These applications implement algorithms and techniques in the field of natural language processing (NLP), which is also a subtask of machine learning. Keywords: sentiment analysis, machine translation, natural language processing, multilingual sentiment analysis, neural machine translation, deep learning.
Motivation
Unstructured data does not fit neatly into the traditional row and column structure of relational databases and represents the vast majority of data available in the real world. Despite this great interest from business and the research community in sub-tasks of NLP such as Sentiment Analysis, most of the work is focused on data in the English language.
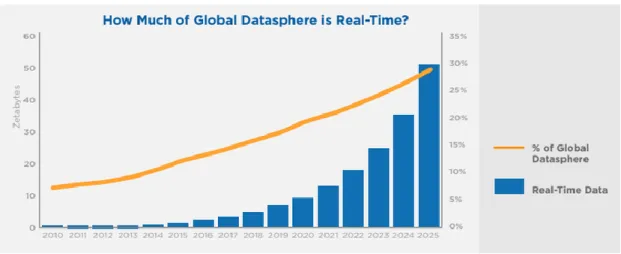
Big Data – An Introduction
It is difficult for an individual to know and understand all the languages of the world. The size of the data determines whether it is considered "large" and it is clear that we are not talking about a sample here, but the entire data set.
Natural Language Processing
- What is NLP?
- Natural Language Generation (NLG)
- Steps in NLP
- NLP pipeline
- Key Tasks of NLP
- NLP capabilities across different domains
- Use Cases of NLP
The sentence like "The school goes to boy" is rejected by English syntactic analyzer. Stop words are words that occur quite frequently in written and spoken natural language and help connect sentences without passing on any additional information, such as "and", "or", "na", "the" etc.
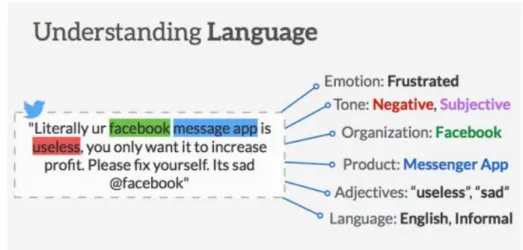
Sentiment Analysis – An Introduction
Innovative companies are engaged in extracting knowledge through user reviews on online stores and social media based on the analysis of emotions. Therefore, sentiment analysis is a practice of measuring the sentiment expressed in a text, such as a Twitter post or a review on TripAdvisor.
Machine Translation – An Introduction
Especially in the last two decades, we have witnessed great progress in the quality of MT, which has made it interesting for use in the translation industry as well. The questions that researchers in the field of machine translation are trying to answer today are: How much can human translators benefit from the use of MT.
Thesis Contribution
Although MT research has been ongoing for the past fifty years, fully automatic high-quality machine translation is still elusive. Machine translation (MT) explores approaches to translating text from one natural language to another. Machine translation is appropriate in a variety of circumstances, especially for unofficial purposes or to provide content that can be improved by the translator.
Thesis Organization
The comparison reveals similar performance rates for sentiment analysis on original and translated data, leading to the conclusion that the advanced machine translation systems can provide an alternative to the costly development of language features to realize sentiment analysis at the multilingual level.
What is Sentiment Analysis (SA)?
How does SA work?
Some of the most popular supervised learning algorithms are Naive Bayes, Maximum Entropy, and Support Vector Machines (SVM). They must of course be a representative sample of the text, while many times, depending on the classification, other features are required. A simple implementation of the lexicon-based approach, in the case of simple sentences, is the addition of emotional ratings of words to the way the sentence parse tree indicates.
Related Work
32] for document-level sentiment classification, which showed that ANN produced competitive results to SVMs in most cases. 35] designed an attention-based LSTM network for document-level cross-linguistic sentiment classification. The model consists of two attention-based LSTMs for bilingual representation, and each LSTM is also hierarchically structured.
Text Classification
Moreover, Support Vector Machines (SVM) is one of the most famous supervised machine learning-based classification algorithms [31]. Finally, the research of recent years is oriented towards the use of neural networks and deep learning techniques, such as Convolutional Neural Networks or Recurrent Neural Networks, which show remarkable results. Much of the recent work on automatic document classification has involved supervised learning techniques such as classification trees, Naive Bayes, support vector machines (SVM), neural networks, and ensemble methods [36].
TF-IDF (Term Frequency-Inverse Document Frequency)
Term weight is measured by how often term j occurs in document I (term frequency tfi, j) and in the entire collection of documents (document frequency dfj. Number of documents containing term j)). When term 𝑡𝑓𝑖, 𝑗 is the frequency of term I in document j (term frequency), DFI is the number of records containing term I (document frequency), and n is the number of records in the collection. The opposite document frequency for a specific word is equal to the total number of documents divided by the number of documents containing that specific word.
Bag of Words (BOW)
The log of the full term is calculated to minimize the impact of division. Given the nature of natural language, a single word can clearly express the authors' point of view, but a sequence of words cannot. Stopword removal or other preprocessing steps can be performed to ignore words based on relevance to a particular use case.
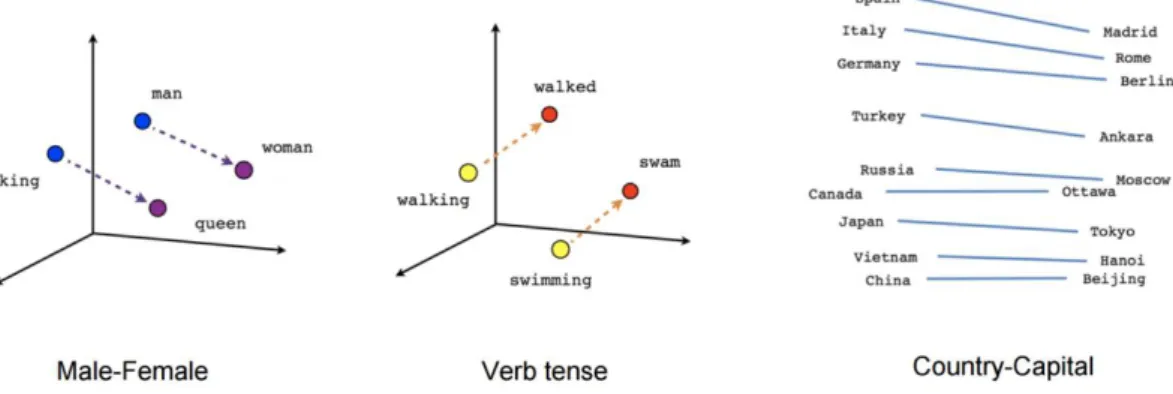
Word Embeddings
The number of hidden neurons is equal to the desired dimension of the word vectors that will result. With CBOW, the prediction relates to the central data word of the surrounding words. In this case, the target word is fed to the input and output levels of the neuron and repeated many times to match the surrounding words.
What is Machine Translation (MT)?
An automated translation system was then implemented by SYSTRAN, which automatically translated texts into other languages. Finally, in 1981, a new system, the METEO system, was deployed in Canada for the translation of weather forecasts in French into English. The world's first web translation program, Babel Fish, was launched in 1997 by the AltaVista search engine.
How does MT work?
- Rule-Based MT
- Statistical MT
- Word-Based MT
- Phrase-Based MT
- Example-Based MT
- Hybrid MT
Rule-Based Machine Translation is a classic approach to machine translation (MT) systems based on linguistic information that includes morphological, syntactic and semantic data from both the source language (SL) and the target language (TL). Rule-based machine translation is the oldest approach and covers a wide range of different technologies. In this approach, a document is translated according to the probability distribution P(e/f) that a string e in the target language is the translation of a string f in the source language.
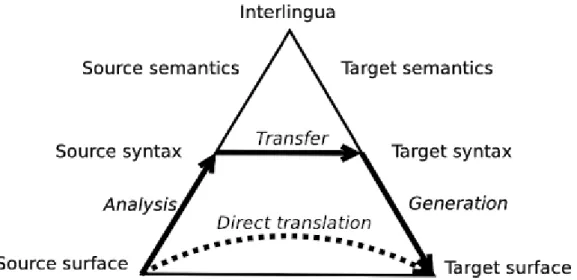
From MT to Neural Machine Translation (NMT)
The main approach and architect of using NNs in NLP tasks and especially in the neural machine translation task is based on the use of an Encoder-Decoder approach. In two years, neural networks surpassed everything that had come out in machine translation in the last twenty years. Neural machine translation contains 50% fewer word order errors, 17% fewer lexical errors and 19% fewer grammatical errors.
Related Work
Google's research team, in their publication [58], introduced an improvement to the model that allows the decoder to pay “attention” to different words in the input string while outputting each word in the output string. One of the latest milestones in Transformers and NLP in general is the release of BERT, an event described as the beginning of a new era in NLP. Shortly after the release of the accompanying paper [62], the team also open-sourced the model's code and made it available for download versions of the model that had already been pre-trained on massive datasets.
DNNs (Deep Neural Networks) in MT
- Convolutional Neural Networks (CNNs)
- Recurrent Neural Networks (RNNs)
- Long Short-Term Memory (LSTMs) Networks
- GRUs (Gated Recurrent Unit)
This problem can be solved by using a slightly modified version of RNNs - long-term memory networks. This is useful for updating or forgetting data because any number multiplied by 0 is 0, causing the values to disappear or be "forgotten". Any number multiplied by 1 is the same value, so that value stays the same or is "kept". The network can learn which data is not important and therefore can be forgotten, or which data is important to keep. In the previous chapter, the three most important and most commonly used Artificial Neural Networks (ANN) for machine translation were analyzed.
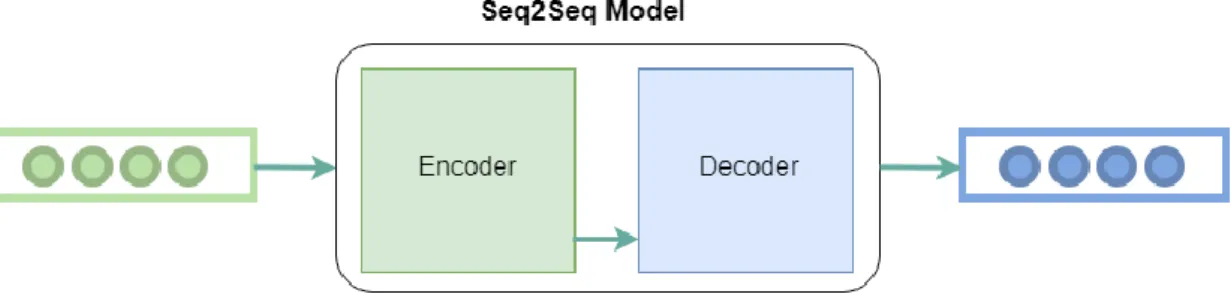
Implementation
Furthermore, we mentioned and noted the impact of Deep Learning in the modern fields of sentiment analysis and machine translation. In addition, the performance of machine translation systems has steadily improved in recent years. Based on this, we seek to investigate the impact machine translation will have on the sentiment of film reviews written in English.

Data Collection
To train our Machine Translation models, we based on language datasets provided by http://www.manythings.org/anki/. In addition, these datasets were used to create the necessary vocabulary and word embeddings for all the languages we used for the purposes of this Thesis.
Evaluation Measures (P,R,F1, BLEU)
Furthermore, the implementation of our code, both for the Sentiment Analysis and Neural Machine Translation tasks, is performed on the Google Colab6 online platform to utilize the GPU option that is available. First applied basic tools and techniques to clean up our raw reviews. Raw reviews contain punctuation, brackets, and some HTML tags as well, so a preprocessing step is essential to provide our system with clean machine-readable data.

Data Preprocessing and Word Embeddings
- Text Preprocessing
- Preparing the Embedding Layer based on Word2Vec model
- Preparing the Embedding Layer based on GloVe
- Tokenization and Padding
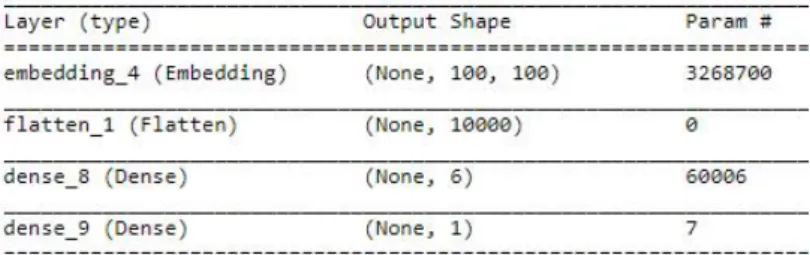
To visualize our Word embeds, we will load our .tsv files into the embedded projector. The embedded Words matrices resulting from the above approach will be used as weights in the embedded layers of our neural network models. Remember that transparent documents are integer-encoded before passing them to the embedding layer.
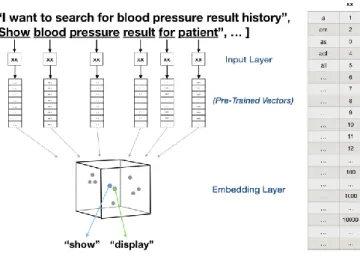
Sentiment Analysis based on DNNs
Since our corpus contains 32687 words and each word is represented as a 100-dimensional vector, the number of trainable parameters will be 32687x100 in the embedding layer. This step is similar to what we had done previously in the Simple Neural Network. As shown in the tables above, the results show that GRU outperforms the other three types, CNN, LSTM and the Simple Neural Network, especially when the dataset is very small, such as 4251 records.
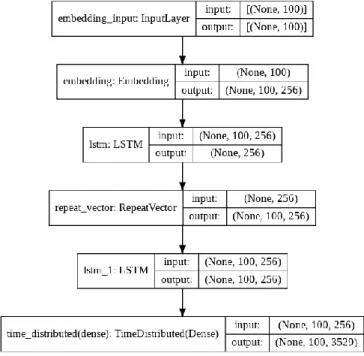
Neural Machine Translation
We can observe a significant loss of about 3-4% in the accuracy and F1 score between the outcomes of performing sentiment analysis on the entire data set than in the smaller one, with only 4251 records. English sentences from the train corpora are 5 words long, while the minimum length of reviews in the examined dataset is 32 words long. So, we make an assumption that if we pad and create larger rows in the train corpora, we can fit the train model in the IMDB dataset.
Machine Translation using open source APIs
This will allow the proper translation for "the" to be "la" and not "le" (singular, masculine) or The attention algorithm will also calculate, based on previously translated words (in this case “the”), that the next word to be translated should be an object (“house”) and not an adjective (“blue”). . It would also calculate that if the adjective was "big" instead of color, it shouldn't reverse them ("big house" => "la grande maison").

Sentiment Analysis on Translated Reviews
On the other hand, the CNN model performs better when used on Greek texts derived from Yandex Translate. If we compare Table 10 with Tables 5 and 6, which contain results of Sentiment Analysis conducted in the source language (English language), we can understand that using our models in the two target languages has similar performance and accuracy according to them in English. Finally, as we also noted in the Sentiment Analysis task in English texts, Deep Neural Network models fail to generalize when trained on small data sets.
Conclusion
Future Work
In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT 2015). In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT 2016). Recurrent Models for Continuous Translation, Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing.