The results of the above experiments show a significant improvement in the accuracy of the proposed method compared to the previous state-of-the-art. Finally, we discuss the limitations of the dominant approach to domain adversarial training, based on the relevant learning theory from different domains and our experimental observations.
Εισαγωγή
Σχετική βιβλιογραφία
Ορισμός Προβλήματος
Προτεινόμενη μέθοδος
Πειράματα
Σύνολο Δεδομένων
Λεπτομέρειες υλοποίησης
Συγκρινόμενες Μέθοδοι
Αποτελέσματα και Συζήτηση
Σύγκριση με το state-of-the-art
Αποτελεσματικότητα ως προς τον αριθμό δειγμάτων
Validation
Οπτικοποίηση χαρακτηριστικών
Σχετικά με τους περιορισμούς του Domain Adversarial Training
Θεωρία Μάθησης από διαφορετικά πεδία
A-distance
Αστάθεια του Domain Adversarial Training
Συμπεράσματα και Μελλοντικές Προεκτάσεις
You can gain an intuition about the structure of an LSTM by considering the following stages. In practice, we monitor the performance of the model on the validation set in each epoch.
Introduction
Motivation
Deep architectures have achieved state-of-the-art results in various machine learning tasks. As for the areas that are important, and given the wide variety of areas represented by human language, the need arises to collect and organize data for each area of interest.
Research Objectives & Contribution
The key idea of our method is that by simultaneously reducing the task-specific loss on the source data and the language modeling loss on the target data during fine-tuning, the model will be able to adapt to the language of the target domain while learning. controlled task from the available labeled data. During fine-tuning, while learning the task from the labeled source data, we maintain the MLM target on the target domain data in a multitasking manner.
Thesis Outline
The main contributions are: (a) We propose a novel, simple and robust unsupervised domain adaptation procedure for downstream BERT models based on multitask learning, (b) we achieve state-of-the-art results for the Amazon reviews benchmark dataset, which outperforms more complicated approaches and (c) we conduct a discussion on the limitations of adversarial domain adaptation, based on theoretical concepts and our empirical observations. Finally, an important part of that work concerns the domain-adversarial training based on the provided theory for multi-domain learning [12, 11] and the relationship of the theory to our empirical results on the task under study.
Machine Learning
Defining Machine Learning
In: Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). In: Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers).
Machine Learning approaches
Perceptron, Activations and Feedforward Networks
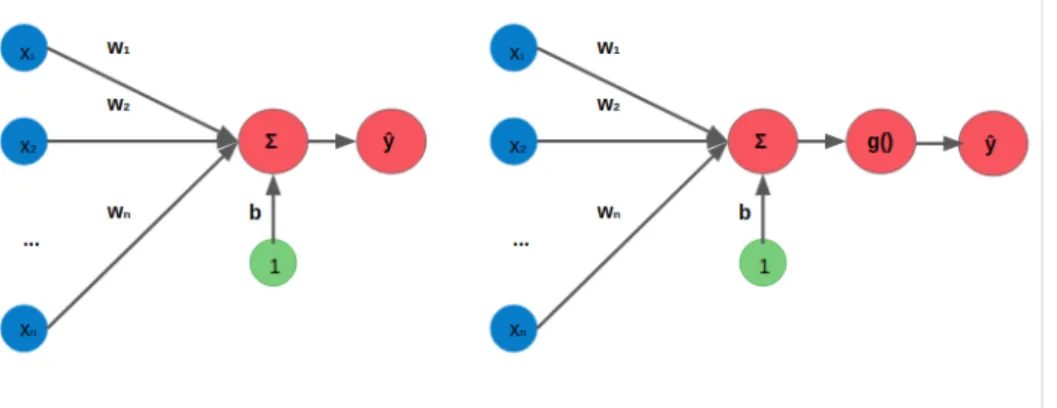
- Perceptron
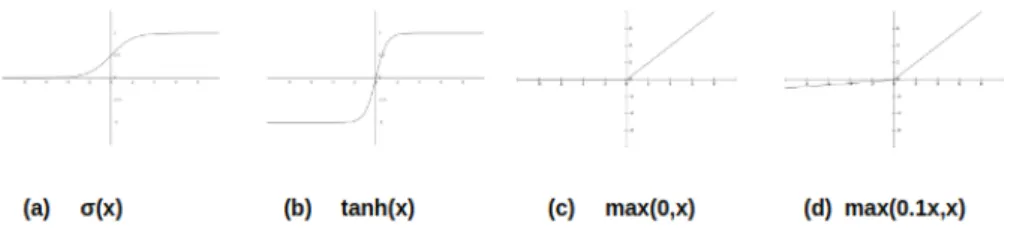
- Activation Functions
- Feedforward Networks
A sigmoid function is a bounded real function, differentiable, defined for all real values of the input and having a non-negative derivative at each point. The sigmoid function is convex for values less than 0 and concave for values greater than 0.
Training
- Quantify Loss
- Gradient Descent
Backpropagation To use the gradient descent algorithm to address the loss optimization problem of deep neural networks, it is essential to calculate the gradient of the loss function with respect to the network weights. To address the issue, stochastic gradient descent was introduced, which proposes to select at each iteration a single data point, and update the parameters using the loss gradient of that particular data, ∂J∂wi(w).
Recurrent Neural Networks
- Vanilla RNNs
- Exploding and Vanishing Gradient Problems
- Gated Recurrent Units (GRU)
- Long-Short-Term Memories (LSTM)
- Bidirectional RNNs
- Attention Mechanisms
At each time step there are two inputs to the hidden layer: the output from the previous time step-1 and the input at the current time step xt. Whh∈IRdh×dh: weight matrix used to condition the output of the previous time step-1.
![Figure 2.4: A RNN unit as loop over time steps and unfolded over time. Figure from [64].](https://thumb-eu.123doks.com/thumbv2/pdfplayerco/333570.53556/44.892.247.634.347.456/figure-rnn-unit-loop-time-steps-unfolded-figure.webp)
Transformers
Some vectors must be introduced which will give the system a sense of order in the input sequence. The first encoder takes positional information and inputs of the input sequence as its input, instead of encodings.
Evaluation of Performance
Unfortunately, we chose the hypothesis in such a way that the test set information leaked out and became known to the learning algorithm. The solution is to use a new set of tests to evaluate the performance of the selected hypothesis.
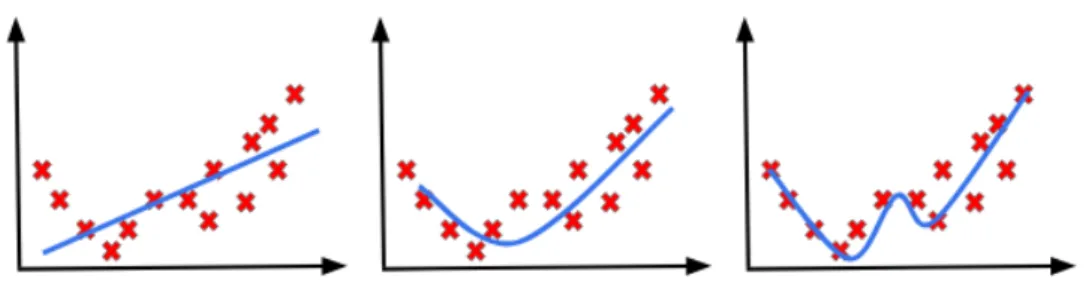
Overfitting and Regularization
- Overfitting and Underfitting
- Regularization
Up to a point, it also improves the model performance on data outside the training set. Validation set is part of the original training set, which is kept out of the training process every time.
Transfer Learning
The proposed method provides state-of-the-art results on 12 customization settings on the multi-domain dataset of Amazon reviews. In: Proceedings of the Eighth International Joint Conference on Natural Language Processing (Part 2: Short Papers).
![Figure 3.1: Word2Vec training modes. Figure from [61]](https://thumb-eu.123doks.com/thumbv2/pdfplayerco/333570.53556/60.892.127.748.415.769/figure-3-word2vec-training-modes-figure-from-61.webp)
Natural Language Processing
Introduction
NLP Tasks
- Common Tasks
- Sentiment analysis
Marking the part of speech Depending on the sentence, determine the part of speech (POS) for each word. Natural language generation Convert information from computer databases or semantic purposes into human-readable language.
Word vectors-Embeddings
- Denotional approach
- Vocabulary indices
- One-hot vectors
- Distributional hypothesis
- Word2Vec
- GloVe
- Contextual Word Embeddings
The first and most naive, denotational method is to use the indices corresponding to the word in the dictionary. Therefore, a one-hot word vector is a1× |V|vector used to distinguish each word in the vocabulary from each other.
Language Modeling
- n-gram Language Models
- Neural Language Models
- Perplexity
Training is performed on aggregated global word-word co-occurrence statistics from a corpus, and the resulting representations exhibit interesting linear substructures of the word vector space. The training goal of GloVe is to learn word vectors such that their dot product is equal to the logarithm of the words' probability of co-occurrence.
ELMo
P perplexity= 2−12∑ni=1log2LM(wi|w1:i−1) (3.8) Good language models that actually reflect real language use will assign high probabilities to the events in the corpus, resulting in lower perplexity values. Confusion is corpus-specific, so the confusions in two language models are only comparable with respect to the same evaluation corpus.
BERT
Domain Adversarial Neural Networks is one of the most widely used domain adaptation approaches in NLP. The goal of the proposed method is to learn a task (i.e. emotion classification) from available labeled data on the source domain, while adapting to the language of the target domain.
![Figure 3.4: BERT applied in various tasks. From [24]](https://thumb-eu.123doks.com/thumbv2/pdfplayerco/333570.53556/65.892.263.654.492.876/figure-3-4-bert-applied-various-tasks-24.webp)
Unsupervised Domain Adaptation in NLP
Introduction
Domain adaptation is an area of machine learning, a specific sub-case of transfer learning, which arises when we aim to learn a well-performing model from a source data distribution on a different, but related, target data distribution. Domain adaptation is the ability to apply an algorithm trained in one or more source domains to a different but related target domain.
NLP Tasks for Unsupervised Domain Adaptation
Notation – Problem Setting
Categories
Model-based approaches
- Pivot-based approaches
During training, labeled source data and unlabeled data from both fields are fed into the model alternately. Both networks are trained together in an adversarial domain fashion, as in DANN, which will be introduced in the next section.
Loss-based approaches
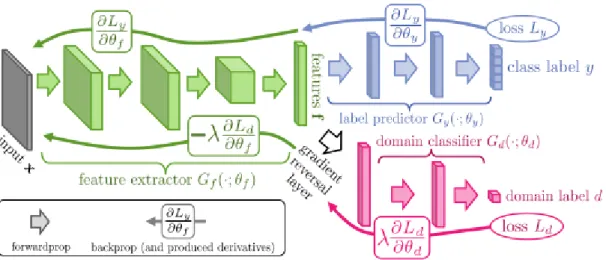
- Domain Adversarial Training
- Reweighting
27] bring domain adversarial training into the context of BERT models, propose a novel domain separation task that predicts during pre-training whether two sentences originate from the same target domain or from different domains. In addition, the proposed BERT-based model is trained under fine-tuning together with a domain adversarial loss via a GRL unit, as originally proposed by Ganin et al.
Data-based approaches
- Pseudo-labeling
- Pretrained Language Models
In order to achieve the desired diversity, an orthogonality constraint is introduced as an additional loss term, as suggested by Bousmalis et al [17]. Taking the pre-trained model and using it without any adjustment on the unseen data can be considered an extreme case, which is equivalent to zero-shot learning.
Introduction
Our key contributions are: (a) We propose a new, simple and robust unsupervised domain matching procedure for downstream BERT models based on multitask learning, (b) we achieve state-of-the-art results for the Amazon reviews benchmark dataset. , which outperforms more complicated approaches and (c) we discuss the limitations of adversarial domain adaptation, based on theoretical concepts and our empirical observations.
Related Work
We propose a new, simple and robust unsupervised domain matching procedure for downstream BERT models based on multitask learning, (b) we achieve state-of-the-art results for the Amazon reviews benchmark dataset, outperforming more complicated approaches and (c) we perform ' a discussion on the limitations of adversarial domain adaptation, based on theoretical concepts and our empirical observations. We refine the model using both a classification loss on the labeled source data and MLM loss on the unlabeled target data.
Problem Definition
Proposed Method
During this procedure, the model learns the task by the classification objective using the labeled source domain samples, and at the same time adapts to the target domain data by the MLM objective. The model is trained on the source domain labeled data for the classification task and target domain unlabeled data for the masked language modeling task.
Experiments
- Dataset
- Implementation Details
- Baselines - Compared methods
For the final refinement step, shown in , we perform supervised refinement on the source data while keeping the MLM objective on the target data as an auxiliary task. We train the model over mixed batches that include both source and target data used for the respected tasks.
Results and Discussion
- Comparison to state-of-the-art
- Sample efficiency
- On the stopping criteria for UDA training
- Visualization of features
We observe that BERT refined only with the source domain labeled data, without any knowledge of the target domain, is a competitive baseline. We further investigate the impact of using different amount of target domain unlabeled data on model performance, to study the sampling efficiency of the proposed method.
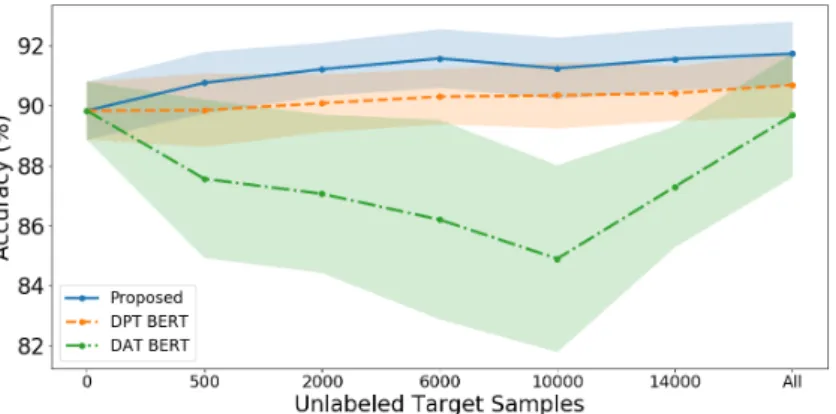
On the limitations of Domain Adversarial Training
- Background Theory
- A-distance only provides an upper bound for target error
- Instability of Domain Adversarial Training
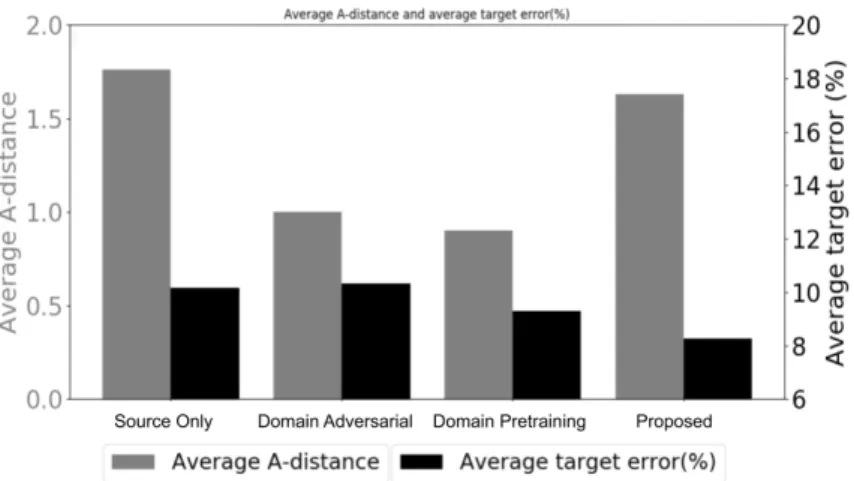
DPT BERT also reduces the A-distance to similar levels as the domain adversarial model without intending to. The extended-domain pretrained BERT also reduces the A-distance to similar levels as the adversarial domain model without aiming to achieve this.
Conclusions and Future Work
In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). In: Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers).
Conclusions & Future Work
Conclusions
We conclude this work by conducting a discussion on the dominant Domain Adversarial training approach. We see no correlation between the resulting A-distance, which reduces adversarial training in the domain, and model performance on target domain.
Future Work
In: Proceedings of the 2018 Conference of the North American Chapter of the Society for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers). In: Proceedings of the 2nd Workshop on Deep Learning Approaches for Low-Resource NLP (DeepLo 2019).
Μέση ακρίβεια των μεθόδων ανάλογα με τον αριθμό δειγμάτων από το πεδίο στόχο. 27
Σύγκριση του μέσου A-distance και του μέσου σφάλματος για διάφορες μεθόδους
Left: a simple perceptron unit. Right: a percpetron unit with an addition of an activa-
Activation functions. (a) The sigmoid function. (b) The tanh function. (c) The ReLU
A neural network and a deep neural network, with more than 3 hidden layers. Both
A RNN unit as loop over time steps and unfolded over time. Figure from [64]
The detailed internal of a GRU. Figure from [57]
The internal of an LSTM. Figure from [64]
A bi-directional RNN. Figure from [64]
The Transformer architecture. From [92]
Left: Scaled Dot-Product Attention. Right: Multi-Head Attention consists of several
From left to right: Underfitting, the model does not have capacity to fully learn the
The effect of dropout during training
Training and validation error over time. Early stopping prevents the increase of gen-
Word2Vec training modes. Figure from [61]
The first deep neural network architecture model presented in [13]
Pre-training and fine-tuning procedures for BERT. From [24]
BERT applied in various tasks. From [24]
Distinction between usual machine learning setting and transfer learning, and posi-
DANN architecture includes a deep feature extractor(green), a deep label predictor