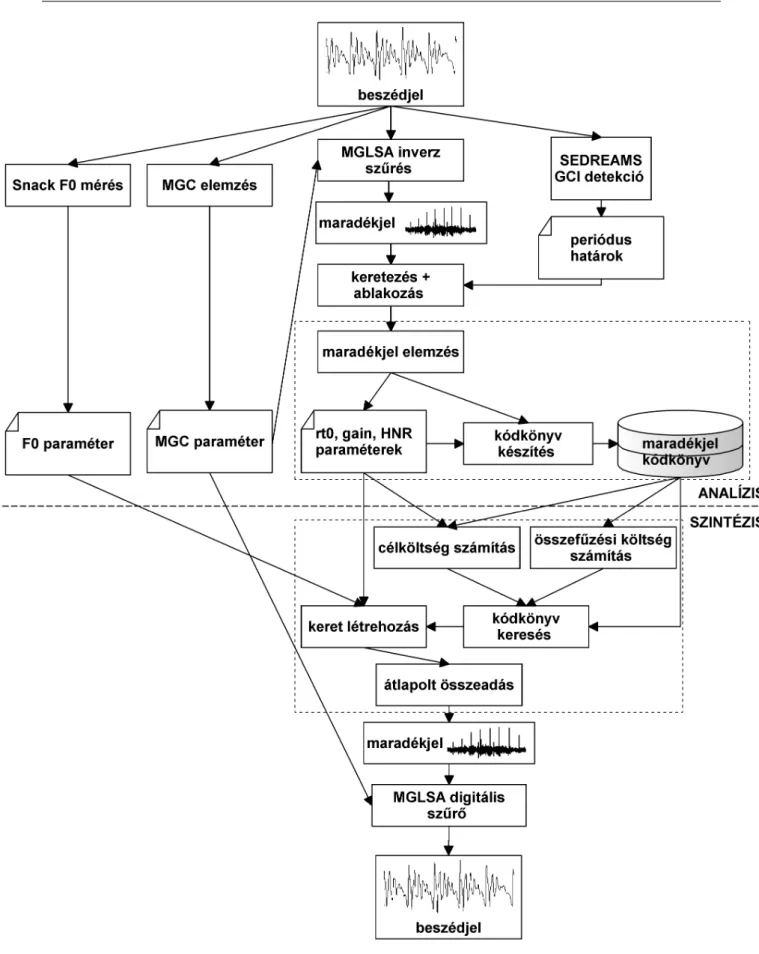
A szabálytalan fonáció egészséges és kóros beszélőben egyaránt előfordul, általában szegmenshatárokon (pl. mondat végén) vagy magánhangzó-magánhangzó kapcsolatban. A szabálytalan fonáció megfelelő modellezése hozzájárulhat természetes, kifejező és személyre szabott beszédszintetizáló rendszerek létrehozásához. A DSM-modellt továbbfejlesztve Drugman és munkatársai elemzési-szintézises kísérletekkel bizonyítják, hogy a reziduális jelperiódusokban fellépő másodlagos impulzusok jelenléte megfelelően modellezi a szabálytalan beszédet [22].
Ezután megvizsgálják, hogy a HTS rendszer mely környezeti címkéi lehetnek hasznosak a glottalizáció előfordulásának előrejelzésében, és új paraméterfolyamokat adnak hozzá a rendszerhez, amelyek elősegítik az irreguláris hang helyére vonatkozó automatikus döntést [23]. A PPBA adatbázisból kiválasztott 5 magyar anyanyelvű beszélőn végeztem beszédelemzési, szintézis és szabálytalan magánhangzóképzési kísérleteket (I. és II. téziscsoport) [27]. A további tézispontokban a modell alkalmazását ismertetem a természetes beszéd észlelt érdességének csökkentésére szabálytalan hangokkal.
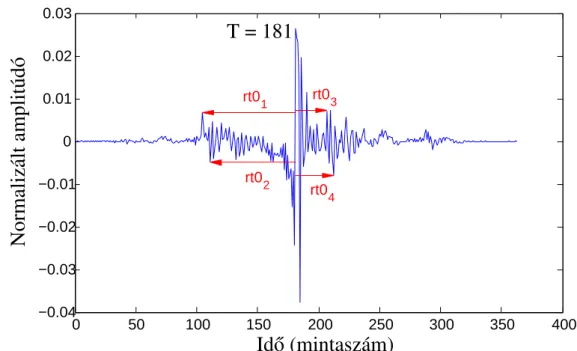
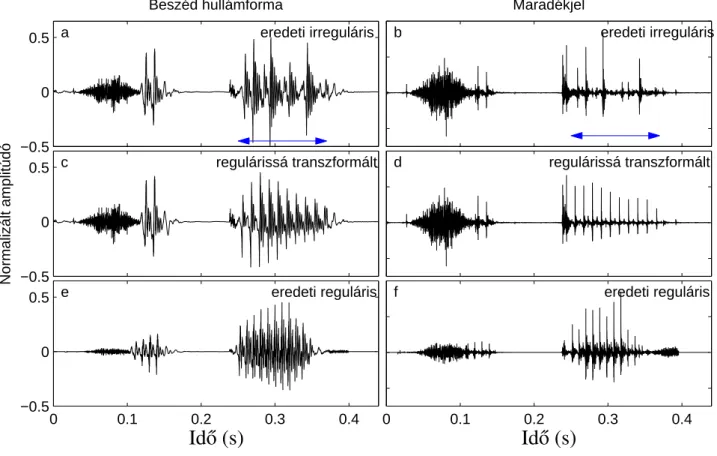
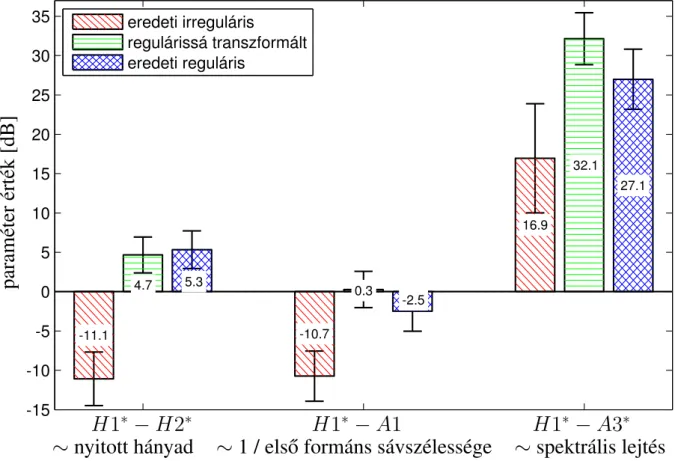
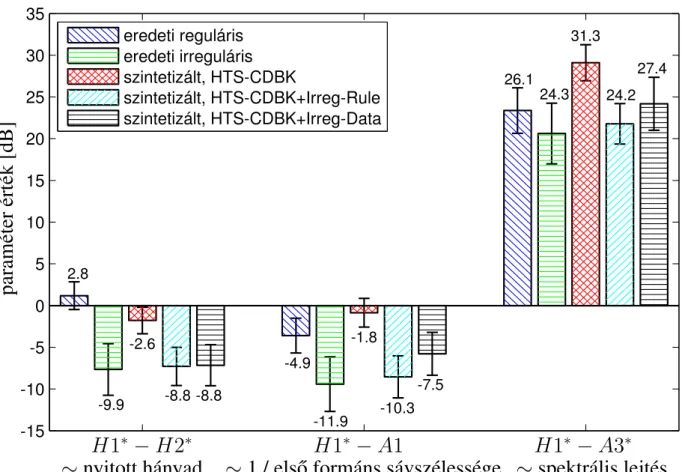
A szabálytalan fonáció kis perturbációkat okoz a képkockánkénti erősítésben és az M GC értékekben a szabálytalan hangperiódusok amplitúdójának hirtelen változása miatt. Az irreguláris-reguláris transzformáció működését a PPBA adatbázis négy interjúalanyának hanganyagán teszteltük (3 férfi: FF1, FF3 és FF4, valamint egy nő: NO3) [27]. A szabálytalan hanggal képzett H1∗−A1 és H1∗−A3∗ szavak közötti különbségek is szignifikánsan eltérnek a szabályos eredetihez képest és szabályos változatokká alakítva (p < 0,0005 és p < 0,05 ), de a szabályos eredetiben és transzformáltban. verziók majdnem azonosak (p = 0,336 és p = 0,321, n.s. különbség).
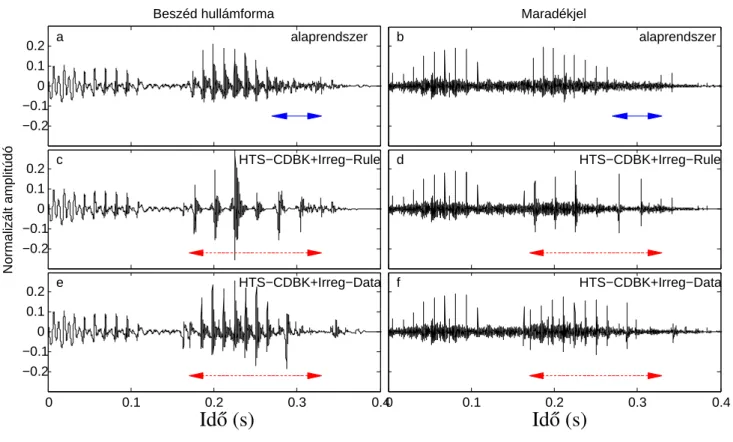
A statisztikai elemzés szerint a HTS-CDBK rendszert szignifikánsan (p < 0,0005) jobb minőségűnek ítélték meg a HTS-PN rendszerhez képest. A gépi tanulás is megtanulja ezt a mintát, és a szabálytalan fonációt a HTS-CDBK rendszer ugyanúgy modellezi, mint a zöngétlen beszédet. A következőkben a II.1. a dolgozatban ismertetett HTS-CDBK rendszert használjuk alaprendszerként és egészítjük ki szabálytalan hangmodellekkel.
Ha az F0 érték legalább 5 egymást követő magánhangzókeretben nulla, akkor a rendszer az adott magánhangzóra alkalmazza a szabálytalan zöngésmintát. Korábbi kutatásaink során azt tapasztaltuk, hogy a szabálytalan szakaszokban mért GC paraméter áramlása kevésbé egyenletes a szabályos beszédhez képest (I.2 tézis, [C1]). A PPBA adatbázisból két férfi beszélő (FF3 és FF4) hangja alapján az alap HTS-CDBK rendszerrel és a kiterjesztett HTS-CDBK+Irreg-Rule rendszerekkel fejlesztettük ki a képzést.
Létrehoztunk egy másik adatvezérelt modellt is a szabálytalan hang szintézisbe illesztésére, amely a maradék jelelemek kiválasztásán alapul. A HTS-CDBK rendszerhez hasonlóan nincs külön előrejelzési eljárás a glottalizáció helyére, hanem a generált F0 paraméterfolyamból kerül meghatározásra. A szabálytalan maradványjel energiáját az erősítési paraméterek átlaga alapján skálázzuk, de a jel egyéb tulajdonságai nem módosulnak.
A HTS-CDBK+Irreg-Rule modellhez hasonlóan spektrális torzítást alkalmaznak és szintetizált beszédet állítanak elő a reziduális jel összekapcsolt modális és irreguláris szakaszaiból MGLSA szűréssel az M GC paraméterek felhasználásával.
![1. ábra. A HTS rendszerben lév˝o alap impulzus-zaj gerjesztés. Forrás: [8] alapján, módosítva.](https://thumb-eu.123doks.com/thumbv2/9dokorg/2498079.294427/4.892.98.792.509.763/ábra-hts-rendszerben-impulzus-gerjesztés-forrás-alapján-módosítva.webp)
Az eredmények alkalmazhatósága
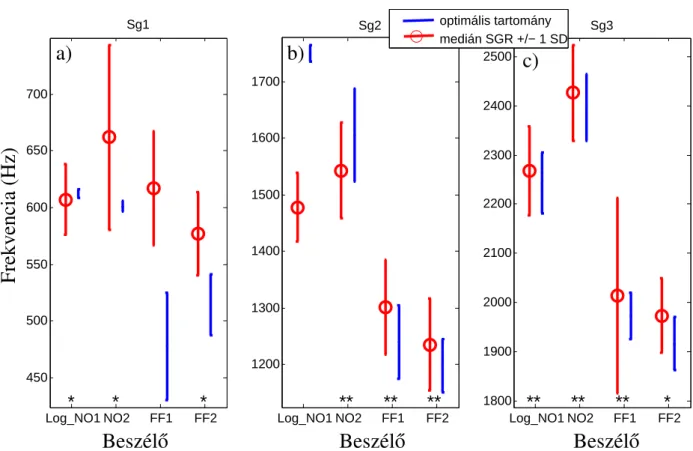
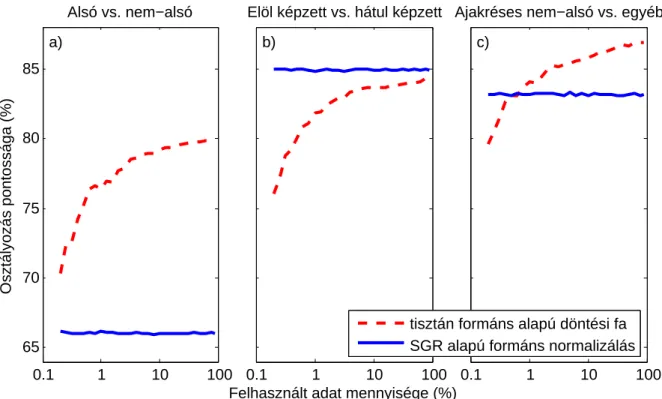
A tisztán formáns alapú döntési fa és az SGR-normalizált formáns alapú automatikus osztályozók pontosságának összehasonlítása a betanításhoz felhasznált adatmennyiség függvényében: a)Sg1, b)Sg2, c)Sg3. A fentiek során a beszédhang formánsok és a szubglottális rezonanciák kapcsolatát vizsgáltuk a beszédprodukcióban és a magyar nyelvű automatikus osztályozás során. Elemzések és kísérletek szerint a magyar szubglottális rezonanciák a magánhangzók megkülönböztető fonológiai sajátosságok szerinti elkülönítését is segítik, ezzel is hozzájárulva a szubglottális rezonanciákra vonatkozó kvantitatív elmélet [25] kiegészítéséhez [7].
A szabálytalanról regulárisra konvertáló folyamat automatikus változatával lehetőség nyílna a szabálytalan magánhangzós szakaszok beszédadatbázisokból történő eltávolítására, így ideálisabbá téve a beszédet a további feldolgozáshoz. A szűkös erőforrások miatt a bonyolultabb gerjesztési modellek nehezen kezelhetők, de a tézismodell várhatóan képes lesz valós időben futni bizonyos erőforrás-korlátos eszközökön. A természetesség és testreszabás alatt azt értem itt, hogy a szintetizált beszédben olyan szabálytalan hangot hozhatunk létre, amely megfelel az eredeti beszédadatbázisban előforduló glottalizált példányoknak.
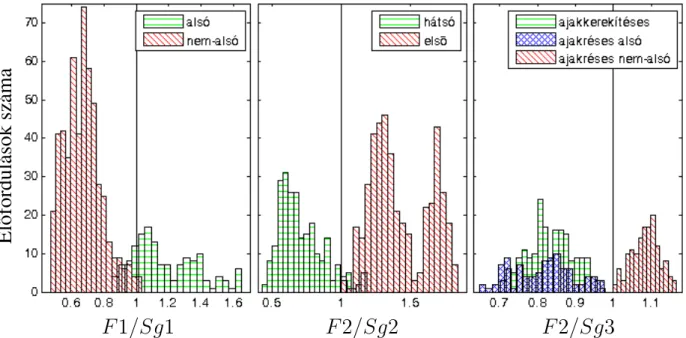
Korábban kimutatták, hogy a beszélők bizonyos érzelmeket (pl. szomorúak és bosszús) is jeleznek hangminőségük módosításával; így az irreguláris hangmodell javíthatja az érzelmi, kifejező beszédszintézist. A feltételezések szerint az észlelés során a beszédhangok formánsait részben összehasonlítják (normalizálják) a szubglottális rezonanciákkal, így megkönnyítve egymás beszédének megértését, hiszen az egyes egyedek akusztikus kimenetében nagy különbségek vannak. Egy előzetes észlelési teszt során megfigyeltük, hogy a formáns és szubglottális rezonanciák aránya összefüggésbe hozható az észlelt magánhangzó minőségével [J4].
A kísérlet eredményei szerint várható, hogy a nem megfelelő F2−Sg2 arány (vagyis ha az arány nem a III.1. tézis modellje szerint) perceptuálisan kedvezőtlen a természetes beszéd során, és megnehezíti a beszéd megértését. beszéd. Ennek alapján létrehozható egy olyan folyamat, amely a formáns-szubglottális rezonancia alapján eltávolítja a nem megfelelő beszédrészleteket a beszédszintetizátor adatbázisából és ezzel hozzájárul a szintetizált beszéd nagyobb érthetőségéhez. Ha a rejtett Markov-modellre épülő beszédszintetizátorban a forrásszűrő modellje kiegészíthető a szubglottális rezonanciák modellezésével, az tovább javíthatja a gépi beszéd természetességét.
Köszönetnyilvánítás
Rövidítések
Jelölések
Hivatkozások
Németh, "Improvements of Hungarian Hidden Markov Model-Based Text-to-Speech Synthesis," Acta Cybernetica, vol. Tokuda, "Details of the Nitech HMM-Based Speech Synthesis System for Blizzard Challenge 2005," IEICE Transactions on Information and Systems, vol. Tao , “Inverse filtering based harmonic plus noise excitation model for HMM-based speech synthesis,” inProc.
Kim, "Statistical Approaches to Excitation Modeling in HMM-Based Speech Synthesis,"IEICE Transactions on Information and Systems, vol. Dutoit, "A deterministic plus stochastic model of the residual signal for improved parametric speech synthesis," inProc. Gilbert, “Acoustic, aerodynamic, physiological, and perceptual properties of modal and vocal brood registers,” The Journal of the Acoustical Society of America , vol.
Alwan, “Automatic detection of second subglottal resonance and its application to speaker normalization,” Journal of the Acoustic Society of America , vol. Klatt, "Analysis, synthesis, and perception of voice quality variations between female and male speakers." Journal of the Acoustical Society of America, vol. Goldman, “Comparisons between aerodynamic, electroglottographic, and acoustic spectral measures of the female voice,” Journal of Speech and Hearing Research , vol.
Alwan, “An improved correction formula for the estimation of harmonic magnitudes and its application to open coefficient estimation,” in Proc.
Publikációs tevékenység
C2] Csapó Gábor Tamás, Németh Géza, "Új irreguláris hangmodell HMM-alapú beszédszintézishez", Proc. C3] Csapó Gábor Tamás, Németh Géza, "A New Codebook-Based Excitation Model for Use in Speech Synthesis", IEEE CogInfoCom 2012, (Kassa, Szlovákia), p. J5] Csapó Gábor Tamás, Zainkó Csaba, Németh Géza, "A Study of Prosodic Variability Methods in a Corpus-Unit Selection Text-to-Speech System", Infokommunikációs folyóirat, LXV.