One of the most challenging problems in modern parallel processing systems is to exploit the large number of cores/threads available on modern hardware in order to improve the efficiency of applications by executing pieces of code in parallel. For this purpose, various programming models have been proposed, among which the task programming model. We first examine the library task scheduler, focusing on the task-stealing mechanism, in order to identify its basic functions, and perform some profiling to verify the task-stealing functionality and measure the overhead of each function. base.
Introduction
- Overview
- Multi-socket, multi-processor systems
- Shared Memory Architectures
- Distributed Memory Architectures
- Hybrid Architectures
- A Multi-Socket Multi-Core Machine
- Parallel Programming, Amdahl’s Law, scalability
- Parallel Programming Models
- Shared Memory programming model
- Distributed Memory programming model
- Hybrid Programming model
- Overview of Key Features for Performance
- Problems and pitfalls of parallel programming that should be avoided
- Desired Properties of Parallel Programming Models
If the parallelizable part of the program is relatively small, its speedup would be small regardless of the number of processing units. A more general classification of the communication in a message passing model is based on whether it is performed in a synchronous or asynchronous manner. The time of the longest running task adds to the span, which limits how quickly the parallel portion of the program can run.

Motivation – Overview of the Problem
Regular vs. Irregular &Nested/Recursive Parallelism – Oversubscription -
Even if it is not that difficult, it certainly loses the elegance, readability and maintainability of the recursive formula. Also, a recursive form of an algorithm can be cache-insensitive, thus enabling better use of cache memory. If the programmer tries to create a thread for each of the two recursive calls, it may result in the creation of a large number of threads, which is undesirable.
The TBB Library
- Overview of the library
- How it satisfies the desired properties
Scheduling of software threads on hardware threads by the OS is usually preemptive; it can happen at any time. In contrast, scheduling tasks on software threads is non-preemptive; a thread only switches tasks at predictable switch points. Also, hierarchically decomposing software modules, composability, and nested parallelism become non-issues, as they all end up simply expressing more optional parallelism that will be scheduled on the right number of software threads carefully, without oversubscribing software threads to the system with the discussed detrimental results.
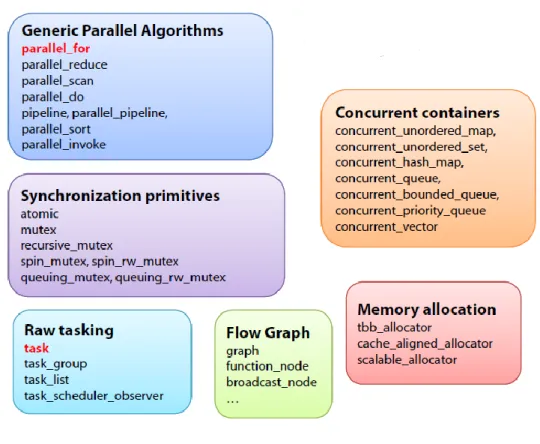
TBB Scheduler
- Cache Coherence Protocols and Problems with Work Stealing
Local instances of the task dispatcher, corresponding to the custom_scheduler class, are registered in each arena slot. When a parallel algorithm is called by a master thread, for example a parallel_for, an initial task is rooted in the main thread's local task pool. In both cases, when the number of threads increases, locking can become a bottleneck for the system due to the randomness of the theft.

Profiling of basic functionalities – Characterization of overhead scalability
- Systems Used
- TBB Scheduler Basics
- Basic TBB Functionalities
- Applications used for characterization
Techniques Used
Optimization targets
Stealing from the nearest neighbor
- Technique description
- Implementation details
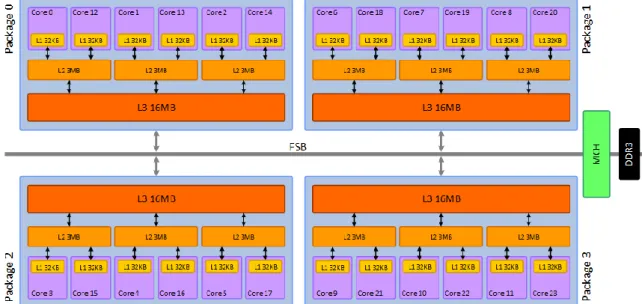
We will refer to these threads as the master worker of the package and the slave workers, respectively. That is, which class of the library should carry the information about the physical core. A number of such objects represent the available slots on each arena that require librarians to populate them and perform some of the arena's work.
When instantiating the master thread's arena, each arena slot is assigned a number that represents the physical core on which it must work. Additionally, the library's stats mechanism keeps track of multiple events and summarizes them for each arena slot. Thus, it was obvious that the library design considers the arena slots as workers and not the dynamic instances of the private_worker class.
The map is essentially a table containing the cpu IDs of the underlying machine, ordered so that for each thread count N, the first N numbers of the table are the cpu IDs for an even distribution of the N OS threads to the packages. Selecting the nearest neighbor required a different data structure, namely an adjacency list for each core containing the core IDs of the machine arranged from nearest to farthest to that core. In more detail, the mechanism works as follows: first, we find the row of the 2d matrix with the neighbors corresponding to the cpu id on which our lock is working.
In case it fails, we continue with the next neighbor until we reach the end of the array if we are the packet master worker, or the end of the L3 neighbors if we are a slave worker.
Stealing from the most loaded processor
- Technique description
- Implementation details
We choose him as a victim and from the reverse map we find the slot in which he works and try to steal them. For this reason, we tried to make a compromise by using the more severe technique theft once in five theft attempts. To have more flexibility in case of failure, a second approach would be for each worker to keep a sorted list of the task loads of all other workers and use that to look for alternatives in case something goes wrong with the heaviest worker.
When the entire area is scanned, it creates ping-pong effects between packets, as all workers must read the workload of all other workers. To implement a mechanism to steal from the heavier CPU, in terms of task load, we needed to add a current_load field to the arena_slot class. Each worker keeps a list of the other workers and their loads, sorted from heaviest to lightest.
When the need arises to steal, the worker chooses his victims from this list, attempting to steal from the most charged worker. The first policy (Policy 1) dictates that the next time we have to steal, we will try to steal from the same victim as the previous successful theft and that we will only return to the beginning of the list if we reach the end or if we refresh the list. . The second policy dictates that every time we have to steal again, even after a successful theft, we start from the beginning of the list, that is, the most burdened worker.
The simple idea was to scan all the arena's slots to refresh the occupancy list.
Evaluation
Physical Systems
Stealing from the nearest neighbor
- Benchmarks Used
- Results
- Remarks
On Sandman, there was an even greater performance increase, reaching up to 40% in high thread counts, indicating that the more NUMA packets, the more potential the cache-aware technique has to exploit localized work theft. Ordtal showed great performance improvement on Sandman, while on Dunnington showed almost the same performance and on Termi suffered excessive performance degradation. In this algorithm, each task keeps a private map that counts the words for its subproblem, and when a join occurs, the task merges its private map with the private map of another task.
Stealing tasks from the same package effectively reduces this overhead, because most of this information is likely found at some cache level, such as the L3 level. The above examples provide the proof-of-concept that stealing neighbors close to our core, in terms of cache hierarchy, can indeed yield large performance improvements. It is noteworthy to mention that the mechanism we implemented does not incur large overheads and applications that do not benefit from this technique also do not suffer from performance degradation.
A number of applications appear to have the same performance as random theft, since their access pattern is not affected by locality issues because there is no significant read-write sharing between cores, which degenerates the selection to be equal to random.

Load Balancing
- Benchmarks Used
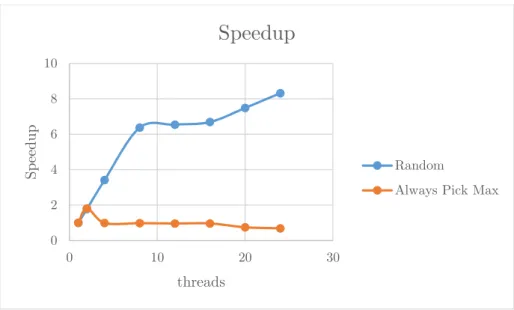
- Results – Finding Max
- Results–Global vs Local Sorted List
As the number of threads increases, the overall cost of these communications dominates the benefits of the technique, resulting in performance degradation. The following sections present the results of the ordered list technique, demonstrating the impact of different alternatives of the two implementations on each application. Streamcluster took advantage of the local search technique in SMP for large thread counts, achieving a performance increase of up to 26%, although at smaller thread counts there was significant performance degradation.
This happens with low thread counts, especially in non-clustered versions, because there are only a few workers in each batch and it is more common to choose a victim from another batch, resulting in more ping-pong effects, given the initial load imbalance that comes with streamcluster . Quicksort takes advantage of the local search variant at high thread counts on SMP, achieving performance gains of up to 17% without incurring excessive overhead at lower thread counts. Applications can be divided into two main categories, those that benefit from a global search technique on all devices (swaptions) and those that benefit from a local search technique on all devices (strassen and streamcluster).
This means that the applications of the first category have a load imbalance that is mainly on a small number of workers and can be mitigated by the global search technique, while the applications of the second category have a more even distribution of work, so that local search benefits the local balance without it caused as much cost as a global search. Both techniques have almost the same performance in Dunnington and Sandman for matrix multiplication. This means that the local search technique could only benefit us with a large number of threads on such platforms.
Furthermore, one could further argue that the overhead of any technique always exists, suggesting that in cases where a technique appears to have negligible overhead, it is because the benefits of the technique compensate for its overhead.
Epilogue – Conclusions & Future Work
Conclusions
Related Work
Future Work
Bibliography - References
Appendix A – Profiling Results
Quicksort
Swaptions
Matrix Multiplication
Convex-hull
Appendix B – Evaluation Results
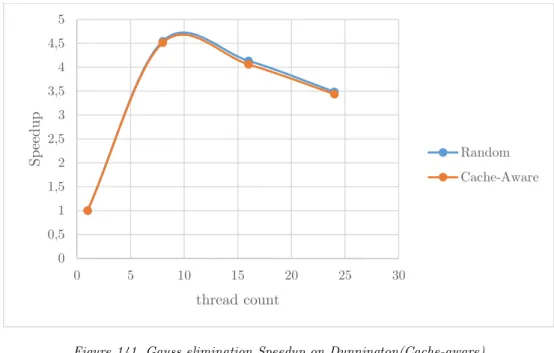
Cache-Aware Techniques
- Heat
- Gauss elimination
- Floyd-Warshall
- Quicksort
- Matrix Multiplication
It is evident from the following figures that the Floyd-Warshall algorithm did not benefit from the cache-aware approach on any machine, nor did it suffer from performance degradation. Quicksort did not benefit from the cache-aware approach to work theft, as shown in the following figures. As can be seen in the following diagrams, our cache-aware mechanism did not cause performance degradation for this application, maintaining its excellent scaling.
Load Balancing Techniques
- Searching for the heaviest once in five steals
- Global vs Local Sorted List