As unsupervised vector word representations, they can be used in a variety of ways, such as word features in NLP systems or input to learning algorithms. In this thesis, we analyze and compare different deep neural network architectures used to produce WE to accurately map syntax, meaning, semantics, and context. Among the models evaluated, the most prominent ones used today are “Improving Word Representations via Global Context and Multiple Word Prototypes” (Huang et al., 2012), “Word2Vec” (Mikolov et al., 2013) and “Glove : Global vectors for word representation” (Pennington et al., 2014).
Background
Word Embeddings & Vector representations
This is a convenient representation that captures the semantic and syntactic information that words contain. These representations can be used to drive similarity measures by computing distances between vectors, leading to a plethora of useful applications, some of which are; information retrieval (IR) (Parsing Manning et al [20] [3]), document classification (Sebastiani chunking [46] and query answering (Tellex et al. A large body of research on semantic and syntactic textual similarity has focused by building state-of-the-art embeddings using sophisticated modeling and careful selection of learning signals.
While word embeddings are extremely useful and are the standard for displaying word meaning, their representations as products of neural networks have a long way to go before they are completely trustworthy.
Word Embedding Applications
Basic Models presentation
Contribution
Finally, we explore the results obtained by testing the models against a selection of data and measurements, discuss the inference provided by the previously mentioned benchmarks, as well as the limitations of the models and areas where improvement is needed.
Methodology
The models were trained on two datasets: the entire Italian Wikipedia dump and a collection of 31,432 books (mostly novels) written in Italian. The authors believe that by using two very different datasets, both in purpose and style, they will investigate the impact of training data on both models. However, it does not have the same accuracy as trained on English datasets, which may be a sign of a higher complexity of the Italian language.
Comparison between different models for word embeddings in different languages is also performed in [26], where the authors first compare Hungarian analogical questions with English questions by training a Skip-gram model on the Hungarian web corpus. Ghannay et al, [15] evaluated word embeddings generated by CSLM word embeddings [40], dependency-based word embeddings [22], combined word embeddings, and Word2Vec's Skip-gram model on several NLP tasks. The models were trained on the Gigaword corpus of 4 billion words, and the authors found that the dependency-based word embeddings gave the best performance.
Authors in [39] compared Word2Vec's CBOW model, GloVe, TSCCA [12], C&W embeddings [11], Hellinger PCA [21] and Sparse Random Projections [24] and concluded that Word2Vec's CBOW model outperformed the other encodings on 10 out of the 14 test datasets. Local context represents the syntactic information of the sentence or phrase in which the word is contained, as well as the grammatical relationships that are formed. Each word embeddingxi is a column in the embedding matrixL∈Rn×|V|where|V|denotes the size of the vocabulary.
For the neural network output that examines the global context, the entire document is also represented as an ordered list of word entries, d = (d1, d2, .., dk). The local score preserves word order and syntactic information, while the global score uses a weighted average which is similar to word clustering features, capturing more of the semantics and topics of the document.
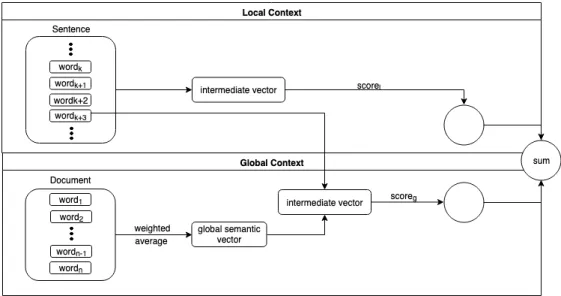
Word2Vec (Mikolov et al, 2013)
The Skip-gram model [28] is used and modifications are provided to improve the accuracy of the representations and the processing time. The calculated probability is used to learn the weights on the hidden layer of the neural network. The problem of frequent words that do not provide useful information to the representation is solved by subsampling frequent words.
Each neuron on that layer has a weight vector which is multiplied against the word vector in the hidden layer. Larger results in more training examples and thus can lead to higher accuracy at the expense of training time. More precisely, each word can be reached by an appropriate path from the root of the tree.
The tree structure used by hierarchical softmax has a significant impact on performance. And while NCE approximately maximizes the log likelihood of the soft maximum, this property is not important for this application. The formula speeds up learning and even significantly improves the accuracy of the learned vectors of rare words.
Many phrases have meanings that are not simply a composite of the meanings of the individual words. The quality of the phrase representations is evaluated using a novel analogical reasoning task involving phrases.
Other Models
- GloVe
- FastText
- LexVec
- PDC/HDC
- Spearman’s ρ
- Kendall’s τ
- Reasoning
In this way many sensible phrases can be formed without increasing the size of the vocabulary; in theory, the Skip-gram model can be trained using all n-grams, but that would be too memory intensive. To take advantage of the plurality of vector representations per words, the skipgram model must use a different scoring function to use the bag of grade decomposition. LexVec is a method for generating distributed order representations that uses low-rank, weighted factorization of the Positive Point-Wise Mutual Information (PPMI) [8] matrix via Stochastic Gradient Descent (SDG) [37] , applying a weighting scheme that assigns harsher penalties for errors on frequent co-occurrences, while still accounting for negative co-occurrence.
It produces corrections in pairs that should be in the corpus due to frequency, but are not observed, automatically taking negative co-occurrences into account. The following section presents the results of tests and benchmarks to evaluate the performance of these models. We produce a rank correlation coefficient for each of the model corpora-human judgment rating groups.
A rank correlation coefficient measures the degree of similarity between two rankings and can be used to assess the significance of the relationship between them. If there are no repeated data values, a perfect Spearman correlation of +1 or −1 occurs when each of the variables is a perfect monotonic function of the other. Intuitively, the Spearman correlation between two variables will be high when observations have a similar (or identical for a correlation of 1) rank (i.e. relative position label of the observations within the variable: 1st, 2nd, 3rd, etc.) between the two. variables and layer.
It is a measure of rank correlation: the similarity of the ranks of the data when ranked by each of the quantities. Intuitively, the Kendall correlation between two variables will be high when the observations have a similar (or identical for a correlation of 1) order (i.e. the label of the relative position of the observations within the variable: 1, 2, 3, etc.) between the two. variables, and low when the observations have a dissimilar ranking (or completely different for a correlation of -1) between the two variables.
Human Ratings
- SimLex-999
- MEN
- WordSim353
- RareWord
- MTurk
- TR9856
- RG65
This diversity enables fine-grained analyzes of the performance of models on concepts of different types, and consequently great insight into how architectures can be improved. The MEN [7] dataset consists of comparative judgments on two pairs of examples at a time, allowing seamless integration of the supervision of many annotators, each of whom may have a different internal "calibration" for the relationship strengths. The dataset has 2034 word pairs chosen in a way to reflect words with low frequency of occurrence in Wikipedia, rated with a similarity scale [0,10].
Manning (2013), the RW dataset is one of the many recent word similarity datasets that get their similarity judgments from crowdsourcing. In addition, the authors asked raters to self-certify themselves: indicate whether they “knew” the word. The MTurk dataset (MTurk-771 Test Collection) [17] contains 771 English word pairs along with human-assigned relatedness judgments.
A minimum of 20 ratings were collected for each word pair, with each judgment task consisting of a series of 50 word pairs. To discard poor quality work, each batch contained 10 pairs of trap words with known extreme relatedness values that served as binary indicators. Additionally, unlike most previous data, the new data provides context for each pair of terms, allowing the terms to be distinguished as needed.
Finally, the new data triples the size of the largest previously available data, consisting of 9,856 pairs of terms. The similarity of each pair is rated on a scale from 0 to 4 (the higher the "similarity", the higher the number).
Results
Using kernel centered alignment (CKA) as a natural generalization of squared cosine similarity for sets of word vectors [48]. In Proceedings of the 2009 Annual Conference of the North American Chapter of the Association for Computational Linguistics (HLT-NAACL-2009), pages 19–27, Boulder, Colorado, 2009. In Proceedings of Human Language Technologies: The 2009 Annual Conference of the North American Chapter of the Association for Computational Linguistics , pages 19–27, Boulder, Colorado, June 2009.
InProceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Deel 1: Long Papers), pagina's 238–247, Baltimore, Maryland, juni 2014. In Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics (Deel 1: Long Papers), pagina's 873–882, Jeju-eiland, Korea, juli 2012. InProceedings of the 14th Conference of the European Chapter of the Association for Computational Linguistics, pagina's 482–.
Proceedings of the 52nd Annual Meeting of the Society for Computational Linguistics (Volume 2: Short Papers), pages 302–. Proceedings of the 53rd Annual Meeting of Association for Computational Linguistics and the 7th Joint International Conference on Natural Processing Language (Volume 2: Short Papers), pages 419–424, Beijing, China, July 2015. - Learning the Uralic Language, page 104 -113, Sofia, Bulgaria, August 2013.
In Human Language Technologies: Annual Conference of the Association for Computational Linguistics North American Section 2010, HLT '10, pages 109-117, USA, 2010. Proceedings of the Conference on Empirical Methods in Natural Language Processing 2015, pages 298-307, Lisbon, Portugal, September 2015 .Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 136-145, Beijing, China, July 2015.
In Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics, pages 384–394, Uppsala, Sweden, July 2010.
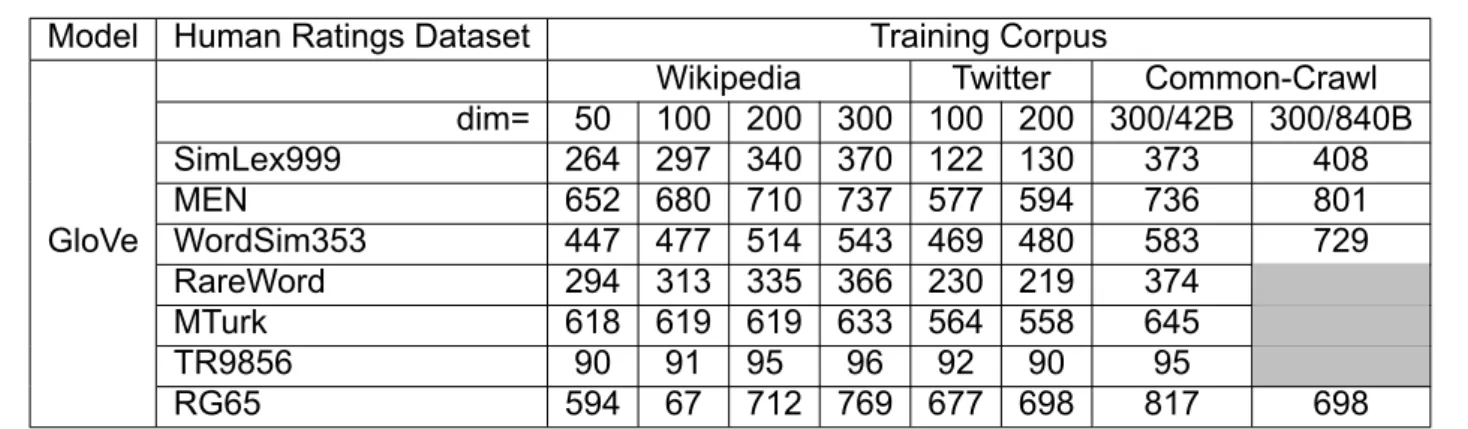
Spearman correlation (x100) of GloVe model (B:Billion Words)
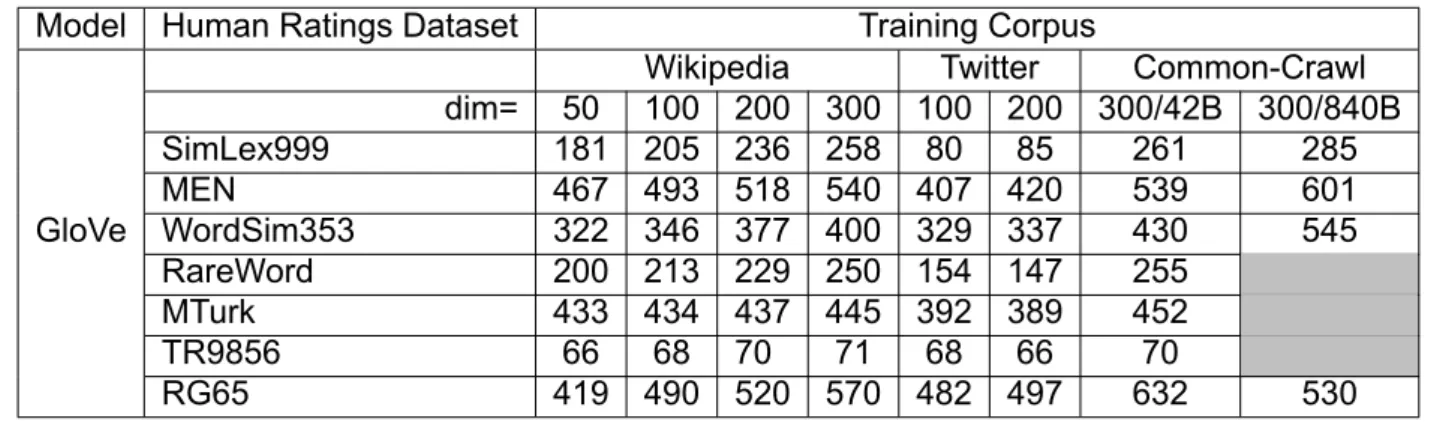
Kendall correlation (x100) of GloVe model (B:Billion Words)
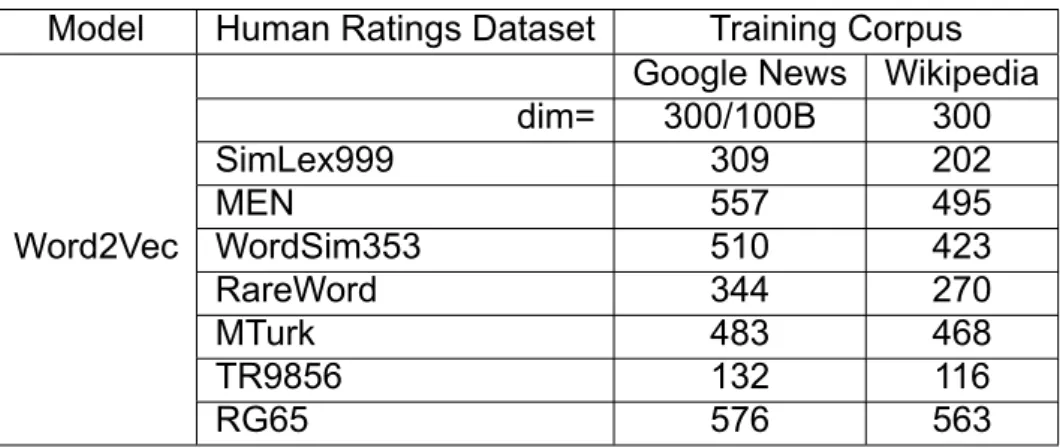
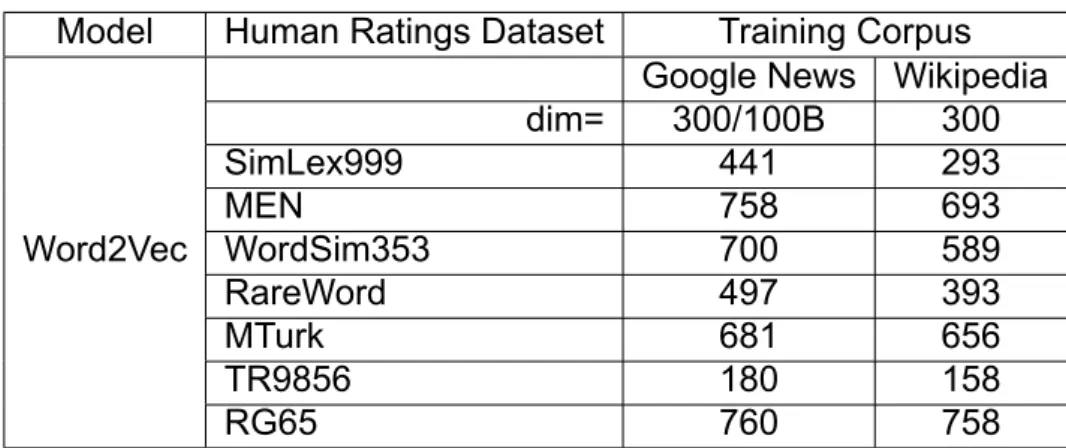
Spearman correlation (x100) of Word2Vec model
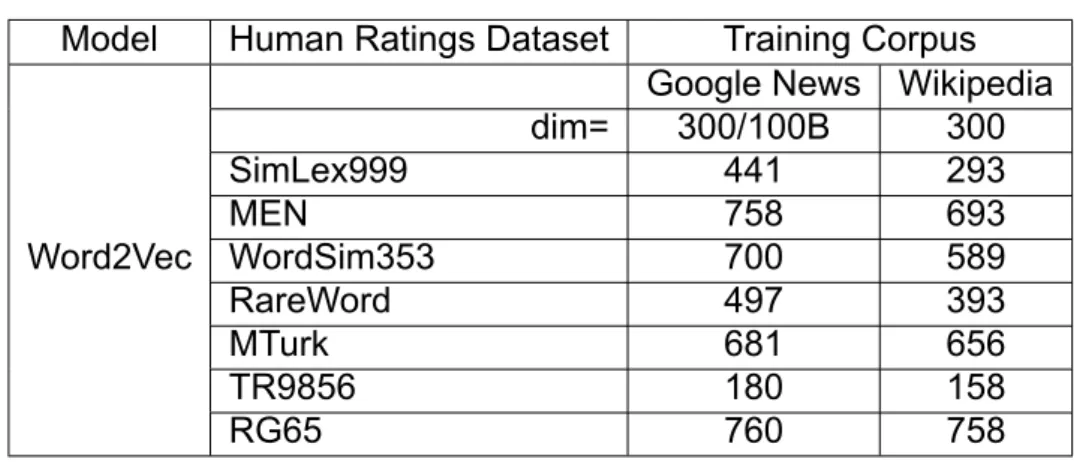
Kendall correlation (x100) of Word2Vec model
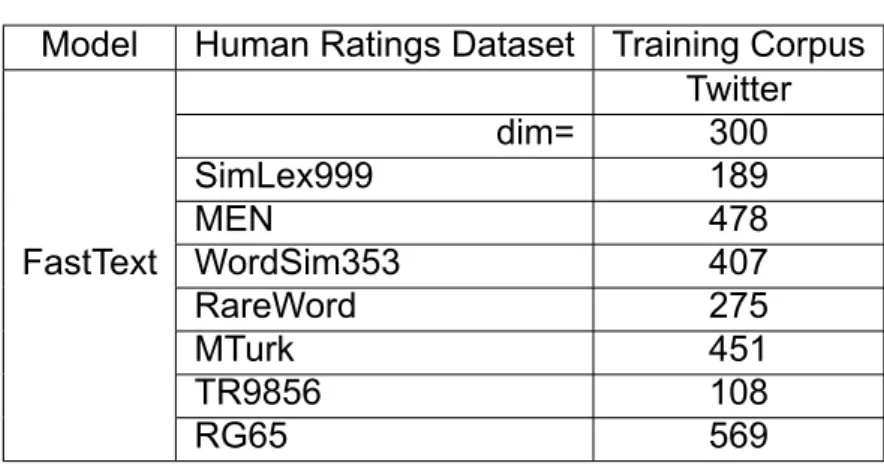
Spearman correlation (x100) of FastText model
Kendall correlation (x100) of FastText model
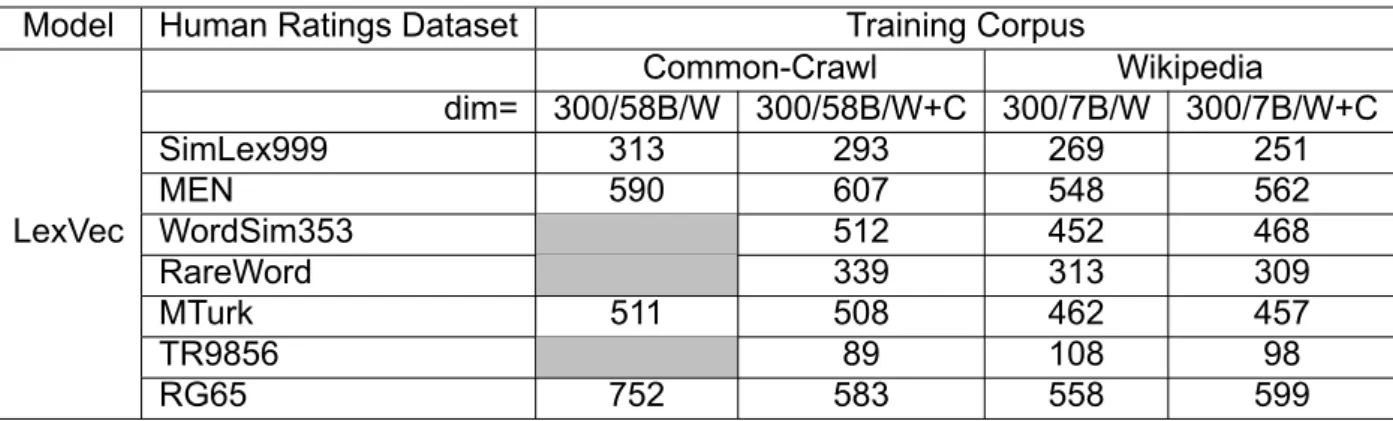
Spearman correlation (x100) of LexVec model (B:Billion Words, W:Words,
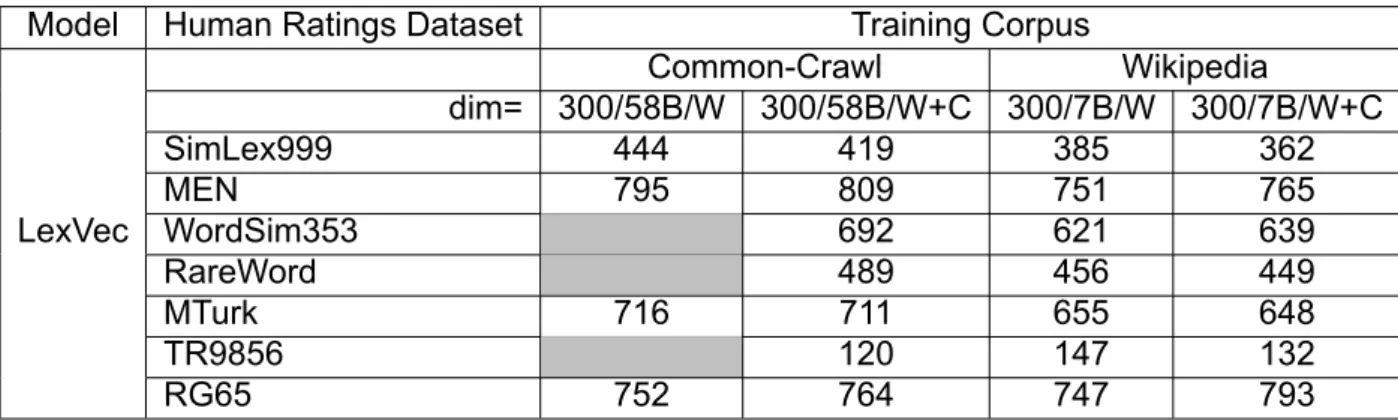
Kendall correlation (x100) of LexVec model (B:Billion Words, W:Words,
Spearman correlation (x100) of PDC model
Kendall correlation (x100) of PDC model
Spearman correlation (x100) of HDC model
Spearman correlation (x100) of HDC model
![Fig. 3.2. Neural architecture overview of Mikolov et al, 2013’ [30]s model.](https://thumb-eu.123doks.com/thumbv2/pdfplayerco/295319.40045/27.892.196.718.166.463/fig-neural-architecture-overview-mikolov-et-2013-model.webp)