Keywords: MapReduce Programming Model, Parallel Programming, High Performance Computing, Pipeline Technique, Shared Memory, Multi-core and Multi-processors. This thesis concludes my studies at the School of Electrical and Computer Engineering at the National Technical University of Athens.
Εισαγωγή
Επισϰόπηση Πρότασης
Θεωρητιϰό Υπόβαϑρο
Phoenix++
Ανασϰόπηση Σχετιϰών Υλοποιήσεων
Pipelined MapReduce
Λεπτοµέρειες Υλοποίησης
Αρχιτεϰτονιϰή Pipelined MapReduce
Μοιραζόµενες Ουρές Ταυτόχρονης Πρόσβασης
Μνήµη-ενήµερη Πολιτιϰή ∆εσίµατος Νηµάτων σε ΚΜΕ
Χαραϰτηρισµός Εφαρµογών
Αποτελέσµατα
Πειραµατιϰή Πλατφόρµα
Αξιολόγηση των ∆ιαφόρων Πολιτιϰών
Κατανάλωση Στοιχείων σε ∆έσµες
Αξιολόγηση Επίδοσης
Συµπεράσµατα ϰαι Μελλοντιϰές Επεϰτάσεις
Συµπεράσµατα
Μελλοντιϰές Επεϰτάσεις
Big Data, is a term that has emerged to characterize extreme volumes of data, with a wide variety of data types, sometimes unstructured, that need to be analyzed periodically or in real time. Scalability The framework should be able to efficiently manage the code execution and the available resources and ideally maintain a linear performance acceleration with the addition of extra computing resources. The framework must be in a position to withstand hardware, software and network failures and recover quickly.
Simplicity The developer should be able to code using a simple model, independent of data size and framework complexity.
MapReduce with Shared-Memory Properties
The fact that MapReduce combines all the above features has coupled it with Big Data processing.
Proposal Overview
Thesis structure
Introduction
MapReduce Runtime
MapReduce Architecture
Periodically, a partition function divides the intermediate buffers on R regions, equal to the number of reduce tasks, and dumps them on local disks. Master is informed of the location of these partitions and will later communicate this to the reduced workers. After that, the reducer passes the keys with their corresponding set of values to the user-defined reduce function that concatenates them.
At the end of the reduction phase, control returns to the user code.
The "Hello World" of MapReduce
Once a reducer has gathered all the necessary key-value pairs, it sorts them by key so that values with the same key are grouped together. Note that the sort is required since multiple keys are generally associated with the same reduce task. After successfully running a MapReduce instance, the output from each reducer worker will be available in a separate file.
Success and Extensive Applicability
Phoenix: MapReduce runtime for multi-cores and multi-processor
- Modern Parallel Programming Models
- Original Phoenix Library
- Phoenix Rebirth
- Phoenix++: The Latest Implementation
- Alternative Shared-Memory MapReduce Libraries
The arguments are the number of Reduce tasks, a pointer to the keys, and a key size. Because of the functional nature of the MapReduce model, Phoenix can actually provide information that simplifies error detection. Once the column is defined, the element is indexed by the hash value of the key.
The key to the efficient behavior of the hast+tree structure described above is the accurate estimation of the number of intermediate keys.
High-Performance Shared Queue Implementations
MCRingBuffer
Two aspects are considered to achieve cache efficiency, (i) cache line protection and (ii) updates of control variable sets. When multiple threads are accessing different data located in the same cache line, they invalidate the state of the cache line. MCRingBuffer places control variables (ie variables used by the buffer implementation to ensure proper thread synchronization, such as the number of elements written or read) into different cache lines using the padding technique.
On a basic implementation of a circular buffer, control variables are updated each time a consumer reads from the buffer, or a producer writes to it.
Fast Forward
Thus, the cache system will require other threads to reload their data from memory, even though their data has not actually been modified. However, MCRingBuffer divides the ring buffer into batch_sizeelements blocks and increments the read or write control variable to the next block only after batch_-sizeread or write operations. Note that this batch update scheme is based on the assumption that new data is always available, which is not always the case.
Proper modification by the programmer is required to support applications with a limited number of elements pushed onto the queue.
MapReduce Architecture Related Work
Pipelined MapReduce
The purpose of this chapter is to provide the reader with a thorough understanding of the implementation and architecture-specific details of our proposed Pipelined MapReduce runtime. The chapter is organized as follows: in Section 4.2 we present the workflow of our proposed runtime, in Section 4.3 we describe and reason about our choice of the mappers-combiners and the shared data structure. In section 4.4 we demonstrate the various thread-to-CP U-binding policies we created.
Pipelined Map Reduce Architecture
If the input needs to be formatted in a certain way, the user must supply the split function, otherwise the input is split using the default function provided by the library. Choosing the optimal task size is not trivial, as large task sizes will result in ordinary load balancing, while very small task sizes will result in non-negligible library overhead in terms of computation. Map workers iteratively dequeue jobs from their local queue and apply the custom map function to the job data.
They fetch batches of key-value pairs from the queue, combine them using the custom combine function, and finally store the result in their local container.

Concurrent Shared Buffer
Queue Characteristics
Assuming hardware support for atomic instructions, such as compare-and-swap (CAS), it has been proven by Maurice Herlihy [43] that it is feasible to create a multiple producer, multiple consumer (MPMC), lock-free, wait-free queue. Since SPSC queues are specialization of MPMC queues, an MPMC queue can also be an acceptable candidate for our design. Unfortunately, the extra overhead of using atomic operations is not negligible on modern processors, and as a result, even the most optimized MPMC arrays are outperformed by Lamport's circular buffer with one producer and one consumer.
Considering all of the above, we conclude that a concurrent, single-producer, single-consumer, lock-free, wait-free, circular, fixed-size buffer is the most suitable data structure for our needs.
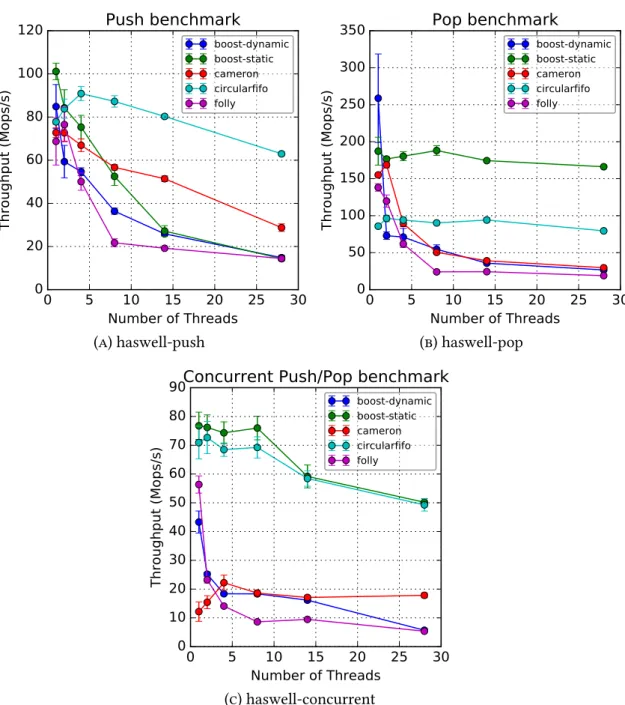
Queue Implementations Benchmark
The overall picture is different from Haswell, with Circularfifo showing the best push performance, cameron and boost-static sharing the best pop throughput, and cameron having the best simultaneous push/pop performance. To select the best queuing implementation, other than from the benchmarks shown in Figures 4.2 and 4.3, we considered their API. With the exception of dynamic/static queues, all res provide a limited API, which includes the basic functions of push(), pop(),top() plus asize() approach.
This led us to decide to use boost, with static memory allocation, as the core of our SPSC queue.
Queue Optimizations
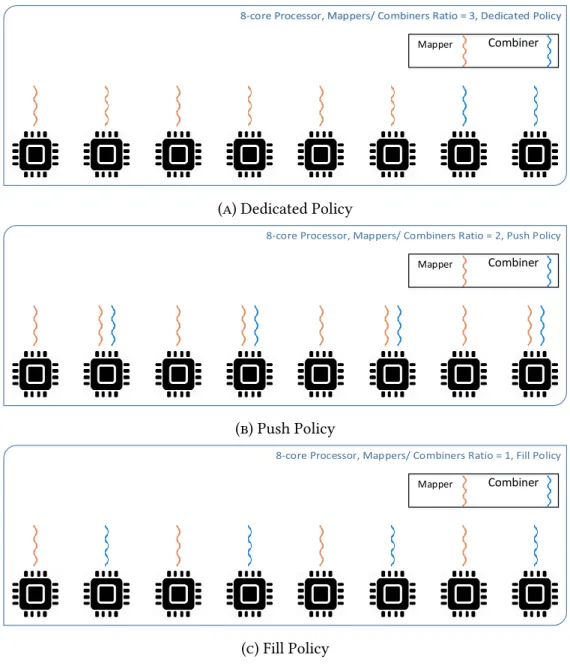
Memory Aware Thread-to-CP U Binding Policies
Memory Aware Thread-to-CPU Connection Policies 51Manufacturer Sleep Time The way our architecture is designed, requires that,. Second, we choose the most appropriate threading policy, from the three different policies we implemented, shown in Figure 4.4.
Proper Configuration is Crucial
MapReduce Runtime Configuration
In practice, we have found little use for the MR_NUMMAPTASKS variable, as choosing an optimal number of map tasks is both application and input size specific. As in all our target applications, the reduce phase takes up only a small fraction of the total execution time, we did not experiment with the number of reduce tasks.
Map-Combine Pipeline Configuration
Secondary Contributions
Synthetic Test Suite
A set of runtime configurable variables are used to adjust the weight of the map and combine tasks independently. We can clearly see how the optimal ratio depends on the workload's weight distribution over card and combination phases.

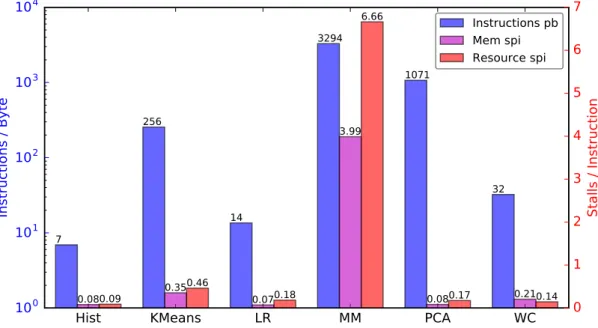
Application Characterization
Finally, PCA and Word Count are neither fully suited nor incompatible with our library, as they have sufficient complexity but not too many deadlocked cycles per instruction. More specifically, a fixed-size hash was used in Histogram, KMeans, linear regression, and word count, and a regular hash for Matrix Multiply and PCA. Looking at Figure 4.7, we conclude that KMeans, Matrix Multiply, and Word Count are suitable for our implementation, as they have sufficient complexity and frequent stalls.
Histogram and linear regression are not completely incompatible, as they often encounter memory and resource bottlenecks, but their workloads are still relatively low.
Experimental Setup
Intel ® Haswell
The platform we used for our measurements is a dual-slot Intel®
Intel ® Xeon Phi™
Static-Dynamic queue comparison
Different policies comparison
Different chunk size
As a general rule, we can conclude that applications benefit from approximately 4 to 8 times smaller chunk sizes. The advantages of smaller chunk sizes are that they fit more comfortably in cache memory and lead to better load balancing due to greater number of map tasks. On Xeon Phi there is an average improvement of 4.3% with optimal chunk size, compared to the default, and on Haswell the average improvement is 1.9%.
Different buffer size
Different batch size
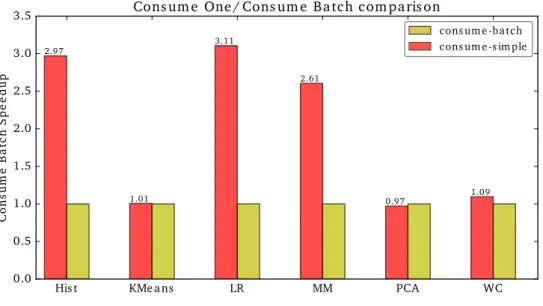
The effect of batch reads is depicted in Figure 5.10 for the Haswell system and in Figure 5.11 for the Intel® Xeon Phi™. We see an impressive speedup of more than 10X for Histogram and Linear Regression on Xeon Phi, and a reasonable speedup up to 3X for Histogram, Linear Regression and Matrix Multiply on Haswell. Figure 5.12 summarizes the effect of different batch sizes on each of the six target applications on Haswell.
Similar results can be seen in Figure 5.13, which shows the effects of batch size on Xeon Phi for each application. f) Number of words Figure 5.12: Effect of batch size on Haswell. f) Number of words Figure 5.13: Effect of batch size on Xeon Phi.
Performance Evaluation
Intel Haswell Platform
This change affects the combiner workload, as a hash value must be calculated and memory allocated each time a new element is stored in the container. Matrix Multiply shows a 2.46x average speedup, Histogram and Word Count a speedup of 1.77x and 1.69x respectively, KMeans is an average of 1.46x times faster and Linear Regression 1.21x.
Intel ® Xeon Phi™ Co-Processor
The former consists of two Haswell nodes of the Intel® Xeon generation, with 14 cores / 28 threads at 2 GHz, and the latter is an Intel® Xeon Phi™, with 57 cores / 228 threads at 1.1 GHz, co-processor. Similarly, on Intel® Xeon Phi™, our implementation performed better in three applications (KMeans, Matrix Multiply and WC), equally in PCA and worse in Histogram and Linear Regression. However, when changing the intermediate container to fixed hashes, the results were impressive, with our architecture achieving a speedup of up to 5.7x in all applications except PCA, which was 20% slower, on both Haswell and Xeon Phi.
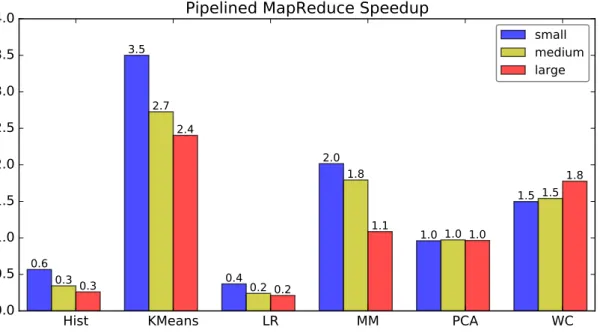
Our Pipelined MapReduce implementation managed to exploit the inefficiencies of the traditional architecture that requires serialization of Map and Combine jobs.
Future Work
However, we noticed that test cases such as histogram and linear regression were not well adapted to our alternative MapReduce runtime. To support memory-aware and communication-pattern-aware CPU thread association, we decided to statically assign mappings to combiners. However, this can result in sub-optimal load balancing, and the ratio of maps to aggregates is very critical for good performance.
Although this approach has the advantages of dynamic load balancing and automatic adjustment of mapper-to-combine ratio, it lacks memory and communication pattern awareness.
Original License
- Traditional MapReduce Work-flow Inefficiency
- Google’s MapReduce execution overview
- Phoenix API
- Phoenix scheduler_args_t data structure type
- Phoenix execution overview
- Phoenix vs PThreads
- Phoenix intermediate buffer
- Pipelined MapReduce Architecture
- Queue Benchmark on Intel Haswell
- Queue Benchmark on Intel Xeon Phi
- Thread to CP U binding policies
- Synthetic Test-case
- Harware counters, Default Containers, Phoenix++
- Harware counters, Hash Containers, Phoenix++
- High Level Architecture of the systems on which we tested our im-
- Static-Dynamic Allocation on Haswell
- Static-Dynamic Allocation on Intel Xeon Phi
- Thread-to-CP U Binding Policies on Haswell
- Thread-to-CP U Binding Policies on Intel Xeon Phi
- Chunk Size Effect on Haswell
- Chunk Size Effect on Xeon Phi
- Buffer Size Effect on Haswell
- Buffer Size Effect on Xeon Phi
- Read Simple vs Read Batches on Haswell
- Read Simple vs Read Batches on Intel Xeon Phi
- Batch Size Effect on Haswell
- Batch Size Effect on Xeon Phi
- Pipelined Phoenix vs Phoenix++ with Default Containers, Haswell . 70
Obviously, the code in listingB.1 is problematic because of the concurrent access to the shared number of variables. In: Proceedings of the 5th ACM/IEEE Symposium on Architectures for Network and Communications Systems. In: Proceedings of the 13th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming.
Design and implementation of the linpack standard for single- and multi-node systems based on the intel® xeon phi coprocessor”.