- Sentiment Analysis model
- User Location Extraction
- Application Interface Implementation
- Conclusions
Because the app aims to provide users with real-time, state-of-the-art feedback. On the other hand, lexicons provide direct feedback about the feeling expressed by certain words.

Doc2KG
- Related Works
- The Doc2KG Framework
- Advanced searching functionality
- Case Study: The DIAVGEIA Portal
- Discussion and Conclusions
In the second stage, we transform the document collection into a knowledge graph based on the descriptions of classes, attributes, and relationships in the ontology. The proposed framework extends the current functionalities of document repositories by using the knowledge graph for advanced search.

MLOpen
Machine Learning Platforms
Inseparable services are offered by IBM's Watson, SAS's Viya and Amazon's Sagemaker, with minimal differences in the tasks supported. Other platforms that offer similar services are H2O.ai and Altair Smartwatch, but they are more limited in capabilities and scope and, compared to all previously mentioned platforms, are not directly related to other products from the same company.
The MLOpen Platform
The second (Figure 6.8) allows the user to enter the data needed to run or train the ML model provided in the pipeline. As illustrated in Figure 6.9, the last view allows the user to select a previously uploaded pipeline and a previously uploaded dataset and run the pipeline.

Discussion and Future works
For Transformers we have the different language modeling approaches enabled and the disadvantages of the. We based our approach on the success of the Biomedical Entity Recognition systems in identifying semantically hard entities and used the Evidence-Based Medicine framework as a source of information.
Future Work
AirSent (Michailidis et al., 2018), which combined sentiment analysis with Location Inference, demonstrates the value of the two tasks working together in a real-world scenario. This effort had led to the creation of benchmarks such as xNLI (Conneau et al., 2018), for cross-language Natural Language Inference.
Publications in Journals
Publications in Conferences
Submitted Publications
Υπόβαθρο
Αναγνώριση Βιοιατρικών Οντοτήτων
Εξόρυξη Επιχειρημάτων υποβοηθούμενη από Ιατρική Βασισμένη στην Τεκ-
Επίλυση αναφορών στην Μοντελοποίηση Γλώσσας
Περιπτωσιολογικές μελέτες
Συμπεράσματα
- Machine Learning landscape overview
- Learning methodology taxonomy
- Natural Language Processing landscape overview with task examples
- Named Entity Recognition example with annotated text to the respective entities. 15
- Coreference Resolution example with annotated text. Subscript numbers repre-
- The Transformer architecture as presented in (Vaswani et al., 2017)
- The stages of KG creation and the related Information Extraction task types
- PICO Entity Recognizer system architecture. “Out” is used to indicate that the
- BioTransformER model architecture overview
- LongSeq model architecture overview
- TransforMED system pipeline view. Example text appears in Red for Popula-
- TransforMED models’ architectures
- Language Model model performance per step on the CoNLL-2012 corpus
- Visualization of the word representations of (a) GPT2E and (b) GPT2E and (c)
- CoreLM Architecture as an extention of GPT2 model (area within dashed border). 91
- Data Set Sentiment Distribution per Airline
- Location Inference Process
- Capture of the AirSent Application Interface
- Doc2KG architecture overview with deployment stages colour annotated
- ML model of the new DIAVGEIA ontology, extended with the ISA 2 Core
- MLOpen welcome screen
- MLOpen “Import Pipelines” view
- MLOpen “Import Data” view
- MLOpen “Run Pipelines” View
- MLOpen Results with different modalities
I Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), sider Online. I Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, sider København, Danmark.
Επισκόπηση του τοπίου Μηχανικής Μάθησης
Επικσόπηση τοπίου Επεξεργασίας Φυσικής Γλώσσας με παραδείγματα ερ-
Αρχιτεκτονική Μετασχηματιστών Νευρωνικών Δικτύων (Vaswani et al., 2017)151
Αρχιτεκτονικές μοντέλων Αναγνώρισης Επιχειρημάτων και Ταξινόμησης Σχέσεων
Παράδειγμα λειτουργίας της πλατφόρμα AirSent
Οντολογία για την μετατροπή των εγγράφων της πλατφόρμας ΔΙΑΥΓΕΙΑ
EBM Models performance comparison
Example predictions of BioTransformER model in comparison to gold labels
BioER-RNN Entity Recognizer ablations results
Ablations study on the BioTransformER model
Architecture and scope results on EBM-NLP corpus using efficient Transformer
Absolute training times comparison between sentence and abstract level inputs. 51
PICO IAA and Cohen Kappa agreement statistics
PICO Statement classifier with and without the use of PICO Entity Recognizer
PICO Statement ablations
Biomedical Entity Recognition corpora and characteristics
Generalization results on NCBI-Disease corpus
Generalization results on SCAI-Chemicals corpus
Generalization results on JNLPBA corpus
Argument Identification models performance comparison
Argument Relation Classification model performance comparison in terms of
Detailed results on Neoplasm test set
Detailed results on Glaucoma test set
Detailed results on Mix test set
Ablations study on the Argument Identification model
Ablations Study on the Argument Relation Classification model
Ablations Study on the Pooled Argument Relation Classification model
Data example from the CoNLL 2012 dataset, as formated for the task
Perplexity and Validation loss on the CoNLL 2012 dataset