Chapter 3 describes the Intel SCC architecture in detail, highlighting aspects of the platform whose understanding is crucial for characterizing application behavior. This introductory chapter first presents an overview of the concepts of distributed file systems and the MapReduce framework, which this thesis will deal with in the following chapters.
The Hadoop Distributed File System
The MapReduce Framework
Energy Inefficiencies of Hadoop Clusters
Because of the above, the energy efficiency of Hadoop clusters is an area that needs to be explored. The Intel SCC provides a fine-grained power management API that allows us to perform frequency and voltage perturbations on subsets of cores of the SCC board.
The Intel SCC Manycore Platform
Intel Labs provides software that runs on the Management Console to manage the SCC chip. Using Linux on the SCC cores is the most common configuration, but it is not mandatory.
The Benchmark Suites
The SCC is the second-generation processor design resulting from Intel's Tera-Scale research. The SCC has a new memory type and a new processor cache instruction to simplify memory management.

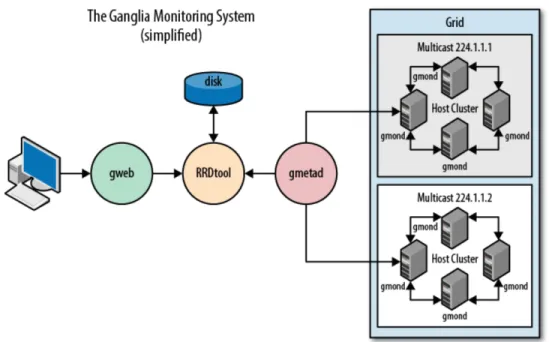
The Ganglia Monitoring System
The Contribution of this Diploma Thesis
For cluster topologies that use only some of the SCC board's cores, the remaining cores operate at the minimum frequency to avoid wasting energy during idle cycles. The second part describes research results on performance and power monitoring of the Intel SCC.
Scale-Out Workloads
In the context of processors for scale-out applications, both architectures make suboptimal use of the die area. Data working sets of scale-out workloads significantly exceed the capacity of on-chip caches.
![Figure 2.1: L1-I and L2 instruction cache miss rates for scale-out workloads compared to traditional benchmarks, [10]](https://thumb-eu.123doks.com/thumbv2/pdfplayerco/330925.52280/32.918.177.743.708.916/figure-instruction-cache-rates-workloads-compared-traditional-benchmarks.webp)
Performance Analysis and Power Consumption Monitoring on the Intel SCCMonitoring on the Intel SCC
High IPC workloads suffer from increased execution time as the distance between communication cores increases. Applications that make heavy use of message broadcasting suffer from significant runtime delays depending on the number of cores involved in the broadcast.
![Figure 2.8: Energy consumption for all possible core clock frequencies, [19]](https://thumb-eu.123doks.com/thumbv2/pdfplayerco/330925.52280/37.918.296.607.285.515/figure-energy-consumption-possible-core-clock-frequencies-19.webp)
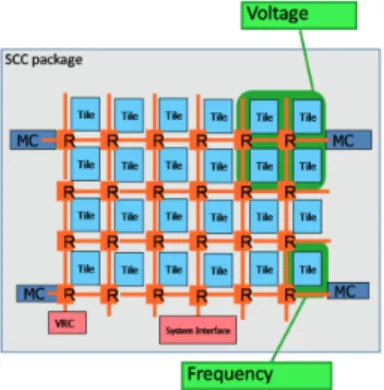
The SCC Core Layout
This chapter provides a detailed description of the functional units of the Intel Single-chip Cloud Computer.
The SCC Tile
- P54C IA Core
- L2 Cache
- Message Passing Buffer (MPB)
- DDR3 Memory Controllers
- Look Up Table (LUT)
- Mesh Interface Unit (MIU)
- Traffic Generator
Each core has a lookup table (LUT) which is a set of configuration registers that map the core's physical addresses to the extended memory map of the system. The core configuration registers are dedicated to each core of the tile and can be written by each core and the system interface unit.
The SCC Mesh
- Router (RXB)
- Packet Structure and Flit Types
- Flow Control in SCC
- Error Checking
Different agents of the mesh fabric communicate with each other at packet granularity. The exception is the MIU, which is the main traffic controller in the tile and uses a request/grant protocol to control tile agent access to the router.
The SCC System Memory
System Memory Map
Credits are automatically returned to the sender when the package moves to the next destination. Each page has a LUT entry that provides route and address translation information.
Memory Address Translation
The SCC Power Management API
- Voltage and Frequency Islands
- The Global Clock Unit (GCU) Configuration Register
- The SCC Power Controller (VRC)
- Changing The Tile Frequency
The value to be written to those bits of the GCU depends on the desired tiling frequency as well as the frequency of the mesh. The resulting executable must be placed in a subdirectory of the /shareddirectory, so that it can be accessed by the kernels.
The Management Console
- sccBoot
- sccPerf
- sccDump
- sccBmc
This command pings all cores on the SCC board and returns the processor IDs of the cores that were successfully reached. The following example shows the output received when sccDumpe is run with the -cswitch, followed by the hexadecimal identifier of the lower left tile (which contains cores rck00 and rck01).

The SCC Linux
The TCP/IP Stack
Packets directed to this interface are sent to the Message Transfer Buffer of the receiving core, that is, the communication between cores takes place entirely within the boundaries of the SCC Mesh and does not leave the SCC board.
The Network File System
This chapter provides a detailed analysis of the Hadoop Distributed File System and the MapReduce framework. Each of the following two sections covers different implementation aspects of HDFS and MapReduce, respectively, and concludes with a list of configuration and runtime parameters that users and cluster administrators can specify regarding HDFS cluster installation and MapReduce job execution.
The Hadoop Distributed File System
- The File System Namespace
- Data Organization
- Data Replication
- The Communication Protocols
- The Persistence of File System Metadata
- Data Availability and Reliability
- File and Block Deletion
- The HDFS Command Line API
- Configuring an HDFS Cluster
Any change to the filesystem namespace or its properties is recorded by the NameNode. The NameNode responds to the client request with the identity of the DataNode and the target data block.

The MapReduce Framework
- The Mapper Function
- The Reducer Function
- Job Configuration
- Task Execution and Environment
- Job Submission and Monitoring
- Job Input
- Job Output
- Configuring the MapReduce Framework
The total number of partitions is the same as the number of Reducer tasks in the job. Create e.g. the temporary output directory of the job during initialization of the job.

Hadoop Runtime Environment for the Intel SCC
- Gentoo Linux for the Intel SCC
- Network Configuration
- Java Installation
- SSH Communication Between Cluster Nodes
- Hadoop Runtime Environment Setup
This way we can enter the Gentoo Linux shell from any Intel SCC core. We made several changes to the network configuration of the Intel SCC and the MCPC.
Hadoop Cluster Topologies on the Intel SCC
Design Choices and Platform Limitations
Another design choice we made concerned the placement of the cluster nodes on the Intel SCC die. As a result, the placement of the DataNodes closer to the memory controllers of the Intel SCC matrix, reduces the latency of their regular.
The hadoop-env.sh Configuration Script
That is, at least one core freeze during the execution of a MapReduce job is the norm and not the exception on Intel SCC. Configuring a replication factor greater than 1 seemed like a reasonable solution at first, as this is the out-of-the-box mechanism that Hadoop provides to ensure that data is always available.
The core-site.xml Configuration File
In this configuration script, we set the JAVA HOME environment variable to the directory path where Java is installed in each Gentoo Linux image on Intel SCC cores. In the HADOOP SSH OPTS variable, we noted that ssh connections should be attempted on port 1234 as the user in order to use the SSH server described in the previous section of this chapter.
The hdfs-site.xml Configuration File
The file block replication factor is defined by the dfs.replication property and the file block size by the dfs.block.size property. Dfs.name.dir defines the local file system directory where the NameNode should store the name table (FsImage) and dfs.data.dir defines the directory where DataNodes should store file data blocks, in their local file systems.
The mapred-site.xml Configuration File
The maximum number of Map and Reduce tasks that can be executed by a TaskTracker at one time is defined in mapred.tasktracker.map.tasks.maximum and mapred.tasktracker.reduce.tasks.maximum properties, respectively. Finally, the mapred.reduce.tasks determines the number of reduce tasks to be executed by a MapReduce job.
The masters Configuration file
There are two scripts to run to run a 32-node Hadoop cluster on an Intel SCC. To run a 48-node Hadoop cluster on an Intel SCC, there are two scripts to run.

Node Failover Watchdog
Once Linux has started, scriptstart.sh is called in order to configure the Hadoop Runtime Environment, the gmond monitoring daemon is started (more details in the next chapter), and the corresponding Hadoop Daemon is launched into the kernel. The only file that is different is the slaves file, which only contains the IP address of the specific core, so the Hadoop Daemon starts only on that core.
Apache Mahout Installation on the MCPC
The first part of the chapter explains the process of configuring a Ganglia cluster, which consists of Intel SCC and MCPC cores, and how this Ganglia cluster works, i.e. the second part of the chapter provides a detailed description of the scripts we developed that query the Ganglia Cluster and BMC to capture runtime metrics, store those metrics in a monitoring database we designed, and visualize the collected data.
Ganglia Monitoring Infrastructure for the Intel SCC
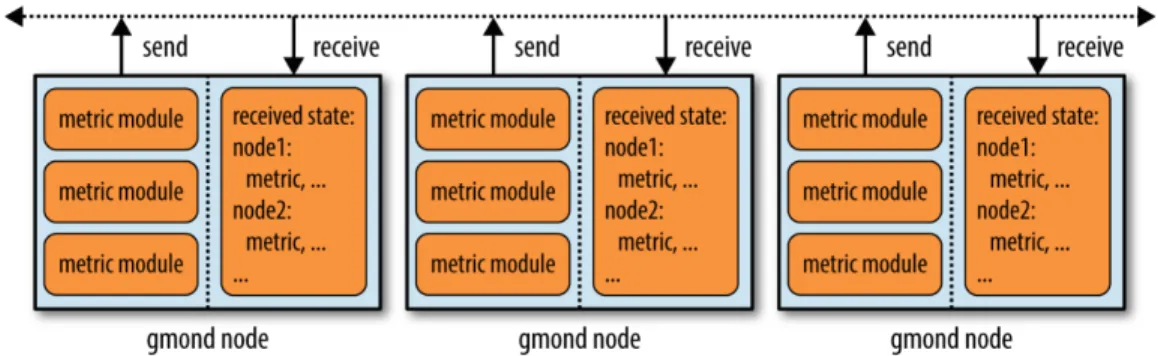
- The gmond Monitoring Daemon
- Ganglia Cluster Topology on the Intel SCC
- The gmond.conf Configuration File
- Ganglia Cluster State Reporting
The runtime metrics reported by the Intel SCC cores are received through this channel. We noticed that the Intel SCC cores always assume they are running at 800 MHz.
Runtime Metrics Extraction and Visualization
- Monitoring Database Structure
- Extracting and Storing Runtime Metrics
- Runtime Metrics Mining
- Runtime Metrics Visualization
The name of the database table to query as well as the name of the CSV output file are also given as command line arguments. The name of the database table to query as well as the name of the CSV output file are given as command line arguments.

The Wordcount Application
Algorithm Description
The Mapper function receives
Application Execution and Input Files
The Mapper function maps each line to extract the words it contains, and outputs intermediate
HOSTS 32
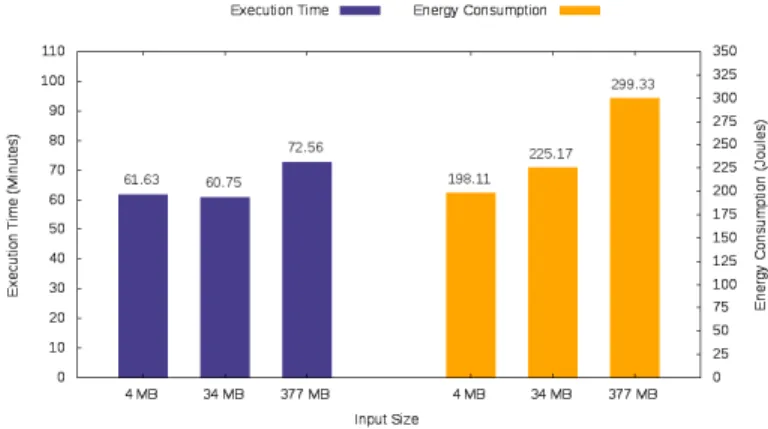
Scalability Analysis Per Input Size
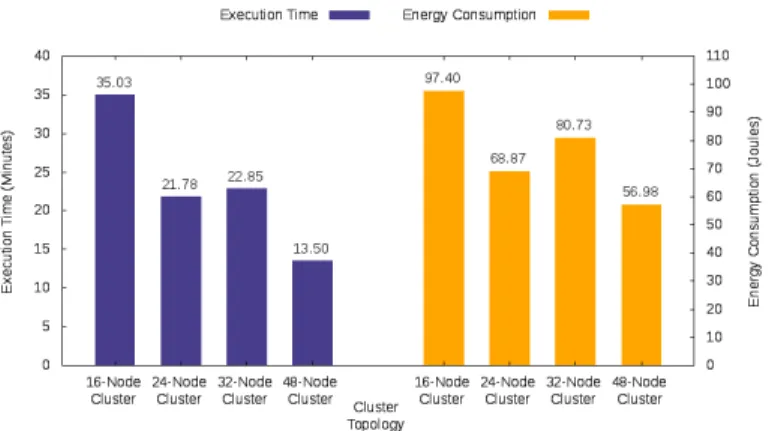
The experimental results we have received regarding the execution time and energy consumption of the Wordcount application are presented below. Our analysis clearly shows that both the execution time and energy consumption of the Wordcount application scale linearly as the size of the input text file increases.
Cluster Topology Analysis
The CPU usage graphs of the TaskTracker nodes illustrate that the increase in execution time can be interpreted by the fact that more. The intermediate
Frequency Scaling Analysis
This fact can be attributed to the lower temperature of the Intel SCC board due to the lower utilization of the platform at that time. Consequently, the results of this rerun cannot be used to more accurately measure the energy consumption of the DN800-TT800 setup.

Cluster Utilization Overview
Due to the fact that in our setup all stress domains also contain DataNodes and TaskTrackers, we were not able to perform stress scaling. Since power consumption is proportional to the product of the core frequency and the square of the voltage, as the following equation indicates, scaling down the voltage will lower energy consumption even more, without compromising performance at all.

The Bayes Classification Application
- Algorithm Description
- Application Execution and Input Files
- Scalability Analysis Per Input Size
- Cluster Topology Analysis
- Frequency Scaling Analysis
- Cluster Utilization Overview
The experimental results we received regarding the runtime and power consumption of the Bayes Classify application are presented below. The experimental results we received regarding the runtime and power consumption of the Bayesian classifier application are presented below.

The K-Means Clustering Application
- Algorithm Description
- Application Execution and Input Files
- Scalability Analysis Per Input Size
- Cluster Topology Analysis
- Frequency Scaling Analysis
- Cluster Utilization Overview
This section analyzes the effects of frequency scaling on the execution time and power consumption of K-Means Clustering on Intel SCC. The experimental results we received regarding the execution time and power consumption of the K-Means Clustering application are presented below.

The Frequent Pattern Growth Application
- Algorithm Description
- Application Execution and Input Files
- Scalability Analysis Per Input Size
- Cluster Topology Analysis
- Frequency Scaling Analysis
- Cluster Utilization Overview
The experimental results we obtained regarding the execution time and power consumption of the Frequent Pattern Growth application are shown below. This section presents our analysis of the behavior of the Frequent Pattern Growth application when it runs on top of different HDFS cluster topologies on Intel SCC.
General Remarks
First, the very low amount of private memory for the Intel SCC core (~640MB) allowed us to configure a maximum of 128MB for the Java Heap Space of the Child JVMs running the Map and Reduce tasks. As a result, a significant percentage of CPU cycles were wasted on garbage collection so that the application could respect that constraint.
Future Work
Coskun. Performance and Power Analysis of RCCE Messaging on Intel Single-Chip Cloud Computing. School of Information Technology, University of Sydney, Australia, 2008. http://www.florian.verhein.com/teaching.