This work is the result of the constant and endless love of my parents, Markos and Anastasia, and my sister Nantia. Consequently, there is a need for an interoperability model that will allow the specification of the entities of interest as well as of the related and useful semantic data.
List of Tables
Introduction
- General Objective
- Motivation and Vision
- Research Questions
- The Approach
- The Approach 5 a list of search results, we introduce a probabilistic (Random Walk-based) ranking model
- Contributions of this Dissertation
- Outline of Dissertation
We present the results of a comparative evaluation with other ranking methods that illustrate the effectiveness (and also quantify the difference) of the proposed ranking scheme. In Appendix B, the formulas of the metrics used in the evaluation of the proposed method of reranking the results are given.

Motivation and Context
- Motivating Scenarios
- Motivating Scenarios 11
- Possible Approaches
- Basic Concepts 15 is that if a user submits a query that does not belong to the index then the systemis that if a user submits a query that does not belong to the index then the system
- Basic Concepts
- The Considered Search Process
- The Considered Configuration Process 17 retrieve the incoming and outgoing properties of each entity URI.retrieve the incoming and outgoing properties of each entity URI
- The Considered Configuration Process
- The Considered Configuration Process 19
Then, for each incoming query, the entities of the top-L hits of the answer are retrieved from the index and given to the user. This functionality can also be offered on demand as a supplementary representation of the identified entities.

Background and Related Work
Semantic Web and Semantic Search
- The Semantic Web (or the Web of Data)
The principles of Linked Data were first described by Berners-Lee in 20061 and provide broad guidelines from which data publishers have begun to realize the web of data. The Web of Data can be accessed through Linked Data browsers, just as the traditional Web of Documents is accessed through HTML browsers [37].

Semantic Web and Semantic Search 23
- Semantic Search
Semantic data search includes crawling, storing and indexing semantic data, searching and arranging semantic data, searching in multi-data source and multi-repository scenarios, handling vague or incomplete semantic data, infrastructure for querying semantic data on the web , etc. Below we discuss the most important works related to both Semantic Data Search and Semantic-driven IR.
Semantic Web and Semantic Search 25 aggregated statistical metadata about the indexed Semantic Web documents and Seman-
GKG tries to understand the submitted query and presents a semantic description (in a right panel) of the entity the user might be looking for. For example (and for now), for the query "Barack Obama and Honolulu", GKG returns no semantic information, even though Honolului is the birthplace of Barack Obama, i.e. the two entities are highly related.
Semantic Web and Semantic Search 27 identified in the list of results (i.e., relationships that do not exist in the underlying knowl-
The final output of the system consists of a set of ontology elements that answer the user's question and a complementary list of semantically ordered relevant documents. In this work, the authors introduce an entity ranking algorithm, called LDRANK, which combines the biased likelihood method we present in 5.3 and a variation of the Singular Value Decomposition (SVD) algorithm that mines textual data associated with the identified entities.
Named Entity Extraction 29 3.1.3 Our Approach3.1.3Our Approach
Named Entity Extraction
- LOD-based NEE Tools of General Purpose
- Life Sciences-tailored Annotation Tools
- Our Approach
The result of entity extraction can be saved in different forms (HTML, XML, JSON or XHTML+RDFa). Configurations can be shared by users/communities, eg, for marking different document bodies using the same configuration, i.e., the same categories, entity lists, SKBs, etc.
Categorizing/Grouping Search Results 33 that accepts and uses such configurations, while the result of the annotation processthat accepts and uses such configurations, while the result of the annotation process
Categorizing/Grouping Search Results
Automatically Improving Search Results
- Automatic Query Expansion
Automatically Improving Search Results 35 query entities and their links to knowledge bases, including structured attributes and text
- Pseudo-Relevance Feedback
- Re-ranking
- Our approach
Link Analysis
Link Analysis 37 the underlying hyperlink graph. A node is created for every Web page and a directed edge
- Link Analysis Techniques
Tomlin [196] proposes a generalization that computes flow values for the edges of the web graph and aTrafficRank value for each page. The hub role captures the quality of the page as a reference to useful resources, while the authority role captures the quality of the page as a resource itself.
Link Analysis 39 ciated every page with a hub and an authority weight. Following the mutual reinforcing
When at the node on the hub side, the algorithm chooses one of the outgoing links uniformly at random and passes to an authority. The parameters of the algorithm are (a) a firing thresholdF (a real number in the interval[0,1]), and (b) a decay factorD (a real number in the interval[0,1]).
Link Analysis 41
- Applying Link Analysis on the Web of Data
- Our approach
- Comparing Link Analysis Techniques
Let A1 and A2 be two link analysis ranking algorithms, then we can define the distance between algorithms A1 and A2 on graphGasd(A1(G),A2(G)), where: Rn×Rn → R is some function that maps two real n-dimensional weight vectors sa1,a2 in a real numbered(a1,a2). Authority vectors can be viewed as points in ann-dimensional space, so we can use common geometric measures of distance (e.g. the Manhattan distance).
Link Analysis 43 by two different algorithms. The motivation is that the ordinal ranking is the usual end-
- Evaluating Link Analysis Techniques
By clicking on the query, the user is shown a combination of the top 10 results of all algorithms. This is the proportion of results in the top 10 ranking positions that are relevant to the query.
Link Analysis 45 the average is taken over the intersection over the top-1, top-2, up to top-10)
Each result was described by the human-readable label and the URI of the entity. The evaluation compared the proposed approach with two relevant baselines and the results showed that the proposed approach outperforms the baselines, and the improvement is large for the domain-specific dataset.
Link Analysis 47 problem of retrieving and ranking entities from a structured knowledge repository based
Configuring Named Entity Extraction
Notions and Notations
For an entity URIu, let Descr(u) be an array of RDF triples expressing information about u in the RDF graph. Graph(doc) =∪u∈U(doc)Descr(u)is a set of triples about these URIs that actually define the RDF graph.
The Proposed Configuration Model
For entity name, let U(e) denote URIs associated with toe that exist in one or more RDF graphs, e.g. U(Chum Salmon) = –http://dbpedia.org/resource/Chum_salmon,https://. In general, we can identify entities of different categories in a given document, each of these entities is associated with URIs, and each of these URIs with triples that describe those URIs.
The Proposed Configuration Model 51 SPARQL queries. This template query is also associated with a name that can be used for
However, a feature of this trivial disambiguation is that we already know the category of the corresponding entity and thus can design the query template accordingly (e.g., we can compare the name of the entity with the names of entities belonging to a given RDF class, as in the template queries in Figures 4.4 and 4.5). To enrich entities, KBM1 can be connected to the template query shown in Figure 4.6, which retrieves the outgoing properties of the entity URI.
The Open NEE Configuration Model
For example, we can define that the category Species is a broader concept of the categories Fish Species and Bird Species. Open NEE Configuration Model 55 is a well-known thesaurus related to the maritime domain, we can define that the category.

The Open NEE Configuration Model 55 is a well-known thesaurus related to the marine domain, we can define that the category
Exporting/Exchanging the Annotation Results
Exporting/Exchanging the Annotation Results 57 SELECT ?tool ?name WHERE {
Finally, the propertyoae:has- MatchedURI is used to represent the URIs that match an entity name.

Exporting/Exchanging the Annotation Results 59
Exporting/Exchanging the Annotation Results 61
The X-Link Framework
- Functionality
- Configurability
Regarding the connectivity of the entity URIs, X-Link calculates a graph to make more clear how the entity URIs are associated. In that example, X-Link supports 7 categories of entities (line 1), that is, the entity names of these categories are retrieved and stored in Gate ANNIE.
The X-Link Framework 65
Evaluation
- Task-based User Study
Evaluation 67
We recorded whether they succeeded in completing each task of the above scenario, as well as the time to successfully complete each task.

Evaluation 69 Q4 How easy was to specify how to enrich the identified entities?
82% of the participants found the overall setup (Q0) an "easy" task, while 18% found it "very easy". Regarding V6, a few participants mentioned a problem in understanding the idea of the SPARQL template queries (one also suggested providing a user-friendly interface for constructing them).

Evaluation 71 2 Case Study: Querying Online DBpedia
The time is highly dependent on the total number of subjects belonging to the respective category. For each resource class, we randomly selected 10 entity tags belonging to that class and measured the average time to execute the SPARQL query shown in Figure 4.26 ([URI_OF_ RES_CLASS] corresponds to the URI of the resource class, while [ENTITY] corresponds to a randomly selected tag ).

Evaluation 73
- Other Aspects
Epilogue
Stochastic Ranking of Entities, Proper- ties and Search Results
- Notions and Notations
- Entity Importance
- Ranking of Entities and Properties 79 consider that the entities detected in the title of the article are more important than thoseconsider that the entities detected in the title of the article are more important than those
- Ranking of Entities and Properties
- The Semantically-Enriched Graph of Identified Entities
- Ranking of Entities and Properties 81 blank node, node “d” (Thunnus atlanticus@en) is a literal (specifically a string in English),
- The State Transition Graph (STG)
- Analyzing the STG
- Ranking of Entities and Properties 83 where J[e i ] = Jump(e i ) and T is the transition matrix
- return r
- Promoting the Important Entities
- Top-K Semantic Graphs
- Ranking of Entities and Properties 85 struction a semantic graph does not contain blank nodes). However, some resources
Consider the following example in themarinedomain (which will be our running example for now): User submits a query to a marine-related search engine, eg, the query "bonito". Also let props(e,e') ⊆ o(e) be the set of (directed) edges connected to' inX(ie, the properties connecting the two entities).

5.4 (Re-)Ranking of Search Results
Modeling a Random Walker
We also report experimental results regarding the distribution of vertices in these clusters for several top-K semantic graphs produced by a prototype system. In the latter case, the user can now either i) open one or more of the displayed results, or ii) click on some other entities and update the displayed list of results accordingly, or iii) delete his selection (reset) and view the results again .
The Semantic Graph of Documents and Entities
The STG
We notice that the transition probabilities are influenced by the “importance” of the identified entities. For simplicity and understandability, the graph contains only the outgoing edges of the gray entity nodes.

Analyzing the STG
First, we need to determine the value for the decay factor, i.e. for the probability that a random walker will make a random jump. As for p3, ie. the probability of selecting a document node or a related entity/property node from an entity node, we believe that when a walker is in an entity node, it is more likely to move to a document node (that is, contains/refers to that entity) as the destination end user to find one or more documents that satisfy his information needs.
Exploiting the Outcome
Since we want to prioritize documents related to important (highly rated) entities, we can define a small value, e.g. d< 0.4. In the event that we want to enable the selection of only the nodes of the document, we can define p3= 1.0.
Evaluation
When searching the web, PageRank is usually initialized with the same value for all web pages. Evaluation 93LOD enriched ranking approach with the simple NER method, and we present the evaluation.
Evaluation 93 LOD-enriched ranking approach with the plain NER method, and we present the evalu-
- Usefulness of Top-K Semantic Graphs
The participant can choose one of the following options: Yes, Maybe Yes - it depends on the interaction model and the quality of the visualization of the graph, Maybe No, No. For example, a query like astuna species looks for instances of a class of entities, while a query like yellowfin tuna looks for information for one specific entity, in this case a certain tuna species.

Evaluation 95
- Effectiveness of Entity and Property Ranking
We also notice that for the last query (of other type of query) which is a fairly common query, a high percentage of participants (26%) chose MAYBE NO or NO. Regarding Q1, the results depicted in the respective column of Table 5.1 show that we can reject the null hypothesis for the first four queries with a Type-I statistical error of 5%, while we cannot reject it for the last one not, i.e. the queryfishing in Hawaii of type.
Evaluation 97 the semantic information (entities and properties) that better characterizes these results
Fish species related to the detected species, but not detected in the search results - Properties (literal and numeric values) related to the detected species. These types of entities correspond to the five clusters described in 5.3.5 (Vans,Vrel,Vlit, Vctg,Vweb).

Evaluation 99
We note that the higher score is for the literal features (Vlit) that correspond to the features of the detected entities. He justifies this by the fact that most of the submitted queries are entity queries, the purpose of which is to find information about a specific entity.
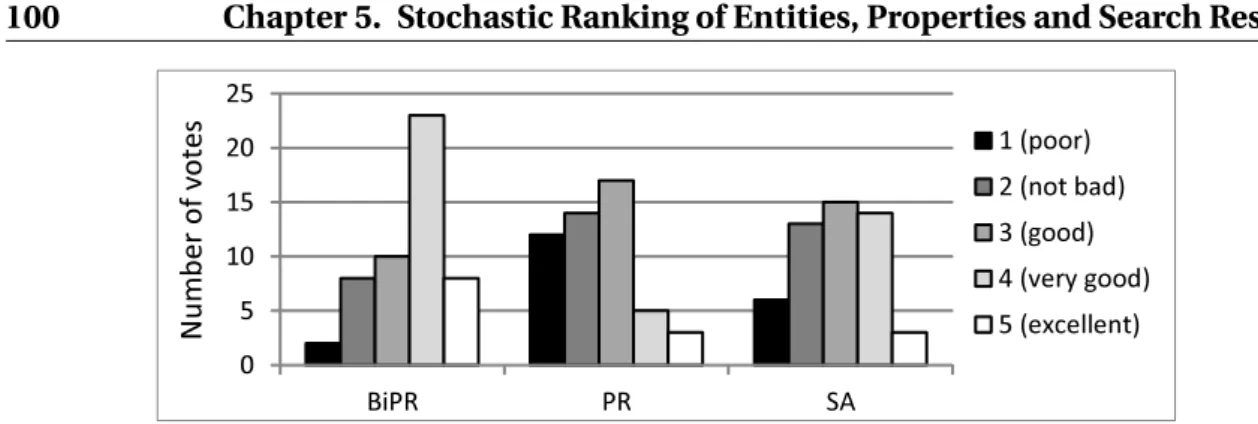
Evaluation 101
Regarding the difference in the top elements, we compared the algorithms using the Jaccard similarity coefficient. As for the difference in the order of the elements, we compared the algorithms using the normalized Kendall tau distance measure as described in 3.5.4.

Evaluation 103
- Effectiveness of Results (Re-)Ranking
A topic is actually a medical case narrative that serves as an idealized representation of an actual medical record and describes information such as the patient's medical history, the patient's current symptoms, the tests performed by a doctor to diagnose the patient's condition , the eventual diagnosis of the patient as. as well as the steps taken by a doctor to treat the patient. For each topic offered, an effective IR system should find documents that can help the physician answer a common general clinical question, such as what is the patient's diagnosis or what tests should the patient receive based on the medical report.
Evaluation 105
The results showed that the improvement is statistically significant for most cases (it fails the test when the improvement is small, less than 14%). ForL = 250andd = 0.0 the results are statistically significant only for the metrics nDCG'andP@10', while ford=0.2 the results are statistically significant for all metrics except Q'.
Evaluation 107
- Efficiency of the Entire Semantic Analysis Process
This means that the specific semantic information about the identified entities (DBpediasubjectproperty), although it may be quite useful in another context (e.g. for entity-based faceted search), misleads the random wanderer and negatively affects the reordering of the retrieved results. The time to perform entity mining in a set of search results depends on many parameters, such as the number of results we want to analyze, the size of the text in each result/document, the efficiency of the underlying NER algorithm, etc. .
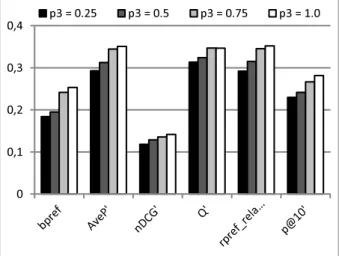
Evaluation 109
The time to generate a SEGIE depends on the number of entities detected, the performance of the underlying SKBs, and the categories of entities detected (as some entity categories may contain many input or output properties). The time to generate STG depends on the number of triples in SEGIE, while the time to run PageRank depends on the number of iterations and on the number of edges in STG.

Evaluation 111 5 Other Aspects
On average, the top-5 entities have a Kendall rope distance of 0.08, which means that there are often (but not always) a few entities in the top-5 list with different orders in the two approaches. Top-10 units have Kendall rope distance of 0.10 (meaning there are about 4-5 pairs of units in the top-10 list with different orders), while top-15 and top-20 units have Kendall- rope distance around 0.20.
Epilogue
In the same experiments, we also compared the linear order of top-5, top-10, top-15 and top-20 entities (not all entities returned as before), ignoring entities that do not exist in the corresponding top-20 . K entities of both approaches, in order to clarify the positions in which there are differences in the linear order. The authors benchmarked (using a crowdsourced dataset): . i) the biased PageRank algorithm we propose in this thesis (they call it HIT), ii) a modified biased PageRank algorithm with prior knowledge based on SVD (called SVD), iii) an unmodified PageRank algorithm which applies equal probability distribution (called EQUI ), and iv)LDRANKi which combines the three previous approaches using a consensus algorithm of opinion group [50].
Epilogue 113
Experimental results on the 2014 and 2015 datasets of the TREC Clinical Decision Support track showed that the proposed reranking approach can improve the list of results returned by a classic IR system, specifically by moving relevant but low-ranked hits to higher positions. move. The results of the experimental evaluation carried out showed that for up to 100 detected entities (which is the case for snippet mining) we can provide the proposed functionality in real time (in less than 4 seconds), even if we have access to an online SKB such as DBpedia.
Interaction Model and Applications
- Faceted Search and Graph Exploitation
- Faceted Search and Graph Exploitation 117 6.3) allowing thereby to control the amount of information that she/he wants to display
- On-Demand Entity Enrichment and Exploration 119
- On-Demand Entity Enrichment and Exploration
- On-Demand Entity Enrichment and Exploration 121 SELECT ?name ?uri ?genus WHERE {
- Assembling the Pieces: The Search System “X-Search”
- Assembling the Pieces: The Search System “X-Search” 123
- Assembling the Pieces: The Search System “X-Search” 125
- X-Search for Patent Search
- Theophrastus: Entity-based Automatic Annotation of Web Documents 127
- Theophrastus: Entity-based Automatic Annotation of Web Doc- uments
- Theophrastus: Entity-based Automatic Annotation of Web Documents 129
- Link
- Weaknesses and Limitations 131
- Weaknesses and Limitations
For example, in Figure 6.15, the user requested to view the properties of the DBpedia resource associated with the "pink salmon" entity. The user can also review identified entities and metadata (grouped into categories) (D) and search space aggregation (E).

Conclusion
- Synopsis of Contributions
- Directions for Future Work and Research 135 We should stress that, due to the lack of standards related to entity extraction, it wouldWe should stress that, due to the lack of standards related to entity extraction, it would
- Directions for Future Work and Research
- Directions for Future Work and Research 137 needed. It is also very interesting to compare the proposed approach with other methods
- Directions for Future Work and Research 139 Interacting with Top-K Semantic Graphs
Another interesting aspect regarding the proposed rearrangement method is the study of the extreme cases. Another related interesting direction is to study approaches on how to automatically (on request) select the NEE services to be used from a list of available descriptions (expressed using the proposed Open NEE configuration model), for example based on the information submitted. query or the context of the retrieved results.
Bibliography
ACM, 2005
Proceedings of the 8th Joint ACM/IEEE-CS Conference on Digital Libraries, JCDL ’08, pages 52–56. Proceedings of the 31st annual ACM SIGIR international conference on Research and development in information retrieval, pages 603–610.
Appendix A
Configuration Forms of X-Link Evalua- tion Prototype
Appendix B
Evaluation Metrics for Incomplete Rel- evance Judgements
Note that r′−numrel(r′) is the number of judged irrelevant documents ranked above the document at rank′. This metric favors aggregated lists that contain many judged relevant documents over judged irrelevant documents at the top of the sorted list.
Appendix C
Publications, Systems and Models
Publications
In (1), we began leveraging LOD to enrich keyword-based web search with entity mining performed at query time. In (4), we elaborate on the configurability of a NEE system and we present the X-Link framework.
Systems and Models
Appendix D
Acronyms