Questions about the use of the work for acquisition should be directed to the author. The resulting blended pyramid corresponds to the Laplacian representation of the flawlessly blended final image.
Types of deepfakes
- Entire face synthesis
- Attribute manipulation
- Face swap
- Face reenactment
For attribute manipulation, the images were extracted from the official StarGAN [23] github site: https://github.com/yunjey/stargan. Finally, for head re-rendering, real images correspond to YouTube footage and fake images were produced using the Head2Head ++ method [36].

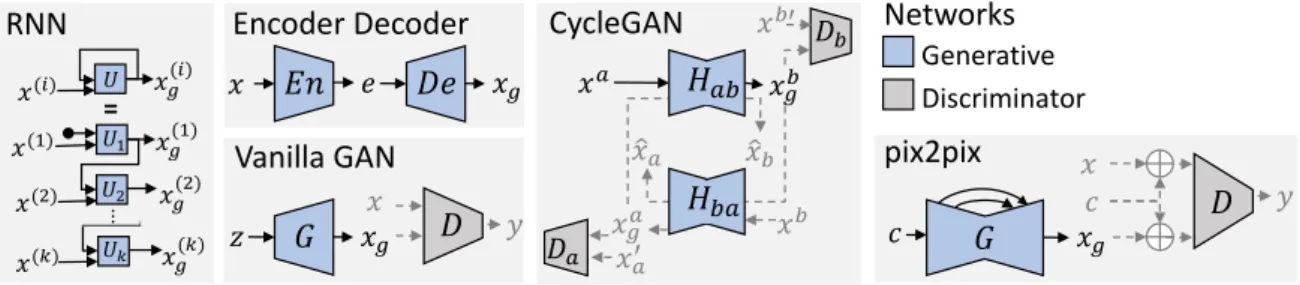
Deep Learning for face generation and manipulation
- Convolutional Neural Network (CNN)
- Recurrent Neural Network (RNN)
- Encoder-Decoder Network (ED)
- Generative Adversarial Network (GAN)
In the case of image synthesis and manipulation, generative deep learning builds models that are capable of synthesizing visually compelling images by simply learning the statistical nature of real-world photographs. In contrast to a fully connected (dense) network, a CNN learns hierarchies of patterns in the data and is therefore much more efficient in image processing. More advanced versions of RNNs include short-term memory (LSTM) [54] and gate recurrent units (GRU) [22] that are efficient in handling vanishing gradient problems, which are common in very long sequences.
Face representations and manipulation process
Train the ED network to separate identity from expression, then change/swap target and source face encodings before passing it through the decoder [89]. Create composite original content (hair, scene, etc.) using a combination of 3D rendering, distorted image, or generated content and pass the composite through another network (such as pix2pix [58]) to improve realism.
Emotion manipulation
Image-based emotion editing
The introduction of GANs [49] has sparked a growing line of research in image manipulation. The vast majority of works use a conditional generator, in the sense that the synthesized image is conditioned by another image (e.g. [58]). This is especially important in the mouth area, as the conveyed speech can be distorted if such techniques are applied independently to each frame of a video.
Geometry-based emotion manipulation
This makes it possible to translate images between different domains (i.e., image-to-image translation) while preserving the content of the source image, even when training on non-parallel data through the notion of cycle consistency [144]. However, their method completely ignores the original expressions and mouth movement of the target actor. 67] presented a style-preserving solution for film dubbing, where the expression parameters of the dubber pass through a style translation network before driving the performance of the foreign actor.
Applications
Movie post-production
Solanki and Roussos [109] train a decoder network that maps Valence-Excitation pairs to the expression coefficients of a 3D face model and synthesizes the target actor with a neural interpreter. Their method preserves the dubber's speech, but can only translate between a pair of speech styles (dubber-to-actor). By controlling the expressive style of the generated speech face, the target actor can appear to follow the foreign speech of the dub, while maintaining his original emotional state [67].
Emotional avatars
Social media content creation
Challenges
Pairwise Training The straightforward way to train a neural network is to associate each given input with the desired output. This data matching process is often impossible for deep forgery systems that are trained on video footage from multiple identities. In some cases, this can be limited by explicitly modeling the person's specific facial geometry with the help of a 3D face model.
Thesis objectives and adopted methodology
However, this can lead to the identity of the target person being distorted, when, for example, the identity of the source/row subject is partially transferred to the output.
Contributions
Thesis Outline
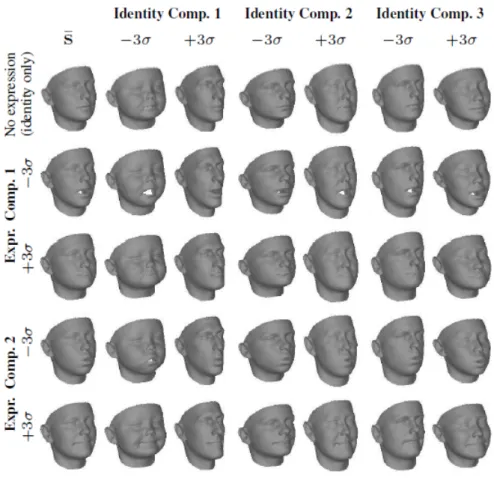
Shape
11] build a large-scale morphable model from a PCA of approximately 10,000 3D scans, one of the largest datasets of 3D faces ever collected. Note that a 3DMM is essentially a generative model and can be associated with a prior distribution p(w) (eg Gaussian) over the shape space. Of course, nonlinear expansions have also been explored in the context of modern deep learning.
Expression
If all instancesci ∈R3n in the dataset correspond to neutral faces (without expressions), then the latent d-dimensional space learned by a 3DMM explains the variability caused by identity alone, i.e. FLAME [82] is another large-scale linear shape model learned by PCA, even more complex, as authors extend it with fine details such as articulated jaw, eyeballs, neck and non-linear pose deformations. Learning a latent space can be seen as the goal of anautoencoderand, so a first approach to train a 3DMM in an encoder-decoder framework was performed by Abrevaya et al.
Appearance
A disadvantage of this approach is that shape and appearance data must be rendered in compatible resolutions, while traditional computer graphics typically rely on a higher resolution 2D texture map for appearance. Therefore, many approaches treat texture as a reflection map of the face instead of RGB values. By combining all the above variations, a fully morphable model of the human face can be built, where the latent space allows the creation of new 3D faces.
Monocular 3D face reconstruction
Model-based reconstruction (Analysis-by-synthesis)
Deep learning approaches
Recovering fine-scale details
Variants of the original loss
StyleGAN
Create a composite of the original content (hair, scene, etc.) with a combination of the 3D rendering, warped image or generated content, and send the composite through another network (such as pix2pix [58]) to to refine realism [36] , [68]. A thorough review of the history of 3DMMs is given in the recent survey of Tewari et al. An overview of the influence of the different energy terms in the reconstruction quality is shown in Fig.
In the original minimax game, the generator minimizes the log-likelihood that the discriminator is correct. The uniqueness of the InfoGAN compared to the standard GAN is the introduction of a regularization term(I) that captures the shared information among the interpretable variables(c) and the generator output.
Image-to-image translation with conditional GANs
- pix2pix
- CycleGAN
- StarGAN
- StarGAN v2
The generator is fed a real input image from a source domain (left) and translates it in the target domain (right). In particular, CycleGAN uses 2 generators and 2 discriminators (see Fig. 3.5): one pair G, DY to map images from the source to the target domain (forward), and the other, F, DX, for the reverse (backward). The mapping network transforms a latent code into style codes for multiple domains. c) The style encoder extracts the style code of an image, enabling the generator to perform reference-controlled image synthesis. (d) The discriminator distinguishes between real and fake images from multiple domains.
![Figure 3.4: Some exemplar results from pix2pix [58]. The generator is fed with a real input image from a source domain (left), and translates it in the target domain (right)](https://thumb-eu.123doks.com/thumbv2/pdfplayerco/330932.52283/68.892.112.761.128.370/figure-exemplar-results-pix2pix-generator-source-domain-translates.webp)
GANs in Computer Graphics: Neural Rendering
- Face detection
- Face segmentation
- Landmark detection and face alignment
- Architecture
- Objective functions
- Training and testing
First, we perform 3D face restoration and alignment on the input frames to obtain facial expression parameters. We use MTCNN [141] to obtain the face bounding box and resize the cropped image to 256×256 pixels. Detecting the face of the target actor in the video is the first essential step when using our 3D facial analysis.
![Figure 3.11: Typical applications of neural rendering. (Top) Semantic image manipulation [7], (Middle) novel view synthesis [132] and (Bottom) portrait relighting [111]](https://thumb-eu.123doks.com/thumbv2/pdfplayerco/330932.52283/75.892.139.778.201.726/typical-applications-rendering-semantic-manipulation-synthesis-portrait-relighting.webp)
Photo-realistic synthesis “in the wild”
- Neural Face Renderer
- Blending
- Datasets for experiments
- Meta-renderer
- Details about running the methods
- Qualitative results
The other two losses in the generator's learning objective function are: 1) a VGG loss LGvgg and 2) a feature corresponding to lossLGf eat, first proposed in the work of Xu et al. The seamless composition of the generated face on the original portrait image is achieved using multi-band blending [17], similar to [89] and [115], as we found this outperformed simple soft masking or Poisson operation [96] in terms of smooth border crossing . Our method implies that a person-specific face renderer had to be trained separately for each actor of the above-mentioned datasets.
![Figure 4.13: Overview of our neural face renderer (only the generator G is shown) which is adopted from Head2Head++ [36]](https://thumb-eu.123doks.com/thumbv2/pdfplayerco/330932.52283/90.892.100.762.129.429/figure-overview-neural-renderer-generator-shown-adopted-head2head.webp)
Comparison with state-of-the-art methods
Quantitative Comparisons
For our experiments, we use the feature vectors of the state-of-the-art ArcFace facial recognition network [31] for all the ground truth and the generated frames. However, for the other 3 methods, the label y of the original video must be known so that it can be used as the target label. As already reported, we observe that our method performs better in preserving the original emotion without distorting the features of the specific identity, resulting in lower FAPD values than all the other methods.
User Studies
In the first user study, participants were shown randomly shuffled manipulated videos of 3 actors from the MEAD database in all 6 basic emotions and asked to rate the realism of the video on a 5-point Likert scale and to identify the expressed emotion ( from a drop-down list that included all 6 emotions ), as shown in the figure. Detailed realism scores for each of the five points of the adopted Likert scale as well as user classification accuracy can be seen in Table 5.3. In another study, we presented users with manipulated videos (including original audio) of 6 YouTube actors in all 6 basic emotions and asked them to rate the realism.

Ablation Study
The results for all measurements (averaged across all 3 actors), as shown in Table 5.5, show the contribution of both the detailed shape images and the face alignment, especially in the very challenging mouth area (see MAPD). Finally, the metrics in the fourth row reveal that the meta-renderer further improves the results, although our motivation for this pre-training step was to improve the realism when the expressions are translated into different emotions. Bold and underlined values correspond to the best and second best values of each metric, respectively.
Conclusions and additional visualizations
The created faces correspond to the same basic sentiment of truth with which they are marked. Our in-depth review of the related literature reveals that the existing methods are mostly limited to image-to-image translation techniques, which show satisfactory results for static images, but do not cope with the third objective, and thus are ineffective for face manipulation in videos. Under this setup, our new 3D-based Emotion Manipulator translates facial expressions by carefully preserving the speech-related content of the source representation.

Future work
Ethical issues and social impact
Dunaway, “A 3D morphable model learned from 10,000 faces”, in Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), 2016. Smolley, “Least squares generative adversarial networks”, in Proceedings of the IEEE International Conference on Computer Vision (ICCV), 2017. Smith, "3d morphable face models revisited", in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2009.